Impala4.x源码阅读笔记(三)——Impala如何管理Iceberg表元数据
前言
本文为笔者个人阅读Apache Impala源码时的笔记,仅代表我个人对代码的理解,个人水平有限,文章可能存在理解错误、遗漏或者过时之处。如果有任何错误或者有更好的见解,欢迎指正。
上一篇文章Impala4.x源码阅读笔记(二)——Impala如何高效读取Iceberg表简单介绍了Iceberg表的基本情况和Impala是如何对其进行扫描的。这一篇则从元数据的角度对Impala如果管理Iceberg元数据进行一些简单的分析,这里的Iceberg元数据不是指Iceberg的那些元数据文件,那些是Iceberg API负责管理的,这里的元数据是指Iceberg表在Impala中的那些内存对象。
为了提升查询性能,Impala本身有一套比较复杂的元数据管理机制,这套机制以Catalogd服务进程为核心,实现了元数据在集群内的集中管理。在一个完整的Impala集群中,Catalogd服务进程主要担任了两个角色,首先是一个自动化的元数据缓存,它会负责缓存并自动同步Hive Metastore中的元数据,并将其广播给集群中其他负责处理查询的Coordinator节点,这使得Coordinator可以省去每次查询时和Hive Metastore(HMS)以及HDFS Namenode(NN)的交互,从而缩短了查询耗时。Catalogd的另一个角色是一个集中式的DDL执行者,其他Coordinator节点接收到的DDL最终都会以RPC的形式交由Catalogd进行执行,这样使得集群内部的元数据统一得到了保证。
Iceberg表作为一种表格式而非文件格式,其核心目标是高效且多功能地管理大量的数据文件,为了达成这一目标,Iceberg表的元数据相较于Hive表也更加复杂,从Impala支持Iceberg表的代码大部分都是元数据相关的也能看出这一点。关于Iceberg元数据管理的代码十分庞大,想要在一篇文章内全面地分析一遍是不太现实的,所以本文首先还是整体地、笼统地描述一下Iceberg表元数据的全貌,然后着重对元数据管理的两个关键环节——Iceberg表的加载和创建进行分析。
Iceberg表的相关接口
由于Impala本身元数据管理的特性和Iceberg表元数据的特殊性,在Impala支持Iceberg表各项功能的过程中定义了很多类型,我们首先看一下Iceberg相关类的整体UML图:

图中画出了Iceberg表在Impala中的主要相关接口和类以及其之间的实现或继承关系,其中绿色背景的就是与Iceberg表直接相关的,每个接口和类中都只列举了个别关键的成员变量和方法。在介绍具体的类之前我们先看一下其中的几个接口。
FeTable
首先是Impala中所有类型的表都要实现的接口FeTable,它定义了Impala Frontend与各类型表交互的一些基本操作,比如获取获取库表名、数据列列表、所有者等,其中还包括了可以获取org.apache.hadoop.hive.metastore.api.Table对象的getMetaStoreTable()方法。因为Impala对HMS是强依赖的,基本上所有元数据都来自HMS,为了与HMS进行元数据交互,Impala中所有类型的表中都包括一个HMS中表对象也就是org.apache.hadoop.hive.metastore.api.Table。它为Impala的表提供了基本的元数据,比如库表名、字段信息和表属性properties等。Iceberg表在Impala也不例外,需要在HMS注册了才能被Impala查询。当然Iceberg表本身并不一定依赖HMS,比如使用HadoopCatalog创建的Iceberg表只依赖一个像HDFS一样的支持原子重命名文件的文件系统而已。对于这种Iceberg表需要先在Impala中通过创建外表的方式在HMS进行注册才能被Impala元数据管理所接受。
FeFsTable
FeFsTable是Impala中所有基于文件系统的表类型都要实现的接口,它继承了FeTable接口,作用也是类似的。像存储在HDFS、S3这种常见的文件系统或存储服务上的表都属于FeFsTable,Iceberg表自然也是FeFsTable。在FeTable的基础之上,FeFsTable额外定义了许多和文件系统相关的方法,比如获取文件系统类型、表位置和文件系统对象FileSystem等。
FeIcebergTable
FeIcebergTable是Impala中Iceberg表类型都要实现的接口,继承了FeFsTable并额外定义了关于Iceberg的通用方法。其中有几个关键方法需要重点介绍:
-
getFeFsTable(),它会返回Iceberg对象内置的一个FeFsTable对象,这个对象会被用于将Iceberg表传递给Impala Backend。我们知道在Impala中Frontend负责制定执行计划、Backend负责执行,两者分别由Java和C++开发,之间主要通过Thrift结构体传递数据,这些数据也包括了查询的执行计划。而Iceberg表在执行期间与普通HDFS表实际上并没有显著差别,可以说都只是一系列规划好的数据文件而已。因此,为了复用Backend中现有的HDFS表扫描代码,Iceberg表对象都内置了一张普通HDFS表对象,在序列化为Thrift结构体传递给Backend时就使用这个内置的FeFsTable对象的相关方法将自身“转变”为HDFS表。 -
getIcebergApiTable(),它会返回Iceberg表对象对应的Iceberg API中的表对象org.apache.iceberg.Table,这是Iceberg API中的表示Iceberg表的接口,它提供了Iceberg表的许多重要API,比如获取快照、Schema和扫描计划。依靠这些接口,Impala可以进行Iceberg表的时间旅行查询、模式演进、谓词下推和获取数据文件列表等操作。 -
getIcebergCatalog(),它会返回Iceberg表的Catalog类型,目前Impala支持的Iceberg Catalog类型有HadoopTables、HadoopCatalog、HiveCatalog和Catalogs。Iceberg的Catalog是用于追踪Iceberg表的,它主要负责储存Iceberg表最近元数据文件的位置,可以说是Iceberg表元数据的元数据。换句话说如果说Iceberg表是管理一系列数据文件并告诉我们数据文件在哪里,那么Iceberg Catalog的作用就是管理一系列Iceberg表并告诉我们Iceberg表在哪里。如果Iceberg表的最近元数据位置也直接储存在文件系统的一个文件中,则对应HadoopTables。如果文件系统中有一个专门的Catalog目录,Iceberg表的元数据位置由其负责管理,则对应HadoopCatalog。如果使用HMS储存Iceberg表的最近元数据位置,则对应HiveCatalog。而Catalogs接口相当于一种复合的自动Catalog,它依赖配置文件和表属性自动识别Iceberg表的Catalog类型。
接口FeIcebergTable可以说是Iceberg表在Impala中的关键抽象,从图中也可以看到许多Iceberg表的相关类实现了该接口。
Iceberg表的相关类
介绍完了相关接口之后,我们接下来继续看看Iceberg相关的类。从图中可以看到与Iceberg直接相关的表类型就有足足七种,当然其中除了IcebergTable和LocalIcebergTable这两个真正表示实际存在的Iceberg表的“正经”表类型外,其他的都可以算是为了支持各种Iceberg特性而抽象出来的功能性的工具类。接下来我们逐个介绍。
IcebergTable
IcebergTable是Iceberg表在Impala元数据管理中的代理类之一,每个对象都是对应了一张实际存在的Iceberg表。IcebergTable实现了FeIcebergTable接口并继承了Table类。Table类是Impala中所有表类的主要父类之一(另一个是LocalTable),它是一个抽象类,实现了FeTable接口,它定义了所有表共有的一些成员变量,如库对象、表名、所有者、表锁和数据列容器等等,它还定义了表对象共有的一些成员方法,其中最重要的就是实现表加载的抽象方法load()以及Coordinator接收到Catalogd服务广播的元数据Thrift结构体后从Thrift结构体加载元数据的loadFromThrift(TTable)方法。IcebergTable作为Table的子类,实现了自己的load()方法来加载Iceberg表,除此之外还包括一些特有的成员,如前文提到的内置的HDFS表对象hdfsTable_、Iceberg API表对象icebergApiTable_和从Iceberg元数据加载Schema的方法loadSchemaFromIceberg()等等。
LocalIcebergTable
LocalIcebergTable可以理解为IcebergTable的Local版本,它只在Coordinator的Local Catalog模式下使用,而IcebergTable会在Catalogd和Coordinator的传统Catalog模式下使用,LocalIcebergTable在Coordinator的作用和IcebergTable基本是一致的,可以说是更加轻量化的IcebergTable。Local Catalog模式是为了解决传统Catalog模式的一些缺点而设计的,它支持更细粒度的元数据缓存并能在启动时按需加载元数据,提升了Coordinator的启动速度并减少了内存消耗。LocalIcebergTable同样实现了FeIcebergTable接口,但是继承的是LocalTable类,而不是Table类。LocalTable类也是抽象类,是Table类的Local版本,其成员LocalDb这是Db类的Local版本。如同IcebergTable一样,LocalIcebergTable也内置了一张HDFS表对象,不过不再是HdfsTable类了,而是其Local版本的LocalFsTable,这些Local类都是只在Coordinator的Local Catalog模式下使用的,和非Local版本一一对应。
IcebergPositionDeleteTable
IcebergPositionDeleteTable是用于Iceberg MOR的虚拟表,在上一篇文章中其实已经登场过了,它只在制定Iceberg的Position Delete扫描计划中会被使用到,用来将Iceberg表的Delete File组织为一张虚拟表,这样才能使用Impala的ScanNode进行扫描,具体的使用过程可以参考上一篇文章Impala4.x源码阅读笔记(二)——Impala如何高效读取Iceberg表。IcebergPositionDeleteTable同样实现了FeIcebergTable接口,不过它继承的是表示虚拟表的抽象类VirtualTable,虚拟表不是实际存在的表,而是为了实现某些特定功能而虚拟出来的表,它往往会根据需要而添加一些虚拟列,可以将非表形式的数据以表的形式进行处理。
IcebergMetadataTable
Iceberg API提供了一系列专门的元数据表来查询Iceberg表的元数据,可通过其MetadataTableUtils类来创建各种类型的Iceberg元数据表,如ManifestEntriesTable、FilesTable和SnapshotsTable等。这些元数据表基于基本的Iceberg表创建,有各自的Schema,用于查询该表的各种元数据。IcebergMetadataTable就是Impala为了对接这些Iceberg元数据表而定义的类,它是另外一个继承了VirtualTable的类,不过它并没有实现FeIcebergTable接口,因为它不是通常的Iceberg表。它可以根据一个FeIcebergTable对象和元数据表类型字符串来创建,利用MetadataTableUtils来对接Iceberg元数据表获取Schema并依此填充自身作为VirtualTable的虚拟列,执行时IcebergMetadataTable由执行引擎这边的专门的IcebergMetadataScanNode负责扫描,当然由于执行引擎是C++编写的,所以实际扫描时还是需要通过JNI调用Iceberg API来完成。
IcebergCtasTarget
IcebergCtasTarget是用于CTAS(Create Table As Select)语句的临时目标表类型,它继承了CtasTargetTable类并实现了FeIcebergTable接口,不过它也不是实际存在的表,只是用于CTAS的分析过程。Impala分析CTAS语句时会将其分解为CREATE语句和INSERT语句,然后根据CREATE语句先创建临时目标表,再结合临时目标表来分析INSERT语句。如果分析过程顺利完成才会真正创建目标表。对于Iceberg表来说,临时目标表只是分析使用的,不应该通过Iceberg API实际创建它,所以需要IcebergCtasTarget来充当这一角色。IcebergCtasTarget实现了FeIcebergTable,但是并不会通过Iceberg API实际创建一张Iceberg表。
ForwardingFelcebergTable
ForwardingFelcebergTable一个用于FeIcebergTable的转发类,也并非什么实际存在的表,只是一种使用组合代替继承的编程技巧,通过ForwardingFelcebergTable可以在不继承基类的前提下将不需要重写的方法委托给基类FeIcebergTable。这个类会在IcebergTimeTravelTable中使用,避免IcebergTimeTravelTable继承IcebergTable、LocalIcebergTable等类。
IcebergTimeTravelTable
IcebergTimeTravelTable表示进行时间旅行的Iceberg表,由于Iceberg表时间旅行和模式演进的特性,在不同的时间点Iceberg表可能有不同的Schema,因此对于进行时间旅行的Iceberg表我们需要根据时间或版本重新加载Schema,为了避免复制或破坏原始的Iceberg元数据,Impala通过IcebergTimeTravelTable来实现时间旅行的Iceberg表。IcebergTimeTravelTable没有继承FeIcebergTable而是继承了ForwardingFelcebergTable,通过ForwardingFelcebergTable嵌入对原始Iceberg表的引用并在此基础之上实现readSchema()加载自己的Schema,而那些未涉及时间旅行的方法都可以通过ForwardingFelcebergTable委托给原始Iceberg表类的同名方法 。
至此Iceberg表在Impala中的相关类就介绍完了,可以发现除了IcebergTable和LocalIcebergTable可以真正称得上是Iceberg表的元数据之外,其他的类都是为了实现Iceberg表的各种功能而定义工具类,这些繁多的类看起来复杂,实际上本身代码量并不多,不如说正是因为定义了这些类才使得Iceberg元数据更好地融入Impala的元数据体系,也使得Impala在支持Iceberg的过程中可以大量复用现有的、可靠的、高性能的代码,反而减少了开发工作量。
Iceberg表的加载
接下来我们分析一下Iceberg表在Impala中是如何加载的,所谓表的加载实际上就是Impala根据HMS的元数据对象创建自己的元数据对象的过程,对于Iceberg也是一样的,不过Iceberg还有很大一部分元数据以文件的形式存在,需要Iceberg API处理。不过在调用IcebergTable的load()方法之前我们需要先知道它是一张Iceberg表,这一判断由其静态方法isIcebergTable()完成:
public static boolean isIcebergTable(org.apache.hadoop.hive.metastore.api.Table msTbl) {// 从HMS元数据获取InputFormat,如果是org.apache.iceberg.mr.hive.HiveIcebergInputFormat// 则HdfsFileFormat会是HdfsFileFormat.ICEBERGString inputFormat = msTbl.getSd().getInputFormat();HdfsFileFormat hdfsFileFormat = inputFormat != null ?HdfsFileFormat.fromHdfsInputFormatClass(inputFormat, null) :null;// 如果表属性中的storage_handler值为org.apache.iceberg.mr.hive.HiveIcebergStorageHandler// 或者HdfsFileFormat为HdfsFileFormat.ICEBERG// 或者table_type值为ICEBERG,则会认为这是一张Iceberg表return isIcebergStorageHandler(msTbl.getParameters().get(KEY_STORAGE_HANDLER)) ||hdfsFileFormat == HdfsFileFormat.ICEBERG ||(hdfsFileFormat == null &&"ICEBERG".equals(msTbl.getParameters().get("table_type")));}
根据表属性判断是一张Iceberg表之后,就可以使用IcebergTable的load()方法加载元数据了:
@Override
public void load(boolean reuseMetadata, IMetaStoreClient msClient,org.apache.hadoop.hive.metastore.api.Table msTbl, String reason)throws TableLoadingException {... // 省略一些非关键代码// IcebergUtil.loadTable()方法会通过Iceberg API加载Iceberg表元数据,返回一个Iceberg的Table对象icebergApiTable_ = IcebergUtil.loadTable(this);catalogSnapshotId_ = FeIcebergTable.super.snapshotId();// loadSchemaFromIceberg()方法会将Iceberg Schema转换为Hive Schema并设置到HMS的Table对象msTable_中// 同时还会将Iceberg Schema转换为Impala的Column并添加到自身的列容器colsByPos_和colsByName_中// 这些转换的过程实际上就是遍历Iceberg Schema的每个字段,创建对应类型的Hive或Impala类型// 此外还有添加虚拟列、加载分区Spec等操作loadSchemaFromIceberg();// 然后是一些表属性的设置icebergFileFormat_ = IcebergUtil.getIcebergFileFormat(msTbl);icebergParquetCompressionCodec_ = Utils.getIcebergParquetCompressionCodec(msTbl);icebergParquetRowGroupSize_ = Utils.getIcebergParquetRowGroupSize(msTbl);icebergParquetPlainPageSize_ = Utils.getIcebergParquetPlainPageSize(msTbl);icebergParquetDictPageSize_ = Utils.getIcebergParquetDictPageSize(msTbl);// 通过IcebergUtil.getIcebergFiles()方法可以获取Iceberg表的数据文件集合// 这个方法还支持传入谓词列表和时间旅行描述来进行谓词下推和时间旅行,得到对应的文件集合// 这里要获取最新快照的全部数据文件来缓存,所以传入空列表和空指针GroupedContentFiles icebergFiles = IcebergUtil.getIcebergFiles(this,new ArrayList<>(), /*timeTravelSpec=*/null);// 最后我们还需要加载Iceberg内置的Hdfs表hdfsTable_.setIcebergFiles(icebergFiles);hdfsTable_.setCanDataBeOutsideOfTableLocation(!Utils.requiresDataFilesInTableLocation(this));hdfsTable_.load(reuseMetadata, msClient, msTable_, reason);... // 省略一些非关键代码
}
可以看到加载过程中调用了许多其他方法,不过其中最关键的还是用来加载Iceberg API中的Table对象的IcebergUtil.loadTable()方法:
public static Table loadTable(FeIcebergTable feTable) throws IcebergTableLoadingException {// 调用下面的重载方法return loadTable(feTable.getIcebergCatalog(), getIcebergTableIdentifier(feTable),feTable.getIcebergCatalogLocation(), feTable.getMetaStoreTable().getParameters());
}public static Table loadTable(TIcebergCatalog catalog, TableIdentifier tableId,String location, Map<String, String> tableProps) throws IcebergTableLoadingException {...// 根据Catalog类型获取对应的IcebergCatalog实例,然后使用该Catalog实例的loadTable方法加载Iceberg表IcebergCatalog cat = getIcebergCatalog(catalog, location);return cat.loadTable(tableId, location, tableProps);
}public static IcebergCatalog getIcebergCatalog(TIcebergCatalog catalog, String location)throws ImpalaRuntimeException {switch (catalog) {// 正如前文所述,Impala目前支持四种Iceberg Catalog,它们在Impala中都对应了各自的单例对象// 这些对象都实现了Impala的IcebergCatalog接口,提供诸如createTable()/loadTable()/dropTable()等方法// 这些IcebergCatalog类封装了对应的Iceberg API,比如IcebergHiveCatalog封装了Iceberg包的HiveCatalog// 它们的loadTable()实际上也就是调用了对应的Iceberg API中Catalog的loadTable()方法case HADOOP_TABLES: return IcebergHadoopTables.getInstance();case HIVE_CATALOG: return IcebergHiveCatalog.getInstance();case HADOOP_CATALOG: return new IcebergHadoopCatalog(location);case CATALOGS: return IcebergCatalogs.getInstance();default: throw new ImpalaRuntimeException("Unexpected catalog type: " + catalog);}
}
Iceberg表的加载过程虽然步骤很多但还是比较清晰的,每部分逻辑都封装为了特定的方法来完成,从方法名也能大致了解其作用。
Iceberg表的创建
除了表的加载之外,表的创建也是元数据另外一个源头,在Impala中DDL由Coordinator解析&分析为特定类型的参数集合,然后通过RPC远程调用Catalogd进程的方法来执行。建表的过程也不例外,在Catalogd进程的Catalog操作执行类CatalogOpExecutor中由方法createTable()完成:
private boolean createTable(TCreateTableParams params, TDdlExecResponse response,EventSequence catalogTimeline, boolean syncDdl, boolean wantMinimalResult)throws ImpalaException {... // 省略一些非关键代码// 根据建表参数params先创建一个基本的HMS Table对象,后续建表过程主要就依赖这个对象了org.apache.hadoop.hive.metastore.api.Table tbl = createMetaStoreTable(params);LOG.trace("Creating table {}", tableName);if (KuduTable.isKuduTable(tbl)) {// 创建Kudu表的分支return createKuduTable(tbl, params, wantMinimalResult, response, catalogTimeline);} else if (IcebergTable.isIcebergTable(tbl)) {// 创建Iceberg表的分支,调用更具体的createIcebergTable()方法来进行return createIcebergTable(tbl, wantMinimalResult, response, catalogTimeline,params.if_not_exists, params.getColumns(), params.getPartition_spec(),params.getTable_properties(), params.getComment());}... // 省略一些非关键代码
}我们接着看createIcebergTable()方法:
private boolean createIcebergTable(org.apache.hadoop.hive.metastore.api.Table newTable,boolean wantMinimalResult, TDdlExecResponse response, EventSequence catalogTimeline,boolean ifNotExists, List<TColumn> columns, TIcebergPartitionSpec partitionSpec,Map<String, String> tableProperties, String tblComment) throws ImpalaException {... // 省略部分代码// 首先获取Iceberg表的Catalog类型,这直接决定了Iceberg表的创建方法TIcebergCatalog catalog = IcebergUtil.getTIcebergCatalog(newTable);String location = newTable.getSd().getLocation();// 如果用户在通过Impala创建一张全新的Iceberg表,也就是同步表,则需要先通过Iceberg API创建一张Iceberg表// 所谓同步表也就是非外表或设置了Purge的外表,这两种情况下我们都期望目标Iceberg表还不存在if (IcebergTable.isSynchronizedTable(newTable)) {// 在使用Iceberg API创建Iceberg表前先需要明确表的创建位置// 如果SQL中没有指定表位置,我们需要根据Catalog类型指定一个表位置if (location == null) {if (catalog == TIcebergCatalog.HADOOP_CATALOG) {// 使用Hadoop Catalog时,建表时应当通过表属性iceberg.catalog_location明确指定Hadoop Catalog的位置location = IcebergUtil.getIcebergCatalogLocation(newTable);} else {// 使用其他Catalog时,使用HMS的API为新表生成一个位置location = MetastoreShim.getPathForNewTable(msClient.getHiveClient().getDatabase(newTable.getDbName()),newTable);}}// 通过IcebergCatalogOpExecutor调用Iceberg API创建一张Iceberg表// IcebergCatalogOpExecutor.createTable()方法会创建Iceberg API的Schema、PartitionSpec对象// 然后根据Catalog类型获取对应的IcebergCatalog实例,然后使用其createTable方法创建Iceberg表// 这一过程与加载Iceberg表时的操作还有些类似String tableLoc = IcebergCatalogOpExecutor.createTable(catalog,IcebergUtil.getIcebergTableIdentifier(newTable), location, columns,partitionSpec, newTable.getOwner(), tableProperties).location();newTable.getSd().setLocation(tableLoc);catalogTimeline.markEvent(CREATED_ICEBERG_TABLE + catalog.name());} else {// 如果不是在创建同步表,那我们期望Iceberg Catalog中已经存在我们需要的Iceberg表了// 此时Impala创建Iceberg表的行为更类似于加载现有的Iceberg表并将其注册到HMS中// 首先同样是先需要得到目标表的Catalog类型TIcebergCatalog underlyingCatalog = IcebergUtil.getUnderlyingCatalog(newTable);String locationToLoadFrom;// 然后根据Catalog类型确定我们从何处加载Iceberg表if (underlyingCatalog == TIcebergCatalog.HADOOP_TABLES) {// 对于Hadoop Tables,直接从建表SQL指定的locatin加载表if (location == null) {addSummary(response,"Location is necessary for external iceberg table.");return false;}locationToLoadFrom = location;} else {// 对于Hadoop Catalog,依然从表属性iceberg.catalog_location获取Hadoop Catalog的位置locationToLoadFrom = IcebergUtil.getIcebergCatalogLocation(newTable);}// 然后通过上文介绍过的IcebergUtil.loadTable()将Iceberg表加载起来TableIdentifier identifier = IcebergUtil.getIcebergTableIdentifier(newTable);org.apache.iceberg.Table iceTable = IcebergUtil.loadTable(catalog, identifier, locationToLoadFrom, newTable.getParameters());... // 省略部分代码
}
可以发现Iceberg表的创建过程和加载过程还是有些类似的,主要都是根据Catalog类型来调用对应的Iceberg Catalog API来实现Iceberg表本身的元数据操作,然后Impala自身负责完成Schema转换、分区转换和配置填充等工作。
总结
这篇文章主要是从Iceberg表的相关接口和类以及表的加载和创建两个方面分析了Iceberg表元数据在Impala中是如何管理的,总的来说为了在Impala中方便且高效地实现Iceberg表的各种功能,代码中定义了许多相关的类,虽然看起来比较复杂,但是每个类的功能用途都很明确。而在表的加载和创建方面,Impala也支持了多种Iceberg Catalog,并能和现有的基于HMS的元数据缓存框架结合起来,这使得用户不用操心诸如元数据同步等问题,使用起来还是比较丝滑的。限于文章篇幅,实际上代码中还有许多内容无法详细展开分析,而且Impala社区目前也在重点开发Iceberg相关的特性,代码变化也比较快,有兴趣的同学也可以直接关注Impala的Github仓库和Jira关注社区最新进展。
相关文章:
Impala4.x源码阅读笔记(三)——Impala如何管理Iceberg表元数据
前言 本文为笔者个人阅读Apache Impala源码时的笔记,仅代表我个人对代码的理解,个人水平有限,文章可能存在理解错误、遗漏或者过时之处。如果有任何错误或者有更好的见解,欢迎指正。 上一篇文章Impala4.x源码阅读笔记࿰…...

Ubuntu2204配置samba
0.前情说明 samba服务器主要是用来局域网共享文件的,如果想公网共享可能行不通,我已经踩坑一天了 所以说如果你想满足公网samba共享你就可以不要看下去了 1.参考连接 Ubuntu 安装 Samba 服务器_ubuntu安装samba服务器-CSDN博客 2.安装samba服务 sud…...

AVL树(超详解)
文章目录 前言AVL树的概念AVL树的实现定义AVL树insert 单旋左单旋右单旋左单旋代码右单旋代码 双旋左右双旋右左双旋 测试AVL树的性能 前言 AVL树是怎么来的呢? 我们知道搜索二叉树会存在退化问题,退化以后就变成单支或者接近单支。 它的效率就变成O(N)…...

禁止浏览器记住密码和自动填充 element-ui+vue
vue 根据element-ui 自定义密码输入框,防止浏览器 记住密码和自动填充 <template><divclass"el-password el-input":class"[size ? el-input-- size : , { is-disabled: disabled }]"><inputclass"el-input__inner"…...
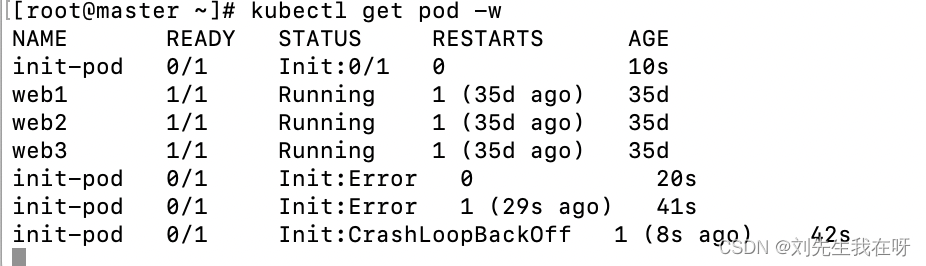
K8s实战-init容器
概念: 初始化容器的概念 比如一个容器A依赖其他容器,可以为A设置多个 依赖容易A1,A2,A3 A1,A2,A3要按照顺序启动,A1没有启动启动起来的 话,A2,A3是不会启动的,直到所有的静态容器全 部启动完毕…...

Vue3.2 自定义指令详解与实战
一、介绍 在Vue3中,自定义指令为开发者提供了一种灵活的方式来扩展Vue的HTML模板语法,使其能够执行特定的DOM操作或组件逻辑。不同于Vue2.x中的全局和局部指令注册方式,Vue3引入了Composition API,这使得自定义指令的编写和使用更…...

XV-3510CB振动陀螺仪传感器
XV-3510CB传感器是一款振动陀螺仪传感器,具有卓越的稳定性和可靠性,超小的封装尺寸SMD53.21.3mm,密封提供了良好的可持续环保能力,采用振动晶体,该传感器具有稳定的性能和超长的寿命。振动晶体的振动能够提供更为精确的…...

设计模式Java向
设计原则: 开闭原则: 用例对象和提供抽象功能进行分割,用例不变,抽象功能被实现,用于不断的扩展,于是源代码不需要进行修改,只在原有基础上进行抽象功能的实现从而进行代码扩展。不变源于代码…...
图片素材管理软件Eagle for mac提高素材整理维度
Eagle for mac是一款图片素材管理软件,支持藏网页图片,网页截屏,屏幕截图和标注,自动标签和筛选等功能,让你设计师方便存储需要的素材和查找,提供工作效率。 Eagle mac软件介绍 Eagle mac帮助你成为更好、…...
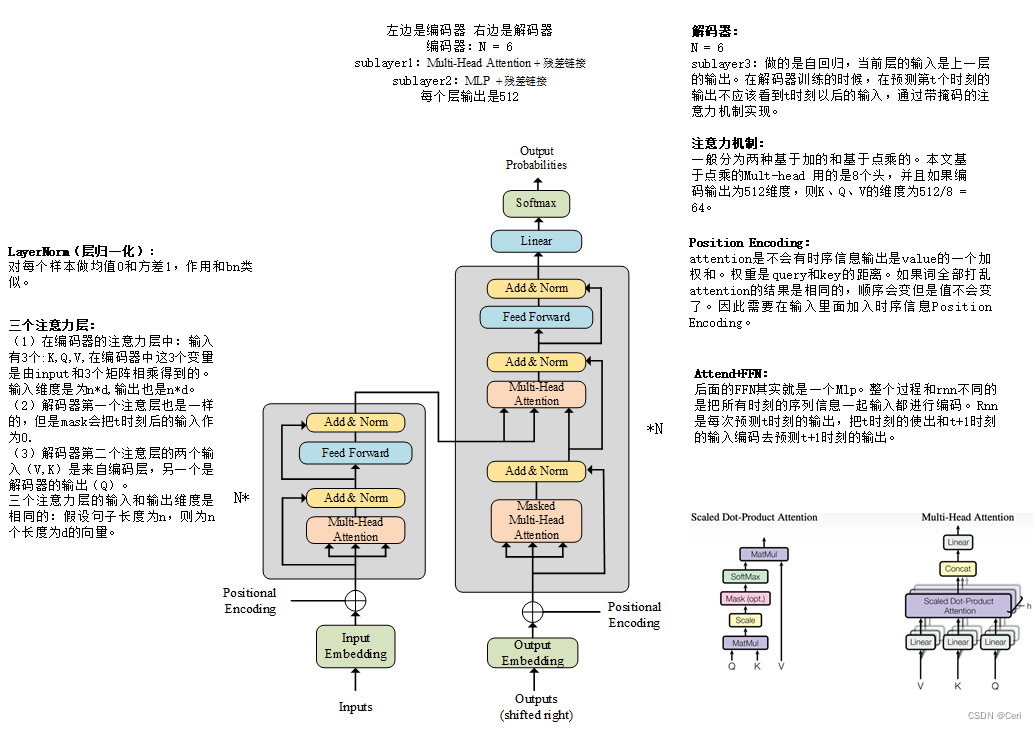
Transformer各模块结构详解(附图)
前言:基于TRANSFORMER的结构在视觉领域是承上启下的作用。刚接触会比较难,上的话需要对RNN,LSTM,ATTENTION先有初步的了解。下的话需要学习VIT,GPT,DETR等结构先了解TRANSFORMER都是必要的。 参考ÿ…...

Python遥感影像深度学习指南(2)-在 PyTorch 中创建自定义数据集和加载器
在上一篇 文章中,我们Fast.ai 在卫星图像中检测云轮廓,检测物体轮廓被称为语义分割。虽然我们用几行代码就能达到 96% 的准确率,但该模型无法考虑数据集中提供的所有输入通道(红、绿、蓝和近红外)。问题在于,深度学习框架(如 Keras、Fast.ai 甚至 PyTorch)中的大多数语…...
客户端渲染管线)
韩版传奇 2 源码分析与 Unity 重制(三)客户端渲染管线
专题介绍 该专题将会分析 LOMCN 基于韩版传奇 2,使用 .NET 重写的传奇源码(服务端 + 客户端),分析数据交互、状态管理和客户端渲染等技术,此外笔者还会分享将客户端部分移植到 Unity 和服务端用现代编程语言重写的全过程。 概览 在这一篇文章中,我们将开始分析传奇客户…...
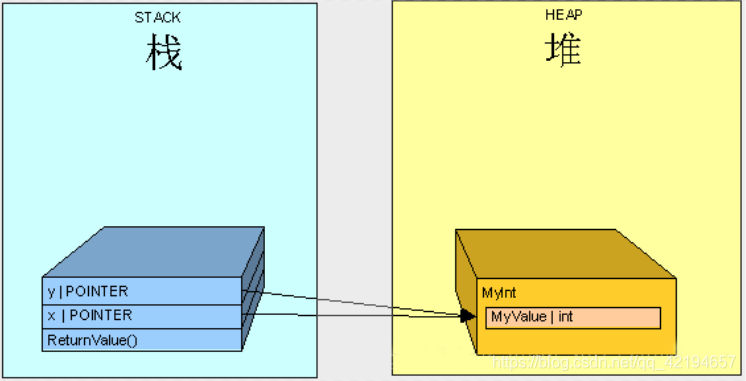
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第三节 栈与堆,值类型与引用类型
深入浅出图解C#堆与栈 C# Heaping VS Stacking 第三节 栈与堆,值类型与引用类型 [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈](https://mp.csdn.net/mdeditor/101021023)[深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工…...

分享好用的chatgpt
1.在vscode中,点击这个: 2.搜索:ChatGPT - 中文版,个人觉得这个更好用: 3.下载完成之后,左侧会多出来这个: 点击这个图标就能进入chatgpt界面了 4.如果想使用tizi访问国外的chatgpt…...

【小白专用】C# 压缩文件 ICSharpCode.SharpZipLib.dll效果:
插件描述: ICSharpCode.SharpZipLib.dll 是一个完全由c#编写的Zip, GZip、Tar 、 BZip2 类库,可以方便地支持这几种格式的压缩解压缩, SharpZipLib 的许可是经过修改的GPL,底线是允许用在不开源商业软件中,意思就是免费使用。具体可访问ICSha…...

Protobuf 编码规则及c++使用详解
Protobuf 编码规则及c使用详解 Protobuf 介绍 Protocol Buffers (a.k.a., protobuf) are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data Protocol Buffers(简称为protobuf)是谷歌的语言无关、…...

Kafka优异的性能是如何实现的?
Apache Kafka是一个分布式流处理平台,设计用来处理高吞吐量的数据。它被广泛用于构建实时数据管道和流式应用程序。Kafka之所以能够提供优秀的性能和高吞吐量,主要得益于以下几个方面的设计和实现: 1. 分布式系统设计 Kafka是一个分布式系统…...
MaterializedMySQL具体实施步骤举例)
(二)MaterializedMySQL具体实施步骤举例
要将 MySQL 中的 test 数据库实时同步到位于同一台服务器(IP 地址为 192.168.197.128)上的 ClickHouse,您可以使用 MaterializedMySQL 引擎。以下是详细的步骤: 1. 准备工作 确保您的 MySQL 和 ClickHouse 服务都在运行…...
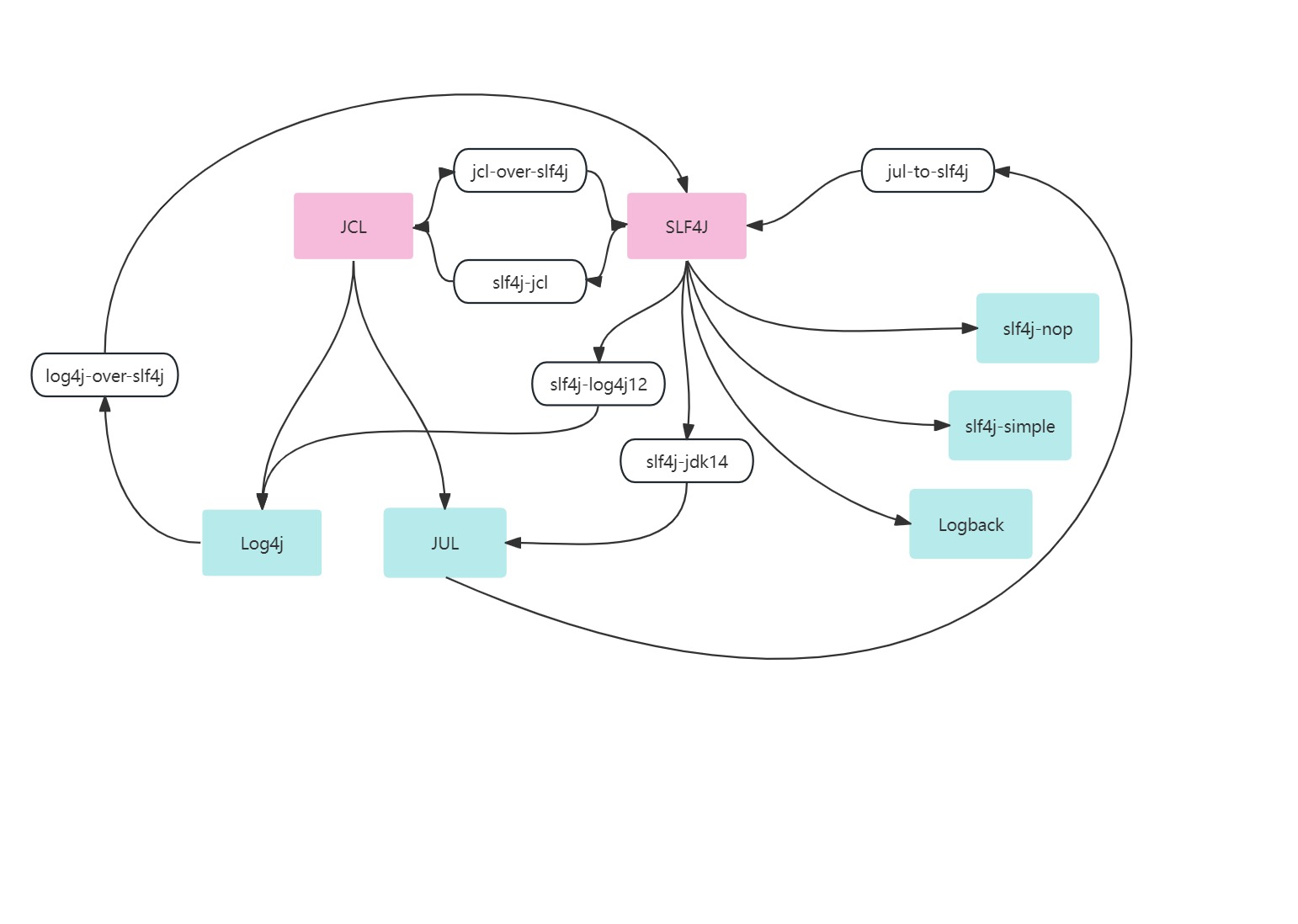
日志框架简介-Slf4j+Logback入门实践 | 京东云技术团队
前言 随着互联网和大数据的迅猛发展,分布式日志系统和日志分析系统已广泛应用,几乎所有应用程序都使用各种日志框架记录程序运行信息。因此,作为工程师,了解主流的日志记录框架非常重要。虽然应用程序的运行结果不受日志的有无影…...

c 语言, 随机数,一个不像随机数的随机数
c 语言, 随机数,一个不像随机数的随机数 使用两种方式获取随机数,总感觉使用比例的那个不太像随机数。 方法一: rand() 获取一个随机数,计算这个随机数跟最大可能值 RAND_MAX(定义在 stdlib.h 中…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...