【Transformer框架代码实现】
Transformer
- Transformer框架
- 注意力机制框架
- 导入必要的库
- Input Embedding / Out Embedding
- Positional Embedding
- Transformer Embedding
- ScaleDotProductAttention(self-attention)
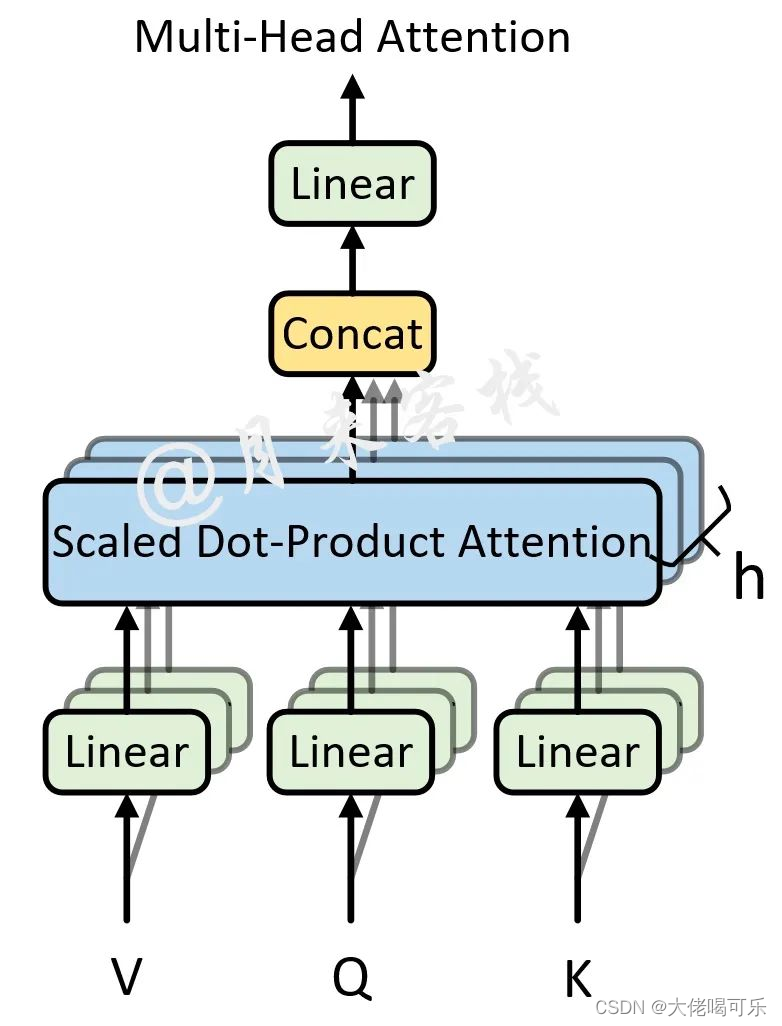
- MultiHeadAttention 多头注意力机制
- EncoderLayer 编码层
- Encoder多层编码块/前馈网络层
- DecoderLayer解码层
- Decoder多层解码块
- MyTransformer实现完整的Transformer框架
Transformer框架
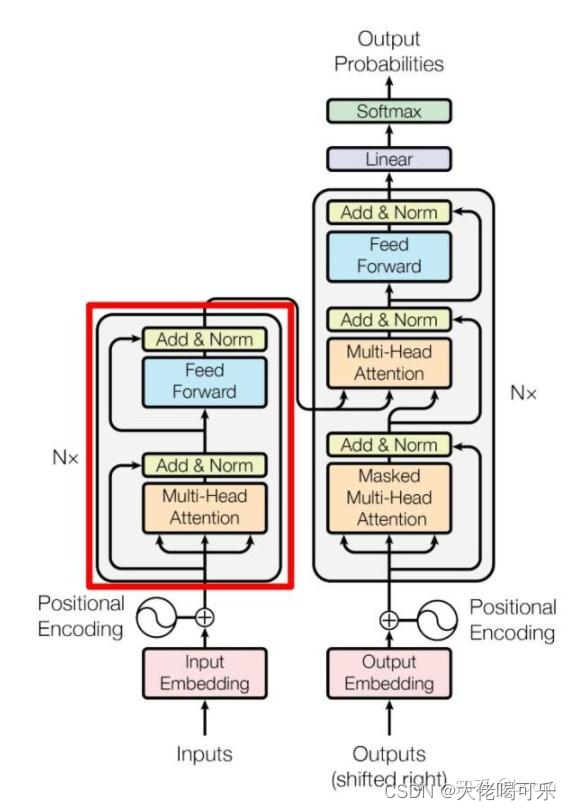
注意力机制框架
导入必要的库
from torch import nn
import torch
import math
import torch.nn.functional as F
Input Embedding / Out Embedding
词嵌入层的实现
nn.Embedding(vocab_size, embed_dim)中
vocab_size: 词典长度,必须大于输入的单词总量
embed_dim:词向量维度
class TokenEmbedding(nn.Module):def __init__(self, vocab_size, embed_dim):""":param vocab_size: 词典长度/维度/图片size(0) 必须大于输入的单词总量. batch_size=句子数量:param embed_dim: 词向量维度"""super(TokenEmbedding, self).__init__()self.embed_dim = embed_dimself.embedding = nn.Embedding(vocab_size, embed_dim)def forward(self, x):# 对原始向量进行缩放,出自论文# [batch_size, vocab_size, embed_dim]return self.embedding(x.long()) * math.sqrt(self.embed_dim)
Positional Embedding
位置编码层的实现
与RNN不同,对于给定输入input = “I am fine”,RNN中会顺序读入每个单词,而在Transformer中则是所有单词同时读入,因此失去了“有序性“,对机器来说,只收到三个单词I,am,fine,其并不知道这三个单词之间的位置关系,为此需要为每个单词附加上额外的位置信息。比如这里我们可以简单的传(I, 1),(am, 2),(fine, 3)。这样不仅传入了句子的单词,还附加上单词的位置信息。
一种好的位置编码方案需要满足以下几条要求:
- 能为每个时间步输出一个独一无二的编码
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致
- 模型应该能毫不费力地泛化到更长的句子,且值是有界的
- 必须是确定性的
class PositionEncoding(nn.Module):def __init__(self, d_model, max_len, dropout=0.1, device='cpu'):""":param max_len: 句子最大长度 default:5000:param d_model: 模型维度/embed_dim default:512 必须为偶数:param device:"""super(PositionEncoding, self).__init__()self.dropout = nn.Dropout(dropout)pos_encoding = torch.zeros(max_len, d_model, device=device)# 2D: [max_len, d_model]pos = torch.arange(0, max_len, dtype=torch.float, device=device).unsqueeze(dim=1)# 2D: [max_len, 1]div_term = torch.exp(torch.arange(0, d_model, step=2, device=device).float() * (-math.log(10000) / d_model))# 1D: [d_model / 2]pos_encoding[:, 0::2] = torch.sin(pos * div_term)pos_encoding[:, 1::2] = torch.cos(pos * div_term)# 2D: [max_len, d_model]pos_encoding = pos_encoding.unsqueeze(dim=0)# print(pos_encoding.shape)# 3D: [1, max_len, d_model], 扩充batch_size维度 batch_size * max_len * d_modelself.register_buffer('pos_encoding', pos_encoding)def forward(self, x):# [batch_size, max_len, d_model]x = x + self.pos_encoding[:, :x.size(1)].requires_grad_(False)return self.dropout(x)
Transformer Embedding
词嵌入层+位置编码层
class TransformerEmbedding(nn.Module):def __init__(self, vocab_size, max_len, d_model, drop, device):""":param vocab_size: 字典大小,字典中不同字符个数:param max_len::param d_model::param drop::param drop_prob::param device:"""super(TransformerEmbedding, self).__init__()self.embed = TokenEmbedding(vocab_size, d_model)self.pos = PositionEncoding(d_model, max_len, drop, device)def forward(self, x):""":param x: padding后的vectors:return: embedding + pos_encoder 后的vectors; shape: [batch_size, max_len, d_model]"""embed = self.embed(x)pos = self.pos(embed)return pos
调试例子,可以详细查看每一步运行的shape变化
if __name__ == '__main__':Input = [[1, 2, 3, 4], [5, 6, 2], [1, 7, 8, 9, 10, 11, 12, 13, 14, 15]]# 有三个句子[['你 好 世 界'], ['我 很 好'], ['你 不 是 真 正 的 快 乐']]# 句子长度不一致进行padding处理max_len = len(Input[2])print('The most length is {} sequences '.format(max_len))src_sentence = torch.tensor([])for i in range(len(Input)):src_sen = torch.tensor([Input[i]])src_sen = F.pad(src_sen, (0, max_len-len(Input[i])), 'constant', 0)src_sentence = torch.cat([src_sentence, src_sen], dim=0)# x = src_sentence.unsqueeze(dim=0)x = src_sentenceprint(x)# token_embed = TokenEmbedding(vocab_size=18, embed_dim=32)# x = token_embed(x)# print('token的维度为:', x.shape)# pos_embed = PositionEncoding(d_model=32, max_len=max_len)# x = pos_embed(x)# print(x.shape)trans = TransformerEmbedding(vocab_size=18, max_len=10, d_model=32, drop=0.1, device='cpu')x = trans(x)print('transformer的维度为:', x.shape)
ScaleDotProductAttention(self-attention)
单头注意力机制/自注意力机制实现
- q: query 查询,
-代表输入序列每个位置的上下文信息,可以看做单个位置向其他位置发出询问 - k: key 键,
-代表输入序列中每个位置的局部信息,每个位置将自己的局部信息编码为键,可以与其他位置进行比较和交互 - v: value 值,
-代表序列中每个位置的具体信息,可以获得具体数据
查询会和键进行一个相似度计算,然后根据相似度的权重对值进行加权求和
class ScaleDotProductAttention(nn.Module):def __init__(self, dim_model):"""self_attention: softmax(QKT / sqrt(d_model))V:param dim_model: 嵌入维度,default: 512"""super(ScaleDotProductAttention, self).__init__()self.q = nn.Linear(dim_model, dim_model)self.k = nn.Linear(dim_model, dim_model)self.v = nn.Linear(dim_model, dim_model)self.softmax = nn.Softmax(dim=-1)def forward(self, query, key, value, mask=None):""":param query: [batch_size, max_len, d_model]:param key::param value::param mask: [max_len, max_len]:return:"""q = self.q(query)k = self.k(key)v = self.v(value)d_k = query.size(-1)qk = self.softmax(torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k))if mask is not None:qk = qk.masked_fill(mask == 0, -1e9)attn_weights = self.softmax(qk)output = torch.matmul(attn_weights, v)return attn_weights, output
MultiHeadAttention 多头注意力机制
多头注意力机制实现
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
import torch
from torch import nn
import torch.nn.functional as F
import mathclass MultiHeadAttention(nn.Module):def __init__(self, dim_model, n_head, bias=True):""":param dim_model: 词嵌入的维度,也就是前面的d_model参数,论文中的默认值为512:param n_head: self-attention的个数 多头注意力机制中多头的数量,也就是前面的n_head参数, 论文默认值为 8:param bias: 最后对多头的注意力(组合)输出进行线性变换时,是否使用偏置"""super(MultiHeadAttention, self).__init__()self.d_model = dim_modelself.head_dim = dim_model // n_headself.k_dim = self.head_dimself.v_dim = self.head_dimself.nums_head = n_head# self.dropout = nn.Dropout(dropout)assert self.nums_head * self.head_dim == self.d_model, 'embed_dim 除以 num_heads必须为整数'self.q_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))# d_model = k_dim * nums_headself.k_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))self.v_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))self.output_weights = nn.Parameter(torch.Tensor(dim_model, dim_model))# self.output_bias = biasself.output = nn.Linear(dim_model, dim_model, bias=bias)def forward(self, query, key, value, drop_p, training=True, attn_mask=None, key_padding_mask=None):"""在论文中,编码时query, key, value 都是同一个输入,解码时 输入的部分也都是同一个输入,解码和编码交互时 key,value指的是 memory, query指的是tgt:param drop_p: attention_weights layer:param training: 是否开启训练模式:param query: [batch_size, tgt_len, embed_dim], tgt_len 表示目标序列的长度:param key: [batch_size, src_len, embed_dim], src_len 表示源序列的长度:param value: [batch_size, src_len, embed_dim], src_len 表示源序列的长度:param attn_mask: [tgt_len,src_len] or [num_heads*batch_size,tgt_len, src_len]一般只在解码时使用,为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息:param key_padding_mask: [batch_size, src_len], src_len 表示源序列的长度. 填充部分掩码操作:return:attn_output: [tgt_len, batch_size, embed_dim]attn_output_weights: # [batch_size, tgt_len, src_len]"""# 第一阶段: 计算得到Q、K、Vq = F.linear(query, self.q_weight)# F.linear(inputs, weights, bias)# query:[batch_size, src_len/tgt_len, d_model], q_weight:[d_model, d_model]k = F.linear(key, self.k_weight)v = F.linear(value, self.v_weight)# 第二阶段:缩放,以及attn_mask维度判断b_s, tgt_len, embed_dim = query.size()source_len = key.size(1)scaling = 1 / math.sqrt(self.head_dim)# q*scaling: [batch_size, query_len, k_dim*nums_head]q = q * scaling# print(tgt_len, source_len)if attn_mask is not None:# [tgt_len, src_len] or [nums_head*batch_size, tgt_len, src_len]if attn_mask.dim() == 2:attn_mask = attn_mask.unsqueeze(0)# print(attn_mask.shape)if list(attn_mask.size()) != [1, tgt_len, source_len]:raise RuntimeError('The size of the 2D attn_mask is not correct.')elif attn_mask.dim() == 3:if list(attn_mask.size()) != [b_s*self.nums_head, tgt_len, source_len]:raise RuntimeError('The size of the 3D attn_mask is not correct.')# 第三阶段: 计算得到注意力权重矩阵# [batch_size, n_head, tgt_dim, k_dim] 计算时候是[tgt_dim, k_dim]* [k_dim, tgt_dim]-># [batch_size, n_head, tgt_dim, tgt_dim] == [batch_size * n_head, tgt_dim, tgt_dim]# q = q.view(b_s, tgt_len, n_head, head_dim).transpose(1, 2)q = q.contiguous().view(b_s*self.nums_head, tgt_len, self.head_dim)# [batch_size * n_head, tgt_len, k_dim]k = k.contiguous().view(b_s*self.nums_head, -1, self.k_dim)v = v.contiguous().view(b_s*self.nums_head, -1, self.v_dim)# print(q.shape, k.shape, v.shape)attn_output_wights = torch.bmm(q, k.transpose(-1, -2))# [batch_size*nums_head, tgt_len, head_dim] * [batch_size*nums_head, k_dim, src_len]# [batch_size*nums_head, tgt_len, src_len]# 第四阶段: 进行相关掩码操作if attn_mask is not None:attn_output_wights = attn_output_wights + attn_mask# [batch_size*nums_head, tgt_len, src_len] + [batch_size*nums_head, tgt_len, src_len]if key_padding_mask is not None:attn_output_wights = attn_output_wights.view(b_s, self.nums_head, tgt_len, source_len)attn_output_wights = attn_output_wights.masked_fill(key_padding_mask.unsqueeze(1).unsqueeze(2) == 0, float('-inf'))attn_output_wights = attn_output_wights.view(b_s * self.nums_head, tgt_len, source_len)attn_output_wights = F.softmax(attn_output_wights, dim=-1)attn_output_wights = F.dropout(attn_output_wights, p=drop_p, training=training)attn_output = torch.bmm(attn_output_wights, v)# [batch_size * nums_head, tgt_len, src_len], [batch_size*nums_head, src_len, v_dim]# [batch_size * nums_head, tgt_len, v_dim]attn_output = attn_output.contiguous().view(b_s, tgt_len, self.d_model)# print(attn_output.shape)attn_output_wights = attn_output_wights.view(b_s, self.nums_head, tgt_len, source_len)Z = F.linear(attn_output, self.output.weight)return Z, attn_output, attn_output_wights.sum(dim=1) / self.nums_head
if __name__ == '__main__':inputs = 'transformer_embedding_out'src_len = 5batch_size = 2d_model = 32num_head = 1src = torch.rand(([batch_size, src_len, d_model]))mha = MultiHeadAttention(dim_model=d_model, n_head=num_head, bias=True)out, attn_out, attn_weight = mha(src, src, src, drop_p=0.1, attn_mask=None, key_padding_mask=None)print(out.shape, attn_out.shape, attn_weight.shape)# print(src, out, attn_out, attn_weight)# out = mha(inputs, inputs, inputs, drop_p=0.1, attn_mask=None, key_padding_mask=None)
EncoderLayer 编码层
单个编码层的实现
注意力机制经过残差连接后,进行层归一化后输出
class EncoderLayer(nn.Module):def __init__(self, embed_dim, n_head, feedforward_dim, drop_fc=None, drop_attn=None, drop_feed=None):"""单个的编码层,论文中6个:param embed_dim: 嵌入维度,词向量和位置编码的嵌入维度,论文中:512:param n_head: 多头注意力机制个数,论文中:8个, 512//64=8,batch_size=64:param drop_attn: 注意力机制层输出的随机丢弃:param drop_feed: 前馈网络层输出的随机丢弃"""super(EncoderLayer, self).__init__()# TransformerEmbedding(vocab_size=2048, d_model=512, drop=0.1, drop_prob=0.1, max_len=None, device='cpu')# 注意力机制层 [batch_size, max_len, d_model]self.attn_encoder = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=True)# 注意力机制输出进行dropself.drop_out1 = nn.Dropout(drop_attn)self.norm1 = nn.LayerNorm(embed_dim)# 前馈网络层self.feedforward = PositionWiseFeedForward(dim_model=embed_dim, drop_fc=drop_fc, dim_feedforward=feedforward_dim)# 前馈网络输出进行dropself.drop_out2 = nn.Dropout(drop_feed)self.norm2 = nn.LayerNorm(embed_dim)self.activation = nn.ReLU()def forward(self, src_sentence, drop=None, training=True, attn_mask=None, src_key_padding_mask=None):"""填充后的句子输入,经过词向量+位置编码/注意力机制层/残差连接/前馈传播层/残差连接/输出:param src_key_padding_mask: 输入句子的填充部分做掩盖处理:param attn_mask: 注意力的掩码,一般在解码部分为了掩盖后续position需要使用:param training: 是否训练模式:param drop: 注意力层weights输出的drop:param src_sentence: 填充后的原始句子:return: 编码层的输出, 解码层的部分输入"""# input_embedding = self.input_embedding(src_sentence)input_embedding = src_sentenceattn_encoder = self.attn_encoder(input_embedding, input_embedding, input_embedding, drop_p=drop,training=training, attn_mask=attn_mask, key_padding_mask=src_key_padding_mask)[0]# add & norm 残差连接后归一化处理,归一化防止数值过大后续训练时候造成梯度丢失或爆炸embedding_attn = input_embedding + self.drop_out1(attn_encoder)attn_out = self.norm1(embedding_attn)attn_out = self.activation(attn_out)# 前馈连接,Feed_Forward层feed_forward = self.feedforward(attn_out)# Feed_Forward层后的残差连接+归一化attn_feed = attn_encoder + self.drop_out2(feed_forward)encoder_layer_out = self.norm2(attn_feed)return encoder_layer_out
Encoder多层编码块/前馈网络层
多个编码层的实现
class Encoder(nn.Module):def __init__(self, embed_dim, n_head, feedforward_dim, drop_fc, drop_attn, drop_feed, n_layers):super(Encoder, self).__init__()self.layers = nn.ModuleList([EncoderLayer(embed_dim=embed_dim, n_head=n_head, feedforward_dim=feedforward_dim,drop_fc=drop_fc, drop_attn=drop_attn, drop_feed=drop_feed)for _ in range(n_layers)])def forward(self, src_sentence, drop, training=True, src_mask=None, src_key_padding_mask=None):""":param drop::param training::param src_sentence: 嵌入向量的输入:param src_mask: 一般只在解码时使用,为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息:param src_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]:return:"""encoder_out = src_sentencefor layer in self.layers:encoder_out = layer(src_sentence, training=training, drop=drop, attn_mask=src_mask,src_key_padding_mask=src_key_padding_mask)return encoder_outclass PositionWiseFeedForward(nn.Module):def __init__(self, drop_fc=None, dim_model=512, dim_feedforward=2048):super(PositionWiseFeedForward, self).__init__()self.fc1 = nn.Linear(dim_model, dim_feedforward)self.fc2 = nn.Linear(dim_feedforward, dim_model)self.relu = nn.ReLU()self.drop = nn.Dropout(drop_fc)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.drop(x)x = self.fc2(x)return xDecoderLayer解码层
单个解码层的实现
需要与Encoder层进行交互
class DecoderLayer(nn.Module):def __init__(self, embed_dim, feedforward_dim, n_head, drop_fc, drop_mask_attn, drop_attn, drop_feed, bias=True):"""解码层:输入嵌入+位置编码-->带掩码的多头注意力-->与编码交互的多头注意力-->前馈网络:param embed_dim: 嵌入维度:512:param feedforward_dim: 前馈网络的隐层维度:2048:param n_head: 多头注意力头数:8 512//64=8 d_model//batch_size=n_head:param drop_fc: 前馈网络中隐层输出的随机丢弃比例:param drop_mask_attn: 带掩码的多头注意力层输出:param drop_attn: 与编码交互的多头注意力层输出:param drop_feed: 前馈网络层输出:param bias: 多头注意力层线性输出时候是否加偏置"""super(DecoderLayer, self).__init__()# self.out_embedding =# TransformerEmbedding(vocab_size=2048, d_model=512, drop=0.1, drop_prob=0.1, max_len=None, device='cpu')self.attn = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=bias)self.mask_attn = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=bias)self.fc = PositionWiseFeedForward(dim_model=embed_dim, drop_fc=drop_fc, dim_feedforward=feedforward_dim)# mask_attention层self.drop1 = nn.Dropout(drop_mask_attn)# encoder_decoder_attention层self.drop2 = nn.Dropout(drop_attn)# 前馈网络层self.drop3 = nn.Dropout(drop_feed)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.norm3 = nn.LayerNorm(embed_dim)self.activation = nn.ReLU()def forward(self, tgt, memory, drop=None, tgt_mask=None, memory_mask=None,tgt_key_padding_mask=None, memory_key_padding_mask=None):""":param drop::param memory_mask: 编码器-解码器交互时的注意力掩码,一般为None:param tgt_mask: 注意力机制中的掩码矩阵,用于掩盖当前position之后的信息, [tgt_len, tgt_len]:param memory: 编码部分的输出(memory), [src_len,batch_size,embed_dim]:param tgt: 解码部分的输入,形状为 [tgt_len,batch_size, embed_dim]:param tgt_key_padding_mask:解码部分输入的padding情况,形状为 [batch_size, tgt_len],填充词的掩码:param memory_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]:return:"""# out_embedding = self.out_embedding(tgt_sentence)# out_embedding = tgt_sentence# MultiHeadAttention返回: attn_out_linear, attn_concat, attn_weightsmask_attn = self.mask_attn(tgt, tgt, tgt, drop_p=drop, training=True,attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0]mask_out = self.norm1(tgt + self.drop1(mask_attn))self_attn = self.attn(tgt, key=memory, value=memory, drop_p=drop, training=True,attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]attn_out = self.norm2(mask_out + self.drop2(self_attn))attn_out = self.activation(attn_out)feed_forward = self.fc(attn_out)decoder_out = self.norm3(attn_out+self.drop3(feed_forward))return decoder_out
Decoder多层解码块
多个解码层的实现
class Decoder(nn.Module):def __init__(self, n_layers, embed_dim, feedforward_dim, n_head, drop_fc,drop_mask_attn, drop_attn, drop_feed, bias=True):super(Decoder, self).__init__()self.layers = nn.ModuleList([DecoderLayer(embed_dim=embed_dim, feedforward_dim=feedforward_dim, n_head=n_head,drop_fc=drop_fc, drop_mask_attn=drop_mask_attn, drop_attn=drop_attn,drop_feed=drop_feed, bias=bias) for _ in range(n_layers)])def forward(self, tgt_sentence, memory, drop, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None,memory_key_padding_mask=None):decoder_out = tgt_sentencefor layer in self.layers:decoder_out = layer(tgt_sentence, memory, drop=drop, tgt_mask=tgt_mask,tgt_key_padding_mask=tgt_key_padding_mask,memory_key_padding_mask=memory_key_padding_mask, memory_mask=None)return decoder_out
if __name__ == '__main__':src_len = 5batch_size = 2d_model = 32num_head = 1n_layer = 6src = torch.rand(([batch_size, src_len, d_model]))encoder = Decoder(n_layers=n_layer, embed_dim=d_model, feedforward_dim=2048, n_head=num_head, drop_fc=0.1,drop_mask_attn=0.1, drop_attn=0.1, drop_feed=0.1, bias=True)print(encoder)
MyTransformer实现完整的Transformer框架
import torch
import torch.nn as nn
import torch.nn.functional as F
from TransformerEmbedding import TransformerEmbedding
from EncoderLayer import Encoder
from DecoderLayer import Decoderclass MyTransformer(nn.Module):def __init__(self, src_vocab_size, src_max_len, tgt_vocab_size, tgt_max_len, embed_dim, feedforward_dim, n_head,drop_prob, n_layers):super(MyTransformer, self).__init__()self.src_embedding = TransformerEmbedding(vocab_size=src_vocab_size, max_len=src_max_len, d_model=embed_dim,drop=drop_prob, device='cpu')self.tgt_embedding = TransformerEmbedding(vocab_size=tgt_vocab_size, max_len=tgt_max_len, d_model=embed_dim,drop=drop_prob, device='cpu')self.encoder = Encoder(embed_dim=embed_dim, n_head=n_head, feedforward_dim=feedforward_dim, n_layers=n_layers,drop_fc=drop_prob, drop_attn=drop_prob, drop_feed=drop_prob)self.decoder = Decoder(embed_dim=embed_dim, feedforward_dim=feedforward_dim, n_head=n_head, n_layers=n_layers,drop_fc=drop_prob, drop_mask_attn=drop_prob, drop_attn=drop_prob, drop_feed=drop_prob)# self.fc = nn.Linear(drop_prob)def forward(self, src, tgt, drop_prob, training=True, src_mask=None, tgt_mask=None,src_key_padding_mask=None, tgt_key_padding_mask=None):src_embedding = self.src_embedding(src)tgt_embedding = self.tgt_embedding(tgt)memory = self.encoder(src_embedding, drop=drop_prob, training=training,src_key_padding_mask=src_key_padding_mask)# print(src_embedding.shape, tgt_embedding.shape, memory.shape)print('编码完成------------------------------')decoder = self.decoder(tgt_embedding, memory, drop=drop_prob, tgt_mask=tgt_mask,tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=src_key_padding_mask)print('解码完成')return decoderdef init_parameters(self):for p in self.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)def generate_square_subsequent_mask(self, s_z):mask = torch.tril(torch.ones(s_z, s_z)).transpose(0, 1)mask = mask.float().masked_fill(mask == 0.0, float('-inf')).masked_fill(mask == 1.0, float('-inf'))return mask
if __name__ == '__main__':Input = [[1, 2, 3, 4], [5, 6, 2], [1, 7, 8, 9, 10, 11, 12, 13, 14, 15]]output = [[1, 1, 2, 3, 4], [5, 5, 6, 2], [1, 7, 7, 8, 9, 10, 11, 12, 13, 14, 15]]# 有三个句子[['你 好 世 界'], ['我 很 好'], ['你 不 是 真 正 的 快 乐']]# 句子长度不一致进行padding处理src_sentence = torch.tensor([])for i in range(len(Input)):src_sen = torch.tensor([Input[i]])src_sen = F.pad(src_sen, (0, len(Input[2]) - len(Input[i])), 'constant', 0)src_sentence = torch.cat([src_sentence, src_sen], dim=0)# x = src_sentence.unsqueeze(dim=0)tgt_sentence = torch.tensor([])for i in range(len(output)):src_sen = torch.tensor([output[i]])src_sen = F.pad(src_sen, (0, len(output[2]) - len(output[i])), 'constant', 0)tgt_sentence = torch.cat([tgt_sentence, src_sen], dim=0)src_len = 10batch_size = 3dmodel = 32tgt_len = 11num_head = 8# src = torch.rand((src_len, batch_size, dmodel)) # shape: [src_len, batch_size, embed_dim]# src_key_padding_mask = torch.tensor([[True, True, True, False, False],# [True, True, True, True, False]]) # shape: [batch_size, src_len]## tgt = torch.rand((tgt_len, batch_size, dmodel)) # shape: [tgt_len, batch_size, embed_dim]# tgt_key_padding_mask = torch.tensor([[True, True, True, False, False, False],# [True, True, True, True, False, False]]) # shape: [batch_size, tgt_len]my_transformer = MyTransformer(src_vocab_size=5000, src_max_len=10, tgt_vocab_size=5000, tgt_max_len=11, embed_dim=32,feedforward_dim=2048, n_head=8, drop_prob=0.1, n_layers=6)tgt_mask = my_transformer.generate_square_subsequent_mask(tgt_len)out = my_transformer(src=src_sentence, tgt=tgt_sentence, drop_prob=0.1, tgt_mask=tgt_mask,src_key_padding_mask=src_sentence,tgt_key_padding_mask=tgt_sentence)print(out.shape)# torch.Size([3, 11, 32])
相关文章:
【Transformer框架代码实现】
Transformer Transformer框架注意力机制框架导入必要的库Input Embedding / Out EmbeddingPositional EmbeddingTransformer EmbeddingScaleDotProductAttention(self-attention)MultiHeadAttention 多头注意力机制EncoderLayer 编码层Encoder多层编码块/前馈网络层…...
Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580
Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580 已亲自复现 漏洞名称漏洞描述影响版本 漏洞复现环境搭建漏洞利用 修复建议总结 Apache ShenYu 网关JWT认证绕过漏洞 CVE-2021-37580 已亲自复现) 漏洞名称 漏洞描述 Apache ShenYu是一个异步的,高性能的&#x…...

锐捷配置重发布RIP进OSPF中
一、实验拓扑 二、实验目的 使用两种动态路由协议,并使两种协议间的路由可以传递 三、实验配置 第一步:配置全网基本IP R1 Ruijie>enable Ruijie#configure terminal Ruijie(config)#interface gigabitEthernet 0/0 Ruijie(config-if-GigabitEthe…...

Android R修改wifi热点默认为隐藏热点以及禁止自动关闭热点
前言 Android R系统中WLAN 热点设置里面默认是没有wifi热点的隐藏设置选项的,如果默认wifi热点为隐藏热点可以修改代码实现。另外wifi热点设置选项里面有个自动关闭热点,这个选项默认是打开的,有些机器里面配置wifi热点后默认是需要关闭掉的,以免自动关闭后要手动打开。 …...

智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于人工大猩猩部队算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.人工大猩猩部队算法4.实验参…...

[JS设计模式]Flyweight Pattern
Flyweight pattern 享元模式是一种结构化的设计模式,主要用于产生大量类似对象而内存又有限的场景。享元模式能节省内存。 假设一个国际化特大城市SZ;它有5个区,分别为nanshan、futian、luohu、baoan、longgang;每个区都有多个图…...
读取配置文件全面总结)
【.Net8教程】(一)读取配置文件全面总结
环境:.net8.0 1. 准备条件 先在appsettings.Development.json或appsettings.json添加配置 添加一个DbOption {"DbOption": {"Conn": "foolishsundaycsdn"} }2.直接读取json配置节点的几种写法 在Main函数中读取json配置 方式一 …...
亚信安慧AntDB:支撑中国广电5G业务的数据库之力
自2019年6月获得5G牌照以来,中国广电积极利用700MHz频谱资源,迅速崛起为第四大运营商,标志着其在数字通信领域取得的巨大成就。通过与中国移动紧密合作,共建共享基站已超过400万座,为实现自主运营和差异化竞争提供了坚…...

C++哈希表的实现
C哈希表的实现 一.unordered系列容器的介绍二.哈希介绍1.哈希概念2.哈希函数的常见设计3.哈希冲突4.哈希函数的设计原则 三.解决哈希冲突1.闭散列(开放定址法)1.线性探测1.动图演示2.注意事项3.代码的注意事项4.代码实现 2.开散列(哈希桶,拉链法)1.概念2.动图演示3.增容问题1.拉…...
[Angular] 笔记 6:ngStyle
ngStyle 指令: 用于更新 HTML 元素的样式。设置一个或多个样式属性,用以冒号分隔的键值对指定。键是样式名称,带有可选的 .<unit> 后缀(如 ‘top.px’、‘font-style.em’),值为待求值的表达式,得到…...

Linux环境下使用logrotate工具实现nginx日志切割
本文已同步到专业技术网站 www.sufaith.com, 该网站专注于前后端开发技术与经验分享, 包含Web开发、Nodejs、Python、Linux、IT资讯等板块. 一. 前提背景及需求 nginx运行日志默认保存在nginx安装目录下的 /usr/local/nginx/logs 文件夹, 包含access.log和error.log两个文件.…...
数字信号的理解
1 数字信号处理简介 数字信号处理 digital signal processing(DSP)经常与实际的数字系统相混淆。这两个术语都暗示了不同的概念。数字信号处理在本质上比实际的数字系统稍微抽象一些。数字系统是涉及的硬件、二进制代码或数字域。这两个术语之间的普遍混…...

【计算机网络】TCP心跳机制、TCP粘包问题
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 更多计算机网络知识专栏:计算机网络🔥 给大家跳段…...
【Linux驱动】字符设备驱动程序框架 | LED驱动
🐱作者:一只大喵咪1201 🐱专栏:《RTOS学习》 🔥格言:你只管努力,剩下的交给时间! 目录 🏀Hello驱动程序⚽驱动程序框架⚽编程 🏀LED驱动⚽配置GPIO⚽编程驱动…...
关于编程网站变成了地方这件事
洛谷: 首页 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) csdn CSDN - 专业开发者社区 力扣 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 常州市力扣紧固件有限公司 常州市 力扣 紧固件 有限公司 博客园 博客园 - 开发…...

stable diffusion工作原理
目录 序言stable diffusion能做什么扩散模型正向扩散逆向扩散 如何训练逆向扩散 Stable Diffusion模型潜在扩散模型变分自动编码器图像分辨率图像放大为什么潜在空间可能存在?在潜在空间中的逆向扩散什么是 VAE 文件? 条件化(conditioning)文本条件化&am…...

华清远见嵌入式学习——ARM——作业2
目录 作业要求: 现象: 代码: 思维导图: 模拟面试题: 作业要求: GPIO实验——3颗LED灯的流水灯实现 现象: 代码: .text .global _start _start: 设置GPIOEF时钟使能 0X50000…...
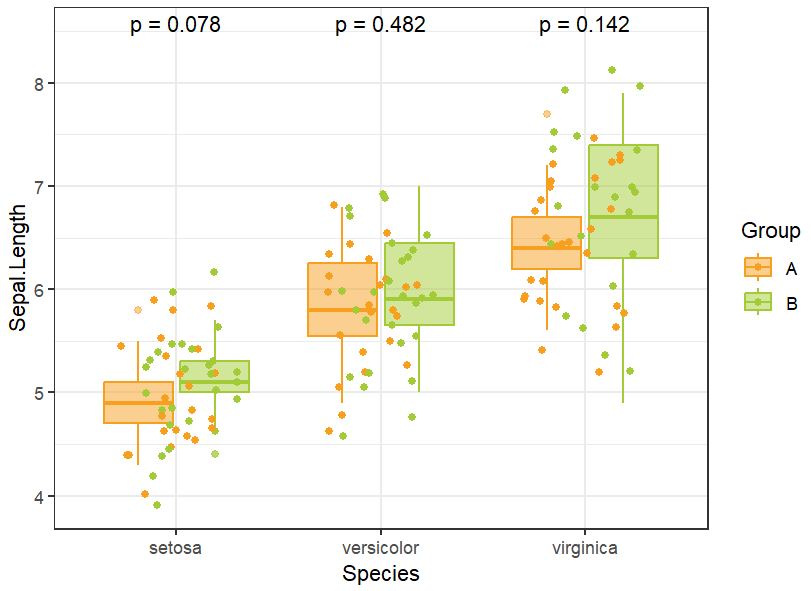
R语言中使用ggplot2绘制散点图箱线图,附加显著性检验
散点图可以直观反映数据的分布,箱线图可以展示均值等关键统计量,二者结合能够清晰呈现数据蕴含的信息。 本篇笔记主要内容:介绍R语言中绘制箱线图和散点图的方法,以及二者结合展示教程,添加差异比较显著性分析…...

51单片机的羽毛球计分器系统【含proteus仿真+程序+报告+原理图】
1、主要功能 该系统由AT89C51单片机LCD1602显示模块按键等模块构成。适用于羽毛球计分、乒乓球计分、篮球计分等相似项目。 可实现基本功能: 1、LCD1602液晶屏实时显示比赛信息 2、按键控制比赛的开始、暂停和结束,以及两位选手分数的加减。 本项目同时包含器件清…...

设计模式之-责任链模式,快速掌握责任链模式,通俗易懂的讲解责任链模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

告别格式焦虑:用StarWind V2V Converter v9.0.1.268在ESXi 8.0和Hyper-V之间无损迁移虚拟机
跨平台虚拟机迁移实战:StarWind V2V Converter的高效应用指南 当企业IT基础设施面临升级或混合云架构转型时,虚拟机格式转换往往成为技术团队最头疼的问题之一。我曾参与过多次从VMware到Hyper-V的迁移项目,亲眼目睹了传统转换方法导致的业务…...

流程可视化引擎定制指南:从技术实现到业务价值转化
流程可视化引擎定制指南:从技术实现到业务价值转化 【免费下载链接】Drawflow Simple flow library 🖥️🖱️ 项目地址: https://gitcode.com/gh_mirrors/dr/Drawflow 在数字化转型过程中,企业面临着业务流程可视化与实际业…...

FindSomething:革新性网页智能信息提取工具完全指南
FindSomething:革新性网页智能信息提取工具完全指南 【免费下载链接】FindSomething 基于chrome、firefox插件的被动式信息泄漏检测工具 项目地址: https://gitcode.com/gh_mirrors/fi/FindSomething 在数字时代,网页中隐藏的敏感信息和数据模式往…...
 #笔记学习资料 内含: 1)
基于PLC1200的水箱液位解耦控制系统(过程控制课程设计) #笔记学习资料 内含: 1
基于PLC1200的水箱液位解耦控制系统(过程控制课程设计) #笔记学习资料 内含: 1.PLC控制程序(博图V18) 2.设计报告(pdf版本,详细介绍整个项目设计方案、Simulink仿真模型结构图、仿真结果、PLC梯…...
)
避开这3个坑!MIPI走线设计如何减少对GSM信号的干扰(含阻抗匹配计算)
避开这3个坑!MIPI走线设计如何减少对GSM信号的干扰(含阻抗匹配计算) 在消费电子硬件设计中,MIPI接口与射频信号的共存问题一直是工程师面临的棘手挑战。特别是当设备需要同时支持高清显示和GSM通信功能时,MIPI信号对GS…...

全网资源嗅探下载神器:轻松获取视频音频资源的终极指南
全网资源嗅探下载神器:轻松获取视频音频资源的终极指南 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcode.co…...

Windows服务器部署:OpenClaw守护进程+Qwen3-32B镜像长期运行
Windows服务器部署:OpenClaw守护进程Qwen3-32B镜像长期运行 1. 为什么需要服务器级部署? 去年我尝试在个人笔记本上运行OpenClaw时,经常遇到两个头疼的问题:一是夜间执行任务时电脑休眠导致流程中断,二是长时间运行后…...

FOC算法避坑指南:克拉克变换的‘等幅值’与‘等功率’到底选哪个?基于AS5600编码器的实测对比
FOC算法避坑指南:克拉克变换的‘等幅值’与‘等功率’到底选哪个?基于AS5600编码器的实测对比 在无刷电机控制领域,FOC(Field Oriented Control)算法因其优异的动态性能和效率表现,已成为工业驱动和高精度…...

ChatGPT官网镜像实战:生产环境内存泄漏排查与修复全记录
国内开发者如果想借助ChatGPT进行生产环境故障排查和性能分析,最便捷的方案是通过聚合镜像平台RskAi(www.rsk.cn)。该平台支持ChatGPT(GPT-4o)国内直接访问,无需任何特殊网络环境,且提供每日免费…...
)
鸿蒙Next通讯录实战:用ArkUI 3.0手把手教你打造新建联系人页面(附完整代码)
鸿蒙Next通讯录实战:用ArkUI 3.0构建企业级新建联系人页面 在移动应用开发领域,通讯录功能一直是检验开发者UI构建和数据管理能力的经典场景。鸿蒙Next作为新一代分布式操作系统,其ArkUI 3.0框架为开发者提供了声明式UI编程范式,让…...