深度学习中的池化
1 深度学习池化概述
1.1 什么是池化
池化层是卷积神经网络中常用的一个组件,池化层经常用在卷积层后边,通过池化来降低卷积层输出的特征向量,避免出现过拟合的情况。池化的基本思想就是对不同位置的特征进行聚合统计。池化层主要是模仿人的视觉系统对数据进行降维,用更高层次的特征表示图像。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。
池化操作的基本思想是将特征图划分为若干个子区域(一般为矩形),并对每个子区域进行统计汇总。池化操作的方式可以有很多种,比如最大池化(Max Pooling)、平均池化(Average Pooling)等。其中,最大池化操作会选取每个子区域内的最大值作为输出,而平均池化操作则会计算每个子区域内的平均值作为输出。
1.2 池化的作用
理论上来说,网络可以在不对原始输入图像执行降采样的操作,通过堆叠多个的卷积层来构建深度神经网络,如此一来便可以在保留更多空间细节信息的同时提取到更具有判别力的抽象特征。然而,考虑到计算机的算力瓶颈,通常都会引入池化层,来进一步地降低网络整体的计算代价,这是引入池化层最根本的目的。
池化层大大降低了网络模型参数和计算成本,也在一定程度上降低了网络过拟合的风险。概括来说,池化层主要有以下五点作用:
-
增大网络感受野
-
抑制噪声,降低信息冗余
-
降低模型计算量,降低网络优化难度,防止网络过拟合
-
使模型对输入图像中的特征位置变化更加鲁棒
1.3 池化核大小
池化窗口的大小,在PyTorch里池化核大小可以是一个整数或者一个元组,例如 kernel_size=2 或者 kernel_size=(2, 3)。
- 如果是一个整数,则表示高和宽方向上的池化窗口大小相同;
- 如果是一个元组,则第一个元素表示高方向上的池化窗口大小,第二个元素表示宽方向上的池化窗口大小。
1.4 步幅大小
用于指定池化窗口在高和宽方向上的步幅大小,可以是一个整数或者一个元组,例如 stride=2 或者 stride=(2, 3)。
- 如果是一个整数,则表示高和宽方向上的步幅大小相同;
- 如果是一个元组,则第一个元素表示高方向上的步幅大小,第二个元素表示宽方向上的步幅大小。
1.5 填充
池化层的填充(padding)可以控制池化操作在特征图边缘的行为,使得池化后的输出特征图与输入特征图大小相同或相近。
在池化操作时,如果输入特征图的尺寸不能被池化窗口的大小整除,那么最后一列或者最后一行的部分像素就无法被包含在池化窗口中进行池化,因此池化后的输出特征图尺寸会减小。
通过在输入特征图的边缘添加填充,可以使得池化操作在边缘像素处进行池化,避免了信息的丢失,并且保持了输出特征图的大小与输入特征图相同或相近。同时,填充也可以增加模型的稳定性,减少过拟合的风险。
需要注意的是,池化层的填充和卷积层的填充有所不同:
- 池化层的填充通常是指在输入特征图的边缘添加0值像素;
- 卷积层的填充是指在输入特征图的边缘添加0值像素或者复制边缘像素。
PyTorch里的填充大小可以是一个整数或者一个元组,例如 padding=1 或者 padding=(1, 2)。
- 如果是一个整数,则表示在高和宽方向上的填充大小相同;
- 如果是一个元组,则第一个元素表示高方向上的填充大小,第二个元素表示宽方向上的填充大小。默认为 0,表示不进行填充。
2 pytorch中的池化详解
2.1 Max Pooling(最大池化)
2.1.1 定义
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。其定义如下:

最大池化就是选取图像区域中的最大值作为该区域池化后的值。在前向传播过程中,选择图像区域中的最大值作为该区域池化后的值;在反向传播过程中,梯度通过前向传播过程时的最大值反向传播,其他位置的梯度为0。如下图所示,采用22的filters,步长stride=2,在原特征图44中提取特征得到右图2*2。

最大值池化的优点在于它能学习到图像的边缘和纹理结构。
对于最大池化,在前向传播计算时,是选取的每个区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其余位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置。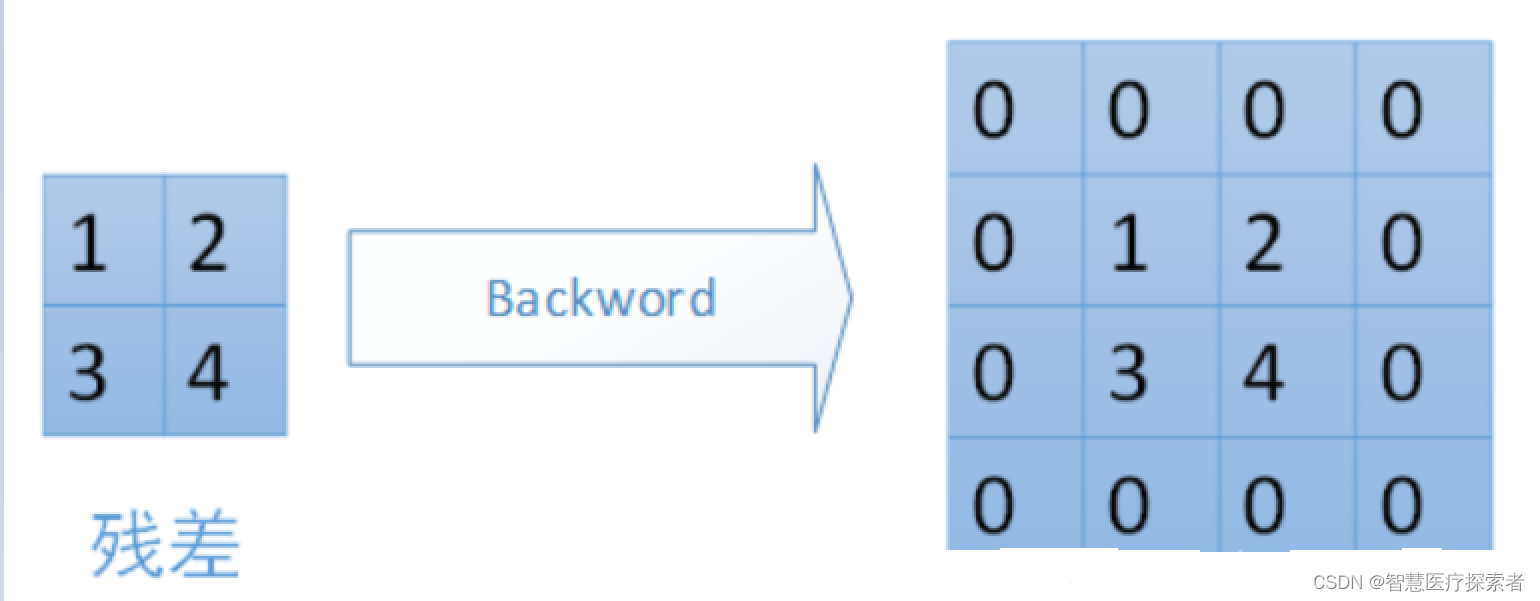
2.1.2 pytorch中的最大池化
PyTorch中的最大池化函数:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
-
kernel_size (int or tuple)【必选】:max pooling 的窗口大小,当最大池化窗口是方形的时候,只需要一个整数边长即可;最大池化窗口不是方形时,要输入一个元组表 高和宽。
-
stride (int or tuple, optional)【可选】:max pooling 的窗口移动的步长。默认值是 kernel_size
-
padding (int or tuple, optional)【可选】:输入的每一条边补充0的层数
-
dilation (int or tuple, optional)【可选】:一个控制窗口中元素步幅的参数
-
return_indices (bool)【可选】:如果等于 True,会返回输出最大值的序号,对于上采样操作会有帮助
-
ceil_mode (bool)【可选】:如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
torch.nn.MaxPool2d 和 torch.nn.functional.max_pool2d,在 pytorch 构建模型中,都可以作为最大池化层的引入,但前者为类模块,后者为函数,在使用上存在不同。
torch.nn.functional.max_pool2d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False
)2.1.3 使用示例
- 张量池化
import torch# 定义输入数据张量,大小为 (batch_size, channels, height, width)
input_tensor = torch.randn(2, 3, 16, 16)# 定义最大池化层,kernel_size 为池化核大小,stride 为步幅
max_pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)# 对输入数据进行最大池化操作
output_tensor = max_pool(input_tensor)# 输出池化前后的结果张量大小
print("input_tensor:", input_tensor.shape)
print("output_tensor:", output_tensor.shape)运行结果显示:
input_tensor: torch.Size([2, 3, 16, 16])
output_tensor: torch.Size([2, 3, 8, 8])输入大小为 (2,3,16,16)的张量, 然后定义了一个最大池化层,池化操作以后,
最后输出的张量大小是: torch.Size([2, 3, 8, 8])
- 图片池化
import torch
from PIL import Image
from torchvision.transforms import ToTensor
from torchvision.transforms.functional import to_pil_image
import matplotlib.pyplot as plt# 读入示例图片并将其转换为 PyTorch 张量
img = Image.open('./data/lena.jpeg')
img_tensor = ToTensor()(img)# 定义 MaxPool2d 函数,进行池化操作
max_pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
img_pool = max_pool(img_tensor.unsqueeze(0)).squeeze(0)# 将池化后的张量转换为 PIL 图像并保存
img_pool_pil = to_pil_image(img_pool)plt.subplot(121)
plt.imshow(img)
plt.title('original')
plt.axis('off')
plt.subplot(122)
plt.imshow(img_pool_pil)
plt.title('pool')
plt.axis('off')
plt.show()运行结果显示:

2.1.4 总结
对于最大池化操作,只选择每个矩形区域中的最大值进入下一层,而其他元素将不会进入下一层。所以最大池化提取特征图中响应最强烈的部分进入下一层,这种方式摒弃了网络中大量的冗余信息,使得网络更容易被优化。同时这种操作方式也常常丢失了一些特征图中的细节信息,所以最大池化更多保留些图像的纹理信息。
2.2 Average Pooling(平均池化)
2.2.1 定义
平均池化(Average Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出所有元素的平均值。其定义如下:

平均池化就是计算图像区域的平均值作为该区域池化后的值,Resnet网络结构后一般会使用平均池化。
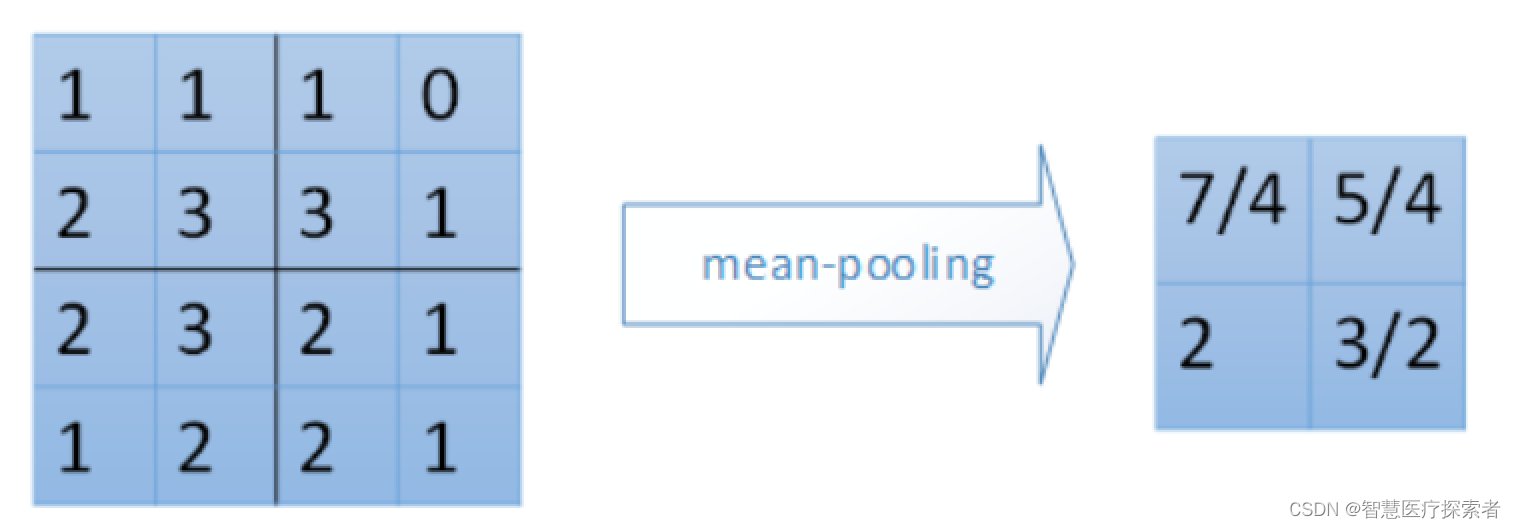
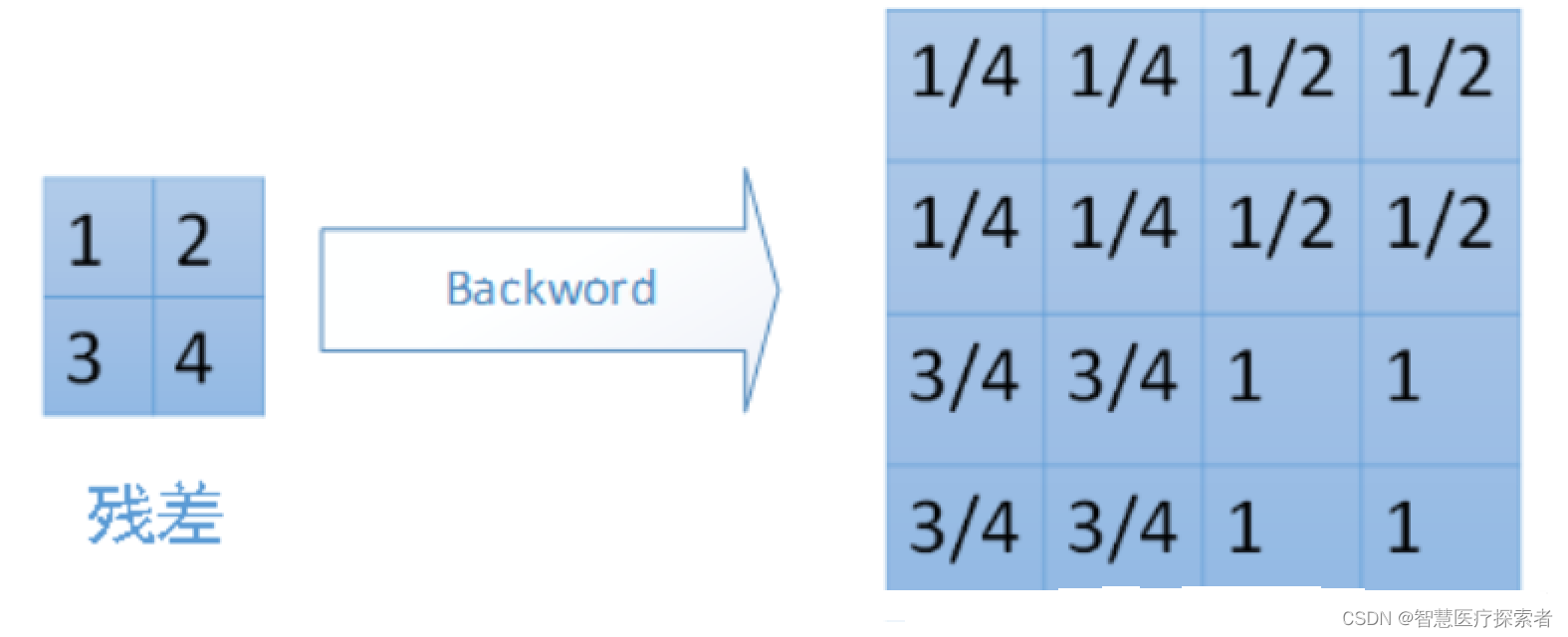
对于平均池化,我们需要把残差平分,传递到前边小区域的n个单元即可,不需要记录下元素在每个小区域中的位置。平均池化比较容易让人理解错的地方就是会简单的认为直接把梯度复制N遍之后直接反向传播回去,但是这样会造成loss之和变为原来的N倍,网络是会产生梯度爆炸的。
2.2.2 pytorch中的平均池化
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)-
kernel_size:池化窗口的大小。可以是一个整数,表示正方形窗口的边长,也可以是一个元组,表示不同维度的窗口大小。例如,(2, 2)表示宽和高为2的正方形窗口。
-
stride:池化窗口的步幅。可以是一个整数,表示在所有维度上的步幅相同,也可以是一个元组,表示不同维度上的步幅。例如,(2, 2)表示在宽和高上的步幅为2。
-
padding:输入张量的填充大小。可以是一个整数,表示在所有维度上的填充大小相同,也可以是一个元组,表示不同维度上的填充大小。例如,(1, 1)表示在宽和高上的填充大小为1。
-
ceil_mode:是否采用向上取整的方式计算输出大小。如果为True,则输出大小会向上取整。默认为False。
-
count_include_pad:是否将填充值计算在内。如果为True,则会将填充值计算在内。默认为True。
-
divisor_override:用于覆盖默认的输出元素数。如果指定了该参数,则输出元素数将被覆盖为该值。默认为None。
2.2.3 使用示例
- 张量池化
import torch# 定义输入数据张量,大小为 (batch_size, channels, height, width)
input_tensor = torch.randn(2, 3, 16, 16)# 定义平均池化层,kernel_size 为池化核大小,stride 为步幅
avg_pool = torch.nn.AvgPool2d(kernel_size=2, stride=2)# 对输入数据进行平均池化操作
output_tensor = avg_pool(input_tensor)# 输出池化前后的结果张量大小
print("input_tensor:", input_tensor.shape)
print("output_tensor:", output_tensor.shape)运行结果显示:
input_tensor: torch.Size([2, 3, 16, 16])
output_tensor: torch.Size([2, 3, 8, 8])- 图片池化
import torch
from PIL import Image
from torchvision.transforms import ToTensor
from torchvision.transforms.functional import to_pil_image
import matplotlib.pyplot as plt# 读入示例图片并将其转换为 PyTorch 张量
img = Image.open('./data/lena.jpeg')
img_tensor = ToTensor()(img)# 定义 AvgPool2d 函数,进行池化操作
avg_pool = torch.nn.AvgPool2d(kernel_size=2, stride=2)
img_pool = avg_pool(img_tensor.unsqueeze(0)).squeeze(0)# 将池化后的张量转换为 PIL 图像并保存
img_pool_pil = to_pil_image(img_pool)plt.subplot(121)
plt.imshow(img)
plt.title('original')
plt.axis('off')
plt.subplot(122)
plt.imshow(img_pool_pil)
plt.title('pool')
plt.axis('off')
plt.show()
2.2.4 总结
平均池化取每个矩形区域中的平均值,可以提取特征图中所有特征的信息进入下一层,而不像最大池化只保留值最大的特征,所以平均池化可以更多保留些图像的背景信息。
2.3 Global Average Pooling(全局平均池化)
在卷积神经网络训练初期,卷积层通过池化层后一般要接多个全连接层进行降维,最后再Softmax分类,这种做法使得全连接层参数很多,降低了网络训练速度,且容易出现过拟合的情况。在这种背景下,M Lin等人提出使用全局平均池化Global Average Pooling[1]来取代最后的全连接层。用很小的计算代价实现了降维,更重要的是GAP极大减少了网络参数(CNN网络中全连接层占据了很大的参数)。
论文地址: https://arxiv.org/pdf/1312.4400.pdf
代码链接: https://worksheets.codalab.org/worksheets
2.3.1 定义
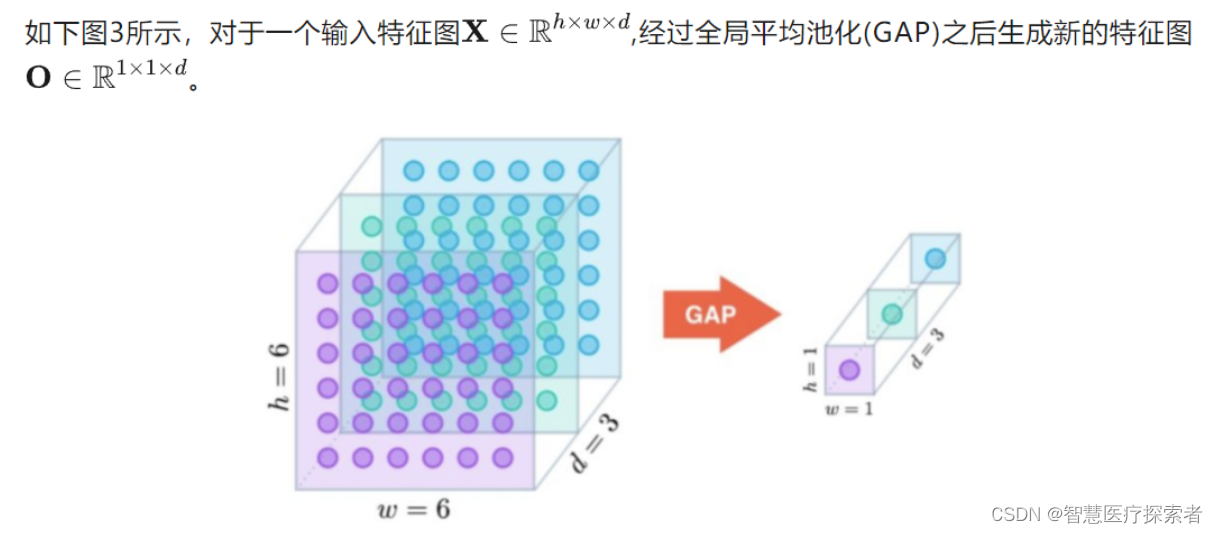
全局平均池化是一种特殊的平均池化,只不过它不划分若干矩形区域,而是将整个特征图中所有的元素取平均输出到下一层。其定义如下:

2.3.2 总结
作为全连接层的替代操作,GAP对整个网络在结构上做正则化防止过拟合,直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。除此之外,使用GAP代替全连接层,可以实现任意图像大小的输入,而GAP对整个特征图求平均值,也可以用来提取全局上下文信息,全局信息作为指导进一步增强网络性能。
2.4 Mix Pooling(混合池化)
论文地址: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.678.7068
2.4.1 定义
为了提高训练较大CNN模型的正则化性能,受Dropout(将一半激活函数随机设置为0)的启发,Dingjun Yu等人提出了一种随机池化Mix Pooling[2] 的方法,随机池化用随机过程代替了常规的确定性池化操作,在模型训练期间随机采用了最大池化和平均池化方法,并在一定程度上有助于防止网络过拟合现象。其定义如下:
2.4.2 总结
混合池化优于传统的最大池化和平均池化方法,并可以解决过拟合问题来提高分类精度。此外该方法所需要的计算开销可忽略不计,而无需任何超参数进行调整,可被广泛运用于CNN。
2.5 Stochastic Pooling(随机池化)
论文地址: https://arxiv.org/pdf/1301.3557
代码链接: https://github.com/szagoruyko/imagine-nn
2.5.1 定义
随机池化Stochastic Pooling[3] 是Zeiler等人于ICLR2013提出的一种池化操作。随机池化的计算过程如下:
先将方格中的元素同时除以它们的和sum,得到概率矩阵。
按照概率随机选中方格。
pooling得到的值就是方格位置的值。
假设特征图中Pooling区域元素值如下(参考Stochastic Pooling简单理解):
则这时候的poolng值为1.5。使用stochastic pooling时(即test过程),其推理过程也很简单,对矩阵区域求加权平均即可。比如对上面的例子求值过程为为:
说明此时对小矩形pooling后的结果为1.625。在反向传播求导时,只需保留前向传播已经记录被选中节点的位置的值,其它值都为0,这和max-pooling的反向传播非常类似。本小节参考Stochastic Pooling简单理解[4]。
2.5.2 总结
随机池化只需对特征图中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大,而不像max-pooling那样,永远只取那个最大值元素,这使得随机池化具有更强的泛化能力。
2.6 Power Average Pooling(幂平均池化)
论文地址: http://proceedings.mlr.press/v32/estrach14.pdf

2.7 Detail-Preserving Pooling(DPP池化)
论文地址: Saeedan_Detail-Preserving_Pooling_in_CVPR_2018_paper.pdf
代码链接: https://github.com/visinf/dpp
为了降低隐藏层的规模或数量,大多数CNN都会采用池化方式来减少参数数量,来改善某些失真的不变性并增加感受野的大小。由于池化本质上是一个有损的过程,所以每个这样的层都必须保留对网络可判别性最重要的部分进行激活。但普通的池化操作只是在特征图区域内进行简单的平均或最大池化来进行下采样过程,这对网络的精度有比较大的影响。基于以上几点,Faraz Saeedan等人提出一种自适应的池化方法-DPP池化Detail-Preserving Pooling[6],该池化可以放大空间变化并保留重要的图像结构细节,且其内部的参数可通过反向传播加以学习。DPP池化主要受**Detail-Preserving Image Downscaling[7]**的启发。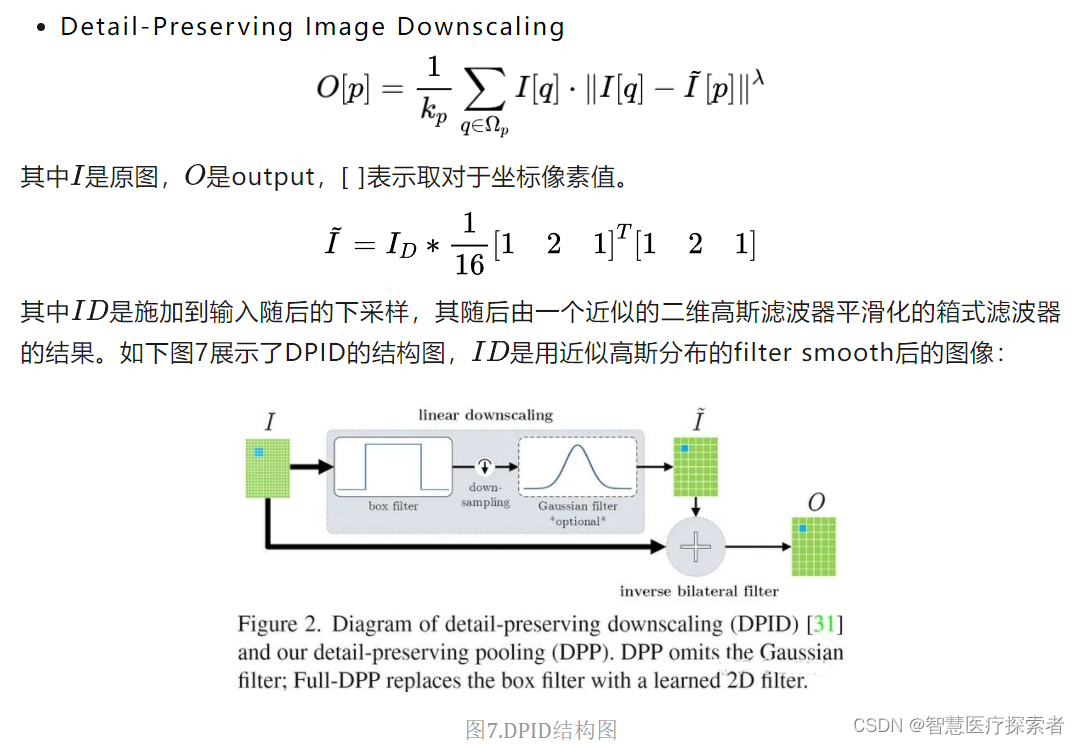
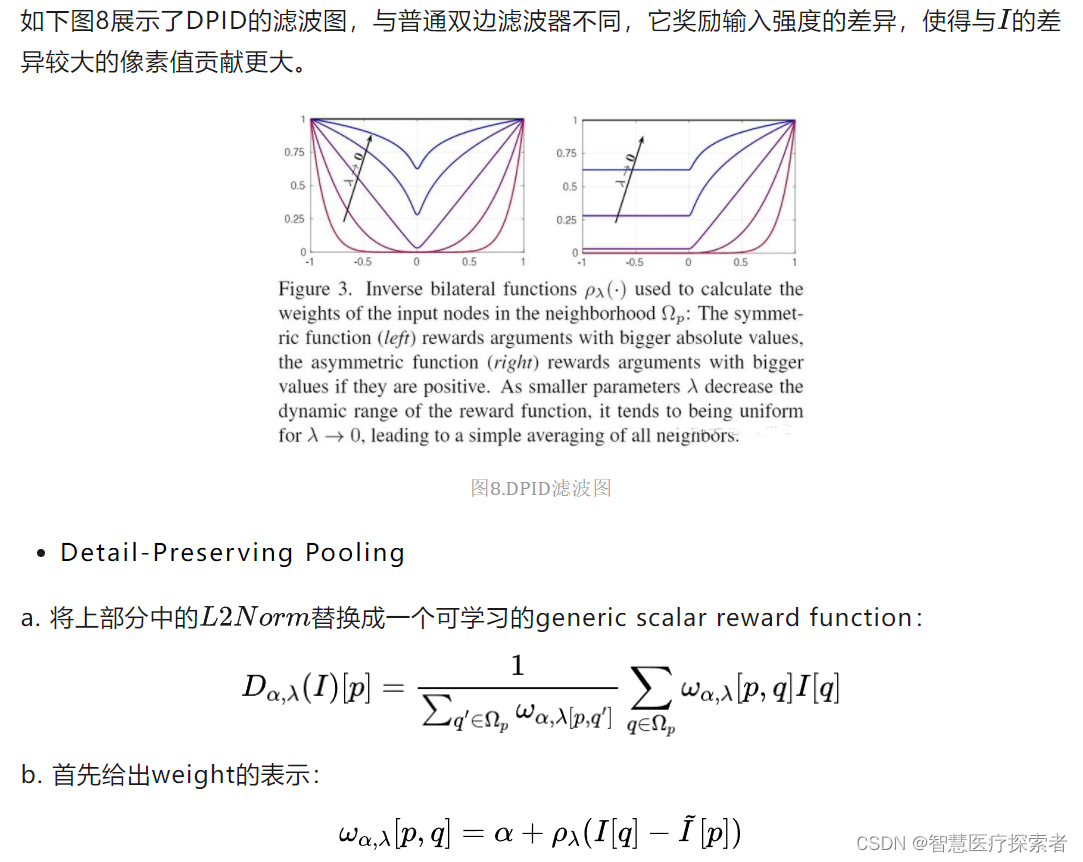
DPP池化允许缩减规模以专注于重要的结构细节,可学习的参数控制着细节的保存量,此外,由于细节保存和规范化相互补充,DPP可以与随机合并方法结合使用,以进一步提高准确率。
2.8 Local Importance Pooling(局部重要性池化)
论文地址: Gao_LIP_Local_Importance-Based_Pooling_ICCV_2019_paper.pdf
代码链接: https://github.com/sebgao/LIP
CNN通常使用空间下采样层来缩小特征图,以实现更大的接受场和更少的内存消耗,但对于某些任务而言,这些层可能由于不合适的池化策略而丢失一些重要细节,最终损失模型精度。为此,作者从局部重要性的角度提出了局部重要性池化Local Importance Pooling[8],通过基于输入学习自适应重要性权重,LIP可以在下采样过程中自动增加特征判别功能。
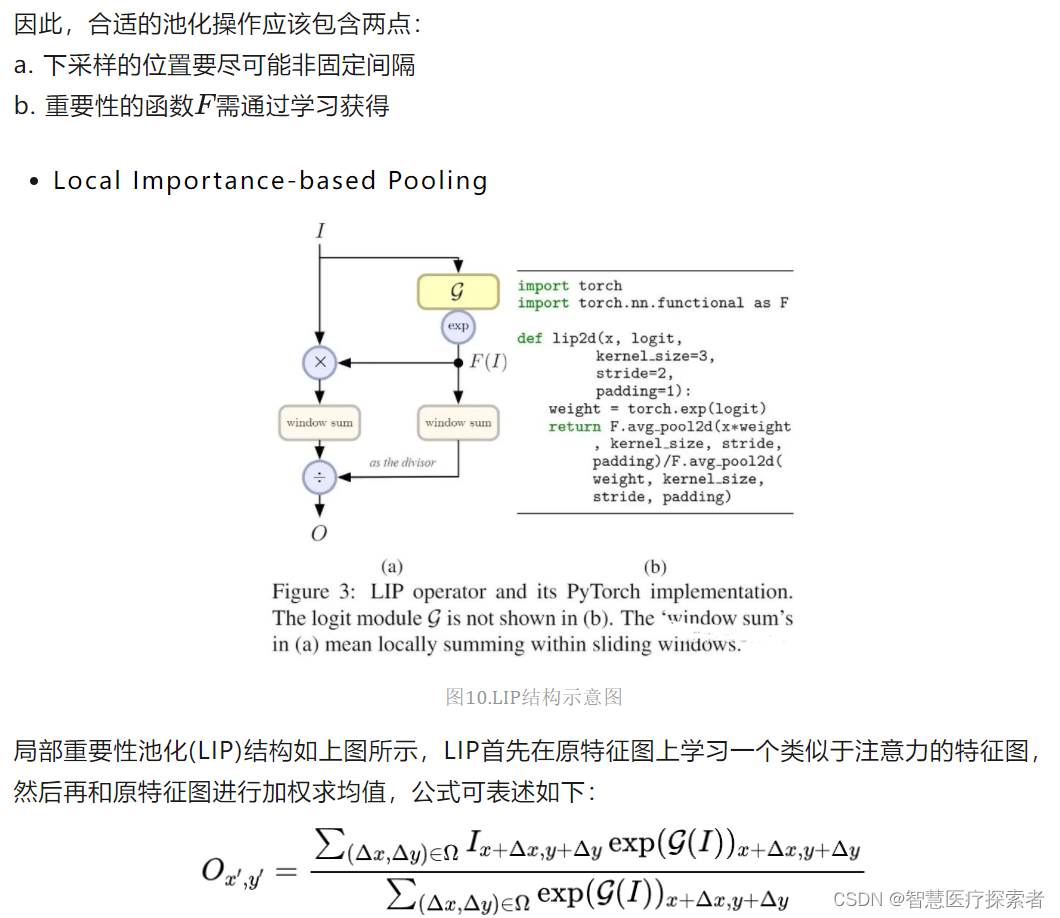

Local Importance Pooling可以学习自适应和可判别性的特征图以汇总下采样特征,同时丢弃无信息特征。这种池化机制能极大保留物体大部分细节,对于一些细节信息异常丰富的任务至关重要。
2.9 Soft Pooling(软池化)
论文地址: https://arxiv.org/pdf/2101.00440
代码链接: https://github.com/alexandrosstergiou/SoftPool
现有的一些池化方法大都基于最大池化和平均池化的不同组合,而软池化Soft Pooling[9] 是基于softmax加权的方法来保留输入的基本属性,同时放大更大强度的特征激活。与maxpooling不同,softpool是可微的,所以网络在反向传播过程中为每个输入获得一个梯度,这有利于提高训练效果。
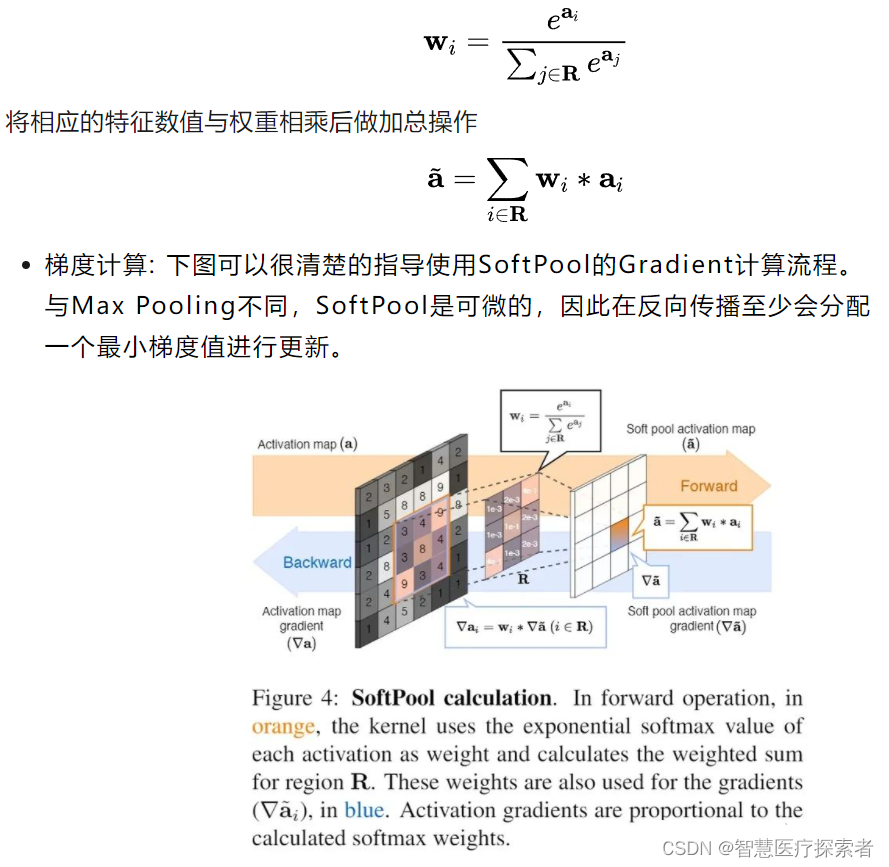
SoftPool的计算流程如下:
- a. 特征图透过滑动视窗来框选局部数值
- b. 框选的局部数值会先经过指数计算,计算出的值为对应的特征数值的权重
- c. 将各自的特征数值与其相对应的权重相乘
- d. 最后进行加总

这样的方式让整体的局部数值都有所贡献,重要的特征占有较高的权重。比Max pooling(直接选择最大值)、Average pooling (求平均,降低整个局部的特征强度) 能够保留更多讯息。
SoftPool的数学定义如下:
计算特征数值的权重,其中R为框选的局部区域,a为特征数值
作为一种新颖地池化方法,SoftPool可以在保持池化层功能的同时尽可能减少池化过程中带来的信息损失,更好地保留信息特征并因此改善CNN中的分类性能。大量的实验结果表明该算法的性能优于原始的Avg池化与Max池化。随着神经网络的设计变得越来越困难,而通过NAS等方法也几乎不能大幅度提升算法的性能,为了打破这个瓶颈,从基础的网络层优化入手,不失为一种可靠有效的精度提升手段。
相关文章:
深度学习中的池化
1 深度学习池化概述 1.1 什么是池化 池化层是卷积神经网络中常用的一个组件,池化层经常用在卷积层后边,通过池化来降低卷积层输出的特征向量,避免出现过拟合的情况。池化的基本思想就是对不同位置的特征进行聚合统计。池化层主要是模仿人的…...

Java面试整理-Java设计模式
Java中的设计模式通常是从更广泛的面向对象设计模式中借鉴而来的,这些模式旨在解决特定的设计问题和改善代码的可维护性、灵活性和可扩展性。设计模式大致可以分为三类:创建型、结构型和行为型。以下是这三类中一些常见的设计模式: 创建型模式 单例模式(Singleton):确保一…...

用CHAT了解更多知识点
问CHAT:什么是硅基生命和碳基生命? CHAT回复:硅基生命和碳基生命是两种理论性的生物体类型,这些生物体主要是由硅或碳元素以及其他元素构成的。 碳基生命是我们当前所熟知的生命形式。碳元素能够形成稳定且复杂的分子,…...
一个利用摸鱼时间背单词的软件
大家好,我是 Java陈序员。 最近进入了考试季,各种考试,英语四六级、考研、期末考等。不知道大家的英语四六级成绩怎么样呢? 记得大学时,英语四级都是靠高中学习积累的老本才勉强过关。 而六级则是考了多次ÿ…...
Matlab/Simulink的一些功能用法笔记(3)
01--引言 最近加入到一个项目组,有一些测试需要去支持,通过了解原先团队的测试方法后,自己作了如下改善,大大提高了工作效率。这也许就是软件开发的意义吧,能够去除一些重复的机械的人工操作并且结果还非常不可靠。 …...

Wafer晶圆封装工艺介绍
芯片封装的目的(The purpose of chip packaging): 芯片上的IC管芯被切割以进行管芯间连接,通过引线键合连接外部引脚,然后进行成型,以保护电子封装器件免受环境污染(水分、温度、污染物等)&…...

Mac OS 13+,Apple Silicon,删除OBS虚拟摄像头(virtual camera),
原文链接: https://www.reddit.com/r/MacOS/comments/142cv OBS为了捕获摄像头视频,将虚拟摄像头插件内置为系统插件了.如下 直接删除没有权限的,要删除他,在mac os 13以后,需要关闭先关闭苹果系统的完整性保护(SIP) Apple 芯片(M1,....)的恢复模式分为两种,回退恢复模式,和…...

精解 ES6 Promise 用法
🐱 个人主页:SHOW科技,公众号:SHOW科技 🙋♂️ 作者简介:2020参加工作,专注于前端各领域技术,共同学习共同进步,一起加油呀! 💫优质专栏&#x…...
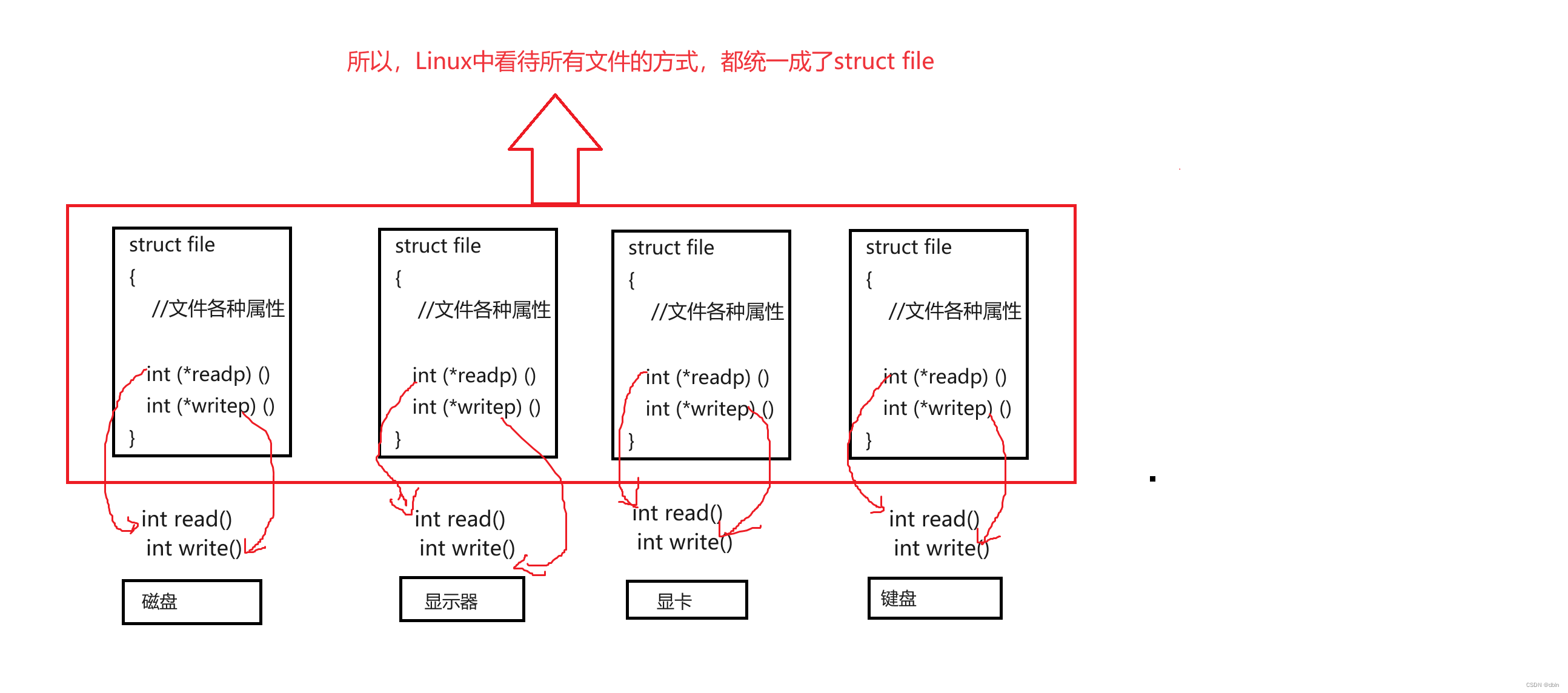
Linux之基础I/O
目录 一、C语言中的文件操作 二、系统文件操作I/O 三、文件描述符fd 1、文件描述符的引入 2、对fd的理解 3、文件描述符的分配规则 四、重定向 1、重定向的原理 2、重定向的系统调用dup2 五、Linux下一切皆文件 一、C语言中的文件操作 1、打开和关闭 在C语言的文…...

Linux开发工具——gcc篇
gcc的使用 文章目录 gcc的使用 历史遗留问题(普通用户sudo) gcc编译过程 预处理(进行宏替换) 编译(生成汇编) 汇编(生成机器可识别代码) 链接(生成可执行文件或库文件&a…...

C#通讯——关于Winform中的简单的Http服务器与客户端
C#通讯——关于Winform中的简单的Http服务器与客户端 前言一、Http是什么?二、简单的Http服务器三、简单的Http客户端四、实际调用五、Winform中Http服务器和WebApi的区别? 前言 在实际项目中通讯的交互的过程中,遇见数据传输时同事和我说用…...

Mendelson AS2 介绍下载和配置
最近与一家国外公司做EDI对接,并且EDI通讯工具是基于AS2协议的。目前开源的as2的开源项目有openas2,Mendelson AS2,和国人写的freeas2但是,现在freeas2已经被从开源中国不能下载了,变为收费的版本了。 如果你需要使用基于AS2协议…...

旅游海报图怎么做二维码展示?扫码即可查看图片
现在旅游攻略的海报可以做成二维码印刷在宣传单单页或者分享给用户来了解目的地的实际情况,出行路线、宣传海报等。用户只需要扫描二维码就可以查看内容,更加的方便省劲,那么旅游海报的图片二维码制作的技巧有哪些呢?使用图片二维…...

常用git指令
初始化Git仓库:git init 添加文件到暂存区:git add <file> 提交更改到本地仓库:git commit -m "commit message" 查看本地仓库的提交历史:git log 创建分支:git branch <branch_name> 切换分支:git checkout <branch_name> 查看所有分支:git…...

【FPGA】分享一些FPGA协同MATLAB开发的书籍
在做FPGA工程师的这些年,买过好多书,也看过好多书,分享一下。 后续会慢慢的补充书评。 【FPGA】分享一些FPGA入门学习的书籍【FPGA】分享一些FPGA协同MATLAB开发的书籍 【FPGA】分享一些FPGA视频图像处理相关的书籍 【FPGA】分享一些FPGA高速…...

幺模矩阵-线性规划的整数解特性
百度百科:幺模矩阵 在线性规划问题中,如果A为幺模矩阵,那么该问题具有最优整数解特性。也就是说使用单纯形法进行求解,得到的解即为整数解。无需再特定使用整数规划方法。 m i n c T x s . t . { A x ≥ b x ≥ 0 \begin{align*} min \quad…...

数据分析思维
Why&What 数据分析是为了驱动决策赋能业务。在数据分析过程中需要对目标进行拆解量化,如何拆解量化目标便是数据分析思维。 在任务拆解过程中使用的软件、统计模型、分析方法等为分析工具和手段,如何在恰当的场景合理的使用这些工具、模型、方法、手…...
C++ boost planner_cond_.wait(lock) 报错1225
1.如下程序段 boost unique_lock doesn’t own the mutex: Operation not permitted 问题: 其中makePlan是一个线程。这里的unlock导致错误这个报错 boost unique_lock doesn’t own the mutex: Operation not permitted bool navigation::makePlan(){ //cv::named…...
LeetCode刷题--- 字母大小写全排列
个人主页:元清加油_【C】,【C语言】,【数据结构与算法】-CSDN博客 个人专栏 力扣递归算法题 http://t.csdnimg.cn/yUl2I 【C】 http://t.csdnimg.cn/6AbpV 数据结构与算法 http://t.csdnimg.cn/hKh2l 前言:这个专栏主要讲述递归递归、搜索与回…...
)
165. 小猫爬山(DFS之剪枝与优化)
165. 小猫爬山 - AcWing题库 翰翰和达达饲养了 N 只小猫,这天,小猫们要去爬山。 经历了千辛万苦,小猫们终于爬上了山顶,但是疲倦的它们再也不想徒步走下山了(呜咕>_<)。 翰翰和达达只好花钱让它们…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...