如何底层调用最快地复制OPC数据到关系数据库
计算机上的二大应用,一是从WEB服务器上获得数据,另一种是向关系数据库中写入数据。在上集我已提出了一个从WEB上获得OPC数据的独创方法,现在谈谈第二种如何快速地把OPC数据写进到数据库中,这也是Calssic OPC最典型的一个应用场景。
使用基金会提供的基于.NET的ADO.NET无疑不是一个最快最有效率的办法,原因是显而易见的。要想速度快,必然要考虑到原生的基于COM的数据库技术,比如OLE DB,ADO或者ODBC。根据《ADO ActiveX Data Objects》一书描述的三者架构关系图,

显然,ADO是对OLE DB技术的上一层封装,是对当时OLE DB技术上的繁琐和难以找到熟悉COM的开发人员的一种妥协。自然,ADO的表现要比OLE DB逊色一些。不同于微软私有的ADO/OLE DB技术,ODBC是一个国际标准,有通用的接口,但性能上还是比OLE DB差了些。原因有三:第一,ODBC诞生在1992年,OLE DB出现在1996年,当年微软是想用它代替ODBC的,所以OLE DB在设计上有后发优势。第二,ODBC和OLEDB都有BIND的功能,比如ODBC有SQLBindCol()函数调用,而OLE DB不一样,要自己亲手写BIND,看上去很繁琐。其实也正是这样的繁琐保证了它性能上的优越。第三,最重要的一点,ODBC是工作在不同的查询语句上的,比如INSERT,UPDATE等,所以服务端需要进行解析。OLE DB可以使用查询语句,也可以不使用查询语句而完成INSERT、UPDATE等操作——没有了服务端的解析,自然就快了许多。有人做过测试,用ODBC的INSERT语句完成十万行的插入,而OLE DB没有使用任何INSERT语句,OLE DB比ODBC快了至少一倍以上。再多聊一些OLE DB的历史,当年没能成功替代ODBC,微软宣布准备让它退出底层的原生数据库编程应用,但是有众多厂家反对再加上OLE DB自身的性能优势,非常符合云时代的要求。所以在2017年微软宣布重新支持OLE DB的编程技术并发布了新一代的OLE DB驱动程序。新的驱动加上了加密功能,更能适应于云生时代。
虽然OLE DB性能优越,但繁琐的code让人望而生却,有没有办法?答案是 Active Template Library(ATL),它封装了很多繁琐的OLE DB底层调用,即起到防止内存泄漏,又帮你写出又快又好的程序。
本样本程序使用最新的OLE DB驱动程序,给出一个有INSERT语句的完整演示,完成快速地把OPC数据复制到数据库中,然后再展现出存贮在数据库中的所有数据。
int main(int argc, CHAR* argv[]) {CoInitializeEx(NULL, COINIT_MULTITHREADED);{CDataSource dataSource;CSession session;const WCHAR szUDLFile[] = L"OPCDA.udl";HRESULT hr = dataSource.OpenFromFileName(szUDLFile);if (FAILED(hr)) {printf("OpenFromFileName() failed\n");goto END;}hr = session.Open(dataSource);if (FAILED(hr)){printf("Open() failed\n");dataSource.Close();goto END;}CLSID cidOpcServer;if (FAILED(listServers(cidOpcServer))){printf("listServers() failed\n");dataSource.Close();goto END;}if (FAILED(DA(cidOpcServer, session))) {printf("DA() failed\n");dataSource.Close();goto END;}printf("\nretrieving rows from database...\n\n");displayResult(session);dataSource.Close();}system("pause");END:CoUninitialize();return(EXIT_SUCCESS);
}这是主程序,运行在多线程状态,这样后面OPC的DataCallBack可以运行在另一个单独的线程中,否则全部都使用一个主线程。
接下来是根据UDL的文件设定来连接数据库。这个UDL的文件如下,
[oledb]
; Everything after this line is an OLE DB initstring
Provider=MSOLEDBSQL19.1;Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=TEST;Data Source=localhost;Use Encryption for Data=Optional;
可以看到,使用了最新的19版本OLE DB的驱动(对应的是msoledbsql19.dll),指定了相应的数据库名和服务器名,不使用用户名和密码作为身份验证手段,同时不要求数据进行加密。有一点要注意的是,当通过UDL界面保存设置时,可能会有很多的属性存在这个UDL文件中,会造成OpenFromFileName()的失败,所以只要留最少的如上属性即可。

OpenFromFileName()是ATL提供的API,帮助获得第一个基于IDataInitialize接口的实例,然后根据UDL连接属性建立和数据库的连接,然后初始化基于IDBInitialize的实例如下,
HRESULT OpenFromFileName(_In_z_ LPCOLESTR szFileName) throw()
{CComPtr<IDataInitialize> spDataInit;CComHeapPtr<OLECHAR> spszInitString;HRESULT hr = CoCreateInstance(__uuidof(MSDAINITIALIZE), NULL, CLSCTX_INPROC_SERVER,__uuidof(IDataInitialize), (void**)&spDataInit);if (FAILED(hr))return hr;hr = spDataInit->LoadStringFromStorage(szFileName, &spszInitString);if (FAILED(hr))return hr;return OpenFromInitializationString(spszInitString);
}
// Open the datasource specified by the passed initialization string
HRESULT OpenFromInitializationString(_In_z_ LPCOLESTR szInitializationString,_In_ bool fPromptForInfo = false) throw()
{CComPtr<IDataInitialize> spDataInit;HRESULT hr = CoCreateInstance(__uuidof(MSDAINITIALIZE), NULL, CLSCTX_INPROC_SERVER,__uuidof(IDataInitialize), (void**)&spDataInit);if (FAILED(hr))return hr;hr = spDataInit->GetDataSource(NULL, CLSCTX_INPROC_SERVER, szInitializationString,__uuidof(IDBInitialize), (IUnknown**)&m_spInit);if (FAILED(hr))return hr;if( fPromptForInfo ){CComPtr<IDBProperties> spIDBProperties;hr = m_spInit->QueryInterface( &spIDBProperties );DBPROP rgProperties[1];DBPROPSET rgPropertySets[1];VariantInit(&rgProperties[0].vValue);rgProperties[0].dwOptions = DBPROPOPTIONS_REQUIRED;rgProperties[0].colid = DB_NULLID;rgProperties[0].dwPropertyID = DBPROP_INIT_PROMPT;rgProperties[0].vValue.vt = VT_I2;rgProperties[0].vValue.lVal = DBPROMPT_COMPLETEREQUIRED;rgPropertySets[0].rgProperties = rgProperties;rgPropertySets[0].cProperties = 1;rgPropertySets[0].guidPropertySet = DBPROPSET_DBINIT;hr = spIDBProperties->SetProperties( 1, rgPropertySets );if (FAILED(hr))return hr;}return m_spInit->Initialize();
}注意下这里CLSID用的是MSDAINITIALIZE,搜索注册表显示的是

也就是从oledb32.dll的地址空间中先获得IDataInitialize的实例,再调用GetDataSource()来获得IDBInitialize的指针,所以这个m_spInit指针也是在oledb32.dll的地址空间中,只不过它同时也加载了msoledbsql19.dll中的相应接口。
回到主程序,session.Open()也是ATL的API,主要是为了获得IOpenRowset的指针如下,
HRESULT Open(_In_ const CDataSource& ds,_Inout_updates_opt_(ulPropSets) DBPROPSET *pPropSet = NULL,_In_ ULONG ulPropSets = 0) throw()
{CComPtr<IDBCreateSession> spSession;// Check we have connected to the databaseATLASSERT(ds.m_spInit != NULL);HRESULT hr = ds.m_spInit->QueryInterface(__uuidof(IDBCreateSession), (void**)&spSession);if (FAILED(hr))return hr;hr = spSession->CreateSession(NULL, __uuidof(IOpenRowset), (IUnknown**)&m_spOpenRowset);if( pPropSet != NULL && SUCCEEDED(hr) && m_spOpenRowset != NULL ){// If the user didn't specify the default parameter, use oneif (pPropSet != NULL && ulPropSets == 0)ulPropSets = 1;CComPtr<ISessionProperties> spSessionProperties;hr = m_spOpenRowset->QueryInterface(__uuidof(ISessionProperties), (void**)&spSessionProperties);if(FAILED(hr))return hr;hr = spSessionProperties->SetProperties( ulPropSets, pPropSet );}return hr;
}接下来的主程序是关于OPC的操作,listServers()是为了获得本机上OPC DA的CLSID,如下,
HRESULT listServers(CLSID& cidOpcServer)
{ULONG fetched = 0;HRESULT hr = S_OK;CComHeapPtr<OLECHAR> bsProgID, lpszUserType, lpszVerIndProgID;CATID arrcatid[3] = { NULL };arrcatid[0] = __uuidof(CATID_OPCDAServer10);arrcatid[1] = __uuidof(CATID_OPCDAServer20);arrcatid[2] = __uuidof(CATID_OPCDAServer30);CComPtr<IOPCServerList2> spIOPCServerList2;if (FAILED(hr = spIOPCServerList2.CoCreateInstance(__uuidof(OpcServerList), spIOPCServerList2, CLSCTX_ALL))){printf("CoCreateInstance() for IOPCServerList2 failed\n");return hr;}CComPtr<IOPCEnumGUID> spEnum;hr = spIOPCServerList2->EnumClassesOfCategories(sizeof arrcatid / sizeof CATID, arrcatid, 0, NULL, &spEnum);if (spEnum.p){while ((hr = spEnum->Next(1, &cidOpcServer, &fetched)) == S_OK){hr = spIOPCServerList2->GetClassDetails(cidOpcServer, &bsProgID, &lpszUserType, &lpszVerIndProgID);if (FAILED(hr)) {_tprintf(_T("GetClassDetails() failed\n"));return hr;}break;}}return hr;
}此段程序也不复杂,获得一个IOPCServerList2的实例,然后对相应的OPC类别进行枚举,再在枚举中循环得到本机的OPC DA的CLSID。
有了DA的CLSID后,开始对DA进行操作,比如创建一个实例,建立一个新组,创建一个回调函数,通知服务端,加入感兴趣的TAG,暂停等待回调函数的结束。具体见下,
HRESULT DA(CLSID& cidOpcServer, CSession& session) {CComPtr<IOPCServer> pIOPCServer;HRESULT hr = pIOPCServer.CoCreateInstance(cidOpcServer, pIOPCServer, CLSCTX_ALL);if (FAILED(hr)) {printf("CoCreateInstance() for IOPCServer failed\n");return E_FAIL;}DWORD dwRevisedUpdateRate = 0;OPCHANDLE hGroup = 0;CComPtr<IOPCItemMgt> pOPCItemMgt;hr = pIOPCServer->AddGroup(L"", TRUE, 1000, NULL, NULL, NULL, LOCALE_SYSTEM_DEFAULT, &hGroup, &dwRevisedUpdateRate, __uuidof(IOPCItemMgt), (LPUNKNOWN*)&pOPCItemMgt);if (FAILED(hr)) {printf("AddGroup() failed\n");return E_FAIL;}DataCallback* pDataCallback = new DataCallback(session);pDataCallback->AddRef();DWORD m_dwCookie;AtlAdvise(pOPCItemMgt, pDataCallback, __uuidof(IOPCDataCallback), &m_dwCookie);hr = addItems(pOPCItemMgt);if (FAILED(hr)) {printf("addItems() failed\n");return E_FAIL;}printf("\npress any key to complete inserting rows to database\n");getchar();AtlUnadvise(pOPCItemMgt, __uuidof(IOPCDataCallback), m_dwCookie);pDataCallback->Release();return S_OK;
}下面具体看下回调函数,它的作用是当TAG的值有变化时,此函数被唤醒在另一线程执行,返回的参数包括TAG的值,时间戳和状态,如下,
STDMETHODIMP OnDataChange(DWORD dwTransid,OPCHANDLE hGroup,HRESULT hrMasterquality,HRESULT hrMastererror,DWORD dwCount,OPCHANDLE* phClientItems,VARIANT* pvValues,WORD* pwQualities,FILETIME* pftTimeStamps,HRESULT* pErrors
)
{CCommand<CManualAccessor> command;CComVariant vVariant[4];vVariant[0].vt = VT_BSTR;vVariant[1].vt = VT_R4;vVariant[2].vt = VT_DATE;vVariant[3].vt = VT_UINT;hr = command.CreateParameterAccessor(4, vVariant, sizeof vVariant); if (FAILED(hr)) {printf("command.CreateParameterAccessor() failed");return hr;}for (DWORD ii = 0; ii < dwCount; ii++){CComVariant vValue;WORD quality = pwQualities[ii] & OPC_QUALITY_MASK;COleDateTime oleTime = COleDateTime(pftTimeStamps[ii]);SYSTEMTIME st;oleTime.GetAsSystemTime(st);if (phClientItems[ii] == 0)CComBSTR("Random.Int1").CopyTo(&vVariant[0].bstrVal);if (phClientItems[ii] == 1)CComBSTR("Random.Int2").CopyTo(&vVariant[0].bstrVal);else if (phClientItems[ii] == 2)CComBSTR("Random.Real8").CopyTo(&vVariant[0].bstrVal);vVariant[1].fltVal = (FLOAT)pvValues[ii].dblVal;vVariant[2].date = oleTime;vVariant[3].iVal = quality;command.m_nCurrentParameter = 0;command.AddParameterEntry(1, DBTYPE_BSTR, NULL, &vVariant[0].bstrVal);command.AddParameterEntry(2, DBTYPE_R4, NULL, &vVariant[1].fltVal);command.AddParameterEntry(3, DBTYPE_DATE, NULL, &vVariant[2].date);command.AddParameterEntry(4, DBTYPE_UI2, NULL, &vVariant[3].iVal);/*This is not the most efficient and fastest way to insert a row to database due to query building/parsing and commit each time.To bulk insert, interface of IRowsetFastLoad has to be used and it is quite different from this code example.Contact developer to have a code example using IRowsetFastLoad, so you can completely understand the big difference between IDBInitialize and IDataInitialize interfaces when trying to get a pointer to IRowsetFastLoad.*/hr = command.Open(session, "insert into OPCDA (Tag, Value, Time, Quality) Values (?,?,?,?)", NULL, NULL);if (FAILED(hr)) {printf("command.Open() failed");break;}elseprintf("\nOnDataChange: %S (%f, %s.%d, %s)", vVariant[0].bstrVal, vVariant[1].fltVal, oleTime.Format("%F %T").GetString(), st.wMilliseconds, quality == OPC_QUALITY_GOOD ? "good" : "bad");SysFreeString(vVariant[0].bstrVal);}return hr;
}这段程序中使用了ATL提供的CCommand,然后用CreateParameterAccessor()构建一个关于查询语句参数的存取器。这也是个ATL的函数,不再展开讨论,主要是执行有关参数的BIND,具体可以参见它的源代码。然后根据OPC提供的返回值的数目进行循环,取出每一个TAG的值、时间戳和状态,结合TAG名称来满足INSERT语句四个参数的要求,最后使用ATL的Open()完成INSERT语句的执行。
回到主程序,完成了INSERT的操作,下一步是从数据库中把刚才插入的数据取出来展示,
void displayResult(CSession &session) {CCommand<CManualAccessor> command;const USHORT uColumns = 4;CComVariant vValues[uColumns]{};HRESULT hr = command.CreateAccessor(uColumns, vValues, sizeof vValues);if (FAILED(hr)){printf("CreateAccessor() failed\n");return;}for (ULONG l = 0; l < uColumns; l++){command.AddBindEntry(l + 1, DBTYPE_VARIANT, NULL, &vValues[l], NULL, NULL);}hr = command.Open(session, "select * from OPCDA", NULL, NULL);if (FAILED(hr)){printf("command.Open() failed\n");return;}ULONG count = 0;while (command.MoveNext() == S_OK) {CComVariant* pBind = (CComVariant*)command.m_pBuffer;count++;COleDateTime dateTime(pBind[2].date);printf("%S (%f, %s, %s)\n", pBind[0].bstrVal, pBind[1].fltVal, dateTime.Format("%F %T").GetString(), pBind[3].iVal == OPC_QUALITY_GOOD ? "good" : "bad");;}printf("\nTotal rows: %d\n", count);
}这段的所有操作都是调用ATL的API,先是CreateAccessor()构建个无参数的存取器,也就是建立一个BIND,供返回的数据存在内存中用。一个Open()语句完成数据的获得,再进行个循环依次展示获得的值。注意一点,返回的是一行的值,有四列。
运行后的结果如下,

综观这一程序,由于有了ATL的加持OLE DB的编程不再那么困难。ATL带来了便利,但也掩盖了对底层OLE DB的理解。每次的INSERT操作都伴随着COMMIT,显然不是最快和最有效率的OLE DB编程方法。也是基于此微软当年(2012年)在新版的Native Client 驱动中引入了IRowsetFastLoad接口,专门进行批量插入。此接口也非常简单只有二个函数,InsertRow()和Commit(),即多次调用InsertRow(),然后一次性地Commit()。为了深入理解更底层的OLE DB编程,我又独自开发了基于IRowsetFastLoad的OPC范例。本以为和这个程序差不多,没想到却被打脸。在开发过程中让我体会到使用IDataInitialize和IDBInitialize实例来获取IRowsetFastLoad指针的巨大不同,对老版的OLE DB驱动sqloledb.dll,老版的Native Client驱动sqlncli11.dll和新版的OLE DB驱动msoledbsql19.dll三者之间的关系有了进一步的了解。在进行完整的BIND过程中也领会到最原始的底层ORM的美(相对于高级语言的ORM,如Hibernate或Entity Framework),这种底层ORM和内存布局直接呼应,没有任何INSERT语句却能快速地完成批量插入,真是“不著一字,尽得风流”。感兴趣的同学可以邮箱联系我获取一份范例,在关键处我都加了注释来加深对OLE DB和COM的编程理解,确保获益满满。
本范例已经在GITHUB开源,下载在此。
相关文章:
如何底层调用最快地复制OPC数据到关系数据库
计算机上的二大应用,一是从WEB服务器上获得数据,另一种是向关系数据库中写入数据。在上集我已提出了一个从WEB上获得OPC数据的独创方法,现在谈谈第二种如何快速地把OPC数据写进到数据库中,这也是Calssic OPC最典型的一个应用场景。…...
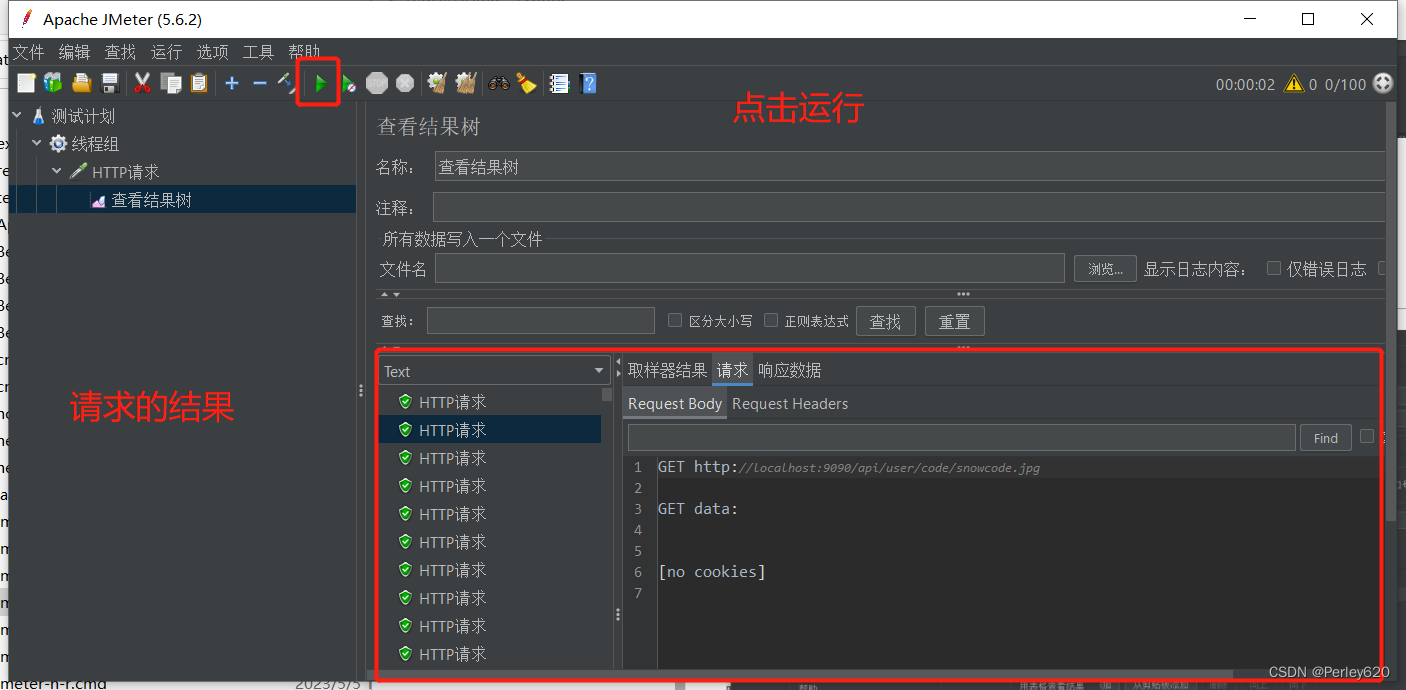
接口测试工具——ApiFox使用初体验 postman导出和ApiFox导入
目录 ApiFox使用初体验初步使用从postman导出到apifox导入 IDEA简单测试Postman测试工具post请求 接口测试工具swaggerKnife4j1.引入依赖2.配置3.常用注解4.接口测试 JMeter什么是JMeter?JMeter安装配置1.官网下载2.下载后解压3.汉语设置 JMeter的使用方法1.新建线程组2.设置参…...
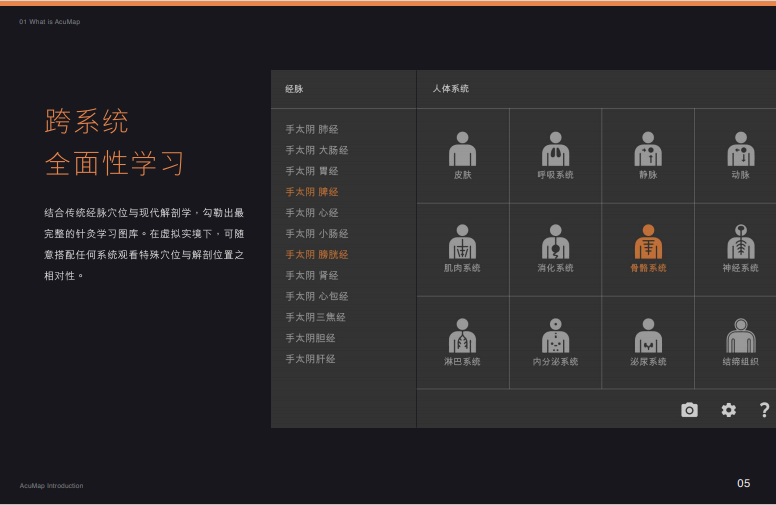
搜维尔科技:经脉腧穴虚拟针灸VR虚拟教学平台AcuMap软件案例分享
北京中医药大学经脉腧穴VR虚拟教学平台案例 主要产品 HTCvive ,AcuMap; 实施内容 一、项目说明 (1)穴位取穴与体表解剖标志关系;(2)穴下层次解剖及周围解剖结构展示; …...

Jenkins的shared library相关
Jenkins的shared library是一种用于在多个Jenkins流水线项目中共享和重用代码的机制。它可以将常用的构建逻辑、工具函数或自定义步骤封装为可复用的库,并以插件的形式提供给Jenkins。 Shared library的作用主要包括以下几个方面: 代码复用:…...
文件IO
文章目录 文章目录 前言 一 . 文件 文件路径 文件类型 Java中操作文件 File 概述 属性 构造方法 方法 createNewFile mkdir 二 . 文件内容的读写 - IO InputStream 概述 FileInputStream 概述 利用 Scanner 进行字符读取 OutputStream 概述 PrintWriter封装O…...

【日常聊聊】编程语言的未来:趋势、多样性、人工智能融合、教育与生态系统
🍎个人博客:个人主页 🏆个人专栏: 日常聊聊 ⛳️ 功不唐捐,玉汝于成 目录 前言: 正文 1. 编程语言的发展趋势 1.1 新语言和编程范式的涌现 1.2 影响和挑战 2. 编程语言的多样性 2.1 互操作性和可移…...

无需手动搜索!轻松创建IntelliJ IDEA快捷方式的Linux教程
轻松创建IntelliJ IDEA快捷方式的Linux教程 一、IntelliJ IDEA简介二、在Linux系统中创建快捷方式的好处三、命令行创建IntelliJ IDEA快捷方式四、图形界面创建IntelliJ IDEA快捷方式五、常见问题总结 一、IntelliJ IDEA简介 IntelliJ IDEA是一个由JetBrains搞的IDE࿰…...

如何去掉微博水印?用它一键去除三秒出图
微博是一款非常流行的社交媒体平台,许多人都在上面分享自己的生活点滴和心得体会。但是,有时候我们会发现,在上传图片时,微博会自动添加水印,这会影响到图片的美观度。那么,如何去掉微博水印呢?…...

Golang 泛型实现原理
文章目录 1.什么是泛型?2.有 interface{} 为什么还要有泛型?3.泛型有哪些特性?3.1 类型参数泛型函数泛型类型 3.2 类型约束3.3 类型集3.4 约束元素任意类型约束元素近似约束元素联合约束元素约束中的可比类型 3.5 类型推断 4.实现原理4.1 类型擦除虚方法…...
[玩转AIGC]LLaMA2之如何微调模型
目录 1、下载训练脚本2、 下载模型2.1、申请下载权限2.2、模型下载 3、模型微调3.1、使用单卡微调3.2、使用多卡训练: 1、下载训练脚本 首先我们从github上下载Llama 2的微调代码:GitHub - facebookresearch/llama-recipes: Examples and recipes for L…...
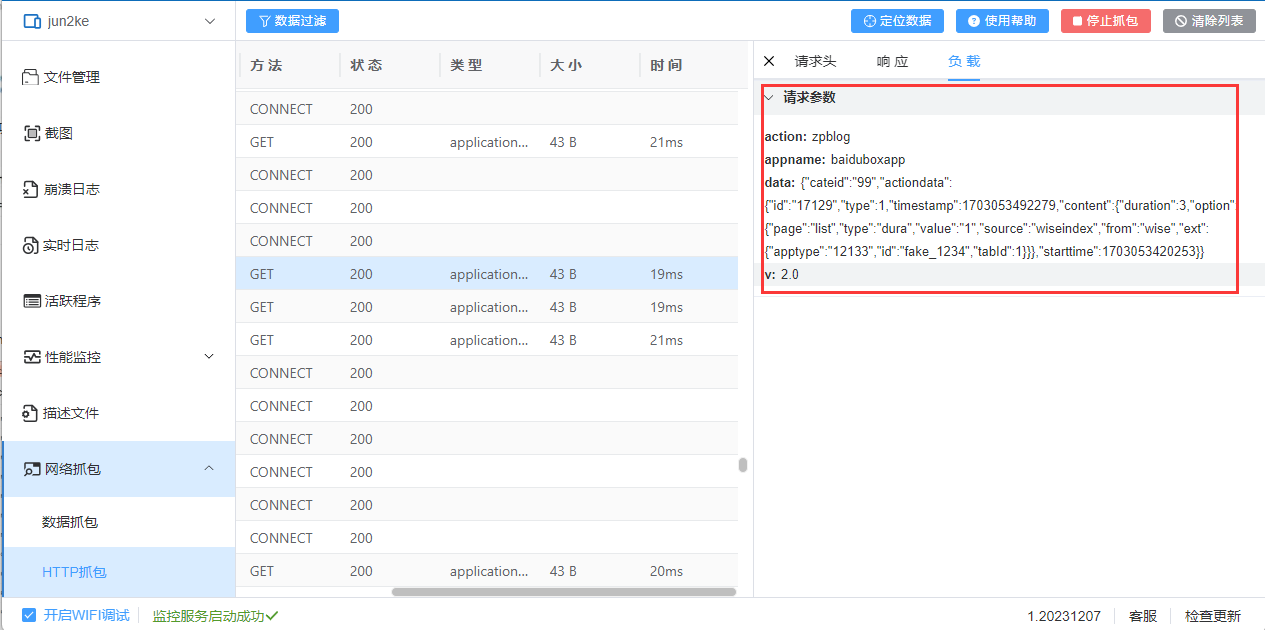
使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解
摘要 本文博客将介绍如何在iOS环境下使用克魔助手进行数据抓包和HTTP抓包。通过抓包,开发者可以分析移动应用程序的网络请求发送和接收过程,识别潜在的性能和安全问题,提高应用的质量和安全性。 引言 在移动应用程序的开发和测试过程中&am…...

【递归 回溯】LeetCode-301. 删除无效的括号
301. 删除无效的括号。 给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。 返回所有可能的结果。答案可以按 任意顺序 返回。 示例 1: 输入:s "()())()" 输出:[…...

C++ 基本的输入输出
C 标准库提供了一组丰富的输入/输出功能,我们将在后续的章节进行介绍。本章将讨论 C 编程中最基本和最常见的 I/O 操作。 C 的 I/O 发生在流中,流是字节序列。如果字节流是从设备(如键盘、磁盘驱动器、网络连接等)流向内存&#…...
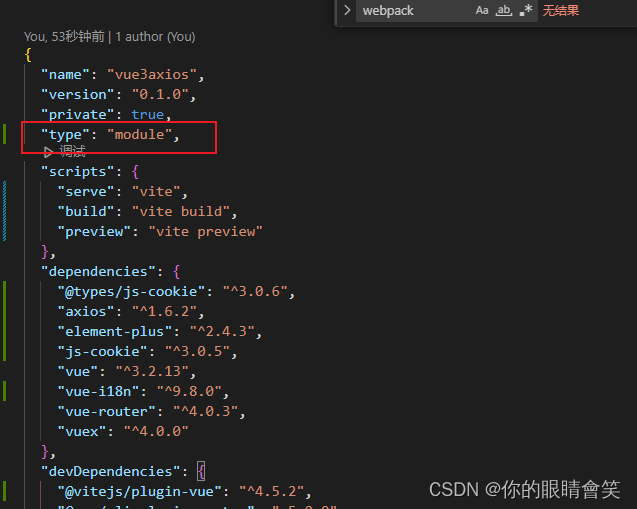
vue3老项目如何引入vite
vue3老项目如何引入vite 安装 npm install vite vitejs/plugin-vue --save-dev Vite官方中文文档修改package.json文件 在 npm scripts 中使用 vite 执行文件 "scripts": {"serve": "vite","build": "vite build","pr…...
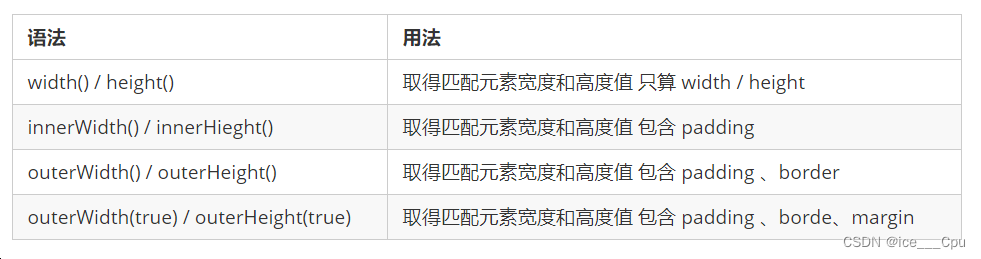
javaEE -19(9000 字 JavaScript入门 - 4)
一: jQuery jQuery是一个快速、小巧且功能丰富的JavaScript库。它旨在简化HTML文档遍历、事件处理、动画效果以及与后端服务器的交互等操作。通过使用jQuery,开发者可以以更简洁、更高效的方式来编写JavaScript代码。 jQuery提供了许多易于使用的方法和…...

二叉树的非递归遍历|前中后序遍历
二叉树的非递归遍历 文章目录 二叉树的非递归遍历前序遍历-栈层序遍历-队列中序遍历-栈后序遍历-栈 前序遍历-栈 首先我们应该创建一个Stack 用来存放节点,首先我们想要打印根节点的数据,此时Stack里面的内容为空,所以我们优先将头结点加入S…...

开源minio-AWS-S3存储的部署及go操作详细
介绍 MinIO是一个开源的分布式对象存储服务,它允许用户在私有云或公有云环境中构建自己的对象存储基础设施。MinIO旨在提供高性能、高可用性的对象存储,并且与Amazon S3兼容,这意味着可以使用S3客户端工具和库直接与MinIO交互,而…...
)
【Web2D/3D】Canvas(第三篇)
1. 前言 <canvas>是HTML5新增元素,它是一个画板,开发人员基于它的2D上下文或webgl上下文,使用JS脚本绘制简单的动画、可交互画面,甚至进行视频渲染。 本篇介绍基于canvas的2D上下文绘制2D画面的一些方法和属性。 2. canvas…...

紫光展锐T820与飞桨完成I级兼容性测试 助推端侧AI融合创新
近日,紫光展锐高性能5G SoC T820与百度飞桨完成I级兼容性测试(基于Paddle Lite工具)。测试结果显示,双方兼容性表现良好,整体运行稳定。这是紫光展锐加入百度“硬件生态共创计划”后的阶段性成果。 本次I级兼容性测试完…...
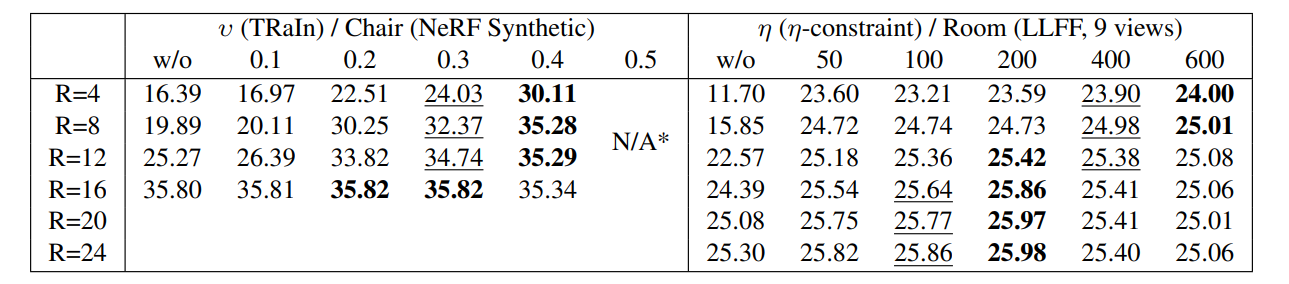
3DV 2024 Oral | SlimmeRF:可动态压缩辐射场,实现模型大小和建模精度的灵活权衡
目前大多数NeRF模型要么通过使用大型模型来实现高精度,要么通过牺牲精度来节省内存资源。这使得任何单一模型的适用范围受到局限,因为高精度模型可能无法适应低内存设备,而内存高效模型可能无法满足高质量要求。为此,本文研究者提…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...