Pytohn data mode plt
文章目录
- 文件的读写
- 创建.csv类型的文件,并读取文件
- 创建.xlsx文件
- 使用Python做图
- 生成数据集
- 切片取值操作
- 修改张量中指定位置的数据
- 知识点
- torch.arange(x)
- torch.tensor(2)
- A=torch.randn(36).reshape(6,6)
- shape
- numel()
- reshape(x,y,z)
- torch.zeros(3,3,4)
- torch.ones(2,3,4)
- torch.randn(4,5)
- torch.tensor([[1,2,3],[4,5,6],[7,8,9]])
- 数组的加减乘除
- torch.exp(x)
- Z1=torch.cat((X,Y),dim=0)
- Z=X==Y
- X.sum()
- 矩阵的广播机制,形状不一样的矩阵变成形状相同的矩阵
- 矩阵中元素的获取
- before =id(Y)
- torch.zeros_like(Y)
- Z[:]=X+Y
- print(type(A),type(B))
- print(a,a.item(),int(a),float(a))
- print(len(x))
- B=A.T
- B=A.clone()
- print(A.sum(axis=[0,1])
- print(A.cumsum(axis=0))
- z=x*y 张量的乘法
- y=torch.mv(A,x)
- np.linalg.norm(A)
- 附录
文件的读写
创建.csv类型的文件,并读取文件
.csv类型的文件是以逗号风格的字符串类型的数据
import os//导入操作计算机系统的对象
os.makedirs(os.path.join('..','data'),exist_ok=True)//在当前项目所在的目录下创建文件data,如果文件存在也不报异常
data_file=os.path.join('..','data','house_tiny.cvs')//在data目录下创建.csv文件
with open(data_file,'w') as f://打开文件的写权限并写入数据f.write('NumRooms,Alley,Price\n')f.write('NA,Pave,127500\n')f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')import pandas//pandas主要用于数据的读取操作data=pandas.read_csv(data_file)//读取.csv类型的数据
print(data)NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
import os
os.makedirs(os.path.join('D:/File/test','data'),exist_ok=True)
data_file=os.path.join('D:/File/test','data','house_tiny.csv')
with open(data_file,'w') as f:f.write('NumRooms,Alley,Price\n')f.write('2.0,Pave,127500\n')f.write('4.0,NA,178100\n')f.write('NA,NA,140000\n')f.write('NA,Pave,127500\n')
import pandas
data =pandas.read_csv(data_file)
print(data)
import torch
import os
os.makedirs(os.path.join("D:/File/test","data"),exist_ok=True)
data_file=os.path.join("D:/File/test","data","house_tiny.csv")
with open(data_file,"w") as f:f.write('NumRooms,Alley,Price\n')f.write('2.0,Pave,127500\n')f.write('4.0,NA,178100\n')f.write('NA,NA,140000\n')f.write('NA,Pave,127500\n')import pandas
data =pandas.read_csv(data_file)
print(data)inputs ,outputs =data.iloc[:,0:2],data.iloc[:,2]
inputs=inputs.fillna(inputs.select_dtypes(include="number").mean())//fillna的作用填充空值,用平均值进行填充
print(inputs)inputs=pandas.get_dummies(inputs,dummy_na=True,dtype=numpy.int8)
print(inputs)
print(outputs)
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
print(X)
print(y)NumRooms Alley Price
0 2.0 Pave 127500
1 4.0 NaN 178100
2 NaN NaN 140000
3 NaN Pave 127500NumRooms Alley
0 2.0 Pave
1 4.0 NaN
2 3.0 NaN
3 3.0 PaveNumRooms Alley_Pave Alley_nan
0 2.0 1 0
1 4.0 0 1
2 3.0 0 1
3 3.0 1 0
0 127500
1 178100
2 140000
3 127500
Name: Price, dtype: int64
tensor([[2., 1., 0.],[4., 0., 1.],[3., 0., 1.],[3., 1., 0.]], dtype=torch.float64)
tensor([127500, 178100, 140000, 127500])
上述代码所用到的知识点总结
Pandas读取某列、某行数据——loc、iloc用法总结
pandas操作4(处理缺失值/位置索引)
【深入浅出学习笔记】李沐《动手学深度学习2.0》之数据预处理学习
import os
os.makedirs(os.path.join("D:/File/test","testdata"),exist_ok=True)
data_file=os.path.join("D:/File/test","testdata","house.csv")
with open(data_file,'w') as f:f.write("size,price\n")f.write('20,10\n')f.write('30,20\n')
import pandas
data=pandas.read_csv(data_file)
print(data)
创建.xlsx文件
import pandas as pd
import numpy as np
import os
os.makedirs(os.path.join("D:/","实验数据"),exist_ok=True)
# 生成DataFrame
data = pd.DataFrame(np.arange(30).reshape((6, 5)),columns=['A', 'B', 'C', 'D', 'E'])
# 写入本地
data.to_excel("D:\\实验数据\\data.xlsx", sheet_name="data")
print(data)
使用Python做图
import numpy
from matplotlib_inline import backend_inline
from d2l import torch as d2l
def f(x):return 3*x**2-4*xdef numerical_lim(f,x,h):return (f(x+h)-f(x))/hh=0.1
for i in range(5):print(f"h={h:.5f},numerical limit={numerical_lim(f,1,h):.5f}")h*=0.1//这是一个求导的过程def use_svg_display():#@savebackend_inline.set_matplotlib_formats('svg')//通过在线的方式,设置画布类型为svgdef set_figsize(figsize):#@saveuse_svg_display()d2l.plt.rcParams['figure.figsize']=figsize//设置画布的尺寸为figsize#@save
def set_axes(axes,xlabel,ylabel,xlim,ylim,xscale,yscale,legend):axes.set_xlabel(xlabel)//设置X轴的标签axes.set_ylabel(ylabel)axes.set_xlim(xlim)//设置X轴上的数值axes.set_ylim(ylim)axes.set_xscale(xscale)//设置X轴上的数值的缩放比例axes.set_yscale(yscale)if legend:axes.legend(legend)//axes.legend()函数说明图例的位置等相关属性axes.grid()//grid()函数用于设置绘图区网格线。#@save
def plot(X,Y=None,xlabel=None,ylabel=None,legend=None,xlim=None,ylim=None,xscale='linear',yscale='linear',fmts=('-','m--','g-.','r:'),figsize=(3.5,2.5),axes=None):
// 这是一种在Matplotib中设置图形线条样式的方式。在Matplotib中,可以使用fmts参数来设置线条样式。fmts参数是一个字符串,由一个或多个字符//组成,每个字符都代表了一个设计元素,用于设置线条的颜色、线型和标记。
//在给定的fmts参数中,每个字符的含义如下:
//·第一个字符(-')代表线的颜色,这里的-'代表黑色。
//·第二个字符('m')代表线的样式,这里的'm--'代表品红色的虚线。·第三个字符('g')代表线的颜色,这里的'g'代表绿色。
//·第四个字符(r')代表线的颜色,这里的'r:'代表红色的点线。
//通过在Matplotlib中设置fmts参数,可以使不同的线条呈现不同的颜色、样式和标记,从而更加直观地表达数据之间的关系。if legend is None:legend=[]set_figsize(figsize)axes=axes if axes else d2l.plt.gca()
//[动手学深度学习-导数和微分-第二章plot函数理解](https://blog.csdn.net/qyk666/article/details/134756786)def has_one_axis(X):return (hasattr(X,'ndim') and X.ndim==1 or isinstance(X,list) and not hasattr(X[0],"__len__"))if has_one_axis(X):X=[X]if Y is None:X,Y=[[]]*len(X),Xelif has_one_axis(Y):Y=[Y]if len(X)!=len(Y):X=X*len(Y)axes.cla()for x,y, fmt in zip(X,Y,fmts):if len(x):axes.plot(x,y,fmt)else:axes.plot(y,fmt)set_axes(axes,xlabel,ylabel,xlim,ylim,xscale,yscale,legend)x=numpy.arange(0,3,0.1)
plot(x,[f(x),2*x-3],'x','f(x)',legend=['f(x)','Tangent line (x=1)'])
plt.show()""""""import numpy
import math
from d2l import torch as d2l
def normal(x,mu,sigma):p=1/np.sqrt(2*math.pi*sigma**2)return p*np.exp(-0.5/sigma**2*(x-mu)**2)x=numpy.arange(-10,10,0.01)
params=[(0,1),(0,2),(3,1)]d2l.plot(x,[normal(x,mu,sigma) for mu,sigma in params],xlabel='x',ylabel='p(x)',figsize=(4.5,2.5),legend=[f'mean{mu},std{sigma}' for mu ,sigma in params])
plt.show()""""""import random
import torch
from d2l import torch as d2l
def synthetic_data(w,b,num_examples):#@saveX=torch.normal(0,1,(num_examples,len(w)))y=torch.matmul(X,w)+by+=torch.normal(0,0.01,y.shape)return X,y.reshape((-1,1))
true_w=torch.tensor([2,-3.4])
true_b=4.2
features ,labels=synthetic_data(true_w,true_b,1000)
print('features:',features[0],'\nlabel:',labels[0])
# print(labels)
d2l.set_figsize()
# print(features[:,(1)].detach().numpy())
# print('fasfsadfsdfsdf')
# print(labels.detach().numpy)
d2l.plt.scatter(features[:,(1)].detach().numpy(),labels,1)plt.show()"""
生成数据集
切片取值操作
修改张量中指定位置的数据
import torch
X=torch.zeros(3,4)
X[1,1]=1
Y=torch.ones(3,4)
Y[0,0]=0
print(X==Y)
print(X>Y)
print((X<Y))
知识点
torch.arange(x)
作用:依据x生成一个数组
import torch
x=torch.arange(12)
print(x)
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
import numpy
x=numpy.arange(12)
print(x)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
import torch
x=torch.arange(4)
print(x)
print(x[2])
torch.tensor(2)
作用:生成指定的张量
import torch
x=torch.tensor(2)
y=torch.tensor(3)
print(x+y,x-y,x*y,x/y,x**y)
tensor(5) tensor(-1) tensor(6) tensor(0.6667) tensor(8)
A=torch.randn(36).reshape(6,6)
作用:生成符合正太分布的数据
A=torch.randn(36).reshape(6,6)
print(A+A.T)
A=torch.arange(25).reshape(5,5)
print(A)
print(len(A))
print(A/A.sum(axis=1))
print(A.sum(axis=1))
print(A)
shape
作用:查看调用者的形状或者称呼为尺寸
import torch
x=torch.arange(12)
a=x.shape
print(a)
torch.Size([12])
import numpy
x=numpy.arange(12)
a=x.shape
print(a)
(12,)
import torch
A=torch.arange(24).reshape(2,3,4)
print(A.shape,A.shape[0],A.shape[1],A.shape[2])
numel()
作用:(名称的字面意思元素的数量)查看元素的数量
import torch
x=torch.arange(12)
a=x.numel()
print(a)
12
reshape(x,y,z)
作用:将数据的展示形状进行重新的塑形
import torch
x=torch.arange(12)
X=x.reshape(3,4)
print(X)
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
import numpy
x=numpy.arange(12)
X=x.reshape(3,4)
print(X)
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]
-1的作用:依据数据自动计算数值并填入
import torch
x=torch.arange(12)
X=x.reshape(-1,4)
print(X)
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
import torch
x=torch.arange(12)
X=x.reshape(3,-1)
print(X)
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
import numpy
x=numpy.arange(12)
X=x.reshape(-1,4)
print(X)
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]
import numpy
x=numpy.arange(12)
X=x.reshape(3,-1)
print(X)
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]
torch.zeros(3,3,4)
作用:生成三维全为零的数据
import torch
X=torch.zeros(3,3,4)
print(X)
tensor([[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]]])
import numpy as np
X=np.zeros((2,2,3),int)
print(X)
[[[0 0 0][0 0 0]][[0 0 0][0 0 0]]]
torch.ones(2,3,4)
作用:生成三维全为1的数据
import torch as to
X=to.ones(2,2,3)
print(X)
tensor([[[1., 1., 1.],[1., 1., 1.]],[[1., 1., 1.],[1., 1., 1.]]])
在python中想要改变函数的返回结果,往往只需要在参数列表中在添加一些参数
import numpy as np
X=np.ones((2,2,2),float)
print(X)
[[[1. 1.][1. 1.]][[1. 1.][1. 1.]]]
torch.randn(4,5)
作用:生成符合正太分布的数据
import torch
X=torch.randn(4,5)
print(X)
tensor([[-1.1866, 1.1176, 1.0693, -1.0216, 0.1562],[ 0.1815, 0.3246, 1.1276, 0.5653, -1.4328],[ 0.1206, 0.6508, -0.4501, 0.0958, 0.7154],[ 1.1551, 0.1163, 0.7360, 0.7723, -0.1527]])
import numpy
X=numpy.random.randn(3,4)
print(X)
[[ 0.77655555 -0.89418554 -1.27220862 -0.52597834][-0.20755957 -0.53087554 -0.83361693 1.29417959][ 0.49374487 1.55469626 0.53871618 -0.01278069]]
torch.tensor([[1,2,3],[4,5,6],[7,8,9]])
自定义数据
import torch
X=torch.tensor([[1,2,3],[4,5,6],[7,8,9]])
print(X)
tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
数组的加减乘除
import torch
x=torch.tensor([1,2,4,8])
y=torch.tensor([2,2,2,2])
print(str(x+y)+"\n"+str(x-y)+"\n"+str(x*y)+"\n"+str(x/y)+"\n"+str(x**y)+"\n")
tensor([ 3, 4, 6, 10])
tensor([-1, 0, 2, 6])
tensor([ 2, 4, 8, 16])
tensor([0.5000, 1.0000, 2.0000, 4.0000])
tensor([ 1, 4, 16, 64])
torch.exp(x)
作用生成数学公式中e函数
import torch
x=torch.tensor([1,2,3,4])
x=torch.exp(x)
print(x)
tensor([ 2.7183, 7.3891, 20.0855, 54.5981])
import numpy
x=numpy.array([1,2,3,4],float)
print(x)
x=numpy.exp(x)
print(x)
[1. 2. 3. 4.]
[ 2.71828183 7.3890561 20.08553692 54.59815003]
Z1=torch.cat((X,Y),dim=0)
作用:合并数据存储类型,dim=0按照列合并,dim=1按照行合并
import torch
X=torch.arange(12,dtype=torch.int).reshape(3,4)
print(X)
Y=torch.tensor([[1,2,3,4],[2,2,2,2],[6,6,6,6]])
Z1=torch.cat((X,Y),dim=0)
Z2=torch.cat((X, Y),dim=1)
print(Y)
print(Z1)
print(Z2)
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]], dtype=torch.int32)
tensor([[1, 2, 3, 4],[2, 2, 2, 2],[6, 6, 6, 6]])
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[ 1, 2, 3, 4],[ 2, 2, 2, 2],[ 6, 6, 6, 6]])
tensor([[ 0, 1, 2, 3, 1, 2, 3, 4],[ 4, 5, 6, 7, 2, 2, 2, 2],[ 8, 9, 10, 11, 6, 6, 6, 6]])
Z=X==Y
作用:比较两个矩阵是否相等,比较的是两个数据存储结构中的每一位元素是否相等
import torch
X=torch.arange(12).reshape(3,4)
print(X)
Y=torch.tensor([[1,2,3,4],[2,2,2,2],[6,6,6,6]])
print(Y)
Z=X==Y
print(Z)
X.sum()
作用 :将矩阵中所有的元素相加
import torch
X=torch.arange(12).reshape(3,4)
print(X.sum())
import torch
x=torch.arange(4)
print(x)
print(x.sum())
矩阵的广播机制,形状不一样的矩阵变成形状相同的矩阵
作用:广播机制可以使形状不一样的矩阵变成一样的矩阵
"import torch
a=torch.arange(3).reshape(3,1)
print(a)
b=torch.arange(2).reshape(1,2)
print(b)
C=a+b
print(C)
tensor([[0],[1],[2]])
tensor([[0, 1]])
tensor([[0, 1],[1, 2],[2, 3]])
import torch
A=torch.tensor([[[1,2,3],[4,5,6]],[[1,2,3],[1,2,3]]])
print(A)
a=2
A=a+A
print(A)
A=A*a
print(A)
矩阵中元素的获取
作用:获取矩阵中特定位置的元素
import torch
X=torch.arange(12).reshape(3,4)
print(X)
print(X[-1])
print(X[1,2])
X[1,2]=111
print(X)
print(X[0:2])
X[0:2]=111111
print(X)
X[0:2,:]=222222
print(X)
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
tensor([ 8, 9, 10, 11])
tensor(6)
tensor([[ 0, 1, 2, 3],[ 4, 5, 111, 7],[ 8, 9, 10, 11]])
tensor([[ 0, 1, 2, 3],[ 4, 5, 111, 7]])
tensor([[111111, 111111, 111111, 111111],[111111, 111111, 111111, 111111],[ 8, 9, 10, 11]])
tensor([[222222, 222222, 222222, 222222],[222222, 222222, 222222, 222222],[ 8, 9, 10, 11]])
before =id(Y)
作用:查看对象在内存中的存储位置
import torch
Y=torch.ones(3,4)
X=torch.ones(3,4)
before =id(Y)
print(before)
Y=X+Y
after=id(Y)
print(after)
2392263829440
2391076947984
torch.zeros_like(Y)
作用:形成一个像Y一样的全为零的张量
import torch
Y = torch.zeros(3,4)
X = torch.ones(3,4)
Z = torch.zeros_like(Y)
print(id(Z))
Z[:]=X+Y
print(id(Z))
2255358553200
2255358553200
Z[:]=X+Y
作用:可以使Z在内存中的存储位置不变(使用+=这种类型的符合也不会改变对象在内存中的存储位置)
import torch
Y = torch.zeros(3,4)
X = torch.ones(3,4)
Z = torch.zeros_like(Y)
print(id(Z))
Z[:]=X+Y
print(id(Z))
2255358553200
2255358553200
import torch
X=torch.zeros(3,2)
Y=torch.ones(3,2)
before=id(X)
X+=Y
print(before==id(X))
True
import torch
X=torch.zeros(2,4,1)
Y=torch.ones(2,4,4)
Y[:]=X+Y
print(Y)
tensor([[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]],[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]])
print(type(A),type(B))
作用:查看数据的数据类型
import torch
X=torch.ones(3,4)
A=X.numpy()
B=torch.tensor(A)
print(type(A),type(B))
print(A)
<class 'numpy.ndarray'> <class 'torch.Tensor'>
[[1. 1. 1. 1.][1. 1. 1. 1.][1. 1. 1. 1.]]
print(a,a.item(),int(a),float(a))
作用:数据类型的强制转换
import torch
a=torch.tensor([3.3])
print(a,a.item(),int(a),float(a))
tensor([3.3000]) 3.299999952316284 3 3.299999952316284
print(len(x))
作用:查看张量的长度
import torch
x=torch.arange(4)
print(x)
print(len(x))
print(x.shape)
B=A.T
作用:将张量进行转置
import torch
A=torch.arange(20).reshape(4,5)
print(A)
print(A[1,1])
B=A.T
print(B)
print(B.shape)
A=torch.arange(20).reshape(5,4)
print(A)
print(A.T)
print(A.T.T)
B=torch.arange(30).reshape(5,4)
print(A.T+B.T==(A+B).T)
B=A.clone()
作用:对张量A进行克隆
import torch
A=torch.arange(24).reshape(2,3,4)
B=A.clone()
print(A)
C=A*B
print(C)
print(A.sum(axis=[0,1])
作用:axis=0代表列,axis=1代表行
import torch
A=torch.arange(20,dtype=torch.float32).reshape(5,4)
print(A.shape)
print(A.sum())
print(A.sum(axis=0))
print(A)
print(A.shape)
print(A.sum(axis=1))
print(A.sum(axis=[0,1]))
print(A.numel())
print(A.mean(),A.sum()/A.numel())
print(A.shape[0])
print(A.mean(axis=0),A.sum(axis=0)/A.shape[0])
import torch
A=torch.arange(24).reshape(2,3,4)
print(A.sum(axis=0))
print(A.sum(axis=1))
print(A.sum(axis=2))
print(A)
print(A.cumsum(axis=0))
作用:列中的值,等于列中这个位置的值加上此列中这个位置上面的所有的值
import torch
A=torch.arange(20,dtype=torch.float32).reshape(5,4)
sum=A.sum(axis=1,keepdims=True)
print(sum)
print(A/sum)
print(A.cumsum(axis=0))
print(A)
tensor([[ 6.],[22.],[38.],[54.],[70.]])
tensor([[0.0000, 0.1667, 0.3333, 0.5000],[0.1818, 0.2273, 0.2727, 0.3182],[0.2105, 0.2368, 0.2632, 0.2895],[0.2222, 0.2407, 0.2593, 0.2778],[0.2286, 0.2429, 0.2571, 0.2714]])
tensor([[ 0., 1., 2., 3.],[ 4., 6., 8., 10.],[12., 15., 18., 21.],[24., 28., 32., 36.],[40., 45., 50., 55.]])
tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[12., 13., 14., 15.],[16., 17., 18., 19.]])
z=x*y 张量的乘法
作用:张量中对应位置的元素相乘
import torch
x=torch.arange(20).reshape(4,5)
y=torch.arange(20).reshape(4,5)
z=x*y
print(z)
tensor([[ 0, 1, 4, 9, 16],[ 25, 36, 49, 64, 81],[100, 121, 144, 169, 196],[225, 256, 289, 324, 361]])
y=torch.mv(A,x)
作用:矩阵和向量相乘,矩阵的行乘以向量的列并相加
import torch
x=torch.arange(4,dtype=torch.float32)
A=torch.arange(20,dtype=torch.float32).reshape(5,4)
print(x.shape,A.shape)
y=torch.mv(A,x)
print(y)
torch.Size([4]) torch.Size([5, 4])
tensor([ 14., 38., 62., 86., 110.])
np.linalg.norm(A)
作用:用于求张量的范数,默认求的是二范数
import torch
import numpy as np
A=torch.arange(24).reshape(2,3,4)
print(np.linalg.norm(A))
附录
关于文中提到的张量
在文中我提到的张量可以是众所周知的一维数组,也可以使二维数组(矩阵),但是三维、四维数组很难用特有的名词来展示,这里对一维、二维、三维、、、等统称为张量。当读到张量时我们需要根据上下文的代码自行推断。
关于文中引用到的链接
在文中引用到的链接,均是上下文中代码知识的拓展,
相关文章:

Pytohn data mode plt
文章目录 文件的读写创建.csv类型的文件,并读取文件创建.xlsx文件 使用Python做图生成数据集切片取值操作修改张量中指定位置的数据 知识点torch.arange(x)torch.tensor(2)Atorch.randn(36).reshape(6,6)shapenumel()reshape(x,y,z)torch.zeros(3,3,4)torch.ones(2,…...

内网离线搭建之----kafka集群
1.系统版本 虚拟机192.168.9.184 虚拟机192.168.9.185 虚拟机192.168.9.186系统 centos7 7.6.1810 2.依赖下载 ps:置顶资源里已经下载好了,直接用!!!!!!!!…...
)
5.1 显示窗口的内容(一)
一,如何显示窗口的内容? 显示器用于在物理硬件(如计算机显示器或触摸屏显示器)上显示窗口的内容。 屏幕API提供的功能允许我们创建同时写入多个窗口和显示的应用程序。屏幕支持多个显示器,但创建和管理使用多个显示器…...
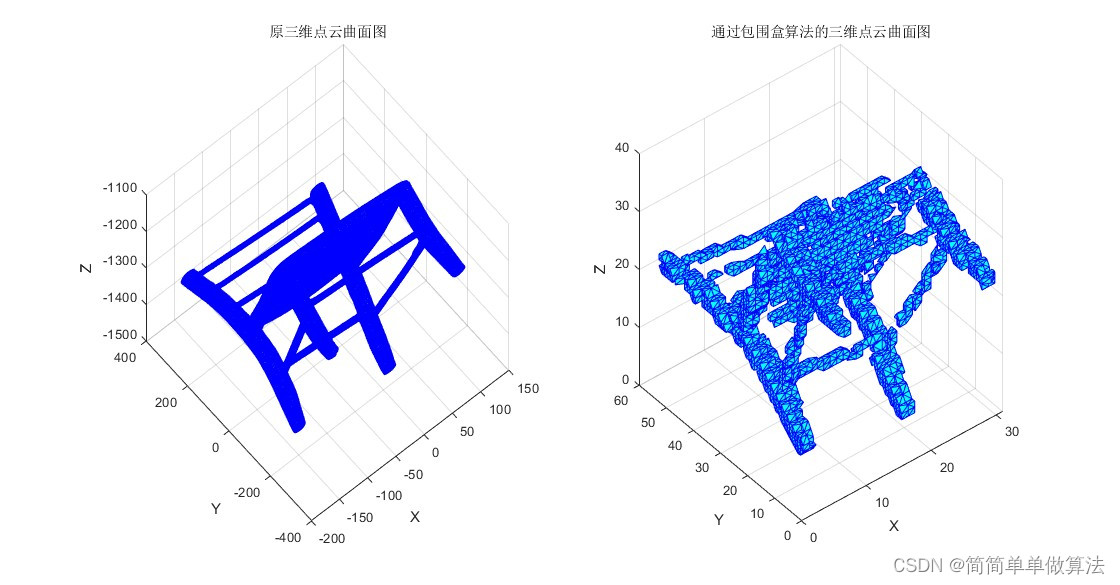
基于包围盒算法的三维点云数据压缩和曲面重建matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 包围盒构建 4.2 点云压缩 4.3 曲面重建 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ...........................................…...
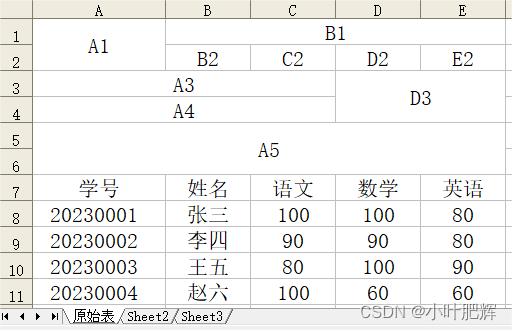
关于Python里xlwings库对Excel表格的操作(十八)
这篇小笔记主要记录如何【设置单元格数据的对齐方式】。前面的小笔记已整理成目录,可点链接去目录寻找所需更方便。 【目录部分内容如下】【点击此处可进入目录】 (1)如何安装导入xlwings库; (2)如何在Wps下…...
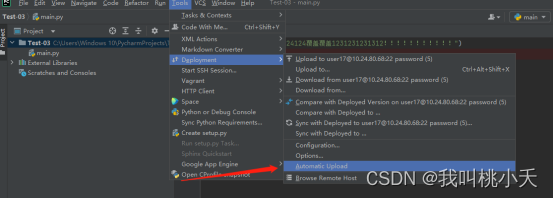
VScode远程连接服务器,Pycharm专业版下载及远程连接(深度学习远程篇)
Visual Code、PyCharm专业版,本地和远程交互。 远程连接需要用到SSH协议的技术,常用的代码编辑器vscode 和 pycharm都有此类功能。社区版的pycharm是免费的,但是社区版不支持ssh连接服务器,只有专业版才可以,需要破解…...
------$bus)
Vue2和Vue3组件间通信方式汇总(3)------$bus
组件间通信方式是前端必不可少的知识点,前端开发经常会遇到组件间通信的情况,而且也是前端开发面试常问的知识点之一。接下来开始组件间通信方式第三弹------$bus,并讲讲分别在Vue2、Vue3中的表现。 Vue2Vue3组件间通信方式汇总(1)…...
PyTorch加载数据以及Tensorboard的使用
一、PyTorch加载数据初认识 Dataset:提供一种方式去获取数据及其label 如何获取每一个数据及其label 总共有多少的数据 Dataloader:为后面的网络提供不同的数据形式 数据集 在编译器中导入Dataset from torch.utils.data import Dataset 可以在jupyter中查看Dataset官方文档&…...

TensorFlow是什么
TensorFlow是什么 Tensorflow是一个Google开发的第二代机器学习系统,克服了第一代系统DistBelief仅能开发神经网络算法、难以配置、依赖Google内部硬件等局限性,应用更加广泛,并且提高了灵活性和可移植性,速度和扩展性也有了大幅…...
docker-compose 安装Sonar并集成gitlab
文章目录 1. 前置条件2. 编写docker-compose-sonar.yml文件3. 集成 gitlab4. Sonar Login with GitLab 1. 前置条件 安装docker-compose 安装docker 创建容器运行的特有网络 创建挂载目录 2. 编写docker-compose-sonar.yml文件 version: "3" services:sonar-postgre…...

支付平台在选择服务器租用时要注意什么?
如果要建设一个支付平台的话要进行服务器租用,一旦涉及到钱的方面就必须要顾虑到多方面,这样才能保证安全性,今天小编就给大家讲一讲要注意什么呢? 1、带宽:带宽是业务稳定性的直接因素,只有带宽充足,这样…...

IDEA2018升级2023,lombok插件不兼容导致get/set方法无法使用
1、问题 最近了解到一款叫CodeGeeX 的智能编程助手,想要试用一下,但是IDEA2018版本太低了,没有CodeGeeX插件,于是打算将IDEA升级到2023.2.5版本,具体升级过程略过,升级完成后,启动项目…...

企业微信服务商代开发模式获取授权企业的客户信息
服务商代开发素材: 服务商可信ip 企业微信认证 测试时不用再次创建一个企业微信,可以用当前的企业微信作为授权企业使用一、创建代开发应用模板 1,代开发模板回调URL配置 参考 注意:保存代开发应用模板时的corpId是服务商的企业…...

库存管理方法有哪些
库存管理是工作中一个离不开的话题,不管是仓管还是业务员都或多或少接触过库存管理方面的工作,例如:进货、销售、库存盘点等等这些都属于库存管理的范筹,那么库存管理方法有哪些?用哪种方法管理库存比较好,…...

数字化车间推动制造业生产创新
一、数字化车间应用场景 1:资源智能化管理 数字化车间通过搭建智能化的设备监测系统,实时采集和监控设备的运行状态和生产数据,对设备进行实时管理和维护,降低故障率和维修成本。同时,通过对生产过程中的数据采集和分…...
Linux的安装及管理程序
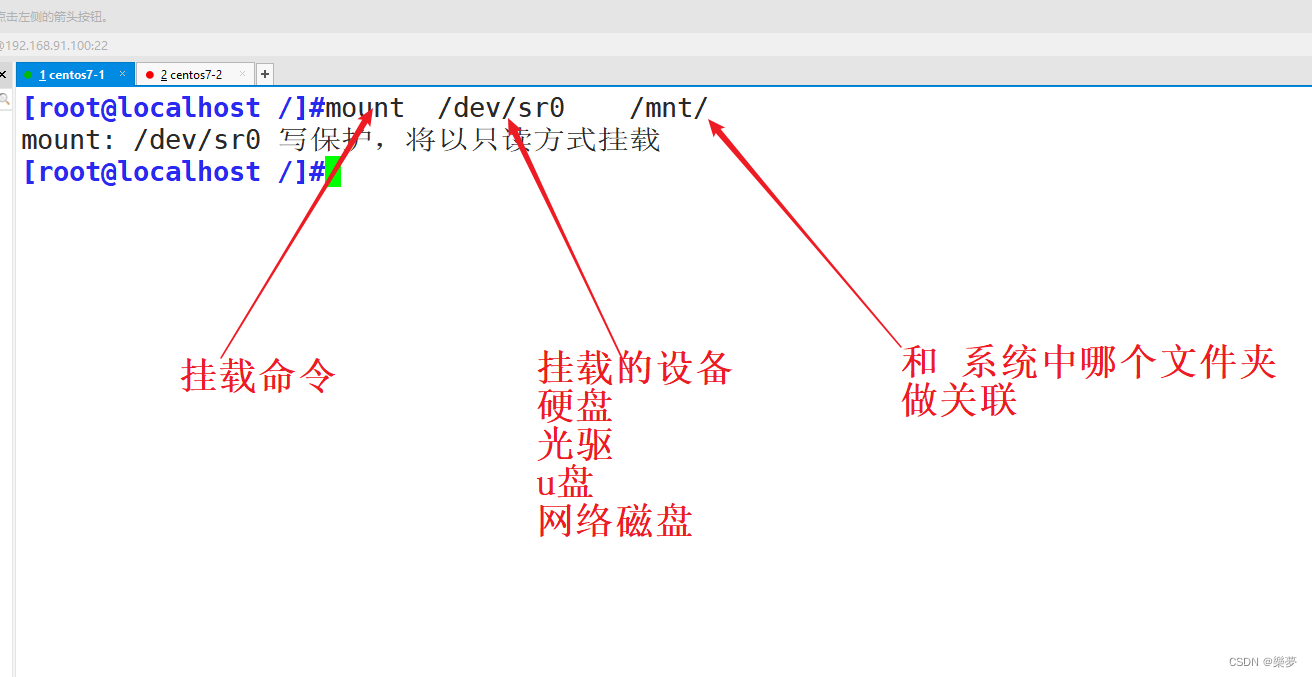
一、如何在linux安装卸载软件 1. 编译安装 灵活性较高 难度较大 可以安装较新的版本 2. rpm安装(redhat) linux 包安装 查软件信息:是否安装,文件列表 rpm 软件名 3. yum yum是RPM升级版本,解决rpm的弊端 安装软件 首…...

c语言-表达式求值
目录 前言一、隐式类型转换1.1 整型提升 二、算术转换三、操作符的属性四、问题表达式总结 前言 表达式求值的顺序一部分由操作符的优先级和结合性决定。 有些表达式的操作数在求值的过程中可能需要转换为其他类型 一、隐式类型转换 隐式类型转换是在编译器自动进行的类型转换…...

小型洗衣机哪个牌子质量好?口碑最好的四款小型洗衣机推荐
随着科技的快速发展,现在的人们越来越注重自己的卫生问题,不仅在吃上面会注重卫生问题,在用的上面也会更加严格要求,而衣服做为我们最贴身的东西,我们对它的要求也会更加高,所以最近这几年较火爆的无疑是内…...

springCould中的Ribbon-从小白开始【5】
目录 1.什么是Ribbo❤️❤️❤️ 2.eureka自带Ribbon ❤️❤️❤️ 3. RestTemplate❤️❤️❤️ 4.IRule❤️❤️❤️ 5.负载均衡算法❤️❤️❤️ 1.什么是Ribbo 1.Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端,负载均衡的工具。2.主要功能是提供客户端的软件…...
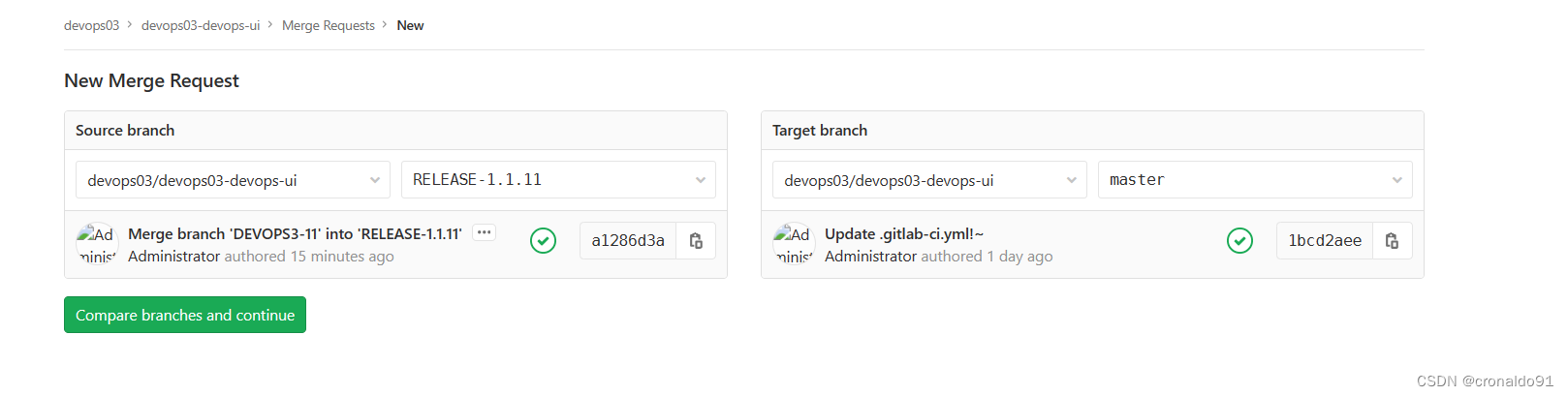
持续集成交付CICD:Jira 发布流水线
目录 一、实验 1.环境 2.GitLab 查看项目 3.Jira 远程触发 Jenkins 实现合并 GitLab 分支 4.K8S master节点操作 5.Jira 发布流水线 一、实验 1.环境 (1)主机 表1 主机 主机架构版本IP备注master1K8S master节点1.20.6192.168.204.180 jenkins…...

ARMv8汇编指令实战解析:adrp、adr与adr_l在Linux内核启动中的应用
1. ARMv8寻址指令家族概览 在ARMv8架构中,adrp、adr和adr_l这三个指令堪称地址计算的"三剑客"。它们虽然名字相似,但各自有着独特的设计哲学和应用场景。就像搬家时选择不同的交通工具——adr是短途搬运的小推车,adrp是能承载重物的…...

从零构建树莓派人脸识别门禁:硬件选型、环境部署与实战避坑
1. 硬件选型与采购清单 第一次玩树莓派人脸识别项目时,我在淘宝上花了整整三天对比各种硬件参数。当时最纠结的就是摄像头模块——普通USB摄像头才30块钱,而官方推荐的Raspberry Pi Camera Module V2要200多。后来实测发现,这差价真不能省。 …...

教无人机操控3年,这款仿真软件让我彻底告别“真机实训焦虑”
作为无人机专业实操教师,深耕一线教学3年,最大的痛点莫过于“真机实训难”——相信同行们都有共鸣,无人机操控教学看似是“练手”,实则处处是坑,每一个难题都让人头疼不已,甚至一度让我陷入教学焦虑。整理了…...

5个步骤掌握PatternMaster图案生成工具:提升设计效率的自动化解决方案
5个步骤掌握PatternMaster图案生成工具:提升设计效率的自动化解决方案 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在数字设计领域,效率与创意往往难以兼…...

Qwen3.5-9B惊艳案例:上传X光片→识别骨折位置→标注解剖结构→生成诊断报告草稿
Qwen3.5-9B惊艳案例:上传X光片→识别骨折位置→标注解剖结构→生成诊断报告草稿 1. 医疗影像分析的革命性突破 想象一下这样的场景:一位急诊医生面对堆积如山的X光片,需要在短时间内做出准确诊断。传统方法需要医生逐张查看、标注异常部位、…...

Fay数字人框架终极指南:30分钟打造你的AI虚拟助手
Fay数字人框架终极指南:30分钟打造你的AI虚拟助手 【免费下载链接】Fay Fay 是一个开源的数字人类框架,集成了语言模型和数字字符。它为各种应用程序提供零售、助手和代理版本,如虚拟购物指南、广播公司、助理、服务员、教师以及基于语音或文…...

Simulink仿真速度太慢?试试用C Mex S函数给模型“提提速”
Simulink性能优化实战:用C Mex S函数突破仿真速度瓶颈 当Simulink模型运行缓慢时,工程师们常常陷入漫长的等待。本文将揭示如何通过C Mex S函数这一利器,将仿真速度提升10倍以上,特别适合处理复杂算法、图像处理和大规模系统仿真等…...

深求·墨鉴快速部署指南:3步搞定,体验优雅的文档图片转文字
深求墨鉴快速部署指南:3步搞定,体验优雅的文档图片转文字 1. 引言:当OCR遇见东方美学 在日常办公和学习中,我们经常需要将纸质文档、书籍图片或手写笔记转换为可编辑的电子文本。传统OCR工具往往只注重功能实现,而忽…...

命名实体识别工具:从技术突破到业务价值重构
命名实体识别工具:从技术突破到业务价值重构 【免费下载链接】W2NER 项目地址: https://gitcode.com/gh_mirrors/w2/W2NER 1 解锁NER效率新范式 传统NER为何在长文本中频频失效? 当面对医疗病例中"高血压引发的左心室肥厚导致劳力性呼吸困…...

软考:团队管理与绩效域50大实战难题破解清单,写进论文直接加分!
对于软考高项(信息系统项目管理师)的考生来说,论文是决定成败的关键。而一篇高分论文的核心,在于能否用真实、具体的项目实践,去论证你对项目管理知识体系的深刻理解。项目团队管理和项目绩效域是论文中最常考、也最容…...