【性能优化】MySql数据库查询优化方案
阅读本文你的收获
- 了解系统运行效率提升的整体解决思路和方向
- 学会MySQl中进行数据库查询优化的步骤
- 学会看慢查询、执行计划、进行性能分析、调优
一、问题:如果你的系统运行很慢,你有什么解决方案?
关于这个问题,我们通常首先考虑的是硬件升级,毕竟服务器的内存、CPU、磁盘IO速度 、网络速度等都是制约我们系统快慢的首要因素。硬件的升级相对来说比较容易,花点钱买台好点的服务器就行了。如果你用的是云服务器,那就更Easy了,花钱升级增配就行了,几分钟就完成了。
那程序(软件)层面我们怎么进行优化呢?我想,主要是以下几个方面:
- 前端方面的优化
页面缓存、前端框架层面的优化等 - 应用程序方面的优化:
- 代码层面进行一些优化,如采用更加适合的数据容器、处理逻辑/算法方便的改进;
- 采用性能更好的数据库访问技术,如Dapper比EF性能好,执行原生SQL语句比用ORM快等
- 引入缓存机制,缓存热点数据以减轻数据库I/O压力
- 采用异步编程,提高接口吞吐量等
- 数据库层面的优化
- 识别慢查询
- 加索引
- 通过执行计划,优化SQL语句
- 采用存储过程
- 读写分离
- 分库分表等
除此以外,还有Web服务器,如IIS服务器的调优、系统架构层面的集群优化等,本文主要分享的是数据库层面的调优。
案例的演示环境:
操作系统:Windows10 专业版
MySQL版本:MySql 5.7.17
MySql客户端:Navicat for MySql
开发框架:ASP.NET Core6.0
二、如何进行数据库调优?
2.1 查出那些查询很慢的SQL语句
慢查询(slow_query):是指MySQL中响应时间超过阀值(long_query_time,单位:秒)的SQL语句。
MySQL的慢查询日志是MySQL提供的一种日志记录,专门用来记录慢查询。可以按照以下的步骤来开启和查看慢查询日志:
-
修改一下mysql的配置文件,然后重启mysql服务器
我们首先要知道
windows下的配置文件在哪里?如何查看?配置哪些选项?在mysql命令行界面,输入以下命令:
mysql> show variables like ‘%data%’;


打开my.ini配置文件,并添加/修改如下的配置参数:
[mysqld]
…
slow-query-log=1 #开启慢查询日志,默认为1,即开启
#slow_query_log_file=“WANGXF-PC-slow.log”
slow_query_log_file=D:/mysql/slow.log #慢查询日志的记录文件路径
#long_query_time=10
long_query_time=1 #查询超过1秒语句全部记录,默认值是10秒
log_queries_not_using_indexes=1 #没有使用索引的查询全部记录
改完之后重启mysql的服务

2. 测试是否记录慢查询!此处用sleep函数来模拟一个很慢的查询,花5秒。

打开“D:/mysql/slow.log”查看是否记录了慢查询日志:

3. 慢查询分析工具mysqldumpslow
mysqldumpslow是MySQL自带的分析慢查询的工具。 该命令格式如下:
mysqldumpslow [ OPTS…][ LOGS…]
mysqldumpslow是一个perl脚本,只需下载并赋权即可执行。所以我们首先需要在windows下安装Perl,安装过程很简单,从官网 http://strawberryperl.com/ 下载windows安装包,安装好之后,测试perl -v,如果能显示版本号,表示安装成功。
几个常用的命令
- 得到返回记录集最多的10条SQL:
perl mysqldumpslow.pl -s r -t 10 D:/mysql/slow.log
- 得到访问次数最多的10条SQL:
perl mysqldumpslow.pl -s r -t 10 D:/mysql/slow.log
- 得到按照时间排序的前10条里面含有左连接的SQL:
perl mysqldumpslow.pl -s t -t 10-g “left join” D:/mysql/slow.log
2.2 通过explain查看执行计划
通过上面的步骤锁定了哪些查询是慢查询,接下来我们可以用explain命令查看执行计划,看看是否命中了索引。如果没有索引则创建索引,如果创建了索引但是没有起作用,则可以优化SQL语句来使索引生效。

创建索引后,再去分析,可以看到他已经命中索引了:


explain命令的执行结果每一列的说明:
| 信息 | 描述 |
|---|---|
| id | 查询的序号,包含一组数字,表示查询中执行select子句或操作表的顺序 两种情况 id相同,执行顺序从上往下 id不同,id值越大,优先级越高,越先执行 |
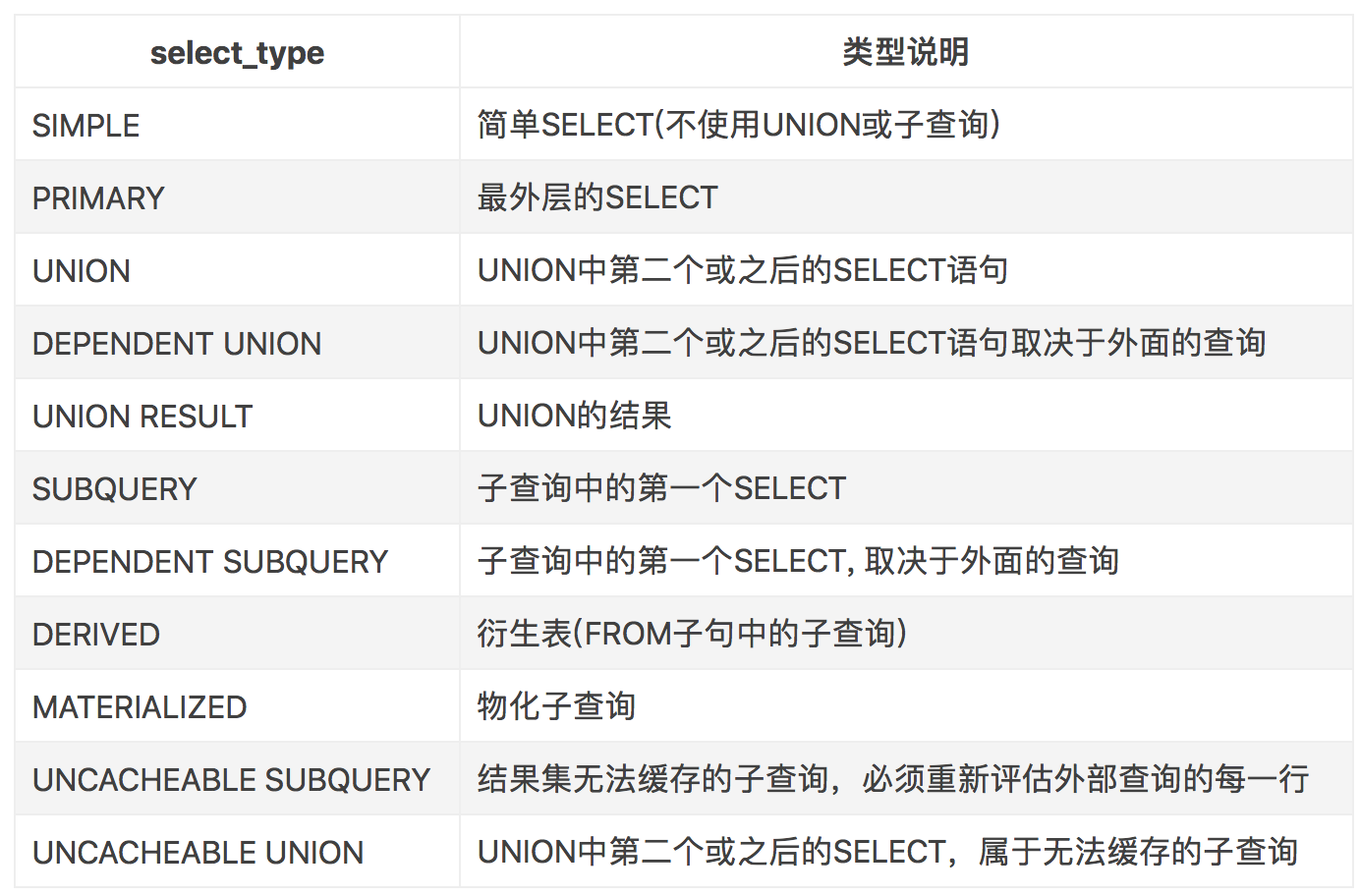
| select_type | 查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询 1、simple ——简单的select查询,查询中不包含子查询或者UNION 2、primary ——查询中若包含任何复杂的子部分,最外层查询被标记 3、subquery——在select或where列表中包含了子查询 4、derived——在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中 5、union——如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived 6、union result:UNION 的结果 |
| table | 输出的行所引用的表 |
| type | 显示联结类型,显示查询使用了何种类型,按照从最佳到最坏类型排序 1、system:表中仅有一行(=系统表)这是const联结类型的一个特例。 2、const:表示通过索引一次就找到,const用于比较primary key或者unique索引。因为只匹配一行数据,所以如果将主键置于where列表中,mysql能将该查询转换为一个常量。 3、eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于唯一索引或者主键扫描。 4、ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,可能会找多个符合条件的行,属于查找和扫描的混合体。 5、range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是where语句中出现了between,in等范围的查询。这种范围扫描索引扫描比全表扫描要好,因为它开始于索引的某一个点,而结束另一个点,不用全表扫描。 6、index:index 与all区别为index类型只遍历索引树。通常比all快,因为索引文件比数据文件小很多。 7、all:遍历全表以找到匹配的行。 注意:一般保证查询至少达到range级别,最好能达到ref。 |
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠。 |
| key_len | 表示索引中使用的字节数,该列计算查询中使用的索引的长度 在不损失精度的情况下,长度越短越好。如果键是NULL,则长度为NULL。该字段显示为索引字段的最大可能长度,并非实际使用长度。 |
| ref | 显示索引的哪一列被使用了,如果有可能是一个常数,哪些列或常量被用于查询索引列上的值 |
| rows | 根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数 |
| Extra | 包含不适合在其他列中显示,但是十分重要的额外信息 1、Using filesort:说明mysql会对数据适用一个外部的索引排序。而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成排序操作称为“文件排序” 2、Using temporary:使用了临时表保存中间结果,mysql在查询结果排序时使用临时表。常见于排序order by和分组查询group by。 3、Using index:表示相应的select操作用使用覆盖索引,避免访问了表的数据行。如果同时出现using where,表名索引被用来执行索引键值的查找;如果没有同时出现using where,表名索引用来读取数据而非执行查询动作。 4、Using where :表明使用where过滤 5、using join buffer:使用了连接缓存 6、impossible where:where子句的值总是false,不能用来获取任何元组 7、select tables optimized away:在没有group by子句的情况下,基于索引优化Min、max操作或者对于MyISAM存储引擎优化count(*),不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 8、distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。 |
2.3 如何进一步进行查询性能分析?
profiling性能分析,可以更进一步去分析每一句sql语句的cpu性能及内存占用。
- 该功能默认是关闭的,要开启profiling功能,输入以下命令:

执行查询语句,接着显示所有查询的性能分析结果:
mysql> select * from syslog;

显示query_id为1的查询的性能报告:

2.4 数据库调优的手段
-
索引优化
可以对where条件后面的条件字段,和order by/group by后面的排序、分组字段创建索引,以提高查询速度。 -
SQL语句优化
- select 时不用* 返回所有字段,查询具体字段可以提高一定速度
- 不用is null或is not null、
- not in/in 不能使,用exists查询替代
- 不能用like ‘%xxx’,%开头的模糊查询用不到索引
- 少用不等于 !=、大于>、小于<的查询
- or查询用union查询替代
- …
-
MySQL实现读写分离
一般数据库都是读多而写少,如果数据量一大,单体数据库服务器造成性能瓶颈,可以采用MySQL数据库集群实现读写分离,一主多从。主库负责写操作,多个从库只负责读操作。 -
分库、分表
按业务系统不同,使用不同的数据库,即“分库”。
分表则分为垂直分表和水平分表。
(注:不做展开了,后续专门发文探讨)
本次主要分享的是MySQL数据库的性能优化思路,如果本文对你有帮助的话,请点赞+评论+关注,或者转发给需要的朋友。
相关文章:
【性能优化】MySql数据库查询优化方案
阅读本文你的收获 了解系统运行效率提升的整体解决思路和方向学会MySQl中进行数据库查询优化的步骤学会看慢查询、执行计划、进行性能分析、调优 一、问题:如果你的系统运行很慢,你有什么解决方案? 关于这个问题,我们通常首先…...
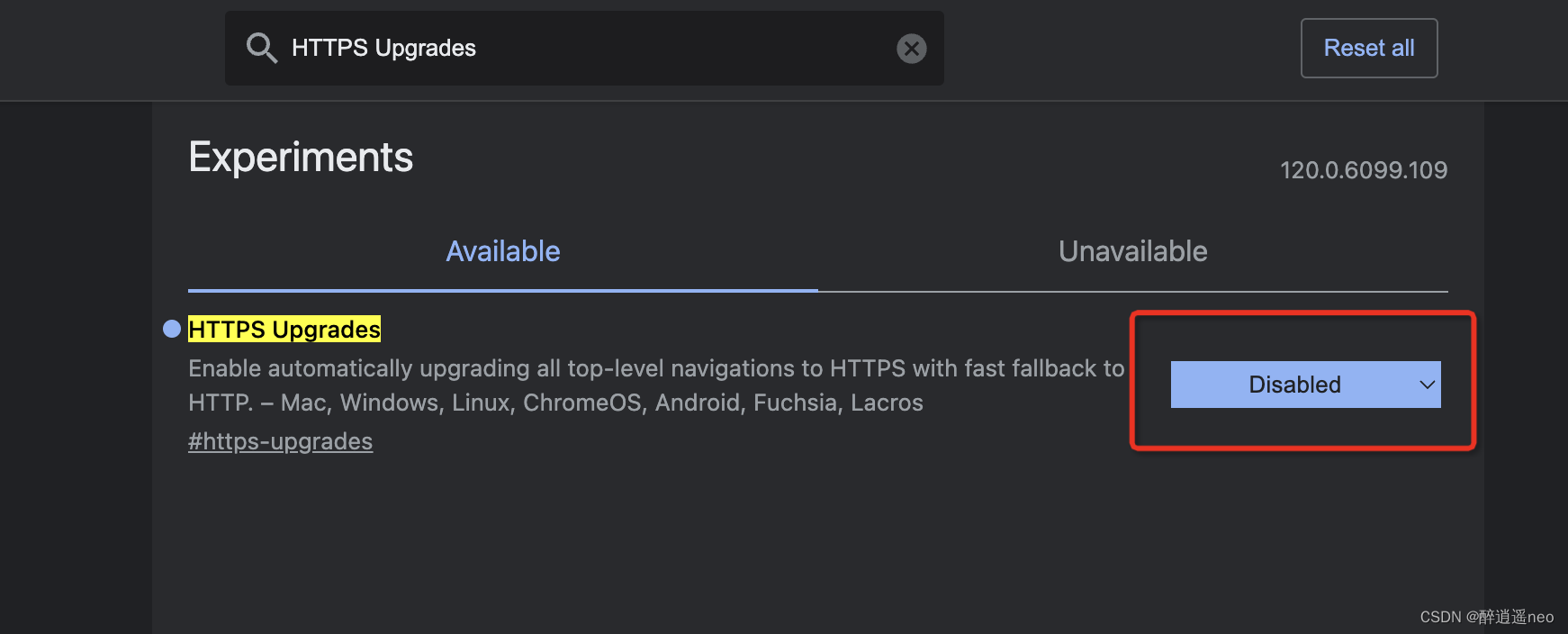
Chrome浏览器http自动跳https问题
现象: Chrome浏览器访问http页面时有时会自动跳转https,导致一些问题。比如: 开发阶段访问dev环境网址跳https,后端还是http,导致接口跨域。 复现: 先访问http网址,再改成https访问…...

【C++进阶02】多态
一、多态的概念及定义 1.1 多态的概念 多态简单来说就是多种形态 同一个行为,不同对象去完成时 会产生出不同的状态 多态分为静态多态和动态多态 静态多态指的是编译时 在程序编译期间确定了程序的行为 比如:函数重载 动态多态指的是运行时 在程序运行…...
PHP开发日志——循环和条件语句嵌套不同,效率不同(循环内加入条件语句,条件语句判断后加入循环,array_map函数中加入条件语句)
十多年前开发框架时,为了效率不断试过各种代码写法,今天又遇到了,想想php8时代会不会有所变化,结果其实也还是和当年一样,但当年没写博客,但现在可以把数据记录下来了。 PHP_loop_ireflies_dark_forest 项目…...
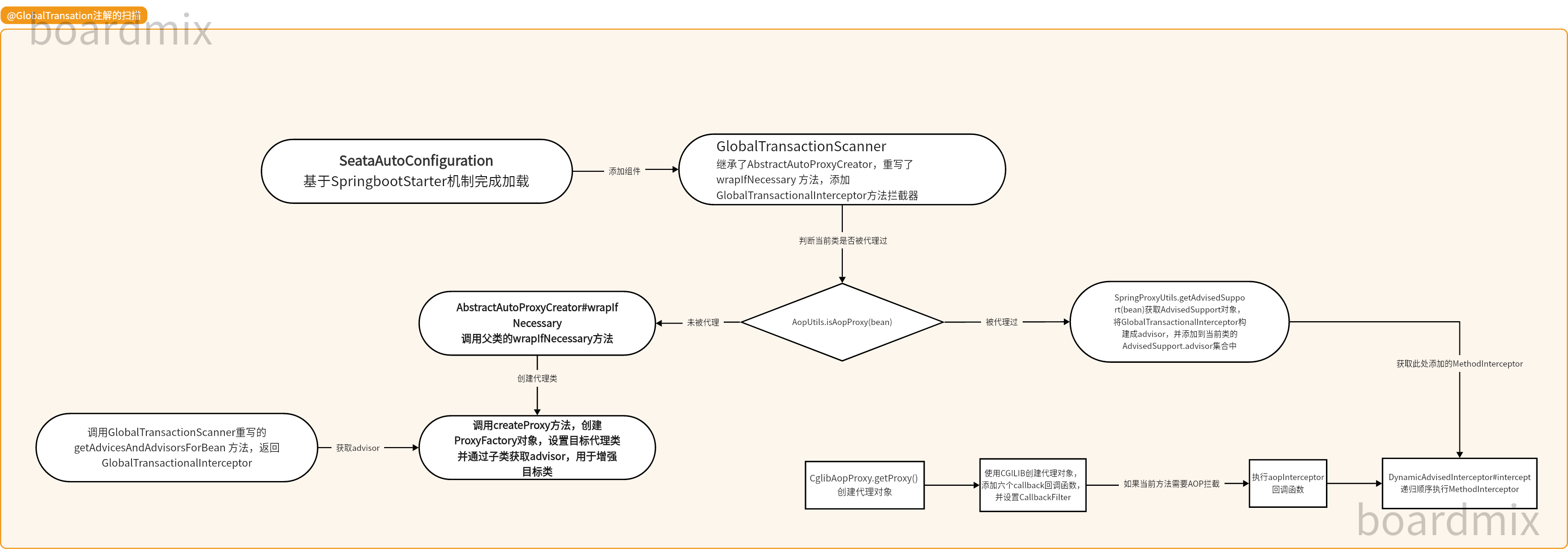
【Seata源码学习 】 扫描@GlobalTransaction注解 篇一
1. SeataAutoConfiguration 自动配置类的加载 基于SpringBoot的starter机制,在应用上下文启动时,会加载SeataAutoConfiguration自动配置类 # Auto Configure org.springframework.boot.autoconfigure.EnableAutoConfigurationio.seata.spring.boot.aut…...
DBA-MySql面试问题及答案-上
文章目录 1.什么是数据库?2.如何查看某个操作的语法?3.MySql的存储引擎有哪些?4.常用的2种存储引擎?6.可以针对表设置引擎吗?如何设置?6.选择合适的存储引擎?7.选择合适的数据类型8.char & varchar9.Mysql字符集10.如何选择…...
网络爬虫之Ajax动态数据采集
动态数据采集 规则 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样,在浏览器中可以看到正常显示的页面教据,但是使用 requests 得到的结果并没有,这是因为requests 获取的都是原始的 HTML 文档…...

c语言的初始学习(练习)
##初学c语言---MOOC浙江大学翁恺先生学习c语言 那么我们先看看这个题目吧,这是初始语法的应用。 记住,我们的程序是按步骤执行的,并不是在不同的两行同时进行。 程序设计:1.了解题目的需要,几个变量需要用到&#x…...

研究论文 2022-Oncoimmunology:AI+癌RNA-seq数据 识别细胞景观
Wang, Xin, et al. "Deep learning using bulk RNA-seq data expands cell landscape identification in tumor microenvironment." Oncoimmunology 11.1 (2022): 2043662. https://www.tandfonline.com/doi/full/10.1080/2162402X.2022.2043662 被引次数࿱…...

ChatGPT4与ArcGIS Pro3助力AI 地理空间分析和可视化及助力科研论文写作
在地学领域,ArcGIS几乎成为了每位科研工作者作图、数据分析的必备工具,而ArcGIS Pro3除了良好地继承了ArcMap强大的数据管理、制图、空间分析等能力,还具有二三维融合、大数据、矢量切片制作及发布、任务工作流、时空立方体等特色功能&#x…...

okhttp系列-一些上限值
1.正在执行的任务数量最大值是64 异步请求放入readyAsyncCalls后,遍历readyAsyncCalls取出任务去执行的时候,如果发现runningAsyncCalls的数量大于等于64,就不从readyAsyncCalls取出任务执行。 public final class Dispatcher {private int …...

C++面向对象(OOP)编程-STL详解(vector)
本文主要介绍STL六大组件,并主要介绍一些容器的使用。 目录 1 泛型编程 2 CSTL 3 STL 六大组件 4 容器 4.1 顺序性容器 4.1.1 顺序性容器的使用场景 4.2 关联式容器 4.2.1 关联式容器的使用场景 4.3 容器适配器 4.3.1 容器适配器的使用场景 5 具体容器的…...

postman几种常见的请求方式
1、get请求直接拼URL形式 对于http接口,有get和post两种请求方式,当接口说明中未明确post中入参必须是json串时,均可用url方式请求 参数既可以写到URL中,也可写到参数列表中,都一样,请求时候都是拼URL 2&am…...
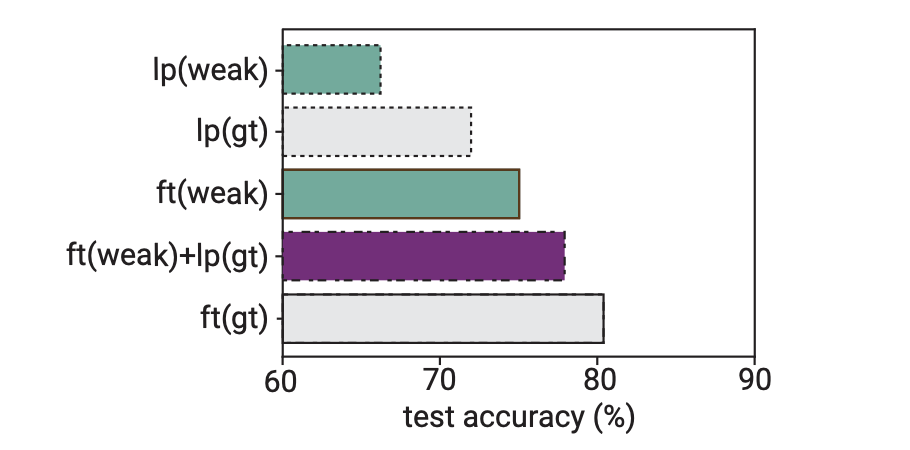
openai最新探索:超级对齐是否可行?
前言 今天来介绍一篇openai最新的paper:弱到强的对齐。 openai专门成立了一个团队来做大模型的超级对齐即superhuman model,之前chatgpt取得成功依赖RLHF即依赖人类反馈,但是作者期望的superhuman model将会是一个能够处理各种复杂问题的强…...

本地websocket服务端结合cpolar内网穿透实现公网访问
文章目录 1. Java 服务端demo环境2. 在pom文件引入第三包封装的netty框架maven坐标3. 创建服务端,以接口模式调用,方便外部调用4. 启动服务,出现以下信息表示启动成功,暴露端口默认99995. 创建隧道映射内网端口6. 查看状态->在线隧道,复制所创建隧道的公网地址加端口号7. 以…...

关于“Python”的核心知识点整理大全37
目录 13.6.2 响应外星人和飞船碰撞 game_stats.py settings.py alien_invasion.py game_functions.py ship.py 注意 13.6.3 有外星人到达屏幕底端 game_functions.py 13.6.4 游戏结束 game_stats.py game_functions.py 13.7 确定应运行游戏的哪些部分 alien_inva…...
Vivado中的FFT IP核使用(含代码)
本文介绍了Vidado中FFT IP核的使用,具体内容为:调用IP核>>配置界面介绍>>IP核端口介绍>>MATLAB生成测试数据>>测试verilogHDL>>TestBench仿真>>结果验证>>FFT运算。 1、调用IP核 该IP核对应手册pg109_xfft.pd…...

创新驱动,边缘计算领袖:亚马逊云科技海外服务器服务再进化
2022年亚马逊云科技re:Invent盛会于近日在拉斯维加斯成功召开,吸引了众多业界精英和创新者。亚马逊云科技边缘服务副总裁Jan Hofmeyr在演讲中分享了关于亚马逊云科技海外服务器边缘计算的最新发展和创新成果,引发与会者热烈关注。 re:Invent的核心主题是…...

什么是“人机协同”机器学习?
“人机协同”(HITL)是人工智能的一个分支,它同时利用人类智能和机器智能来创建机器学习模型。在传统的“人机协同”方法中,人们会参与一个良性循环,在其中训练、调整和测试特定算法。通常,它的工作方式如下…...

数学建模笔记-拟合算法
内容:拟合算法 一.概念: 拟合的结果就是找到一个确定的曲线 二.最小二乘法: 1. 2.最小二乘法的二表示的是平方的那个2 3.求解最小二乘法: 三.评价拟合的好坏 1.总体评分和SST: 2.误差平方和SSE: 3.回…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...