如何设计树形结构
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
前置知识:前后端数据传输格式(下)
新手程序员,尤其是非科班的朋友,往往都非常重视具体技术点的学习,比如多线程、JWT、Redis、甚至Spring源码,但却经常性地忽略数据库表的设计。
为什么会造成这种情况呢?
第一,大部分新手程序员参与到一个项目时,表都已经建好了,他们的工作就是在现有工程下做做CRUD。
第二,不管培训班还是网络上的学习资料,很少会专门去讲怎么设计数据库、为什么要这么设计。
所以,绝大部分非科班程序员都不具备数据库设计能力。这会带来哪些坏处呢?我个人最大的体会是,去甲方开会时,对于甲方提出的各种需求,你基本是懵逼的,完全无法和实际编程联系在一起:
啊?这个需求怎么设计表结构啊,听起来好难啊...
我自己的看法是,数据库设计是整个项目最关键、最难的地方,数据库设计的好坏直接影响编码的质量和效率。
怎么提升自己的数据库设计能力呢?我有两个建议:
- 多观察公司现有项目的某些需求设计,研究它的表结构和编码,然后抽取出几种常见的设计思路
- 自己平时多想、多做、多借鉴,自己给自己出需求,然后考虑如何设计、SQL和代码怎么写,卡住了就百度,借鉴别人的设计思路
我始终觉得数据库设计其实是存在若干种模式的,而每一种模式只要稍微变通一下,又可以用来完成很多看似完全不同的需求。限于篇幅,这里优先介绍树形结构。
树形结构是一种非常经典的表设计模型,看似平凡却又包罗万象,在实际开发中有着非常广泛的应用。
最典型的树形结构就是商品分类:
|-家用电器
|-电视
|-空调
|-洗衣机
|-滚筒洗衣机
|-洗烘一体机
|-...
|-手机/运营商/数码
|-手机通讯
|-运营商
|-手机配件
|-手机壳
|-贴膜
|-...
还有省-市-区级联:
|-浙江省
|-杭州市
|-宁波市
|-温州市
|-...
|-安徽省
|-合肥市
|-黄山市
|-芜湖市
|-...
其他的还包括目录、部门、甚至RBAC权限控制等,随处可见树形结构的设计。
严格来说,真正的树应该只有一个root节点,而上面提到的都有多个root节点,但我还是习惯称为“树形结构”。
设计阶段
如何定义JavaBean
我以前接触过一个前端插件,叫zTree。这个插件的作用是把接口返回的数据以树形结构的形式展示出来:

zTree插件需要后端返回特定的数据格式才能做出上面的效果,官方文档给的demo如下:
<!--1.准备一个Div,设置id-->
<div class="panel-body"><ul id="permissionTree" class="ztree"></ul>
</div>// 2.需要的数据
var zNodes =[{ name:"父节点1 - 展开", open:true,children: [{ name:"父节点11 - 折叠",children: [{ name:"叶子节点111"},{ name:"叶子节点112"},{ name:"叶子节点113"},{ name:"叶子节点114"}]},{ name:"父节点12 - 折叠",children: [{ name:"叶子节点121"},{ name:"叶子节点122"},{ name:"叶子节点123"},{ name:"叶子节点124"}]},{ name:"父节点13 - 没有子节点", isParent:true}]},{name:"父节点2 - 折叠", children: [{...},{...}]},{ name:"父节点3 - 没有子节点", isParent:true}
];// 3.把数据在指定div渲染成一棵树
$.fn.zTree.init($("#permissionTree"), setting, zNodes);有些字段省略,不用在意,关注外部结构即可
现在的问题是,后端如何返回上面这样的数据结构?
我们由外到内,分两步分析zNodes需要的数据格式!
先观察zNodes最外层:
var zNodes =[{ name:"父节点1", open:true,children: [...]},{ name:"父节点2",children: [...]},{ name:"父节点3 - 没有子节点", isParent:true}
];我们发现zNode其实是一个JS对象数组,现有三个对象:父节点1,父节点2,父节点3。
等等,这里有个重点!
一起放慢节奏思考一下:
现在我们已经明确zNodes是一个JS对象数组,那么Java中什么类型的数据返回到前端会变成一个数组呢?
答案是:常用List!
来做个试验:
@RestController
public class TestController {@RequestMapping("/testList")public List getList() {ArrayList<User> userList = new ArrayList<>();userList.add(new User("李健", 18));userList.add(new User("周杰伦", 20));userList.add(new User("李雪健", 30));return userList;}@RequestMapping("/testMap")public Map getMap() {HashMap<String, User> hashMap = new HashMap<>();hashMap.put("1号男嘉宾", new User("卡卡罗特", 21));hashMap.put("2号男嘉宾", new User("贝吉塔", 22));hashMap.put("3号男嘉宾", new User("雅木茶", 23));return hashMap;}@RequestMapping("/testSet")public Set getSet() {HashSet<User> hashSet = new HashSet<>();hashSet.add(new User("刘备", 33));hashSet.add(new User("关羽", 32));hashSet.add(new User("张飞", 31));return hashSet;}
}Postman测试(以List为例):
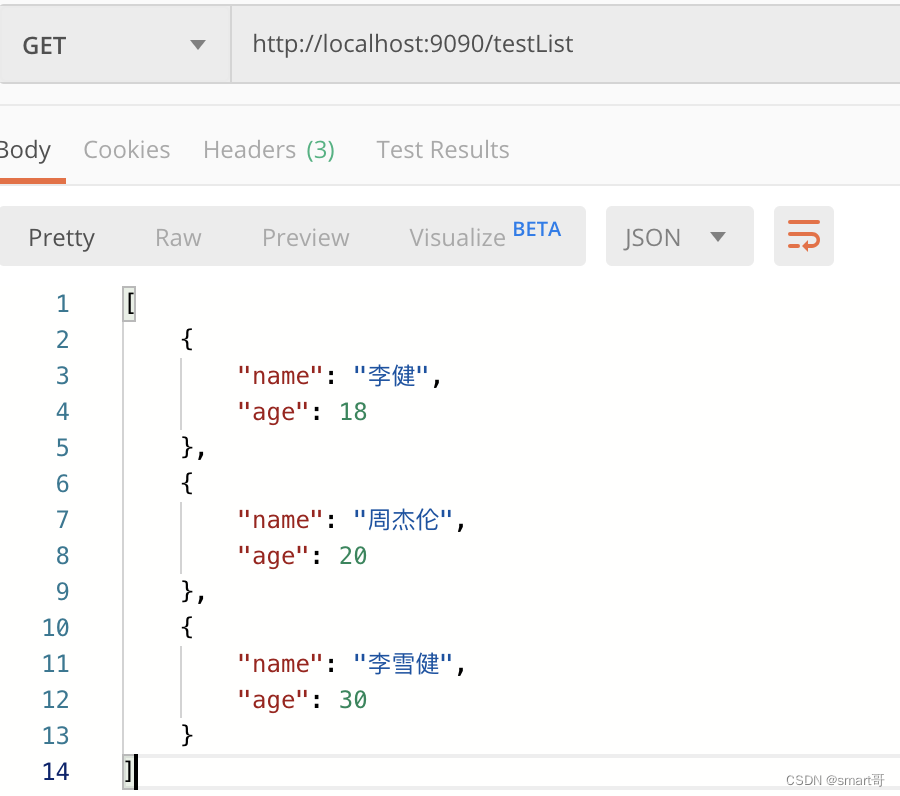
全部测完,对比结果:

后端返回的其实都是JSON,但是本文的视角是前端,所以把JSON和JS对象一同看待
上面只例举了Map、List、Set,其实数组的返回结果和List、Set一样。但通常不用数组,因为数组可用的方法太少,不利于后端通过数组对数据进行操作。
我们发现,Map到了前端对应一个JS对象,而Set和List都是对应一个JS数组。实际开发中,前端如果需要一个数组,我们通常返回List即可,Set的情况较少(除非要去重)。
至此,关于如何设计JavaBean,我们确定了一个大方向:最外层用List返回。
接下来,我们往zNodes的内层走走,分析一下后端的List应该存什么对象,也就是如何设计JavaBean。
var zNodes =[{ name:"父节点1 - 展开11111", open:true,children: [{ name:"父节点11 - 折叠",children: [...]},{ name:"父节点12 - 折叠",children: [...]},{ name:"父节点13 - 没有子节点", isParent:true}]},{ name:"父节点2 - 折叠",children: [...]},{ name:"父节点3 - 没有子节点", isParent:true}
];我们发现父节点1的children其实也是一个对象数组,而且内部JS对象的结构和最外面三个父节点JS对象一致。很多新手看到这样的数据,老觉得这里是递归,无穷无尽,后端干脆没法设计...
那么,前端是否是无限递归呢?
我们退回来,慢慢推导。
假设后端List中存的对象叫JsBean,那么JsBean最终传到前端就变成了zNodes对象数组中的JS对象。
List [JsBean, JsBean, JsBean...] ===> zNodes[{...}, {...}, {...}]
这个应该能理解吧?后端List对应前端zNodes的[],JsBean对应zNodes数组内部的JS对象。
后端:JsBean
public class JsBean{private String name;private Boolean open;private Boolean isParent;// 前端JS对象的children数组(对应List)里存的还是JS对象(对应JsBean),所以是List<JsBean>private List<JsBean> children;
}前端:JS对象(请和上面JsBean对照,看看这样设计是否合理)
{ name:"父节点1 - 展开11111", open:true,children: [{ name:"父节点11 - 折叠",children: [...]},{ name:"父节点12 - 折叠",children: [...]},{ name:"父节点13 - 没有子节点", isParent:true}]
}先不考虑递归啥的,就暂时当数据只有三级好了~
那么,后端这样设计Bean表示到底对不对呢?做个试验吧:
@RestController
public class TestController {@RequestMapping("testList")public List getList() {// 定义一个List,用来存储最终结果ArrayList<JsBean> superMen = new ArrayList<>();//------------------------七龙珠(从下往上看会好理解些,开枝散叶)------------------------// 孙悟饭的儿子们:悟饭儿子1、悟饭儿子2List<JsBean> grandChildren1 = new ArrayList<>();grandChildren1.add(new JsBean("悟饭儿子1", false, false, null));grandChildren1.add(new JsBean("悟饭儿子2", false, false, null));// 孙悟天的儿子们:悟天儿子1、悟天儿子2List<JsBean> grandChildren2 = new ArrayList<>();grandChildren2.add(new JsBean("悟天儿子1", false, false, null));grandChildren2.add(new JsBean("悟天儿子2", false, false, null));// 孙悟空的儿子:悟饭、悟天List<JsBean> children = new ArrayList<>();children.add(new JsBean("悟饭", false, true, grandChildren1));children.add(new JsBean("悟天", false, true, grandChildren2));// 孙悟空本人JsBean wukong = new JsBean("悟空", true, true, children);//------------------------火影忍者(从下往上看会好理解些,开枝散叶)------------------------// 鸣人的徒弟们:博人1、博人2List<JsBean> grandChildren3 = new ArrayList<>();grandChildren3.add(new JsBean("博人1", false, false, null));grandChildren3.add(new JsBean("博人2", false, false, null));// 佐助的徒弟们:佐良娜1、佐良娜2List<JsBean> grandChildren4 = new ArrayList<>();grandChildren4.add(new JsBean("佐良娜1", false, false, null));grandChildren4.add(new JsBean("佐良娜2", false, false, null));// 卡卡西的徒弟们:鸣人、佐助List<JsBean> children2 = new ArrayList<>();children2.add(new JsBean("鸣人", false, true, grandChildren3));children2.add(new JsBean("佐助", false, true, grandChildren4));// 卡卡西本人JsBean kakaxi = new JsBean("卡卡西", true, true, children2);//------------------------处理结果------------------------// 只把孙悟空和卡卡西加入ListsuperMen.add(wukong);superMen.add(kakaxi);return superMen;}
}
Postman得到结果:
[{"name": "悟空","open": true,"isParent": true,"children": [{"name": "悟饭","open": false,"isParent": true,"children": [{"name": "悟饭儿子1","open": false,"isParent": false,"children": null},{"name": "悟饭儿子2","open": false,"isParent": false,"children": null}]},{"name": "悟天","open": false,"isParent": true,"children": [{"name": "悟天儿子1","open": false,"isParent": false,"children": null},{"name": "悟天儿子2","open": false,"isParent": false,"children": null}]}]},{"name": "卡卡西","open": true,"isParent": true,"children": [{"name": "鸣人","open": false,"isParent": true,"children": [{"name": "博人1","open": false,"isParent": false,"children": null},{"name": "博人2","open": false,"isParent": false,"children": null}]},{"name": "佐助","open": false,"isParent": true,"children": [{"name": "佐良娜1","open": false,"isParent": false,"children": null},{"name": "佐良娜2","open": false,"isParent": false,"children": null}]}]}
]后端返回一个List,所以前端整体看是一个JS数组。数组最外层是两个JS对象:

展开:

是不是和 zNodes一模一样?
也就是说,后端这样设计JavaBean完全没问题。前端JS对象数组并不是所谓的无限递归,它的层级取决于数据库表中数据设计了多少层。所以在树形结构中,不要去担心前端会不会出现无限递归,而要问后端要设置多少级数据!从后往前设计,由后端来控制整个树形结构的深度。
就好比刚才的程序中,我让悟天孩子不再有孩子,于是返回前端后,悟天儿子1就没有children了:

也就是说,前端是跟着后端走的,不要尝试从前端逆推,那样你会觉得似乎是无限递归,无从下手。
至此,JavaBean设计完毕,后端只要返回Superman的List集合就能刚好满足zNodes的数据格式:
public class Superman{private String name;private Boolean open;private Boolean isParent;// 前端JS对象的children数组(对应List)里存的还是JS对象(对应Superman),所以是List<Superman>private List<Superman> children;
}如何设计表
接下来我们考虑下数据库表如何设计(刚才只是验证了Bean的设计,数据是我们在代码里造的)。
对于树形结构,我们最直观的想法自然是为每一级都创建一个对应的表。又由于父可以有多个子,具备一对多的关系。遇到一对多,我首先最直观的想法是使用外键(pid)关联。
分析龙珠里的人物关系,我发现数据最深层级是3级。
如果每一级都创建一张表,共需设计三张表。比如一级的我都存入t_first,二级的我都存入t_second...然后用外键关联每张表。
t_first
| id | name | open | isParent |
| 1 | 孙悟空 | 0 | 1 |
| 2 | 贝吉塔 | 0 | 1 |
t_second(pid指向t_first,表明他们的父亲)
| id | name | open | isParent | pid |
| 1 | 孙悟饭 | 0 | 1 | 1 |
| 2 | 孙悟天 | 0 | 0 | 1 |
| 3 | 特兰克斯 | 0 | 0 | 2 |
t_third(pid指向t_second,表明她的父亲)
| id | name | open | isParent | pid |
| 1 | 小芳 | 0 | 0 | 1 |
先不说表字段是否合理,这个表本身就不合理...万一小芳再生小孩呢(层级加深)?我需要再建一张表。另外,遇到某些业务场景下数据层级很深的情况,那我要建多少张表?
我们能不能把这些表合并,用一张表表示复杂的父子层级关系?
很容易发现,这三张表字段都是基本相同,合并起来还是比较容易的。我们采用并集。
合并的第一步,是让三张表具有相同的字段(其实就是给t_first补充pid字段):
t_first
| id | name | open | isParent | pid |
| 1 | 孙悟空 | 0 | 1 | ? |
| 2 | 贝吉塔 | 0 | 1 | ? |
t_second(pid指向t_first,表明他们的父亲)
| id | name | open | isParent | pid |
| 1 | 孙悟饭 | 0 | 1 | 1 |
| 2 | 孙悟天 | 0 | 0 | 1 |
| 3 | 特兰克斯 | 0 | 0 | 2 |
t_third(pid指向t_second,表明她的父亲)
| id | name | open | isParent | pid |
| 1 | 小芳 | 0 | 0 | 1 |
万事开头难,我们发现t_first加了pid字段后,竟不知该填什么数据(用?占位)...问题出在哪?因为在我们目前这个设定中,孙悟空和贝吉塔是第1级,他们没有父亲。那就干脆写个0好了。以后看到pid=0的,就知道这是第1级。
嗯?等等。如果用pid表示父亲的id,pid=0代表第1级,那么第2级的pid指向第1级的id,不就形成了一对多的关系了吗?

所以,合并第二步就是把三张表压缩成一张:
| id | name | isParent | open | pid |
| 1 | 孙悟空 | 1 | 0 | 0 |
| 2 | 贝吉塔 | 1 | 0 | 0 |
| 3 | 孙悟饭 | 1 | 0 | 1 |
| 4 | 孙悟天 | 0 | 0 | 1 |
| 5 | 特兰克斯 | 0 | 0 | 2 |
| 6 | 小芳 | 0 | 0 | 3 |
这样一来,原先三张表通过外键关联,现在变成了一张表自关联:pid关联id。
接着,我们尝试一下能否根据这张表查出具有层级关系的数据
- 先找第1级:pid=0,得到孙悟空(id=1)、贝吉塔(id=2)
- 再找第2级:
-
- pid=1的都是孙悟空的孩子
-
-
- 孙悟饭(id=3)
- 孙悟天(id=4)
-
-
- pid=2的都是贝吉塔的孩子
-
-
- 特兰克斯(id=5)
-
- 最后找第3级:
-
- pid=3的都是孙悟饭的孩子
-
-
- 小芳(id=6)
-
-
- pid=4的都是孙悟天的孩子(无)
- pid=5的都是特兰克斯的孩子(无)
- 尝试查找第4级:
-
- pid=6的都是小芳的孩子(无)
嗯,完美,都查出来了,但我们发现查找过程中根本没用到name,isParent,open。
对于一颗树,其实只需要id和pid,相当于树干脉络,其他的都是点缀。
name:前端展示时,显示当前节点的名称
isParent:当前节点下面有没有孩子
open:前端根据它确定是否要展开显示
为了给上面的字段分类,我新创了两个名词:
- 结构字段:pid、id
- 业务字段:name、isParent、open
pid和id属于结构字段,它俩是维持树形结构的必须字段,是根基,而其他3个字段属于业务字段,用于展示数据,或作为前端的判断标识,可以根据业务需求进行增添。
其中isParent蛮有意思的,这里单独说一下。比如我在数据库中随便指着一个节点,你能否马上告诉我他下面有没有孩子?(之所以有这个需求,是因为前端有可能需要把有孩子的节点渲染成文件夹样式)
答案是不能。不要想pid,它只是告诉你当前节点的parent是谁,而不是当前节点有没有子节点。如果没有isParent字段,你必须去数据库查有没有以这个节点的id为pid的数据,这显然很麻烦。所以,我们可以在插入或更新时去维护这个字段(一般这种分类很少会改动,查询居多)。
那么,最终我们得到一个可以表示树形层级结构的表:
t_superman
| id | name | isParent | open | pid |
| 1 | 孙悟空 | 1 | 0 | 0 |
| 2 | 贝吉塔 | 1 | 0 | 0 |
| 3 | 孙悟饭 | 1 | 0 | 1 |
| 4 | 孙悟天 | 0 | 0 | 1 |
| 5 | 特兰克斯 | 0 | 0 | 2 |
| 6 | 小芳 | 0 | 0 | 3 |
一句话总结:
对于多层级的表来说最重要的id和pid,它们决定了数据的层级脉络,其他的属于附属内容。比如该节点是不是父节点(isParent),如果是,前端渲染时是否展开(open)。这些对于数据结构本身是无关紧要的。
但是反过来,从业务内容来讲,pid是其次的,name等附属内容才是最重要的,它们才是数据主体。
读取表中数据
至此我们完成了JavaBean和表的设计,接下来我们学习一下如何查询数据并返回树形结构的数据。一般我们参与开发时,主要做的就是这一步。从这个角度来看,上面的设计固然重要,但学会如何编码才是当务之急。
这里介绍三种方法:
- 递归读取
- for循环读取
- map集合读取
本节介绍的三种方法都是全量嵌套查询,而一般情况下根据pid分步查询更为妥当,既简单又不容易出错。希望大家学了这篇文章后,不要无脑使用全量嵌套。为了炫技而炫技,可能会被打。
环境准备
SQL文件
/*Navicat Premium Data TransferSource Server : learnforfunSource Server Type : MySQLSource Server Version : 50719Source Host : localhost:3306Source Schema : testTarget Server Type : MySQLTarget Server Version : 50719File Encoding : 65001Date: 31/12/2019 10:56:18
*/SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for t_superman
-- ----------------------------
DROP TABLE IF EXISTS `t_superman`;
CREATE TABLE `t_superman` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,`open` tinyint(2) DEFAULT NULL,`pid` int(11) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;-- ----------------------------
-- Records of t_superman
-- ----------------------------
BEGIN;
INSERT INTO `t_superman` VALUES (1, '孙悟空', 0, 0);
INSERT INTO `t_superman` VALUES (2, '贝吉塔', 0, 0);
INSERT INTO `t_superman` VALUES (3, '孙悟饭', 0, 1);
INSERT INTO `t_superman` VALUES (4, '孙悟天', 0, 1);
INSERT INTO `t_superman` VALUES (5, '特兰克斯', 0, 2);
INSERT INTO `t_superman` VALUES (6, '小芳', 0, 3);
COMMIT;SET FOREIGN_KEY_CHECKS = 1;Pom依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>tk.mybatis</groupId><artifactId>mapper-spring-boot-starter</artifactId><version>2.1.5</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
</dependencies>启动类
@SpringBootApplication
@MapperScan("com.bravo.tree.mapper")
public class SpringbootDemoApplication {public static void main(String[] args) {SpringApplication.run(SpringbootDemoApplication.class, args);}
}
Pojo
@Data
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "t_superman")
public class Superman {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Integer id;private String name;private String isParent;private Boolean open;private Integer pid;// 前端JS对象的children数组(对应List)里存的还是JS对象(对应Superman),所以是List<Superman>@Transientprivate List<Superman> children = new ArrayList<>();
}Controller
@RestController
public class SupermanController {@Autowiredprivate SupermanService supermanService;@RequestMapping("/getAllSuperman")public List getAllSuperman() {// supermanService才是重点,接下来演示三种全量嵌套查询的方法List<Superman> list = supermanService.getAllSuperman();return list;}
}递归读取
我个人不是很擅长递归,不知道其他人是否一样。下面3个方法其实可以合并,但是为了降低理解难度,我还是拆开:
@Service
public class SupermanService {@Autowiredprivate SupermanMapper supermanMapper;/*** 查询所有赛亚人* @return*/public List<Superman> getAllSuperman() {// 查出所有的根节点:孙悟空、贝吉塔List<Superman> rootSupermanList = getRootSuperman();// 分别查出孙悟空和贝吉塔的孩子,并设置for (Superman superman : rootSupermanList) { List<Superman> children = queryChildrenByParent(superman);superman.setChildren(children);}// 返回return rootSupermanList;}/*** 查出根节点(pid=0)* @return*/private List<Superman> getRootSuperman() {Superman superman = new Superman();superman.setPid(0);return supermanMapper.select(superman);}/*** 递归查询孩子* @param parent* @return*/private List<Superman> queryChildrenByParent(Superman parent) {// 准备查询条件querySuperman query = new Superman();query.setPid(parent.getId());// 查出孩子List<Superman> children = supermanMapper.select(query);// 查出每个孩子的孩子,并设置for (Superman child : children) {List<Superman> grandChildren = queryChildrenByParent(child);// 递归child.setChildren(grandChildren);}return children;}
}
特别注意递归的结束条件,否则容易出现死递归,造成内存溢出。在当前案例中,叶子节点是没有child的,所以不会再调用查询方法,也就走出递归了。

优点:直观(并没有觉得...递归对我而言很难)
缺点:在我们程序中,每次递归调用都会查询一次数据库,效率非常低
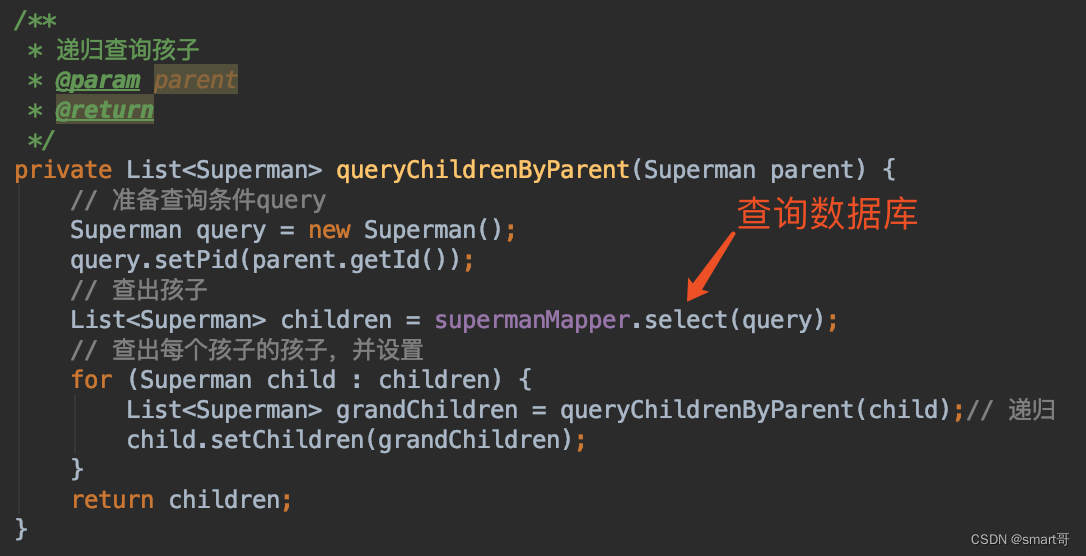
之前提到过,假设查询数据库总耗时10s,那么光是连接数据库就要花3s,也就是说,频繁调用数据库必然会降低性能。
上面递归方式不是重点,所以这里就不继续深入,只给出优化的方向:
- 造一个根节点,简化递归(根节点不止一个,所以上面代码只能配合for,每个根节点来一遍递归,很冗余)
- 先查出全部数据,再递归,而不是每递归一层就查询一次数据库,效率很低
for循环读取
吸取上面递归查询的教训,我们做两点改良:
- 先全量查询数据,再考虑如何组装树形结构
- 用for循环代替递归

/*** 查询所有赛亚人* @return*/
public List<Superman> getAllSuperman() {// 用来存储最终的结果List<Superman> list = new ArrayList<>();// 先查出全部数据List<Superman> data = supermanMapper.selectAll();// 双层for循环完成数据组装for (Superman left : data) {for (Superman right : data) {// 如果右边是左边的孩子,就设置进去if(left.getId() == right.getPid()){left.getChildren().add(right);}}// 只把第1级加到listif(left.getPid() == 0){list.add(left);}}return list;
}示意图
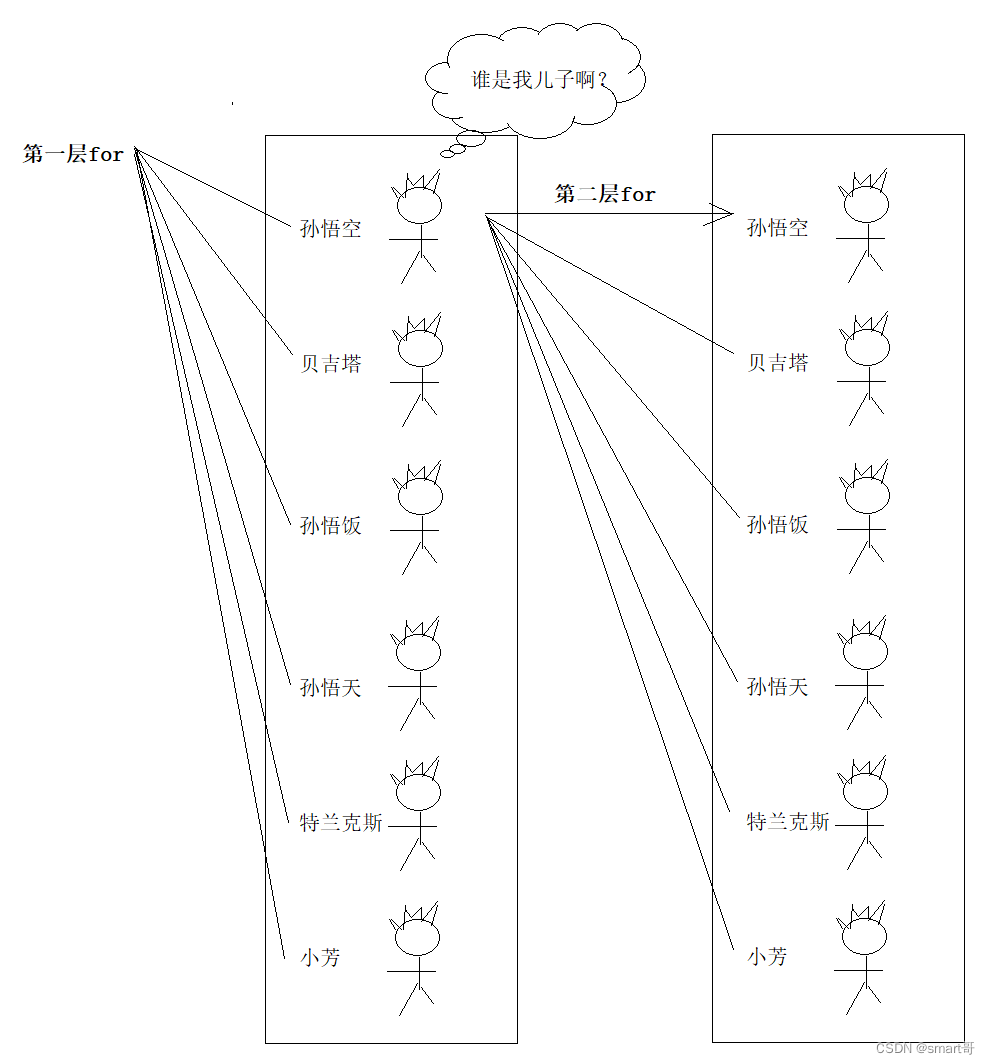
你可能会觉得,不对啊,左边孙悟空全部喊一遍后,设置了孙悟饭、孙悟天。但是此时悟饭没有设置小芳啊!
别忘了,孙悟空设置的其实是孙悟饭的引用。等左边悟饭全部喊一遍,把小芳加进来时,悟空里的悟饭不就有小芳了吗?
关于这点,需要的话可以停下来想想是不是这么回事。
优点:只查询一次数据库,而且很直观(个人觉得比递归直观)
缺点:双层for效率仍然很低,如果list长度为n,那么要循环n2次。也就是说,如果现在这个List表示的是全国的高校(学校-院系-专业),截止至2019年6月15日,教育部公布的全国高等学校共计有2956所,那么需要循环29562次,差不多是30002=900w次...
map集合读取
其实看到上面使用双层for,相信一部分同学已经能想到《实用小算法》了~没错,我们当时说《实用小算法》就是为了解决“数据匹配问题”而生的!
/*** 查询所有赛亚人* @return*/
public List<Superman> getAllSuperman() {// 用来存储最终的结果List<Superman> list = new ArrayList<>();// 源数据,需要处理List<Superman> data = supermanMapper.selectAll();// Map,用来转存ListHashMap<Integer, Superman> hashMap = new HashMap<>();// 先把List转为Map,把Map作为左侧parentfor (Superman superman : data) {hashMap.put(superman.getId(), superman);}// 右边child进行for循环找parentfor (Superman child : data) {if(child.getPid() == 0){list.add(child);// 找到第一级(悟空、贝吉塔)} else {// 不是第一级,那么肯定有parent,帮它找到parent,并把它自己设置到parent里Superman parent = hashMap.get(child.getPid());// hash索引!找爸爸很快!parent.getChildren().add(child);}}return list;
}示意图

优点:查询效率提高了
缺点:空间利用率降低了(List/Array可以只存元素,而Map需要额外存储key)
本次循环次数是2n,双层for循环是n2 ,非要说的话,就是典型的“空间换时间”。
最终代码
Controller
public class SupermanController {@Autowiredprivate SupermanService supermanService;/*** 全量嵌套查询,数据具备树形结构* @return*/@RequestMapping("/getAllSuperman")public List getAllSuperman() {List<Superman> list = supermanService.getAllSuperman();return list;}/*** 根据pid分步查询(实际开发最常用)* @param pid* @return*/@RequestMapping("getSupermanByPid")public List getSupermanByPid(Integer pid) {List<Superman> list = supermanService.getSupermanByPid(pid);return list;}
}Service
@Service
public class SupermanService {@Autowiredprivate SupermanMapper supermanMapper;/*** 查询所有赛亚人* @return*/public List<Superman> getAllSuperman() {// 用来存储最终的结果List<Superman> list = new ArrayList<>();// 源数据,需要处理List<Superman> data = supermanMapper.selectAll();// Map转ListHashMap<Integer, Superman> hashMap = new HashMap<>();for (Superman superman : data) {hashMap.put(superman.getId(), superman);}// 遍历源数据for (Superman child : data) {if(child.getPid() == 0){list.add(child);// 找到根节点并存储} else {// 如果不是根节点,则找到上一级,并把自己设置为上一级的子节点Superman parent = hashMap.get(child.getPid());parent.getChildren().add(child);}}return list;}/*** 查询pid对应的下级内容* @param pid* @return*/public List<Superman> getSupermanByPid(Integer pid) {Superman query = new Superman();query.setPid(pid);return supermanMapper.select(query);}
}
延伸思考
写到最后,你会突然发现,其实不管业务场景是下面哪种:
- 省-市
- 省-市-区
- 高校-院系-专业-班级
- 商品分类
- ...
其实都是一样的!上面的模式其实就分为两部分:
- 表设计层面
- 代码层面
首先,表结构设计都是一样的,都是树形结构,变化的只是业务字段。
- 结构字段:pid、id
- 业务字段:city_name/school_name/category_name
其次,代码层面也不会因为前端是二级联查、三级联查还是N级联查而改变,双层for可以应付N级联查,代码都不需要改动。
到底前端是几级,和表结构无关,而和表数据有关。
二级(省-市)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
三级(省-市-县)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
| 7 | 苍南县 | 3 |
| 8 | 平阳县 | 3 |
四级(省-市-县-镇)
| id | name | pid |
| 1 | 浙江省 | 0 |
| 2 | 安徽省 | 0 |
| 3 | 温州市 | 1 |
| 4 | 杭州市 | 1 |
| 5 | 合肥市 | 2 |
| 6 | 芜湖市 | 2 |
| 7 | 苍南县 | 3 |
| 8 | 平阳县 | 3 |
| 9 | 钱库镇 | 7 |
| 10 | 金乡镇 | 7 |
四级(学校-院系-专业-班级)
| id | name | pid |
| 1 | 浙江大学 | 0 |
| 2 | 浙江工业大学 | 0 |
| 3 | 外国语学院 | 1 |
| 4 | 计算机学院 | 1 |
| 5 | 人文学院 | 2 |
| 6 | 土木工程 | 2 |
| 7 | 日语 | 3 |
| 8 | 英语 | 3 |
| 9 | 日语111班 | 7 |
| 10 | 日语112班 | 7 |
一模一样的表结构,但是前端展示出来的分别是二级、三级、四级,也就是说:结构字段决定树形结构,而业务数据决定树的深度。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬
相关文章:
如何设计树形结构
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 前置知识:前…...

限量25台,川崎亮相Ninja ZX-10RR冬季限量款
最近川崎发布了自家ZX-10RR的超级限量版,官方称之为冬季测试版,之前也有一些车型推出过冬季测试版,通常是在年底推出,因为这个时候北半球都是非常寒冷的冬天。 不过这台ZX-10RR冬季测试版,并不仅仅只是限量那么简单&am…...
【QT八股文】系列之篇章1 | QT的基础知识及事件/机制
【QT八股文】系列之篇章1 | QT的基础知识及事件/机制 前言0. 基础Qt/PyQt5介绍/关联Qt的优缺点(为什么要用qt来做界面)Qt 的核心机制请简要介绍一下Qt中的主窗口(MainWindow)类,它有哪些重要的函数和成员变量ÿ…...

SpringBoot 3 集成Hive 3
前提条件: 运行环境:Hadoop 3.* Hive 3.* MySQL 8 ,如果还未安装相关环境,请参考:Hive 一文读懂 Centos7 安装Hadoop3 单机版本(伪分布式版本) SpringBoot 2 集成Hive 3 pom.xml <?xml ver…...

STL中优先队列的模拟实现与仿函数的介绍
文章目录 仿函数优先队列的模拟实现 仿函数 上回我们说到,优先队列的实现需要用到仿函数的特性 让我们再回到这里 这里我们发现他传入的用于比较的东西竟然是一个类模板,而不是我们所见到的函数 我们可以先创建一个类,用于比较大小 struc…...
LeetCode刷题--- 目标和
个人主页:元清加油_【C】,【C语言】,【数据结构与算法】-CSDN博客 个人专栏 力扣递归算法题 http://t.csdnimg.cn/yUl2I 【C】 http://t.csdnimg.cn/6AbpV 数据结构与算法 http://t.csdnimg.cn/hKh2l 前言:这个专栏主要讲述递归递归、搜…...
详解(二))
【.NET Core】反射(Reflection)详解(二)
【.NET Core】反射(Reflection)详解(二) 文章目录 【.NET Core】反射(Reflection)详解(二)一、概述二、Type类2.1 Type对象表示哪些类型2.2 获取Type及其关联对象类型的方式2.3 Type…...

【错误记录/js】保存octet-stream为文件后数据错乱
目录 说在前面场景解决方式其他 说在前面 后端:go、gin浏览器:Microsoft Edge 120.0.2210.77 (正式版本) (64 位) 场景 前端通过点击按钮来下载一些文件,但是文件内容是一些非文件形式存储的二进制数据。 后端代码 r : gin.Default()r.Stat…...

sql_lab之sqli中的post注入
Post注入 用burpsuit抓包去做 Post第一关:(gxa5) 1.判断是否存在注入 username1or 11 #&password123&submit%E7%99%BB%E5%BD%95 有回显 username1or 12 #&password123&submit%E7%99%BB%E5%BD%95 没有回显 则证明存在sq…...

智能优化算法应用:基于白冠鸡算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于白冠鸡算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于白冠鸡算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.白冠鸡算法4.实验参数设定5.算法结果6.参考文…...
DETR++: Taming Your Multi-Scale Detection Transformer论文解读
文章目录 前言一、摘要二、引言三、相关研究四、模型方法1、Removing the Encoder方法2、Multi-Head方法3、Shifted Windows方法4、Bi-directional Feature Pyramid方法5、DETR方法 五、实验结果总结 前言 今天查看了一篇DETR论文,本想网络上找博客大概浏览一下&am…...

高级数据结构 <二叉搜索树>
本文已收录至《数据结构(C/C语言)》专栏! 作者:ARMCSKGT 目录 前言正文二叉搜索树的概念二叉搜索树的基本功能实现二叉搜索树的基本框架插入节点删除节点查找函数中序遍历函数析构函数和销毁函数(后序遍历销毁)拷贝构造和赋值重载(前序遍历创建)其他函数…...
蚂蚁集团5大开源项目获开放原子 “2023快速成长开源项目”
12月16日,在开放原子开源基金会主办的“2023开放原子开发者大会”上,蚂蚁集团主导开源的图数据库TuGraph、时序数据库CeresDB、隐私计算框架隐语SecretFlow、前端框架OpenSumi、数据域大模型开源框架DB-GPT入选“2023快速成长开源项目”。 (图…...
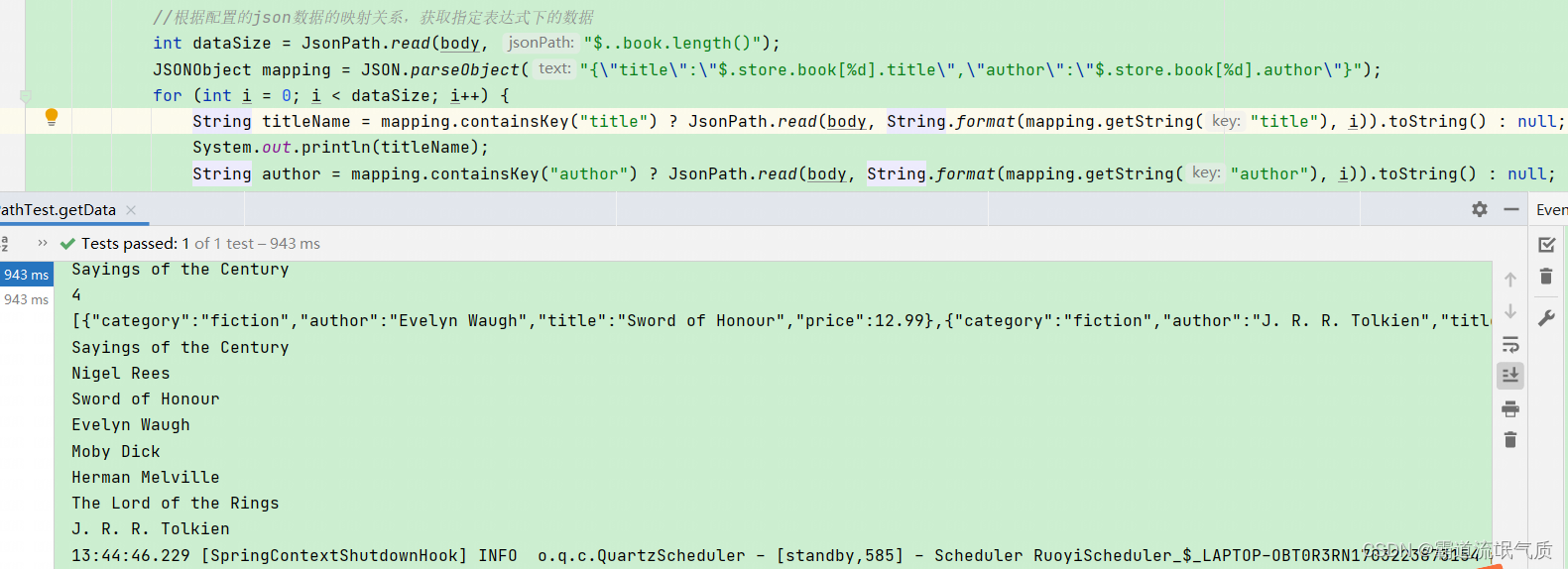
SpringBoot+JaywayJsonPath实现Json数据的DSL(按照指定节点表达式解析json获取指定数据)
场景 若依前后端分离版手把手教你本地搭建环境并运行项目: 若依前后端分离版手把手教你本地搭建环境并运行项目_前后端分离项目本地运行-CSDN博客 在上面搭建SpringBoot项目的基础上,并且在项目中引入fastjson、hutool等所需依赖后。 Jayway JsonPat…...

气压计LPS28DFW开发(2)----水压检测
气压计LPS28DFW开发.2--水压检测 概述视频教学样品申请完整代码下载水压计算设置速率和分辨率轮询读取数据测试结果 概述 本文将介绍如何使用 LPS28DFW 传感器来读取的压强数据,来估算水下深度,可以利用液体静压的原理。 最近在弄ST和瑞萨RA的课程&…...

设计模式之-装饰模式,快速掌握装饰模式,通俗易懂的讲解装饰模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

计算机网络个人小结
不同层的数据报的名称 应用层: data TCP层: segment IP 层: packet MAC层: frame MTU vs MSS: MTU:一个网络包的最大长度,以太网中一般为 1500 字节。 https://www.xiaolincoding.com/network/1_base/how_os_deal_network_package.html#linux-%E7%BD%91…...

酒店网站搭建的作用是什么
线上已经成为各行业商家增长破局的必要手段,传统酒店行业因信息扩展度不够,导致品牌难以传播、无法实现用户对酒店所有信息全面知悉,也无法实现在线预约及其它赋能用户消费的路径。 面对获客转化难题,很多酒店商家通过建立自营商…...

俄罗斯联邦税务局遭乌克兰入侵,数据库和副本被清空,政府数据安全不容忽视
俄罗斯联邦税务局遭乌克兰入侵,数据库和副本被清空,政府数据安全不容忽视 据相关报道,2023年12月12日,乌克兰国防情报局(GUR)称其成功入侵了俄罗斯联邦税务局(FNS)系统,并清除了该机构的数据库和…...
WPF组合控件TreeView+DataGrid之TreeView封装
(关注博主后,在“粉丝专栏”,可免费阅读此文) wpf的功能非常强大,很多控件都是原生的,但是要使用TreeViewDataGrid的组合,就需要我们自己去封装实现。 我们需要的效果如图所示&#x…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...