网络通信-Linux 对网络通信的实现
Linux 网络 IO 模型
同步和异步,阻塞和非阻塞
同步和异步
阻塞和非阻塞
两者的组合
Linux 下的五种 I/O 模型

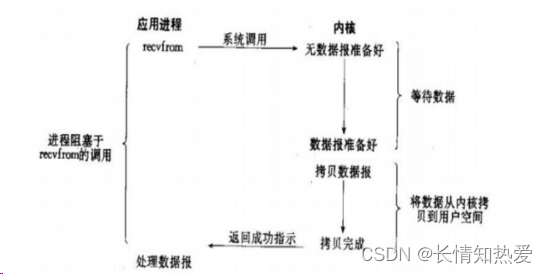
阻塞 IO 模型

I/O 复用模型

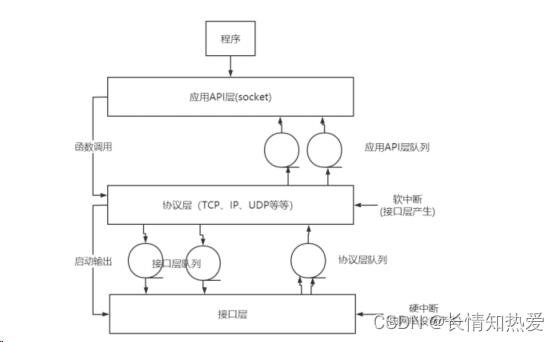
Linux 下的 IO 复用编程
文件描述符 FD
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval*timeout);
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
epoll
int epoll_create(int size) ;int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) ;int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
select、poll、epoll 的比较


2、FD 剧增后带来的 IO 效率问题
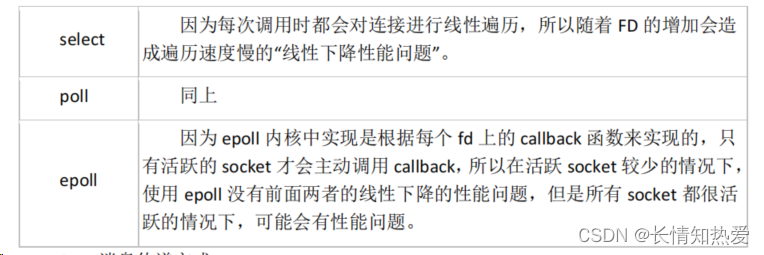
3、 消息传递方式

epoll 高效原理和底层机制分析

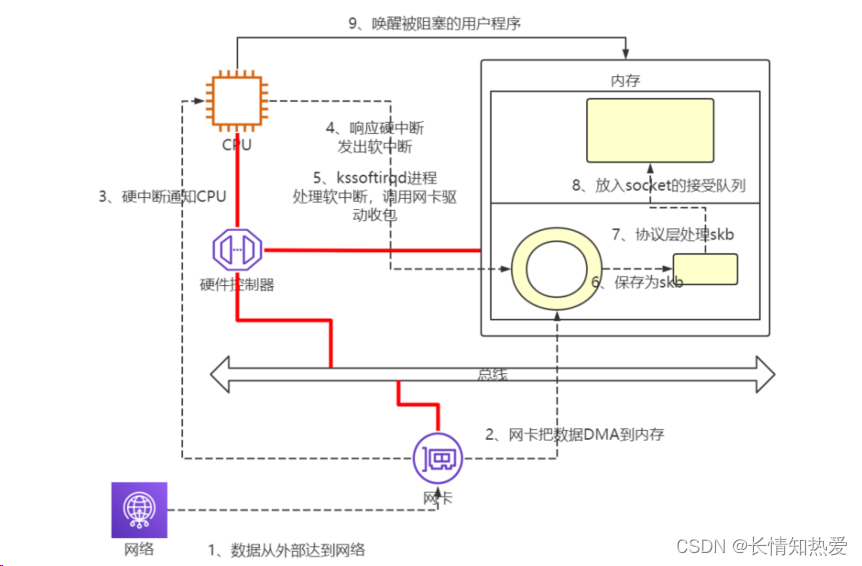
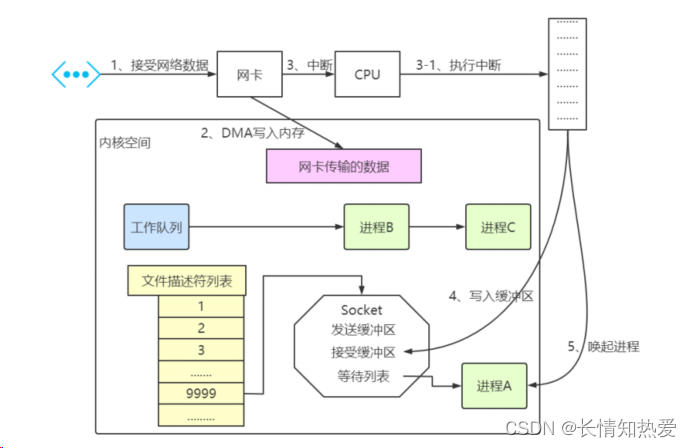
从网卡接收数据说起
如何知道接收了数据?
中断、上半部、下半部
内核收包的概览
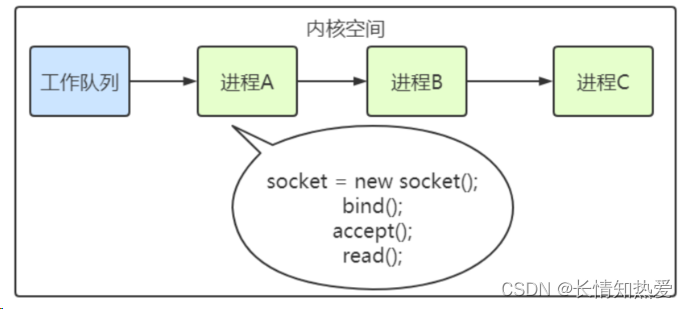
进程阻塞
//创建 socketint s = socket(AF_INET, SOCK_STREAM, 0);//绑定bind(s, ...)//监听listen(s, ...)//接受客户端连接int c = accept(s, ...)//接收客户端数据recv(c, ...);//将数据打印出来printf(...)
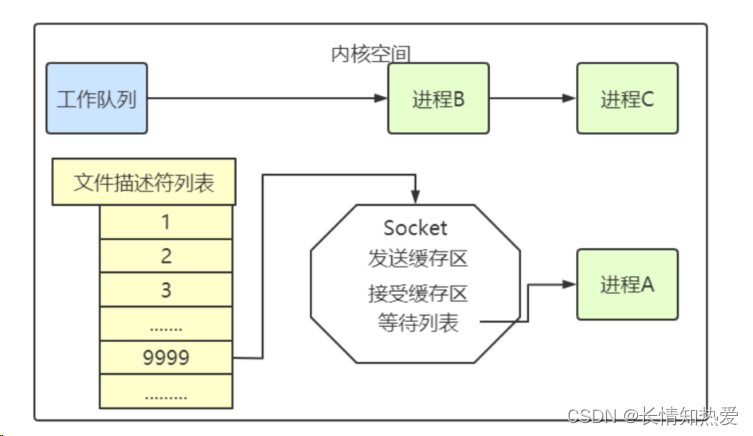
内核接收网络数据
同时监视多个 socket 的简单方法
int fds[] = 存放需要监听的 socket
while(1){int n = select(..., fds, ...)for(int i=0; i < fds.count; i++){if(FD_ISSET(fds[i], ...)){//fds[i]的数据处理}} }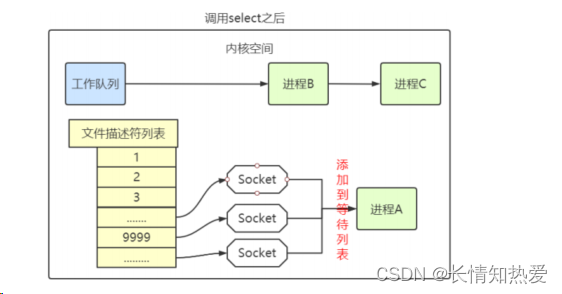
epoll 的设计思路
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的 socket 添加到 epfd 中
while(1){int n = epoll_wait(...)for(接收到数据的 socket){//处理} }epoll 的原理和流程
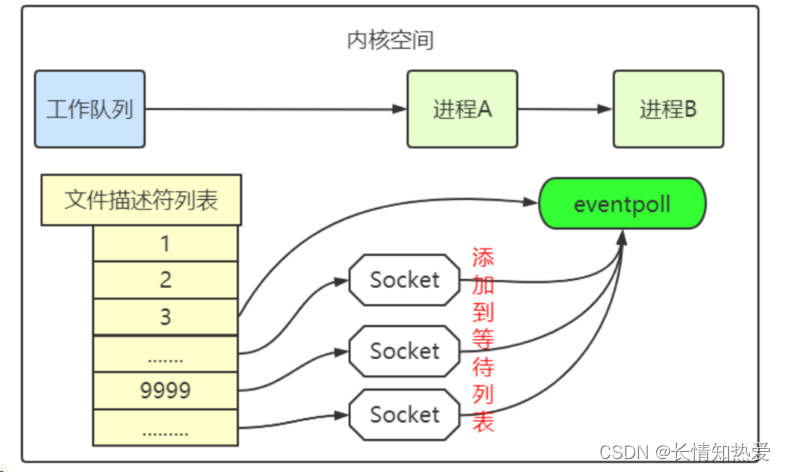
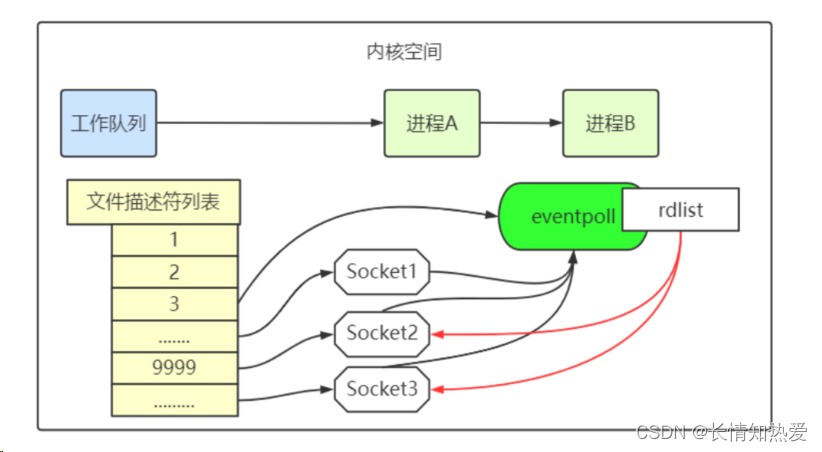
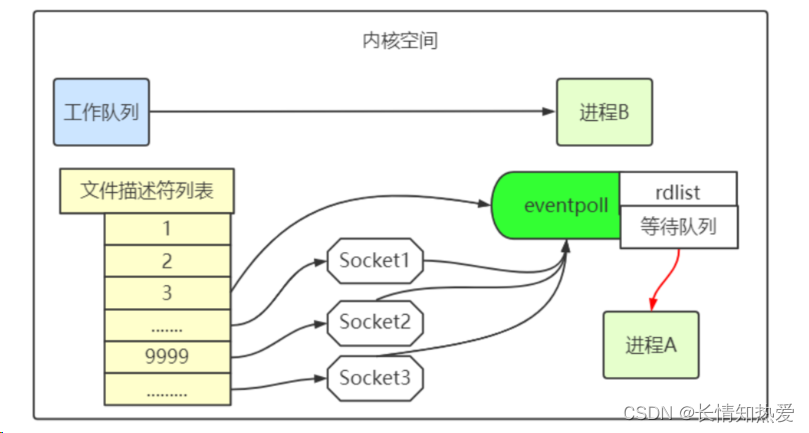
epoll 的实现细节
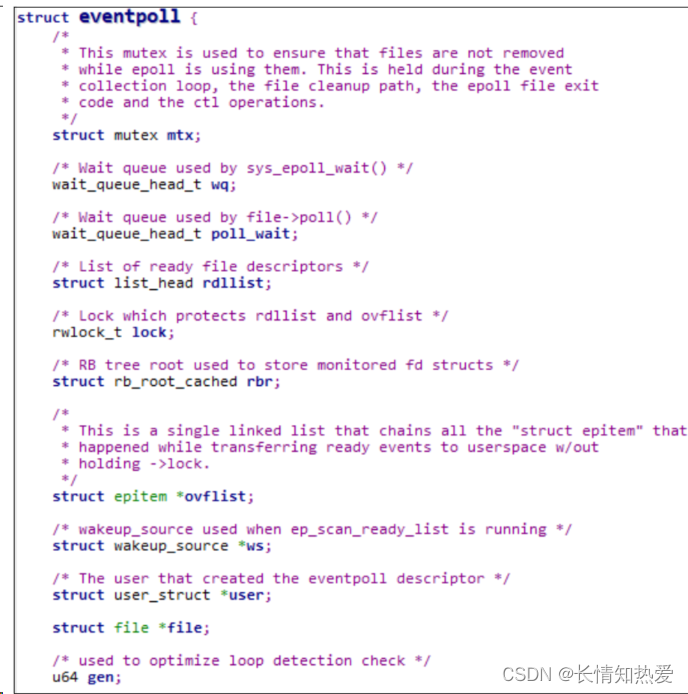
就绪列表引用着就绪的 socket,所以它应能够快速的插入数据。


总结
相关文章:
网络通信-Linux 对网络通信的实现
Linux 网络 IO 模型 同步和异步,阻塞和非阻塞 同步和异步 关注的是调用方是否主动获取结果 同步:同步的意思就是调用方需要主动等待结果的返回 异步:异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知࿰…...

mysql修改密码
mysql -u root -p ALTER USER USER() IDENTIFIED BY root; FLUSH PRIVILEGES; 其它cmd: ①查看端口,找到占用3306端口的进程:命令行输入 netstat -aon ,找到端口号为3306的对应的PID ②结束占用端口3306的进程:命令…...
(int) ) ) (int))
深入解析C语言中void (*signal(int ,void(*)(int) ) ) (int)
目录 深入解析C语言中的signal函数声明 1. signal函数声明 1.1 signal是一个函数 1.2 返回类型是一个函数指针 2. 函数指针的理解 3. 简化声明使用typedef 为啥不这么写typedef void (*)(int) acc? 代码: 结论 深入解析C语言中的signal函数声明…...

网站显示不安全警告怎么办?消除网站不安全警告超全指南
网站显示不安全警告怎么办?当用户访问你的网站,而您的网站没有部署SSL证书实现HTTPS加密时,网站就会显示不安全警告,这种警告,不仅有可能阻止用户继续浏览网站,影响网站声誉,还有可能影响网站在…...

[SWPUCTF 2021 新生赛]finalrce
[SWPUCTF 2021 新生赛]finalrce wp 注:本文参考了 NSSCTF Leaderchen 师傅的题解,并修补了其中些许不足。 此外,参考了 命令执行(RCE)面对各种过滤,骚姿势绕过总结 题目代码: <?php highlight_file(__FILE__); …...

如何底层调用最快地复制OPC数据到关系数据库
计算机上的二大应用,一是从WEB服务器上获得数据,另一种是向关系数据库中写入数据。在上集我已提出了一个从WEB上获得OPC数据的独创方法,现在谈谈第二种如何快速地把OPC数据写进到数据库中,这也是Calssic OPC最典型的一个应用场景。…...
接口测试工具——ApiFox使用初体验 postman导出和ApiFox导入
目录 ApiFox使用初体验初步使用从postman导出到apifox导入 IDEA简单测试Postman测试工具post请求 接口测试工具swaggerKnife4j1.引入依赖2.配置3.常用注解4.接口测试 JMeter什么是JMeter?JMeter安装配置1.官网下载2.下载后解压3.汉语设置 JMeter的使用方法1.新建线程组2.设置参…...
搜维尔科技:经脉腧穴虚拟针灸VR虚拟教学平台AcuMap软件案例分享
北京中医药大学经脉腧穴VR虚拟教学平台案例 主要产品 HTCvive ,AcuMap; 实施内容 一、项目说明 (1)穴位取穴与体表解剖标志关系;(2)穴下层次解剖及周围解剖结构展示; …...

Jenkins的shared library相关
Jenkins的shared library是一种用于在多个Jenkins流水线项目中共享和重用代码的机制。它可以将常用的构建逻辑、工具函数或自定义步骤封装为可复用的库,并以插件的形式提供给Jenkins。 Shared library的作用主要包括以下几个方面: 代码复用:…...
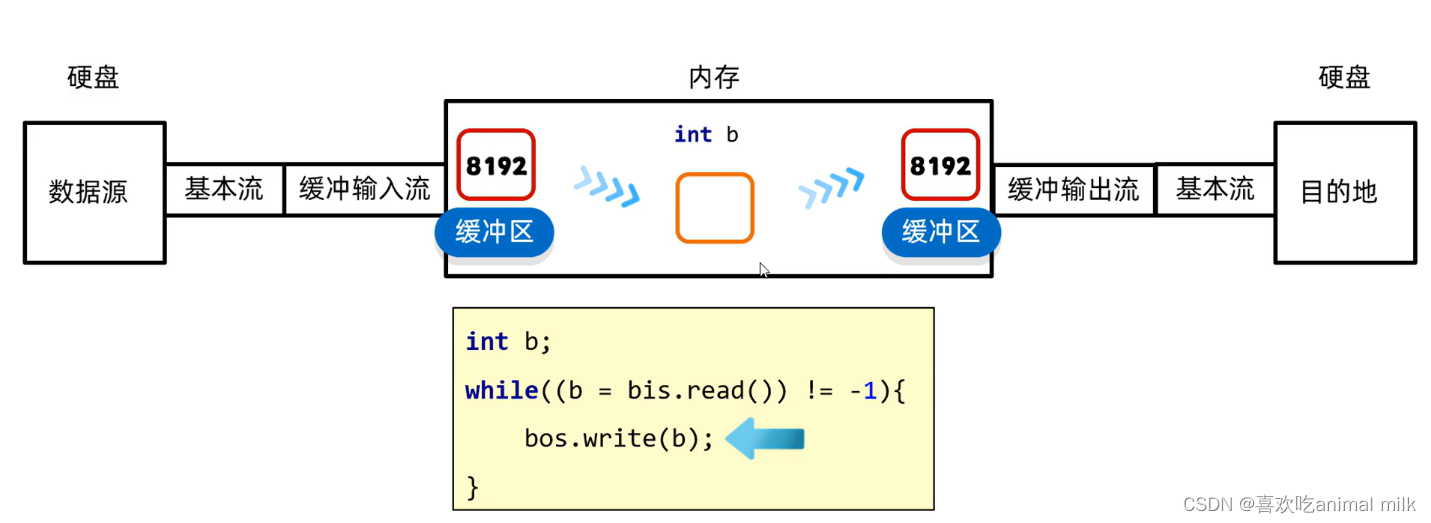
文件IO
文章目录 文章目录 前言 一 . 文件 文件路径 文件类型 Java中操作文件 File 概述 属性 构造方法 方法 createNewFile mkdir 二 . 文件内容的读写 - IO InputStream 概述 FileInputStream 概述 利用 Scanner 进行字符读取 OutputStream 概述 PrintWriter封装O…...

【日常聊聊】编程语言的未来:趋势、多样性、人工智能融合、教育与生态系统
🍎个人博客:个人主页 🏆个人专栏: 日常聊聊 ⛳️ 功不唐捐,玉汝于成 目录 前言: 正文 1. 编程语言的发展趋势 1.1 新语言和编程范式的涌现 1.2 影响和挑战 2. 编程语言的多样性 2.1 互操作性和可移…...

无需手动搜索!轻松创建IntelliJ IDEA快捷方式的Linux教程
轻松创建IntelliJ IDEA快捷方式的Linux教程 一、IntelliJ IDEA简介二、在Linux系统中创建快捷方式的好处三、命令行创建IntelliJ IDEA快捷方式四、图形界面创建IntelliJ IDEA快捷方式五、常见问题总结 一、IntelliJ IDEA简介 IntelliJ IDEA是一个由JetBrains搞的IDE࿰…...

如何去掉微博水印?用它一键去除三秒出图
微博是一款非常流行的社交媒体平台,许多人都在上面分享自己的生活点滴和心得体会。但是,有时候我们会发现,在上传图片时,微博会自动添加水印,这会影响到图片的美观度。那么,如何去掉微博水印呢?…...

Golang 泛型实现原理
文章目录 1.什么是泛型?2.有 interface{} 为什么还要有泛型?3.泛型有哪些特性?3.1 类型参数泛型函数泛型类型 3.2 类型约束3.3 类型集3.4 约束元素任意类型约束元素近似约束元素联合约束元素约束中的可比类型 3.5 类型推断 4.实现原理4.1 类型擦除虚方法…...
[玩转AIGC]LLaMA2之如何微调模型
目录 1、下载训练脚本2、 下载模型2.1、申请下载权限2.2、模型下载 3、模型微调3.1、使用单卡微调3.2、使用多卡训练: 1、下载训练脚本 首先我们从github上下载Llama 2的微调代码:GitHub - facebookresearch/llama-recipes: Examples and recipes for L…...
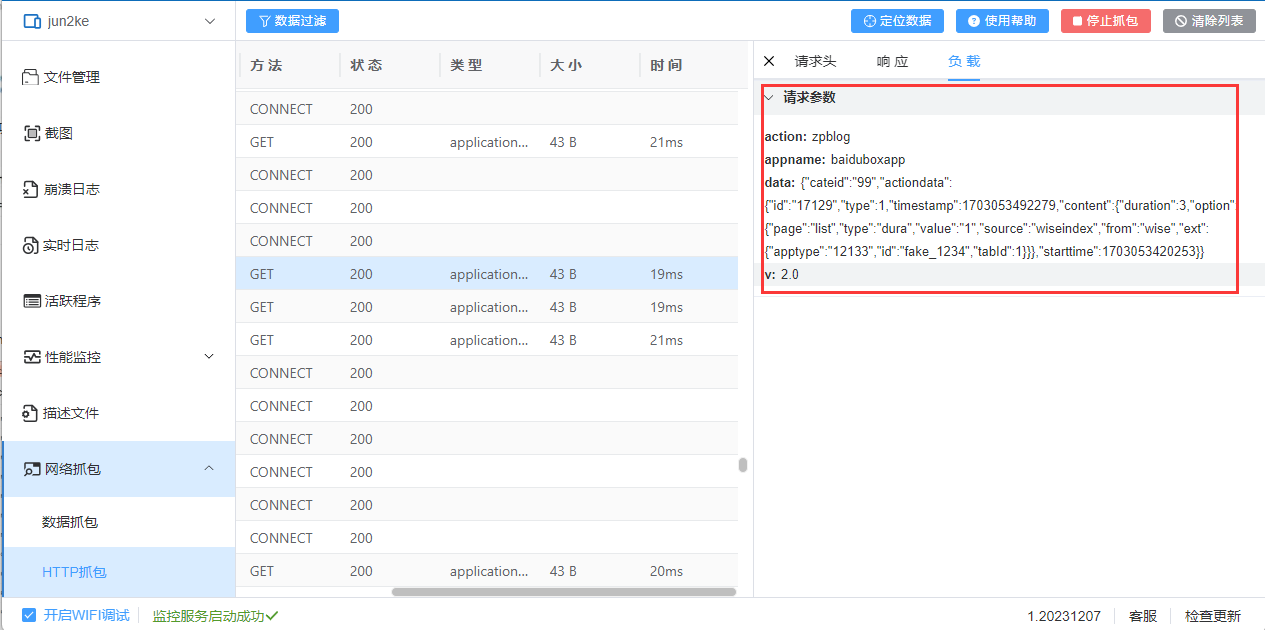
使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解
摘要 本文博客将介绍如何在iOS环境下使用克魔助手进行数据抓包和HTTP抓包。通过抓包,开发者可以分析移动应用程序的网络请求发送和接收过程,识别潜在的性能和安全问题,提高应用的质量和安全性。 引言 在移动应用程序的开发和测试过程中&am…...

【递归 回溯】LeetCode-301. 删除无效的括号
301. 删除无效的括号。 给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。 返回所有可能的结果。答案可以按 任意顺序 返回。 示例 1: 输入:s "()())()" 输出:[…...

C++ 基本的输入输出
C 标准库提供了一组丰富的输入/输出功能,我们将在后续的章节进行介绍。本章将讨论 C 编程中最基本和最常见的 I/O 操作。 C 的 I/O 发生在流中,流是字节序列。如果字节流是从设备(如键盘、磁盘驱动器、网络连接等)流向内存&#…...
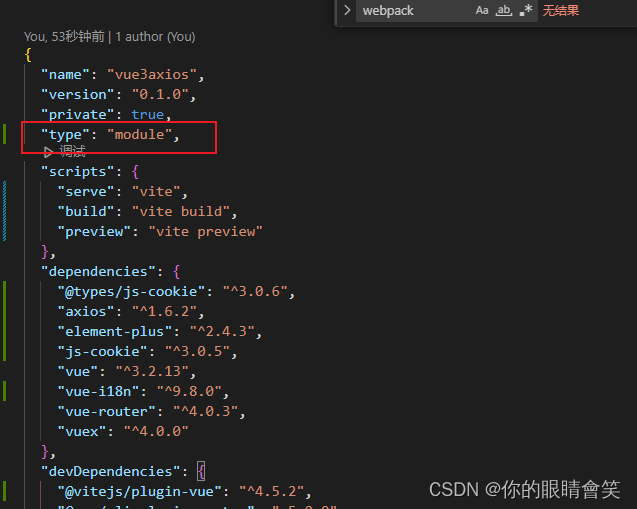
vue3老项目如何引入vite
vue3老项目如何引入vite 安装 npm install vite vitejs/plugin-vue --save-dev Vite官方中文文档修改package.json文件 在 npm scripts 中使用 vite 执行文件 "scripts": {"serve": "vite","build": "vite build","pr…...
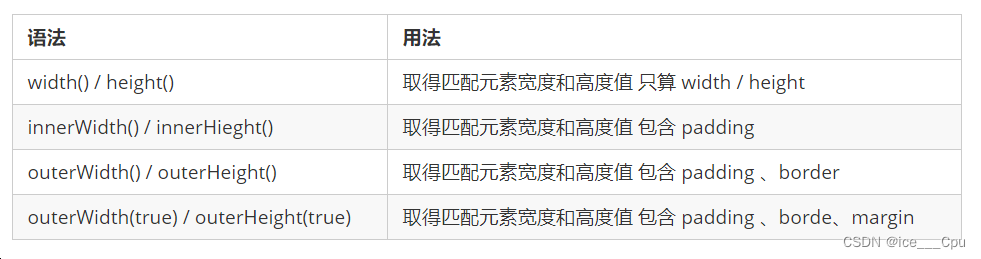
javaEE -19(9000 字 JavaScript入门 - 4)
一: jQuery jQuery是一个快速、小巧且功能丰富的JavaScript库。它旨在简化HTML文档遍历、事件处理、动画效果以及与后端服务器的交互等操作。通过使用jQuery,开发者可以以更简洁、更高效的方式来编写JavaScript代码。 jQuery提供了许多易于使用的方法和…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
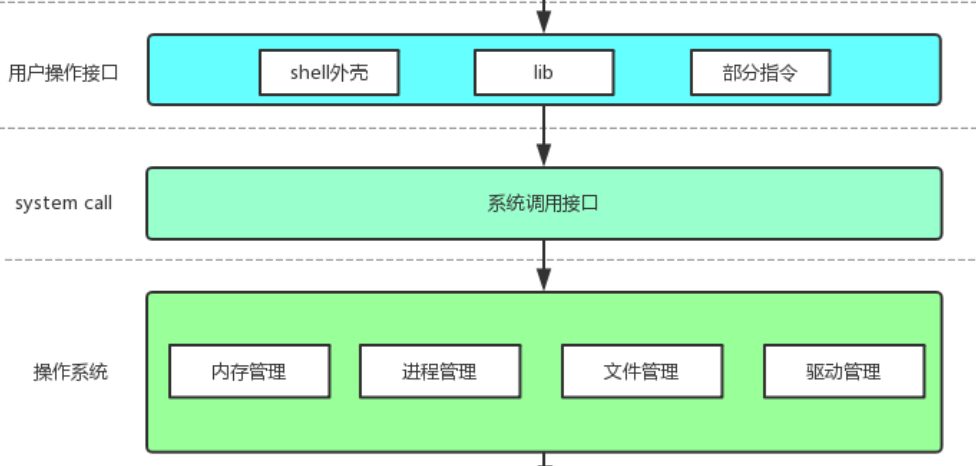
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...
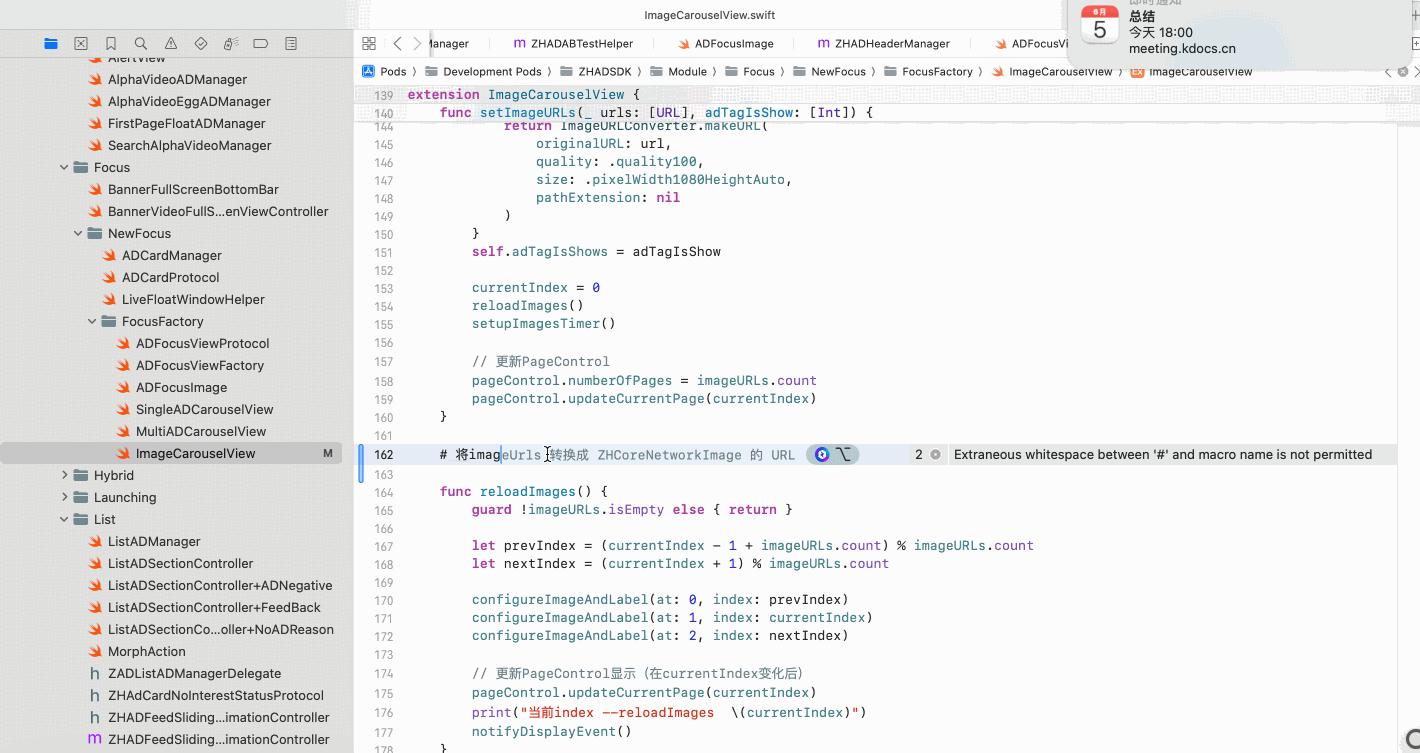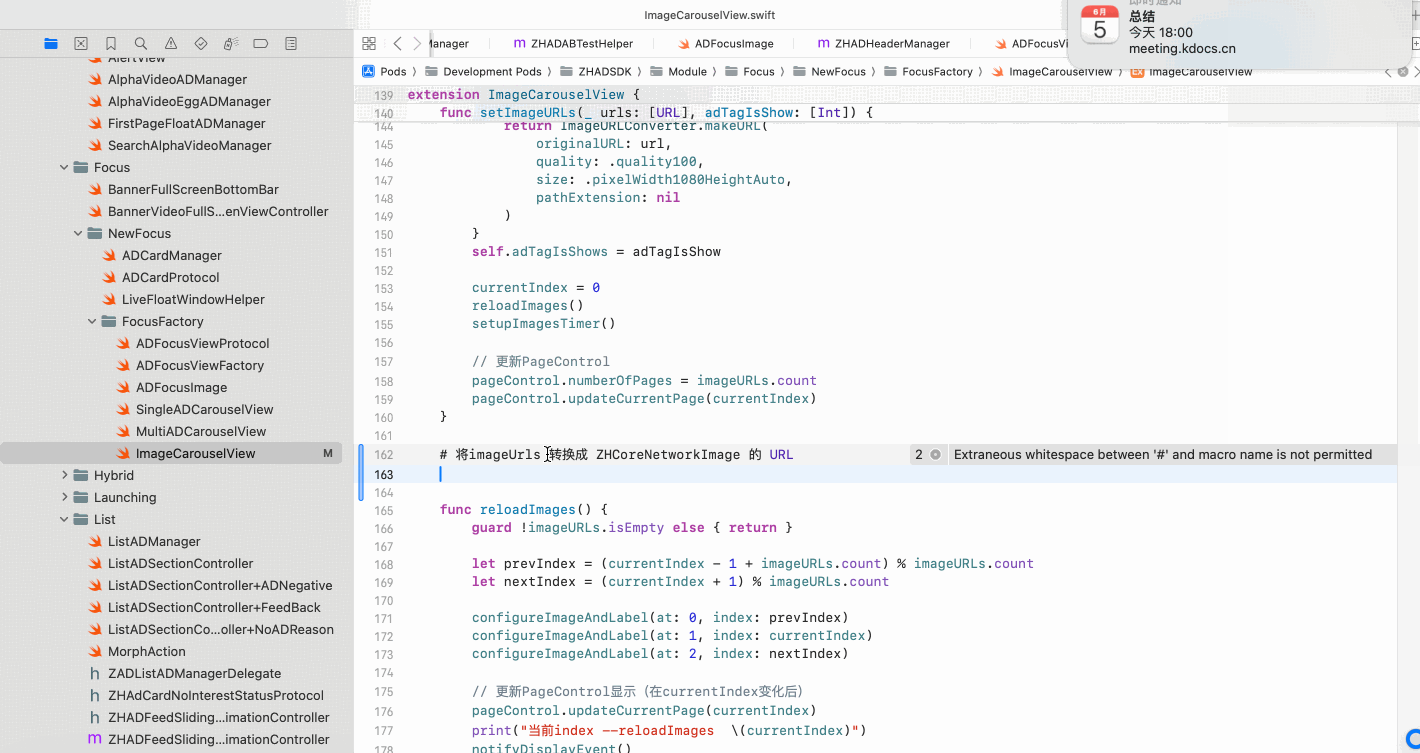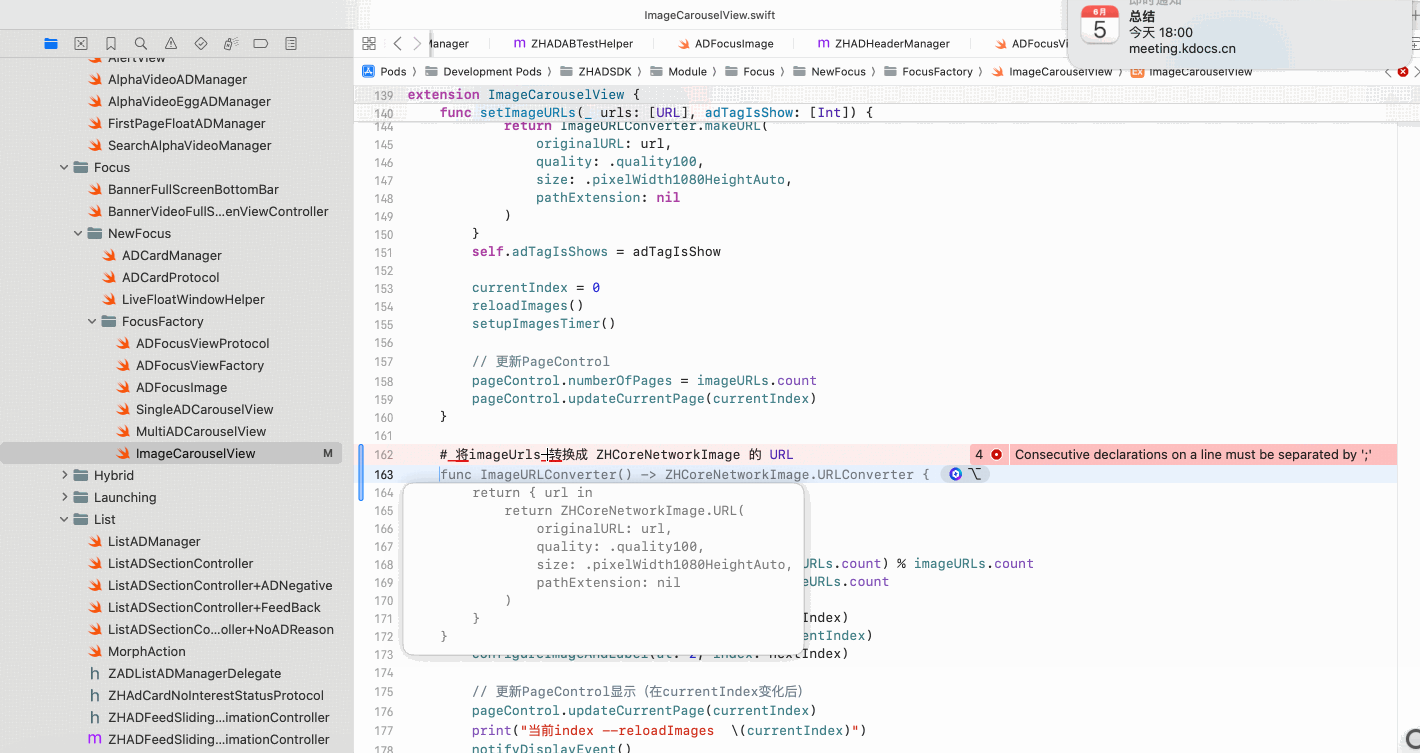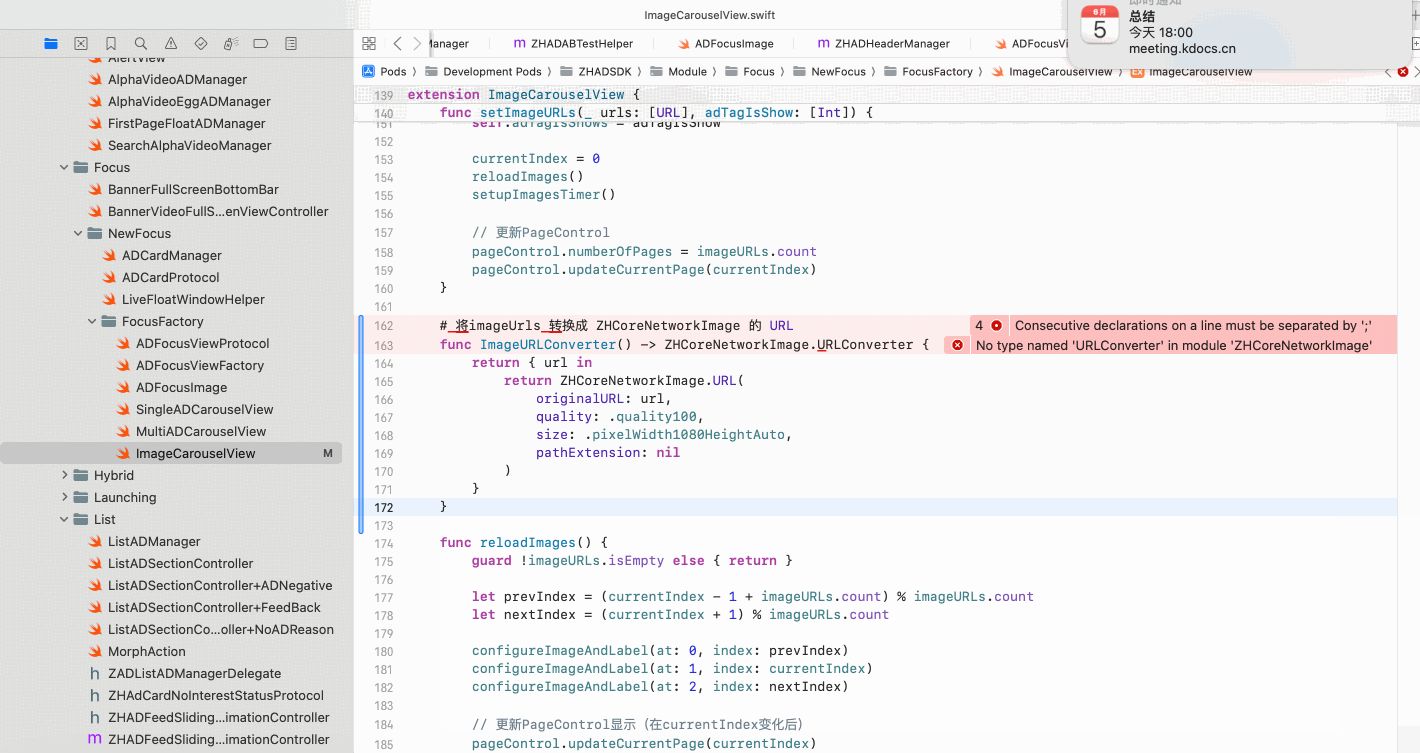
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...
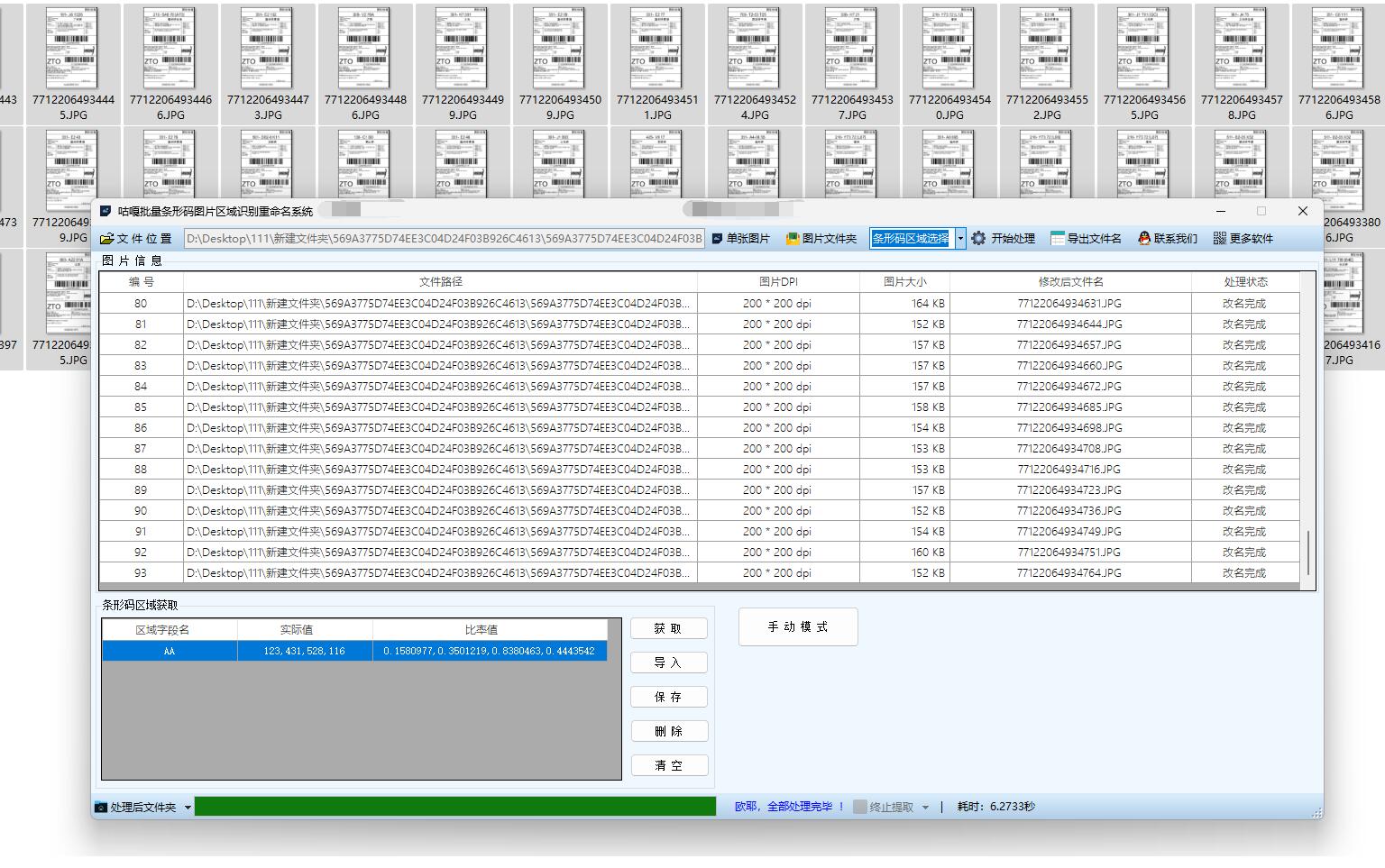
【工具教程】多个条形码识别用条码内容对图片重命名,批量PDF条形码识别后用条码内容批量改名,使用教程及注意事项
一、条形码识别改名使用教程 打开软件并选择处理模式:打开软件后,根据要处理的文件类型,选择 “图片识别模式” 或 “PDF 识别模式”。如果是处理包含条形码的 PDF 文件,就选择 “PDF 识别模式”;若是处理图片文件&…...