ClickHouse基础知识(四):ClickHouse 引擎详解
1. 表引擎的使用
表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。包括:
➢ 数据的存储方式和位置,写到哪里以及从哪里读取数据。 默认存放在/var/lib/clickhouse/data
➢ 支持哪些查询以及如何支持。
➢ 并发数据访问。
➢ 索引的使用(如果存在)。
➢ 是否可以执行多线程请求。
➢ 数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关 参数。
特别注意:引擎的名称大小写敏感
2. TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表, 生产环境上作用有限。可以用于平时练习测试用。 如:
create table t_tinylog ( id String, name String) engine=TinyLog;3. Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。 读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太 大(上限大概 1 亿行)的场景。
4. MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree) 中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree, 还衍生除了很多小弟,也是非常有特色的引擎。
1)建表语句
create table t_order_mt(id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime
) engine =MergeTreepartition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id);2)插入数据
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');MergeTree 其实还有很多参数(绝大多数用默认值即可),但是三个参数是更加重要的, 也涉及了关于 MergeTree 的很多概念。

主键不唯一,按照年月日来进行分区,同时,他们的排序是分区内的排序,排序中规定的id,sku_id表示如果id相同,就会进行sku_id排序。
4.1 partition by 分区(可选)
1)作用
学过 hive 的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度
2)如果不填
只会使用一个分区(all)。
3)分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文 件就会保存到不同的分区目录中。
bin文件:数据文件
mrk文件:标记文件,标记文件在 idx索引未见和bin数据文件之间起到了桥梁的作用。以mrk2结尾的文件,表示该表启用了自适应索引间隔。
primary.idx文件:主键索引文件,用于加快查询效率。
minmax_create_time.idx:分区键的最大最小值
checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值。分区目录名的解释:
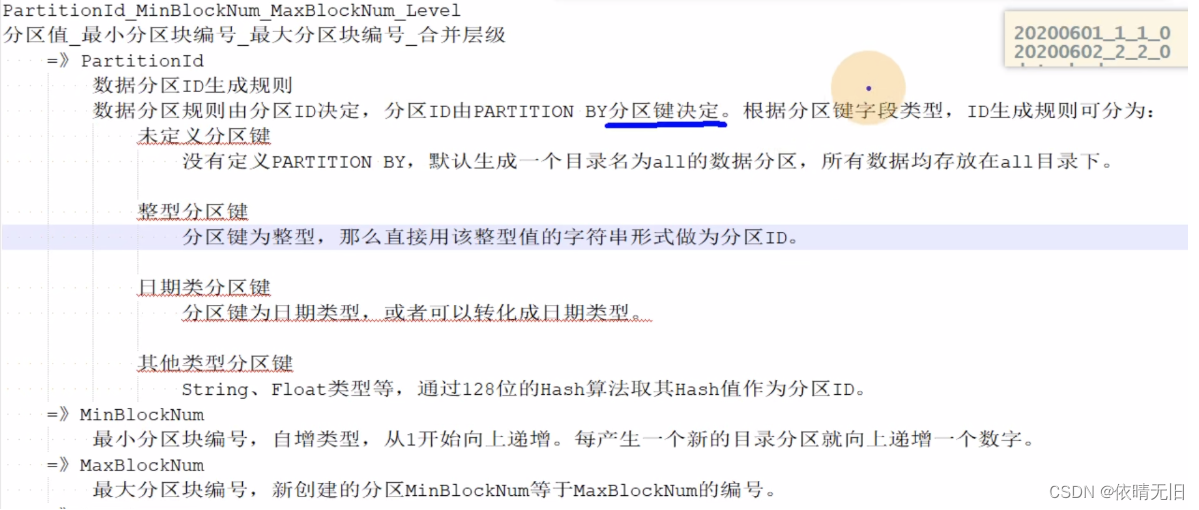
=》Level:合并的层级,被合并的次数。合并次数越多,层级越大。
4)并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
5)数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动 通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;6)例如:再次执行上面的插入操作
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');查看数据并没有纳入任何分区
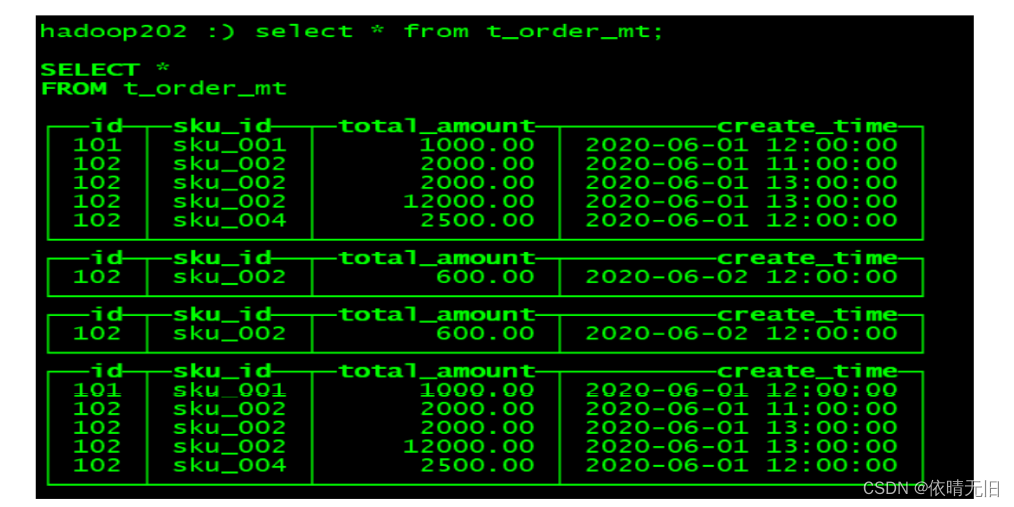
手动 optimize 之后
hadoop102 :) optimize table t_order_mt final; 再次查询

4.2 primary key 主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数 据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引(查找时类似于一个二分查找法):

稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索 引粒度的第一行,然后再进行进行一点扫描。
4.3 order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是 order by 字段的前缀字段。
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
4.4 二级索引
目前在 ClickHouse 的官网上二级索引的功能在 v20.1.2.4 之前是被标注为实验性的,在 这个版本之后默认是开启的。
1)老版本使用二级索引前需要增加设置
是否允许使用实验性的二级索引(v20.1.2.4 开始,这个参数已被删除,默认开启)
set allow_experimental_data_skipping_indices=1;2)创建测试表
create table t_order_mt2(id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 5
) engine =MergeTreepartition by toYYYYMMDD(create_time)primary key (id)order by (id, sku_id);其中 GRANULARITY N 是设定二级索引对于一级索引粒度的粒度。
3)插入数据
insert into t_order_mt2 values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');4)对比效果
那么在使用下面语句进行测试,可以看出二级索引能够为非主键字段的查询发挥作用。
clickhouse-client --send_logs_level=trace <<< 'select
* from t_order_mt2 where total_amount > toDecimal32(900., 2)';
4.5 数据 TTL
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。
1)列级别 TTL
(1)创建测试表
create table t_order_mt3(id UInt32,sku_id String,total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)primary key (id)order by (id, sku_id);(2)插入数据(注意:根据实际时间改变)
insert into t_order_mt3 values
(106,'sku_001',1000.00,'2021-01-26 11:26:30'),
(107,'sku_002',2000.00,'2021-01-26 11:26:30'),
(110,'sku_003',600.00,'2021-01-26 11:26:00');(3)手动合并,查看效果 到期后,指定的字段数据归 0,然后退出命令行,再次进入
hadoop101 :) optimize table t_order_mt3 final;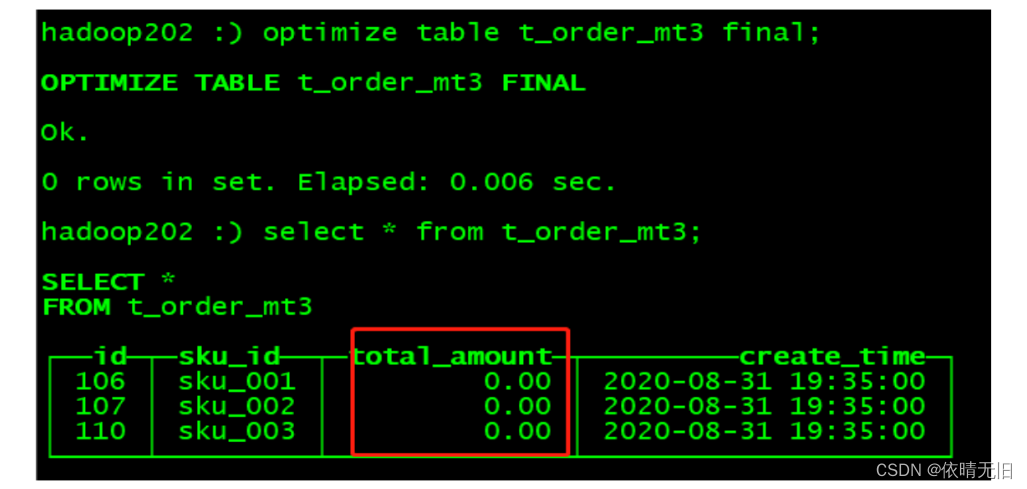
2)表级 TTL
下面的这条语句是数据会在 create_time 之后 10 秒丢失
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND; 涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
5. ReplacingMerge Tree
ReplacingMerge Tree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束 的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。
1)去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预 先作出计划。有一些数据可能仍未被处理。
2)去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
所以 ReplacingMergeTree 能力有限, ReplacingMergeTree 适用于在后台清除重复的数 据以节省空间,但是它不保证没有重复的数据出现。
3)案例演示
(1)创建表
create table t_order_rmt(id UInt32,sku_id String,total_amount Decimal(16,2) ,create_time Datetime
) engine =ReplacingMergeTree(create_time)partition by toYYYYMMDD(create_time)primary key (id)order by (id, sku_id);ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。
如果不填版本字段,默认按照插入顺序保留最后一条。
(2)向表中插入数据
insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');(3)执行第一次查询
hadoop102 :) select * from t_order_rmt;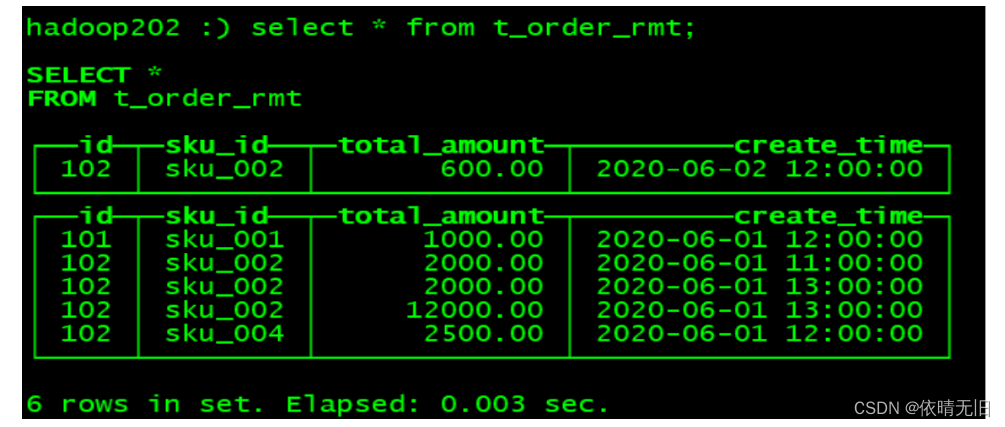
(4)手动合并
OPTIMIZE TABLE t_order_rmt FINAL;(5)再执行一次查询
hadoop102 :) select * from t_order_rmt;
4)通过测试得到结论
➢ 实际上是使用 order by 字段作为唯一键
➢ 去重不能跨分区
➢ 只有同一批插入(新版本)或合并分区时才会进行去重
➢ 认定重复的数据保留,版本字段值最大的
➢ 如果版本字段相同则按插入顺序保留最后一笔
6. SummingMerge Tree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree 的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree
1)案例演示
(1)创建表
create table t_order_smt(id UInt32,sku_id String,total_amount Decimal(16,2) ,create_time Datetime
) engine =SummingMergeTree(total_amount)partition by toYYYYMMDD(create_time)primary key (id)order by (id,sku_id );(2)插入数据
insert into t_order_smt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');(3)执行第一次查询
hadoop102 :) select * from t_order_smt;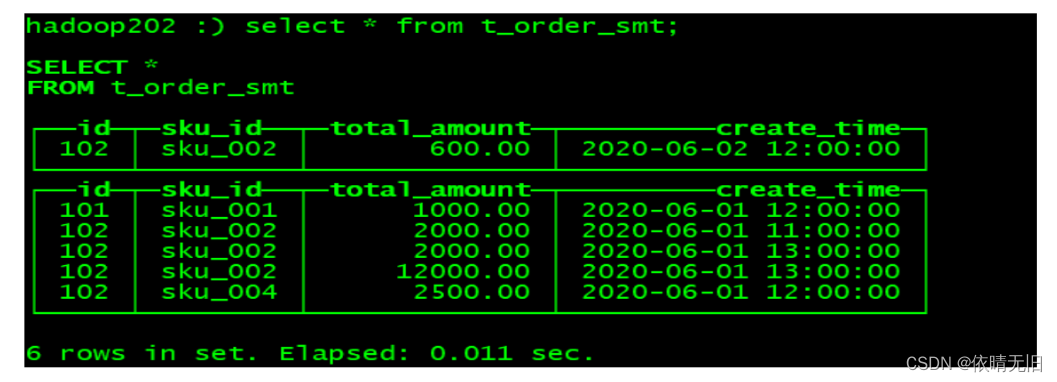
(4)手动合并
OPTIMIZE TABLE t_order_smt FINAL;(5)再执行一次查询
hadoop102 :) select * from t_order_smt;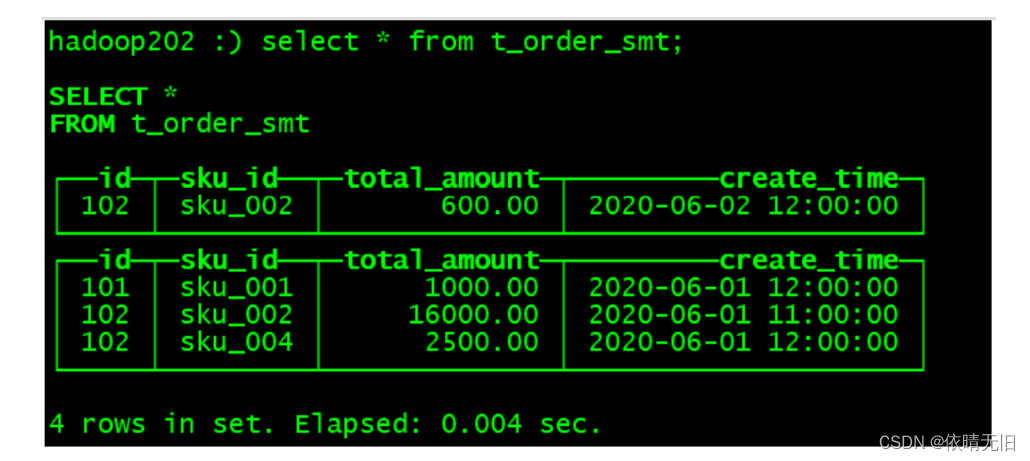
2)通过结果可以得到以下结论
➢ 以 SummingMergeTree()中指定的列作为汇总数据列
➢ 可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
➢ 以 order by 的列为准,作为维度列
➢ 其他的列按插入顺序保留第一行
➢ 不在一个分区的数据不会被聚合
➢ 只有在同一批次插入(新版本)或分片合并时才会进行聚合
3)开发建议
设计聚合表的话,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳。
4)问题
能不能直接执行以下 SQL 得到汇总值
select total_amount from XXX where province_name=’’ and create_date=’xxx’ 不行,可能会包含一些还没来得及聚合的临时明细
如果要是获取汇总值,还是需要使用 sum 进行聚合,这样效率会有一定的提高,但本 身 ClickHouse 是列式存储的,效率提升有限,不会特别明显。
select sum(total_amount) from province_name=’’ and create_date=‘xxx’相关文章:
ClickHouse基础知识(四):ClickHouse 引擎详解
1. 表引擎的使用 表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。包括: ➢ 数据的存储方式和位置,写到哪里以及从哪里读取数据。 默认存放在/var/lib/clickhouse/data ➢ 支持哪些查询以及如何支持。 ➢ 并发数…...
关于设计模式、Java基础面试题
前言 之前为了准备面试,收集整理了一些面试题。 本篇文章更新时间2023年12月27日。 最新的内容可以看我的原文:https://www.yuque.com/wfzx/ninzck/cbf0cxkrr6s1kniv 设计模式 单例共有几种写法? 细分起来就有9种:懒汉&#x…...

Python爱心光波完整代码
文章目录 环境需求完整代码详细分析环境需求 python3.11.4PyCharm Community Edition 2023.2.5pyinstaller6.2.0(可选,这个库用于打包,使程序没有python环境也可以运行,如果想发给好朋友的话需要这个库哦~)【注】 python环境搭建请见:https://want595.blog.csdn.net/arti…...

PowerShell Instal 一键部署gitea
gitea 前言 Gitea 是一个轻量级的 DevOps 平台软件。从开发计划到产品成型的整个软件生命周期,他都能够高效而轻松的帮助团队和开发者。包括 Git 托管、代码审查、团队协作、软件包注册和 CI/CD。它与 GitHub、Bitbucket 和 GitLab 等比较类似。 Gitea 最初是从 Gogs 分支而来…...
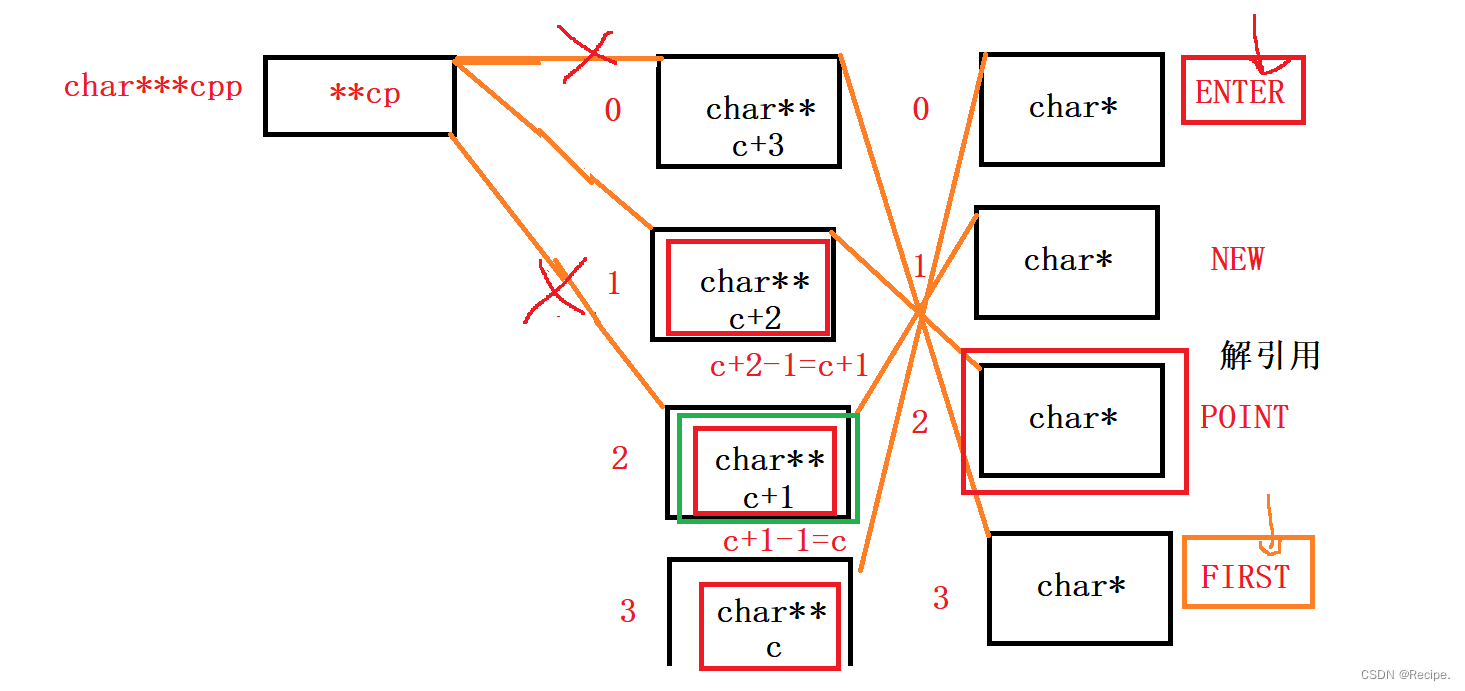
C语言——指针题目“指针探测器“
如果你觉得你指针学的自我感觉良好,甚至已经到达了炉火纯青的地步,不妨来试试这道题目? #include<stdio.h> int main() {char* c[] { "ENTER","NEW","POINT","FIRST" };char** cp[] { c 3…...
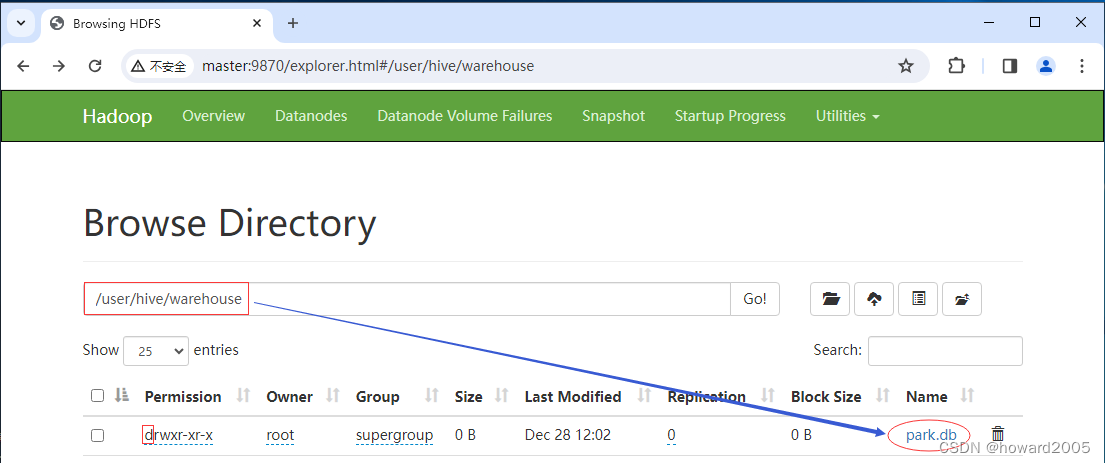
Hive讲课笔记:内部表与外部表
文章目录 一、导言二、内部表1.1 什么是内部表1.1.1 内部表的定义1.1.2 内部表的关键特性 1.2 创建与操作内部表1.2.1 创建并查看数据库1.2.2 在park数据库里创建student表1.2.3 在student表插入一条记录1.2.4 通过HDFS WebUI查看数据库与表 三、外部表2.1 什么是外部表2.2 创建…...

Docker本地部署开源浏览器Firefox并远程访问进行测试
文章目录 1. 部署Firefox2. 本地访问Firefox3. Linux安装Cpolar4. 配置Firefox公网地址5. 远程访问Firefox6. 固定Firefox公网地址7. 固定地址访问Firefox Firefox是一款免费开源的网页浏览器,由Mozilla基金会开发和维护。它是第一个成功挑战微软Internet Explorer浏…...

PHP:服务器端脚本语言的瑰宝
PHP(Hypertext Preprocessor)是一种广泛应用于服务器端编程的开源脚本语言,它以其简单易学、灵活性和强大的功能而成为Web开发的瑰宝。本文将深入介绍PHP的历史、特性、用途以及与生态系统的关系,为读者提供对这门语言全面的了解。…...

【MySQL】数据库并发控制:悲观锁与乐观锁的深入解析
🍎个人博客:个人主页 🏆个人专栏: 数 据 库 ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 悲观锁(Pessimistic Locking): 乐观锁(Optimistic Locking): 总结&#x…...

作业--day38
1.定义一个Person类,包含私有成员,int *age,string &name,一个Stu类,包含私有成员double *score,Person p1,写出Person类和Stu类的特殊成员函数,并写一个Stu的show函数ÿ…...

pytest 的 fixture 固件机制
一、前置说明 固件(fixture)是一些函数,pytest 会在执行测试函数之前(或之后)加载运行它们。pytest 使用 fixture 固件机制来实现测试的前置和后置操作,可以方便地设置和共享测试环境。 二、操作步骤 1. 编写测试代码 atme/demos/demo_pytest_tutorials/test_pytest_…...

分布式技术之分布式计算Stream模式
文章目录 什么是 Stream?Stream 工作原理Storm 的工作原理 实时性任务主要是针对流数据的处理,对处理时延要求很高,通常需要有常驻服务进程,等待数据的随时到来随时处理,以保证低时延。处理流数据任务的计算模式&#…...

2023年12月GESP Python五级编程题真题解析
【五级编程题1】 【试题名称】:小杨的幸运数 【问题描述】 小杨认为,所有大于等于a的完全平方数都是他的超级幸运数。 小杨还认为,所有超级幸运数的倍数都是他的幸运数。自然地,小杨的所有超级幸运数也都是幸运数。 对于一个…...
探索Apache Commons Imaging处理图像
第1章:引言 大家好,我是小黑,咱们今天来聊聊图像处理。在这个数字化日益增长的时代,图像处理已经成为了一个不可或缺的技能。不论是社交媒体上的照片编辑,还是专业领域的图像分析,图像处理无处不在。而作为…...

【11】ES6:async/await
一、概念 async/await 是 ES2017(ES8)的新特性,它是一种基于 Promise 实现的异步编程方式。async/await 也是一种语法糖。 1、async/await 实现了用同步方式来写异步代码(promise是链式调用形式写异步代码) 2、asyn…...

深入理解Java集合框架
导语: Java集合框架是Java提供的一组用于管理对象的类和接口,它是Java编程中非常重要的一部分。Java集合框架通过提供诸如List、Set、Map等数据结构,为程序员提供了一种方便、高效的管理对象的方式。本文将深入理解Java集合框架,包…...

极智嘉加快出海发展步伐,可靠产品方案获客户认可
2023年,国内本土企业加快出海征程,不少企业在出海发展中表现出了优越的集团实力与创新的产品优势,有力彰显了我国先进的科技研发实力。作为全球仓储机器人引领者,极智嘉(Geek)也在不断加快出海发展步伐&…...

运动目标检测方法的概述
目录 ① 光流法 ② 帧差法 ③ 背景差分法 ④ 混合高斯模型法 ⑤ 总结 运动目标检测技术的应用十分的广泛,尤其是在智能视频监控领域。运动目标检测为后续的图像处理等操作提供了基础,在某种程度上,决定了整个系统的性能。运动目标检测&a…...

【Qt-Edit】
Qt编程指南 ■ QTextEdit■ QLineEdit■ QLineEdit 设置正则表达式■ QPlainTextEdit■ QKeySequenceEdit■ QList<QLineEdit *> edits■■■ QTextEdit /* 实例和对象,设置位置和显示大小 */ textEdit = new QTextEdit(this)...

vue data变量不能以“_”开头,否则会产生很多怪异问题
1、 比如给子组件赋值,子组件无法得到这个值(也不是一直无法得到,设置后this.$forceUpdate() 居然可以得到), 更无法watch到 <zizujian :config"_config1"> </zizujian>this._config1 { ...…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...