大数据平台建设方法论集合
文章目录
- 从0到1建设大数据解决方案
- 大数据集群的方法论
- 数据集成方法论
- 机器学习算法平台方法论
- BI建设的方法论
- 云原生大数据的方法论
- 低代码数据中台的方法论
- 大数据SRE运维方法论
- 批流一体化建设的方法论
- 数据治理的方法论
- 湖仓一体化建设的方法论
- 数据分析挖掘方法论
- 数字化转型方法论
- 数据服务建设方法论
- 元数据管理方法论
- 知识图谱建设方法论
- 数仓建模的方法论
- 人工智能建设方法论
从0到1建设大数据解决方案
从0到1建设大数据解决方案是一个相对比较宏观的过程, 需要考虑从业务需求分析, 数据采集, 数据处理, 数据存储, 数据查询分析到数据可视化展示等多个环节,
以下是一个简单的大数据解决方案建设方法论:
需求分析: 首先需要明确业务需求, 包括数据源, 数据量, 数据类型, 数据质量等等, 可以与业务人员进行沟通, 制定出明确的需求和目标, 确定解决方案的规模和数据的范围
数据采集: 根据需求分析结果, 确定数据来源和采集方式, 可以使用采集工具或者开发自定义采集程序, 采集的数据需要进行清洗和过滤, 确保数据的准确性和完整性
数据处理: 数据采集后需要进行清洗, 整合, 加工等处理, 以便后续的存储和分析, 数据处理可以使用数据流处理或者批处理等方式
数据存储: 对于大数据解决方案, 数据存储是一个非常重要的环节, 需要选择合适的存储方案, 包括分布式存储, 列式存储, 内存数据库等, 可以根据数据量和查询分析方式等要素进行选择
数据查询分析: 建立数据查询和分析体系, 需要考虑数据查询和分析的灵活性和效率, 可以使用数据查询引擎和分析工具, 如Hadoop, Spark, Hive, Presto, Superset等
数据可视化展示: 通过数据可视化展示方式, 使数据分析结果直观, 易于理解, 可以使用开源的可视化工具, 如Tableau, Power BI, Echarts等
安全与隐私: 对于大数据解决方案, 安全和隐私是非常重要的, 需要采取一系列的安全措施, 包括数据加密, 访问控制, 数据备份等, 以保障数据的安全性和隐私性
评估和优化: 在建设过程中需要不断评估和优化解决方案, 调整方案架构和技术选型, 以提高解决方案的性能和效率, 满足业务需求和用户期望
以上是一个简单的从0到1建设大数据解决方案的方法论, 需要根据实际情况进行具体的调整和优化
大数据集群的方法论
大数据集群是用于处理大规模数据的分布式系统,通常由多个节点组成,节点之间相互协作,通过分布式计算和存储来处理大量的数据。以下是大数据集群的方法论:
需求分析:通过对业务和数据的分析,确定数据集群的规模和功能需求,包括数据处理和存储的容量、计算能力和数据安全等方面。
系统架构:根据需求分析的结果,设计集群的架构方案,包括节点数量、节点类型、数据分片和数据备份等方面。
节点部署:在设计好的系统架构下,选择合适的硬件和软件,按照一定的部署规划,将节点部署到不同的物理或虚拟机器上。
网络配置:配置集群节点之间的网络,保证节点间的数据交换和通信能力,同时考虑网络安全和防火墙等方面。
数据迁移:将现有的数据迁移到集群中,确保数据的完整性和一致性,同时保证数据的备份和灾难恢复能力。
集群监控:建立监控和管理系统,对集群的运行状态和性能进行监控,及时发现和处理故障和异常。
集群维护:定期维护和更新集群,包括软件更新、安全补丁、节点替换和性能优化等方面,以保证集群的稳定性和性能。
通过以上的方法论和流程,可以保证大数据集群的高效和可靠运行,为企业提供更加高效的数据处理和分析服务。
数据集成方法论
数据集成是指将来自不同数据源的数据整合在一起,使其具有一致性、完整性和可用性的过程。
数据集成方法论通常包括以下步骤:
明确集成目标:在开始数据集成之前,需要明确集成的目标,例如整合哪些数据源、需要整合到哪个目标数据仓库或数据湖中、需要整合哪些数据字段等。
数据源评估:评估各个数据源的质量和可用性,以决定是否使用这些数据源,并如何使用它们。
数据预处理:对数据进行预处理,例如去重、数据清洗、数据格式转换等。
数据映射:将来自不同数据源的数据映射到目标数据仓库或数据湖中,以确保数据的一致性。
数据转换:将数据转换为目标数据仓库或数据湖中的统一格式,以保证数据的一致性。
数据加载:将经过映射和转换的数据加载到目标数据仓库或数据湖中。
数据一致性检验:对集成后的数据进行检验,以确保数据的一致性和完整性。如果发现数据不一致或不完整,需要进行调整和修复。
数据质量评估:评估集成后的数据质量,例如数据的准确性、完整性、可靠性等,以确保数据质量符合要求。
数据集成管控:对数据集成的整个过程进行管控,包括数据质量管控、流程管控、权限管控等,以确保数据集成过程的可控性和安全性。
以上是通用的数据集成方法论,具体应用时可能需要根据不同的场景和需求进行调整和定制。
机器学习算法平台方法论
机器学习算法平台方法论是指在构建机器学习算法平台时采取的一系列方法和流程。
以下是一些通用的机器学习算法平台方法论:
确定平台目标和需求:在开始构建机器学习算法平台之前,需要明确平台的目标和需求,例如支持的算法类型、数据处理能力、性能和扩展性等。
收集和预处理数据:收集与机器学习算法平台相关的数据,并对数据进行预处理和清洗,以准备用于模型训练和测试。
算法模型选择和优化:选择合适的算法模型,例如分类、回归、聚类、推荐等,并对算法模型进行优化和调参,以提高模型的准确性和性能。
模型训练和评估:使用收集到的数据训练机器学习模型,并评估模型的准确性和性能。如果模型的准确性不够,需要重新调整算法和模型的参数。
部署和应用:将训练好的模型部署到生产环境中,并应用到实际的业务场景中,不断优化和改进模型的性能和效果。
监控和维护:对部署的机器学习算法平台进行监控和维护,保证平台的稳定性和可靠性,及时发现和解决问题。
同时,根据实际应用场景不断地更新和迭代算法平台,保证其持续性能的提升。
合规性和安全性:在机器学习算法平台建设过程中,需要遵循合规性和安全性的标准和法规,保证数据和模型的安全和隐私。
同时,要对算法平台进行风险评估和安全审查,确保平台不会对社会造成负面影响。
BI建设的方法论
BI(Business Intelligence)建设是指利用数据分析、数据挖掘等技术,将企业的各类数据进行整合、加工、分析和展示,以帮助企业进行商业决策。
以下是BI建设的方法论:
明确需求:明确企业的商业目标和决策需求,以确定BI建设的范围和重点。
确定数据源:收集、整合和清洗企业的数据,包括结构化数据(如数据库、Excel文件等)和非结构化数据(如文本、图像、音频等),并确定数据源的类型和格式。
设计数据模型:设计数据模型,包括数据表结构、数据类型、数据关系等,以便更好地管理和分析数据。
数据仓库建设:建立数据仓库,将数据从各种数据源中整合到数据仓库中,并进行数据清洗、转换、集成和存储。
数据分析:利用BI工具(如Tableau、Power BI、QlikView等)进行数据分析,包括数据挖掘、数据可视化等,以便更好地理解数据、发现数据中的价值和趋势。
报表设计和展示:根据需求和分析结果,设计和展示报表和图表,以便更好地展示数据、分析结果和趋势,为商业决策提供依据。
应用集成:将BI应用集成到企业应用中,如CRM、ERP、人力资源管理系统等,以便更好地支持业务流程和决策。
持续优化:持续优化BI建设,根据业务需求和数据分析结果,不断改进数据整合和分析方案,以提高数据价值和使用效果。
云原生大数据的方法论
云原生大数据是指将大数据应用和平台迁移到云环境下,并利用云原生技术和架构,以更高效、更灵活的方式进行大数据处理和分析。
以下是云原生大数据的方法论:
选用合适的云平台:选择适合企业业务需求和数据处理的云平台,如AWS、Azure、Google Cloud等,并了解其提供的大数据服务和工具。
选择适合的容器平台:选择适合的容器平台,如Docker、Kubernetes等,并了解其提供的容器管理、部署、扩容等服务。
应用微服务化:将大数据应用进行微服务化,将不同的功能拆分成独立的服务,以便更灵活的进行扩展和管理。
选择适合的存储和计算方案:根据业务需求选择适合的存储和计算方案,如Hadoop、Spark、Flink等,并考虑其在云环境下的性能和成本。
建立自动化流水线:建立自动化流水线,将代码、测试、构建和部署自动化,以提高效率和减少出错概率。
采用持续集成/持续部署:采用持续集成和持续部署技术,以便更快速地发布新功能和更新。
建立监控和告警系统:建立监控和告警系统,实时监测大数据平台的运行状态,及时发现和处理问题。
强化安全管理:加强大数据平台的安全管理,包括访问控制、数据加密、漏洞扫描等,以保证数据的安全和隐私。
通过以上的方法论和流程,可以帮助企业将大数据平台迁移到云环境下,并实现云原生架构,以更高效、更灵活的方式进行大数据处理和分析,提高数据的价值和使用效果。
低代码数据中台的方法论
低代码数据中台是指利用低代码平台技术和方法,快速构建和部署数据中台,实现数据整合、数据管理和数据分析。以下是低代码数据中台的方法论:
定义数据需求:明确业务需求和数据需求,确定需要整合的数据源和数据类型,并制定数据整合和分析方案。
选用低代码平台:选择适合企业业务需求和数据处理的低代码平台,如OutSystems、Salesforce、Microsoft Power Platform等,并了解其提供的数据管理、分析和可视化工具。
定义数据模型:设计数据模型,包括数据表结构、数据类型、数据关系等,以便更好地管理和分析数据。
数据整合:利用低代码平台提供的数据整合工具,将不同的数据源进行整合和清洗,并将数据存储到数据中心或数据仓库中。
数据分析和可视化:利用低代码平台提供的数据分析和可视化工具,进行数据挖掘、数据分析和数据可视化,帮助企业更好地理解数据,发现数据中的价值。
应用集成:将数据中台集成到企业应用中,如CRM、ERP、人力资源管理系统等,以便更好地支持业务流程和决策。
持续优化:持续优化低代码数据中台,根据业务需求和数据分析结果,不断改进数据整合和分析方案,以提高数据价值和使用效果。
大数据SRE运维方法论
SRE(Site Reliability Engineering)是一种针对服务的高可用性、稳定性和可扩展性进行设计和运维的方法论。以下是大数据SRE运维方法论的一些关键点:
设计可靠架构:为了实现高可用性和稳定性,需要在系统设计阶段就考虑架构的可靠性,采用分布式架构、负载均衡、故障转移等技术,实现系统的高可用性和容错能力。
自动化运维:采用自动化运维工具,如Puppet、Chef、Ansible等,实现配置管理、部署、监控和故障处理的自动化。
实时监控:利用实时监控系统,如Zabbix、Nagios、Prometheus等,实时监控系统的各项指标,包括CPU、内存、磁盘、网络等,以便及时发现系统故障和异常。
快速响应:通过灰度发布、A/B测试、蓝绿部署等技术,实现快速响应和快速恢复,最大程度地降低系统的宕机时间和影响范围。
容量规划:通过容量规划和负载测试,评估系统的承载能力和瓶颈,及时升级硬件、优化配置,以满足系统的可扩展性和性能要求。
异常处理:建立完善的异常处理机制,实现快速定位、分析、修复系统异常,提高系统的可用性和稳定性。
知识管理:建立SRE知识库,记录系统的运维流程、故障处理方法、最佳实践等,以便团队成员随时查阅和学习。
持续优化:持续优化SRE
批流一体化建设的方法论
批流一体是指将批处理和流式处理相结合,在一个平台上同时支持批处理和流式处理,以便在处理海量数据时更加高效和灵活。
以下是批流一体化建设的方法论:
确定业务需求:首先需要明确业务需求,确定需要处理的数据类型和数量,以便在批流一体化的建设中做出相应的决策。
构建批处理:构建批处理,对批量数据进行处理和分析,处理方式主要是离线批量处理,需要提供高容量和高性能的数据存储和处理能力。
构建流式处理:构建流式处理,对实时数据进行处理和分析,处理方式主要是在线流式处理,需要提供高并发和低延迟的数据处理和分析能力。
数据标准化:对数据进行标准化处理,包括数据的格式、结构、质量等方面,以便批处理和流式处理都能够更好地进行数据处理和分析。
数据集成:将批处理和流式处理进行集成,以确保数据的一致性和完整性,同时提供灵活的数据处理和分析功能。
建立数据治理:建立数据治理框架,包括数据安全、数据质量、数据访问控制、数据备份和恢复等方面,以确保批流一体的数据处理的安全和可靠性。
持续优化:持续优化批流一体化的建设和运维,根据业务需求和数据变化的情况,及时调整批流一体化的架构和技术选型,以提高数据的价值和使用效果。
通过以上的方法论和流程,可以有效地建立批流一体化的数据处理平台,满足企业对海量数据的各种需求,提高数据的处理效率和价值。
数据治理的方法论
数据治理是一种通过规范化、协调、管理和监督企业数据资产的过程,旨在确保数据的正确性、一致性、完整性、安全性和可靠性,以便企业能够更好地利用数据为业务决策提供支持。
以下是数据治理的方法论:
制定数据治理政策:在企业内部,要建立数据治理政策,明确数据资产的所有权、规范、标准和管理责任等方面,以确保数据资产的高质量、安全和可靠性。
确定数据质量标准:制定数据质量标准并按照这些标准对数据进行评估和监控。数据质量标准可以根据不同的业务需求,对数据进行不同的质量评估和监控。
建立数据管理流程:建立完整的数据管理流程,包括数据采集、存储、处理、发布、使用、备份和恢复等方面,以确保数据的全生命周期管理。
数据安全管理:对数据进行安全管理,包括数据加密、访问控制、身份认证、数据备份和灾难恢复等方面,以确保数据的安全性和完整性。
数据元数据管理:建立元数据管理框架,管理数据的定义、结构、属性和关系等信息,以确保数据的正确性、一致性和可靠性。
建立数据使用规则:建立数据使用规则,明确数据的访问权限、使用范围、保密性等方面的规则,以确保数据的正确使用和共享。
持续改进:对数据治理流程进行持续的改进和优化,不断提高数据治理的效率和质量。
通过以上的方法论和流程,可以有效地管理企业的数据资产,提高数据资产的质量和价值,提升企业的业务决策水平和竞争力。
湖仓一体化建设的方法论
湖仓一体化是指将数据湖和数据仓库结合在一起,从而形成一个统一的数据管理平台,以满足企业日益增长的数据需求。以下是湖仓一体化建设的方法论:
确定业务需求:首先需要明确业务需求,确定需要存储、处理和分析的数据类型和数量,以便在湖仓一体化的建设中做出相应的决策。
构建数据湖:构建数据湖,收集、存储各种类型的原始数据,包括结构化数据、半结构化数据和非结构化数据等,数据湖需要提供高容量和高性能的数据存储和处理能力。
建立数据仓库:在数据湖的基础上建立数据仓库,对数据进行清洗、转换和整合,形成适合分析的数据模型,数据仓库需要提供高性能和高可靠性的数据查询和分析能力。
数据标准化:对数据进行标准化处理,包括数据的格式、结构、质量等方面,以便数据仓库能够更好地进行数据处理和分析。
数据集成:将数据湖和数据仓库进行集成,以确保数据的一致性和完整性,同时提供灵活的数据查询和分析功能。
建立数据治理:建立数据治理框架,包括数据安全、数据质量、数据访问控制、数据备份和恢复等方面,以确保数据湖和数据仓库的安全和可靠性。
持续优化:持续优化湖仓一体化的建设和运维,根据业务需求和数据变化的情况,及时调整湖仓一体化的架构和技术选型,以提高数据的价值和使用效果。
通过以上的方法论和流程,可以有效地建立湖仓一体化的数据管理平台,满足企业对数据的各种需求,提高数据的使用效率和价值。
数据分析挖掘方法论
数据分析挖掘方法论是指在数据挖掘过程中所需的方法论和技能,它包括以下步骤:
确定业务问题和数据需求:了解业务问题和数据需求,确定需要分析的数据,这是数据分析挖掘的第一步。
数据采集和预处理:数据采集和预处理是数据分析挖掘的重要步骤,需要将原始数据转换为可分析的数据,包括数据清洗、去重、数据转换、数据集成等。
数据探索和可视化:在探索数据的过程中,需要使用可视化工具和技术,以帮助识别数据的特征和模式,并支持数据挖掘的决策过程。
模型选择和建立:在选择模型时,需要根据业务问题和数据需求选择适当的算法,例如聚类、分类、回归等。在建立模型时,需要使用工具和技术对数据进行训练和测试。
模型评估和优化:在评估模型时,需要使用交叉验证等技术来评估模型的性能,如准确率、召回率等。在优化模型时,可以尝试使用不同的算法和参数,以提高模型的性能。
结果解释和应用:在将数据分析结果应用到实际业务中时,需要对结果进行解释和说明,帮助业务用户理解数据分析的结果,并支持业务决策过程。
持续改进和监控:数据分析和挖掘是一个持续改进和监控的过程,需要定期进行数据分析和挖掘,并监控和分析数据的变化,以便及时调整和改进分析过程。
数字化转型方法论
数字化转型是指将传统企业在信息化, 网络化, 智能化, 数据化等技术的支撑下, 对业务, 组织, 文化, 价值创造, 利益分配等方面进行全面的革新和升级,
以适应市场, 技术, 用户等环境的变化数字化转型的目标是实现企业从传统生产经营方式向数字化经营模式的转变, 提高企业的效率, 创新能力, 市场竞争力和盈利能力
数字化转型方法论可以概括为以下几个方面:
确定数字化转型的战略目标和方向, 明确数字化转型的意义和价值, 为数字化转型的实施提供方向和支撑
分析业务过程, 识别业务痛点和机会, 确定数字化转型的重点领域和项目, 以提高效率, 创新能力和用户体验为导向
优化组织结构和流程, 建立数字化组织架构和工作流程, 激发组织创新和员工动力, 提高业务效率和创新能力
采用先进的信息技术和数据技术, 例如云计算, 大数据, 人工智能, 物联网等, 为数字化转型提供技术支持
建立数字化文化, 通过数字化营销, 数字化服务, 数字化协同等方式, 提升品牌价值, 用户满意度和市场影响力
实施数字化监管, 建立数字化安全, 合规和风险控制体系, 确保数字化转型的合法性, 合规性和可持续性
数字化转型是一个复杂的过程, 需要综合运用战略, 组织, 技术, 文化, 监管等多方面的手段和方法, 才能取得成功
数据服务建设方法论
数据服务建设方法论是指建立可重用、可扩展、标准化的数据服务,使得数据可以方便地被其他业务系统或数据应用所调用和使用。以下是一些常见的数据服务建设方法论:
确定数据服务的需求:在开始数据服务建设之前,需要明确业务系统的需求,以及这些需求如何转化为具体的数据服务。
确定数据服务的范围:根据需求,确定数据服务的范围和边界,明确数据服务需要支持哪些数据源、数据处理和数据输出。
设计数据服务接口:根据数据服务的需求和范围,设计数据服务接口,包括输入参数、输出数据、调用方式等。
设计数据服务架构:在设计数据服务架构时,需要考虑数据服务的可扩展性、可维护性、安全性等因素。常见的数据服务架构包括SOA(面向服务的架构)、微服务架构等。
数据服务开发和测试:在进行数据服务开发之前,需要进行技术选型、开发环境搭建、开发框架选择等工作。在开发过程中,需要进行单元测试、集成测试、性能测试等。
发布和管理数据服务:在数据服务开发完成后,需要进行发布和管理。发布时需要考虑版本控制、文档编写、安全管理等问题。管理时需要监控数据服务的运行状况、处理异常情况等。
数据服务维护和优化:在数据服务发布后,需要进行维护和优化。维护包括数据服务的更新、问题修复等工作。优化则包括性能优化、安全优化等工作。
元数据管理方法论
元数据是描述数据的数据,是数据管理中的重要组成部分,可以帮助用户更好地理解和利用数据。
元数据管理方法论是对元数据进行有效管理的一套标准化流程和方法,主要包括以下几个方面:
定义元数据:对需要管理的元数据进行定义和分类,包括数据类型、数据来源、数据格式、数据质量、数据访问权限等。
确定元数据管理策略:制定元数据管理策略,包括元数据收集、存储、维护和更新的规范和流程。
确认元数据的业务价值:明确元数据的业务价值和重要性,以便制定元数据管理策略和计划。
元数据收集:采集和收集元数据信息,包括元数据的数据字典、数据表、数据结构等,还可以通过数据建模、数据分析和数据挖掘等技术获取元数据。
元数据存储:确定元数据的存储方式,包括元数据仓库、元数据管理工具、数据库等。
元数据维护和更新:对元数据进行定期维护和更新,以保证元数据的准确性和完整性,同时可以对元数据进行版本控制。
元数据使用和共享:提供元数据的查询和使用接口,以便用户可以方便地查询、使用和共享元数据信息。
元数据安全:为元数据设置安全控制,以保证元数据的安全性和保密性,包括元数据的访问权限和审计日志等。
通过以上的方法论和流程,可以实现对元数据的有效管理和利用,帮助用户更好地理解和利用数据,提高数据管理和分析的效率和质量。
基于DataHub+Flink Lineage建设元数据管理平台
知识图谱建设方法论
一, 知识图谱技术架构: 确定知识的表示方式和知识的存储方式;
二, 知识图谱建设方法论: 知识图谱建设可以分为知识建模, 知识抽取, 知识验证这样几个阶段, 形成一个知识图谱
从知识抽取的内容上, 又可以分为实体抽取, 属性抽取, 关系抽取, 事件抽取:
实体抽取指从数据源中检测到可命名的实体, 并将它们分类到已建模的类型中, 例如人, 组织, 地点, 时间等等;
属性抽取是识别出命名实体的具体属性;
关系抽取是识别出实体与实体之间的关系, 例如从句子“著名歌手周杰伦的妻子昆凌”中识别出“周杰伦”与“昆凌”之间的夫妻关系;
事件抽取是识别出命名实体相关的事件信息, 例如“周杰伦”与“昆凌”结婚就是一个事件
可以看出实体抽取, 属性抽取, 关系抽取是抽取我们在知识建模中定义的拓扑结构部分数据,
事件抽取是事件建模相关数据的抽取, 所以在领域知识图谱建设中, 也需要包括数据准备域的抽取方式, 处置域的数据抽取方式
知 识 验 证
从各种不同数据源抽取的知识, 并不一定是有效的知识, 必须进行知识的验证, 将有效的, 正确的知识进入知识库造成知识不准确的原因,
通常是原始数据存在错误, 术语存在二义性, 知识冲突等等, 例如前面提到的"1#"压水堆, "1号"压水堆, “一号”压水堆这三个词对应一个实体,
如果在抽取中没有合理定义规则, 这就需要在知识验证阶段得到处理, 以便形成闭环
三, 基于知识图谱建设应用: 每一类应用的侧重点不同, 使用技术和达到的效果也不同, 我们总结为知识推理类, 知识呈现类, 知识问答类, 知识共享类
1, 知识图谱建设
1.1 人工数据标注工具: https://github.com/doccano/doccano
1.2 自动标注+知识抽取: https://github.com/zjunlp/DeepKE
2, 知识存储: https://github.com/alibaba/GraphScope
3, 知识图谱应用: https://github.com/lemonhu/stock-knowledge-graph
知识图谱构建方法论
知识图谱构建方法论是指为了创建一个高质量的知识图谱而采取的一系列方法和流程。
以下是一些通用的知识图谱构建方法论:
定义知识图谱的目标和范围:在开始构建知识图谱之前,需要明确知识图谱的目标和范围,例如知识图谱的主题、应用场景、覆盖领域等。
收集数据源:根据定义的目标和范围,收集相关的数据源。这些数据源可以包括结构化和非结构化数据、知识库、文档、网站、API等。
数据预处理:对收集到的数据进行预处理,包括数据清洗、归一化、去重、实体抽取等操作,以确保数据的准确性和一致性。
构建本体和模式:定义本体和模式,包括实体和关系类型、属性、约束等,以规范知识图谱的结构和语义。
实体链接:将不同数据源中的相同实体进行链接,以消除实体之间的歧义。
知识抽取:从数据源中自动抽取知识,并将其映射到知识图谱中的实体和关系中。
知识补充和验证:使用自动化方法和人工标注的方式补充和验证知识,以提高知识图谱的准确性和完整性。
知识应用:将知识图谱应用到具体的应用场景中,例如自然语言理解、问答系统、推荐系统等。
需要注意的是,知识图谱构建方法论是一个不断迭代的过程,需要根据实际情况进行调整和优化。
同时,知识图谱的构建也需要依赖于强大的技术支持,如自然语言处理、机器学习、图数据库等。
数仓建模的方法论
数仓建模是构建数据仓库的关键步骤之一,它是将源系统数据经过抽取、清洗、转换、加载等过程,
最终按照一定的业务需求进行聚合、汇总、计算、分析等处理,形成数据仓库的过程。数仓建模的方法论主要包括以下几个方面:
维度建模:维度建模是一种常用的建模技术,它通过识别业务过程中的业务实体和业务事件,将其转化为维度和事实表的关系模型,以支持企业级的数据分析和决策。
维度建模包括多维模型和星型模型两种。
E-R建模:实体-关系(Entity-Relationship,E-R)建模是一种用图形表示法来描述数据和它们之间关系的方法。
它以实体和实体之间的关系为中心来构建数据模型,并通过将实体和关系映射到关系数据库中的表和外键来支持数据查询和分析。
OLAP建模:OLAP建模(Online Analytical Processing)是在数仓中支持多维数据分析的一种建模方法。
它通过将维度和指标的层次结构进行组合,构建立方体(Cube)来支持数据多维分析。
时间序列建模:时间序列建模是针对具有时间维度的数据,采用时间序列分析方法对其进行建模的过程。
时间序列建模可以采用传统的统计方法,如ARIMA、ETS等,也可以使用机器学习方法进行建模。
以上是数仓建模的常用方法论,不同的建模方法适用于不同的业务场景和需求。
在实际应用中,需要结合业务需求和数据特点,选择合适的建模方法,并不断优化迭代,保证数据仓库的数据质量和分析效果。
人工智能建设方法论
确定目标和需求:在开始构建人工智能系统之前,需要明确人工智能系统的目标和需求,例如系统的应用场景、数据来源、预测和决策的准确性等。
收集数据和特征:收集与人工智能系统相关的数据和特征,并对这些数据和特征进行清洗、处理和转换,以准备用于训练和测试模型。
数据分析和建模:对数据和特征进行分析和建模,以识别出与目标变量相关的特征和模式,同时选择和优化合适的算法和模型。
模型训练和评估:使用收集到的数据和特征训练人工智能模型,并评估模型的准确性和性能。如果模型的准确性不够,需要重新调整特征、算法和模型的参数。
部署和应用:将训练好的模型部署到生产环境中,并应用到实际的业务场景中,不断优化和改进模型的性能和效果。
监控和维护:对部署的人工智能系统进行监控和维护,保证系统的稳定性和可靠性,及时发现和解决问题。同时,根据实际应用场景不断地更新和迭代人工智能系统,保证其持续性能的提升。
合规性和安全性:在人工智能建设过程中,需要遵循合规性和安全性的标准和法规,保证数据和模型的安全和隐私。
同时,要对人工智能系统进行风险评估和安全审查,确保系统不会对社会造成负面影响。
相关文章:

大数据平台建设方法论集合
文章目录从0到1建设大数据解决方案大数据集群的方法论数据集成方法论机器学习算法平台方法论BI建设的方法论云原生大数据的方法论低代码数据中台的方法论大数据SRE运维方法论批流一体化建设的方法论数据治理的方法论湖仓一体化建设的方法论数据分析挖掘方法论数字化转型方法论数…...
25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)
知识要点 卷积神经网络的几个主要结构: 卷积层(Convolutions): Valid :不填充,也就是最终大小为卷积后的大小. Same:输出大小与原图大小一致,那么N 变成了N2P. padding-零填充. 池化层(Subsampli…...

把数组里面数值排成最小的数
问题描述:输入一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的一个。例如输入数组{12, 567},则输出这两个能排成的最小数字12567。请给出解决问题的算法,并证明该算法。 思路:先将…...
云his系统源码 SaaS应用 基于Angular+Nginx+Java+Spring开发
云his系统源码 SaaS应用 功能易扩 统一对外接口管理 一、系统概述: 本套云HIS系统采用主流成熟技术开发,软件结构简洁、代码规范易阅读,SaaS应用,全浏览器访问前后端分离,多服务协同,服务可拆分ÿ…...

小红书场景营销怎么做?场景营销主要模式有哪些
小红书作为新兴媒体领域的佼佼者,凭借着生动,直观,代入感等元素的分享推荐收揽了巨额的流量。但是,随着时代的脚步逐渐加快,发展和变革随之涌来,传统的营销已经无法满足。所以场景营销就出现了。今天就来和…...

c++基础——数组
数组数组是存放相同类型对象的容器,数组中存放的对象没有名字,而是要通过其所在的位置访问。数组的大小是固定的,不能随意改变数组的长度。定义数组数组的声明形如 a[b],其中,a 是数组的名字,b 是数组中元素…...
odoo15 登录界面的标题自定义
odoo15 登录界面的标题自定义 原代码中查询:<title>Odoo<title> <html> <head><meta http-equiv="content-type" content="text/html; charset=utf-8" /><title>Odoo</title><link rel="shortcut icon…...

【内网服务通过跳板机和公网通信】花生壳内网穿透+Nginx内网转发+mqtt服务搭建
问题:服务不能暴露公网 客户的主机不能连外网,服务MQTT服务部署在内网。记做:p1 (computer 1)堡垒机(跳板机)可以连外网,内网IP 和 MQTT服务在同一个网段。记做:p2 (computer 2)对他人而言&…...

【多线程常见面试题】
谈谈 volatile关键字的用法? volatile能够保证内存可见性,强制从主内存中读取数据,此时如果有其他线程修改被volatile修饰的变量,可以第一时间读取到最新的值 Java多线程是如何实现数据共享的? JVM把内存分成了这几个区域: 方法区,堆区,栈区,程序计数器; 其中堆区…...

深度剖析指针(下)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容还是我们的指针呀,上两篇博客我们基本上已经把知识点过了一遍,这篇博客就让小雅兰来带大家看一些和指针有关的题目吧,现在,就让我们进入指针的世界吧 复习: 数组和…...

爬虫与反爬虫技术简介
互联网的大数据时代的来临,网络爬虫也成了互联网中一个重要行业,它是一种自动获取网页数据信息的爬虫程序,是网站搜索引擎的重要组成部分。通过爬虫,可以获取自己想要的相关数据信息,让爬虫协助自己的工作,…...

Pag的2D渲染执行流程
Pag的渲染 背景 根据Pag文章里面说的,Pag之前长时间使用的Skia库作为底层渲染引擎。但由于Skia库体积过大,为了保证通用型(比如兼容CPU渲染)做了很多额外的事情。所以Pag的工程师们自己实现了一套2D图形框架替换掉Skiaÿ…...

k8s 概念说明,k8s面试题
什么是Kubernetes? Kubernetes是一种开源容器编排系统,可自动化应用程序的部署、扩展和管理。 Kubernetes 中的 Master 组件有哪些? Kubernetes 中的 Master 组件包括 API Server、etcd、Scheduler 和 Controller Manager。 Kubernetes 中的…...

Docker--(四)--搭建私有仓库(registry、harbor)
私有仓库----registry官方提供registry仓库管理(推送、删除、下载)私有仓库----harbor私有镜像仓库1.私有仓库----registry官方提供 Docker hub官方已提供容器镜像registry,用于搭建私有仓库 1.1 镜像拉取、运行、查看信息、测试 (一) 拉取镜像 # dock…...

Invalid <url-pattern> [sso.action] in filter mapping
Tomcat 8.5.86版本启动web项目报错Caused by: java.lang.IllegalArgumentException: Invalid <url-pattern> [sso.action] in filter mapping 查看项目的web.xml文件相关片段 <filter-mapping><filter-name>SSOFilter</filter-name><url-pattern&g…...

【11】linux命令每日分享——useradd添加用户
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...
Newman+Jenkins实现接口自动化测试
一、是什么Newman Newman就是纽曼手机这个经典牌子,哈哈,开玩笑啦。。。别当真,简单地说Newman就是命令行版的Postman,查看官网地址。 Newman可以使用Postman导出的collection文件直接在命令行运行,把Postman界面化运…...
MySQL:事务+@Transactional注解
事务 本章从了解为什么需要事务到讲述事务的四大特性和概念,最后讲述MySQL中的事务使用语法以及一些需要注意的性质。 再额外讲述一点Springboot中Transactional注解的使用。 1.为什么需要事务? 我们以用户转账为例,假设用户A和用户B的银行账…...
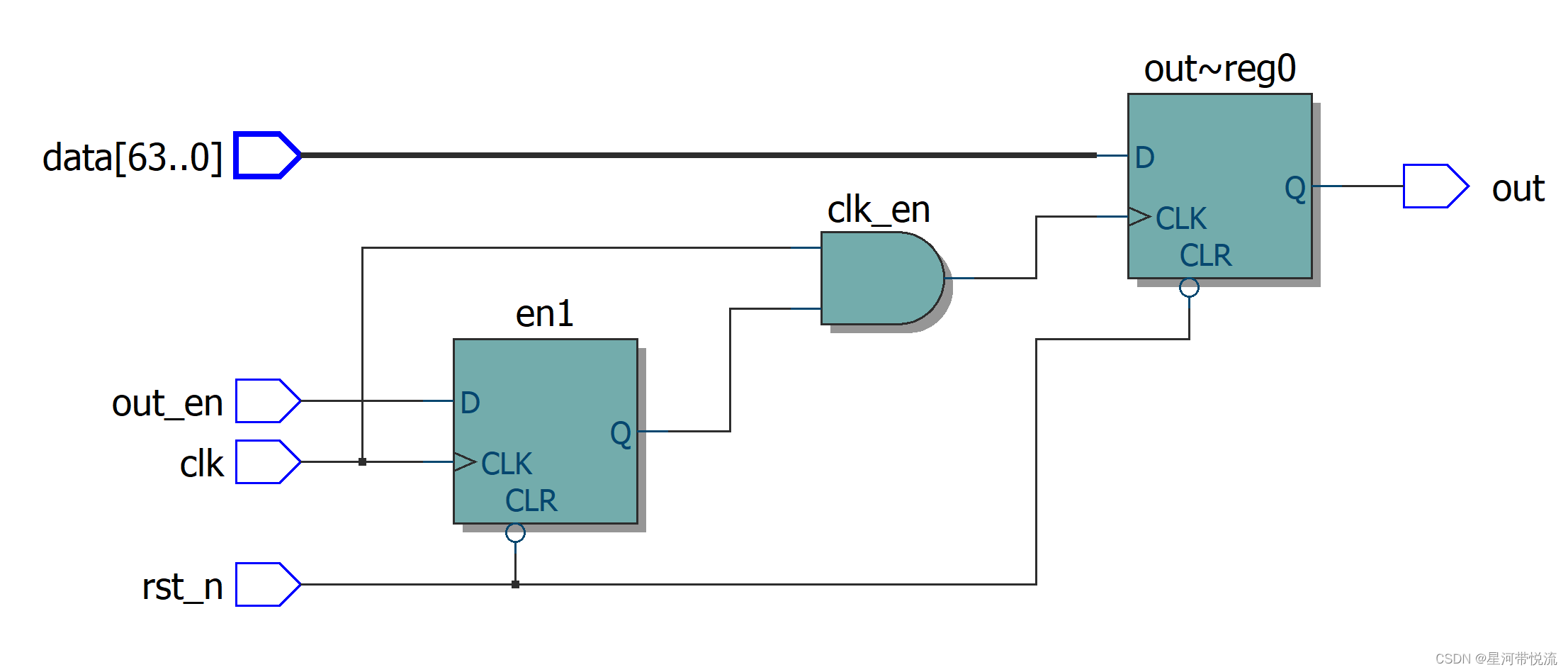
数字IC手撕代码--低功耗设计 Clock Gating
背景介绍芯片功耗组成中,有高达 40%甚至更多是由时钟树消耗掉的。这个结果的原因也很直观,因 为这些时钟树在系统中具有最高的切换频率,而且有很多时钟 buffer,而且为了最小化时钟 延时,它们通常具有很高的驱动强度。 …...

易基因|m6A RNA甲基化研究的数据挖掘思路:干货系列
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。关于m6A甲基化研究思路(1)整体把握m6A甲基化图谱特征:m6A peak数量变化、m6A修饰基因数量变化、单个基因m6A peak数量分析、m6A peak在基因元件上的分布…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...