neo4j运维管理
管理数据库
概念
Neo4j 5(从v4.0),可以同时创建和使用多个活动数据库。
DBMS
Neo4j是一个数据库管理系统(DBMS),能够管理多个数据库。DBMS可以管理一个独立的服务器,也可以管理集群中的一组服务器。
实例
Neo4j实例是运行Neo4j服务器代码的Java进程。
Transaction domain(事务域)
Transaction domain是可以在单个事务的上下文中更新的图的集合。
执行上下文
执行上下文是执行请求的运行时环境。实际上,请求可以是查询、事务或内部函数或过程。
Graph
单个数据库中的数据模型。
数据库
数据库是DBMS的一个管理分区。实际上,它是在目录或文件夹中组织的文件的物理结构,具有与数据库相同的名称。
在Neo4j 5中,每个标准数据库包含一个单独的Graph。许多管理命令通过使用数据库名称来引用特定的图。
数据库定义了事务域和执行上下文。这意味着一个事务不能跨多个数据库。类似地,过程调用是在一个数据库中,尽管其逻辑可以访问存储在其他数据库中的数据。
Neo4j 5 的默认安装包括2个数据库:
system:系统数据库,包含DBMS上的元数据和安全配置。Neo4j:默认数据库,用户数据的单一数据库。可以在第一次启动Neo4j之前配置不同的名称。
Composite database
复合数据库是包含在其他标准数据库中的多个图的逻辑分组。复合数据库定义了一个执行上下文和一个(有限的)事务域。
Neo4j的版本决定了可能的数据库数量:
Community Edition的安装只能有一个用户数据库。
企业版的安装可以有任意数量的用户数据库。
所有安装都包括系统数据库。
System数据库
所有安装都包括一个名为system的内置数据库,其中包含元数据和安全配置。
系统数据库的行为不同于所有其他数据库。特别是,当连接到该数据库时,只能执行一组特定的管理功能。大多数可用的管理命令仅限于具有特定管理权限的用户。细粒度访问控制中描述了配置安全特权的示例。
默认数据库和主数据库
如果用户连接到Neo4j时没有指定数据库,那么将连接到主数据库。在选择主数据库时,服务器将首先使用为该用户配置的主数据库。如果连接用户没有配置主数据库,服务器将使用默认数据库,每个Neo4j实例都有默认数据库。
默认数据库是可配置的。具体请参见配置参数。
每个用户的主数据库可以通过Cypher管理命令进行控制。User Management.
管理和配置
管理命令
在使用管理命令之前,了解已停止(stopped )数据库和已删除(dropped )数据库之间的区别是很重要的:
-
使用
STOP命令停止的数据库将完全关闭,并可能通过START命令再次启动。在集群中,只要数据库处于关闭状态,它就不能被认为对集群的其他成员可用。对关闭的数据库进行在线备份是不可能的,在灾难恢复期间需要特别考虑它们,因为它们在关闭时没有运行的Raft机器。 -
被删除的数据库将被完全删除,并且根本不打算再次使用。
以下Cypher命令用于管理系统数据库上的多个数据库:
| Command | Description |
|---|---|
CREATE DATABASE name | 企业版功能 |
DROP DATABASE name | 企业版功能 |
ALTER DATABASE name | 企业版功能 |
START DATABASE name | |
STOP DATABASE name | |
SHOW DATABASE name | |
SHOW DATABASES | |
SHOW DEFAULT DATABASE | |
SHOW HOME DATABASE |
数据库命名规则:
-
长度必须在3 ~ 63个字符之间。
-
名称的第一个字符必须是ASCII字母。
-
后续字符必须是ASCII字母或数字字符、点或破折号。
[a. . z][0 . . 9] . - -
名称不区分大小写,并规范化为小写。
-
以下划线(
_)和前缀system开头的名称保留供内部使用。
以上所有命令都作为
Cypher命令执行,数据库名称受Cypher对有效标识符的标准限制。特别是-(破折号)和.(点)字符在Cypher变量中是不合法的,因此带有破折号的名称必须用反引号括起来。例如,CREATE DATABASE main-db。数据库名称是唯一不需要转义点的标识符。例如,main.db是一个有效的数据库名称。
可以创建别名来引用现有数据库,以避免这些限制。
配置参数
配置参数在neo4j.conf文件中定义。
以下配置参数适用于管理数据库:
| 参数名 | 描述 |
|---|---|
initial.dbms.default_database | Neo4j实例的默认数据库名称。如果实例启动时数据库不存在,则创建该数据库。默认值: ’ neo4j ’ 在集群设置中,initial.dbms.default_database 的值仅用于设置初始默认数据库。稍后可更改默认数据库。 |
dbms.max_databases | Neo4j单个实例或集群中可使用的最大数据库数量。包括所有在线和离线数据库。整数形式,最小取值为2。企业版默认值: 100。 一旦达到限制,就不可能再创建任何额外的数据库。类似地,如果将限制更改为低于现有数据库总数的数字,则不能创建其他数据库。 |
server.databases.default_to_read_only | 所有数据库的默认模式。如果将此设置设置为 true ,所有现有的和新的数据库将处于只读模式,因此将阻止写查询。默认值: false |
server.databases.read_only | 防止写入查询的数据库名称列表。这个集合也可以包含尚未存在的数据库,但不包括“system”数据库。不管server.databases.default_to_read_only, server.databases.read_only, dbms.databases.writable如何设置,system数据库永远不会是只读的。防止写操作的另一种方法是使用ALTER DATABASE命令将数据库访问设置为只读。example :server.databases.read_only=["foo", "bar"] |
dbms.databases.writable | 要接受写查询的数据库名称列表。此集合还可以包含尚未存在的数据库。如果server.databases.default_to_read_only设置为 false ,则忽略此设置的值。如果两个集合中都有数据库名,则数据库将是只读的,并阻止写查询。example: dbms.databases.writable=["foo", "bar"] |
如果同时使用了
Cypher命令和配置参数,并且它们包含冲突的信息,则将有问题的数据库设置为只读。
Cypher 查询
//显示单个数据库
SHOW DATABASE neo4j;
//显示所有数据库
SHOW DATABASES;
//显示默认数据库
SHOW DEFAULT DATABASE;
//切换数据库
:use sales
//
CREATE OR REPLACE DATABASE sales;
STOP DATABASE sales;
START DATABASE sales;
DROP DATABASE sales;
数据库状态
| State | Description |
|---|---|
online | 在线 |
offline | 离线 |
starting | 正在启动 |
stopping | 正在停止,离线操作(e.g. load,dump) 不能执行 |
store copying | 数据库目前正在从Neo4j的另一个实例进行更新。 |
initial | 初始化,还未创建。 |
dirty | 此状态表示发生了错误。数据库的基础存储文件可能无效。要了解更多信息,查阅 statusMessage 列或服务器的日志。 |
quarantined | 数据库将有效停止,并且在不再隔离之前,不能更改其状态。要了解更多信息,查阅 statusMessage 列或服务器的日志。 |
unknown | |
dropped | 已删除 |
连接远程数据库(企业版功能)
见:remote
组合数据库(企业版功能)
组合数据库是Neo4j 5中引入的一种特殊类型的数据库。它取代了Neo4j 4中以前的Fabric实现。
Fabric是统一系统的架构设计,它为本地或分布式图形数据提供单个访问点。它允许您有效地管理数据、计算资源、存储和网络流量。
组合数据库是使用单个Cypher查询访问这些分区数据或图的方法。
见 组合数据库
事务行为
为了维护数据完整性并确保可靠的事务行为,Neo4j DBMS支持具有完整ACID属性的事务,并且它使用预写事务日志来确保持久性。
Neo4j DBMS支持以下事务行为:
-
所有访问Graph、索引或模式的数据库操作都必须在事务中执行。
-
默认隔离级别为读提交隔离级别。
-
写锁是在节点和关系级别自动获取的。但是,如果希望实现更高级别的隔离——可序列化隔离级别,也可以手动获取写锁。
-
通过遍历获取的数据不受其他事务修改的保护。
-
可能会发生不可重复的读操作(即,只获取写锁并保持到事务结束)。
-
死锁检测内置于核心事务管理中。
事务管理
访问Graph、索引或模式的数据库操作在事务中执行,以确保ACID属性。事务是单线程的、受限的和独立的。多个事务可以在单个线程中启动,并且它们彼此独立。
完成每个事务是至关重要的,因为事务获得的锁或内存只有在完成时才会释放。在语句结束时,所有未提交的事务作为资源清理的一部分被回滚。对于显式提交或回滚的事务,不需要进行资源清理,事务闭包是一个空操作。
在事务中执行的所有修改都保存在内存中。这意味着必须将非常大的更新拆分为几个事务,以避免内存耗尽。
事务配置
db.transaction.concurrent.maximum:并发事务最大数量,默认1000,设置为0时,表示禁用数量限制。
db.transaction.timeout:事务超时时间,设置为0时,表示禁用此特性。
可以使用 dbms.setConfigValue('db.transaction.timeout','10s') 设置。
超时时间可以在
JAVA API或neo4j驱动中覆盖掉,但是一定要比设置db.transaction.timeout的值小。
//事务cypher
SHOW TRANSACTIONS
TERMINATE TRANSACTIONS
锁和死锁
锁由用户运行的查询自动获取。它们确保节点/关系被锁定到一个特定的事务,直到该事务完成。换句话说,一个事务对节点或关系的锁定会暂停其他事务以并发地修改同一节点或关系。因此,锁可以防止事务间共享资源的并发修改。
Neo4j中使用锁来确保数据一致性和隔离级别。它们不仅保护逻辑实体(如节点和关系),而且保护内部数据结构的完整性。
Neo4j支持以下隔离级别:
-
已提交读
默认值。在第一个事务完成之前,读取节点/关系的事务不会阻止另一个事务写入该节点/关系。这种类型的隔离比可序列化隔离级别弱,但提供了显著的性能优势,同时足以满足绝大多数情况。 -
可序列化
节点和关系的显式锁定。使用锁可以通过显式地获取和释放锁来模拟更高级别隔离的效果。例如,如果在公共节点或关系上使用写锁,则在该锁上序列化所有事务,从而产生可序列化隔离级别的效果。
Cypher的更新丢失
在Cypher中,在某些情况下可以获取写锁来模拟改进的隔离。考虑多个并发Cypher查询增加属性值的情况。由于已提交读隔离级别的限制,增量可能不会产生确定的最终值。如果存在直接依赖,Cypher在读取之前自动获取写锁。直接依赖是SET的右侧在表达式中读取依赖属性或在字面映射中读取键值对的值。 类似于 Java 中的 先get 再 +1,再set 回去。
MATCH (n:Example {id: 42})
SET n.prop = n.prop + 1 //调用100次,值并不一定是100
MATCH (n)
SET n += {prop: n.prop + 1}
MATCH (n)WITH n.prop AS p
// ... operations depending on p, producing k
SET n.prop = k + 1
//解决方法:设置显示锁
MATCH (n:Example {id: 42})
SET n._LOCK_ = true
WITH n.prop AS p
// ... operations depending on p, producing k
SET n.prop = k + 1
REMOVE n._LOCK_
事务日志
Neo4j跟踪对每个数据库的所有写操作,以确保数据一致性并支持恢复。
事务日志文件
事务日志文件包含一系列记录,其中包含作为每个事务的一部分对特定数据库所做的所有更改,包括数据、索引和约束。
事务日志有多种用途,包括提供差异备份和支持集群操作。至少,对于任何给定的配置,都会保留最新的非空事务日志。需要注意的是,事务日志与日志监视无关。
事务日志配置是为每个数据库设置的,可以使用以下配置设置进行配置:
-
事务日志位置
默认情况下,一个数据库的日志文件位置为:
/<neo4j-home>/data/transactions/<database-name>。server.directories.transaction.logs.root配置根目录,如果是个相对路径,则相对server.directories.data指定的目录。考虑性能,把日志存储在专用设备上。 -
事务日志预分配
您可以使用参数
db.tx_log.preallocate指定Neo4j是否应该尝试提前预分配逻辑日志文件。缺省情况下,为true。日志预分配通过确保有空间容纳新生成的文件和避免文件级碎片来优化文件系统。此配置设置是动态的,可以在运行时更改。 -
配置事务日志轮询大小
可以使用
db.tx_log.rotate.size指定单个事务日志文件大致可以占用多少空间。缺省情况下,它被设置为256 MiB,这意味着当一个事务日志文件达到这个大小时,它转换创建一个新的。最小可接受值为128K。此配置设置是动态的,可以在运行时更改。此设置影响以下情况下所有检查点策略可以回收的空间大小。要回收给定的文件,事务日志的最新检查点必须存在于另一个文件中。因此,如果您有一个巨大的事务日志,那么很可能您的最新检查点位于同一个文件中,因此无法回收该文件。 -
事务日志保留策略
您可以使用参数
db.tx_log. rotate .retention_policy控制Neo4j保留的事务日志的数量来备份数据库。此配置设置是动态的,可以在运行时更改。默认情况下,它被设置为2天,这意味着Neo4j保留包含2天内提交的任何事务的逻辑日志,并删除只包含超过2天的事务的日志。
不支持手动删除事务日志。
另外,如果有很大的日志,但是从某个点开始之后。在从此checkpoint到保留周期之内,没有任何数据变更。不会触发删除过期的log。可以通过其他数据变更操作,触发,就会自动删除日志文件了。
日志保留策略:
db.tx_log.rotation.retention_policy=true|keep_all:永久保留。不建议db.tx_log.rotation.retention_policy=false|keep_none:只保留最近的非空日志。- 其他具体值:
| Type | Description | Example |
|---|---|---|
files | 日志修剪之后保存的最大文件数 | db.tx_log.rotation.retention_policy=10 files |
size | 最大文件size | db.tx_log.rotation.retention_policy=300M size |
txs / entries | 最大事务数量。与文件大小,时间都无关 | db.tx_log.rotation.retention_policy=500k txs |
hours | 最大小时数 | db.tx_log.rotation.retention_policy=10 hours |
days | 最大天数 | db.tx_log.rotation.retention_policy=30 days |
只有在检查点完成后才调用日志修剪。
检查点和日志修剪(pruning)
检查点是将所有挂起的更新从易失性内存刷新到非易失性数据存储的过程。此操作对于限制在恢复过程中需要重放的事务数量至关重要,特别是对于在数据库不当关闭或崩溃后最小化恢复所需的时间。
类似于关系型数据库的日志,检查点。
消除恢复不再需要的事务日志的过程称为修剪。修剪依赖于检查点。检查点确定哪些日志可以被修剪,并确定修剪是否发生,因为检查点的缺失意味着可用于修剪的事务日志文件集不能更改。因此,只要检查点发生,就会触发修剪。
配置检查点策略通过 db.checkpoint 设置。可选的配置包括:
PERIODIC:默认配置。此策略每10分钟检查一次是否有更改等待刷新,如果有,则执行检查点并随后触发日志修剪。定时策略由db.checkpoint.interval.tx和db.checkpoint.interval.time设置指定,当达到其中一个时触发检查点。VOLUME:当事务日志的大小达到db.checkpoint.interval.volume设置指定的值时,此策略运行检查点。缺省值为250.00MiB。CONTINUOUS:企业版配置。该策略忽略db.checkpoint.interval.tx和db.checkpoint.interval.time设置,并始终运行检查点进程。在检查点完成后立即触发日志修剪,就像在周期性策略中一样。VOLUMETRIC:企业版配置。此策略每10秒检查一次是否有足够的日志量可供修剪,如果有,则触发一个检查点,然后修剪日志。默认情况下,卷被设置为256MiB,但它可以通过设置db.tx_log.rotation.retention_policy和db.tx_log.rotate.size。
配置检查点
观察到事务日志文件比预期的要多,可能是由于检查点发生的频率不够高,或者花费的时间太长。这是一个临时情况,预期和观察到的日志文件数量之间的差距将在下一个成功的检查点上关闭。检查点之间的间隔可以使用以下命令配置:
db.checkpoint.interval.time:默认值15m。检查点间隔时间。db.checkpoint.interval.tx:默认值100000。检查点之间的事务数量。
控制日志修剪
事务日志修剪是指安全、自动地删除旧的、不必要的事务日志文件。要删除一个文件,需要做两件事:
-
文件一定被切换过。
-
最近的日志文件中必须至少发生过一个检查点。
事务日志修剪配置主要处理指定应该保持可用的事务日志的数量。保留超过恢复所需的绝对最小数量的主要原因来自于集群部署和在线备份的需求。由于数据库更新是通过事务日志在集群成员和备份客户端之间进行通信的,因此保留超过最小数量的数据库更新可以只传输增量更改(以事务的形式),而不是传输整个存储文件,这可以节省大量的时间和网络带宽。
修剪操作后剩余的事务日志数量由设置dbms.tx_log.rotate.retention_policy控制。默认值是2天,这意味着Neo4j保留包含2天内提交的任何事务的逻辑日志,并删除只包含超过2天的事务的日志。
拥有最少量的事务日志数据可以加快检查点处理的速度。要配置检查点进程每秒允许使用的IOs数,使用配置参数db.checkpoint.iops.limit。
检查点记录和度量
可以使用 CALL db.checkpoint() 产生检查点。
可以在metrics/目录下看到检查点度量:
neo4j.check_point.duration.csv
neo4j.check_point.total_time.csv
neo4j.check_point.events.csv
附录
参考
管理数据库
docker 设置 :https://neo4j.com/docs/operations-manual/current/docker/ref-settings/
相关文章:

neo4j运维管理
管理数据库 概念 Neo4j 5(从v4.0),可以同时创建和使用多个活动数据库。 DBMS Neo4j是一个数据库管理系统(DBMS),能够管理多个数据库。DBMS可以管理一个独立的服务器,也可以管理集群中的一组服务器。 实例 Neo4j实例是运行Neo4j服务器代…...
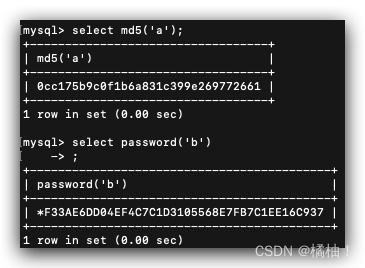
【MYSQL】-函数
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...
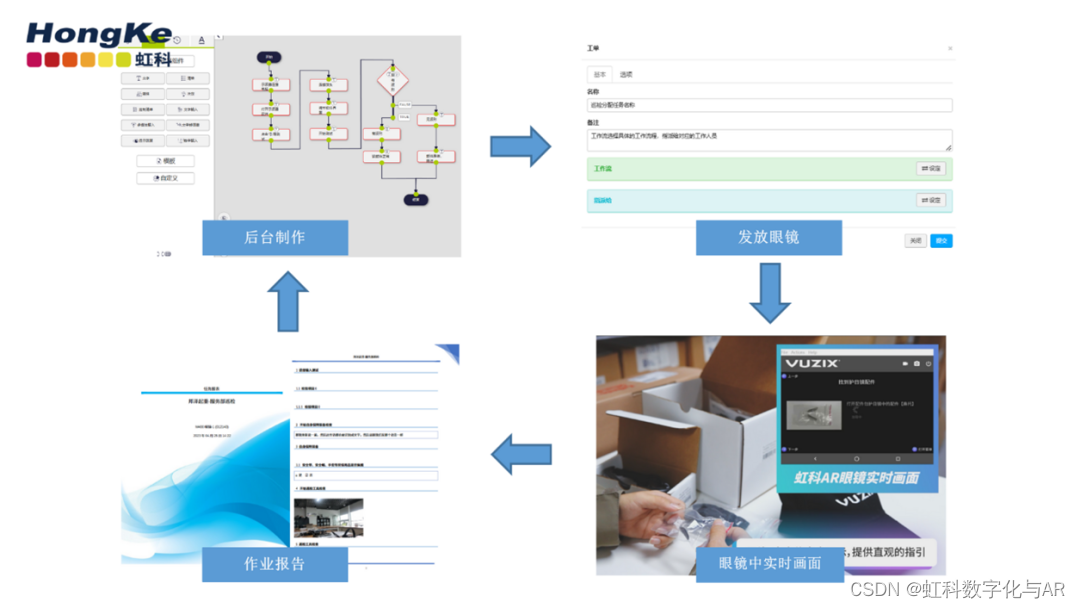
传统船检已经过时?AR智慧船检来助力!!
想象一下,在茫茫大海中,一艘巨型货轮正缓缓驶过。船上的工程师戴着一副先进的AR眼镜,他们不再需要反复翻阅厚重的手册,一切所需信息都实时显示在眼前。这不是科幻电影的场景,而是智慧船检技术带来的现实变革。那么问题…...

JAVA进化史: JDK11特性及说明
JDK 11(Java Development Kit 11)是Java平台的一个版本,于2018年9月发布。这个版本引入了一些新特性和改进,以下是其中一些主要特性。 HTTP Client(标准化) JDK 11引入了一个新的HTTP客户端,用…...
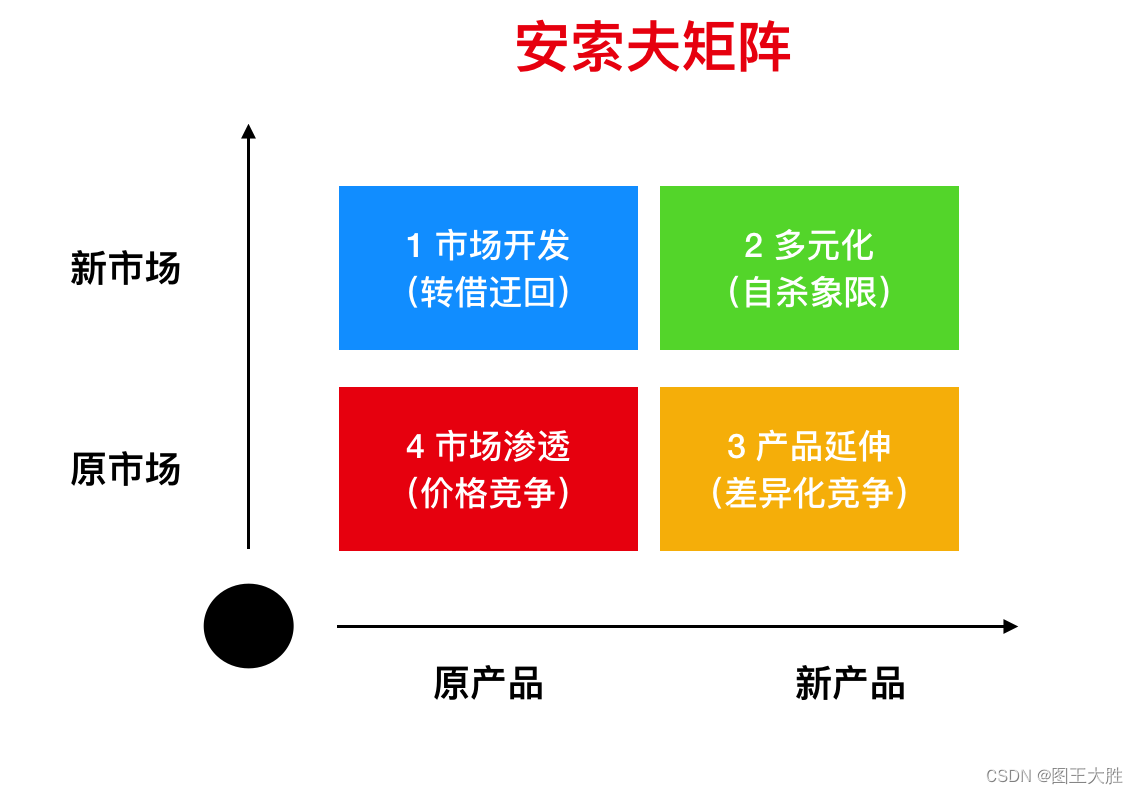
模型 安索夫矩阵
本系列文章 主要是 分享模型,涉及各个领域,重在提升认知。产品市场战略。 1 安索夫矩阵的应用 1.1 江小白的多样化经营策略 使用安索夫矩阵来分析江小白市场战略。具体如下: 根据安索夫矩阵,江小白的现有产品是其白酒产品&…...

性能手机新标杆,一加 Ace 3 发布会定档 1 月 4 日
12 月 27 日,一加宣布将于 1 月 4 日发布新品一加 Ace 3。一加 Ace 系列秉持「产品力优先」理念,从一加 Ace 2、一加 Ace 2V 到一加 Ace 2 Pro,款款都是现象级爆品,得到了广大用户的认可与支持。作为一加 2024 开年之作࿰…...

Vue 框架前导:详解 Ajax
Ajax Ajax 是异步的 JavaScript 和 XML。简单来说就是使用 XMLHttpRequest 对象和服务器通信。可以使用 JSON、XML、HTML 和 text 文本格式来发送和接收数据。具有异步的特性,可在不刷新页面的情况下实现和服务器的通信,交换数据或者更新页面 01. 体验 A…...

3分钟快速安装 ClickHouse、配置服务、设置密码和远程登录以及修改数据目录
下面是一个完整的 ClickHouse 安装和配置流程,包括安装 ClickHouse、配置服务、设置密码和远程登录以及修改数据目录。 安装 ClickHouse 安装 YUM 工具包: sudo yum install -y yum-utils添加 ClickHouse YUM 仓库: sudo yum-config-manager…...

PHP8使用PDO对象增删改查MySql数据库
PDO简介 PDO(PHP Data Objects)是一个PHP扩展,它提供了一个数据库访问层,允许开发人员使用统一的接口访问各种数据库。PDO 提供了一种用于执行查询和获取结果的简单而一致的API。 以下是PDO的一些主要特点: 统一接口…...
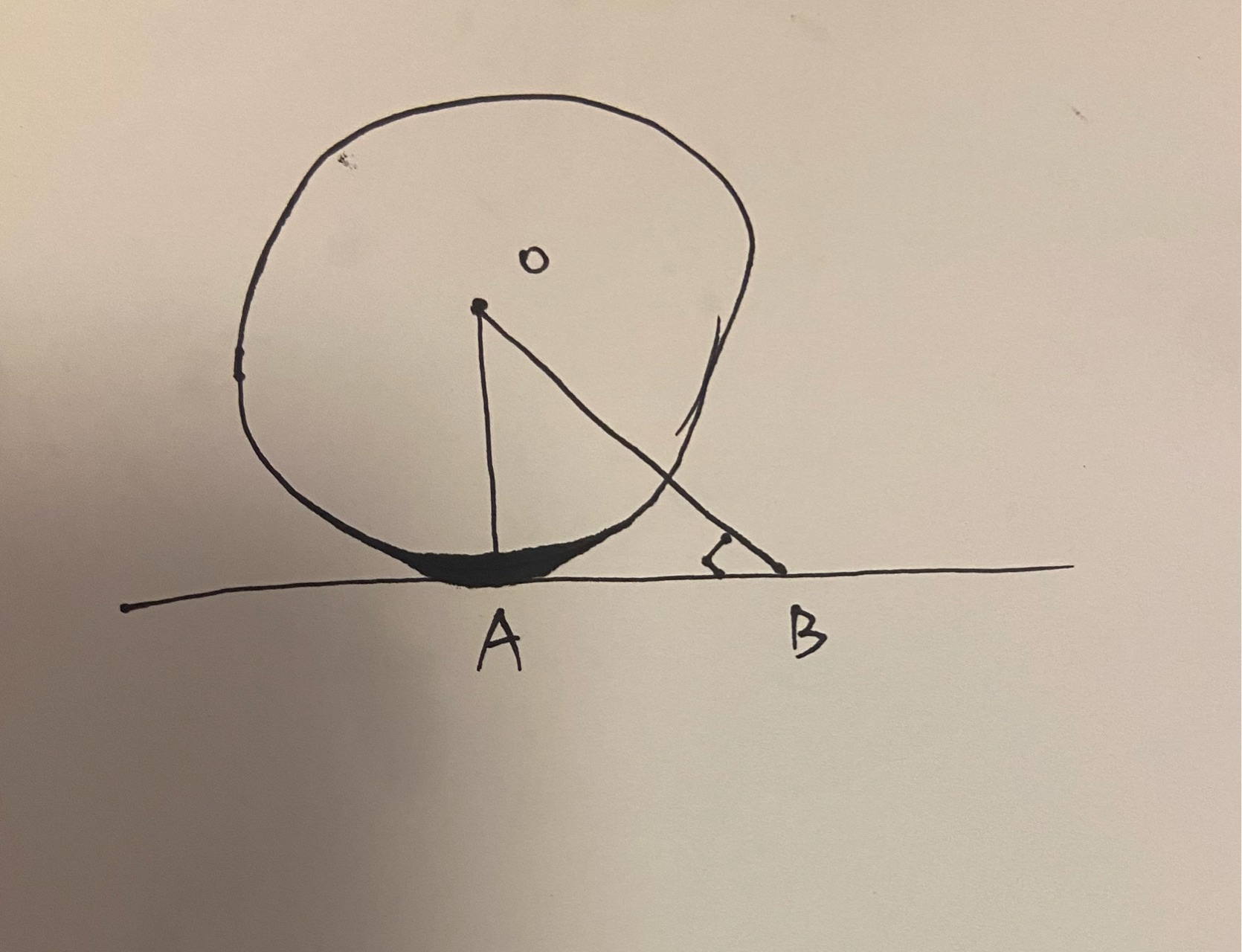
证明:切线垂直于半径
证明: 切线垂直于过切点的半径。 下面是网上最简单的证明方法。 证明: 利用反证法。 如下图所示,直线AB和圆O切于点A,假设OA 不垂直于 AB,而 O B ⊥ A B OB \perp AB OB⊥AB,则 ∠ O B A 90 \angle OB…...
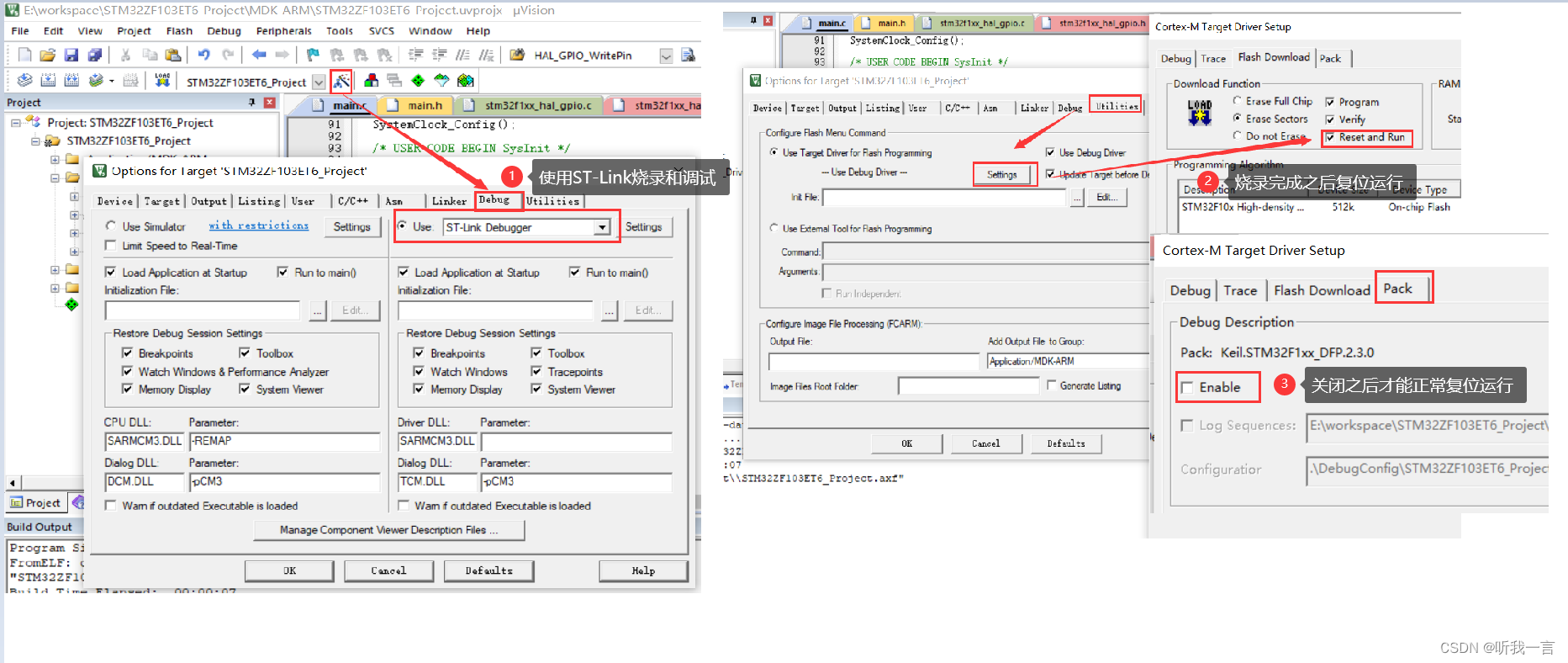
普中STM32-PZ6806L开发板(STM32CubeMX创建项目并点亮LED灯)
简介 搭建一个用于驱动 STM32F103ZET6 GPIO点亮LED灯的任务;电路原理图 LED电路原理图 芯片引脚连接LED驱动引脚原理图 创建一个点亮LED灯的Keil 5项目 创建STM32CubeMX项目 New Project -> 单击 -> 芯片搜索STM32F103ZET6->双击创建 初始化时钟 调试设置 一…...
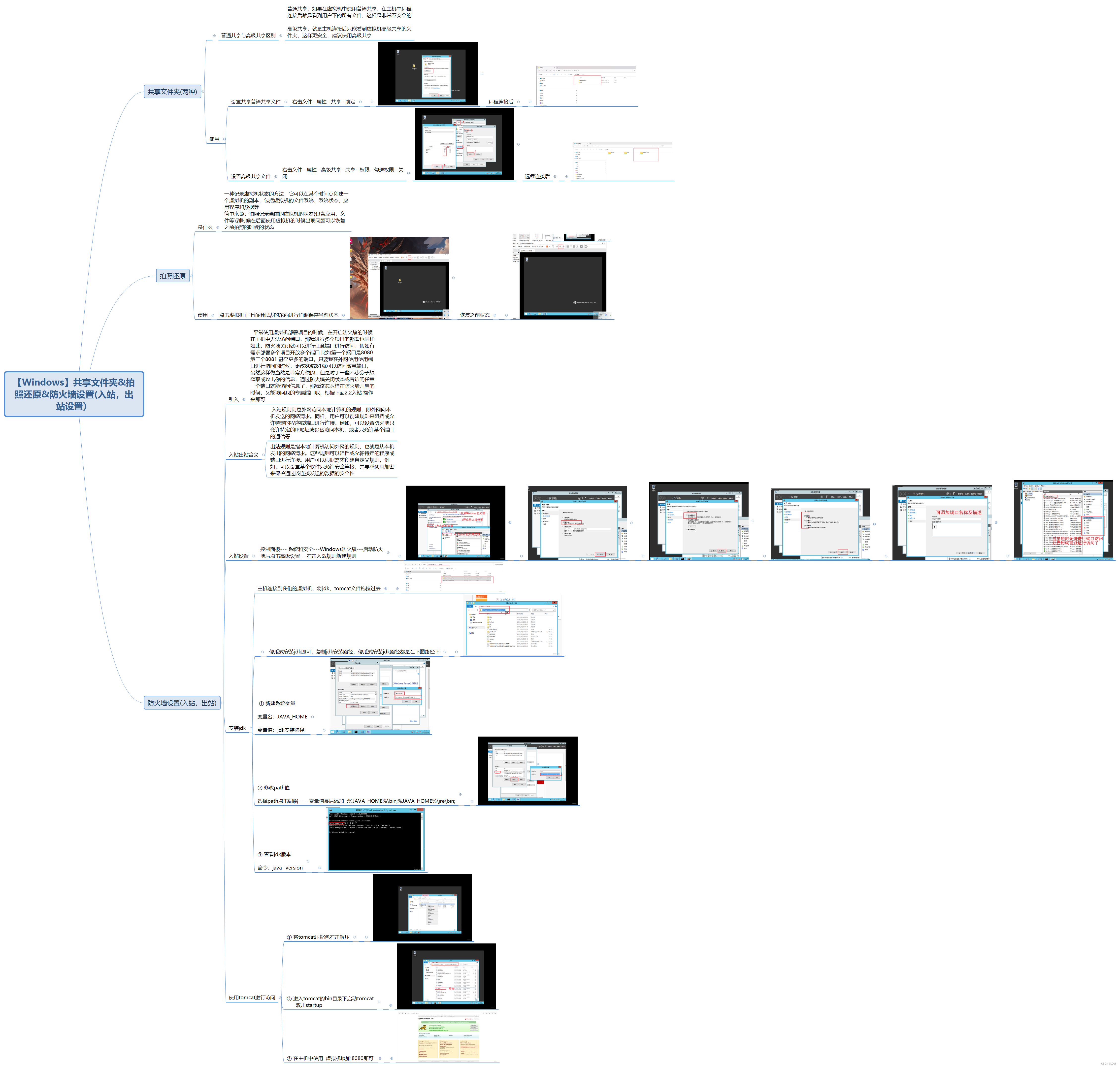
【Windows】共享文件夹拍照还原防火墙设置(入站,出站设置)---图文并茂详细讲解
目录 一 共享文件夹(两种形式) 1.1 普通共享与高级共享区别 1.2 使用 二 拍照还原 2.1 是什么 2.2 使用 三 防火墙设置(入栈,出站设置) 3.1 引入 3.2 入站出站设置 3.2.1入站出站含义 3.3入站设置 3.4安装jdk 3.5使用tomcat进行访…...
1.决策树
目录 1. 什么是决策树? 2. 决策树的原理 2.1 如何构建决策树? 2.2 构建决策树的数据算法 2.2.1 信息熵 2.2.2 ID3算法 2.2.2.1 信息的定义 2.2.2.2 信息增益 2.2.2.3 ID3算法举例 2.2.2.4 ID3算法优缺点 2.2.3 C4.5算法 2.2.3.1 C4.5算法举例 2.2.4 CART算法 2.2.4…...

基于微信小程序的停车预约系统设计与实现
基于微信小程序的停车预约系统设计与实现 项目概述 本项目旨在结合微信小程序、后台Spring Boot和MySQL数据库,打造一套高效便捷的停车预约系统。用户通过微信小程序进行注册、登录、预约停车位等操作,而管理员和超级管理员则可通过后台管理系统对停车…...

再见2023,你好2024
再见2023,你好2024 生活1月 悲伤与治愈2~4月 运动与偏爱5月 体验与美食6月 婚礼与热爱7~8月 就医与别离9~11月 陪伴与暖房12月 体验&新生 运动追剧读书总结 生活 生活是一个修罗场,来世间一场,要经历丰腴有趣的人生。去体验各种滋味&…...

年度总结|存储随笔2023年度最受欢迎文章榜单TOP15-part1
原创 古猫先生 存储随笔 2023-12-31 08:31 发表于上海 回首2023 2-8月份有近半年时间基本处于断更状态 好在8月份后小编没有松懈 (虽然2023年度总结,更像是近4个月总结) 本年度顺利加V啦! 感谢各位粉丝朋友的一路支持与陪伴 …...

微信小程序 手机号授权登录 偶尔后端解密失败
微信小程序wx.login获取code要在手机号授权前触发 <button:id"code":open-type"hasGetPrivacySetting ? getPhoneNumber|agreePrivacyAuthorization : getPhoneNumber"getphonenumber"onGetPhoneNumber"class"btn"click"cli…...

Mysql 容易忘的 sql 指令总结
目录 一、操作数据库的基本指令 二、查询语句的指令 1、基本查询语句 2、模糊查询 3、分支查询 4、 分组查询 5、分组查询 6、基本查询总结: 7、子查询 8、连接查询 三、MySQL中的常用函数 1、时间函数 2、字符串函数 3、聚合函数 4、运算函数 四、表…...

【SD】tile 模型 - 固定衣服 生成人物 ☑
原理1:tile re 生成固定衣服的人物 tile1-1 re1-1 原理2:tile re 生成随机衣服的人物 tile0.5-1 re0.5-1 原理3:更改动作 必须使用衣服LORA 才可以进行穿衣服 测试大模型:###最爱的模型\meinamix_meinaV11.safe…...
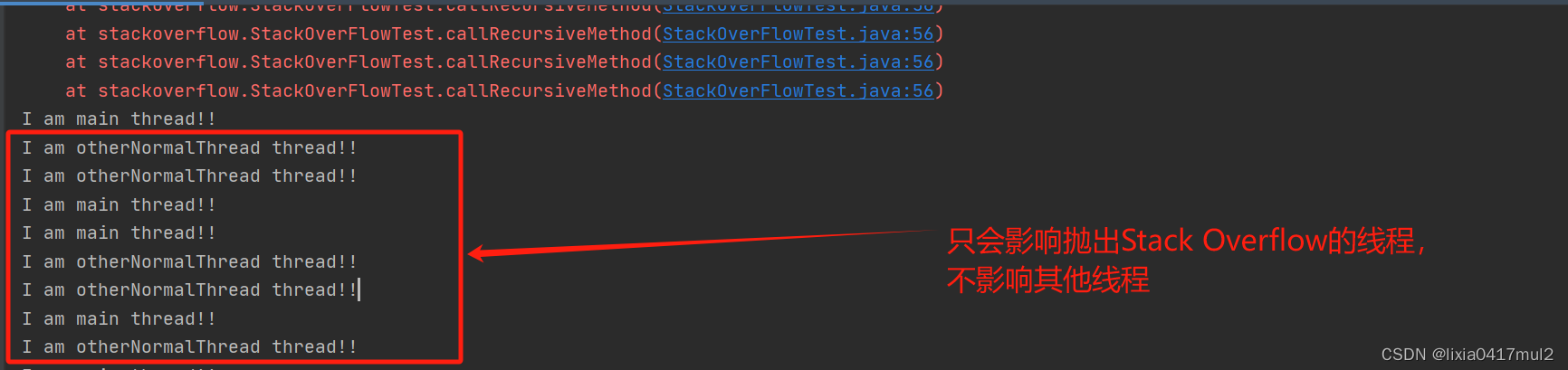
StackOverflowError的JVM处理方式
背景: 事情来源于生产的一个异常日志 Caused by: java.lang.StackOverflowError: null at java.util.stream.Collectors.lambda$groupingBy$45(Collectors.java:908) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at java.util.ArrayL…...
)
软件开发模型详细梳理流程图、优缺点、适用场景(含Scrum和看板)
目录 1 软件开发模型 1.1 瀑布模型 1.2 快速原型模型 1.3 增量模型 1.4 螺旋模型 1.5 敏捷模型 1.5.1 Scrum(开发管理框架) 1.5.2 Kanban(看板) 1 软件开发模型 软件开发模型规定了软件开发应遵循的步骤,是软件…...

2026年防爆门选购指南:这5个厂家秘密,安全专家绝不告诉你!
在2026年的今天,随着工业安全标准的不断提升和公众安全意识的日益增强,防爆门作为守护高危作业区域、化工园区、能源站等关键场所的最后一道物理防线,其重要性不言而喻。然而,面对市场上琳琅满目的防爆门产品,如何甄别…...

Horos医疗影像平台:开源解决方案的技术解析与应用指南
Horos医疗影像平台:开源解决方案的技术解析与应用指南 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos is based up…...
 - 目标管理)
Management By Objectives (MBO) - 目标管理
Management By Objectives {MBO} - 目标管理ReferencesManagement by objectives (MBO), also known as management by results (MBR), was first popularized by Peter Drucker in his 1954 book The Practice of Management. 目标管理 (MBO),也称为结果管理 (MBR)…...

读懂 SAP 中的 tuning object:把性能优化从业务对象中解耦出来
在很多 ABAP 项目里,开发人员一谈性能优化,脑海里浮现的往往是 SQL Trace、索引、Hint 或者代码重写。可是在 SAP 官方的数据建模体系里,还存在一类很容易被忽略、却非常有工程价值的对象,那就是 tuning object。它并不直接承载业务语义,也不是拿来定义字段、关联和行为逻…...

PocketLCD终极指南:如何打造带充电宝功能的便携显示器
PocketLCD终极指南:如何打造带充电宝功能的便携显示器 【免费下载链接】PocketLCD 带充电宝功能的便携显示器 项目地址: https://gitcode.com/gh_mirrors/po/PocketLCD PocketLCD是一款创新的便携显示器解决方案,将高清显示与充电宝功能完美结合&…...

开源长文本大模型落地指南:GLM-4-9B-Chat-1M在vLLM上的GPU优化部署
开源长文本大模型落地指南:GLM-4-9B-Chat-1M在vLLM上的GPU优化部署 1. 开篇:为什么选择GLM-4-9B-Chat-1M? 如果你正在寻找一个既能处理超长文本,又支持多语言对话的开源大模型,GLM-4-9B-Chat-1M绝对值得关注。这个模…...
(论文速读)Funnel-Transformer: 过滤掉顺序冗余的高效语言处理
论文题目:Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing(过滤掉顺序冗余的高效语言处理)会议:NeurIPS 2020摘要:随着语言预训练的成功,人们迫切希望开发出更…...

No.378 S7-200PLC程序MCGS组态基于MCGS与PLC的恒温控制设计加热
No.378 S7-200PLC程序MCGS组态基于MCGS与PLC的恒温控制设计加热 手把手搞个恒温箱:当MCGS遇上S7-200PLC 最近在车间折腾一个恒温控制系统,用S7-200 PLC做底层控制,MCGS当人机界面。这组合就像“老坛酸菜配泡面”——经典又实用。今天把实现过…...

基于Python的代驾管理系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在开发一套基于Python的代驾管理系统,以满足现代城市交通中代驾服务的需求。具体研究目的如下: 首先,通过构建一套完…...