1.决策树
目录
1. 什么是决策树?
2. 决策树的原理
2.1 如何构建决策树?
2.2 构建决策树的数据算法
2.2.1 信息熵
2.2.2 ID3算法
2.2.2.1 信息的定义
2.2.2.2 信息增益
2.2.2.3 ID3算法举例
2.2.2.4 ID3算法优缺点
2.2.3 C4.5算法
2.2.3.1 C4.5算法举例
2.2.4 CART算法
2.2.4.1 Gini指数(基尼指数)
2.2.4.2 Cart算法 相关公式
2.2.4.3 Cart算法举例
3. 未完待续。。。
4. 本文涉及的代码
1. 什么是决策树?
决策树分类的思想类似于找对象。
想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女孩决定是否见男孩的一个过程,就像一个树形结构,只不过是反正的树, 数学上或者机器学习里的树,根在最上方
最上方的为树的根节点,下面的都是子节点
像下图的橙色的部分,下面在没有往下的结点的叫叶子节点
如果一颗树每个节点下面最多只有两个节点就属于二叉树
下图的就是一个非二叉树( 到收入下面有三个节点)
上图完整表达了这个女孩决定是否见一个约会对象的策略,
其中绿色节点表示判断条件,
橙色节点表示决策结果,
箭头表示在一个判断条件在不同情况下的决策路径,
图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,
如果将所有条件量化,则就变成真正的决策树了。
有了上面直观的认识,我们可以正式定义决策树了:决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节
点,将叶子节点存放的类别作为决策结果可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支
生物学以及商业等诸多领域。决策树的主要优势就在于数据形式非常容易理解。决策树算法能够读取数据集合,构建类似于上面的决策树,决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。专家系统中经常使用决策树,而且决策树给出结果往往可以匹敌在当前领域具有几十年工作经验的人类专家
2. 决策树的原理
2.1 如何构建决策树?
首先,例如上方的图,我们可以分析到,我们要先选择 判断条件,
例如有些女孩找男朋友的第一个条件考虑年龄而有的考虑收入有的还考虑长相等等,所以这就是构造决策树的第一个关键的点:判断条件的顺序,
有了判断条件之后,怎么判断这个节点的分裂,例如,年龄这个判断条件,是按照30岁分还是按照什么分,符合这个条件是一个节点,不符合这个判断条件的是另外一个节点,这就是构造决策树的第二个关键的点:节点分裂的界限或者说节点分裂的定义和分类
构造决策树关键步骤是分裂属性,所谓分裂属性就是在某个节点处,按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能的“纯”,尽可能“纯” 就是尽量让一个分裂子集中待分类项属于同一类别
2.2 构建决策树的数据算法
2.2.1 信息熵
有了刚说的两个关键点,对于这个两个关键点的选择就有点困难,所以需要具体的算法来做
建决策树的数据算法有很多
ID3算法
C4.5算法
CART算法
.....
等等
这里面就牵扯了信息论中的信息熵 有关信息熵可参考(可以点开全部回答,然后搜索 阅读 ,或者自行查看 )
信息熵是什么? - 知乎原创文章,一家之言。转载请注明出处。个人公众号:follow_bobo机器学习入门:重要的概念---信息熵(Shan…
https://www.zhihu.com/question/22178202/answer/265757803
信息熵的数学公式:
2.2.2 ID3算法
ID3算法算的是信息增益
2.2.2.1 信息的定义
熵定义为信息的期望值,在明确这个概念之前,我们必须知道信息的定义,如果待分类的事务划分在多个分类之中,则符合X的信息定义为:
其中p(x)是选择该分类的概率
为了计算熵,我们需要计算所有类别所有可能的信息期望值,通过下面的公式得到:
其中n 是分类的数目
在决策树当中,设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi 表示第i个类别在整个训练元组出现的概率,可以用属于此类别元素的数量除以训练元组元素总数作为估计。
熵的实际意义表示是D中元组的类标号所需要的平均信息量
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
2.2.2.2 信息增益
ID3算法 利用 信息增益来决定优先使用哪个特征进行分裂
先用没有进行任何属性分类的时候,计算一个信息熵
再选其中的某一个特征进行分裂构造决策树,再计算一个信息熵,具体用哪个特征来计算,要看哪个特征计算出来的信息熵大,就用哪个,因为这样算出来的值越大相减之后就消除了原来数据里面最大的不确定性
这两个信息熵之间会有一个差值, 这两个信息熵之差,得到的值叫做信息增益
2.2.2.3 ID3算法举例
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂,
如下图假设训练集合包含10条数据,预测一下,社交网站上的账号是否真实的账号
根据日志密度,好友密度,是否使用真是头像等(这些都为特征)来预测
代表的含义: s 小,m中等,l 大
先完成构建决策树其中一个关键点:首先用那个特征进行分裂
计算思路:
1⃣️ 先计算没有使用任何特征对账号是否真实的计算的信息熵
2⃣️ 再算随便使用一个特征对账号是否真实的计算的信息熵
代码如下:(使用 jupyter notebook)
import pandas as pd import numpy as np# 计算图中的信息熵,确定一个分类的特征 # D 就是我们的原始数据 # 先计算未使用任何特征的进行分类的信息熵(所以只需关心账号是否真实这一列) # 账号是否真实: 有两种情况,分别为 yes no, yes数量为7(概率为0.7),no的数量为3(概率为0.3) # 根据信息熵公式: info_D = -(0.7 * np.log2(0.7) + 0.3 * np.log2(0.3)) info_D # 0.8812908992306927使用 日志密度 对账号是否真实的信息熵
使用公式# 使用 日志密度 对账号是否真实的信息熵 使用公式 # j 就是 3(因为日志密度有三种情况,s,l,m) # s 三个(0.3),对应账号是否真实列,2个no, 1个yes # l 三个(0.3), 对应账号是否真实列,0个no, 3个yes # m 四个(0.4), 对应账号是否真实列,1个no, 3个yes # s情况中对日志密度划分的信息熵 = s 的 概率 ✖️ s 中对账号是否真实的信息熵 = 0.3 * ((-1/3) * np.log2(1/2) + (-2/3) * np.log2(2/3)) # 同理 l = 0.3 * (-1 * log2(1)) # 同理 m = info_D_Log = 0.3 * ((-1/3) * np.log2(1/3) + (-2/3) * np.log2(2/3)) + 0.3 * (-1 * np.log2(1)) + 0.4 * ((-1/4) * np.log2(1/4) + (-3/4) * np.log2(3/4)) info_D_Log# 使用 日志密度 进行划分的信息增益 info_D - info_D_Log # 0.2812908992306927# 使用 好友密度 对账号是否真实的信息熵 # s 4个(0.4),对应账号是否真实列,3个no, 1个yes # m 4个(0.4), 对应账号是否真实列,0个no, 4个yes # l 2个(0.2), 对应账号是否真实列,0个no, 2个yes info_D_F = 0.4 * ((-3/4) * np.log2(3/4) + (-1/4) * np.log2(1/4)) + 0 + 0 info_D_F # 0.32451124978365314# 使用 好友密度 进行划分的信息增益 info_D - info_D_F # 0.5567796494470396# 使用 是否使用真实头像 对账号是否真实的信息熵 # no 5个 2个no,3个yes # yes 5个 1个no,4个yes info_D_H = 0.5 * ((-2/5) * np.log2(2/5) + (-3/5) * np.log2(3/5)) + 0.5 * ((-1/5) * np.log2(1/5) + (-4/5) * np.log2(4/5)) info_D_H # 0.8464393446710154# 使用 是否使用真实头像 进行划分的信息增益 info_D - info_D_H # 0.034851554559677256根据上述的运算结果,可以看到, 使用 好友密度 进行划分的信息增益 的 值最大 ,所以 我们就用好友密度这个特征来构建决策树
再完成构建决策树另外一个关键点:首先用那个特征进行分裂节点分裂的界限或者说节点分裂的定义和分类, 而这些我们不需要关心,ID3算法会帮我们做好,只要能确定出来用哪个特征即可
分裂属性分为三种不同的情况:
- 属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
- 属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
- 属性是连续值。此时确定一个值作为分裂点split_point,
按照>split_point和<=split_points生成两个分支。离散值即 例子中的 s,m,l,这种就是有三个划分,而连续值类似年龄这种连续值,29,30,31等
2.2.2.4 ID3算法优缺点
- 优点:简单、时间复杂度、时间复杂度都不高
- 缺点:数据中大量的离散型的数据,会对分裂造成误差
2.2.3 C4.5算法
因为ID3算法在对于离散型特征的处理不好,引入C4.5算法
C4.5算法,计算的是信息增益率
计算步骤:
- 先计算信息增益
- 再除以这个特征本身的信息熵
2.2.3.1 C4.5算法举例
信息增益,上面ID3算法已经计算出来,可以直接使用, 代码如下
2.2.4 CART算法
2.2.4.1 Gini指数(基尼指数)
由上面的内容我们已经知道,决策树的核心就是寻找纯净的划分,因此引入了纯度的概念。在属性选择上,我们是通过统计“不纯度”来做判断的,ID3 是基于信息增益做判断,C4.5 在 ID3 的基础上做了改进,提出了信息增益率的概念。实际上 CART 分类树与 C4.5 算法类似,只是属性选择的指标采用的是基尼指数。
基尼指数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。所以 CART 算法在构造分类树的时候,会选择基尼系数最小的属性作为属性的划分。
在决策树Cart算法中用Gini指数来衡量数据的不纯度或者不确定性
2.2.4.2 Cart算法 相关公式
在分类问题中,样本属于第 i 类的概率为
经过特征a分割之后集合D的不确定性,基尼指数越大,不确定性越大,因此我们需要寻找基尼指数越小的特征作为节点
2.2.4.3 Cart算法举例
3. 本文涉及的代码
https://download.csdn.net/download/wei18791957243/88660903
https://download.csdn.net/download/wei18791957243/88664136







相关文章:
1.决策树
目录 1. 什么是决策树? 2. 决策树的原理 2.1 如何构建决策树? 2.2 构建决策树的数据算法 2.2.1 信息熵 2.2.2 ID3算法 2.2.2.1 信息的定义 2.2.2.2 信息增益 2.2.2.3 ID3算法举例 2.2.2.4 ID3算法优缺点 2.2.3 C4.5算法 2.2.3.1 C4.5算法举例 2.2.4 CART算法 2.2.4…...

基于微信小程序的停车预约系统设计与实现
基于微信小程序的停车预约系统设计与实现 项目概述 本项目旨在结合微信小程序、后台Spring Boot和MySQL数据库,打造一套高效便捷的停车预约系统。用户通过微信小程序进行注册、登录、预约停车位等操作,而管理员和超级管理员则可通过后台管理系统对停车…...

再见2023,你好2024
再见2023,你好2024 生活1月 悲伤与治愈2~4月 运动与偏爱5月 体验与美食6月 婚礼与热爱7~8月 就医与别离9~11月 陪伴与暖房12月 体验&新生 运动追剧读书总结 生活 生活是一个修罗场,来世间一场,要经历丰腴有趣的人生。去体验各种滋味&…...

年度总结|存储随笔2023年度最受欢迎文章榜单TOP15-part1
原创 古猫先生 存储随笔 2023-12-31 08:31 发表于上海 回首2023 2-8月份有近半年时间基本处于断更状态 好在8月份后小编没有松懈 (虽然2023年度总结,更像是近4个月总结) 本年度顺利加V啦! 感谢各位粉丝朋友的一路支持与陪伴 …...

微信小程序 手机号授权登录 偶尔后端解密失败
微信小程序wx.login获取code要在手机号授权前触发 <button:id"code":open-type"hasGetPrivacySetting ? getPhoneNumber|agreePrivacyAuthorization : getPhoneNumber"getphonenumber"onGetPhoneNumber"class"btn"click"cli…...

Mysql 容易忘的 sql 指令总结
目录 一、操作数据库的基本指令 二、查询语句的指令 1、基本查询语句 2、模糊查询 3、分支查询 4、 分组查询 5、分组查询 6、基本查询总结: 7、子查询 8、连接查询 三、MySQL中的常用函数 1、时间函数 2、字符串函数 3、聚合函数 4、运算函数 四、表…...

【SD】tile 模型 - 固定衣服 生成人物 ☑
原理1:tile re 生成固定衣服的人物 tile1-1 re1-1 原理2:tile re 生成随机衣服的人物 tile0.5-1 re0.5-1 原理3:更改动作 必须使用衣服LORA 才可以进行穿衣服 测试大模型:###最爱的模型\meinamix_meinaV11.safe…...
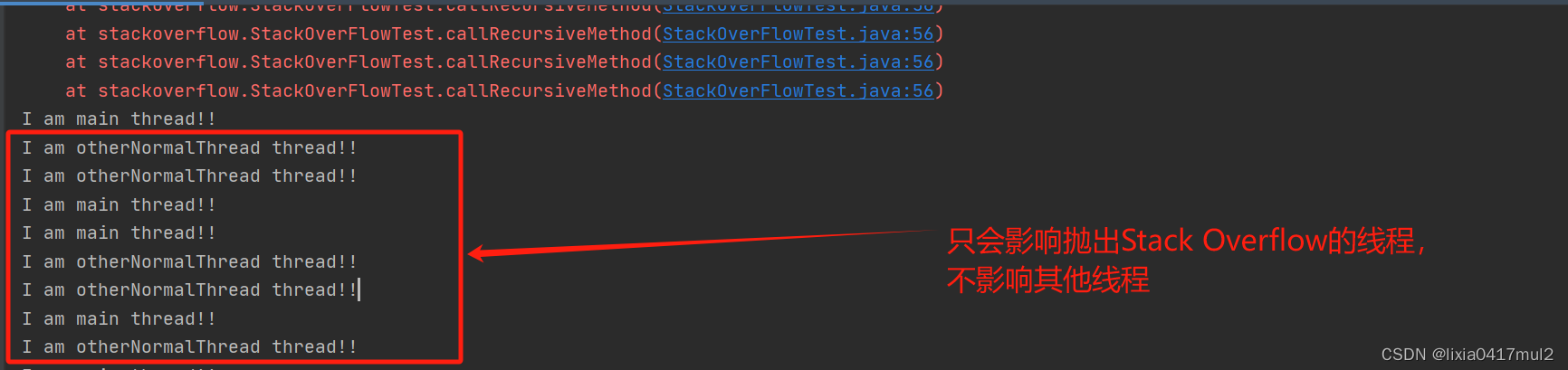
StackOverflowError的JVM处理方式
背景: 事情来源于生产的一个异常日志 Caused by: java.lang.StackOverflowError: null at java.util.stream.Collectors.lambda$groupingBy$45(Collectors.java:908) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at java.util.ArrayL…...

基于DFA算法实现敏感词过滤
何为DFA DFA,全称为Deterministic Finite Automaton,即确定有穷自动机、确定有限状态自动机或确定有限自动机 对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态࿰…...
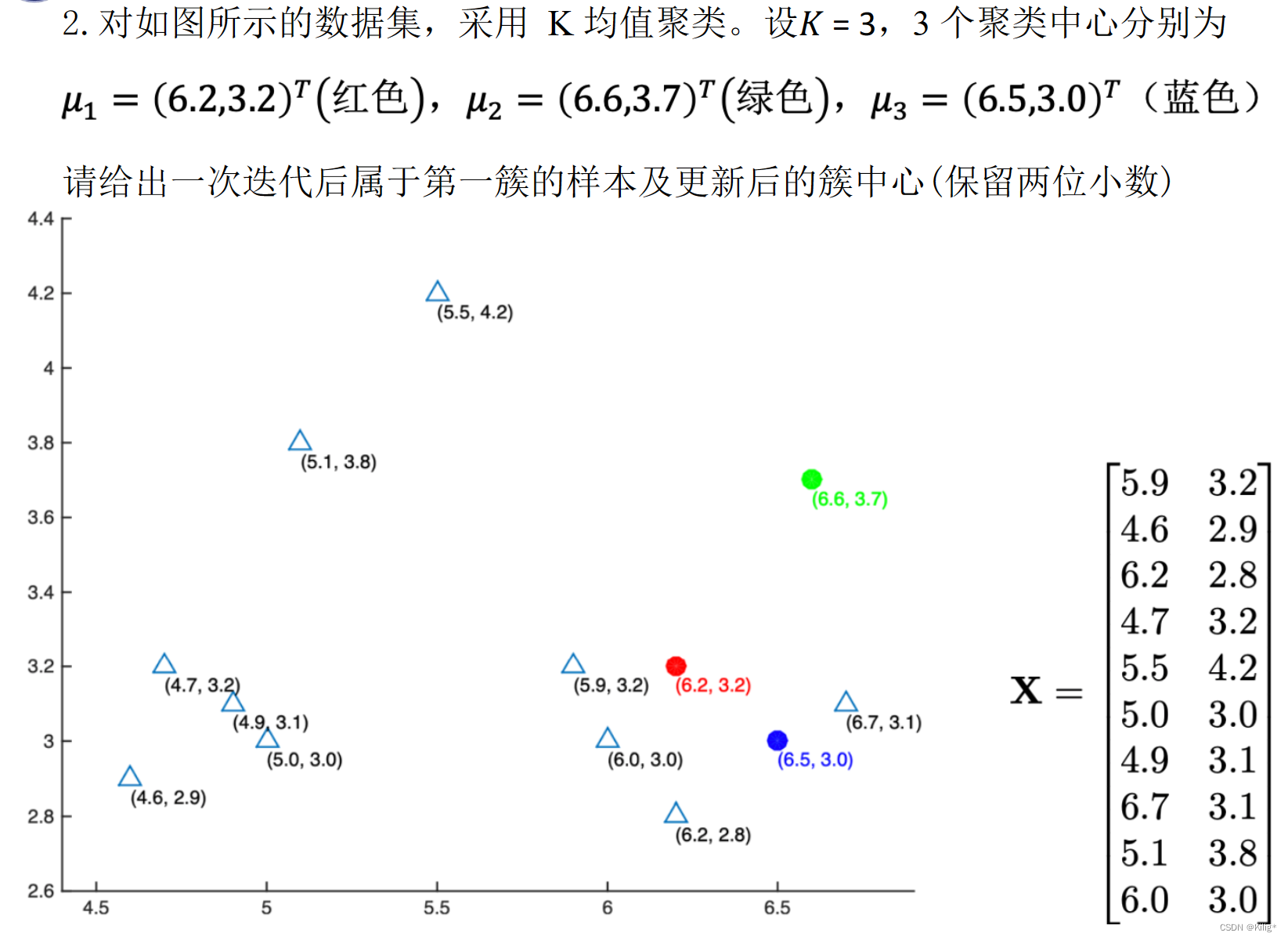
模式识别与机器学习-无监督学习-聚类
无监督学习-聚类 监督学习&无监督学习K-meansK-means聚类的优点:K-means的局限性:解决方案: 高斯混合模型(Gaussian Mixture Models,GMM)多维高斯分布的概率密度函数:高斯混合模型ÿ…...

Python中property特性属性是什么
在Java中,通常在类中定义的成员变量为私有变量,在类的实例中不能直接通过对象.属性直接操作,而是要通过getter和setter来操作私有变量。 而在Python中,因为有property这个概念,所以不需要写getter和setter一堆重复的代…...
vue3 全局配置Axios实例
目录 前言 配置Axios实例 页面使用 总结 前言 Axios 是一个基于 Promise 的 HTTP 客户端,用于浏览器和 Node.js 环境。它提供了一种简单、一致的 API 来处理HTTP请求,支持请求和响应的拦截、转换、取消请求等功能。关于它的作用: 发起 HTTP …...

EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.【EI级】 Matlab实现TCN-BiGRU-Mult…...

WeNet语音识别分词制作词云图
在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错 介绍 本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代码…...
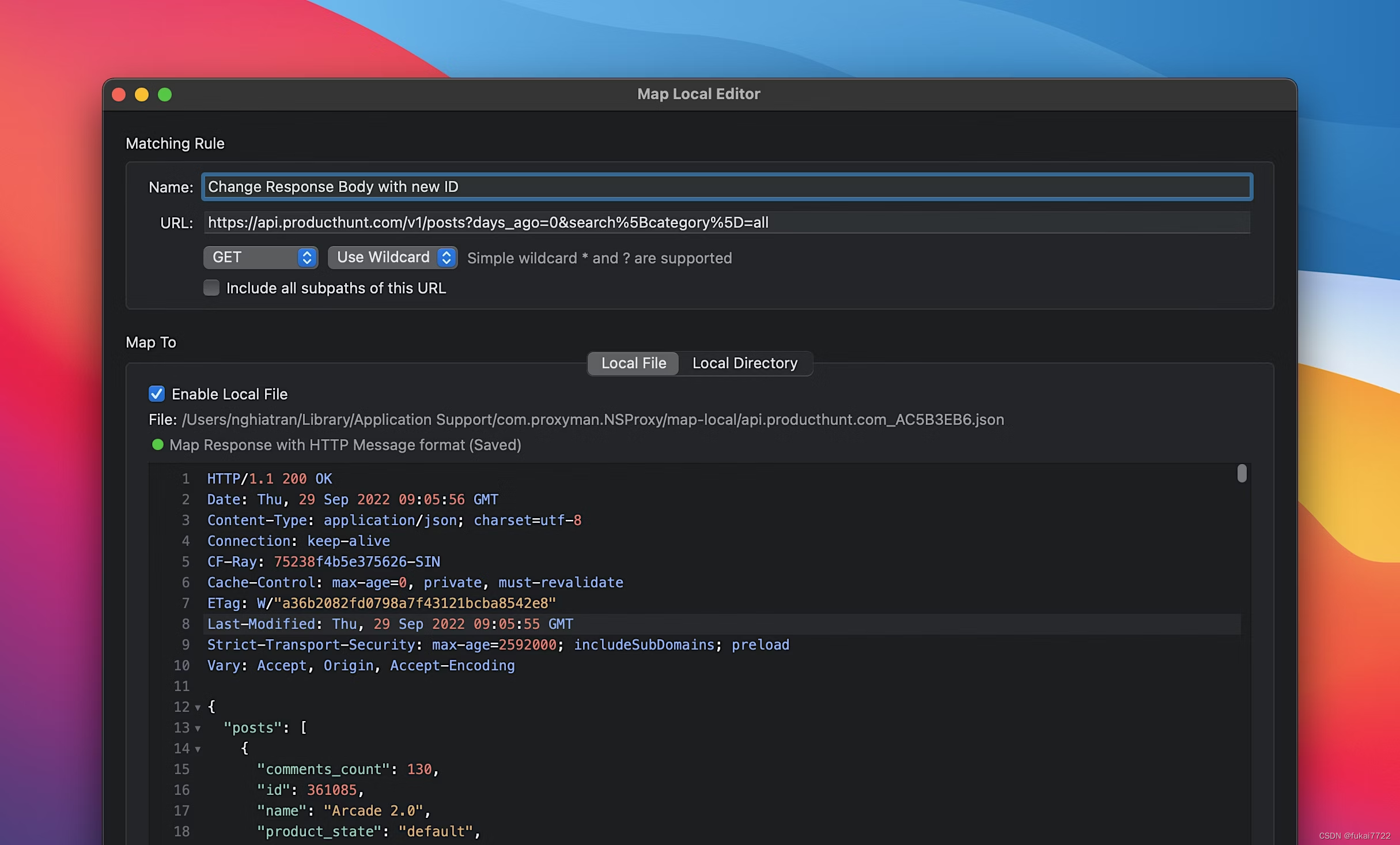
Proxyman:现代本地Web调试代理工具
1. 简介 1.1 什么是Proxyman? Proxyman是一款专为macOS设计的现代本地Web调试代理工具,它不仅支持macOS平台,还能无缝地与iOS和Android设备进行集成。作为一个网络调试工具,Proxyman的设计旨在提供高性能、直观且功能丰富的解决…...

k8s中DaemonSet实战详解
一、DaemonSet介绍 DaemonSet 的主要作用,是在 Kubernetes 集群里,运行一个 Daemon Pod。DaemonSet 只管理 Pod 对象,然后通过 nodeAffinity 和 Toleration 这两个调度器参数的功能,保证了每个节点上有且只有一个 Pod。 二、Daem…...

信号处理设计模式
问题 如何编写信号安全的应用程序? Linux 应用程序安全性讨论 场景一:不需要处理信号 应用程序实现单一功能,不需要关注信号 如:数据处理程序,文件加密程序,科学计算程序 场景二:需要处理信…...
Linux权限的基本理解
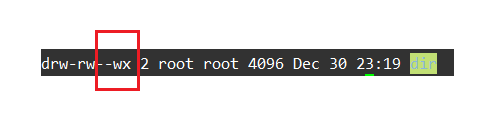
一:🚩Linux中的用户 1.1🥦用户的分类 🌟在Linux中用户可以被分为两种用户: 超级用户(root):可以在Linux系统中做各种事情而不被约束普通用户:只能做有限的事情被权限约束 在实际操作时超级用户的命令提示符为#,普通用户的命令提示符为$,可…...

AI人工智能大模型讲师叶梓《基于人工智能的内容生成(AIGC)理论与实践》培训提纲
【课程简介】 本课程介绍了chatGPT相关模型的具体案例实践,通过实操更好的掌握chatGPT的概念与应用场景,可以作为chatGPT领域学习者的入门到进阶级课程。 【课程时长】 1天(6小时/天) 【课程对象】 理工科本科及以上࿰…...

nat地址转换
原理 将内网地址转换成外网地址 方式 掌握动态NAT的配置方法 掌握Easy IP的配置方法 掌握NAT Server的配置方法 实验 r1 r2 是内网 ar1 ip地址 ip add ip地址 掩码 ip route-static 0.0.0.0 0 192.168.1.254 默认网关 吓一跳网关 相等于设置了网关 ar2 …...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...