stable diffusion工作原理
目录
- 序言
- stable diffusion能做什么
- 扩散模型
- 正向扩散
- 逆向扩散
- 如何训练
- 逆向扩散
- Stable Diffusion模型
- 潜在扩散模型
- 变分自动编码器
- 图像分辨率
- 图像放大
- 为什么潜在空间可能存在?
- 在潜在空间中的逆向扩散
- 什么是 VAE 文件?
- 条件化(conditioning)
- 文本条件化(文本到图像)
- 分词器
- 嵌入
- 将嵌入向量输入噪声预测器
- 交叉注意力 (Cross-attention)
- 其他条件化
- 逐步理解Stable Diffusion
- 文本到图像
- 噪音表
- 图像到图像
- 局部修复
- 深度到图像
- CFG值是什么?
- 分类器指导
- 无分类器指导
- 稳定扩散 v1.5 与 v2
- 模型差异
- 其他差异
- SDXL 模型
序言
只是为了记录;英文原文,反反复复看了很多遍,特此记录下。这个原理将有助于在未来AI绘画领域的深耕。
stable diffusion能做什么
简单来说,就是能根据你输入的一段文字,来生成根这段文字匹配的一张图片。(文生图)

如上面这张图,左边是一段文字,通过stable diffusion就可以生成右边的图片。
扩散模型
我们今天讲的stable diffusion属于一类称为扩散模型的深度学习模型。它们是生成模型。这意味着它们旨在生成与训练中看到的类似的新数据。在stable diffusion的情况下,数据是图像。
为什么叫扩散模型呢?因为它的数学公式看起来非常类似于物理学中的扩散现象。让我们来探讨这个概念。
- 这里的
数学公式看起来是指扩展模型在数学描述上和物理学中扩散现象的数学描述有类似之处。在物理学中,扩散是指物质由高浓度区域向低浓度区域的自然运动过程,这一过程通常可以用偏微分方程,比如扩散方程,来描述。 - 在深度学习中的扩散模型(如生成模型),模型的训练过程涉及到数据分布的变化,从而生成新的数据点。这个生成过程在某些方面可以被视为“扩散”。
- 扩散模型在训练过程中
添加噪声,使得数据分布逐渐趋向简单分布(比如高斯分布),这部分是类似于物理扩散。(添加噪声的过程,就是类似物理学中的扩散过程,数学上也会用到扩散方程)。但在生成新样本时,模型进行的是一个去噪过程,逐步从简单的噪声分布恢复出复杂的数据分布,与物理扩散过程相反,这是一种有控制的、目标导向的“扩散”(逆向扩散)。
正向扩散

正向扩散过程会向训练图像添加噪声,逐渐将其变成一个没有特征的噪声图像。这个正向过程会将任何猫或狗的图像变成一个噪声图像。最终,你将无法辨别它们最初是狗还是猫。(这一点很重要)
这就像一滴墨水掉进了一杯水中。墨水滴在水中扩散。几分钟后,它会随机地分散到整个水中。你再也无法分辨它最初是掉在中心还是靠近边缘。
以下是一张图像经历正向扩散的例子。猫的图像变成了随机噪声。

逆向扩散
现在是激动人心的部分。如果我们能够逆转扩散过程会怎样呢?就像倒放一段视频一样。向时间的逆流而动。我们将能够看到墨水滴最初是在哪里加入的。

从技术上讲,每个扩散过程都有两个部分:(1)漂移(drift)和(2)随机运动(random motion)。逆向扩散会向猫或狗的图像漂移,但不会是介于两者之间的状态。这就是为什么结果要么是猫要么是狗的原因。
如何训练
逆向扩散的理念无疑是巧妙和优雅的。但是价值百万美元的问题是,“这怎么能做到呢?”
为了逆向扩散过程,我们需要知道有多少噪声被添加到图像中。答案是训练一个神经网络模型来预测被添加的噪声。在稳定扩散(Stable Diffusion)中,这被称为噪声预测器。它是一个U-Net模型。训练过程如下:
- 选择一张训练图像,比如一张猫的照片。
- 生成一张随机噪声图像。
- 将这张噪声图像通过一定数量的步数添加到训练图像中,已达到破坏训练图像的效果。
- 教导噪声预测器告诉我们添加了多少噪声。这是通过调整它的权重并向它展示正确答案来完成的。

训练完毕后,我们拥有了一个能够估计图像中添加噪声量的噪声预测器。
逆向扩散
现在我们有了噪声预测器。如何使用它呢?
首先,我们生成一张完全随机的图像,并要求噪声预测器告诉我们噪声的信息。接着,我们从原始图像中减去这个估计出来的噪声。重复这个过程几次。你将会得到一张猫或狗的图像。

逆向扩散的工作原理是从图像中连续减去预测出的噪声。
你可能会注意到我们无法控制生成猫或狗的图像。当我们讨论条件化(conditioning)时,我们会解决这个问题。目前,图像生成是无条件的。
您可以在本文中阅读有关反向扩散采样和采样器的更多信息。
Stable Diffusion模型
现在我需要告诉你一些坏消息:我们刚才谈论的并不是稳定扩散(Stable Diffusion)的工作原理!原因在于上述的扩散过程是在图像空间(image space)中进行的。这种方法在计算上非常非常慢。你不可能在任何单个的GPU上运行它,更不用说你笔记本上的糟糕GPU了。
图像空间是巨大的。想象一下:一个有三个颜色通道(红色、绿色和蓝色)的512×512图像就是一个786,432维的空间!(你需要为一张图像指定这么多的值。)
像谷歌的Imagen和OpenAI的DALL-E这样的扩散模型是在像素空间中运作的。它们使用了一些技巧来加快模型的速度,但仍然不够快。
潜在扩散模型
稳定扩散旨在解决速度问题。以下是解决方法。
**稳定扩散是一种潜在扩散模型。**它不是在高维的图像空间中操作,而是首先将图像压缩到潜在空间中。潜在空间的维度比原来小了48倍,因此它获得了处理更少数字的好处。这就是为什么它运行得更快的原因。
变分自动编码器
这是通过一种叫做变分自动编码器的技术完成的。没错,它正是 VAE 文件,但我稍后会讲得更清楚。
变分自动编码器(VAE)神经网络有两个部分:(1)编码器和(2)解码器。编码器将图像压缩到潜在空间中,变成低维的形式。解码器从潜在空间恢复图像。

变分自编码器将图像转换到潜在空间,并从潜在空间转换回来。
稳定扩散模型的潜在空间是 4x64x64,比图像像素空间小48倍。我们谈论的所有正向和逆向扩散实际上都是在潜在空间中进行的。
所以在训练过程中,模型不是生成一个带噪声的图像,而是在潜在空间生成一个随机张量(潜在噪声)。模型不是通过给图像添加噪声来破坏图像,而是通过在潜在空间用潜在噪声破坏图像的表示。这样做的原因是因为潜在空间更小,所以速度会快很多。
图像分辨率
图像分辨率体现在潜在图像张量的大小上。仅对于 512×512 图像,潜在图像的大小是 4x64x64。对于 768×512 的肖像图像,它是 4x96x64。这就是为什么生成较大图像需要更长的时间和更多的显存。
由于 Stable Diffusion v1 在 512×512 图像上进行了微调,生成大于 512×512 的图像可能会导致重复的对象,例如,臭名昭著的两个头。
图像放大
为了生成一张大幅打印,至少保持图像的一边是512像素。使用 AI 放大器或图像到图像功能进行图像放大。
或者,使用 SDXL 模型。它有更大的默认尺寸:为 1,024 x 1,024 像素。
为什么潜在空间可能存在?
你可能会好奇为什么变分自编码器(VAE)能够将图像压缩到一个小得多的潜在空间中而不丢失信息。原因并不令人意外,那就是自然图像并非随机的。它们具有很高的规律性:一张脸遵循着眼睛、鼻子、脸颊和嘴巴之间特定的空间关系。一只狗有4条腿,并且是特定的形状。
换句话说,图像的高维度是人为的。自然图像可以轻易地被压缩到小得多的潜在空间中而不丢失任何信息。这在机器学习中被称为流形假设。
-
流形假设(Manifold Hypothesis)是机器学习和模式识别中的一个概念,它指出尽管数据(如图像、文本、声音等)可能存在于高维空间中,但实际上它们通常会聚集在低维的流形(Manifold)上。在这个假设下,数据点不是均匀分散在整个高维空间中,而是集中在某些低维结构(即流形)周围,这些结构反映了内在的规律性或数据的本质特征。
流形是一个数学概念,指的是在局部具有欧几里得空间性质的一个空间。例如,地球表面是一个三维空间中的二维流形,因为地球表面上的任何局部区域都可以用二维平面来近似,尽管整个地球是三维的。
在潜在空间中的逆向扩散
以下是稳定扩散中潜在反向扩散的工作原理:
- 生成一个随机潜在空间矩阵。
- 噪声预测器估计潜在矩阵的噪声。
- 然后从潜在矩阵中减去估计的噪声。
- 重复步骤 2 和 3 直至达到特定的采样步骤。
- 变分自编码器(VAE)的解码器将潜在矩阵转换为最终图像。
什么是 VAE 文件?
VAE文件在Stable Diffusion v1中被用来改善眼睛和面部。它们是我们刚刚讨论的自编码器的解码器。通过进一步微调解码器,模型能够绘制更精细的细节。
您可能意识到我之前提到的并不完全正确。将图像压缩到潜在空间确实会丢失信息,因为原始的VAE无法恢复细微的细节。相反,VAE解码器负责绘制精细的细节。
条件化(conditioning)
我们的理解还不完整:文本提示在何处发挥作用?没有它,Stable Diffusion就不是一个文本到图像的模型。你将会得到一张猫或狗的图片,但没有任何办法来控制它。
这就是条件化发挥作用的地方。条件化的目的是引导噪声预测器,使得预测出的噪声在从图像中减去后能够得到我们想要的结果。
文本条件化(文本到图像)
下面是文本提示如何被处理并输入到噪声预测器的概述。首先,分词器将提示中的每个词转换为一个称为令牌的数字。然后,每个令牌都会转换为 768 个值的向量,这个过程称为嵌入。(是的,这就是你在AUTOMATIC1111中使用的那个嵌入)这些嵌入随后被文本变换器处理,并准备好被噪声预测器使用。
- 嵌入是能够捕捉词汇语义和上下文信息的连续向量表示。

如何处理文本提示并将其输入噪声预测器以指导图像生成。
现在让我们更仔细地看看每个部分。如果上述高级概述对您来说已经足够了,您可以跳到下一部分。
使用这个链接检查任何提示的令牌和嵌入。
分词器
- 在许多现代NLP模型中,如BERT、GPT或Stable Diffusion中使用的文本编码器,分词器首先将输入文本分解成单词或子词单元,然后将这些单词或子词映射到唯一的数字ID,这些数字ID被称为令牌(token)。接着,这些令牌被转换成嵌入(embeddings),嵌入是能够捕捉词汇语义和上下文信息的连续向量表示。(自己搜索的大模型给的解释)

分词器
文本提示首先由CLIP分词器进行分词处理。CLIP是OpenAI开发的一个深度学习模型,用于生成任何图像的文本描述。Stable Diffusion v1使用了CLIP的分词器。
分词是计算机理解单词的方式。我们人类可以阅读单词,但计算机只能阅读数字。这就是为什么在文本提示中的单词首先被转换成数字。
分词器只能分词它在训练期间见过的单词。例如,在CLIP模型中有“dream”和“beach”,但没有“dreambeach”。分词器会将“dreambeach”这个词分解成两个令牌:“dream”和“beach”。所以一个词并不总是对应一个令牌!
另一个需要注意的细节是空格字符也是令牌的一部分。在上述情况中,“dream beach”这个短语产生两个令牌“dream”和“[space]beach”。这些令牌与“dreambeach”生成的令牌不同,后者是“dream”和“beach”(beach之前没有空格)。
Stable Diffusion模型在一个提示中的使用限制为75个令牌。(现在你知道了,这并不等同于75个单词!)
嵌入

嵌入
Stable Diffusion v1使用的是OpenAI的ViT-L/14 CLIP模型。嵌入是一个有768个值的向量。每个令牌都有自己独特的嵌入向量。嵌入是由CLIP模型固定的,这是在训练过程中学习到的。
**为什么我们需要嵌入?**这是因为有些单词彼此之间关系密切。我们希望利用这些信息。例如,“man”(男人)、 “gentleman”(绅士)和“guy”(家伙)的嵌入几乎是相同的,因为它们可以互换使用。莫奈(Monet)、马奈(Manet)和德加(Degas)都是以印象派风格绘画,但各有不同。这些名字的嵌入向量是接近的,但不完全相同。
这就是我们讨论过的,用关键词触发特定风格的嵌入。嵌入可以发挥魔法。科学家们已经表明,找到合适的嵌入可以触发任意对象和风格,这种微调技术被称为文本反转。
将嵌入向量输入噪声预测器

从嵌入向量到噪声预测器。
嵌入向量在输入噪声预测器之前需要通过文本转换器进行进一步处理。转换器就像一个通用的条件适配器。在这种情况下,它的输入是文本嵌入向量,但同样也可以是其他东西,比如类标签、图像和深度图。转换器不仅进一步处理数据,还提供了一种包含不同条件模态的机制。
交叉注意力 (Cross-attention)
文本转换器的输出在整个U-Net结构的噪声预测器中被多次使用。U-Net通过交叉注意力机制来消费这些输出。这就是提示与图像的结合处。
以“一个有蓝眼睛的男人”(A man with blue eyes)为例。Stable Diffusion将“蓝色”(blue)和“眼睛”(eyes)这两个词结对在一起(提示内部的自注意力),以便生成一个有蓝眼睛的男人,而不是一个穿蓝色衬衫的男人。然后它使用这些信息来指导逆向扩散过程,朝着包含蓝眼睛的图像生成。(提示与图像之间的交叉注意力)
附注:超网络(Hypernetwork)是一种用于微调Stable Diffusion模型的技术,它劫持了交叉注意力网络来插入风格。LoRA模型修改了交叉注意力模块的权重来改变风格。仅仅修改这个模块就能微调一个Stable Diffusion模型的事实告诉我们这个模块有多重要。
其他条件化
文本提示并不是Stable Diffusion模型唯一的条件化方式。
文本提示和深度图像都被用来对深度到图像模型进行条件化。
ControlNet通过检测到的轮廓、人体姿势等对噪声预测器进行条件控制,并在图像生成过程中实现了出色的控制。
逐步理解Stable Diffusion
现在你已经了解了Stable Diffusion的所有内部机制,让我们通过一些例子来看看在幕后发生了什么。
文本到图像
在文本到图像中,你给Stable Diffusion一个文本提示,它会返回一张图片。
步骤1. Stable Diffusion在潜在空间生成一个随机张量。你可以通过设置随机数生成器的种子来控制这个张量。如果你将种子设置为某个特定值,你将总是得到相同的随机张量。这就是你在潜在空间中的图像。但现在它全部是噪声。

在潜在空间中生成了一个随机张量。
步骤2. 噪声预测器U-Net将潜在噪声图像和文本提示作为输入,并在潜在空间中预测噪声(一个4x64x64的张量)。

步骤3. 从潜在图像中减去潜在噪声。这将成为你的新潜在图像。

步骤2和步骤3会重复执行特定数量的采样步骤,例如,重复20次。
步骤4. 最终,变分自编码器(VAE)的解码器将潜在图像转换回像素空间。这是在运行Stable Diffusion之后得到的图像。

以下是图像在每个采样步骤中的演变方式。
每个采样步骤中的图像。
噪音表
图片从嘈杂变得清晰。你是否想知道噪声预测器在最初的步骤中是否工作得不好?实际上,这只是部分正确的。真正的原因是我们试图在每个采样步骤中达到预期的噪声水平。这被称为噪声时间表。以下是一个例子。

15 个采样步骤的噪声表。
噪声时间表是我们自己定义的。我们可以选择在每个步骤中减去相同数量的噪声。或者我们可以像上面那样在开始时减去更多的噪声。采样器在每个步骤中减去恰到好处的噪声量,以达到下一步骤的预期噪声水平。这就是你在逐步图片中看到的。
图像到图像
图像到图像是通过稳定扩散(Stable Diffusion)将一张图片转换成另一张图片。这最初是在SDEdit方法中提出的。SDEdit可以应用于任何扩散模型。因此,我们有了针对稳定扩散(一个潜在扩散模型)的图像到图像转换。
在图像到图像转换中,输入包括一张输入图像和一段文本提示。生成的图像将同时受到输入图像和文本提示的条件限制。例如,使用这张业余绘画和文本提示“带茎、水滴、戏剧性光照的完美绿苹果照片”作为输入,图像到图像转换可以将其变成一张专业的绘画:

图像到图像
现在来看一下逐步过程。
步骤1. 将输入图像编码到潜在空间。

步骤2. 向潜在图像添加噪声。去噪强度控制添加了多少噪声。如果为0,则不添加噪声。如果为1,则添加最大量的噪声,使得潜在图像变成一个完全随机的张量。

步骤3. 噪声预测器 U-Net 将潜在噪声图像和文本提示作为输入,并预测潜在空间(4x64x64 张量)中的噪声。

步骤4. 从潜在图像中减去潜在噪声。这成为你的新潜在图像。

步骤3和步骤4会重复执行特定数量的采样步骤,例如,重复20次。
步骤5. 最后,VAE(变分自编码器)的解码器将潜在图像转换回像素空间。这就是在运行图像到图像转换后你获得的图像。

所以现在你知道什么是图像到图像转换了:它所做的就是用一点噪声和输入图像设置初始的潜在图像。将去噪强度设置为1相当于文本到图像转换,因为初始的潜在图像是完全随机的。
局部修复
局部修复实际上只是图像到图像的一种特殊情况。噪点会添加到你想要修复图像的局部区域。噪声的数量同样由去噪强度控制。
深度到图像
深度到图像是图像到图像转换的一种增强;它使用深度图进行额外条件控制来生成新图像。
步骤1. 输入图像被编码成潜在状态

步骤2. MiDaS(一个人工智能深度模型)从输入图像中估计深度图。

步骤3. 向潜在图像添加噪声。去噪强度控制添加了多少噪声。如果去噪强度为0,则不添加噪声。如果去噪强度为1,则添加最大噪声,以便潜在图像变成一个随机张量。

步骤4. 噪声预测器根据文本提示和深度图估计潜在空间的噪声。

步骤5. 从潜在图像中减去潜在噪声。这样就变成了新的潜在图像。

步骤4和步骤5将重复进行若干次,次数取决于抽样步骤的数量。
步骤6. 变分自编码器(VAE)的解码器对潜在图像进行解码。现在,您从深度到图像得到了最终图像。

CFG值是什么?
CFG值是“Classifier Free Guidance”(无分类器引导)的缩写,这是一个在生成模型,特别是在文本到图像的生成模型中使用的参数,用于控制模型生成结果时文本提示的影响强度。简单来说,CFG值越高,生成的图像越可能遵循文本提示的细节;CFG值越低,文本提示对生成结果的影响就越小。
如果不解释“无分类器引导”(Classifier-Free Guidance, CFG),这篇文章将不会完整,这是一个人工智能艺术家每天都在调整的值。要理解它是什么,我们首先需要简要了解它的前身——分类器引导……
分类器指导
分类器引导是一种在扩散模型中结合图像标签的方法。您可以使用一个标签来指导扩散过程。例如,标签“猫”会引导逆向扩散过程生成猫的照片。
分类器引导尺度是一个参数,用于控制扩散过程应该多么紧密地遵循标签。
以下是我从这篇论文中摘录的一个例子。假设有3组带有标签的图像:“猫”、“狗”和“人类”。如果扩散过程没有引导,模型将从每个组的总体中抽取样本,但有时它可能会绘制适合两个标签的图像,例如,一个抚摸狗的男孩。

分类器引导。左图:无引导。中图:小引导尺度。右图:大引导尺度。
在高分类器引导下,扩散模型生成的图像将倾向于极端或明确无误的例子。如果你让模型生成一只猫的图像,它将返回一张毫无疑问只是猫而没有其他元素的图像。
分类器引导尺度控制着引导的遵循程度。在上面的图中,右边样本的分类器引导尺度比中间的要高。实际上,这个尺度值就是具有该标签的数据漂移项的乘数。
无分类器指导
尽管分类器引导取得了破纪录的性能,但它需要一个额外的模型来提供这种引导。这在训练过程中带来了一些困难。
用作者的话来说,“无分类器引导”是一种“不使用分类器实现分类器引导”的方法。他们没有使用类别标签和一个单独的模型进行引导,而是使用图像标题并训练一个条件扩散模型,就像我们在文本到图像中讨论的模型一样。
他们将分类器部分作为噪声预测器U-Net的条件化处理,实现了图像生成中所谓的“无分类器”(即不使用单独的图像分类器)。
文本提示提供了文本到图像的指导。
##无分类器引导尺度
现在,我们有了一个使用条件化的无分类器扩散过程。我们如何控制AI生成的图像应该多大程度上遵循这个引导呢?
无分类器引导尺度(CFG比例)是一个控制文本提示指导扩散过程程度的值。当CFG比例设置为0时,AI图像生成是无条件的(即忽略提示)。较高的 CFG 比例会引导扩散朝向提示。
稳定扩散 v1.5 与 v2
这已经是一篇很长的文章了,但如果不比较 v1.5 和 v2 模型之间的差异,它就不完整。
模型差异
Stable Diffusion v2使用OpenClip进行文本嵌入。Stable Diffusion v1使用Open AI的CLIP ViT-L/14进行文本嵌入。这一变化的原因是:
- OpenClip的模型尺寸大约是原来的五倍。更大的文本编码模型提高了图像质量。
- 尽管 Open AI 的 CLIP 模型是开源的,但这些模型是使用专有数据进行训练的。切换到 OpenClip 模型使研究人员在研究和优化模型时更加透明。这样更有利于长远发展。
v2 模型有两个优点。
-
512版本生成512×512图像
-
768版本生成768×768图像
-
还有训练数据上的差异,这里就不说了,随着时间的推移,这些东西也就过时了,没啥意义。
其他差异
用户通常发现使用Stable Diffusion v2来控制风格和生成名人形象更困难。尽管Stability AI并没有明确过滤掉艺术家和名人的名称,但在v2中,这些名称的效果要弱得多。这可能是由于训练数据的差异造成的。Open AI的专有数据可能包含更多的艺术作品和名人照片。他们的数据可能经过高度过滤,以便一切和每个人都看起来细致美观。
而且v2 和 v2.1 模型并不流行。人们只使用经过微调的 v1.5 和 SDXL 模型。
SDXL 模型
SDXL模型是对v1和v2模型的官方升级。该模型以开源软件的形式发布。
它是一个更大的模型。在人工智能领域,我们可以预期它会更好。SDXL模型的总参数数量是66亿,相比之下,v1.5模型的参数数量是9.8亿。

SDXL管道由一个基础模型和一个精炼模型 组成。
在实践中,SDXL模型是两个模型。你先运行基础模型,然后是精炼模型。基础模型设定全局构图,而精炼模型添加更精细的细节。
你可以单独运行基础模型,而不需要精炼模型。
SDXL基础模型的变化包括:
- 文本编码器结合了最大的OpenClip模型(ViT-G/14)和OpenAI的专有CLIP ViT-L。这是一个明智的选择,因为它使得SDXL易于提示,同时保持了强大且可训练的OpenClip特性。
- 新的图像尺寸条件化旨在使用小于256×256像素的训练图像。通过不丢弃 39% 的图像,显著增加了训练数据。
- U-Net的大小是v1.5的三倍。
- 默认的图像尺寸是1024×1024。这是v1.5模型512×512尺寸的四倍。(参见与SDXL模型一起使用的图像尺寸)
参考地址:
https://stable-diffusion-art.com/how-stable-diffusion-work
相关文章:
stable diffusion工作原理
目录 序言stable diffusion能做什么扩散模型正向扩散逆向扩散 如何训练逆向扩散 Stable Diffusion模型潜在扩散模型变分自动编码器图像分辨率图像放大为什么潜在空间可能存在?在潜在空间中的逆向扩散什么是 VAE 文件? 条件化(conditioning)文本条件化&am…...

华清远见嵌入式学习——ARM——作业2
目录 作业要求: 现象: 代码: 思维导图: 模拟面试题: 作业要求: GPIO实验——3颗LED灯的流水灯实现 现象: 代码: .text .global _start _start: 设置GPIOEF时钟使能 0X50000…...
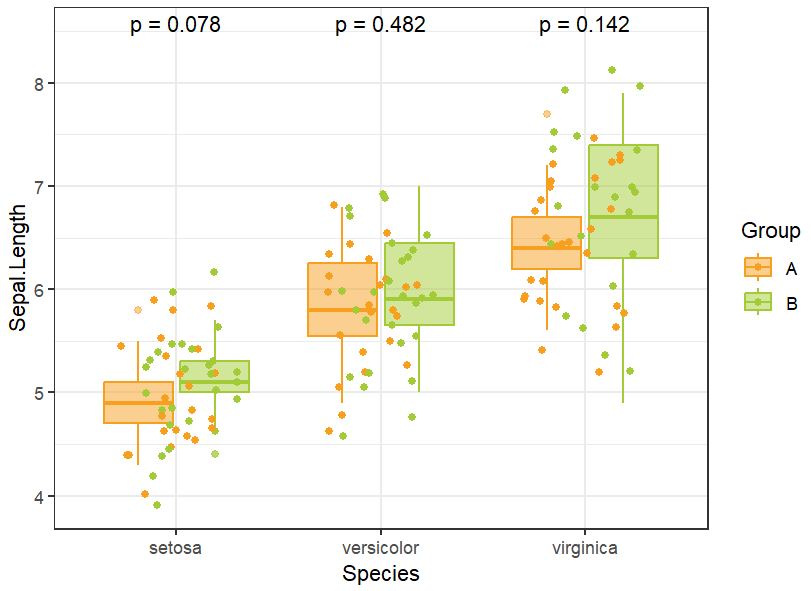
R语言中使用ggplot2绘制散点图箱线图,附加显著性检验
散点图可以直观反映数据的分布,箱线图可以展示均值等关键统计量,二者结合能够清晰呈现数据蕴含的信息。 本篇笔记主要内容:介绍R语言中绘制箱线图和散点图的方法,以及二者结合展示教程,添加差异比较显著性分析…...

51单片机的羽毛球计分器系统【含proteus仿真+程序+报告+原理图】
1、主要功能 该系统由AT89C51单片机LCD1602显示模块按键等模块构成。适用于羽毛球计分、乒乓球计分、篮球计分等相似项目。 可实现基本功能: 1、LCD1602液晶屏实时显示比赛信息 2、按键控制比赛的开始、暂停和结束,以及两位选手分数的加减。 本项目同时包含器件清…...

设计模式之-责任链模式,快速掌握责任链模式,通俗易懂的讲解责任链模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

Qt通用属性工具:随心定义,随时可见(一)
一、开胃菜,没图我说个DIAO 先不BB,给大家上个效果图展示下: 上图我们也没干啥,几行代码: #include "widget.h" #include <QApplication> #include <QObject> #include "QtPropertyEdit…...

Python中json模块的使用与pyecharts绘图的基本介绍
文章目录 json模块json与Python数据的相互转化 pyecharts模块pyecharts基本操作基础折线图配置选项全局配置选项 json模块的数据处理折线图示例示例代码 json模块 json实际上是一种数据存储格式,是一种轻量级的数据交互格式,可以把他理解成一个特定格式…...
nodejs+vue+微信小程序+python+PHP医院挂号系统-计算机毕业设计推荐
当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术, 本医院挂号系统也是紧跟科学技术的发展,运用当今一流的软件技术实现软件系统的开发,让家具销…...

数据大模型与低代码开发:赋能技术创新的黄金组合
在当今技术领域,数据大模型和低代码开发已经成为两个重要的趋势。数据大模型借助庞大的数据集和强大的计算能力,助力我们从海量数据中挖掘出有价值的洞见和预测能力。与此同时,低代码开发通过简化开发流程和降低编码需求,使得更多…...

Redis BitMap(位图)
这里是小咸鱼的技术窝(CSDN板块),我又开卷了 之前经手的项目运行了10多年,基于重构,里面有要实现一些诸如签到的需求,以及日历图的展示,可以用将签到信息存到传统的关系型数据库(MyS…...

使用eclipse创建一个java文件并运行
启动 Eclipse 并创建一个新的 Java 项目: 打开 Eclipse。 选择 “File” > “New” > “Java Project”(文件 > 新建 > Java 项目)。 在弹出的窗口中,为你的项目命名,比如 MyJavaProject。 点击 “Finish”ÿ…...

C#上位机与欧姆龙PLC的通信05---- HostLink协议
1、介绍 Hostlink协议是欧姆龙PLC与上位机链接的公开协议。上位机通过发送Hostlink命令,可以对PLC进行I/O读写、可以对PLC进行I/O读写、改变操作模式、强制置位/复位等操作。由于是公开协议,即便是非欧姆龙的上位设备(软件)&…...
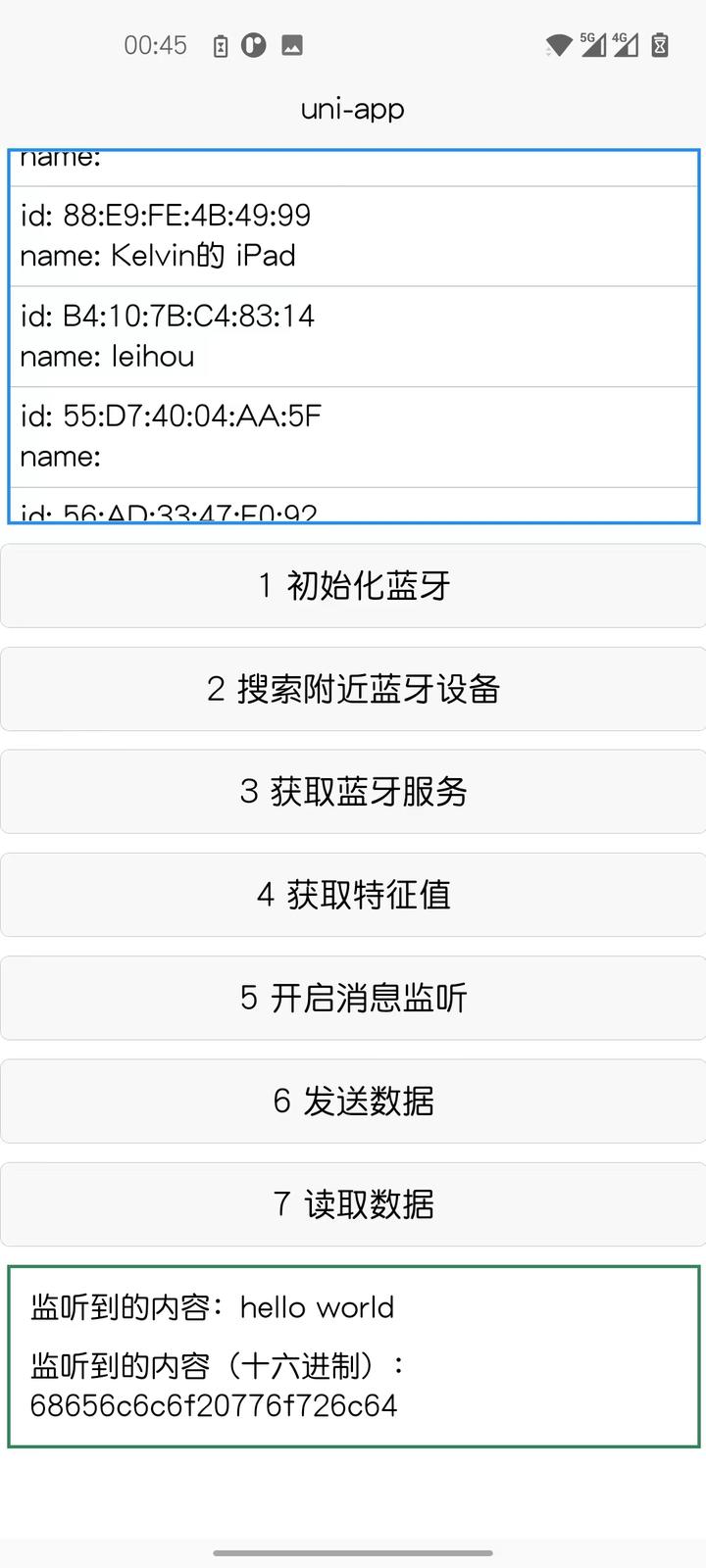
Uniapp 开发 BLE
BLE 低功耗蓝牙(Bluetooth Low Energy,或称Bluetooth LE、BLE,旧商标Bluetooth Smart),用于医疗保健、运动健身、安防、工业控制、家庭娱乐等领域。在如今的物联网时代下大放异彩,扮演者重要一环ÿ…...

c语言排序算法
C语言代码示例: 冒泡排序(Bubble Sort): void bubbleSort(int arr[], int n) {for (int i 0; i < n-1; i) {for (int j 0; j < n-i-1; j) {if (arr[j] > arr[j1]) {int temp arr[j];arr[j] arr[j1];arr[j1] temp;…...

【机器学习】模式识别
1 概述 模式识别,简单来讲,就是分类问题。 模式识别应用:医学影像分析、人脸识别、车牌识别、遥感图像 2 模式分类器 分类器的分类:线性分类器、非线性分类器、最近邻分类器 2.1 分类器的训练(学习)过…...
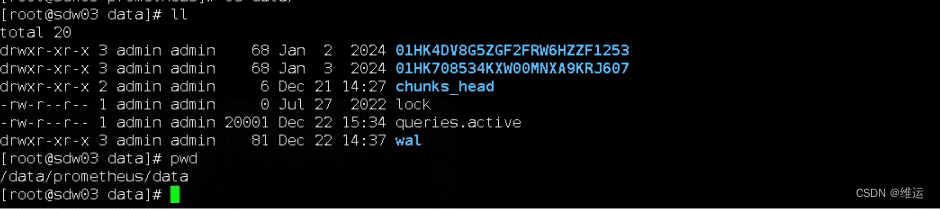
【Prometheus|报错】Out of bounds
【背景】进入Prometheus地址的9090端口,pushgateway(0/1)error : out of bounds 【排查分析】 1、out of bounds报错,是由于Prometheus向tsdb存数据出错,与最新存数据的时间序列有问题,有可能当前时间与最…...
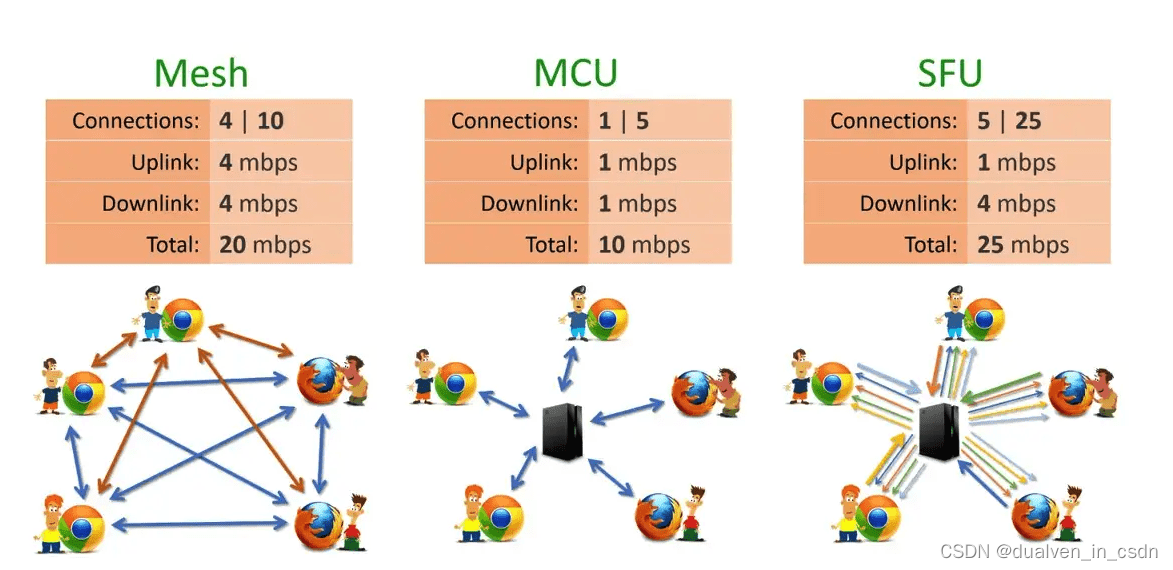
【音视频】Mesh、Mcu、SFU三种框架的总结
目录 三种网络场景介绍 【Mesh】 【MCU】(MultiPoint Control Unit) 【SFU】(Selective Forwarding Unit) 三种网络架构的优缺点 Mesh架构 MCU架构(MultiPoint Control Unit) SFU架构(Selective Forwarding Unit) 总结 参考文章 三种网络场景介绍 【Mesh】 Mesh架构…...
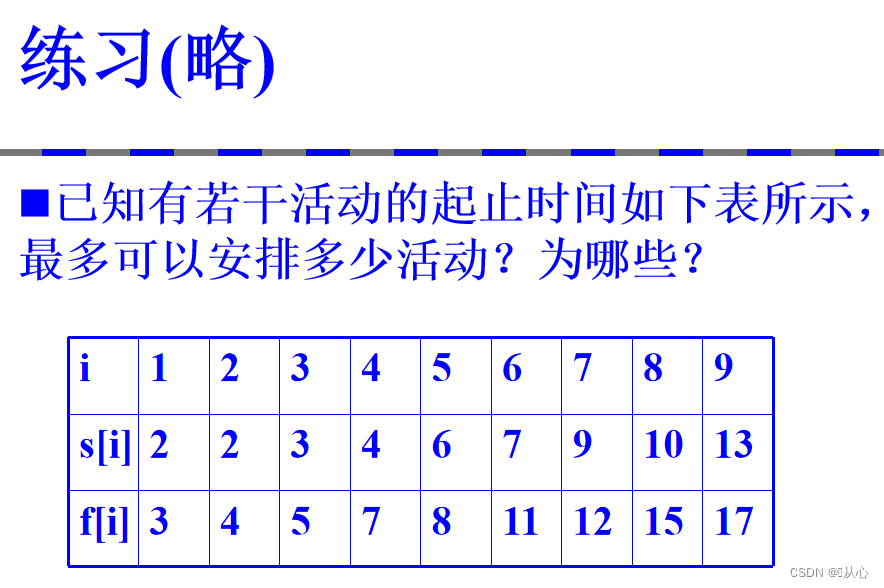
高级算法设计与分析(四) -- 贪心算法
系列文章目录 高级算法设计与分析(一) -- 算法引论 高级算法设计与分析(二) -- 递归与分治策略 高级算法设计与分析(三) -- 动态规划 高级算法设计与分析(四) -- 贪心算法 高级…...
MATLAB - 机器人逆运动学设计器(Inverse Kinematics Designer APP)
系列文章目录 前言 一、简介 通过逆运动学设计器,您可以为 URDF 机器人模型设计逆运动学求解器。您可以调整逆运动学求解器并添加约束条件,以实现所需的行为。使用该程序,您可以 从 URDF 文件或 MATLAB 工作区导入 URDF 机器人模型。调整逆…...
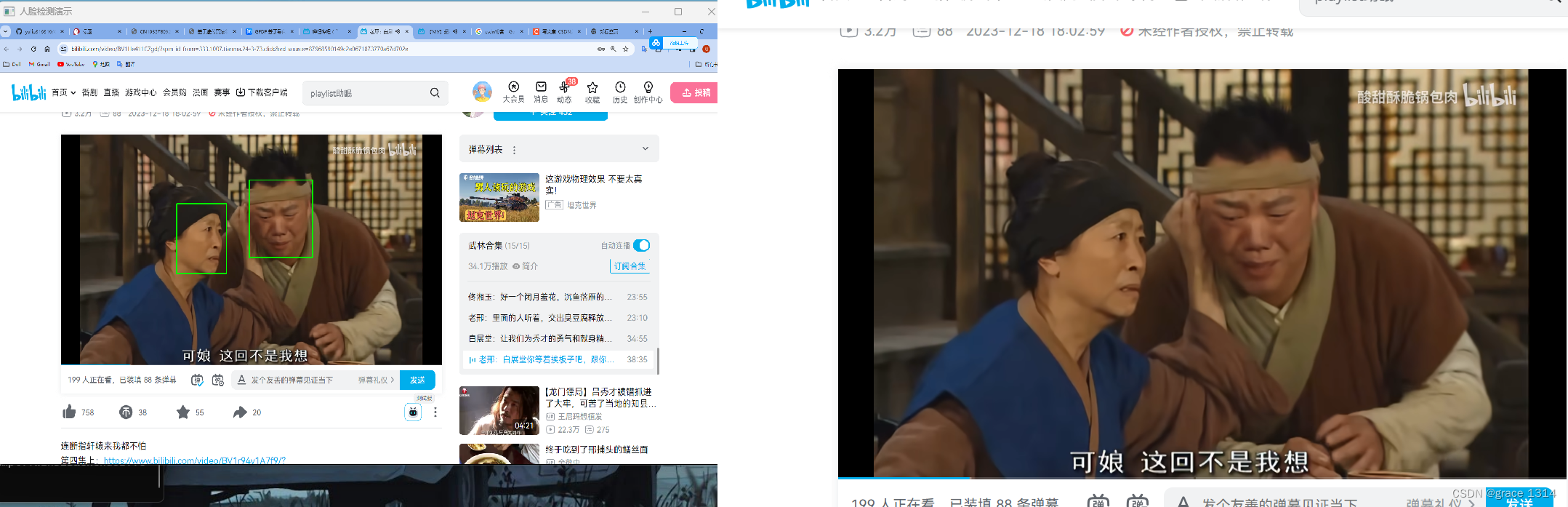
使用OpenCV DNN模块进行人脸检测
内容的一部分来源于贾志刚的《opencv4应用开发、入门、进阶与工程化实践》。这本书我大概看了一下,也就后面几章比较感兴趣,但是内容很少,并没有想像的那种充实。不过学习还是要学习的。 在实际工程项目中,并不是说我们将神经网络…...

智能LED控制入门指南:用WLED打造低代码灯光项目
智能LED控制入门指南:用WLED打造低代码灯光项目 【免费下载链接】WLED Control WS2812B and many more types of digital RGB LEDs with an ESP8266 or ESP32 over WiFi! 项目地址: https://gitcode.com/GitHub_Trending/wl/WLED 智能LED控制技术正在改变我们…...
。这是一个基于 Docker 的文档管理系统,主要依赖 Python (Django)、PostgreSQL、Redis 和 Tesse)
分析 paperlessngx 的典型项目结构(基于其官方仓库)。这是一个基于 Docker 的文档管理系统,主要依赖 Python (Django)、PostgreSQL、Redis 和 Tesse
好的,收到您的项目代号 paperlessngx。我将以资深技术文档工程师/DevOps专家的身份,为您生成一份详细的部署指南。 首先,我将按照预设的工作流,分析项目、推断环境要求,并最终整合成完整的部署文档。第一步:…...

2026AI Agent风口来袭!告别README小白,这篇保姆级教程助你从入门到精通!
你是否也曾面对复杂的AI Agent项目,却只能照着README文档傻傻使用?这篇文章将帮你彻底打破这一局面,轻松掌握AI Agent开发技能!从核心概念到实战框架,一文打尽! 🔍 AI Agent到底是什么ÿ…...

AnimeGarden创新解决方案:动漫资源聚合与管理全攻略
AnimeGarden创新解决方案:动漫资源聚合与管理全攻略 【免费下载链接】AnimeGarden 動漫花園 3-rd party mirror site and Anime Torrent aggregation site 项目地址: https://gitcode.com/gh_mirrors/an/AnimeGarden 在数字娱乐爆炸的时代,动漫爱…...

Phi-3-mini-128k-instruct助力软件测试:自动化测试用例与脚本生成
Phi-3-mini-128k-instruct助力软件测试:自动化测试用例与脚本生成 1. 引言 想象一下这个场景:产品经理刚刚更新了一份长达几十页的需求文档,开发团队紧锣密鼓地开始编码,而测试工程师看着密密麻麻的功能点,心里盘算着…...

告别云端推理:在老旧Android手机上流畅运行YOLOv11目标检测的优化技巧
告别云端推理:在老旧Android手机上流畅运行YOLOv11目标检测的优化技巧 当我们在2023年测试YOLOv11模型时,发现即使是搭载骁龙835的中端手机,运行标准模型也会出现明显的卡顿和发热。这促使我们开发了一套完整的优化方案,让5年前的…...
)
MySQL的三大核心日志详解(redo log,bin log,undo log)
MySQL的三大核心日志——redo log、binlog 和 undo log——是保障数据一致性、实现崩溃恢复以及支持高可用架构的基石。它们各有分工,又相互协作。 我先用一个表格帮你快速建立起对它们核心区别的直观认识,然后再详细拆解它们各自的作用、使用方法以及如…...

SpringBoot循环依赖避坑指南:为什么@Lazy注解不是万能的?
SpringBoot循环依赖避坑指南:为什么Lazy注解不是万能的? 在SpringBoot开发中,循环依赖问题就像一把双刃剑——表面上看是技术问题,深层次却反映了架构设计的合理性。许多开发者遇到循环依赖时,第一反应就是加上Lazy注…...

Depth Anything 3 深度估计模型:如何实现92.4精度突破与多平台集成方案
Depth Anything 3 深度估计模型:如何实现92.4精度突破与多平台集成方案 【免费下载链接】Depth-Anything-3 Depth Anything 3 项目地址: https://gitcode.com/gh_mirrors/de/Depth-Anything-3 Depth Anything 3(DA3)作为当前领先的视觉…...

Unity集成ChatGPT实战:从API调用到对话系统设计
Unity集成ChatGPT实战:从API调用到对话系统设计 在开发Unity项目时,尤其是角色扮演、模拟经营或VR社交类应用,我们常常希望NPC(非玩家角色)能摆脱预设的、重复的台词,拥有更自然、更智能的对话能力。然而&…...