生物系统学中的进化树构建和分析R工具包V.PhyloMaker2的介绍和详细使用
V.PhyloMaker2是一个R语言的工具包,专门用于构建和分析生物系统学中的进化树(也称为系统发育树或phylogenetic tree)。以下是对V.PhyloMaker2的一些基本介绍和使用说明:
论文介绍:V.PhyloMaker2: An updated and enlarged R package that can generate very large phylogenies for vascular plants - ScienceDirect
github仓库代码:jinyizju/V.PhyloMaker2: This package (an updated version of 'V.PhyloMaker') can generate a phylogenetic tree for vascular plants based on three different botanical nomenclature systems. (github.com)
介绍:
V.PhyloMaker2提供了一系列的函数和方法,帮助用户处理和分析分子序列数据,包括但不限于:
- 数据预处理:对分子序列数据进行质量控制、格式转换和多重比对。
- 进化树构建:支持多种流行的进化树构建方法,如最大似然法(Maximum Likelihood)、贝叶斯推断法(Bayesian Inference)等。
- 进化树优化:通过搜索最优的树形结构和参数组合来提高进化树的准确性。
- 进化树可视化:提供丰富的图形选项来定制和美化进化树的显示。
- 树形数据分析:包括节点支持度评估、分支长度分析、祖先状态重建等。
详细使用:
由于V.PhyloMaker2的具体使用会涉及到具体的代码操作和数据分析过程,以下是一些基本的使用步骤:
-
安装V.PhyloMaker2: 在R环境中,使用
install.packages("V.PhyloMaker2")命令来安装这个包。#BioManager安装 if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager") BiocManager::install("V.PhyloMaker2")#github 安装 install.packages("devtools")library(devtools) install_github("JinYongJiang/V.PhyloMaker") -
加载V.PhyloMaker2: 安装后,使用
library(V.PhyloMaker2)命令来加载这个包。 -
数据预处理: 根据你的数据类型和格式,使用相应的函数进行数据导入和预处理。例如,如果你的数据是fasta格式的序列文件,可以使用
read.FASTA()函数将其读入R。# 导入数据:首先,你需要将你的序列数据导入到R中。这通常是以fasta或 nexus格式存储的。 library(ape) sequences <- read.fasta("your_file.fasta")#数据清理:检查并处理缺失数据、异质性(例如,核苷酸替换)、和错误。 # 查看是否存在任何缺失数据 sum(is.na(sequences))# 如果存在缺失数据,可以考虑删除含有缺失数据的行 sequences <- sequences[!apply(sequences, 1, function(x) any(is.na(x))), ]# 或者用某种方法填补缺失数据(例如,通过平均或中位数) sequences[is.na(sequences)] <- median(sequences, na.rm = TRUE) -
多重比对: 使用
muscle()或其他比对函数对序列进行比对。#序列对齐:对于DNA或蛋白质序列,你需要进行序列对齐。 aligned_sequences <- muscle(sequences)#转换为距离矩阵:将对齐后的序列转换为距离矩阵,这通常是后续构建系统发育树的步骤。 dist_matrix <- dist.dna(aligned_sequences) -
进化树构建: 使用
build.tree()或其他相关函数,根据你的数据和研究目标选择合适的树构建方法。# 假设您已经有了一个包含序列数据的数据框df,并且列名是物种名称 # df <- data.frame(sequence1, sequence2, ..., sequenceN) # 或前面的 data_matrix# 使用build.tree()函数构建进化树 # 这里的参数是假设的,实际参数需要参考V.PhyloMaker包的文档 tree <- build.tree(data = df(或data_matrix), seq_type = "dna", # 数据类型,可以是"dna"、"rna"或"protein"method = "neighbor_joining", # 构建树的方法,例如"neighbor_joining"(邻接法)或"maximum_likelihood"(最大似然法)distance_method = "kimura") # 距离计算方法,例如"kimura"(金氏距离) -
进化树优化: 对构建的初步树进行优化,例如使用
optimize.tree()函数。# 假设你已经使用 build.tree() 建立了一个决策树模型 # 假设 tree_model 是你建立的模型# 查看建立的树的概况 summary(tree_model)# 根据交叉验证选择最佳的剪枝参数 prune_model <- prune.tree(tree_model)# 查看剪枝后的树的概况 summary(prune_model)# 如果需要,你可以根据需要进一步调整剪枝参数 -
进化树可视化: 使用
plot.tree()函数将进化树可视化,并通过调整各种参数来定制图形。# 可视化决策树并调整参数 plot(tree_model, type = "uniform", fsize = 0.8, cex = 0.8, label = "all")# 添加各种参数以定制图形 plot(my_tree,type = "fan", # 树的类型,可以是"phylogram"(分支长度代表进化时间)、"cladogram"(所有分支长度相等)或"fan"(扇形树)show.tip.label = TRUE, # 是否显示叶节点的标签edge.width = 2, # 分支线的宽度edge.color = "black", # 分支线的颜色tip.color = "blue", # 叶节点的颜色no.margin = TRUE, # 是否移除图形边框cex = 0.8, # 标签的字体大小font = 2, # 标签的字体类型main = "My Evolutionary Tree", # 图形的标题sub = "Customized with plot() function") # 图形的副标题 -
树形数据分析: 根据你的研究问题,选择相应的函数进行树形数据分析,如节点支持度评估、分支长度分析等。
# 安装并加载相关包 install.packages("ape") install.packages("phytools") library(ape) library(phytools)# 假设 tree 是你的树形数据# 计算节点支持度 bootstrap_tree <- bootstrap.phylo(tree, FUN = your_function_for_tree, B = 100) # your_function_for_tree 是用于估计树的函数# 生成共识树 consensus_tree <- consensus(bootstrap_tree)# 计算树的相似性矩阵 coph_matrix <- cophenetic(tree)# 绘制共演化历史图 cophyloplot(tree1, tree2)
补充分析示例:
树形数据分析可以使用R中的多个包来实现,例如ape、phangorn、ggtree等。下面是一个简单的示例代码,使用了ape包来进行树形数据分析。
首先,我们需要安装并加载ape包:
install.packages("ape")
library(ape)
接下来,我们可以根据需求读取树形数据。假设我们有一棵简单的进化树,包含5个物种,并且我们想要计算节点的支持度值:
# 创建一个简单的进化树
tree <- rtree(5)# 计算节点的支持度值
supports <- node.depths(tree)
接下来,我们可以绘制树形图,并标记节点的支持度值:
# 绘制树形图
plot(tree, show.node.label = TRUE)# 标记节点支持度值
nodelabels(round(supports, 2), bg = "white")
要分析分支长度,我们可以使用cophenetic.phylo()函数计算树的协同形态矩阵,然后使用plot()函数绘制分支长度图:
# 计算协同形态矩阵
cophenetic_matrix <- cophenetic(tree)# 绘制分支长度图
plot(cophenetic_matrix, main = "Branch Lengths", xlab = "Pairwise Distances")
相似工具包S.PhyloMaker
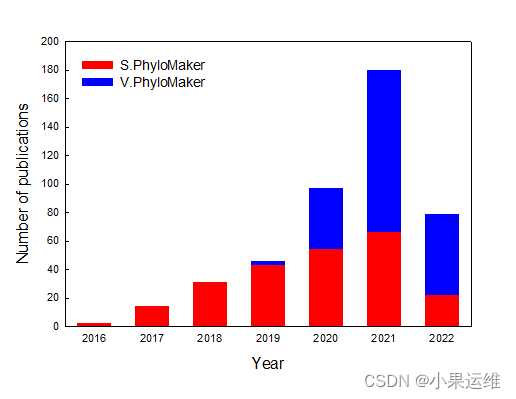
S.PhyloMaker的介绍和使用看这里:种系进化树分析和构建工具R工具包S.phyloMaker的介绍和详细使用方法-CSDN博客
相关文章:
生物系统学中的进化树构建和分析R工具包V.PhyloMaker2的介绍和详细使用
V.PhyloMaker2是一个R语言的工具包,专门用于构建和分析生物系统学中的进化树(也称为系统发育树或phylogenetic tree)。以下是对V.PhyloMaker2的一些基本介绍和使用说明: 论文介绍:V.PhyloMaker2: An updated and enla…...

XStream 反序列化漏洞 CVE-2021-39144 已亲自复现
XStream 反序列化漏洞 CVE-2021-39144 已亲自复现 漏洞名称漏洞描述影响版本 漏洞复现环境搭建 修复建议总结 漏洞名称 漏洞描述 在Unmarshalling Time处包含用于重新创建前一对象的类型信息。XStream基于这些类型的信息创建新实例。攻击者可以控制输入流并替换或注入对象&am…...

深入剖析LinkedList:揭秘底层原理
文章目录 一、 概述LinkedList1.1 LinkedList简介1.2 LinkedList的优点和缺点 二、 LinkedList数据结构分析2.1 Node节点结构体解析2.2 LinkedList实现了双向链表的原因2.3 LinkedList如何实现了链表的基本操作(增删改查)2.4 LinkedList的遍历方式 三、 …...

计算机网络复习-OSI TCP/IP 物理层
我膨胀了,挂我啊~ 作者简介: 每年都吐槽吉师网安奇怪的课程安排、全校正经学网络安全不超20人情景以及割韭菜企业合作的FW,今年是第一年。。 TCP/IP模型 先做两道题: TCP/IP协议模型由高层到低层分为哪几层: 这题…...

虚拟机服务器中了lockbit2.0/3.0勒索病毒怎么处理,数据恢复应对步骤
网络技术的不断发展也为网络威胁带来了安全隐患,近期,对于许多大型企业来说,许多企业的虚拟机服务器系统遭到了lockbit2.0/3.0勒索病毒攻击,导致企业所有计算机系统瘫痪,无法正常工作,严重影响了企业的正常…...

【MATLAB】 RGB和YCbCr互转
前言 在视频、图像处理领域经常会遇到不同色域图像的转换,比如RGB、YUV、YCbCr色域间的转换,这里提供一组转换公式,供大家参考。 色彩模型 RGB RGB色彩模型是一种用于表示数字图像的颜色空间,其中"RGB"代表红色&…...

【线性代数】决定张成空间的最少向量线性无关吗?
答1: 是的,张成空间的最少向量是线性无关的。 在数学中,张成空间(span space)是一个向量空间,它由一组向量通过线性组合(即每个向量乘以一个标量)生成。如果这组向量是线性无关的&…...
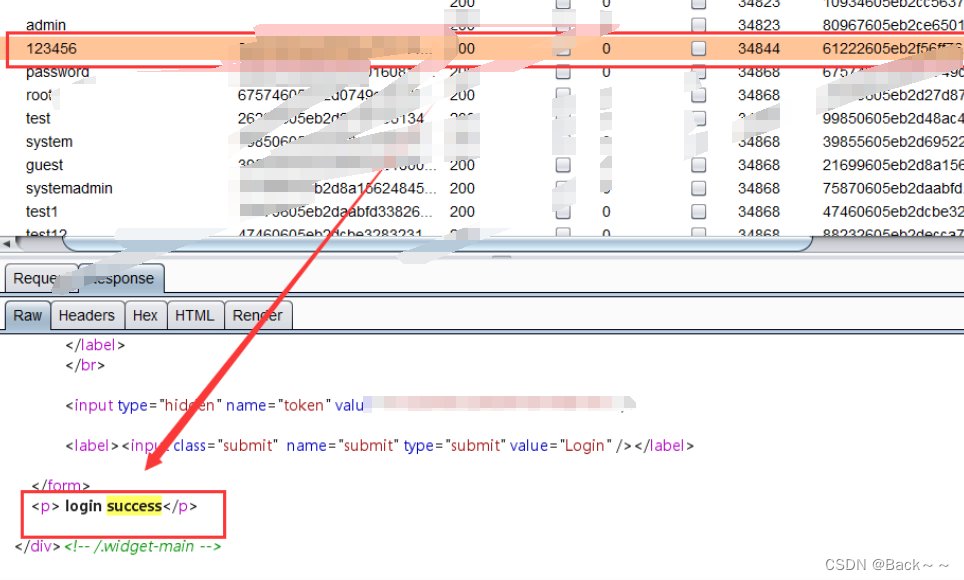
暴力破解(Pikachu)
基于表单的暴力破解 先随便输入一下,然后抓包,进行字典爆破 验证码绕过(on server) server服务端要输入正确的验证码后进行爆破 之后的操作没什么不一样 验证码绕过(on client) 这个也需要输入验证码,但是后面进行字典爆破的时候…...

如何使用CMake查看opencv封装好的函数
当我们有时想查看opencv自带的函数的源代码,比如函数cvCreateImage, 此时我们选中cvCreateImage, 点击鼠标右键->转到定义,我们会很惊讶的发现为什么只看到了cvCreateImage的一个简单声明,而没有源代码呢?这是因为openCV将很多…...

微盛·企微管家:用户运营API集成,电商无代码解决方案
连接电商平台的新纪元:微盛企微管家 随着电子商务的蓬勃发展,电商平台的高效运营已经成为企业成功的关键。在这个新纪元里,微盛企微管家以其创新的无代码开发连接方案,成为企业之间连接电商平台的强大工具。它允许企业轻松集成电…...
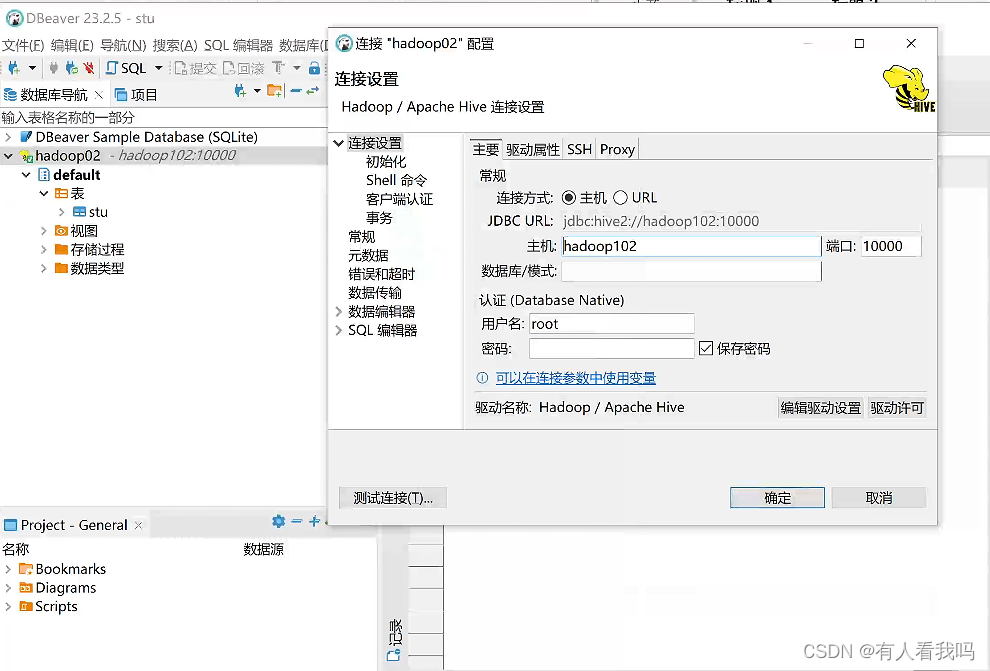
Hive 部署
一、介绍 Apache Hive是一个分布式、容错的数据仓库系统,支持大规模的分析。Hive Metastore(HMS)提供了一个中央元数据存储库,可以轻松地进行分析,以做出明智的数据驱动决策,因此它是许多数据湖架构的关键组…...

CopyOnWriteArrayList源码阅读
1、构造方法 无参构造函数 //创建一个空数组,赋值给array引用 public CopyOnWriteArrayList() {setArray(new Object[0]); }//仅通过getArray / setArray访问的数组。 private transient volatile Object[] array;//设置数组 final void setArray(Object[] a) {arra…...

Windows操作系统:共享文件夹,防火墙的设置
1.共享文件夹 1.1 共享文件夹的优点 1.2 共享文件夹的优缺点 1.3 实例操作 编辑 2.防火墙设置 2.1 8080端口设置 3.思维导图 1.共享文件夹 1.1 共享文件夹的优点 优点 协作和团队合作:共享文件夹使多个用户能够在同一文件夹中协作和编辑文件。这促进了团…...
STM32独立看门狗
时钟频率 40KHZ 看门狗简介 STM32F10xxx 内置两个看门狗,提供了更高的安全性、时间的精确性和使用的灵活性。两个看 门狗设备 ( 独立看门狗和窗口看门狗 ) 可用来检测和解决由软件错误引起的故障;当计数器达到给 定的超时值时,触发一个中…...

财务数据智能化:用AI工具高效制作财务分析PPT报告
Step1: 文章内容提取 WPS AI 直接打开文件,在AI对话框里输入下面指令: 假设你是财务总监,公司考虑与茅台进行业务合作、投资或收购,请整合下面茅台2021年和2022年的财务报告信息。整理有关茅台财务状况和潜在投资回报的信息&…...

vue3中使用three.js记录
记录一下three.js配合vitevue3的使用。 安装three.js 使用npm安装: npm install --save three开始使用 1.定义一个div <template><div ref"threeContainer" class"w-full h-full"></div> </template>可以给这个di…...
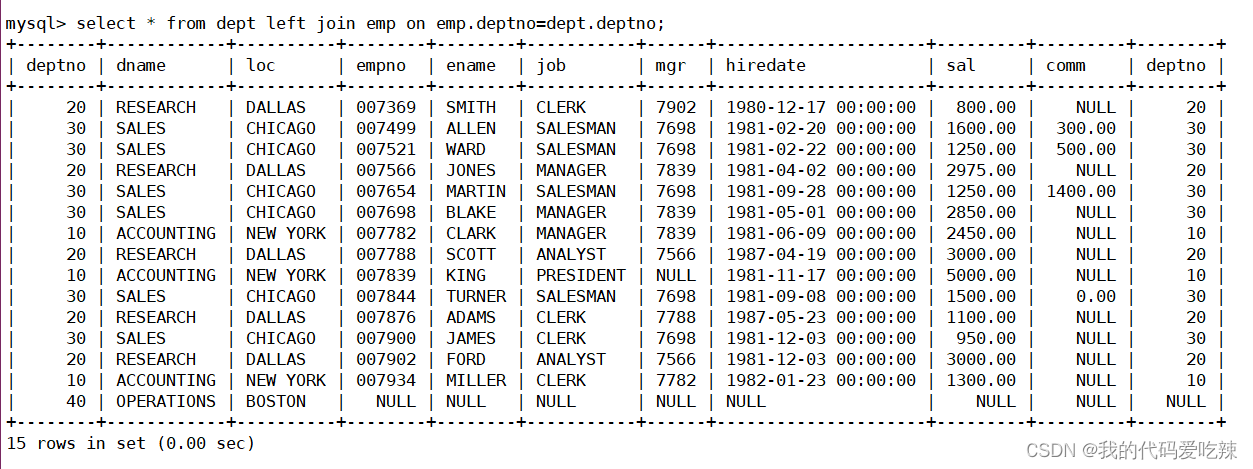
MySQL——表的内外连接
目录 一.内连接 二.外连接 1.左外连接 2.右外连接 一.内连接 表的连接分为内连和外连 内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。 语法: s…...

基于IPP-FFT的线性调频Z(Chirp-Z,CZT)的C++类库封装并导出为dll(固定接口支持更新)
上一篇分析了三种不同导出C++类方法的优缺点,同时也讲了如何基于IPP库将FFT函数封装为C++类库,并导出为支持更新的dll库供他人调用。 在此基础上,结合前面的CZT的原理及代码实现,可以很容易将CZT变换也封装为C++类库并导出为dll,关于CZT的原理和实现,如有问题请参考: …...

【C语言】指针
基本概念 在C语言中,指针是一种非常重要的数据类型,它用于存储变量的内存地址。指针提供了对内存中数据的直接访问,使得在C语言中可以进行灵活的内存操作和数据传递。以下是关于C语言指针的一些基本概念: 1. 指针的声明ÿ…...

PostgreSql 索引使用技巧
索引种类详情可参考《PostgreSql 索引》 一、适合创建索引的场景 经常与其他表进行连接的表,在连接字段上应该建索引。经常出现在 WHERE 子句中的字段,特别是大表的字段,应该建索引。经常出现在 ORDER BY 子句中的字段,应该建索…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...