Linux: ARM GIC仅中断CPU 0问题分析
文章目录
- 1. 前言
- 2. 分析背景
- 3. 问题
- 4. 分析
- 4.1 ARM GIC 中断芯片简介
- 4.1.1 中断类型和分布
- 4.1.2 拓扑结构
- 4.2 问题根因
- 4.2.1 设置GIC SPI中断的CPU亲和性
- 4.2.2 GIC初始化:缺省的CPU亲和性
- 4.2.2.1 boot CPU亲和性初始化流程
- 4.2.2.1 其它非 boot CPU亲和性初始化流程
- 5. GIC 的救赎?
- 5.1 默认配置成转发给所有CPU
- 5.2 用当前 CPU ID 作为 gic_cpu_map[] 索引
- 6. 一个解决方案:irqbalance
- 7. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 分析背景
本文分析基于 linux-4.14.132 内核代码分析,运行环境 Ubuntu 16.04.4 LTS + QEMU + ARM vexpress-a9 ,rootfs 基于 ubuntu-base-16.04-core-armhf.tar.gz 制作。
3. 问题
在使用全志H3机器时,观察到一个现象,外设中断总是集中在 CPU0 处理:
# cat /proc/interruptsCPU0 CPU1 CPU2 CPU316: 0 0 0 0 GICv2 25 Level vgic17: 0 0 0 0 GICv2 50 Level /soc/timer@01c20c0018: 0 0 0 0 GICv2 29 Level arch_timer19: 6119 3595 3947 3046 GICv2 30 Level arch_timer20: 0 0 0 0 GICv2 27 Level kvm guest timer22: 0 0 0 0 GICv2 120 Level 1ee0000.hdmi, dw-hdmi-cec24: 0 0 0 0 GICv2 118 Level 1c0c000.lcd-controller25: 0 0 0 0 GICv2 82 Level 1c02000.dma-controller26: 24 0 0 0 GICv2 92 Level sunxi-mmc27: 25 0 0 0 GICv2 93 Level sunxi-mmc28: 2697 0 0 0 GICv2 94 Level sunxi-mmc29: 0 0 0 0 GICv2 103 Level musb-hdrc.4.auto30: 0 0 0 0 GICv2 104 Level ehci_hcd:usb131: 0 0 0 0 GICv2 105 Level ohci_hcd:usb232: 0 0 0 0 GICv2 106 Level ehci_hcd:usb333: 0 0 0 0 GICv2 107 Level ohci_hcd:usb634: 0 0 0 0 GICv2 108 Level ehci_hcd:usb435: 0 0 0 0 GICv2 109 Level ohci_hcd:usb736: 0 0 0 0 GICv2 110 Level ehci_hcd:usb537: 0 0 0 0 GICv2 111 Level ohci_hcd:usb840: 205 0 0 0 GICv2 63 Level 1c25000.ths42: 1802 0 0 0 GICv2 114 Level eth043: 0
我们观察到,除了第6行
19: 6119 3595 3947 3046 GICv2 30 Level arch_timer
之外,其它所有的行,CPU1~CPU3 的中断计数都为0。另外,用 QEMU 模拟的 vexpress-a9 板上,也观察到类似的现象:
$ cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 16: 69412 69401 69376 69332 GIC-0 29 Level twd17: 6 0 0 0 GIC-0 34 Level timer27: 0 0 0 0 GIC-0 92 Level arm-pmu28: 0 0 0 0 GIC-0 93 Level arm-pmu29: 0 0 0 0 GIC-0 94 Level arm-pmu30: 0 0 0 0 GIC-0 95 Level arm-pmu34: 3521 0 0 0 GIC-0 41 Level mmci-pl18x (cmd)35: 197190 0 0 0 GIC-0 42 Level mmci-pl18x (pio)36: 8 0 0 0 GIC-0 44 Level kmi-pl05037: 100 0 0 0 GIC-0 45 Level kmi-pl05038: 23 0 0 0 GIC-0 37 Level uart-pl01144: 0 0 0 0 GIC-0 36 Level rtc-pl031
IPI0: 0 1 1 1 CPU wakeup interrupts
IPI1: 0 0 0 0 Timer broadcast interrupts
IPI2: 750 1231 1441 947 Rescheduling interrupts
IPI3: 1 2 3 3 Function call interrupts
IPI4: 0 0 0 0 CPU stop interrupts
IPI5: 0 0 0 0 IRQ work interrupts
IPI6: 0 0 0 0 completion interrupts
Err: 0
4. 分析
4.1 ARM GIC 中断芯片简介
4.1.1 中断类型和分布
我们这里讨论的是 ARM GICv1 芯片,该芯片的中断分为3类:
SGI(Software-generated interrupt):用于处理期之间的通信,编号为 0~15 ;
PPI(Private peripheral interrupt):发送到特定处理器的中断,编号为 16~31 ;
SPI(Shared peripheral interrupt):可以发送给所有处理器的中断,编号为 32~1019 。
注意,每个处理器都有自己的 SGI 和 PPI 中断,它们使用相同的编号。假设系统有4个处理器,则这4个处理器都有自己的16个 SGI 中断和16个 PPI 中断。SPI 中断是全局的、所有处理器共享的。
4.1.2 拓扑结构
ARM GIC 芯片的内部结构如下图:
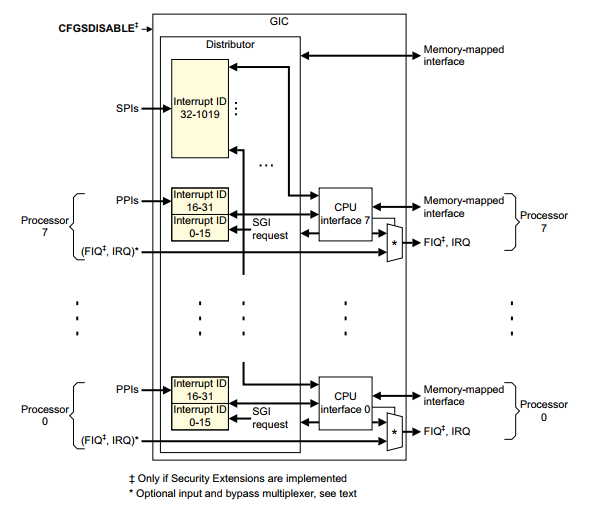
GIC 芯片内部包含两大功能模块:Distributor 和 CPU interface 。Distributor 用于将外设投递的中断信号转发给 CPU interface,具体转发给哪些 CPU interface ,可通过寄存器 ICDIPTRn 进行配置,当然,Distributor 也可以禁止外设中断信号的传入。而 CPU interface 用于将接收自 Distributor 的中断信号传递给连接的 CPU, CPU interface 也可以禁止将信号传递给 CPU 。
4.2 问题根因
4.2.1 设置GIC SPI中断的CPU亲和性
从上一小节了解到,具体将中断转发给哪个 CPU 核处理,取决于寄存器 ICDIPTRn 的配置。看一下 GIC 手册对该寄存器的描述:
4.3.11 Interrupt Processor Targets Registers (ICDIPTRn)The ICDIPTR characteristics are:
Purpose The ICDIPTRs provide an 8-bit CPU targets field for each interrupt supported bythe GIC. This field stores the list of processors that the interrupt is sent to if it isasserted.
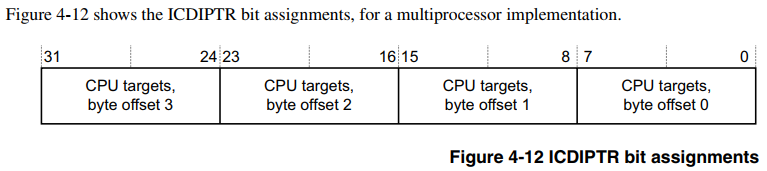
准确来讲,这是一个寄存器集,可以按字节访问,每个字节对应一个中断号的 Distributor 转发配置,每个bit对应一个CPU核的配置,最多支持8核。对于 SGI 和 PPI 中断号区间对应的寄存器,它们是每个CPU一份的(上面的引用没有描述),而对于 SPI 中断号区间对应的寄存器,它们的所有CPU共享一份的。GIC 芯片驱动提供接口 gic_set_affinity() 来配置 Distributor ICDIPTRn 寄存器,来决定 Distributor 将中断信号转发给哪个CPU核来处理,来看它的逻辑:
int cpumask_next_and(int n, const struct cpumask *src1p,const struct cpumask *src2p)
{while ((n = cpumask_next(n, src1p)) < nr_cpu_ids)if (cpumask_test_cpu(n, src2p))break;return n;
}/*** cpumask_next_and - get the next cpu in *src1p & *src2p* @n: the cpu prior to the place to search (ie. return will be > @n)* @src1p: the first cpumask pointer* @src2p: the second cpumask pointer** Returns >= nr_cpu_ids if no further cpus set in both.*/
int cpumask_next_and(int n, const struct cpumask *src1p,const struct cpumask *src2p)
{while ((n = cpumask_next(n, src1p)) < nr_cpu_ids)if (cpumask_test_cpu(n, src2p))break;return n;
}/*** cpumask_first_and - return the first cpu from *srcp1 & *srcp2* @src1p: the first input* @src2p: the second input** Returns >= nr_cpu_ids if no cpus set in both. See also cpumask_next_and().*/
#define cpumask_first_and(src1p, src2p) cpumask_next_and(-1, (src1p), (src2p))/*** cpumask_any_and - pick a "random" cpu from *mask1 & *mask2* @mask1: the first input cpumask* @mask2: the second input cpumask** Returns >= nr_cpu_ids if no cpus set.*/
/* 这个注释里的 "random" 真是个误导,根本没有什么随机可言 */
#define cpumask_first_and(src1p, src2p) cpumask_next_and(-1, (src1p), (src2p))/*** cpumask_first - get the first cpu in a cpumask* @srcp: the cpumask pointer** Returns >= nr_cpu_ids if no cpus set.*/
static inline unsigned int cpumask_first(const struct cpumask *srcp)
{return find_first_bit(cpumask_bits(srcp), nr_cpumask_bits);
}static int gic_set_affinity(struct irq_data *d, const struct cpumask *mask_val,bool force)
{/* 计算中断 @d->hwirq 的 ICDIPTRn 寄存器地址 */void __iomem *reg = gic_dist_base(d) + GIC_DIST_TARGET + (gic_irq(d) & ~3);/* ICDIPTRn 是 32-bit 寄存器,包含4个中断的设置,要计算中断 @d->hwirq 配置域的位偏移 */unsigned int cpu, shift = (gic_irq(d) % 4) * 8;u32 val, mask, bit;unsigned long flags;/** 从 @mask_val 选一个 CPU,然后用它的转发配置来配置对中断 @d->hwirq 的转发。* 这里就是导致 SPI 中断都转发给 CPU0 的根因了。force 可能是 true ,也可能是 * false ,看起来似乎得到的 @cpu 的值会是变化的。* SPI 中断初始化从 request_irq*() 系列调用发起,在过程中会设置 SPI 中断的CPU* 亲和性,传进来的 @mask_val 掩码包含系统所有的 CPU,这样在这里得到的 @cpu 均* 为 0 (假定 CPU0 是 boot CPU,这是通常的情形) !!!* 当然,从 request_percpu_irq() 注册的每 CPU 中断是例外。*/if (!force)cpu = cpumask_any_and(mask_val, cpu_online_mask);elsecpu = cpumask_first(mask_val);...mask = 0xff << shift;/* * 这个逻辑,说实话,很是违反人类的直觉(至少是我的)。 譬如,用户空间通过指令* echo f > /proc/irq/38/smp_affinity * 来配置38号中断的 CPU affinity (即 Distributor 转发38号中断给哪些CPU核),* 我理解的是可以将38号中断发送给 CPU0~3 中的任一个来处理。* 但最终发生了什么呢?GIC 驱动代码仅仅是从掩码计算出一个编号 @cpu ,然后以 * @cpu 为索引,取值 @gic_cpu_map[@cpu] 来配置中断 @d->hwirq 的 Distributor * 的转发配置:发送中断 @d->hwirq 给哪些 CPU !!! 呵呵,完全出乎意料。* 从前面的代码片段了解到,除非特殊配置,索引值 @cpu 总是返回 0,这意味着,驱动* 总是将 SPI 中断的转发配置为固定值 @gic_cpu_map[@cpu] ,也就是 SPI 中断总是* 被某几个或某个CPU核处理,最终结果是 SPI 中断总是被 CPU0 处理。* 从哪里知道 @gic_cpu_map[@cpu] 是固定值,而且是 0x01 这个固定值(假设 boot CPU * 是 CPU0)?简略的看后面中断初始化的流程,可以了解到这些。*/bit = gic_cpu_map[cpu] << shift;val = readl_relaxed(reg) & ~mask;writel_relaxed(val | bit, reg);...irq_data_update_effective_affinity(d, cpumask_of(cpu));return IRQ_SET_MASK_OK_DONE;
}
4.2.2 GIC初始化:缺省的CPU亲和性
4.2.2.1 boot CPU亲和性初始化流程
int __init
gic_of_init(struct device_node *node, struct device_node *parent)
{...ret = __gic_init_bases(gic, -1, &node->fwnode);...
}static int __init __gic_init_bases(struct gic_chip_data *gic,int irq_start,struct fwnode_handle *handle)
{if (gic == &gic_data[0]) { /* ROOT 中断控制器 */for (i = 0; i < NR_GIC_CPU_IF; i++)gic_cpu_map[i] = 0xff; /* 初始将中断转发给所有 CPU interface 上的 CPU */.../* 设置非 boot CPU 中断初始化入口 gic_starting_cpu() */cpuhp_setup_state_nocalls(CPUHP_AP_IRQ_GIC_STARTING,"irqchip/arm/gic:starting",gic_starting_cpu, NULL);set_handle_irq(gic_handle_irq); /* 设置中断 GIC 中断处理入口 */...}...ret = gic_init_bases(gic, irq_start, handle);...
}static int gic_init_bases(struct gic_chip_data *gic, int irq_start,struct fwnode_handle *handle)
{...gic_dist_init(gic);ret = gic_cpu_init(gic);if (ret)goto error;...
}static void gic_dist_init(struct gic_chip_data *gic)
{...cpumask = gic_get_cpumask(gic); /* 读取当前 CPU 的默认中断转发配置 *//* 将 gic_get_cpumask() 读回的 8-bit 值复制到 32-bit @cpumask * 的所有 4个 8-bit 域 */cpumask |= cpumask << 8;cpumask |= cpumask << 16;/* * 默认的 Distributor 转发配置:只将中断转发给 boot CPU。 * 这是合理的,因为当前处于 boot 阶段,除 boot CPU 外的其它CPU还没有运行起来。*/for (i = 32; i < gic_irqs; i += 4)writel_relaxed(cpumask, base + GIC_DIST_TARGET + i * 4 / 4);...
}/* 读取当前 CPU 的默认中断转发配置 */
static u8 gic_get_cpumask(struct gic_chip_data *gic)
{/* * 这里的代码,如果没读过 GIC 手册,是比较难理解的。 * 这里读的是 CPU 私有中断 SGI,PPI 的转发配置值,它们的理所当然的是只会* 转发给对应的 CPU 核,譬如编号为 29 的 PPI 中断:* . CPU0 读到的值就应该是 0xXX_XX_01_XX* . CPU1 读到的值就应该是 0xXX_XX_02_XX* . CPU2 读到的值就应该是 0xXX_XX_04_XX* . CPU3 读到的值就应该是 0xXX_XX_08_XX* 对于 SGI,PPI 这些私有中断,寄存器是多份的(banked register),所以不同的CPU* 在这里读的是自己私有的寄存器;而 SPI 中断的寄存器是全局独一份的。*/for (i = mask = 0; i < 32; i += 4) {/* * 对于不同的 SPI 中断号,读到值的不为 0 的 8-bit 的位偏移位置不同, * 后面的移位操作是为了保证将不为 0 的 8-bit 移动到最低 8-bit 。* 为什么?因为返回值类型是 u8 。*/mask = readl_relaxed(base + GIC_DIST_TARGET + i);mask |= mask >> 16;mask |= mask >> 8;/** 为什么 @mask 不为 0 就返回了?* 因为只要是同一 CPU 核,只要读到某个 SGI 或 PPI 中断的转发配置值不为0,剩余* 其它 SGI 或 PPI 中断配置值一定是相同的。这里只是要取得当前 CPU 的某个 SGI * 或 PPI 中断转发配置值就够了。* 那又为什么不直接根据 CPU ID 返回 0x01, 0x02, 0x04, 0x08, ... 这样的值呢?* 因为 SGI 或 PPI 中断转发配置寄存器的值它们是【只读的】,具体的值是由硬件设* 计决定的,有可能 CPU0 读到的值是 0x02 ,因为 GIC 的 CPU interface 0 有可* 能连接到 CPU1 ,这在理论上是可能出现的。*/if (mask) /* 硬件实现了某 SGI, PPI 中断的映射,即中断转发配置不为0值 */break;}return mask;
}static int gic_cpu_init(struct gic_chip_data *gic)
{if (gic == &gic_data[0]) {cpu_mask = gic_get_cpumask(gic);gic_cpu_map[cpu] = cpu_mask; /* 当前 CPU @cpu 中断的默认转发配置:只转发给自身 *//** Clear our mask from the other map entries in case they're* still undefined.*/for (i = 0; i < NR_GIC_CPU_IF; i++)if (i != cpu)gic_cpu_map[i] &= ~cpu_mask;}...
}
4.2.2.1 其它非 boot CPU亲和性初始化流程
secondary_start_kernel()notify_cpu_starting(cpu)struct cpuhp_cpu_state *st = per_cpu_ptr(&cpuhp_state, cpu);enum cpuhp_state target = min((int)st->target, CPUHP_AP_ONLINE);...while (st->state < target) {st->state++;ret = cpuhp_invoke_callback(cpu, st->state, true, NULL, NULL);...gic_starting_cpu(cpu)}...
static int gic_starting_cpu(unsigned int cpu)
{gic_cpu_init(&gic_data[0]); /* 见 4.2.2.1 章节分析 */return 0;
}
总结起来就是,在 boot CPU 为 CPU0 的情形下,所有 SPI 中断的 ICDIPTRn 寄存器 都配置为 gic_cpu_map[0] == 0x01 ,即将所有 SPI 中断都转发给 CPU0 处理。注意,SGI 和 PPI 中断不在考虑范围之内,因为它们本来就是特定于 CPU 的。
5. GIC 的救赎?
以下测试均基于 QEMU 模拟的 vexpress-a9 开发板 。
5.1 默认配置成转发给所有CPU
这看起来是比较合理的解决方案,对 GIC 驱动的 gic_set_affinity() 接口做如下修改:
- bit = gic_cpu_map[cpu] << shift;
+ bit = 0xff << shift; /* 默认转发给所有的 CPU */
我们来看一下实际效果:
$ cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 16: 4558 4548 4578 4505 GIC-0 29 Level twd17: 6 0 0 0 GIC-0 34 Level timer27: 0 0 0 0 GIC-0 92 Level arm-pmu28: 0 0 0 0 GIC-0 93 Level arm-pmu29: 0 0 0 0 GIC-0 94 Level arm-pmu30: 0 0 0 0 GIC-0 95 Level arm-pmu34: 1426 1146 1275 1308 GIC-0 41 Level mmci-pl18x (cmd)35: 81272 78233 77890 78991 GIC-0 42 Level mmci-pl18x (pio)36: 0 0 8 0 GIC-0 44 Level kmi-pl05037: 0 0 99 1 GIC-0 45 Level kmi-pl05038: 18 3 0 2 GIC-0 37 Level uart-pl01144: 0 0 0 0 GIC-0 36 Level rtc-pl031
IPI0: 0 1 1 1 CPU wakeup interrupts
IPI1: 0 0 0 0 Timer broadcast interrupts
IPI2: 750 501 548 864 Rescheduling interrupts
IPI3: 0 2 2 1 Function call interrupts
IPI4: 0 0 0 0 CPU stop interrupts
IPI5: 0 0 0 0 IRQ work interrupts
IPI6: 0 0 0 0 completion interrupts
Err: 0
看起来不错,SPI 中断的处理,已经散落到各个 CPU 核上了。如果…,但世界上没有如果,由于 GIC 芯片设计的缺陷,当配置多个 CPU 接收中断的时候,所有这些 CPU 核在中断发生时,都会收到信号,来争抢处理进入的中断,当然最终只会有一个CPU获得胜利,其它的核白白的在那里浪费时间,在有很多核的服务器场景下,这是极大的浪费。如果某核当前正在睡眠,如执行了 WFI,WFE 指令,就会造成能耗,这在很多设备是电池供电的嵌入式环境下,也是不合适的。看看 Russell King 的解释:
The behaviour of the GIC is as follows. If you set two CPUs in
GICD_ITARGETSRn, then the interrupt will be delivered to _both_ of
those CPUs. Not just one selected at random or determined by some
algorithm, but both CPUs.Both CPUs get woken up if they're in sleep, and both CPUs attempt to
process the interrupt. One CPU will win the lock, while the other CPU
spins waiting for the lock to process the interrupt.The winning CPU will process the interrupt, clear it on the device,
release the lock and acknowledge it at the GIC CPU interface.The CPU that lost the previous race can now proceed to process the
very same interrupt, discovers that it's no longer pending on the
device, and signals IRQ_NONE as it appears to be a spurious interrupt.The result is that the losing CPU ends up wasting CPU cycles, and
if the losing CPU was in a low power idle state, needlessly wakes up
to process this interrupt.If you have more CPUs involved, you have more CPUs wasting CPU cycles,
being woken up wasting power - not just occasionally, but almost every
single interrupt that is raised from a device in the system.On architectures such as x86, the PICs distribute the interrupts in
hardware amongst the CPUs. So if a single interrupt is set to be sent
to multiple CPUs, only _one_ of the CPUs is actually interrupted.
Hence, x86 can have multiple CPUs selected as a destination, and
the hardware delivers the interrupt across all CPUs.On ARM, we don't have that. We have a thundering herd of CPUs if we
set more than one CPU to process the interrupt, which is grossly
inefficient.
原文见此处。
5.2 用当前 CPU ID 作为 gic_cpu_map[] 索引
对 GIC 驱动的 gic_set_affinity() 接口做如下修改:
- if (!force)
- cpu = cpumask_any_and(mask_val, cpu_online_mask);
- else
- cpu = cpumask_first(mask_val);
+ cpu = smp_processor_id();
将当前 CPU ID 作为数组 gic_cpu_map[] 的索引,这样 SPI 中断不会集中到 CPU0 上。看一下实际效果:
$ cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 16: 7626 7583 7531 7495 GIC-0 29 Level twd17: 6 0 0 0 GIC-0 34 Level timer27: 0 0 0 0 GIC-0 92 Level arm-pmu28: 0 0 0 0 GIC-0 93 Level arm-pmu29: 0 0 0 0 GIC-0 94 Level arm-pmu30: 0 0 0 0 GIC-0 95 Level arm-pmu34: 0 0 0 2912 GIC-0 41 Level mmci-pl18x (cmd)35: 0 0 0 204459 GIC-0 42 Level mmci-pl18x (pio)36: 0 0 0 8 GIC-0 44 Level kmi-pl05037: 0 0 0 100 GIC-0 45 Level kmi-pl05038: 23 0 0 0 GIC-0 37 Level uart-pl01144: 0 0 0 0 GIC-0 36 Level rtc-pl031
IPI0: 0 1 1 1 CPU wakeup interrupts
IPI1: 0 0 0 0 Timer broadcast interrupts
IPI2: 1423 1288 1527 360 Rescheduling interrupts
IPI3: 1 2 2 1 Function call interrupts
IPI4: 0 0 0 0 CPU stop interrupts
IPI5: 0 0 0 0 IRQ work interrupts
IPI6: 0 0 0 0 completion interrupts
Err: 0
SPI 中断集中在 CPU0,CPU3 两个核上处理,但至少不会集中在同一个核上了。一个改进思路是记录每个核上当前接收的 SPI 中断号个数,然后根据记录,将它们均匀地散落到各个核上,这其实有点类似于我们后面即将提到的 irqbalance 了。但这并不值得提倡,因为这意味将机制实现在内核中,限制了用户空间的灵活性,内核应该只提供策略,而实现留给用户空间。
6. 一个解决方案:irqbalance
使用 irqbalance 是一个常见的解决方案,它的实现原理是:监控 CPU 上的中断处理状况,然后通过 /proc/irq/N/smp_affinity 或 /proc/irq/N/smp_affinity_list 对中断进行 CPU 亲和性配置,让它们均匀的散落到各个 CPU 上去。
irqbalance 是完美的吗?由于可能会经常的改变中断转发的 CPU,所以也会影响到数据访问的 CPU 本地 cache 的命中率,在网络场景下,可能对性能造成损害。世界就是这样,总是这么复杂,没有什么是完美无缺的。
7. 参考资料
《IHI0048A_gic_architecture_spec_v1_0.pdf》
《DDI0471A_gic400_r0p0_trm.pdf》
相关文章:
Linux: ARM GIC仅中断CPU 0问题分析
文章目录1. 前言2. 分析背景3. 问题4. 分析4.1 ARM GIC 中断芯片简介4.1.1 中断类型和分布4.1.2 拓扑结构4.2 问题根因4.2.1 设置GIC SPI中断的CPU亲和性4.2.2 GIC初始化:缺省的CPU亲和性4.2.2.1 boot CPU亲和性初始化流程4.2.2.1 其它非 boot CPU亲和性初始化流程5…...
)
第20篇:Java运算符全面总结(系列二)
目录 4、逻辑运算符 4.1 逻辑运算符 4.2 代码示例 5、赋值运算符 5.1 赋值运算符...
)
OpenCV4.x图像处理实例-OpenCV两小时快速入门(基于Python)
OpenCV两小时快速入门(基于Python) 文章目录 OpenCV两小时快速入门(基于Python)1、OpenCV环境安装2、图像读取与显示3、图像像素访问、操作与ROI4、图像缩放5、几何变换5.1 平移5.2 旋转6、基本绘图6.1 绘制直线6.2 绘制圆6.3 绘制矩形6.4 绘制文本7、剪裁图像8、图像平滑与…...

【Git】Mac忽略.DS_Store文件
我们在github上经常看到某些仓库里面包含了.DS_Store文件,或者某些sdk的压缩包里面可以看到,这都是由于随着git的提交把这类文件也提交到仓库,压缩也是一样,压缩这个先留着后面处理。 Mac上的.DS_Store文件 .DS_Store 文件&#…...
12.2 基于Django的服务器信息查看应用(CPU信息)
文章目录CPU信息展示图表展示-视图函数设计图表展示-前端界面设计折线图和饼图展示饼图测试折线图celery和Django配合实现定时任务Windows安装redis根据数据库中的数据绘制CPU折线图CPU信息展示 图表展示-视图函数设计 host/views.py def cpu(request):logical_core_num ps…...

【软件测试】接口测试总结
本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什么要做? 第二部分࿱…...

代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组
代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组 300.最长递增子序列 题目介绍 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或…...
gitblit 安装使用
1 安装服务端 简而言之:需要安装 java,gitblit, git 三个软件 Windows 10环境使用Gitblit搭建局域网Git服务器 前言 安装Java并配置环境安装gitblit并配置启动gitblit为windows服务使用gitblit创建repository并管理用户 1.1 安装Java并配…...

使用 TensorFlow、Keras-OCR 和 OpenCV 从技术图纸中获取信息
简单介绍输入是技术绘图图像。对象检测模型获取图像后对其进行分类,找到边界框,分配维度,计算属性。示例图像(输入)分类后,找到“IPN”部分。之后,它计算属性,例如惯性矩。它适用于不…...

ESP32设备驱动-GUVA-S12SD紫外线检测传感器驱动
GUVA-S12SD紫外线检测传感器驱动 文章目录 GUVA-S12SD紫外线检测传感器驱动1、GUVA-S12SD介绍2、硬件准备3、软件准备4、驱动实现1、GUVA-S12SD介绍 GUVA-S12SD 紫外线传感器芯片适用于检测太阳光中的紫外线辐射。 它可用于任何需要监控紫外线量的应用,并且可以简单地连接到任…...

WIN7下 program file 权限不足?咋整?!!
在WIN7下对Program Files目录的权限问题 [问题点数:40分,结帖人mysunck] 大部分人说要使用manifest,但是其中一个人说: “安装程序要求管理员很正常,你的程序可以在programfiles,但用户数据不能放那里,因…...
119.(leaflet篇)文字碰撞
听老人家说:多看美女会长寿 地图之家总目录(订阅之前建议先查看该博客) 文章末尾处提供保证可运行完整代码包,运行如有问题,可“私信”博主。 效果如下所示: 下面献上完整代码,代码重要位置会做相应解释 <!DOCTYPE html> <html>...

cuda编程以及GPU基本知识
目录CPU与GPU的基本知识CPU特点GPU特点GPU vs. CPU什么样的问题适合GPU?GPU编程CUDA编程并行计算的整体流程CUDA编程术语:硬件CUDA编程术语:内存模型CUDA编程术语:软件线程块(Thread Block)网格(…...

Python 机器学习/深度学习/算法专栏 - 导读目录
目录 一.简介 二.机器学习 三.深度学习 四.数据结构与算法 五.日常工具 一.简介 Python 机器学习、深度学习、算法主要是博主从研究生到工作期间接触的一些机器学习、深度学习以及一些算法的实现的记录,从早期的 LR、SVM 到后期的 Deep,从学习到工…...
Springboot怎么实现restfult风格Api接口
前言在最近的一次技术评审会议上,听到有同事发言说:“我们的项目采用restful风格的接口设计,开发效率更高,接口扩展性更好...”,当我听到开头第一句,我脑子里就开始冒问号:项目里的接口用到的是…...

Jetpack Compose 深入探索系列六:Compose runtime 高级用例
Compose runtime vs Compose UI 在深入讨论之前,非常重要的一点是要区分 Compose UI 和 Compose runtime。Compose UI 是 Android 的新 UI 工具包,具有 LayoutNodes 的树形结构,它们稍后在画布上绘制其内容。Compose runtime 提供底层机制和…...
 A~E)
23.3.2 Codeforces Round #834 (Div. 3) A~E
FG明天补 A-Yes-Yes? 题面翻译 给定 ttt 个字符串,请判定这些字符串是否分别是 YesYesYesYes…\texttt{YesYesYesYes\dots}YesYesYesYes… 的子串。是则输出 YES,否则输出 NO(YES 和 NO 大小写不定)。 Translated by JYqwq …...
一次失败的面试经历:我只想找个工作,你却用面试题羞辱我!
金三银四近在咫尺,即将又是一波求职月,面对跳槽的高峰期,很多软件测试人员都希望能拿一个满意的高薪offer,但是随着招聘职位的不断增多,面试的难度也随之加大,而面试官更是会择优录取小王最近为面试已经焦头…...

java版工程管理系统 Spring Cloud+Spring Boot+Mybatis实现工程管理系统源码
java版工程管理系统Spring CloudSpring BootMybatis实现工程管理系统 工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和…...
附录3-大事件项目后端-项目准备工作,config.js,一些库的简易用法,main.js
目录 1 一些注意 2 创建数据库 3 项目结构 4 配置文件 config.js 5 参数规则包 hapi/joi与escook/express-joi 5.1 安装 5.2 文档中的demo 5.2.1 定义规则 5.2.2 使用规则 5.3 项目中的使用 5.3.1 定义信息规则 5.3.2 使用规则 6 密码加密包 bcrypt.…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...
损坏诊断全解)
半导体元件(二极管/三极管/MOS管/IC)损坏诊断全解
半导体元件(二极管、三极管、MOS 管、集成电路)是 PCB 的核心功能单元,对过压、过流、ESD、高温极度敏感,损坏后直接导致电路功能失效、短路烧板。很多工程师维修时盲目更换芯片,不仅成本高,还易误判。一…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...