ccc-pytorch-小实验合集(4)
文章目录
- 一、 Himmelblau 优化
- 二、多分类实战-Mnist
- 三、Sequential与CPU加速-Mnist
- 四、visidom可视化
一、 Himmelblau 优化
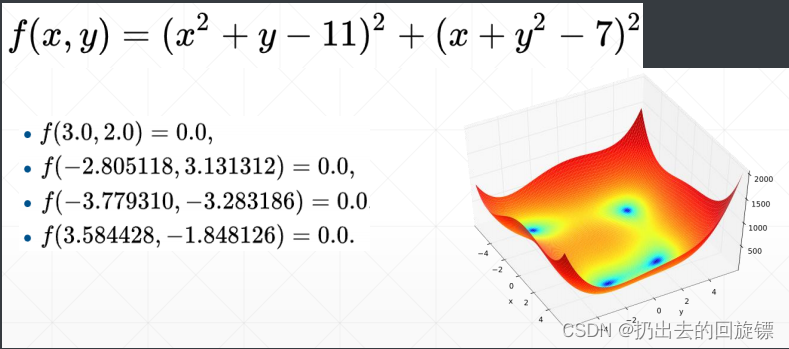
Himmelblau 是一个具有4个最优值的2维目标函数。其函数和最优值点如下:
图象绘制:
import numpy as np
from matplotlib import pyplot as pltdef himmelblau(x):return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print('x,y range:', x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print('X,Y maps:', X.shape, Y.shape)
Z = himmelblau([X, Y])fig = plt.figure('himmelblau')
ax = fig.add_subplot(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
Gradient Descent:
# [1., 0.], [-4, 0.], [4, 0.]
x = torch.tensor([-4., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3)
for step in range(20000):pred = himmelblau(x)# 清空各参数的梯度optimizer.zero_grad()pred.backward()# 优化器更新参数x'=x-lr*梯度optimizer.step()if step % 2000 == 0:print ('step {}: x = {}, f(x) = {}'.format(step, x.tolist(), pred.item()))
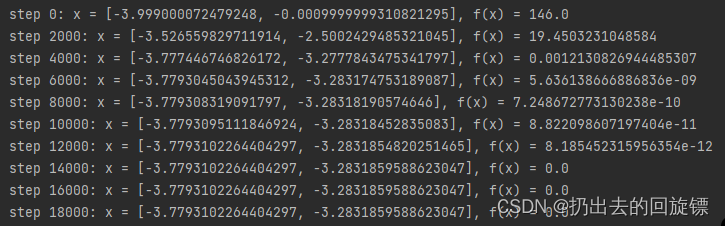
给予x不同的初始化位置可以得到不同的收敛结果和次数。说明初始位置的选择对于收敛的过程和结果非常重要。
二、多分类实战-Mnist
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsbatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)#Network Architecture
w1, b1 = torch.randn(200, 784, requires_grad=True),\torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),\torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\torch.zeros(10, requires_grad=True)
#kaiming初始化
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)def forward(x):x = x@w1.t() + b1x = F.relu(x)x = x@w2.t() + b2x = F.relu(x)x = x@w3.t() + b3x = F.relu(x)return xoptimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
# cross-entropy 等同于 softmax + log + nll_loss三个和
criteon = nn.CrossEntropyLoss()for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)logits = forward(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)logits = forward(data)test_loss += criteon(logits, target).item()pred = logits.data.max(1)[1]correct += pred.eq(target.data).sum()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
注意事项:
- Batch_Size太小导致收敛过慢,太大导致易陷入sharp minima,泛化性不好
- 注意初始化这个关键步骤
三、Sequential与CPU加速-Mnist
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transformsbatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item()pred = logits.argmax(dim=1)correct += pred.eq(target).float().sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))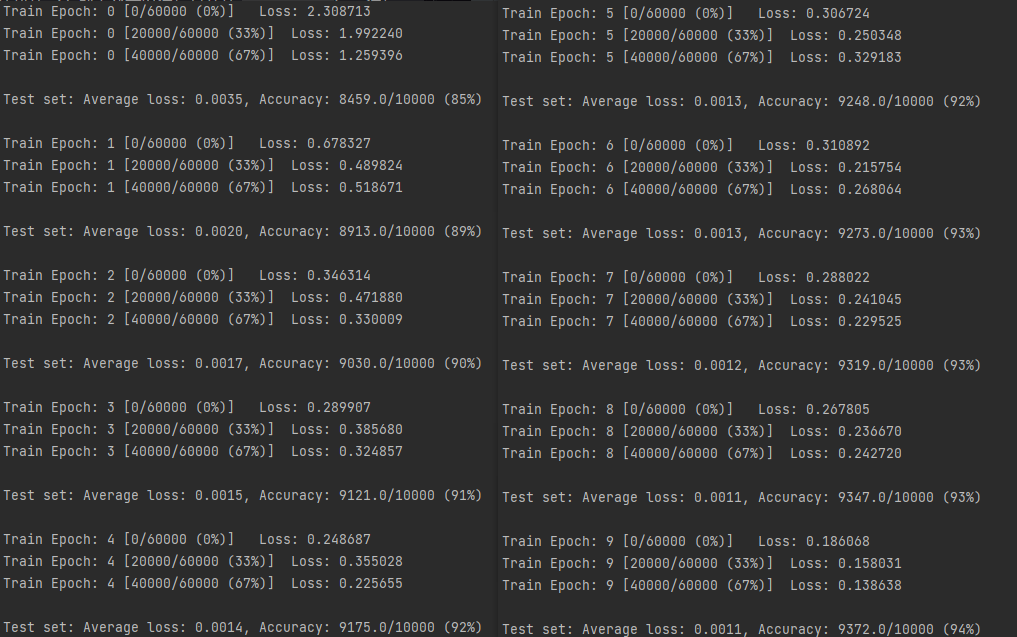
注意事项:
- MLP Class中对继承自父类的属性进行初始化,而且是用父类的初始化方法来初始化继承的属性。
- Sequential 本质是一个可以添加组件的模块,输入通过组成的流水线后得到输出
- 对于单卡计算机而言,使用torch.device(‘cuda’) 与 torch.device(‘cuda:0’)相同
四、visidom可视化
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdombatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),# transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),# transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)viz = Visdom()viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',legend=['loss', 'acc.']))
global_step = 0for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()optimizer.step()global_step += 1viz.line([loss.item()], [global_step], win='train_loss', update='append')if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item()pred = logits.argmax(dim=1)correct += pred.eq(target).float().sum().item()viz.line([[test_loss, correct / len(test_loader.dataset)]],[global_step], win='test', update='append')viz.images(data.view(-1, 1, 28, 28), win='x')viz.text(str(pred.detach().cpu().numpy()), win='pred',opts=dict(title='pred'))test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))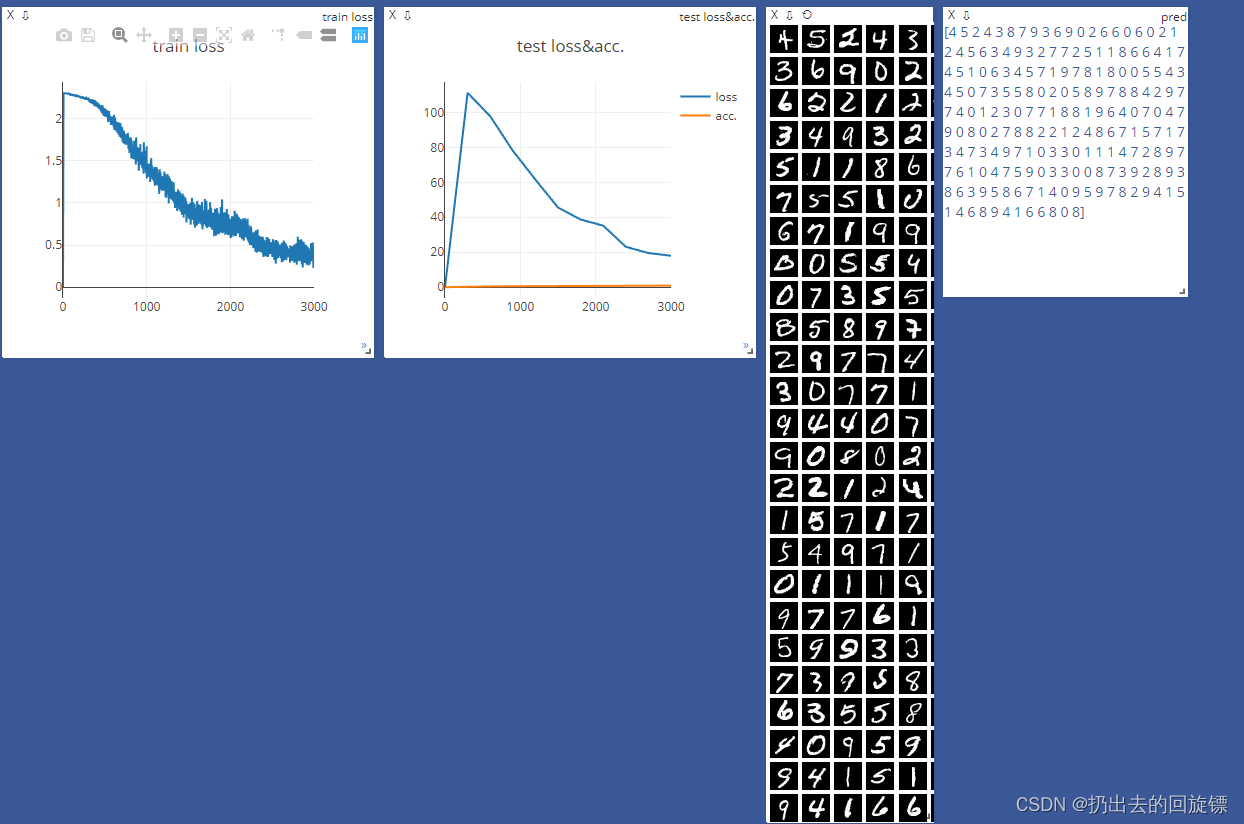
相关文章:
ccc-pytorch-小实验合集(4)
文章目录一、 Himmelblau 优化二、多分类实战-Mnist三、Sequential与CPU加速-Mnist四、visidom可视化一、 Himmelblau 优化 Himmelblau 是一个具有4个最优值的2维目标函数。其函数和最优值点如下: 图象绘制: import numpy as np from matplotlib impo…...

webrtc音频系列——4、RTP与RTCP协议
如果让你从0开发一套实时互动直播系统,你首先要选择网络传输协议。UDP 还是 TCP?答案是:UDP。为什么实时传输不能用 TCP ?TCP 的目的就是实现数据的可靠传输,因此他有一套 握手,发送 -> 确认,…...
)
C++枚举解读(enum)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、枚举是什么?二、使用步骤1.作用域2.隐式类型转换3.显式指定枚举值类型4.指定枚举值的值4.整形显式转换成枚举总结前言 对于开发C来说࿰…...
)
OSCP-课外5(Web图片泄露服务信息、日志中毒)
目录 一、主机发现与端口扫描 二、Web信息收集 三、系统信息收集与提权 一、主机发现与端口扫描...
汇编指令学习(ADD,SUB,MUL,DIV,XADD,INC,DEC,NEG)
一、ADD加法操作指令将eax置1,ebx置2,运行下面命令,将结果保存到eaxadd eax,ebx扩展:adc需要再加上CF标志位的值adc eax,ebx二、SUB减法操作指令将eax置3,ebx置2,运行下面命令,将结果…...

【电源专题】案例:充电芯片损坏为什么判断是从NTC进入的EOS
最近有发现一个异常就是测试部测试测试然后充电芯片就无法使用了。通过二极管特性分析(参考文章:电源专题】案例:电源芯片厂家怎么判断电源芯片端口是否损坏)是NTC管脚已经损坏对地短路了。但是以前没有发现这个问题,最近更换了芯片后就发现的特别明显。 首先分析一下现在…...

C语言中的数据储存规则
写在开头 关于复习的相关内容其实从一开始就列出了大纲,但是迟迟没有开始复习,一方面是因为学校学业却是繁忙,另一方面还是内心对旧知识掌握不熟练需要再学一遍的畏惧和懒惰,但如今,复习必须开始了。今天我从C语言的最…...
Android kotlin实战之协程suspend详解与使用
前言 Kotlin 是一门仅在标准库中提供最基本底层 API 以便各种其他库能够利用协程的语言。与许多其他具有类似功能的语言不同,async 与 await 在 Kotlin 中并不是关键字,甚至都不是标准库的一部分。此外,Kotlin 的 挂起函数 概念为异步操作提供…...

Pycharm中的Virtualenv Environment、Conda Environment
版本一 Conda Environment该不该选? 先说结论,该选,而且还是正解。前提是你打算"用Anaconda来管理各种Python环境,同时管理Python下面的各种包"。 选了Conda Environment意味着什么? 意味着你以后如果要装新的包的话…...

C++容器介绍:vector
目录vector简介使用方法1.头文件2.vector声明及初始化3.vector基本操作(1). 容量(2). 修改(3)迭代器(4)元素的访问(5)算法vector 简介 vector是表示可变大小数组的序列容器。就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vecto…...
抗锯齿和走样(笔记)
Artifacts(瑕疵): 比如人眼采样频率跟不上陀螺的旋转速度,这时就有可能看到陀螺在反方向旋转怎么做抗锯齿(滤波): 在采样之前先进行一个模糊操作,可以降低锯齿的明显程度 通过傅里叶…...
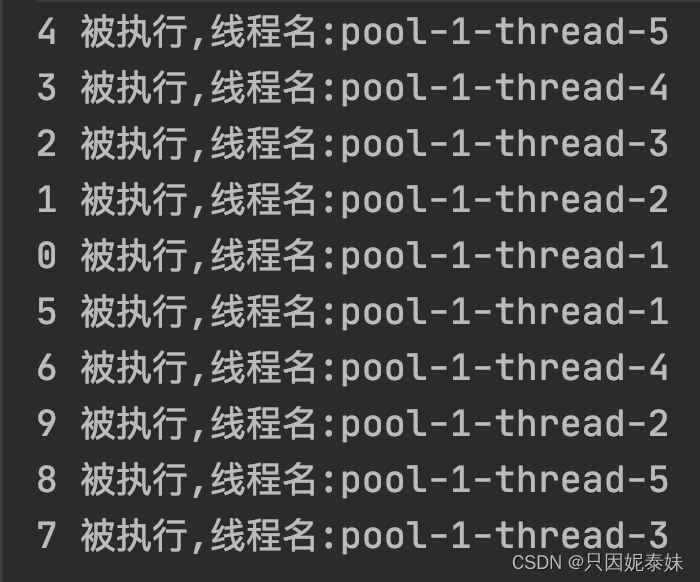
线程池的使用——线程池的创建方式
线程池的使用——创建线程线程池的创建线程池的创建方式Executors.newFixedThreadPool:Executors.newCachedThreadPool:Executors.newSingleThreadExecutor:Executors.newScheduledThreadPool:Executors.newSingleThreadScheduled…...
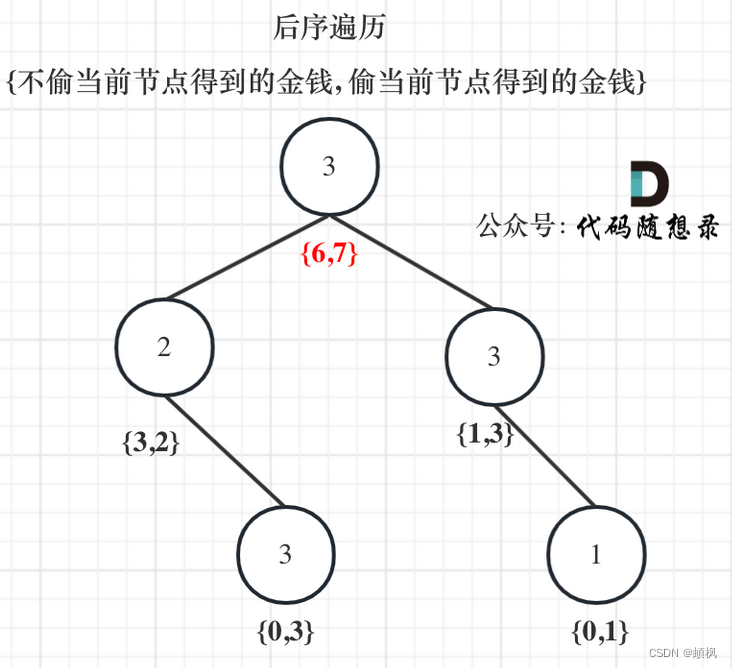
代码随想录算法训练营day47 |动态规划 198打家劫舍 213打家劫舍II 337打家劫舍III
day47198.打家劫舍1.确定dp数组(dp table)以及下标的含义2.确定递推公式3.dp数组如何初始化4.确定遍历顺序5.举例推导dp数组213.打家劫舍II情况一:考虑不包含首尾元素情况二:考虑包含首元素,不包含尾元素情况三&#x…...
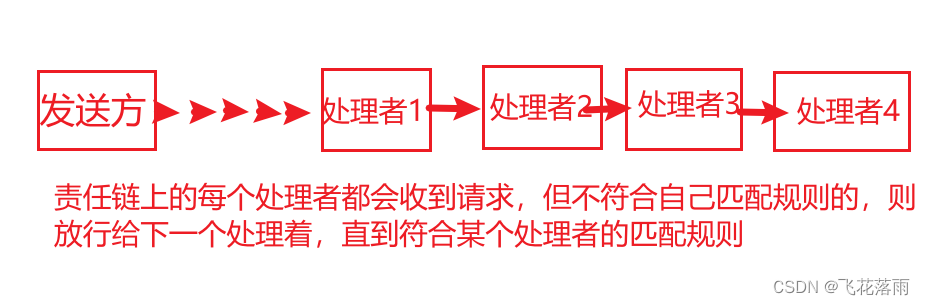
项目设计模式和规范
1、责任链模式 自己的理解:避免发生方与接收方解耦 优点:①降低发送方与接收方的耦合 ②简化他们对象 ③方便扩展新增 处理者 缺点:①不方便排错 ②性能问题,且使用不当容易搞出死循环 应用场景:拦截器 Interceptor和过滤器 filter:符合模式的进行拦截或者过滤到,然…...

无线WiFi安全渗透与攻防(一)之无线安全环境搭建
无线安全环境搭建 1.802.11标准 (1).概念 802.11标准是1997年IEEE最初制定的一个WLAN标准,工作在2.4GHz开放频段,支持1Mbit/s和2Mbit/s的数据传输速率,定义了物理层和MAC层规范,允许无线局域网及无线设备…...
【matplotlib】可视化解决方案——如何解决matplotlib中文乱码问题
问题概述 Matplotlib 默认不支持中文字体,这是因为 matplotlib 只支持 ASCII 字符,但是国人使用 matplotlib 肯定需要中文标注。如下图所示,当不对 Matplotlib 进行设置,而直接使用中文时,绘制的图像会出现中文乱码。…...
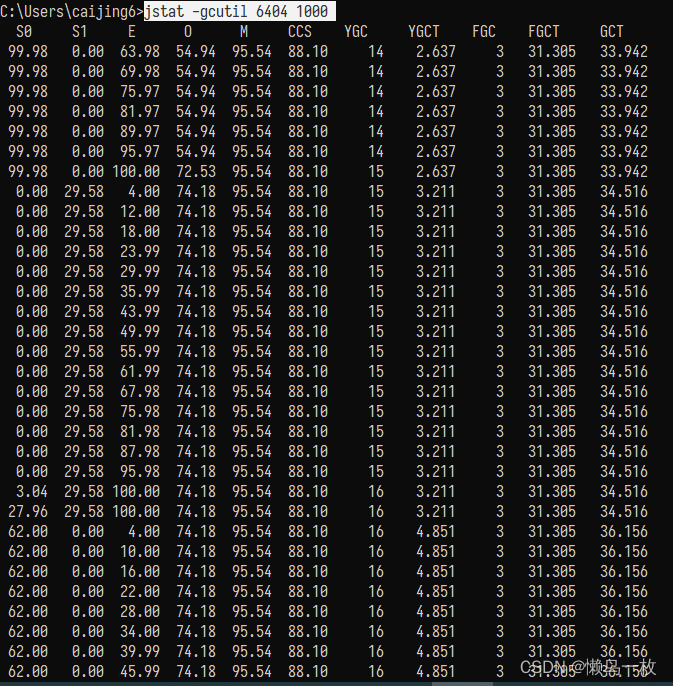
JAVA开发中GC日志打印简单通用的配置详解
如何配置一个完美的JVM日志打印信息 打印内容 打印基本的GC信息 打印对象分布情况 GC后打印堆数据 打印STW时间 打印safepoint信息 打印Reference处理信息 综上所述,最终的参数如下: 还有哪些问题呢?是不是有文件输出更好? 打印日…...

十进制的小数如何转二进制?二进制表示的小数如何转十进制?
😄 基础不牢,地动山摇~ 补补基础~ 文章目录 1、十进制的小数转二进制?2、二进制表示的小数转十进制?3、做道coding题巩固下:1、十进制的小数转二进制? 整数部分: 用普通的二进制表示即可。小数部分: 首先,将小数部分乘以2,取出整数部分作为二进制表示的第1位;然后…...
klipper使用webcam设置多个摄像头方式
一、前言 使用klipper设置多个摄像头,折腾了好些天,网上资料很少,这里写一个帖子记录一下 二、环境 参考链接:https://www.cnblogs.com/sjqlwy/p/klipper_webcam.html 我的klipper安装在香橙派上面,系统是debian&a…...

风力发电机组浪涌保护器安全防护方案
风机的庞大与危险高空作业注定了其在基建和维护中不易操作,风机设备的主电源、过程控制、网络与通讯、现场设备需要高等级的防雷浪涌保护器冲击保护,提高系统及设备的可靠性和可用性。风电场的主要发电设备风力发电机组“大风车”是风电场的主要发电设备…...

猫抓Cat-Catch终极指南:5分钟掌握浏览器资源嗅探与视频下载
猫抓Cat-Catch终极指南:5分钟掌握浏览器资源嗅探与视频下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓Cat-Catch是一款完全免…...

特斯拉Model 3/Y CAN总线DBC文件:3步掌握汽车数据解析的终极指南
特斯拉Model 3/Y CAN总线DBC文件:3步掌握汽车数据解析的终极指南 【免费下载链接】model3dbc DBC file for Tesla Model 3 CAN messages 项目地址: https://gitcode.com/gh_mirrors/mo/model3dbc 特斯拉Model 3/Y的CAN总线通讯协议是汽车电子开发者和技术爱好…...

AI编程助手集成Codex CLI:MCP协议实现智能代码分析与本地模型部署
1. 项目概述:连接AI与代码的智能桥梁 如果你和我一样,日常开发中频繁使用 Claude 或 Cursor 这类AI编程助手,同时又深度依赖 OpenAI Codex CLI 进行代码分析和重构,那么你很可能面临一个效率瓶颈:如何在不同的工具之间…...

AI协同开发新范式:基于规范驱动的Agentic Workflows实践
1. 项目概述:告别碎片化,用“活的”规范驱动AI协同开发如果你和我一样,每天都在跟Claude Code、Cursor这类AI编程工具打交道,那你肯定也经历过这种痛苦:想实现一个复杂功能,得先花十几分钟给AI解释一遍项目…...
安装新选择:用MIM一键搞定环境,告别繁琐编译)
OpenMMLab全家桶(mmdet+mmcv)安装新选择:用MIM一键搞定环境,告别繁琐编译
OpenMMLab全家桶环境配置革命:MIM工具全指南与避坑实践 刚接触OpenMMLab生态时,我被mmdetection和mmcv的安装过程折磨得够呛——CUDA版本冲突、PyTorch兼容性问题、漫长的编译等待…直到发现官方推出的MIM工具,才意识到原来环境配置可以如此优…...

Hermes Agent 云端部署实战:从零到一在 DigitalOcean 上构建 24/7 智能体服务
1. 项目概述与核心价值如果你正在构建一个基于 Claude Code 或 agent-skills 的智能体,并且希望它能像一台永不关机的服务器一样,7x24小时在线,随时响应你的指令,那么将 Hermes Agent 部署到云端虚拟服务器(VPS&#x…...

Godot引擎官方文档:开源协作、架构解析与高效使用指南
1. 项目概述:一份开源游戏引擎的“官方说明书”如果你正在使用或者考虑使用 Godot 引擎来开发你的下一款游戏,那么你迟早会与一个名为godotengine/godot-docs的仓库打交道。这不仅仅是 Godot 的官方文档,它更像是一本由全球开发者共同维护、持…...

Davinci Resolve/达芬奇 21安装教程及下载
软件介绍: DaVinci Resolve Studio 是一款世界上第一个结合了专业离线和在线编辑,色彩校正,音频后期制作和Fusion视觉特效于一体的软件工具的解决方案!你可以获得无限的创作灵活性,因为 DaVinci Resolve 让个体艺术家更容易探索不…...

AI辅助编程中无障碍检查的实践:从设计到代码的内置思维
1. 项目概述:在设计与构建阶段内嵌的无障碍检查思维作为一名长期在Web前端和交互设计领域摸爬滚打的从业者,我见过太多项目在临近上线甚至上线之后,才被测试或用户反馈“这个按钮读屏软件读不出来”、“键盘没法操作这个弹窗”。这时候再回头…...
)
【C++模板】:开启泛型编程之门(函数模版,类模板)
1. 函数模板概念与格式函数模板就像一个函数家族的蓝图,该函数模板与类型无关,在使用时被参数化,编译器根据实参类型产生函数的特定类型版本。其格式如下:代码语言:javascriptAI代码解释template<typename T1, type…...