Hadoop入门学习笔记——五、在虚拟机中部署Hive
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 五、在虚拟机中部署Hive
- 5.1. 在node1虚拟机安装MySQL
- 5.2. 配置Hadoop
- 5.3. 下载并加压Hive
- 5.4. 下载MySQL驱动包
- 5.5. 配置Hive
- 5.6. 初始化元数据库
- 5.7. 使用hadoop用户身份启动Hive
五、在虚拟机中部署Hive
Hive是单机工具,只需要部署在一台服务器即可。
Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
本次部署服务清单:
| 服务 | 部署节点 |
|---|---|
| Hive服务 | node1 |
| 元数据服务所需的关系型数据库(本次选择MySQL) | node1 |
5.1. 在node1虚拟机安装MySQL
本次安装的是MySQL 5.7 社区版。
以root用户身份,在node1虚拟机分别执行以下命令:
# 更新rpm中MySQL相关仓库的密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022# 安装MySQL yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm# yum安装Mysql社区版
yum -y install mysql-community-server# 启动MySQL服务
systemctl start mysqld
# 启动MySQL服务设置开机启动
systemctl enable mysqld# 检查Mysql服务状态
systemctl status mysqld# 通过MySQL的日志查看默认生成的MySQL root用户的密码
cat /var/log/mysqld.log | grep 'password'
查看root用户的密码结果如下图所示,图中红框部分便是自动生成的密码。

使用mysql -u root -p命令,输入上面的密码登录MySQL。
在MySQL命令行中执行以下命令,实现对root命令的修改。
# 如果你想设置简单密码,需要降低Mysql的密码安全级别
# 设置密码安全级别为低
set global validate_password_policy=LOW;
# 设置密码长度最低4位即可
set global validate_password_length=4;
# 将root用户本地登录的密码修改为123456
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
# 打开root用户的远程登录权限,并将远程登录密码修改为123456
grant all privileges on *.* to root@"%" identified by '123456' with grant
# 刷新MySQL用户权限
flush privileges;
至此,MySQL安装完成。
5.2. 配置Hadoop
Hive的运行依赖于Hadoop(HDFS、MapReduce、YARN都依赖),同时涉及到HDFS文件系统的访问,所以需要配置Hadoop的代理用户,即设置hadoop用户允许代理(模拟)其它用户。
在core-site.xml配置文件中,增加以下配置信息(该配置在前面配置通过NFS挂载HDFS系统时配置过):
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property>
其中:
hadoop.proxyuser.hadoop.groups配置项的值为 *,表示允许hadoop用户代理任何其他用户组;
hadoop.proxyuser.hadoop.hosts配置型的值为 *,表示允许代理任意服务器的请求。
配置完成后,使用scp命令,将该配置文件分发到node2和node3服务器上。
5.3. 下载并加压Hive
下载Hive-3.1.3:http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
将下载下来的文件传至node1虚拟机/home/hadoop目录下,在node1虚拟机中,切换到hadoop用户,进行解压:
# 切换到hadoop用户
su hadoop
# 切换到hadoop用户的home目录(即/home/hadoop)
cd ~
# 解压压缩包
tar -zxvf apache-hive-3.1.3-bin.tar.gz
# 将解压得到的文件夹移动到/export/server/目录下
mv apache-hive-3.1.3-bin /export/server/
# 切换工作目录
cd /export/server/
# 创建软链接
ln -s /export/server/apache-hive-3.1.3-bin/ /export/server/hive
5.4. 下载MySQL驱动包
下载MySQL驱动包:https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
将下载下来的文件传至node1虚拟机/home/hadoop目录下,在node1虚拟机中,以hadoop用户将其移动至hive安装文件夹的lib目录内:
# 切换到hadoop用户的home目录(即/home/hadoop)
cd ~
# 将MySQL驱动程序复制到hive安装目录的lib文件夹下
mv mysql-connector-java-5.1.34.jar /export/server/apache-hive-3.1.3-bin/lib/
# 切换到root用户
su root
# 修改MySQL驱动程序的所有者和所有组为hadoop
chown -R hadoop:hadoop /export/server/apache-hive-3.1.3-bin/lib/mysql-connector-java-5.1.34.jar
# 切换回hadoop用户
exit
5.5. 配置Hive
1、配置hive-env.sh文件:
# 进入hive配置文件目录
cd /export/server/apache-hive-3.1.3-bin/conf/
# 复制一份hive-env.sh模板
cp hive-env.sh.template hive-env.sh
# 打开hive-env.sh文件
vim hive-env.sh
在hive-env.sh文件中追加如下内容:
# 添加环境变量
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
2、创建并配置hive-site.xml文件,在其中添加如下内容:
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>hive.server2.thrift.bind.host</name><value>node1</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
其中,
javax.jdo.option.ConnectionURL 表示Hive所用到的存储元数据的关系型数据库的连接地址;
javax.jdo.option.ConnectionDriverName 表示连接数据库所使用的驱动类;
javax.jdo.option.ConnectionUserName 表示数据库用户名;
javax.jdo.option.ConnectionPassword 表示数据库密码;
hive.server2.thrift.bind.host 表示Hive的server 2绑定的主机;
hive.metastore.uris 表示Hive的metastore(元数据)服务绑定的IP和端口;
hive.metastore.event.db.notification.api.auth 表示是否开启API授权认证。
5.6. 初始化元数据库
在MySQL数据库中新建hive库(这里库的名字需要和上面的数据库连接地址里面的库名保持一致):
CREATE DATABASE hive CHARSET UTF8;
创建好数据库后,在node1虚拟机命令行执行以下命令:
# 切换工作目录
cd /export/server/hive/bin/
# 使用schematool初始化hive数据库
./schematool -initSchema -dbType mysql -verbos
其中,
-initSchema 表示初始化数据库;
-dbType mysql 表示元数据存储的数据库是MySQL数据库;
-verbos 表示开启啰嗦模式(详细日志模式)。
初始化成功后,会在MySQL的hive库中新建74张元数据管理的表。
5.7. 使用hadoop用户身份启动Hive
1、在启动前,需要确保Hive安装目录及其子目录的所有用户和用户组应是hadoop用户,若不是,可以root用户身份执行chown -R hadoop:hadoop /export/server/apache-hive-3.1.3-bin/命令进行修改。

2、创建一个hive的日志文件夹
# 切换成hadoop用户
su hadoop
# 创建logs文件夹,后面用于存放hive日志
mkdir /export/server/hive/logs
3、启动元数据管理服务(必须启动,否则无法工作)
在启动Hive服务之前,一定要确保HDFS集群和YARN集群已经启动!!!
前台启动方式:
# 切换工作目录
cd /export/server/hive/bin
# 前台启动metastore服务
./hive --service metastore
后台启动方式:
# 切换工作目录
cd /export/server/hive/bin
# 使用后台方式启动metastore,并将相关日志输出到metastore.log文件中
nohup ./hive --service metastore >> ../logs/metastore.log 2>&1 &
在实际工作中,一般使用后台启动方式。
启动后,可以使用tail -f ../logs/metastore.log命令查看到日志文件的内容。
4、启动Hive客户端
Hive Shell方式(可以直接写SQL):./hive
Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用): ./hive --service hiveserver2
先演示Hive Shell方式,直接在命令行输入
# 切换工作目录
cd /export/server/hive/bin/
# 打开hive客户端
./hive
打开Hive客户端后,能看到如下效果:
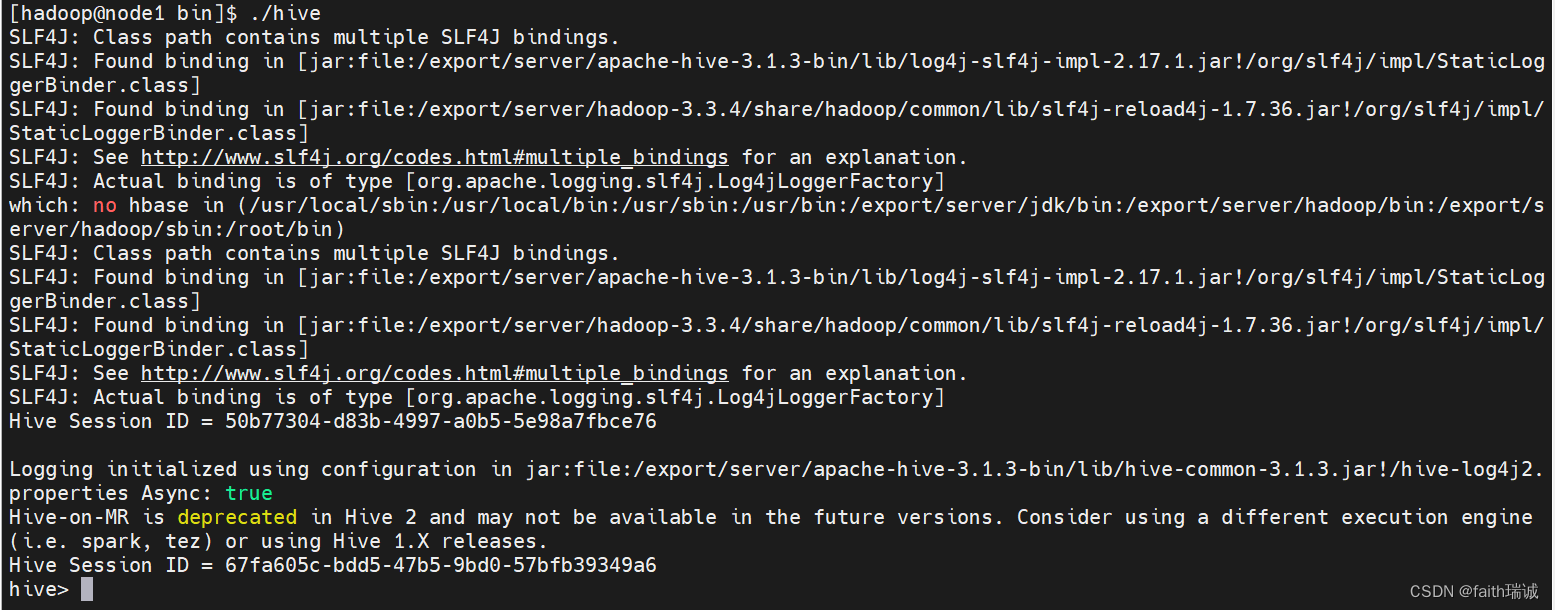
可以看到hive>标签,在这里就可以输入SQL语句:

5、停止元数据管理服务
可以通过ps -aux | grep hive来看hive的进程号,然后kill掉相关的进程即可。
相关文章:
Hadoop入门学习笔记——五、在虚拟机中部署Hive
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 五、在虚拟机中部署Hive5.1. 在node1虚拟机安装MySQL5.2.…...

用Nest 实现大文件分片上传,加速工作效率神器
文件上传是常见需求,只要指定 content-type 为 multipart/form-data,内容就会以这种格式被传递到服务端: 服务端再按照 multipart/form-data 的格式提取数据,就能拿到其中的文件。 但当文件很大的时候,事情就变得不一样…...

将ncnn及opencv的mat存储成bin文件的方法
利用fstream,将ncnn及opencv的mat存储成bin文件。 ncnn::Mat to bin std::ios::binary标志指示文件以二进制模式进行读写, std::ofstream file("output_x86.bin", std::ios::binary); 将input_mat中的宽、高和通道数分别赋值给width、heig…...
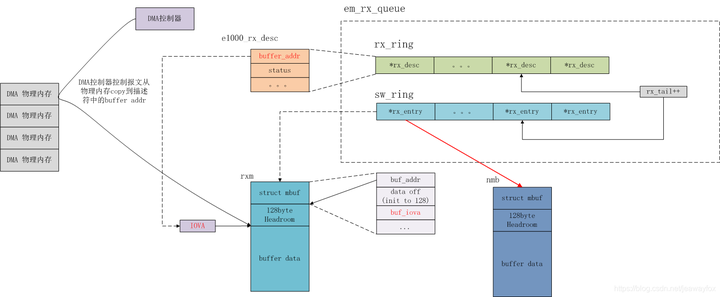
dpdk原理概述及核心源码剖析
dpdk原理 1、操作系统、计算机网络诞生已经几十年了,部分功能不再能满足现在的业务需求。如果对操作系统做更改,成本非常高,所以部分问题是在应用层想办法解决的,比如前面介绍的协程、quic等,都是在应用层重新开发的框…...
VTK+QT配置(VS)
先根据vtk配置这个博客配置基本环境 然后把这个dll文件从VTK的designer目录复制到qt的对应目录里 记得这里是debug版本,你也可以配置release都一样的步骤,然后建立一个qt项目,接着配置包含目录,库目录,链接输入&…...

5G边缘计算:解密边缘计算的魔力
引言 你是否曾想过,网络可以更贴心、更智能地为我们提供服务?5G边缘计算就像是网络的小助手,时刻待命在你身边,让数字生活变得更加便捷。 什么是5G边缘计算? 想象一下,边缘计算就像是在离你最近的一层“云…...
Sentinel 流量治理组件教程
前言 官网首页:home | Sentinel (sentinelguard.io) 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形…...

C语言第五十九弹---介绍说明内存函数memcmp
使用C语言介绍说明内存函数memcmp memcmp是C语言标准库中的一个函数,用于比较两个内存区域的内容是否相同。 源代码: int memcmp(const void* ptr1, const void* ptr2, size_t num);ptr1和ptr2分别是要比较的两个内存区域的指针,num是要比较…...

jar混淆,防止反编译,Allatori工具混淆jar包
文章目录 Allatori工具简介下载解压配置config.xml注意事项 Allatori工具简介 官网地址:https://allatori.com/ Allatori不仅混淆了代码,还最大限度地减小了应用程序的大小,提高了速度,同时除了你和你的团队之外,任何人…...

linux中批量将HEIC转jpg
苹果目前已大量使用HEIC格式的照片,虽然上传到Windows系统的时候是会自动转为jpg的,但也经常会在很多场景中保留了HEIC格式,前两天就收到了一大堆HEIC文件,window10里都打不开,照片的插件是需要付费下载的,…...

听GPT 讲Rust源代码--src/tools(25)
File: rust/src/tools/clippy/clippy_lints/src/methods/suspicious_command_arg_space.rs 在Rust源代码中,suspicious_command_arg_space.rs文件位于clippy_lints工具包的methods目录下,用于实现Clippy lint SUSPICIOUS_COMMAND_ARG_SPACE。 Clippy是Ru…...

一款C++编写的数据可视化库Matplot++
它是基于著名的 Matplotlib 库(Python 中广泛使用的绘图库)构建的,旨在提供类似于 Matplotlib 的功能,但专门为 C 设计。Matplot 支持多种图表类型,包括线图、散点图、条形图、直方图、误差线图等,使数据可…...
)
paddle 56 将图像分类模型嵌入到目标检测中并实现端到端的部署(用图像分类模型进行目标检测切片分类)
目标检测在功能上一直是涵盖了图像分类的,其包含目标切片检测,目标切片分类。由于某些原因,需要将目标检测的功能退化为检测,忽略其切片分类,使用外部的分类模型。然而这样操作会使得其与原始的部署代码不兼容,为此博主实现将图像分类模型嵌入到目标检测中,并实现端到端…...
SQL手工注入漏洞测试(MySQL数据库)
一、实验平台 https://www.mozhe.cn/bug/detail/elRHc1BCd2VIckQxbjduMG9BVCtkZz09bW96aGUmozhe 二、实验目标 获取到网站的KEY,并提交完成靶场。 三、实验步骤 ①、启动靶机,进行访问查找可能存在注入的页面 ②、通过测试判断注入点的位置(id) (1)…...

JAVA WEB用POI导出EXECL多个Sheet
前端方法:调用exportInfoPid这个方法并传入要查询的id即可,也可以用其他参数看个人需求 function exportInfoPid(id){window.location.href 服务地址"/exportMdsRoutePid/"id; } 后端控制层代码 Controller Scope("prototype") R…...

@RequestBody详解:用于获取请求体中的Json格式参数
获取请求体中的Json格式参数 (RequestBody) 当前端将一些比较复杂的参数转换成Json字符串通过请求体传递过来给后端,这种时候就可以使用RequestBody注解获取请求体中的数据。 而json字符串是包含在请求体中的,使用请求体传参通常…...

AI日报:2024年人工智能对各行业初创企业的影响
欢迎订阅专栏 《AI日报》 获取人工智能邻域最新资讯 文章目录 2024年人工智能对初创企业的影响具体行业医疗金融服务运输与物流等 新趋势 2024年人工智能对初创企业的影响 2023年见证了人工智能在各个行业的快速采用和创新。随着我们步入2024年,人工智能初创公司正…...
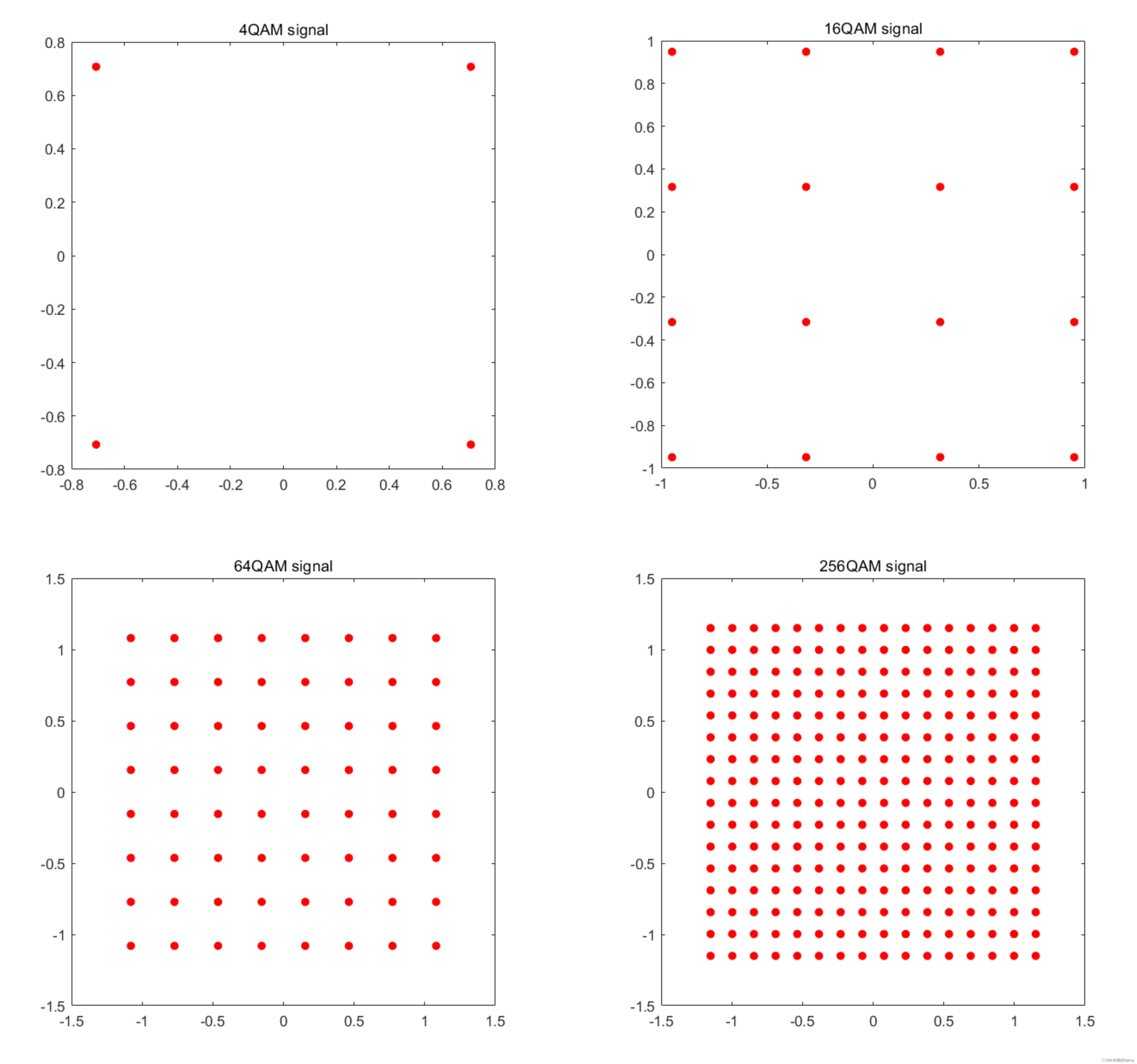
QAM 归一化因子
文章目录 前言一、归一化1、作用2、OFDM 归一化因子 二、归一化因子公式 前言 在做通信系统仿真时,遇到了 QAM 归一化因子的求解,对这里不是很清楚,因此本文对 QAM(正交振幅调制)归一化因子学习做了一下记录。 一、归…...

PoE交换机传输距离是多少?100米?250米?
你们好,我的网工朋友。 今天和你聊聊PoE交换机,之前有系统地给你讲解过一篇,可以先回顾一下哈:《啥样的交换机才叫高级交换机?这张图告诉你》 为什么都说PoE交换机好?它最显著的特点就是: 可…...
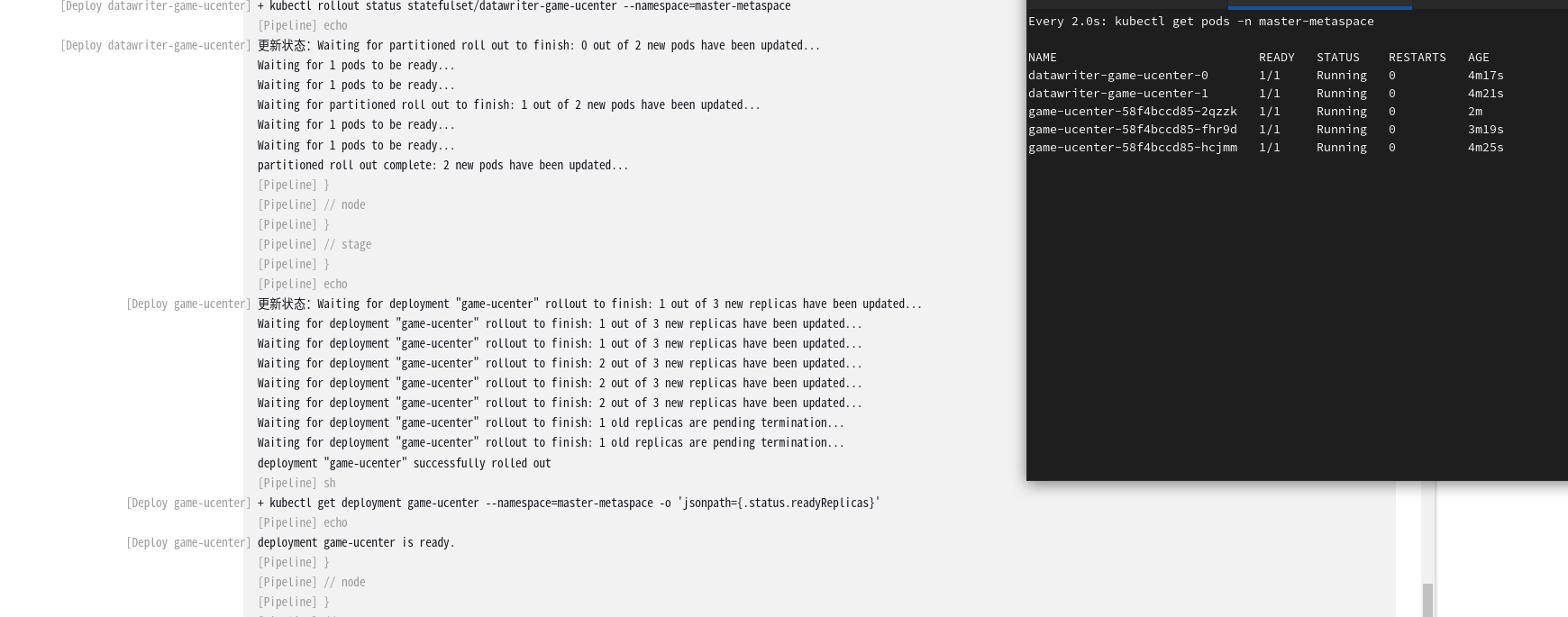
Jenkins Pipeline脚本优化:为Kubernetes应用部署增加状态检测
引言 在软件部署的世界中,Jenkins已经成为自动化流程的代名词。不断变化的技术环境要求我们持续改进部署流程以满足现代应用部署的需要。在本篇博客中,作为一位资深运维工程师,我将分享如何将Jenkins Pipeline进化至不仅能支持部署应用直至R…...

GPT-OSS-20B场景实战:如何用它快速生成营销文案与工作报告
GPT-OSS-20B场景实战:如何用它快速生成营销文案与工作报告 引言:当写作成为日常,你需要一个得力的助手 每天一睁眼,是不是就被各种文案和工作报告包围了?电商同事催着要新品推广文案,市场部等着活动策划方…...

【Simulink】T-NPC三电平并网逆变器FCS-MPC:从代价函数设计到中点电位平衡优化
1. FCS-MPC在三电平T-NPC逆变器中的核心价值 我第一次接触T-NPC拓扑时,被它独特的结构惊艳到了。相比传统的I型NPC,T型结构在正负极之间形成了更复杂的电流路径,这使得中点电位平衡问题变得尤为关键。而有限控制集模型预测控制(FC…...

IndexTTS2 V23应用场景:打造有温度的教育内容语音助手
IndexTTS2 V23应用场景:打造有温度的教育内容语音助手 在教育的世界里,声音不仅仅是信息的载体,更是情感的桥梁。一句充满鼓励的“你真棒”,一段饱含悬念的故事旁白,或是一道难题讲解时循循善诱的语气,都能…...

PyAutoGUI实战避坑指南:从安装到常见问题解决
1. PyAutoGUI安装与配置避坑指南 第一次接触PyAutoGUI时,我兴冲冲地打开终端输入pip install pyautogui,结果等待我的不是安装成功的喜悦,而是满屏红色错误提示。相信很多朋友都遇到过类似情况,今天我就把这些年踩过的坑和解决方案…...

深入解析SCT分散加载文件:从FLASH到SRAM的高效内存管理策略
1. 嵌入式系统中的内存管理挑战 在嵌入式系统开发中,内存管理一直是个让人头疼的问题。我刚开始接触STM32开发时,就遇到过FLASH空间不足导致编译失败的尴尬情况。当时项目需要实现一个复杂的通信协议栈,代码量激增到接近芯片FLASH容量上限。通…...

Ubuntu终端会话守护者:Screen命令从入门到精通实战
1. 为什么你需要Screen这个终端守护者? 想象一下这样的场景:你正在通过SSH连接远程服务器运行一个耗时很长的数据分析脚本,突然网络波动导致连接中断,几个小时的运算成果瞬间消失。或者你需要同时监控服务器日志、运行测试脚本和编…...

Python Pandas实战:自动化生产线数据分析全流程解析与代码复现
1. 自动化生产线数据分析实战入门 第一次拿到生产线CSV日志时,我盯着密密麻麻的几十列数据发呆了半小时。作为刚接手工厂数据分析的新人,面对"抓取次数"、"故障代码"这些陌生字段,连从哪里开始分析都毫无头绪。直到发现P…...
)
MCP身份验证必须升级OAuth 2026?3大安全审计红线已触发,配置失败率高达67.3%(2025.06真实渗透测试数据)
第一章:MCP身份验证OAuth 2026升级的强制性与审计背景随着全球数据合规框架持续收紧,MCP(Managed Cloud Platform)平台于2025年Q4正式发布《MCP Identity Policy v3.1》,明确将OAuth 2026规范设为所有生产环境API访问的…...

基于 Docker Compose 一键部署 XXL-Job 调度中心实战
1. 为什么选择Docker Compose部署XXL-Job? 第一次接触XXL-Job时,我尝试过传统部署方式:先手动安装MySQL,再配置Java环境,最后部署war包。光是处理各种依赖冲突就花了半天时间。直到发现Docker Compose方案,…...
:隐私保护新利器的机遇与挑战)
全球隐私控制(GPC):隐私保护新利器的机遇与挑战
全球隐私控制(GPC):隐私保护的新防线全球隐私控制(GPC)始于 2020 年,灵感源自《加州消费者隐私法案》,旨在帮助用户重新掌控自己的隐私。用户可以通过一些浏览器和浏览器扩展程序,知…...