Elasticsearch常见面试题
文章目录
- 1.简单介绍下ES?
- 2.简单介绍当前可以下载的ES稳定版本?
- 3.安装ES前需要安装哪种软件?
- 4.请介绍启动ES服务的步骤?
- 5.ES中的倒排索引是什么?
- 6. ES是如何实现master选举的?
- 7. 如何解决ES集群的脑裂问题
- 8. 详细描述一下ES索引文档的过程?
- 9. 详细描述一下ES更新和删除文档的过程?
- 10. 详细描述一下ES搜索的过程?
- 11.索引是什么?
- 12.请解释什么是分片(SHARDs)?
- 13.什么是副本(REPLICA), 他的作用是什么?
- 14.在ES集群中增加和创建索引的步骤是什么?
- 15.ES支持哪些类型的查询?
- 16.Elasticsearch在部署时,对Linux的设置有哪些优化方法
- 17.什么是ElasticSearch中的编译器?
- 18.拼写纠错是如何实现的?
- 19.ElasticSearch中的分析器是什么?
- 20.是否了解字典树?
- 21. 在并发情况下,ES如果保证读写一致?
- 22. ES对于大数据量(上亿量级)的聚合如何实现?
- 23. 对于GC方面,在使用ES时要注意什么?
- 24. 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?
- 参考
1.简单介绍下ES?
ES是一种存储和管理基于文档和半结构化数据的数据库(搜索引擎)。它提供实时搜索(ES最近几个版本才提供实时搜索,以前都是准实时)和分析结构化、半结构化文档、数据和地理空间信息数据。
2.简单介绍当前可以下载的ES稳定版本?
最新的稳定版本是8.11.3
3.安装ES前需要安装哪种软件?
JDK 8或者 Java 1.8.0
4.请介绍启动ES服务的步骤?
A: 启动步骤如下
Windows下进入ES文件夹的bin目录下,点击ElasticSearch.bat开始运行
打开本地9200端口http://localhost:9200, 就可以使用ES了
5.ES中的倒排索引是什么?
传统的检索方式是通过文章,逐个遍历找到对应关键词的位置。
倒排索引,是通过分词策略,形成了词和文章的映射关系表,也称倒排表,这种词典 + 映射表即为倒排索引。
其中词典中存储词元,倒排表中存储该词元在哪些文中出现的位置。
有了倒排索引,就能实现 O(1) 时间复杂度的效率检索文章了,极大的提高了检索效率。
加分项:
倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
Lucene 从 4+ 版本后开始大量使用的数据结构是 FST。FST 有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2)查询速度快。O(len(str)) 的查询时间复杂度。
6. ES是如何实现master选举的?
前置条件:
1)只有是候选主节点(master:true)的节点才能成为主节点。
2)最小主节点数(min_master_nodes)的目的是防止脑裂。
Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个RPC来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
获取主节点的核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。
选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值 discovery.zen.minimum_master_nodes;
第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
- 补充:
- 这里的 id 为 string 类型。
- master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
7. 如何解决ES集群的脑裂问题
所谓集群脑裂,是指 Elasticsearch 集群中的节点(比如共 20 个),其中的 10 个选了一个 master,另外 10 个选了另一个 master 的情况。
当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data 节点,避免脑裂问题。
8. 详细描述一下ES索引文档的过程?
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
第一步:客户端向集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演协调节点的角色。)
第二步:协调节点接受到请求后,默认使用文档 ID 参与计算(也支持通过 routing),得到该文档属于哪个分片。随后请求会被转到另外的节点。
bash# 路由算法:根据文档id或路由计算目标的分片id
shard = hash(document_id) % (num_of_primary_shards)
第三步:当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 Memory Buffer,然后定时(默认是每隔 1 秒)写入到F ilesystem Cache,这个从 Momery Buffer 到 Filesystem Cache 的过程就叫做 refresh;
第四步:当然在某些情况下,存在 Memery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
第五步:在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
第六步:flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512 M)时。
- 补充:关于 Lucene 的 Segement
- Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
- 段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
- 对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗 CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
- 为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。(段合并)
9. 详细描述一下ES更新和删除文档的过程?
删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更。
磁盘上的每个段都有一个相应的 .del 文件。当删除请求发送后,文档并没有真的被删除,而是在 .del 文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在 .del 文件中被标记为删除的文档将不会被写入新段。
在新的文档被创建时,Elasticsearch 会为该文档指定一个版本号,当执行更新时,旧版本的文档在 .del 文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
10. 详细描述一下ES搜索的过程?
搜索被执行成一个两阶段过程,即 Query Then Fetch;
Query阶段:
查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
Fetch阶段:
协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
11.索引是什么?
ES集群包含多个索引,每个索引包含一种表,表包含多个文档,并且每个文档包含不同的属性。
12.请解释什么是分片(SHARDs)?
随着索引文件的增加,磁盘容量、处理能力都会变得不够,在这种情况下,将索引数据切分成小段,这就叫分片(SHARDS)。它的出现大大改进了数据查询的效率。
13.什么是副本(REPLICA), 他的作用是什么?
副本是分片的完整拷贝,副本的作用是增加了查询的吞吐率和在极端负载情况下获得高可用的能力。副本有效的帮助处理用户请求。
14.在ES集群中增加和创建索引的步骤是什么?
可以在Kibana中配置新的索引,进行Fields Mapping,设置索引别名。也可以通过HTTP请求来创建索引。
15.ES支持哪些类型的查询?
主要分为匹配(文本)查询和基于Term的查询。
文本查询包括基本匹配,match phrase, multi-match, match phrase prefix, common terms, query-string, simple query string.
Term查询,比如term exists, type, term set, range, prefix, ids, wildcard, regexp, and fuzzy。
16.Elasticsearch在部署时,对Linux的设置有哪些优化方法
面试官:想了解对ES集群的运维能力。 解答:
- 1)关闭缓存swap;
- 2)堆内存设置为:Min(节点内存/2, 32GB);
- 3)设置最大文件句柄数;
- 4)线程池+队列大小根据业务需要做调整;
- 5)磁盘存储raid方式——存储有条件使用RAID10,增加单节点性能以及避免单节点存储故障。
17.什么是ElasticSearch中的编译器?
编译器用于将字符串分解为术语或标记流。一个简单的编译器可能会将字符串拆分为任何遇到空格或标点的地方。Elasticsearch有许多内置标记器,可用于构建自定义分析器。
18.拼写纠错是如何实现的?
1、拼写纠错是基于编辑距离来实现;编辑距离是一种标准的方法,它用来表示经过插入、删除和替换操作从一个字符串转换到另外一个字符串的最小操作步数;
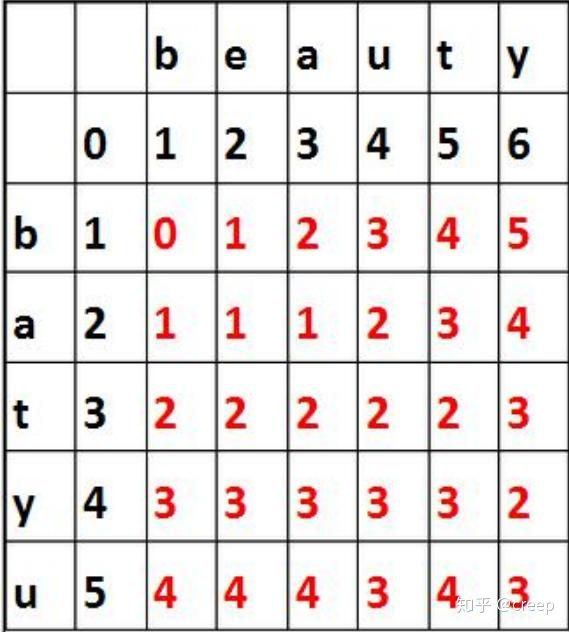
2、编辑距离的计算过程:比如要计算 batyu 和 beauty 的编辑距离,先创建一个7×8 的表(batyu 长度为 5,coffee 长度为 6,各加 2),接着,在如下位置填入黑色数字。其他格的计算过程是取以下三个值的最小值:
如果最上方的字符等于最左方的字符,则为左上方的数字。否则为左上方的数字+1。(对于 3,3 来说为 0)
左方数字+1(对于 3,3 格来说为 2)
上方数字+1(对于 3,3 格来说为 2)
最终取右下角的值即为编辑距离的值 3。
对于拼写纠错,我们考虑构造一个度量空间(Metric Space),该空间内任何关
系满足以下三条基本条件:
d(x,y) = 0 – 假如 x 与 y 的距离为 0,则 x=y
d(x,y) = d(y,x) – x 到 y 的距离等同于 y 到 x 的距离
d(x,y) + d(y,z) >= d(x,z) – 三角不等式
1、根据三角不等式,则满足与 query 距离在 n 范围内的另一个字符转 B,其与 A
的距离最大为 d+n,最小为 d-n。
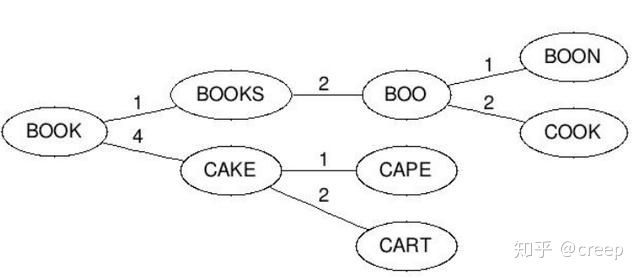
2、BK 树的构造就过程如下:每个节点有任意个子节点,每条边有个值表示编辑距离。所有子节点到父节点的边上标注 n 表示编辑距离恰好为 n。比如,我们有棵树父节点是”book”和两个子节点”cake”和”books”,”book”到”books”的边标号 1,”book”到”cake”的边上标号 4。从字典里构造好树后,无论何
时你想插入新单词时,计算该单词与根节点的编辑距离,并且查找数值为d(neweord, root)的边。递归得与各子节点进行比较,直到没有子节点,你就可以创建新的子节点并将新单词保存在那。比如,插入”boo”到刚才上述例子的树中,我们先检查根节点,查找 d(“book”, “boo”) = 1 的边,然后检查标号为1 的边的子节点,得到单词”books”。我们再计算距离 d(“books”, “boo”)=2,则将新单词插在”books”之后,边标号为 2。
3、查询相似词如下:计算单词与根节点的编辑距离 d,然后递归查找每个子节点标号为 d-n 到 d+n(包含)的边。假如被检查的节点与搜索单词的距离 d 小于 n,则返回该节点并继续查询。比如输入 cape 且最大容忍距离为 1,则先计算和根的编辑距离 d(“book”, “cape”)=4,然后接着找和根节点之间编辑距离为 3 到5 的,这
个就找到了 cake 这个节点,计算 d(“cake”, “cape”)=1,满足条件所以返回 cake,然后再找和 cake 节点编辑距离是 0 到 2 的,分别找到 cape 和cart 节点,这样就得到 cape 这个满足条件的结果。
19.ElasticSearch中的分析器是什么?
在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。 分析器由一个Tokenizer和零个或多个TokenFilter组成。编译器可以在一个或多个CharFilter之前。分析模块允许您在逻辑名称下注册分析器,然后可以在映射定义或某些API中引用它们。
Elasticsearch附带了许多可以随时使用的预建分析器。或者,您可以组合内置的字符过滤器,编译器和过滤器器来创建自定义分析器。
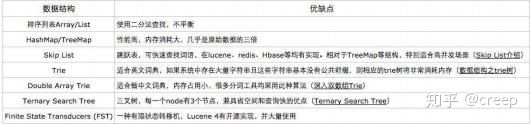
20.是否了解字典树?
常用字典数据结构如下所示:
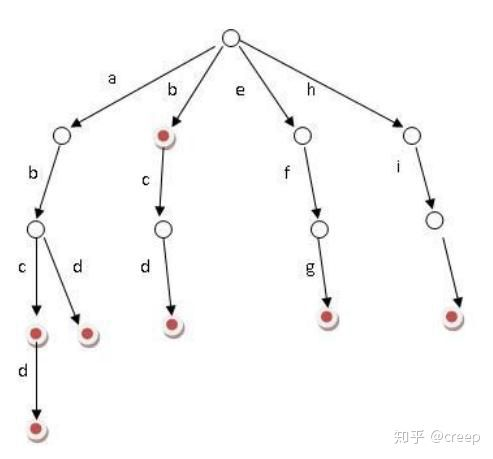
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有 3 个基本性质:
1、根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3、每个节点的所有子节点包含的字符都不相同。
1、可以看到,trie 树每一层的节点数是 26^i 级别的。所以为了节省空间,我们还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单词长度。
2、实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿子右兄弟表示法记录这棵树;
3、对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而且查询速度上可以保留哈希的复杂度 O(1)。
21. 在并发情况下,ES如果保证读写一致?
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
22. ES对于大数据量(上亿量级)的聚合如何实现?
Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
23. 对于GC方面,在使用ES时要注意什么?
1)倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
2)各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
3)避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
4)cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
5)想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
24. 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及一些调优手段?
根据实际情况回答即可,如果是我的话会这么回答:
我司有多个ES集群,下面列举其中一个。该集群有20个节点,根据数据类型和日期分库,每个索引根据数据量分片,比如日均1亿+数据的,控制单索引大小在200GB以内。
下面重点列举一些调优策略,仅是我做过的,不一定全面,如有其它建议或者补充欢迎留言。
部署层面:
1)最好是64GB内存的物理机器,但实际上32GB和16GB机器用的比较多,但绝对不能少于8G,除非数据量特别少,这点需要和客户方面沟通并合理说服对方。
2)多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
3)尽量使用SSD,因为查询和索引性能将会得到显著提升。
4)避免集群跨越大的地理距离,一般一个集群的所有节点位于一个数据中心中。
5)设置堆内存:节点内存/2,不要超过32GB。一般来说设置export ES_HEAP_SIZE=32g环境变量,比直接写-Xmx32g -Xms32g更好一点。
6)关闭缓存swap。内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个100微秒的操作可能变成10毫秒。 再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是多么可怕。
7)增加文件描述符,设置一个很大的值,如65535。Lucene使用了大量的文件,同时,Elasticsearch在节点和HTTP客户端之间进行通信也使用了大量的套接字。所有这一切都需要足够的文件描述符。
8)不要随意修改垃圾回收器(CMS)和各个线程池的大小。
9)通过设置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
索引层面:
1)使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
2)段合并:Elasticsearch默认值是20MB/s,对机械磁盘应该是个不错的设置。如果你用的是SSD,可以考虑提高到100-200MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。另外还可以增加 index.translog.flush_threshold_size 设置,从默认的512MB到更大一些的值,比如1GB,这可以在一次清空触发的时候在事务日志里积累出更大的段。
3)如果你的搜索结果不需要近实时的准确度,考虑把每个索引的index.refresh_interval 改到30s。
4)如果你在做大批量导入,考虑通过设置index.number_of_replicas: 0 关闭副本。
5)需要大量拉取数据的场景,可以采用scan & scroll api来实现,而不是from/size一个大范围。
存储层面:
1)基于数据+时间滚动创建索引,每天递增数据。控制单个索引的量,一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
2)冷热数据分离存储,热数据(比如最近3天或者一周的数据),其余为冷数据。对于冷数据不会再写入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率。
参考
https://zhuanlan.zhihu.com/p/265399976
https://www.wenyuanblog.com/blogs/elasticsearch-interview-questions.html
http://www.mianshigee.com/question
海的那边是什么已经不重要了
相关文章:
Elasticsearch常见面试题
文章目录 1.简单介绍下ES?2.简单介绍当前可以下载的ES稳定版本?3.安装ES前需要安装哪种软件?4.请介绍启动ES服务的步骤?5.ES中的倒排索引是什么?6. ES是如何实现master选举的?7. 如何解决ES集群的脑裂问题8…...
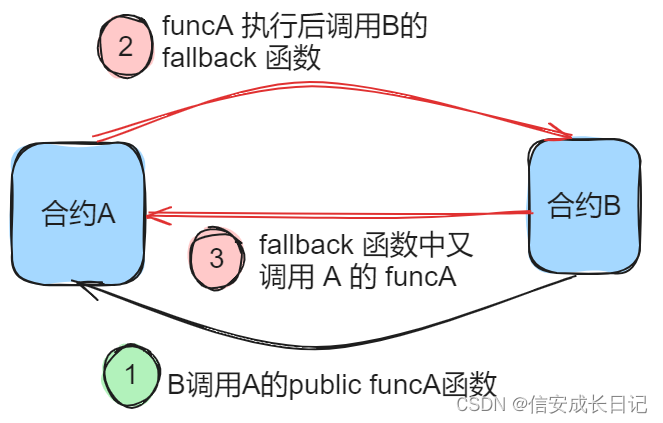
solidity 重入漏洞
目录 1. 重入漏洞的原理 2. 重入漏洞的场景 2.1 msg.sender.call 转账 2.2 修饰器中调用地址可控的函数 1. 重入漏洞的原理 重入漏洞产生的条件: 合约之间可以进行相互间的外部调用 恶意合约 B 调用了合约 A 中的 public funcA 函数,在函数 funcA…...
【智能家电】东胜物联离在线语音方案为厨电企业赋能,实现厨房智能化控制
近年来,我国厨电市场蓬勃发展。据行业统计数据显示,至今年6月,市场规模已达356亿元,同比增长8.8%。随着数字科技、物联网和人工智能的兴起,厨电产品正在朝着更智能、多功能化的方向迅速发展。 为此厨电厂商正在积极布…...

3DMAX英文版怎么切换到中文版?
3DMAX英文换到中文版的方法 3dMax是专业三维建模、渲染和动画软件,它使你能够创建广阔的真实世界和各种高级设计。 -使用强大的建模工具为环境和景观注入活力。 -使用直观的纹理和着色工具创建精细的细节设计和道具。 -迭代并制作具有完全艺术控制的专业级渲染图…...
WEB渗透—PHP反序列化(八)
Web渗透—PHP反序列化 课程学习分享(课程非本人制作,仅提供学习分享) 靶场下载地址:GitHub - mcc0624/php_ser_Class: php反序列化靶场课程,基于课程制作的靶场 课程地址:PHP反序列化漏洞学习_哔哩…...

LeetCode——2415. 反转二叉树的奇数层
通过万岁!!! 题目:给你一个完全二叉树,然后将其奇数层进行反转。思路:这个题他都说了是奇数层了,那基本就是层序遍历了。但是存在两个问题,一个是如何判断奇数层,另外一…...

【Spring学习笔记】Spring 注解开发
Spring学习——注解开发 注解开发注解开发定义bean纯注解开发 Bean管理bean作用范围bean生命周期 依赖注入自动装配 第三方bean管理注解开发总结XML配置与注解配置比较 注解开发 注解开发定义bean 使用Component定义开发 Component("bookDao") public class BookD…...
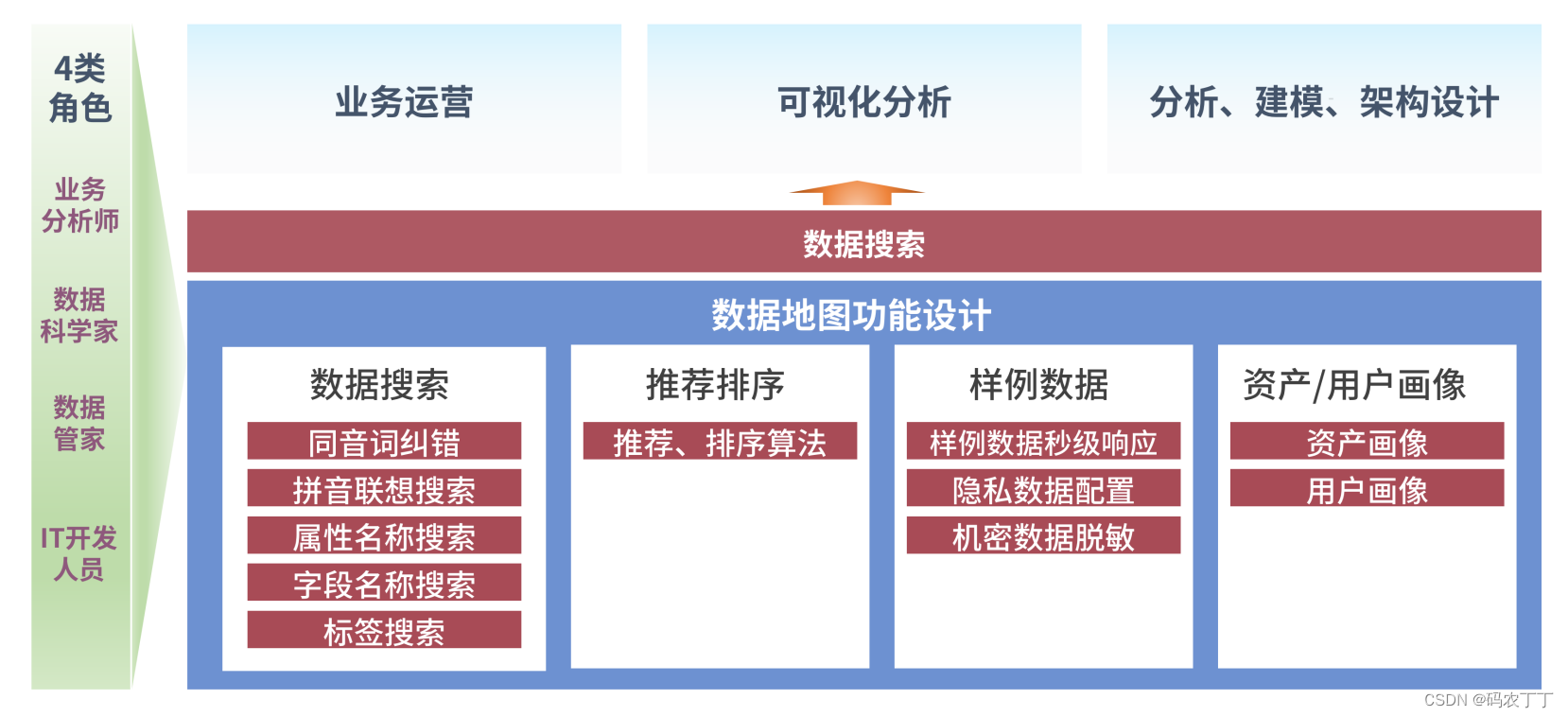
【华为数据之道学习笔记】6-5数据地图的核心价值
数据供应者与消费者之间往往存在一种矛盾:供应者做了大量的数据治理工作、提供了大量的数据,但数据消费者却仍然不满意,他们始终认为在使用数据之前存在两个重大困难。 1)找数难 企业的数据分散存储在上千个数据库、上百万张物理表…...
JavaWeb笔记之JSP
一、引言 现有问题 在之前学习Servlet时,服务端通过Servlet响应客户端页面,有什么不足之处? 开发方式麻烦:继承父类、覆盖方法、配置Web.xml或注解。 代码修改麻烦:重新编译、部署、重启服务。 显示方式麻烦&#x…...
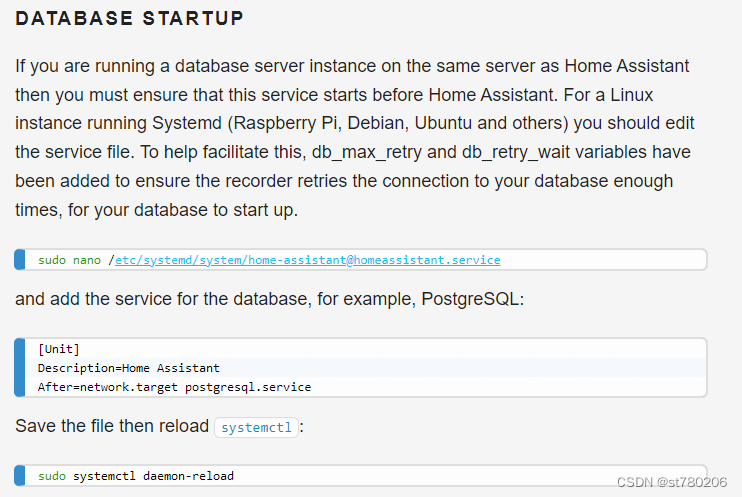
在x64上构建智能家居(home assistant)(二)(新版Debain12)连接Postgresql数据库
新版数据库安装基本和旧版相同,大部分可以参考旧版本在x64上构建智能家居(home assistant)(二)连接Postgresql数据库_homeassist 数据库-CSDN博客 新版本的home assistant系统安装,我在原来写的手顺上直接修改了,需要的可以查看在x64上构建智能家居(home…...
)
八股文打卡day6——计算机网络(6)
面试题:GET请求和POST请求的区别 我的回答: 1.作用不同:GET是用来获取服务器资源的;POST是用来向服务器提交资源的; 2.参数传递方式不同:GET请求参数一般写在URL中的,只能接收ASCII字符;POST的…...
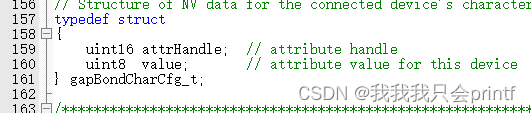
【PHY6222】绑定详解
1.函数详解 bStatus_t GAPBondMgr_SetParameter( uint16 param, uint8 len, void* pValue ) 设置绑定参数。 bStatus_t GAPBondMgr_GetParameter( uint16 param, void* pValue ) 获取绑定参数。 param: GAPBOND_PAIRING_MODE,配对模式,…...
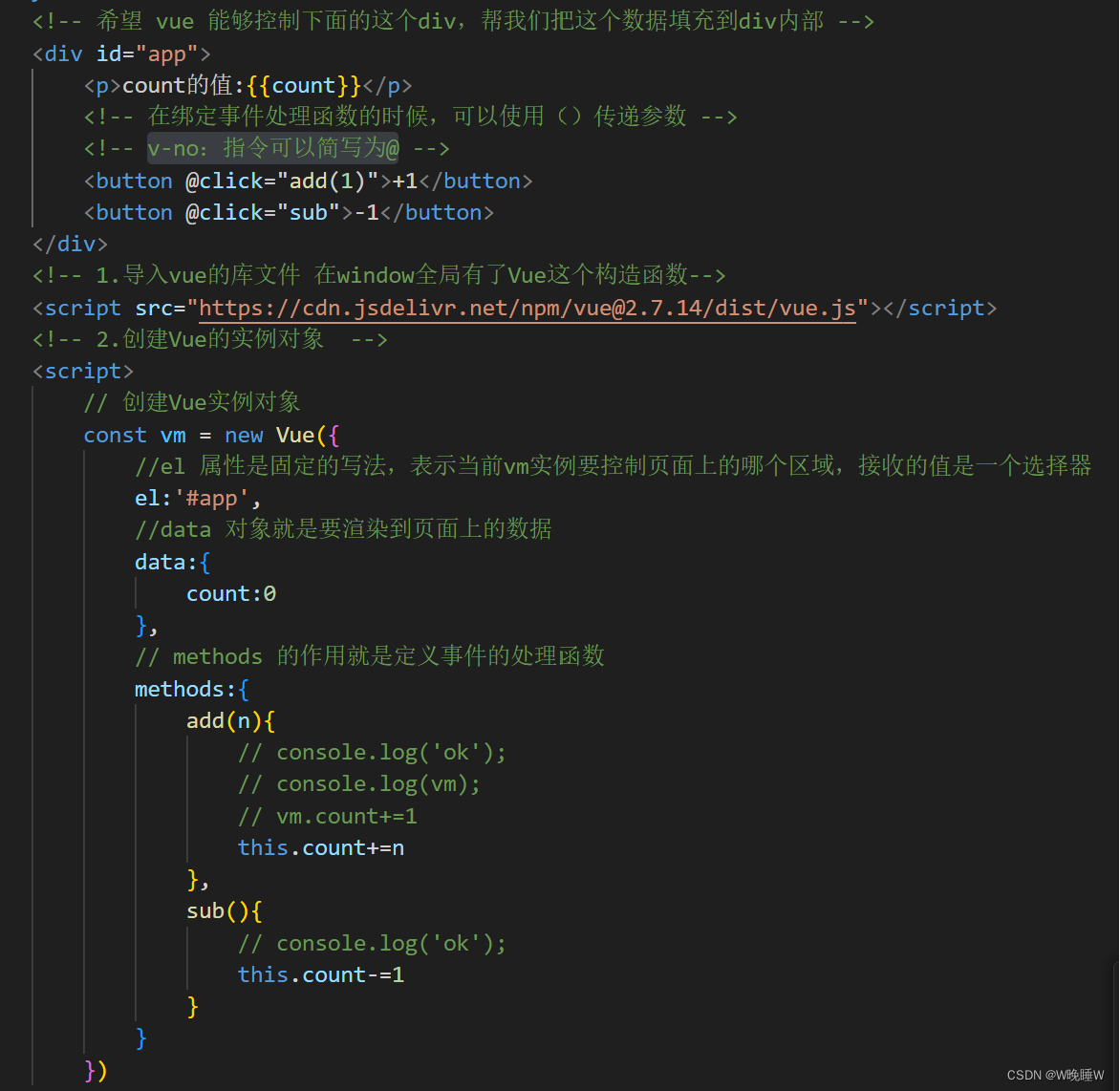
vue事件绑定
vue提供了v-on事件绑定指令,用来辅助程序员为DOM元素绑定事件监听,语法格式如下: v-on:指令可以简写为 注意:原生DOM对象有onclick,oninput,onkeyup等原生事件,替换为vue的事件绑定…...

如何在服务器上部署springboot项目
在服务器上部署Spring Boot项目通常有以下步骤: 在服务器上安装Java运行环境:首先确保服务器上已经安装了Java运行环境(至少需要Java 8或以上版本)。 快速安装JDK命令: yum install java-1.8.0-openjdk.x86_64 打包S…...

基于Spring Boot的支教志愿者招聘网站
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring Boot的支教志愿者招聘网站,j…...
安装gnvm,nodejs,npm使用方法
安装gnvm,nodejs,npm使用方法 一、安装gnvm gnvm.exe下载地址: https://download.csdn.net/download/hsg77/88651752 http://ksria.com/gnvm/#download 二、配置gnvm环境变量 新建目录,如:d:/nodejs 并把gnvm.exe存储到此目录 并把d:/node…...

word导入导出-Apache POI 和 Poi-tl
word 文件读取 使用Apache POI Word 进行读取文件 使用poi 时如果报ClassNotFoundException 等错误,请注意请求以下maven 文件的版本 Apache POI Word 说明文档:Apache POI Word 说明文档 maven 解决依赖冲突教程:https://www.cnblogs.com/…...
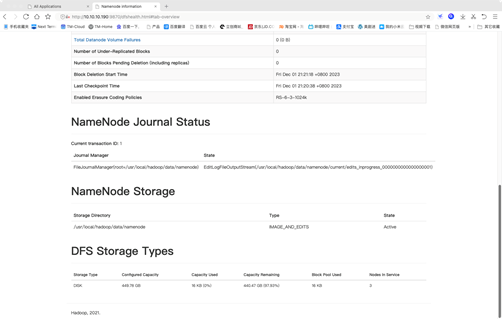
Hadoop 集群环境搭建
目录 第一部分:系统安装... 3 1:图形化安装... 3 2:选择中文... 3 3:安装选项... 3 4:软件选项... 4 5:安装位置... 4 6:网络配置... 6 7:开始安装... 7 8:创建用户... 7…...

maven完结,你真的学完了吗
书接上文:必学的maven的起步-CSDN博客 分模块开发与设计 分模块开发: 创建模块书写代码模块 模块中需要其他的模块,就将他安装到仓库然后再dep中导入依赖通过maven指令安装模块到本地仓库(install) 聚合与继承 聚合…...
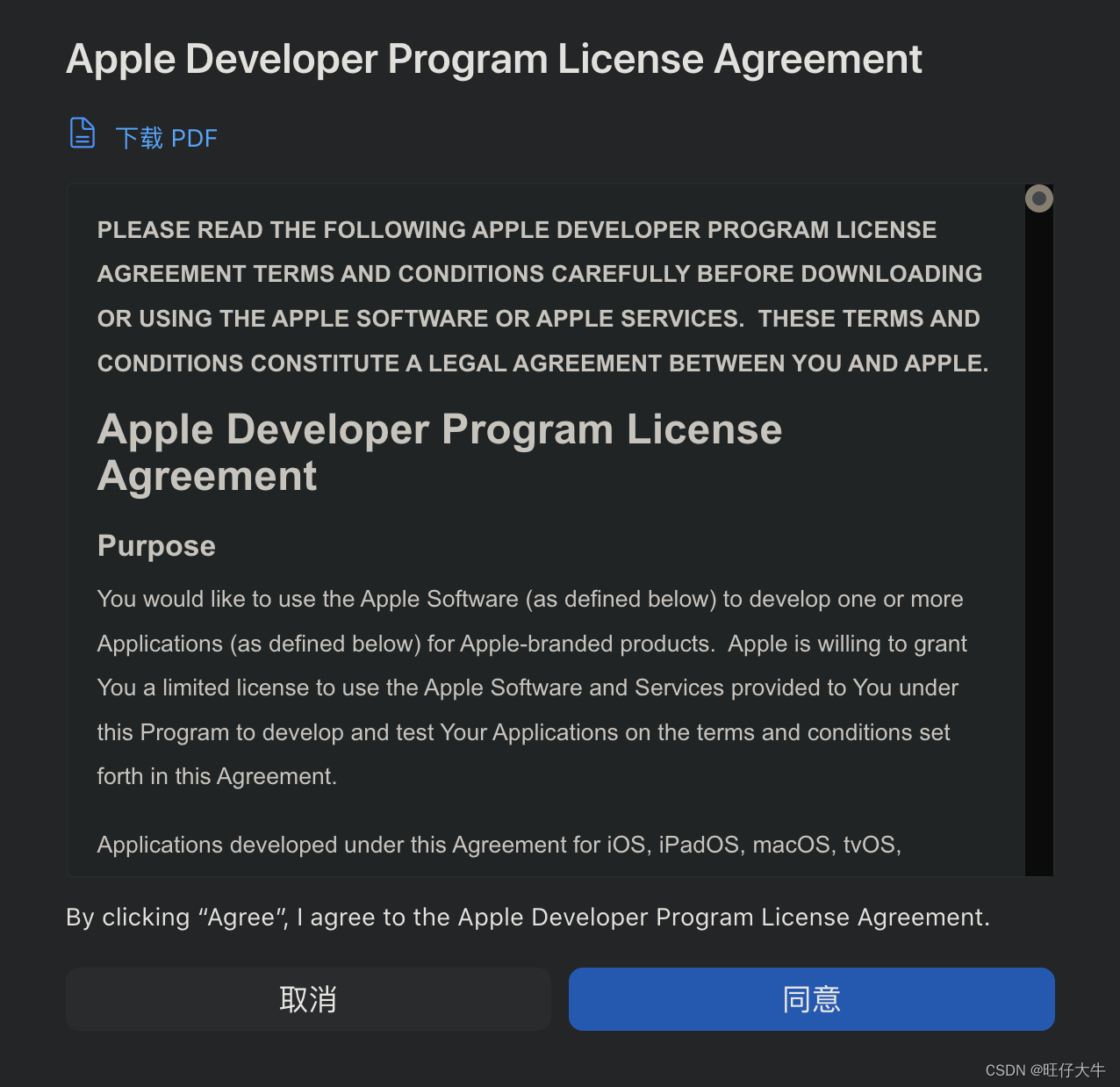
【Xcode】解决Unable to process request - PLA Update available
出现场景 IOS更新app时,使用Xcode上传新版本的包时,提示无法上传。 Unable to process request -PLA update available you currently dont have access to this membership resource. To resolve this issue ,agree to the latest program license a…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...