Go语言学习第二天
-
Go语言数组详解
-
var 数组变量名 [元素数量]Type
-
数组变量名:数组声明及使用时的变量名。
-
元素数量:数组的元素数量,可以是一个表达式,但最终通过编译期计算的结果必须是整型数值,元素数量不能含有到运行时才能确认大小的数值。
-
Type:可以是任意基本类型,包括数组本身,类型为数组本身时,可以实现多维数组。
-
-
var a [3]int // 定义三个整数的数组 fmt.Println(a[0]) // 打印第一个元素 fmt.Println(a[len(a)-1]) // 打印最后一个元素 // 打印索引和元素 for i, v := range a {fmt.Printf("%d %d\n", i, v) } // 仅打印元素 for _, v := range a {fmt.Printf("%d\n", v) } -
默认情况下,数组的每个元素都会被初始化为元素类型对应的零值,对于数字类型来说就是 0,同时也可以使用数组字面值语法,用一组值来初始化数组:
-
var q [3]int = [3]int{1, 2, 3} var r [3]int = [3]int{1, 2} fmt.Println(r[2]) // "0"
-
-
在数组的定义中,如果在数组长度的位置出现“...”省略号,则表示数组的长度是根据初始化值的个数来计算,因此,上面数组 q 的定义可以简化为:
-
q := [3]int{1, 2, 3} q = [4]int{1, 2, 3, 4} // 编译错误:无法将 [4]int 赋给 [3]int
如果两个数组类型相同(包括数组的长度,数组中元素的类型)的情况下,我们可以直接通过较运算符(
==和!=)来判断两个数组是否相等,只有当两个数组的所有元素都是相等的时候数组才是相等的,不能比较两个类型不同的数组,否则程序将无法完成编译-
a := [2]int{1, 2} b := [...]int{1, 2} c := [2]int{1, 3} fmt.Println(a == b, a == c, b == c) // "true false false" d := [3]int{1, 2} fmt.Println(a == d) // 编译错误:无法比较 [2]int == [3]int -
var team [3]string team[0] = "hammer" team[1] = "soldier" team[2] = "mum" for k, v := range team {fmt.Println(k, v) }
-
-
-
Go语言的多维数组
-
var array_name size1...[sizen] array_type
-
array_name 为数组的名字,array_type 为数组的类型,size1、size2 等等为数组每一维度的长度。
-
// 声明一个二维整型数组,两个维度的长度分别是 4 和 2 var array [4][2]int // 使用数组字面量来声明并初始化一个二维整型数组 array = [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}} // 声明并初始化数组中索引为 1 和 3 的元素 array = [4][2]int{1: {20, 21}, 3: {40, 41}} // 声明并初始化数组中指定的元素 array = [4][2]int{1: {0: 20}, 3: {1: 41}} -
只要类型一致,就可以将多维数组互相赋值,如下所示,多维数组的类型包括每一维度的长度以及存储在元素中数据的类型
-
// 声明两个二维整型数组 var array1 [2][2]int var array2 [2][2]int // 为array2的每个元素赋值 array2[0][0] = 10 array2[0][1] = 20 array2[1][0] = 30 array2[1][1] = 40 // 将 array2 的值复制给 array1 array1 = array2
-
因为数组中每个元素都是一个值,所以可以独立复制某个维度,如下所示。
-
// 将 array1 的索引为 1 的维度复制到一个同类型的新数组里 var array3 [2]int = array1[1] // 将数组中指定的整型值复制到新的整型变量里 var value int = array1[1][0]
-
-
Go语言切片
-
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
-
var identifier []type
-
-
切片不需要说明长度。或使用 make() 函数来创建切片:
-
var slice1 []type = make([]type, len)
也可以简写为
slice1 := make([]type, len)
-
-
也可以指定容量,其中 capacity 为可选参数。
-
make([]T, length, capacity)
-
这里 len 是数组的长度并且也是切片的初始长度。
-
-
切片初始化
-
s :=[] int {1,2,3 } -
直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3。
-
s := arr[:]
-
初始化切片 s,是数组 arr 的引用。
-
s := arr[startIndex:endIndex]
-
将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
-
s := arr[startIndex:]
-
默认 endIndex 时将表示一直到arr的最后一个元素。
-
s := arr[:endIndex]
-
默认 startIndex 时将表示从 arr 的第一个元素开始。
-
s1 := s[startIndex:endIndex]
-
通过切片 s 初始化切片 s1。
-
s :=make([]int,len,cap)
-
通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片。
-
-
len() 和 cap() 函数
-
切片是可索引的,并且可以由 len() 方法获取长度。
-
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
-
package main import "fmt" func main() {var numbers = make([]int,3,5) printSlice(numbers) } func printSlice(x []int){fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x) }
-
-
空(nil)切片
-
一个切片在未初始化之前默认为 nil,长度为 0,实例如下:
-
package main import "fmt" func main() {var numbers []int printSlice(numbers) if(numbers == nil){fmt.Printf("切片是空的")} } func printSlice(x []int){fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x) }
-
-
切片截取
-
可以通过设置下限及上限来设置截取切片 [lower-bound:upper-bound],实例如下:
-
package main import "fmt" func main() {/* 创建切片 */numbers := []int{0,1,2,3,4,5,6,7,8} printSlice(numbers) /* 打印原始切片 */fmt.Println("numbers ==", numbers) /* 打印子切片从索引1(包含) 到索引4(不包含)*/fmt.Println("numbers[1:4] ==", numbers[1:4]) /* 默认下限为 0*/fmt.Println("numbers[:3] ==", numbers[:3]) /* 默认上限为 len(s)*/fmt.Println("numbers[4:] ==", numbers[4:]) numbers1 := make([]int,0,5)printSlice(numbers1) /* 打印子切片从索引 0(包含) 到索引 2(不包含) */number2 := numbers[:2]printSlice(number2) /* 打印子切片从索引 2(包含) 到索引 5(不包含) */number3 := numbers[2:5]printSlice(number3) } func printSlice(x []int){fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x) }
-
-
-
append() 和 copy() 函数
-
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。
-
在使用 append() 函数为切片动态添加元素时,如果空间不足以容纳足够多的元素,切片就会进行“扩容”,此时新切片的长度会发生改变。
-
切片在扩容时,容量的扩展规律是按容量的 2 倍数进行扩充,例如 1、2、4、8、16……,
-
-
package main import "fmt" func main() {var numbers []intprintSlice(numbers) /* 允许追加空切片 */numbers = append(numbers, 0)printSlice(numbers) /* 向切片添加一个元素 */numbers = append(numbers, 1)printSlice(numbers) /* 同时添加多个元素 */numbers = append(numbers, 2,3,4)printSlice(numbers) /* 创建切片 numbers1 是之前切片的两倍容量*/numbers1 := make([]int, len(numbers), (cap(numbers))*2) /* 拷贝 numbers 的内容到 numbers1 */copy(numbers1,numbers)printSlice(numbers1) } func printSlice(x []int){fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x) } -
除了在切片的尾部追加,我们还可以在切片的开头添加元素:
-
var a = []int{1,2,3} a = append([]int{0}, a...) // 在开头添加1个元素 a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片 -
在切片开头添加元素一般都会导致内存的重新分配,而且会导致已有元素全部被复制 1 次,因此,从切片的开头添加元素的性能要比从尾部追加元素的性能差很多。
-
因为 append 函数返回新切片的特性,所以切片也支持链式操作,我们可以将多个 append 操作组合起来,实现在切片中间插入元素:
-
var a []int a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片 -
每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 中。
-
Go语言copy():切片复制(切片拷贝)
-
copy( destSlice, srcSlice []T) int
-
其中 srcSlice 为数据来源切片,destSlice 为复制的目标(也就是将 srcSlice 复制到 destSlice),目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致,copy() 函数的返回值表示实际发生复制的元素个数。
-
slice1 := []int{1, 2, 3, 4, 5} slice2 := []int{5, 4, 3} copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中 copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置 -
然通过循环复制切片元素更直接,不过内置的 copy() 函数使用起来更加方便,copy() 函数的第一个参数是要复制的目标 slice,第二个参数是源 slice,两个 slice 可以共享同一个底层数组,甚至有重叠也没有问题。
-
Go语言从切片中删除元素
-
从开头位置删除
-
a = []int{1, 2, 3} a = a[1:] // 删除开头1个元素 a = a[N:] // 删除开头N个元素 -
也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化)
-
a = []int{1, 2, 3} a = append(a[:0], a[1:]...) // 删除开头1个元素 a = append(a[:0], a[N:]...) // 删除开头N个元素 -
还可以用 copy() 函数来删除开头的元素:
-
a = []int{1, 2, 3} a = a[:copy(a, a[1:])] // 删除开头1个元素 a = a[:copy(a, a[N:])] // 删除开头N个元素
-
-
从中间位置删除
-
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用 append 或 copy 原地完成:
-
a = []int{1, 2, 3, ...} a = append(a[:i], a[i+1:]...) // 删除中间1个元素 a = append(a[:i], a[i+N:]...) // 删除中间N个元素 a = a[:i+copy(a[i:], a[i+1:])] // 删除中间1个元素 a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素
-
-
从尾部删除
-
a = []int{1, 2, 3} a = a[:len(a)-1] // 删除尾部1个元素 a = a[:len(a)-N] // 删除尾部N个元素 -
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况
-
-
Go语言range关键字:循环迭代切片
-
// 创建一个整型切片,并赋值 slice := []int{10, 20, 30, 40} // 迭代每一个元素,并显示其值 for index, value := range slice {fmt.Printf("Index: %d Value: %d\n", index, value) } -
需要强调的是,range 返回的是每个元素的副本,而不是直接返回对该元素的引用
-
// 创建一个整型切片,并赋值 slice := []int{10, 20, 30, 40} // 迭代每个元素,并显示值和地址 for index, value := range slice {fmt.Printf("Value: %d Value-Addr: %X ElemAddr: %X\n", value, &value, &slice[index]) } Value: 10 Value-Addr: 10500168 ElemAddr: 1052E100 Value: 20 Value-Addr: 10500168 ElemAddr: 1052E104 Value: 30 Value-Addr: 10500168 ElemAddr: 1052E108 Value: 40 Value-Addr: 10500168 ElemAddr: 1052E10C -
因为迭代返回的变量是一个在迭代过程中根据切片依次赋值的新变量,所以 value 的地址总是相同的,要想获取每个元素的地址,需要使用切片变量和索引值
-
如果不需要索引值,也可以使用下划线
_来忽略这个值 -
// 创建一个整型切片,并赋值 slice := []int{10, 20, 30, 40} // 迭代每个元素,并显示其值 for _, value := range slice {fmt.Printf("Value: %d\n", value) }
-
Go语言多维切片简述
-
var sliceName ...[]sliceType
-
其中,sliceName 为切片的名字,sliceType为切片的类型,每个
[ ]代表着一个维度,切片有几个维度就需要几个[ ] -
//声明一个二维切片 var slice [][]int //为二维切片赋值 slice = [][]int{{10}, {100, 200}} -
// 声明一个二维整型切片并赋值 slice := [][]int{{10}, {100, 200}}
-
-
Go语言map(Go语言映射)
-
Go语言中 map 是一种特殊的数据结构,一种元素对(pair)的无序集合,pair 对应一个 key(索引)和一个 value(值),所以这个结构也称为关联数组或字典,这是一种能够快速寻找值的理想结构,给定 key,就可以迅速找到对应的 value。
-
map 是引用类型,可以使用如下方式声明:
-
var mapname map[keytype]valuetype
-
mapname 为 map 的变量名。
-
keytype 为键类型。
-
valuetype 是键对应的值类型。
-
-
在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 pair 的数目。
-
package main import "fmt" func main() {var mapLit map[string]int//var mapCreated map[string]float32var mapAssigned map[string]intmapLit = map[string]int{"one": 1, "two": 2}mapCreated := make(map[string]float32)mapAssigned = mapLitmapCreated["key1"] = 4.5mapCreated["key2"] = 3.14159mapAssigned["two"] = 3fmt.Printf("Map literal at \"one\" is: %d\n", mapLit["one"])fmt.Printf("Map created at \"key2\" is: %f\n", mapCreated["key2"])fmt.Printf("Map assigned at \"two\" is: %d\n", mapLit["two"])fmt.Printf("Map literal at \"ten\" is: %d\n", mapLit["ten"]) } -
mapCreated 的创建方式
mapCreated := make(map[string]float)等价于mapCreated := map[string]float{}。 -
注意:可以使用 make(),但不能使用 new() 来构造 map,如果错误的使用 new() 分配了一个引用对象,会获得一个空引用的指针,相当于声明了一个未初始化的变量并且取了它的地址:
-
mapCreated := new(map[string]float)
-
接下来当我们调用
mapCreated["key1"] = 4.5的时候,编译器会报错: -
invalid operation: mapCreated["key1"] (index of type *map[string]float).
-
-
map容量
-
和数组不同,map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity,
-
make(map[keytype]valuetype, cap)
-
当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
-
noteFrequency := map[string]float32 { "C0": 16.35, "D0": 18.35, "E0": 20.60, "F0": 21.83, "G0": 24.50, "A0": 27.50, "B0": 30.87, "A4": 440}
-
-
-
用切片作为 map 的值
-
既然一个 key 只能对应一个 value,而 value 又是一个原始类型,那么如果一个 key 要对应多个值怎么办?例如,当我们要处理 unix 机器上的所有进程,以父进程(pid 为整形)作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅的解决这个问题,示例代码如下所示:
-
mp1 := make(map[int][]int) mp2 := make(map[int]*[]int)
-
-
-
Go语言遍历map(访问map中的每一个键值对)
-
map 的遍历过程使用 for range 循环完成,代码如下:
-
scene := make(map[string]int) scene["route"] = 66 scene["brazil"] = 4 scene["china"] = 960 for k, v := range scene {fmt.Println(k, v) } -
如只遍历值,可以使用下面的形式:
-
将不需要的键使用
_改为匿名变量形式 -
for _, v := range scene { -
只遍历键时,使用下面的形式:
-
for k := range scene { -
遍历输出元素的顺序与填充顺序无关,不能期望 map 在遍历时返回某种期望顺序的结果,如果需要特定顺序的遍历结果,正确的做法是先排序,代码如下:
-
scene := make(map[string]int) // 准备map数据 scene["route"] = 66 scene["brazil"] = 4 scene["china"] = 960 // 声明一个切片保存map数据 var sceneList []string // 将map数据遍历复制到切片中 for k := range scene {sceneList = append(sceneList, k) } // 对切片进行排序 sort.Strings(sceneList) // 输出 fmt.Println(sceneList) -
输出结果:[brazil china route]
-
-
-
Go语言map元素的删除和清空
-
使用 delete() 函数从 map 中删除键值对
-
使用 delete() 内建函数从 map 中删除一组键值对,delete() 函数的格式如下:
-
delete(map, 键) -
其中 map 为要删除的 map 实例,键为要删除的 map 中键值对的键。
-
scene := make(map[string]int) // 准备map数据 scene["route"] = 66 scene["brazil"] = 4 scene["china"] = 960 delete(scene, "brazil") for k, v := range scene {fmt.Println(k, v) } //输出结果 route 66 china 960
-
-
清空 map 中的所有元素
-
Go语言中并没有为 map 提供任何清空所有元素的函数、方法,清空 map 的唯一办法就是重新 make 一个新的 map,不用担心垃圾回收的效率,Go语言中的并行垃圾回收效率比写一个清空函数要高效的多。
-
-
-
Go语言map的多键索引——多个数值条件可以同时查询
-
Go语言sync.Map(在并发环境中使用的map)
-
Go语言中的 map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。
-
下面来看下并发情况下读写 map 时会出现的问题,代码如下:
-
// 创建一个int到int的映射 m := make(map[int]int) // 开启一段并发代码 go func() { // 不停地对map进行写入for {m[1] = 1} }() // 开启一段并发代码 go func() { // 不停地对map进行读取for {_ = m[1]} }() // 无限循环, 让并发程序在后台执行 for { } //运行代码会报错,输出如下: //fatal error: concurrent map read and map write -
错误信息显示,并发的 map 读和 map 写,也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题,map 内部会对这种并发操作进行检查并提前发现。
-
需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。特性如下:
-
无须初始化,直接声明即可。
-
sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
-
使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
-
package main import ("fmt""sync" ) func main() { var scene sync.Map // 将键值对保存到sync.Mapscene.Store("greece", 97)scene.Store("london", 100)scene.Store("egypt", 200) // 从sync.Map中根据键取值fmt.Println(scene.Load("london")) // 根据键删除对应的键值对scene.Delete("london") // 遍历所有sync.Map中的键值对scene.Range(func(k, v interface{}) bool { fmt.Println("iterate:", k, v)return true}) } //代码输出如下 100 true iterate: egypt 200 iterate: greece 97 -
sync.Map 没有提供获取 map 数量的方法,替代方法是在获取 sync.Map 时遍历自行计算数量,sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
-
-
-
-
Go语言list(列表)
-
列表是一种非连续的存储容器,由多个节点组成,节点通过一些变量记录彼此之间的关系,列表有多种实现方法,如单链表、双链表等。
-
列表的原理可以这样理解:假设 A、B、C 三个人都有电话号码,如果 A 把号码告诉给 B,B 把号码告诉给 C,这个过程就建立了一个单链表结构,如下图所示。
-

-
如果在这个基础上,再从 C 开始将自己的号码告诉给自己所知道号码的主人,这样就形成了双链表结构,如下图所示。
-

-
如果 B 换号码了,他需要通知 A 和 C,将自己的号码移除,这个过程就是列表元素的删除操作,如下图所示。
-

-
在Go语言中,列表使用 container/list 包来实现,内部的实现原理是双链表,列表能够高效地进行任意位置的元素插入和删除操作。
-
-
初始化列表
-
list 的初始化有两种方法:分别是使用 New() 函数和 var 关键字声明,两种方法的初始化效果都是一致的。
-
通过 container/list 包的 New() 函数初始化 list
-
变量名 := list.New()
-
通过 var 关键字声明初始化 list
-
var 变量名 list.List
-
列表与切片和 map 不同的是,列表并没有具体元素类型的限制,因此,列表的元素可以是任意类型,这既带来了便利,也引来一些问题,例如给列表中放入了一个 interface{} 类型的值,取出值后,如果要将 interface{} 转换为其他类型将会发生宕机。
-
-
在列表中插入元素
-
双链表支持从队列前方或后方插入元素,分别对应的方法是 PushFront 和 PushBack。
-
这两个方法都会返回一个 *list.Element 结构,如果在以后的使用中需要删除插入的元素,则只能通过 *list.Element 配合 Remove() 方法进行删除,这种方法可以让删除更加效率化,同时也是双链表特性之一。
-
l := list.New() l.PushBack("fist") l.PushFront(67) -
第 1 行,创建一个列表实例。
-
第 3 行,将 fist 字符串插入到列表的尾部,此时列表是空的,插入后只有一个元素。
-
第 4 行,将数值 67 放入列表,此时,列表中已经存在 fist 元素,67 这个元素将被放在 fist 的前面。
-
-
列表插入元素的方法如下表所示。
-
方 法 功 能 InsertAfter(v interface {}, mark * Element) * Element 在 mark 点之后插入元素,mark 点由其他插入函数提供 InsertBefore(v interface {}, mark * Element) *Element 在 mark 点之前插入元素,mark 点由其他插入函数提供 PushBackList(other *List) 添加 other 列表元素到尾部 PushFrontList(other *List) 添加 other 列表元素到头部
-
-
从列表中删除元素
-
列表插入函数的返回值会提供一个 *list.Element 结构,这个结构记录着列表元素的值以及与其他节点之间的关系等信息,从列表中删除元素时,需要用到这个结构进行快速删除。
-
package main import "container/list" func main() {l := list.New() // 尾部添加l.PushBack("canon") // 头部添加l.PushFront(67) // 尾部添加后保存元素句柄element := l.PushBack("fist") // 在fist之后添加highl.InsertAfter("high", element) // 在fist之前添加noonl.InsertBefore("noon", element) // 使用l.Remove(element) } -
第 6 行,创建列表实例。 第 9 行,将字符串 canon 插入到列表的尾部。 第 12 行,将数值 67 添加到列表的头部。 第 15 行,将字符串 fist 插入到列表的尾部,并将这个元素的内部结构保存到 element 变量中。 第 18 行,使用 element 变量,在 element 的位置后面插入 high 字符串。 第 21 行,使用 element 变量,在 element 的位置前面插入 noon 字符串。 第 24 行,移除 element 变量对应的元素。
-
操作内容 列表元素 l.PushBack("canon") canon l.PushFront(67) 67, canon element := l.PushBack("fist") 67, canon, fist l.InsertAfter("high", element) 67, canon, fist, high l.InsertBefore("noon", element) 67, canon, noon, fist, high l.Remove(element) 67, canon, noon, high
-
-
遍历列表——访问列表的每一个元素
-
遍历双链表需要配合 Front() 函数获取头元素,遍历时只要元素不为空就可以继续进行,每一次遍历都会调用元素的 Next() 函数,代码如下所示。
-
l := list.New() // 尾部添加 l.PushBack("canon") // 头部添加 l.PushFront(67) for i := l.Front(); i != nil; i = i.Next() {fmt.Println(i.Value) } //代码输出如下: 67 canon -
第 1 行,创建一个列表实例。
-
第 4 行,将 canon 放入列表尾部。
-
第 7 行,在队列头部放入 67。
-
第 9 行,使用 for 语句进行遍历,其中 i:=l.Front() 表示初始赋值,只会在一开始执行一次,每次循环会进行一次 i != nil 语句判断,如果返回 false,表示退出循环,反之则会执行 i = i.Next()。
-
第 10 行,使用遍历返回的 *list.Element 的 Value 成员取得放入列表时的原值。
-
-
-
Go语言nil:空值/零值
-
在Go语言中,布尔类型的零值(初始值)为 false,数值类型的零值为 0,字符串类型的零值为空字符串
"",而指针、切片、映射、通道、函数和接口的零值则是 nil。 -
nil 是Go语言中一个预定义好的标识符,有过其他编程语言开发经验的开发者也许会把 nil 看作其他语言中的 null(NULL),其实这并不是完全正确的,因为Go语言中的 nil 和其他语言中的 null 有很多不同点。
-
nil 标识符是不能比较的
-
package main import ("fmt" ) func main() {fmt.Println(nil==nil) } -
==对于 nil 来说是一种未定义的操作
-
-
nil 不是关键字或保留字
-
nil 并不是Go语言的关键字或者保留字,也就是说我们可以定义一个名称为 nil 的变量,比如下面这样
-
var nil = errors.New("my god"),不建议这样做
-
-
nil 没有默认类型
-
package main import ("fmt" ) func main() {fmt.Printf("%T", nil)print(nil) } -
PS D:\code> go run .\main.go \# command-line-arguments .\main.go:9:10: use of untyped nil```
-
-
不同类型 nil 的指针是一样的
-
package main import ("fmt" ) func main() {var arr []intvar num *intfmt.Printf("%p\n", arr)fmt.Printf("%p", num) } -
PS D:\code> go run .\main.go 0x0 0x0
-
通过运行结果可以看出 arr 和 num 的指针都是 0x0。
-
-
不同类型的 nil 是不能比较的
-
package main import ("fmt" ) func main() {var m map[int]stringvar ptr *intfmt.Printf(m == ptr) } -
PS D:\code> go run .\main.go # command-line-arguments .\main.go:10:20: invalid operation: arr == ptr (mismatched types []int and *int)
-
-
两个相同类型的 nil 值也可能无法比较
-
在Go语言中 map、slice 和 function 类型的 nil 值不能比较,比较两个无法比较类型的值是非法的,下面的语句无法编译。
-
package main import ("fmt" ) func main() {var s1 []intvar s2 []intfmt.Printf(s1 == s2) } -
PS D:\code> go run .\main.go # command-line-arguments .\main.go:10:19: invalid operation: s1 == s2 (slice can only be compared to nil)
-
通过上面的错误提示可以看出,能够将上述不可比较类型的空值直接与 nil 标识符进行比较,如下所示:
-
package main import ("fmt" ) func main() {var s1 []intfmt.Println(s1 == nil) } -
运行结果如下所示:
-
PS D:\code> go run .\main.go true
-
-
nil 是 map、slice、pointer、channel、func、interface 的零值
-
package main import ("fmt" ) func main() {var m map[int]stringvar ptr *intvar c chan intvar sl []intvar f func()var i interface{}fmt.Printf("%#v\n", m)fmt.Printf("%#v\n", ptr)fmt.Printf("%#v\n", c)fmt.Printf("%#v\n", sl)fmt.Printf("%#v\n", f)fmt.Printf("%#v\n", i) } -
运行结果如下所示:
-
PS D:\code> go run .\main.go map[int]string(nil) (*int)(nil) (chan int)(nil) []int(nil) (func())(nil) <nil>
-
零值是Go语言中变量在声明之后但是未初始化被赋予的该类型的一个默认值。
-
-
不同类型的 nil 值占用的内存大小可能是不一样的
-
一个类型的所有的值的内存布局都是一样的,nil 也不例外,nil 的大小与同类型中的非 nil 类型的大小是一样的。但是不同类型的 nil 值的大小可能不同。
-
package main import ("fmt""unsafe" ) func main() {var p *struct{}fmt.Println( unsafe.Sizeof( p ) ) // 8 var s []intfmt.Println( unsafe.Sizeof( s ) ) // 24 var m map[int]boolfmt.Println( unsafe.Sizeof( m ) ) // 8 var c chan stringfmt.Println( unsafe.Sizeof( c ) ) // 8 var f func()fmt.Println( unsafe.Sizeof( f ) ) // 8 var i interface{}fmt.Println( unsafe.Sizeof( i ) ) // 16 } -
运行结果如下所示:
-
PS D:\code> go run .\main.go 8 24 8 8 8 16
-
具体的大小取决于编译器和架构,上面打印的结果是在 64 位架构和标准编译器下完成的,对应 32 位的架构的,打印的大小将减半。
-
-
相关文章:
Go语言学习第二天
Go语言数组详解 var 数组变量名 [元素数量]Type 数组变量名:数组声明及使用时的变量名。 元素数量:数组的元素数量,可以是一个表达式,但最终通过编译期计算的结果必须是整型数值,元素数量不能含有到运行时才能确认大小…...
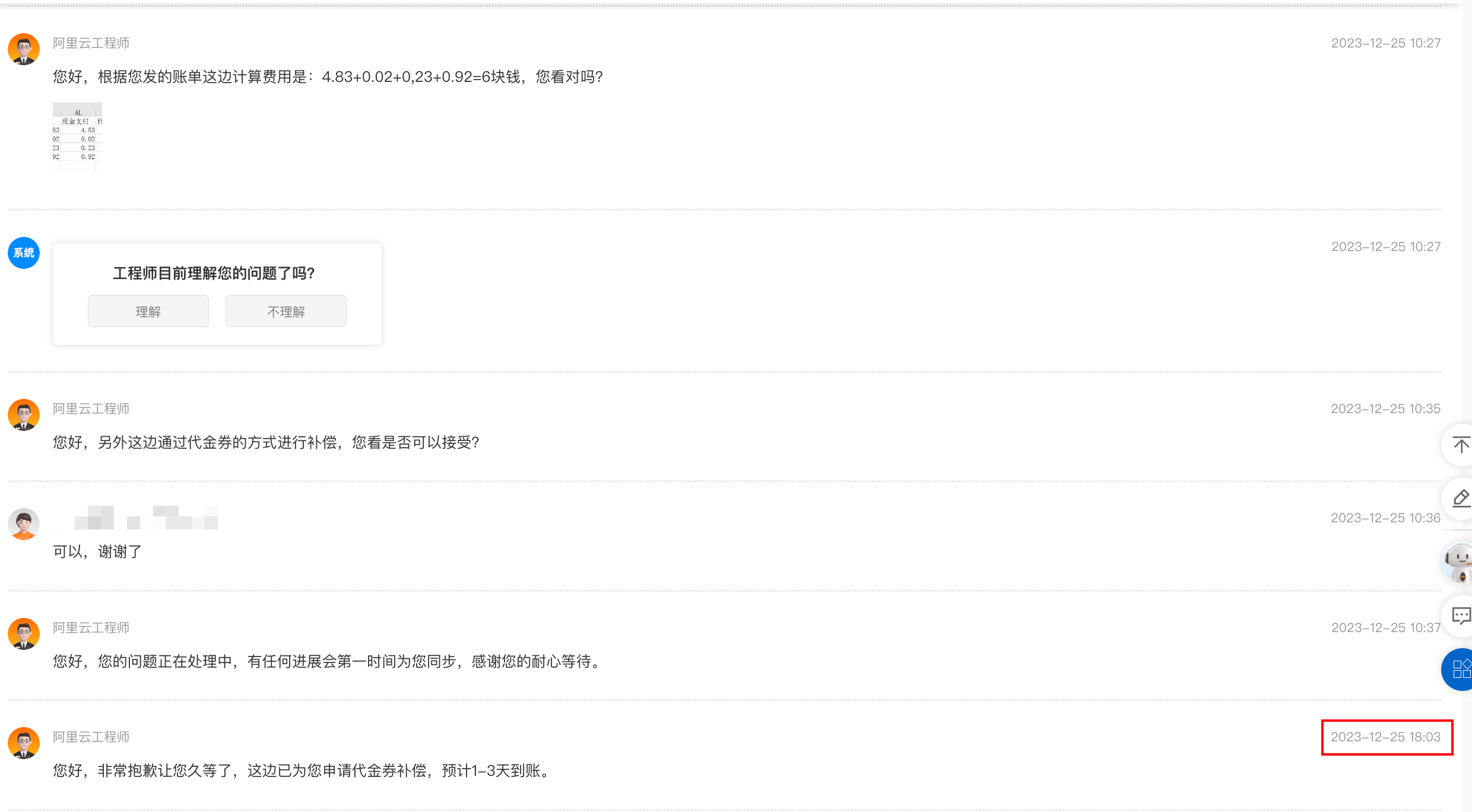
阿里云OpenSearch-LLM智能问答故障的一天
上周五使用阿里云开放搜索问答版时,故障了一整天,可能这个服务使用的人比较少,没有什么消息爆出来,特此记录下这几天的阿里云处理过程,不免让人怀疑阿里云整体都外包出去了,反应迟钝,水平业余&a…...

城市分站优化系统源码:提升百度关键排名 附带完整的搭建教程
城市分站优化已成为企业网络营销的重要手段,今天来给大家分享一款城市分站优化系统源码。 以下是部分代码示例: 系统特色功能一览: 1.多城市分站管理:该系统支持多个城市分站的管理,用户可以根据业务需求,…...

【华为OD题库-107】编码能力提升计划-java
题目 为了提升软件编码能力,小王制定了刷题计划,他选了题库中的n道题,编号从0到n-1,并计划在m天内按照题目编号顺序刷完所有的题目(注意,小王不能用多天完成同一题) 在小王刷题计划中,小王需要用time[i]的时…...

使用pytorch进行图像预处理的常用方法的详细解释
一般来说,我们在使用pytorch进行图像分类任务时都会对训练集数据做必要的格式转换和增广处理,对测试集做格式处理。 以下是常用的数据集处理函数: data_transform { "train": transforms.Compose([transforms.RandomResizedCro…...

天线根据什么进行分类
天线是信息化时代的一个标准,广播信号塔,通信基站塔,卫星天线还有每天都要用到的手机,都是含有天线的,只是各种天线的作用不同,大小不同。今天给大家说一下,天线是如何分类的。 1.按工作性质可…...
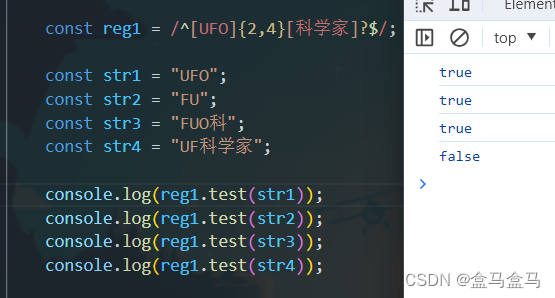
JavaScript:正则表达式
JavaScript:正则表达式 什么是正则表达式正则表达式语法定义正则表达式判断是否有匹配的字符串查找匹配的字符串 正则表达式匹配法则元字符边界符量词字符类 什么是正则表达式 正则表达式用于匹配字符串中字符的组合模式。 正则表达式会依据其自身语法,…...
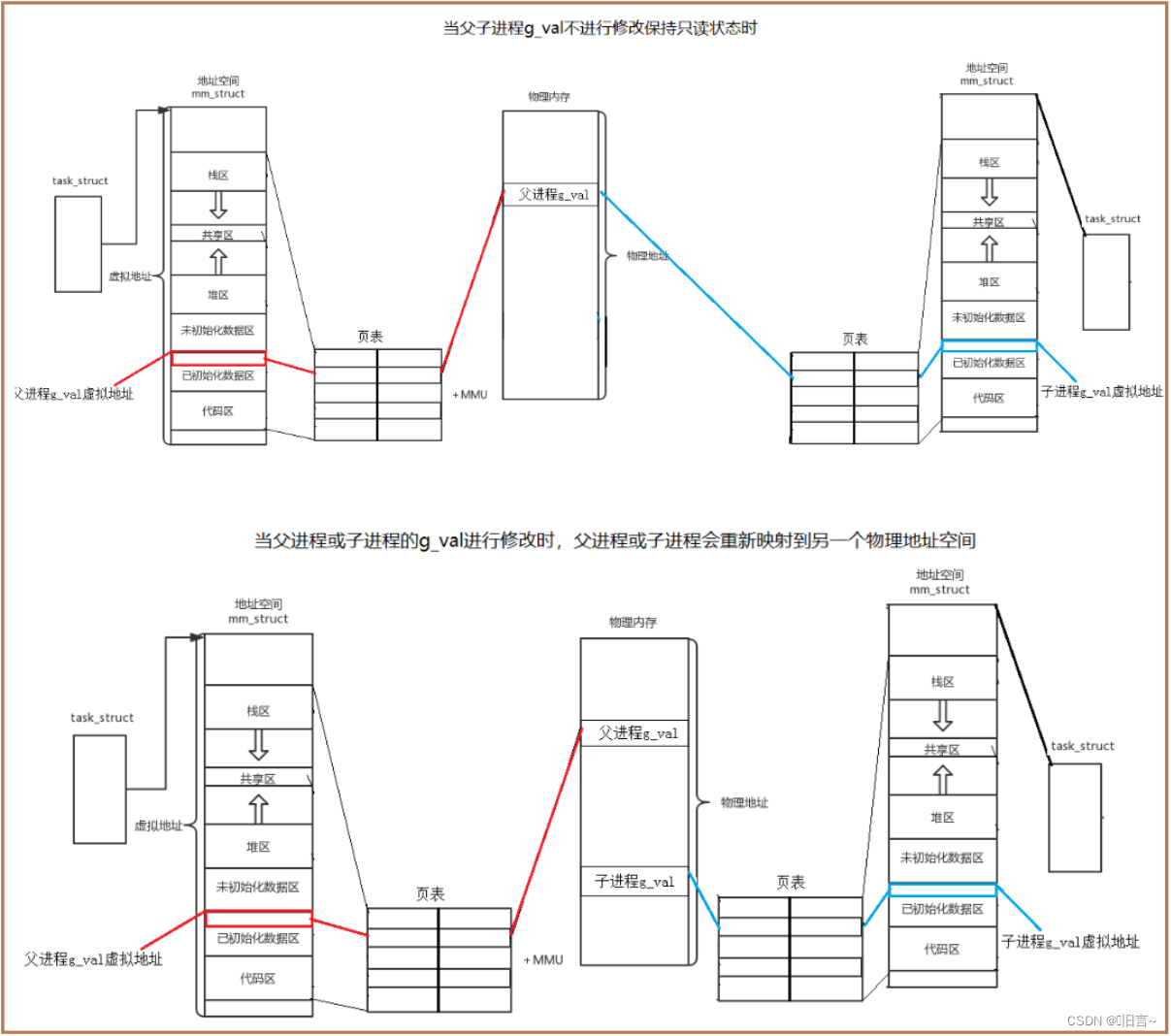
【Linux】深挖进程地址空间
> 作者简介:დ旧言~,目前大二,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:熟悉【Linux】进程地址空间 > 毒鸡汤ÿ…...

SVM(支持向量机)-机器学习
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归分析的监督学习算法。它属于机器学习中的一类强大而灵活的模型,广泛应用于模式识别、图像分类、自然语言处理等领域。 基本原理: SVM的基本原理是通过找到能够有效分…...

解决生成的insert语句内有单引号的情况
背景 因为Mybatis-Plus的saveBatch()方法的批量插入其实也是循环插入,而不是真正的一个SqlSession完成的批插,效率很低。所以我们在写批量插入的时候是自己实现了一个工具类去生成批量插入的sql再去执行,但是会遇到有些文本里有单引号导致插…...

【Linux 程序】1. 程序构建
文章目录 【 1. 配置 】【 2. 编译 】makefile编写的要点makefile中的全局自变量CMake编译依赖的库g编译 【 3. 安装 】 一般源代码提供的程序安装需要通过配置、编译、安装三个步骤; 配置。检查当前环境是否满足要安装软件的依赖关系,以及设置程序安装所…...
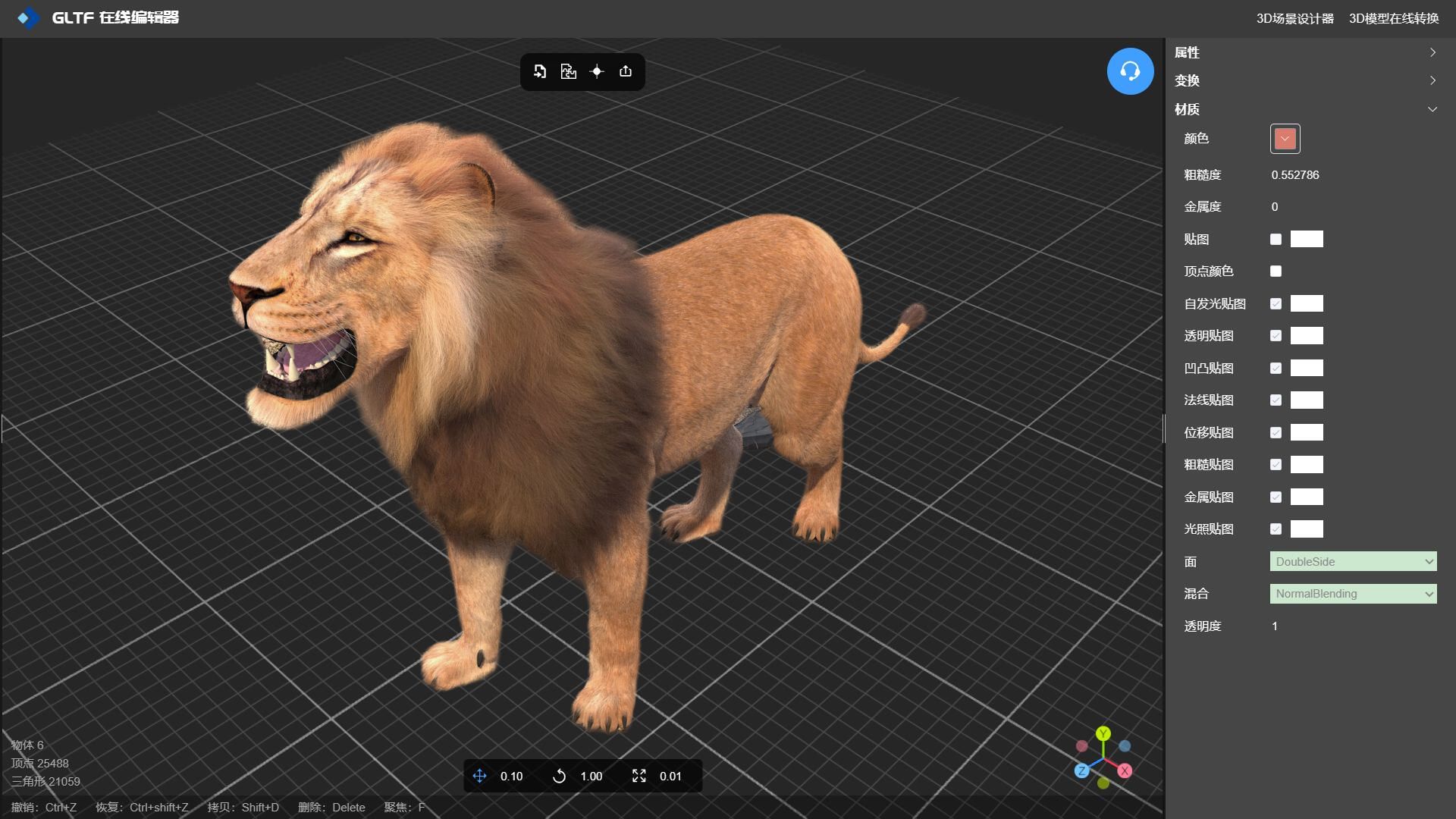
GLTF 编辑器实现逼真3D动物毛发效果
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 要实现逼真的3D动物毛发效果,可以采用以下技术和方法&…...

【Go语言入门:Go语言的方法,函数,接口】
文章目录 4.Go语言的方法,函数,接口4.1. 方法4.1.1. 指针接受者4.1.2. 值接收者和指针接收者有什么区别?4.1.3. 方法 4.2. 接口4.2.1. 接口定义 4.3. 函数4.3.1. 函数介绍 4.Go语言的方法,函数,接口 4.1. 方法 4.1.1…...
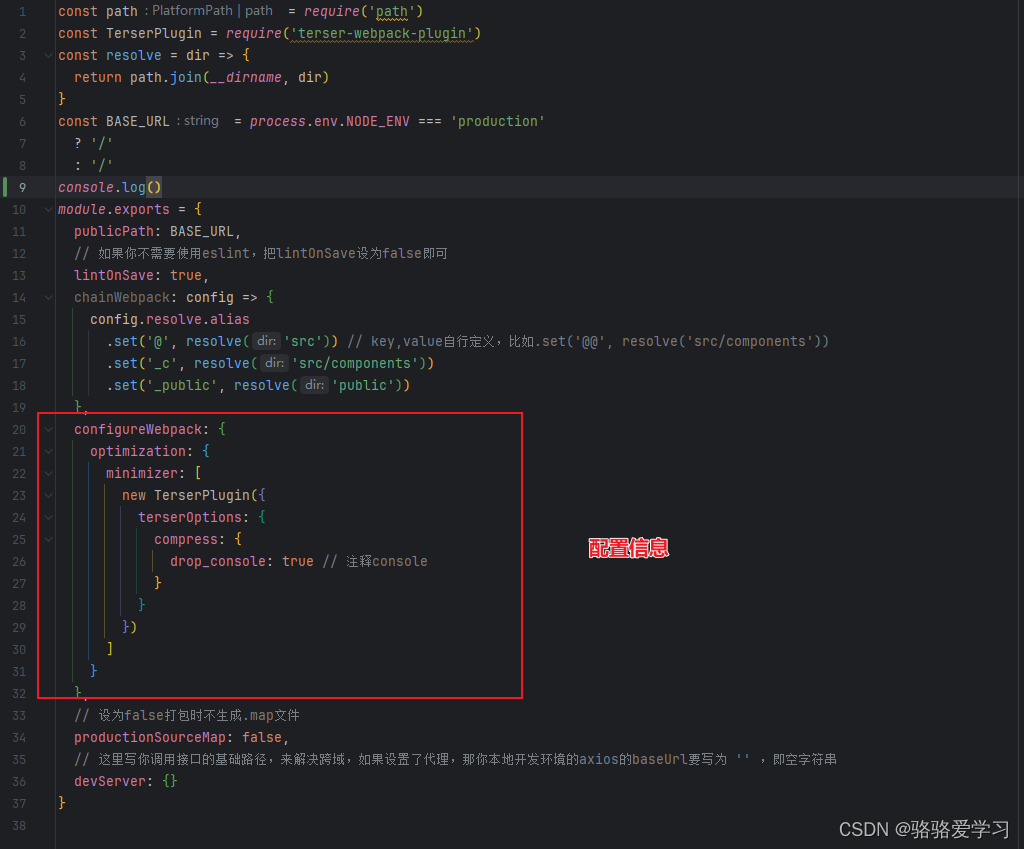
vue-cli3/webpack打包时去掉console.log调试信息
文章目录 前言一、terser-webpack-plugin是什么?二、使用配置vue-cli项目 前言 开发环境下,console.log调试信息,有助于我们找到错误,但在生产环境,不需要console.log打印调试信息,所以打包时需要将consol…...

企业品牌推广在国外媒体投放的意义和作用何在?
海外广告投放是企业在国际市场推广的重要战略,具有多种形式,包括社交媒体广告、短视频广告、电视广告等。这些广告形式在传播信息、推动销售、塑造品牌形象等方面发挥着独特的作用。 其中软文发稿是一种注重叙事和信息传递的广告形式,对于企…...
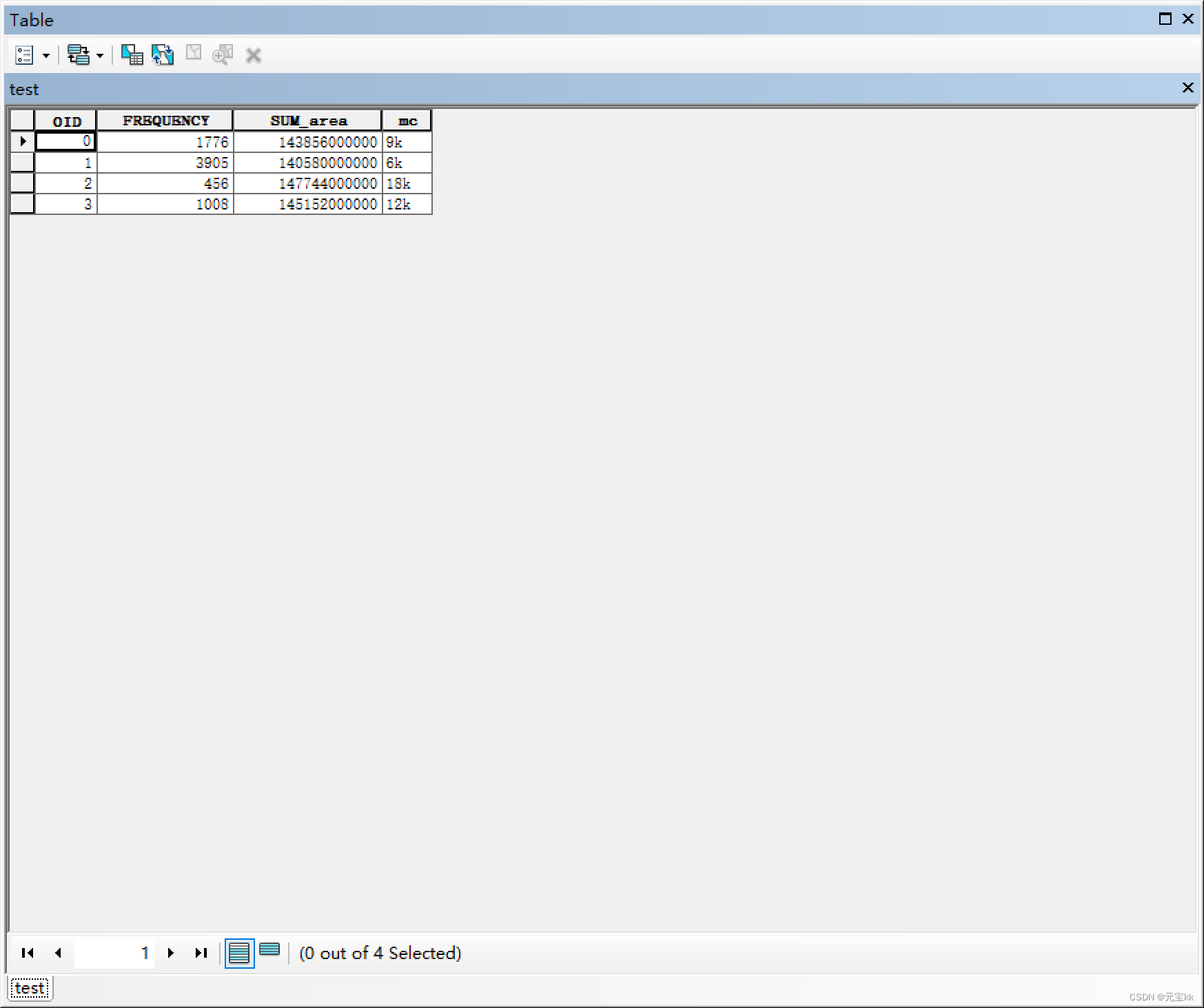
ArcGIS批量计算shp面积并导出shp数据总面积(建模法)
在处理shp数据时, 又是我们需要知道许多个shp字段的批量计算,例如计算shp的总面积、面积平均值等,但是单个查看shp文件的属性进行汇总过于繁琐,因此可以借助建模批处理来计算。 首先准备数据:一个含有多个shp的文件夹。…...
代码质量评价及设计原则
1.评价代码质量的标准 1.1 可维护性 可维护性强的代码指的是: 在不去破坏原有的代码设计以及不引入新的BUG的前提下,能够快速的修改或者新增代码. 不易维护的代码指的是: 在添加或者修改一些功能逻辑的时候,存在极大的引入新的BUG的风险,并且需要花费的时间也很长. 代码可…...

编程笔记 html5cssjs 012 HTML分块
编程笔记 html5&css&js 012 HTML分块 一、HTML 块级元素二、HTML 内联元素三、HTML <div> 元素四、HTML <span> 元素五、HTML<article>元素六、<article>元素和<div>元素的区别与联系小结 像报纸排版一样,很多时候需要把平面…...
【持续更新ing】uniapp+springboot实现个人备忘录系统【前后端分离】
目录 (1)项目可行性分析 (2)需求描述 (3)界面原型 (4)数据库设计 (5)后端工程 接下来我们使用uniappspringboot实现一个简单的前后端分离的小项目----个…...
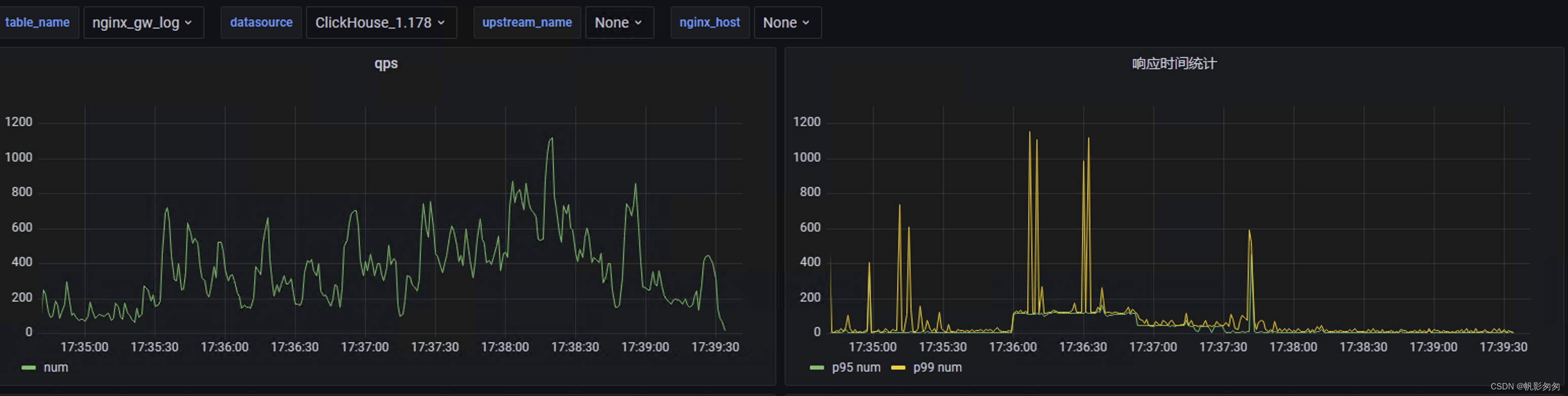
nginx+rsyslog+kafka+clickhouse+grafana 实现nginx 网关监控
需求 我想做一个类似腾讯云网关日志最终以仪表方式呈现,比如说qps、p99、p95的请求响应时间等等 流程图 数据流转就像标题 nginx ----> rsyslog ----> kafka —> clickhouse —> grafana 部署 kafka kafka 相关部署这里不做赘述,只要创…...

比话降AI和嘎嘎降AI处理80%+AI率哪个更好
比话降AI和嘎嘎降AI是目前市面上处理极高AI率最有效的两款工具,但很多人不知道该选哪个。 这篇文章做一个直接的对比:两款工具在AI率80%场景下,各有什么优势和劣势,你的情况适合哪个。 基础信息对比 项目比话降AI嘎嘎降AI官网b…...
)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧) 在AI模型部署领域,量化技术正成为突破硬件限制的关键手段。当我们面对Atlas 800I A2这样的高性能服务器时,如何充分发挥其64GB显存优势&#…...

别再乱配了!给COMSOL选工作站,CPU、内存、主板到底怎么搭才不浪费钱?
COMSOL工作站黄金配置法则:精准匹配需求,避开性能陷阱 当你面对琳琅满目的CPU型号、内存规格和主板参数时,是否感到无从下手?COMSOL Multiphysics作为一款强大的多物理场仿真工具,其性能表现与硬件配置息息相关。但盲目…...
_kaic)
weixin283基于微信小程序校园订餐的设计与开发+ssm(文档+源码)_kaic
第5章 系统实现 5.1用户登录功能的界面实现 本系统中可以保证安全的功能就是用户登录功能,登录可以验证用户的身份,用户可以注册,当密码忘记后也可以通过忘记密码功能进行找回。在用户登录界面里采用上中下的方式进行设计。在上设计的是功能…...

2026年全链路性能测试方案选型与实施指南
2026年全链路性能测试方案选型与实施指南 全链路性能测试已从单一功能验证转向覆盖多终端、多场景的质量保障,需结合硬件层、服务层、决策层三类方案才能应对行业复杂挑战。主流方案包括云真机兼容性测试(硬件层)、SaaS化压力测试平台&#x…...

告别subfloat!LaTeX中minipage+subfigure排版多图的最佳实践
LaTeX多图排版进阶指南:minipage与subfigure的黄金组合 在学术论文和技术文档写作中,图片排版往往是让人头疼的问题。特别是当需要处理多张图片并为其添加子标题时,传统的subfloat方法常常会遇到标题溢出、无法自动换行等令人沮丧的情况。本文…...

Boss-Key老板键:一键隐藏窗口的终极隐私保护神器
Boss-Key老板键:一键隐藏窗口的终极隐私保护神器 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 你是否曾经历过这样的尴尬时刻…...

不只是投屏:挖掘Scrcpy + ADB在Mac上的高阶玩法,提升开发调试效率
不只是投屏:挖掘Scrcpy ADB在Mac上的高阶玩法,提升开发调试效率 在移动应用开发与测试的日常工作中,效率工具的选择往往决定了生产力水平。Scrcpy作为一款开源的安卓设备投屏工具,其价值远不止于简单的屏幕镜像。当它与ADB&#…...

如何用SillyTavern在5分钟内创建你的第一个AI虚拟伙伴?
如何用SillyTavern在5分钟内创建你的第一个AI虚拟伙伴? 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾幻想过拥有一个专属的AI聊天伙伴?一个能理解你情绪、…...

终极指南:如何快速上手ALOHA开源双臂机器人系统,开启你的机器人开发之旅
终极指南:如何快速上手ALOHA开源双臂机器人系统,开启你的机器人开发之旅 【免费下载链接】aloha 项目地址: https://gitcode.com/gh_mirrors/al/aloha 你是否梦想拥有一个能够像人类一样灵巧操作的双臂机器人?ALOHA开源双臂机器人系统…...