【Java开发岗面试】八股文—数据库MySQLRedis
声明:
- 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。
- 本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试技巧等等,如有建议,可以友好指出,感谢,我也会不断完善。
- 想了解我个人情况的,可以关注我的B站账号:东瓜Lee
文章目录
- MySQL
- Redis
MySQL
B树:
是一种多叉路平衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。
以一颗最大度数(max-degree) 为5(5阶)的b-tree为例, 那这个B树每个节点最多存储4个key

B+树:
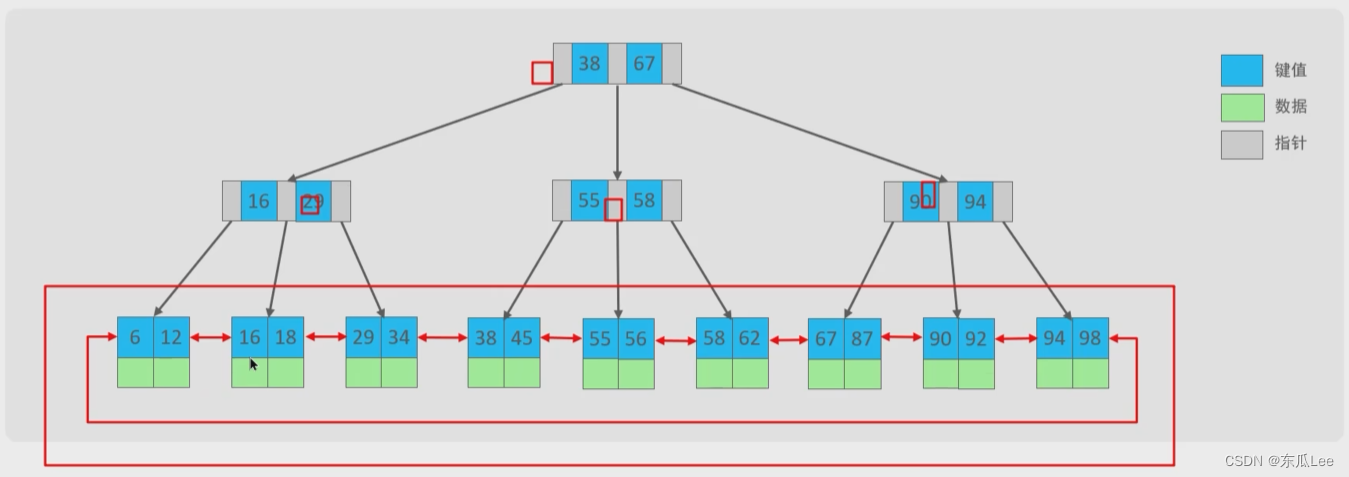
B+Tree是在BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+ Tree实现其索引结构。
非叶子结点上不存储数据,只存储指针,叶子结点上存储数据(叶子结点之间是用双向指针进行连接的)
B树和B+树的对比:
①:磁盘读写代价B+树更低,效率更高;
②:查询效率B+树更加稳定;
③: B+树便于扫库和区间查询;
面试题:
-
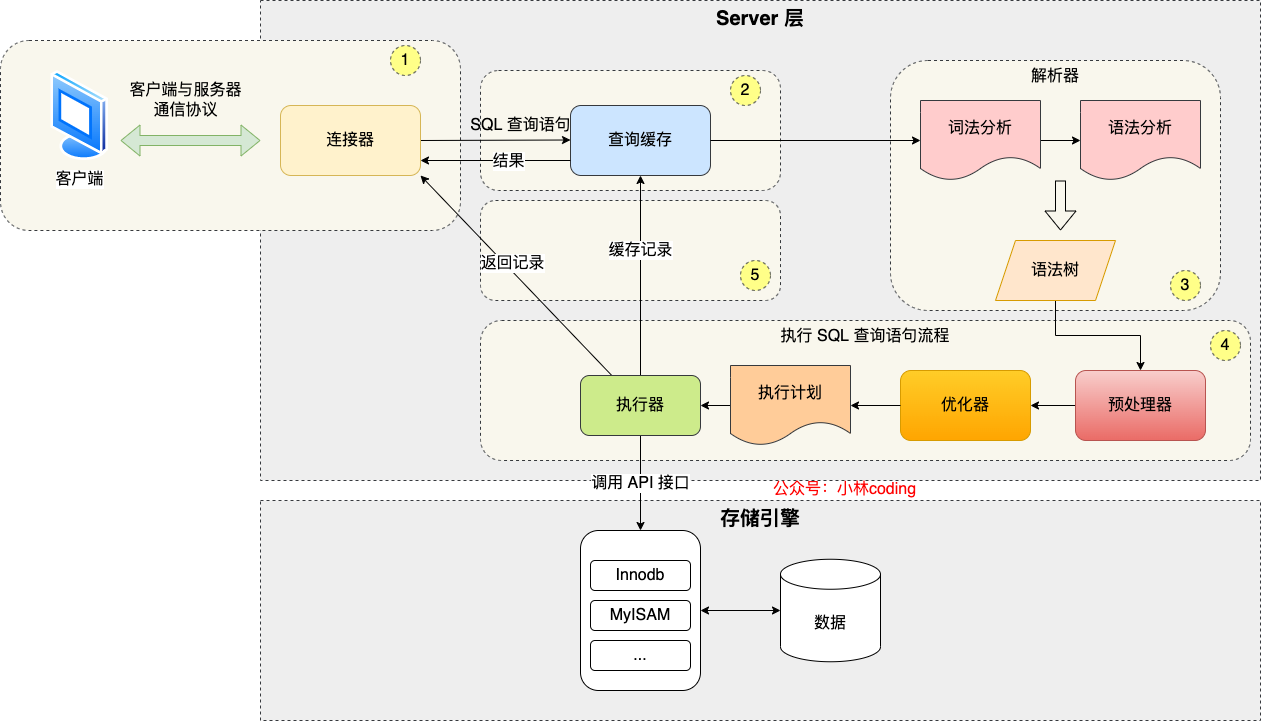
执行一条 SQL 查询语句,期间发生了什么?
-
通过连接器,建立连接、管理连接、校验用户身份;
-
查询缓存:要查询的内容如果在缓存中命中,则直接返回,否则继续往下执行。MySQL 8.0 已删除缓存模块(因此限制比较多,比如数据表更新,缓存就要更新,如果更新操作多,那就很影响效率);
-
解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
-
执行 SQL:执行 SQL 共有三个阶段:
-
预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列。 -
优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
-
执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
-
-
-
在MySQL中,如何定位慢查询?
慢查询是指执行速度比较慢的dql操作,比如聚合查询、多表查询、表的数据量过大、深度的分页查询都会导致慢查询,表现形式就是页面加载很慢or对某个接口的压测响应时间过长
-
使用一些开源工具,比如Arthas(阿尔萨斯)
-
使用MySQL自带的慢查询日志
慢查询日志记录了所有执行时间超过指定参数的所有SQL语句的日志清空,如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf) 中配置如下信息:
- slow_ query_log=1:开始慢查询日志(一般只在调试环境下才开启,生产环境下不开启,因为会损耗一些性能)
- long_ query_time=2:超过2s就是慢sql,就会记录到日志文件中
-
-
那这个SQL语句执行很慢,如何优化呢?
可以采用MySQL自带的分析工具EXPLAIN
- 通过key和key_ len检查是否命中了索引
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
-
了解过索引吗?
-
在数据之外,数据库系统还维护着满足特定查找算法的数据结构(B+树) ,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
-
索引(index) 是帮助数据库高效查询数据 的一种数据结构。
作用:
- 索引能提高数据查询的效率,降低数据库的IO成本。
- 通过索引列对数据进行了排序,降低数据排序的成本。
-
-
索引的底层数据结构了解过嘛?
- mysql默认的存储引擎是innodb,innodb的索引使用B+树实现的。
- B+树的非叶子结点上不存储数据,只存储指针,叶子结点上存储数据。
- B+树便于扫库和区间查询,因为叶子节点是一个用双向链表连接起来的。
其他问题:
-
B+树的查询时间跟树的高度有关,是log(n),如果用hash存储,那么查询时间是O(1),既然hash比B+树更快,为什么mysql用B+树来存储索引呢?
如果只选择一个数据那确实是hash更快,但是数据库中经常会选中多条数据,这时候由于B+树索引是有序的,并且又有链表相连,它的查询效率比hash就快很多了
-
为什么不用红黑树?
树的查询时间跟树的层高有关,层数多一层,磁盘IO就多一次,数据量相同的情况下,红黑树是二叉树,树的层数高,B+树是一棵多叉树,每一层的数据多一些,层数小一些。
-
B树和B+树的对比
- B树:是一种多叉路平衡查找树,相对于二叉树,B树每个节点可以有多个分支,非叶子结点上存储了数据和指针,叶子结点存储了数据。
- B+树:是在B树基础上的一种优化,非叶子结点上不存储数据,只存储指针,叶子结点上存储数据,然后叶子节点是一个用双向链表连接起来的。
- 查询效率B+树更加稳定。
- B+树便于扫库和区间查询。
- 磁盘读写代价B+树更低,效率更高(数据量相同的情况下,B数的层数更高)。
-
什么是聚簇索引什么是非聚簇索引(二级索引)?
- 聚簇索引:将数据存储与索引放到了一块,B+树的叶子节点关联的是当前行的数据,有且只有一个
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE) 索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引, 则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
- 非聚簇索引:将数据与索引分开存储,B+树的叶子节点关联的是对应的主键id,可以存在多个
- 单独给字段创建的索引就是二级索引(比如下面的name)
- 聚簇索引:将数据存储与索引放到了一块,B+树的叶子节点关联的是当前行的数据,有且只有一个

-
什么是回表查询?
通过二级索引找到对应的主键值,到聚集索索引中查找整行数据,这个过程就是回表查询。
-
什么是覆盖索引?
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到(如果不能全部找到,就还要回表查询,就是非覆盖索引)。
-
索引创建的原则有哪些?
聚集索引(主键索引、唯一索引)、非聚集索引(根据业务创建的索引—复合索引)
原则:
- 针对于数据量较大,且查询比较频繁的表建立索引(单表超过10万条数据)。
- 针对于常作为查询条件(where) 、排序(order by)、分组(group by)操作的字段建立索引。
- 索引并不是越多越好,要合理控制数量,太多了维护成本就会增加,效率反而受到影响。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
-
什么情况下索引会失效?
索引就是用来高效查找数据的,如果失效了,那当然就失去使用它的意义的,所以要尽可能的避免索引失效的情况出现,平时定位索引失效可以使用mysql自带的工具EXPLAIN,可以通过看key和key_len字段看是否命中了索引。
一般来说可能的情况有:
- 模糊查询:使用%开头的Like模糊查询会导致索引失效,但是如果是把%放到后面就不会了
- 类型转换:如果在查询中用了某种类型转换,则索引会失效。例如,在查询中将字符串转换为数字(本来应该用字符串的,却用了数字)。
- 函数:如果在查询中使用了函数,例如LOWER或UPPER函数,该函数可能会使索引不再有效,可以建立基于函数的索引。
- 运算:对索引列进行加减乘除等运算操作,会导致索引失效
- 违反最左匹配原则:如果用了联合索引,要遵守最左匹配原则(查找从索引的最左的列开始,并且不能跳过索引中的列),如果不遵守就会索引失效
-
单个索引和联合索引的设计
-
单个索引:就是给某一个字段设置索引
- 一般来说自己设置的索引都是非聚集索引,B+树叶子节点关联的是主键id
- 聚集索引就是默认的主键id or 唯一id or 隐藏字段row_id
-
联合索引:就是将多个字段共同作为索引,比如给某个字段A设置为了非聚集索引,如果要找另一个字段B,就要先找到主键id,再去回表查询找到那个字段B,如果同时把这两个字段AB设置为一个索引,那就不用回表了,效率更高。
要满足一个最左匹配原则(查找从索引的最左的列开始,并且不能跳过索引中的列)
-
-
谈一谈你对SQL优化的经验
-
表的设计可以优化
- 设置合适的数值类型比如(tinyint、int、bigint)
- 设置合适的字符串类型比如(char和varchar) char定长效率高,但是不灵活, varchar可变长度,效率稍低,但是比较灵活
-
索引优化
要按照创建索引的几大原则
-
SQL语句优化
- SELECT语句务必指明字段名称(避免直接使用select *)(防止不必要的回表查询)
- SQL语句要避免造成索引失效的写法
- 避免在where子句中对字段进行表达式操作
-
主从复制、读写分离
如果数据库的使用场景 读的操作比较多的时候,为了避免写的操作所造成的性能影响,可以采用读写分离的架构。
-
分库分表,可能的场景:
- 单张表的数据量超过了百万级别,就要分表
- 单个数据库的性能无法满足业务需求,就要分库
-
-
事务的特性是什么?可以详细说一下吗?
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体 一起向系统提交或撤销,也就是说这些操作 同时成功、同时失败。
事务的四大特性ACID:(可以用转账案例来说)
- 原子性(Atomicity) :事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency) :事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation) :数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability) :事务一旦提交或回滚, 它对数据库中的数据的改变就是永久的。
-
MySQL事务的底层实现原理
事务一组操作的集合,是一个不可分割的工作单位,事务会把所有的操作作为一个整体 一起向系统提交或撤销,也就是说这些操作 同时成功、同时失败。
事务满足四大特性ACID:原子性、一致性、隔离性、持久性
事务的实现原理实际上就是如何保证这四大特性:
- 原子性:也就是要保证同时成功、同时失败,如果失败了意味着要对原本执行成功的操作进行回滚,这依赖于InnoDB存储引擎下的undo log日志文件,undo log日志文件会记录数据的逻辑日志,可以用于回滚操作。
- 一致性:表示数据的完整性约束没有被破坏,这个更多是依赖于业务层面,比如转账业务,一个减少了,一个就需要增加,就可以保证数据的一致性。
- 隔离性:当多个并发事务对数据库进行操作的时候,要保证多个事务之间不受影响,就采用了四大隔离级别来保证,默认是可重复读,可以解决脏读和不可重复读的问题,然后用临键锁和间隙锁也极大程度的解决了幻读的问题。
- 持久性:事务一旦提交,那么对数据的改变一定是永久的,MySQL中采用了缓冲池的机制,当数据变更的时候先更新缓冲池,然后再持久化到数据页,如果数据库发生了宕机,缓冲池的数据还没有同步到数据页,这个时候就可以使用InnoDB存储引擎下的redo log日志文件,它记录了数据更新的物理日志,就可以把数据同步到数据页,保证了持久性。
-
并发的事务会带来哪些问题?
- 脏读:一个事务读到了另外一个事务还没有提交的数据,就是脏读
- 不可重复读:一个事务先后读取同一条记录,但是另一个事务可能在中途把这条记录给改了,那就会出现先后读取的记录不一样,就是不可重复读(重复读不了)
- 幻读:一个事务A按照指定条件查询数据时,发现数据库中没有指定的数据,刚想插入这条数据,然后另一个事务B突然先它一步 向数据库插入了这条数据,事务A再插入的时候就会报错(发现数据竟然存在了,是不是刚才出现了幻觉)
-
如何解决并发事务带来的问题?
使用事务的隔离级别
-
读未提交:脏读、不可重复读、幻读一个也解决不了
-
读已提交:只能解决脏读(不可重复读,幻读解决不了)
-
可重复读:只能解决脏读、不可重复读(幻读解决不了)
-
串行化:脏读、不可重复读、幻读都可以解决
事务的执行是串行的,效率很低,实际开发中肯定要使用并发事务
-
-
MySQL的默认隔离级别是?
- 事务隔离级别越高,虽然数据是更安全了,但是性能就会降低,考虑到性能和数据安全的平衡,默认就是使用可重复读
- 可重复读:只能解决脏读、不可重复读(幻读解决不了)
-
undo log和redo log的区别
- 都属于mysql的日志文件
- mysql中的数据存储被划分为了两个区域:
- 磁盘的数据页(page) :每个页的大小默认为16KB,页中存储的是数据表中的行数据,一张表可能对应多个数据页。
- 缓冲池(buffer pool) :内存中的一个区域,里面可以缓存磁盘上经常操作的数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,再从磁盘上加载并缓存到缓冲池中),可以减少磁盘IO,加快处理速度。
- **redo log:**记录的是事务提交时数据页的物理修改,用来实现事务的持久性,比如数据库服务宕机了,缓冲池中的数据还没来记得保存到磁盘的数据页中,就会发生数据丢失,这个时候就可以使用redo log日志文件来同步数据。
- **undo log:**记录的是逻辑日志,比如执行了一个删除操作,undo log里面就会把删除的数据进行记录,比如执行了一个更新操作,undo log就会记录更新前的记录,当事务回滚时,就通过逆操作恢复到原来的数据(undo log保证了事务的原子性和一致性)。
-
事务中的隔离性是如何保证的呢?
- 排他锁:如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁
- MVCC多版本并发控制
-
MVCC是什么?
MVCC多版本并发控制,可以维护一个数据的多个版本,使得并发事务对数据的读写操作没有冲突。
具体实现主要依赖于数据库记录中的隐式字段、undo log、readView
- 隐式字段:事务id、回滚指针
- undo log:用于回滚的日志文件、有个undo log版本链 记录不同事务修改数据的版本
- readView:解决的是一个事务查询版本选择的问题
-
读写分离是什么?
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
-
MySQL主从复制的原理
MySQL数据库自带主从复制的功能,只需要配置即可。
原理:
- MySQL主从复制的核心就是通过二进制日志,二进制日志(BINLOG) 记录了所有的DDL (数据定义语言)语句和DML (数据操纵语言)语句,不包含数据查询操作
- 主库在执行增删改的写操作时,会把数据变更记录在二进制日志文件Binlog中。
- 从库会调用一个I/O线程读取主库的二进制日志文件Binlog,然后写入到从库的中继日志Relay Log。
- 从库会调用另外一个SQL线程解析中继日志Relay Log的内容,将对数据的操作反映从库上。
-
MySQL 有哪些锁?
根据粒度大小分为三种:
- 全局锁:粒度最大,锁定数据库中所有的表(往往用于数据备份)
- 表级锁:粒度较大
- 表锁:锁住整张数据表,比如
lock tables 表名 ... read/write,显式加锁 - 元数据锁:为了防止DML和DDL冲突,隐式加的锁(系统自己加的锁)
- 意向锁:为了避免加表锁时 一行一行的去查看行锁的加锁情况 带来的性能问题,也是隐式加的锁
- 表锁:锁住整张数据表,比如
- 行级锁:粒度较小
- 行锁:锁住某一行(某一个条记录),对于读已提交rc、可重复读rr 下的隔离级别都支持(用的最多)
- 间隙锁:锁的是记录间的间隙,rr才有
- 临键锁:锁的是当前记录 + 记录前的间隙,rr才有
- 间隙锁和临键锁 主要是为了解决 可重复读隔离级别下 的幻读问题
- 上述锁都是悲观锁
根据性质,可以分为:
- 共享读锁
- 独占写锁
-
说一下innodb 存储引擎下(MySQL)的死锁问题
-
表级锁的死锁
用户A锁住了表1,然后又去访问表2,此时用户B锁住了表2,准备去访问表1,两个用户都是去请求共享资源,然后又不释放现有资源,就形成了一个循环等待的现象,这就是表级锁的死锁。
这种死锁比较常见,解决方法就是在进行数据库的多表操作的时候,尽量按照一定的顺序进行处理,尽量避免同时锁定两个资源。
-
行级锁的死锁
如果在事务中执行了一条没有使用索引的查询,引发了全表扫描,就会把行级锁上升为全表记录锁定(等价于表级锁),多个这样的事务执行后,就很容易产生死锁和阻塞。
解决方法就是 在SQL语句中不要使用太复杂的关联多表的查询
-
-
update是行锁还是表锁?
即可以加行锁也可以加表锁,要分情况考虑,取决于update后面的条件、事务隔离级别等因素
- 如果update后面的where条件 包含了索引列(用了索引),并且只修改一条数据,就加行锁,
- 如果update后面的where条件 不包含索引列(没用索引),就加表锁
-
MySQL的存储引擎 InnoDB 与 MyISAM 有什么区别?
MySQL默认使用的是InnoDB作为存储引擎,具体的区别有几点:
- InnoDB 有事务,MyISAM不支持事务
- InnoDB 可以有外键约束,MyISAM没有外键约束
- InnoDB 支持数据恢复, MyISAM 不支持(InnoDB 可以通过redo log日志文件来恢复数据)
- InnoDB 除了表级锁还支持行级锁,MyISAM 只有表级锁没有行级锁
- MyISAM 的读取速度会比 InnoDB 快,但是在高并发环境下,InnoDB 的性能更好一些(因为 InnoDB 支持行级锁和事务处理,而 MyISAM 不支持),所以如果是非高并发环境 且 读多写少的情况下,MyISAM作为存储引擎 数据库性能会更好一些。
Redis

面试题:
-
谈下你对 Redis 的了解?
Redis 就是远程数据服务,是一个基于内存且支持持久化的高性能 key-value 非关系型数据库,具备以下三个基本特征:
- 多种数据类型(十种数据类型,五种常用的)
- 持久化机制
- 主从同步
-
Redis 支持的数据类型有哪些?
五种常用的数据类型(key都是string,数据类型指定的是对应的value)
- String:这是最简单的数据类型,value就是字符串(比如key为name,value为" ")
- Hash:key对应的value,value本身也是一个键值对(比如key为animal1,value就有多个字段,name=“”,sex=“”,age=“”)
- List:key对应的value是一个list集合,可以保证数据有序,且可以重复(实现队列)
- Set:key对应的value是一个set集合,里面的数据无序,而且不可以重复
- ZSet:key对应的value也是一个set集合,但是集合中的每个元素都有一个权重,元素是按照对应的权重来有序排序的,而且也不可以重复
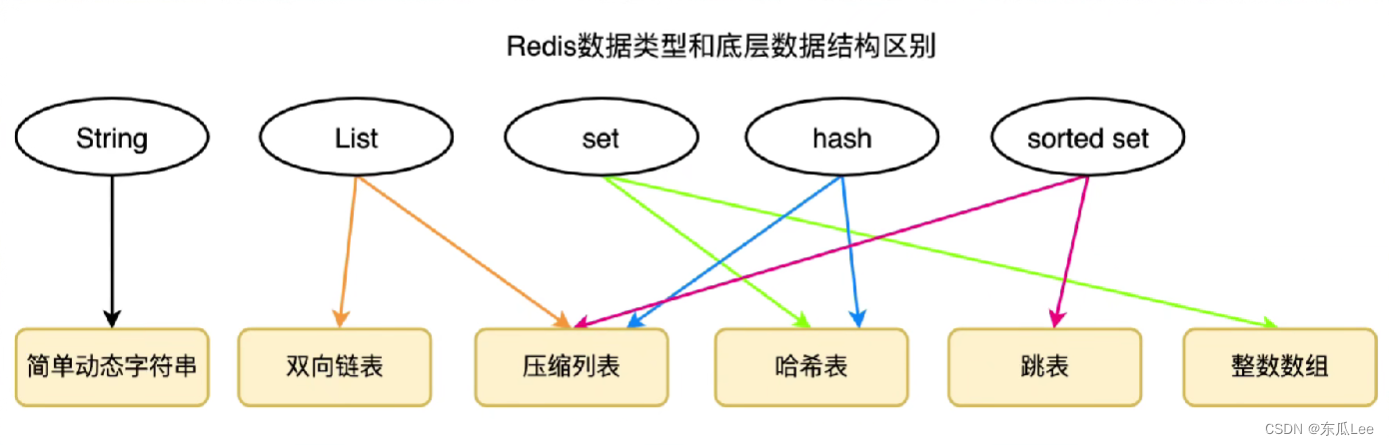
Redis各种数据类型 的底层数据结构:
- String:简单动态字符串
- ZSet:压缩列表、跳表
- Hash:哈希表、压缩列表
- List:双向链表、压缩列表
- Set:哈希表、数组
-
ZSet的底层数据结构是什么?
压缩列表 或者 跳表
-
有序集合中保存的元素数量小于128个 且 有序集合中保存的所有元素的长度小于64字节 的时候使用 压缩列表(ziplist)
- 压缩列表本质上就是一个数组,只不过是它增加了一些标识位而已,比如列表的长度、列表的实际元素个数等等,这样的话,就有利于快速的查找列表的首、尾的节点。
- 但是如果要查找中间的节点,还要要O(n)的来遍历
-
其他时候使用跳表(skiplist)
- 调表在链表的基础上增加了多级索引,过多级索引的转跳,实现了O(logn)的快速查找。
- 使用调表的目的就是为了提高查找效率
- **红黑树也是O(logn)的查找效率,为什么zset是采用的跳表呢?**因为跳表的范围查找效率更高,而且跳表的实现更简单。
-
-
Redis优缺点?
优点:
- 基于内存的,所以读写速度很快
- 基于单线程实现的(但是Redis6.0后增加了多线程),避免了多个线程之间线程切换开销
- 支持多种数据类型
- 支持持久化,可以有效地避免数据丢失问题。
- 支持事务,Redis的所有操作都是原子性的
- 支持主从复制,主节点会自动将数据同步到从节点,可以实现读写分离。
缺点:
- 数据库容量受到内存的限制,不适合用作海量数据的高性能读写,主要局限在较小数据量的操作。
-
Redis 为什么这么快?
- 基于内存的数据库:Redis是使用内存存储的,没有磁盘IO上的开销
- 基于单线程实现的:Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销。
- 具有的高效的数据结构:Redis 每种数据类型底层都做了优化,目的就是为了追求更快的速度。
-
Redis为何选择单线程?
这里的单线程指的是 Redis 网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
- 避免过多的上下文切换开销。程序始终运行在进程中单个线程内,没有多线程切换的场景。
- 避免同步机制的开销:如果 Redis选择多线程模型,需要考虑数据同步的问题,则必然会引入某些同步机制,会导致在操作数据过程中带来更多的开销,增加程序复杂度的同时还会降低性能。
- 实现简单,方便维护:如果 Redis使用多线程模式,那么所有的底层数据结构的设计都必须考虑线程安全问题,那么 Redis 的实现将会变得更加复杂。
-
Redis6.0为何引入多线程?
- 为了解决网络IO的性能瓶颈,增加的多线程只是为了处理网络IO事件,以多线程并行的方式提升网络IO效率。
- Redis6.0的多线程默认是关闭的,需要在redis.conf修改配置才能开启。
-
Redis存在线程安全问题吗?
Redis 一般来说是单线程的,所以是线程安全的。虽然在 Redis 6.0 里面,引入了多线程,但是增加的多线程只是用来处理网络 IO 事件,对于指令的操作执行过程,仍然是由主线程来处理,所以不会存在多个线程 执行操作指令的情况,就还是线程安全的。
如果对指令的执行也采用多线程,那为了解决线程安全问题,需要对数据的操作加锁,增加了复杂度,还影响了性能,性价比不高。
-
Redis中事务和MySQL中事务的区别:
- Redis默认不开启事务;MySQL默认开启事务
- Redis不支持事务回滚,MySQL支持事务回滚(基于undo log日志文件)
- Redis实现事务基于commands队列; MySQL实现事务基于undo log/redo log日志文件
-
Redis的使用场景
- 缓存
- 分布式锁
- 消息队列
-
Java怎么实现简单的缓存(不用redis的话)?
可以使用基于concurrentHashmap的缓存,然后配合上SpringCache框架(不需要单独导入依赖,SpringContext自带的),就可以用注解的方式简化缓存代码实现。
好处就是比较方便,不需要使用其他中间件
坏处就是java自带的map是基于内存的,程序一关掉就没有了,如果是Redis的话,那缓存数据还存在。
-
缓存穿透是什么?
- 缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求(不存在的数据)都查数据库,就会造成数据库的巨大压力
- 解决方案一:缓存空数据(即使去数据库中查询不到对应的数据,也放入缓存中,下次直接从缓存中得到空数据)
- 优点:简单、缺点:缓存占用的是内存空间,空数据存放过多,导致内存压力过大,而且可能会出现数据不一致的问题(比如数据库中有对应的数据了,但是缓存中还是空的)
- 解决方案二:布隆过滤器
- 做缓存预热的时候(也就是把一些热点数据放到缓存中),往布隆过滤器添加数据
- 发生查询请求的时候,查询缓存之前先查询布隆过滤器(采用哈希表的结构),如果存在数据(也就是对应的值为1),就再去查缓存
- 如果数据不存在(也就是对应的值为0),就直接返回,主要作用就是拦截了不存在的数据
-
缓存击穿是什么?
- 缓存击穿:给某一个热点key设置了过期时间, 当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间数据库压垮(当第一次查询缓存失败,会去查询数据库,然后再重建缓存,但是是需要时间的)
- 解决方案一:互斥锁,也就是分布式锁,某个线程在查询缓存失败后,去查询数据库重建缓存的时候会加上互斥锁,如果其他线程过来就会阻塞。可以保证强一致性,但是性能差。
- 解决方案二:逻辑过期,也就是不给key设置真正的过期时间,而是在value上加一个expire过期时间的字段,用来描述这个键值对是否过期,不可以保证强一致性,但是性能好。
-
缓存雪崩是什么?
-
缓存雪崩是指在同一时段缓存中大量的key同时失效 or Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
-
解决方案一:(可能设置key的失效时间都设置的差不多)给不同的Key的TTL(过期时间)添加随机值
-
解决方案二:利用Redis集群 提高Redis服务的可用性
比如可以提前搭建好Redis的主从服务器进行数据同步,并配置哨兵机制,这样在Redis服务器因为宕机而无法提供服务时,可以由哨兵将Redis从服务器 设置为主服务器,继续提供服务。
-
-
Redis做缓存,怎么保证缓存和数据库的一致性(双写一致性)?
Redis做缓存的主要目的就是为了减少数据库的IO,提升性能,因为数据库的数据放在磁盘,磁盘的IO速度相比内存要慢很多。整体逻辑就是去读取数据的时候,先看在Redis缓存里面能否命中该条记录,如果有的话就直接返回,没有的话就去查询数据库,查询到了数据再放到缓存里面,以便下次查询的时候能直接从缓存命中。
双写一致性就是指:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库中的数据要保持一致。
如何保证一致性?(要分为两种业务场景)
1. 强一致性业务:对一致性的要求很高,缓存和数据库的数据必须时刻保持一致,我项目中主要的也是这种业务场景
- 采用延迟双删的机制,当要执行写操作的时候(也就是增删改),先删除缓存中的数据,再修改数据库的中的值,然后延迟一会儿再删除缓存中的值。
- 为什么要删除两次缓存呢,因为如果正常执行的话,你删除了缓存中的数据,再去修改数据库,下次查询的时候就可以把正确的数据放到缓存中,但是!事务是并发执行的,可能会出现这么一种情况:你删除了缓存中的值,然后在修改数据库前,另一个事务执行查询数据库的操作,就会把还没修改的值放到缓存中了,当修改完数据库中的值后,就会出现不一致性了,所以要再删除一次缓存中的值。
- 为什么第二次删除缓存要延迟一会呢,因为数据库一般采用了读写分离,主库和从库的主从复制要时间。
- 整体来讲,延迟双删可以极大程度的避免缓存中的脏数据产生,但是要保证强一致性,就要采用互斥锁的方式,就是给事务的执行加锁,但是性能比较低。
2. 允许短暂不一致的业务:对一致性的要求没那么高,缓存和数据库的数据可以短暂的不一致,实际更主流的就是这个)
- 异步通知可以保证缓存和数据库的最终一致性(也就是最终反正会一致的)(有基于MQ的,也有基于Canal的)
-
Redis持久化是怎么实现的?
Redis 的读写操作都是在内存中,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证Redis 中的数据不会丢失,就要通过Redis的持久化机制,这个机制会把数据存储到磁盘,在 Redis 重启时就能够从磁盘中恢复原有的数据。Redis默认采用的是RDB持久化机制,还有一种AOF持久化机制,要去配置才能开启
两种持久化机制RDB和AOF的对比:
RDB:快照就是记录某个瞬间的内存数据,是实际的数据
- RDB持久化机制是以快照的形式来存储数据结果,存储格式简单
- 追求大量数据恢复速度要快 的应用场景选用RDB持久化机制
- RDB持久化模式 不可以做到实时的持久化(AOF可以)
AOF:记录的是命令操作的日志,不是实际的数据
- AOF持久化机制会记录每一条操作命令,以追加日志的形式来存储操作过程,存储格式复杂
- 对业务数据敏感、对安全性要求比较高 的应用场景选用AOF持久化机制
- AOF持久化机制比RDB持久化机制的 存储速度快
- AOF持久化机制比RDB持久化机制的 恢复速度慢
Redis 4.0 使用了混合持久化
- 结合了RDB的AOF持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,也就是恢复速度快,同时结合 AOF 的优点,减低了大量数据丢失的风险。
- 缺点就是AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差
-
Redis的数据过期策略(假如redis的key过期之后,会立即删除吗?)
Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的数据过期策略。
- 惰性删除:设置该key过期时间后,不去管它,当需要该key时,再检查是否过期,如果过期,就删掉(如果不要用到这个key,那就一直没有删除)
- 定期删除:每隔一段时间, 就随机取一些key进行检查, 删除里面过期的key(在一大段时间里面,所有的key都会被检查到)
Redis默认是 这两种删除策略配合使用
-
Redis的内存用完了会怎么办?
要根据数据淘汰策略来看:
- 如果是默认的数据淘汰策略,noeviction,那就是内存满了就满了,再来数据就直接报错
- 如果是用的其他策略,就会按照指定的要求删除一定的key,然后在把新的数据放进来
-
Redis的数据淘汰策略(假如缓存太多,内存被占满了怎么办?)
当Redis中的内存不够用时,再向Redis中添加新的key,那么Redis就会按照某种规则将内存中的数据删除掉,删除规则被称之为内存的淘汰策略。
八种不同策略来选择要删除的key:
- noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl:对设置 了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- volatile-random:对设置了TTL的key,随机进行淘汰。
- allkeys-random:对全体key,随机进行淘汰
- alkeys-lru:对全体key,基于LRU算法进行淘汰
- LRU:最近最少使用(当前时间 - 最后一次访问的时间)值越大说明最近最少使用,则淘汰的优先级最高
- LFU:最少频率使用,统计每个key的访问频率,值越小说明最少频率使用,则则淘汰的优先级最高
- allkeys-lfu:对全体key,基于LFU算法进行淘汰
- volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
- volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
-
LRU和LFU的对比
- LRU(最近最少使用):核心思想是,如果一个数据项最近很久没有被访问过的,就认为不会被访问到了,而如果最近被访问过,那么它在未来可能还会被访问到。因此,LRU策略是淘汰最近很久没有被访问过的,保留最近被访问过的。为了实现LRU策略,可以使用双向链表和哈希表等数据结构。
- LFU(最不频繁使用):核心思想是,认为访问频次较低的数据 就不会被访问了,就可以淘汰,访问频次较高的数据可能在未来还会被访问,就应该保留。为了实现LFU策略,可以使用最小堆或者哈希表等数据结构。
区别:
- LRU侧重于数据项最近的访问时间,而LFU侧重于数据项的访问频率。
- LRU易于实现,通常使用双向链表和哈希表。而LFU实现起来相对复杂,需要使用最小堆或哈希表等数据结构。
- 在某些情况下,LFU可能比LRU表现得更好,因为它更关注访问频率。然而,LFU对于某些访问模式可能会导致较低的命中率。
因此需要根据实际的应用场景,可以选择合适的缓存淘汰策略。
-
什么是Redis集群?
- Redis集群是一种通过将多个Redis节点连接在一起以实现高可用性、数据分片和负载均衡的技术。
- 它允许Redis在不同节点上同时提供服务,提高整体性能和可靠性。
- 根据搭建的方式和集群的特性,Redis集群主要有三种模式:主从复制模式、哨兵模式、Cluster模式
作用和优势:
- 高可用性:可以在某个节点发生故障时,自动进行故障转移,保证服务的持续可用
- 负载均衡:可以将客户端请求分发到不同的节点上,有效地分摊节点的压力,提高系统的整体性能
- 数据分片:在Cluster模式下,Redis集群可以将数据分散在不同的节点上,从而突破单节点的内存限制,实现更大规模的数据存储。
-
Redis常用的集群方案/模式有哪些?
- 主从复制模式(Master-Slave):适用于数据备份和读写分离场景,配置简单,但在主节点故障时需要手动切换。
- 哨兵模式(Sentinel):在主从复制的基础上实现自动故障转移,提高高可用性,适用于高可用性要求较高的场景。
- Cluster模式:通过数据分片和负载均衡实现大规模数据存储和高性能,适用于大规模数据存储和高性能要求场景。
【后续继续补充,敬请期待】
相关文章:
【Java开发岗面试】八股文—数据库MySQLRedis
声明: 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试…...
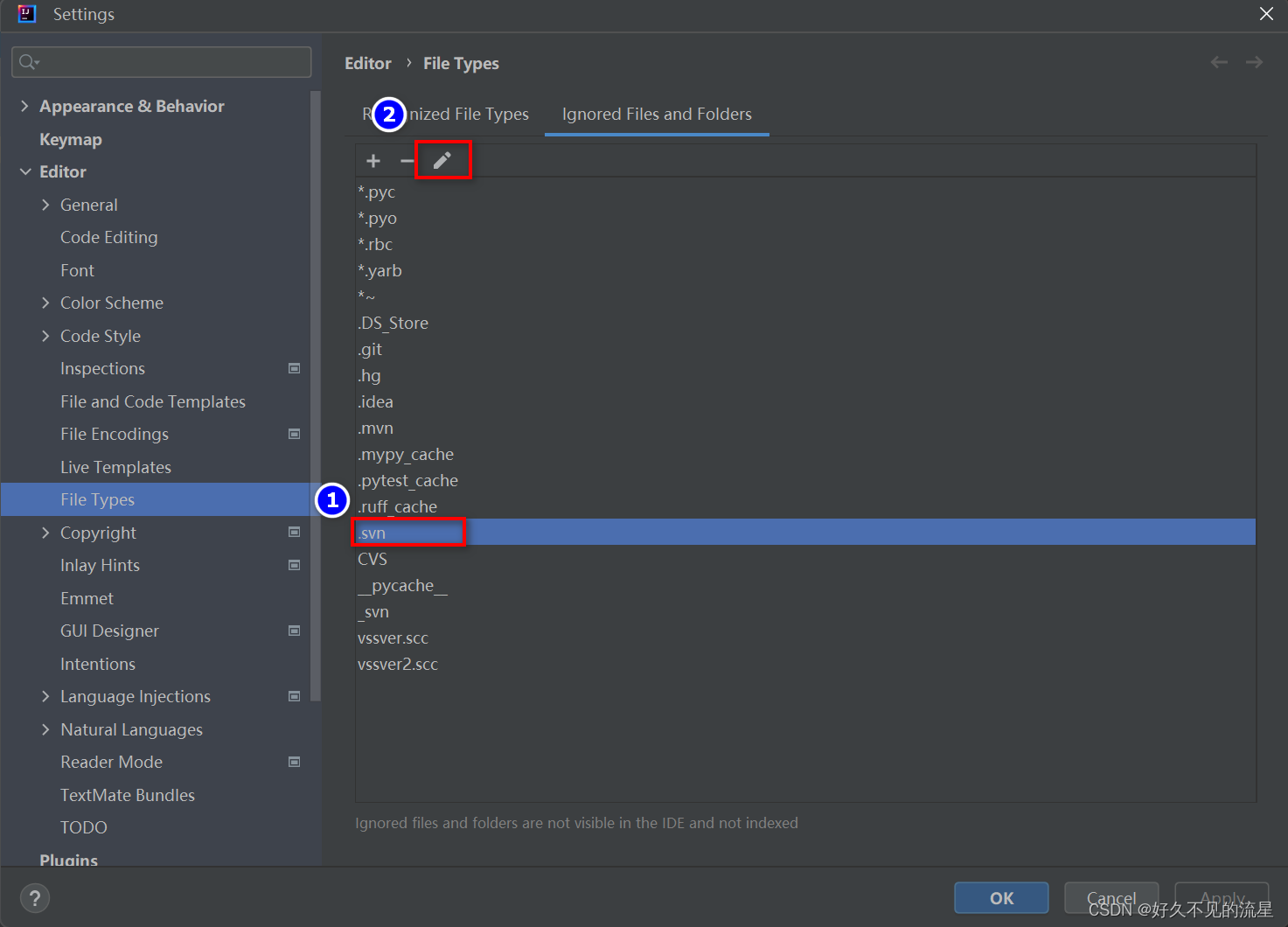
IntelliJ IDEA [设置] 隐藏 .idea 等 .XXX 文件夹
文章目录 1. 问题描述2. 解决办法3. 最后效果4. 特殊处理(正常不需要此步骤)总结 我们使用 IntelliJ IDEA 导入项目的时候,经常会看到一些 .XXX 的文件夹(例如:.idea,.mvn,.gradle 等࿰…...

每日一题——LeetCode961
方法一 排序法: 2*n长度的数组里面有一个元素重复了n次,那么将数组排序,求出排序后数组的中间值(因为长度是偶数,没有刚好的中间值,默认求的中间值是偏左边的那个)那么共有三种情况:…...

基于Unity Editor开发一个技能编辑器可能涉及到的内容
基于Unity Editor开发一个技能编辑器,涉及到的方面较多,涵盖了Unity自身的GUI框架、序列化系统、自定义编辑器、脚本调用与数据存储等。下面是几个关键点和你可能会用到的类以及API: 自定义Inspector: 使用Editor类来重写组件的I…...
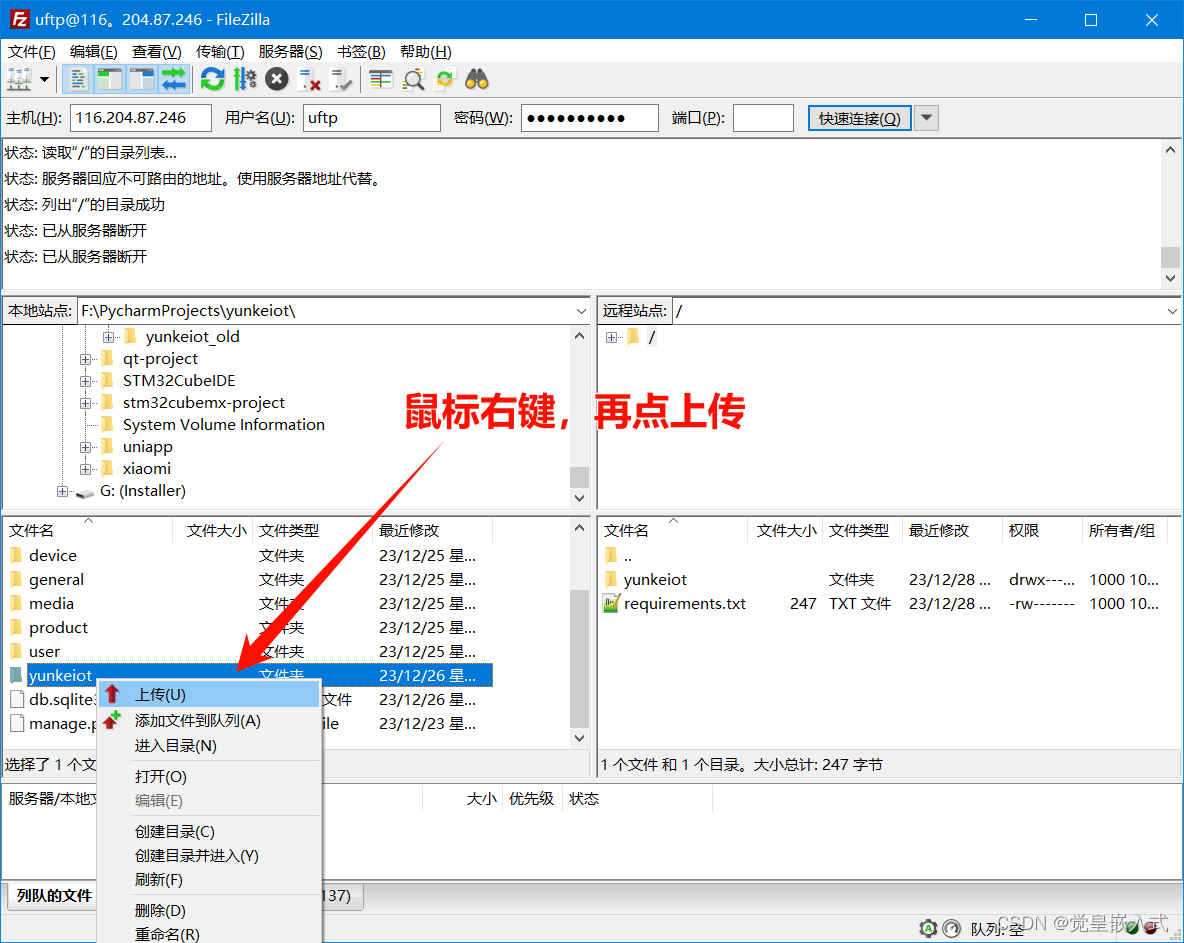
Ubuntu 22.04 安装ftp实现与windows文件互传
Ubuntu 22.04 安装ftp实现与windows文件互传 1、配置安装 安装: sudo apt install vsftpd -y使能开机自启: sudo systemctl enable vsftpd 启动: sudo systemctl start vsftpd创建ftp工作目录: sudo mkdir -p /home/ftp/uftp…...

EasyPoi使用案例
EasyPoi使用案例 easypoi旨在简化Excel和Word的操作。基于注解的导入导出,修改注解就可以修改Excel;支持常用的样式自定义;基于map可以灵活定义表头字段;支持一对多的导入导出;支持模板的导出;支持HTML/Exc…...

分布式系统架构设计之分布式数据存储的分类和组合策略
在现下科技发展迅猛的背景下,分布式系统已经成为许多大规模应用和服务的基础架构。分布式架构的设计不仅仅是一项技术挑战,更是对数据存储、管理和处理能力的严峻考验。随着云原生、大数据、人工智能等技术的崛起,分布式系统对于数据的高效存…...

javaEE -18(11000字 JavaScript入门 - 3)
一:事件 (高级) 1.1 注册事件(绑定事件) 给元素添加事件,称为注册事件或者绑定事件,注册事件有两种方式:传统方式和方法监听注册方式 传统注册方式 : 利用 on 开头的…...

LangChain.js 实战系列:入门介绍
📝 LangChain.js 是一个快速开发大模型应用的框架,它提供了一系列强大的功能和工具,使得开发者能够更加高效地构建复杂的应用程序。LangChain.js 实战系列文章将介绍在实际项目中使用 LangChain.js 时的一些方法和技巧。 LangChain.js 是一个…...
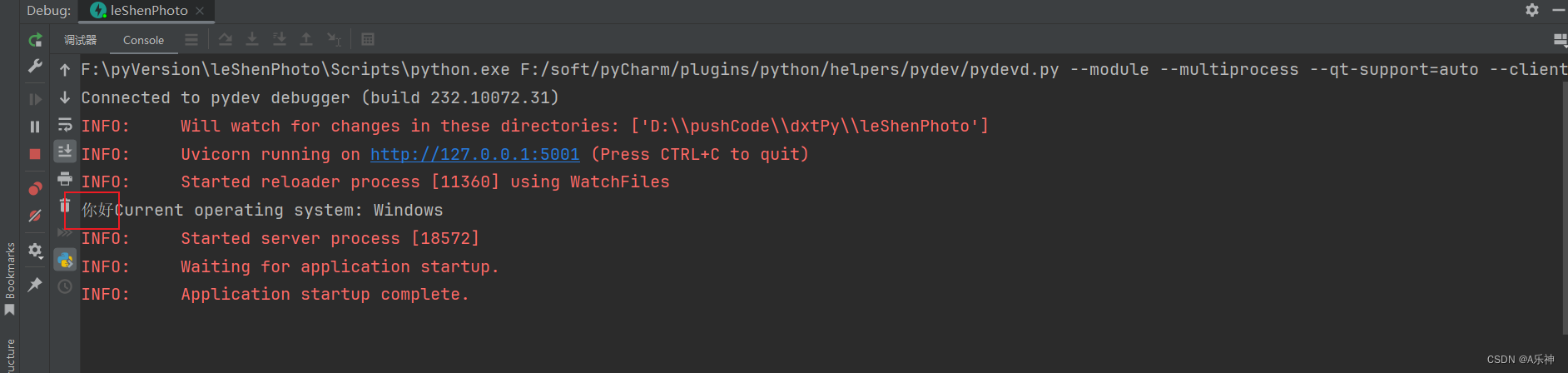
pyCharm 打印控制台中文乱码解决办法
解决方法 在 "File" -> "Settings" 中的控制台设置: 在 "File" -> "Settings" 中,你可以找到 "Editor" -> "General" -> "Console"。在这里,你可能会找到…...

计算机基础--Linux详解
一概述 Linux是一种自由和开放源码的类UNIX操作系统。它是由林纳斯托瓦兹于1991年首次发布的,并从那时起在全球范围内得到了广泛的应用和开发。Linux具有强大的可定制性,可以运行在各种硬件平台上,包括x86、ARM、MIPS等。它不仅广泛应用于服…...
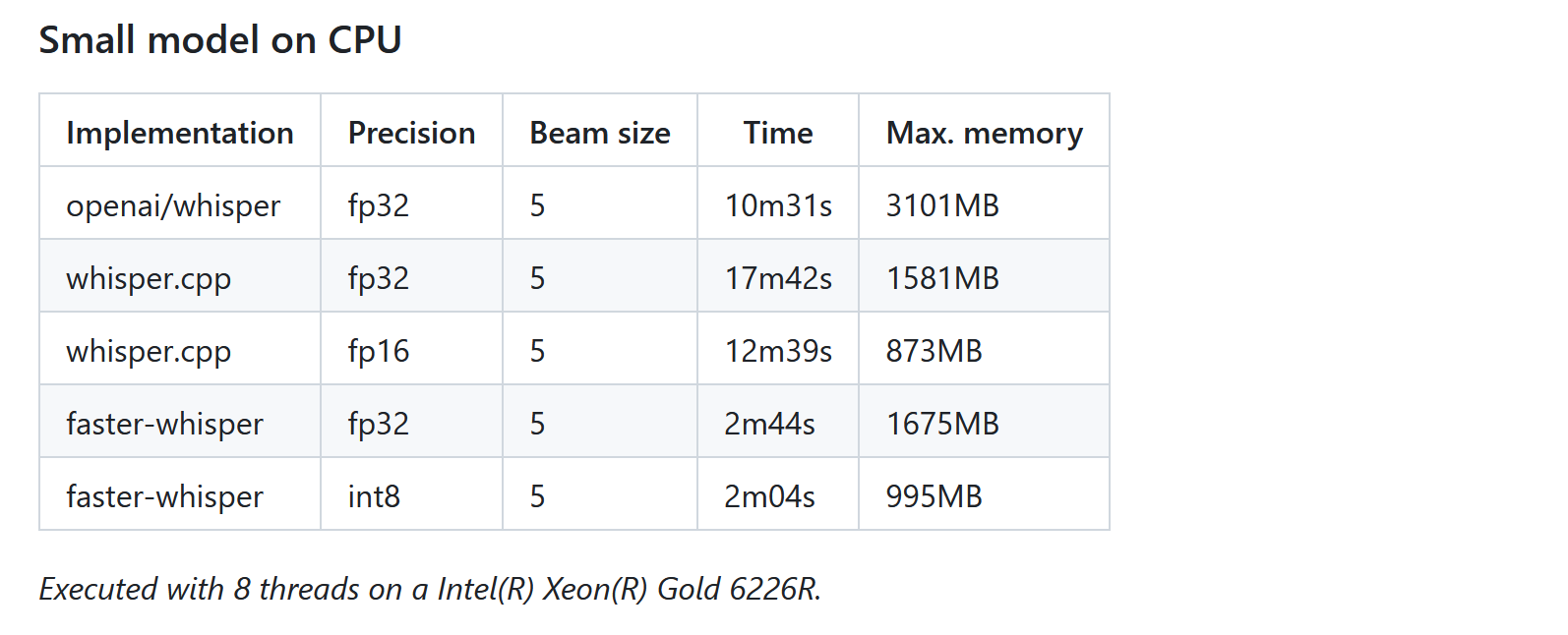
基于OpenAI的Whisper构建的高效语音识别模型:faster-whisper
1 faster-whisper介绍 faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在…...
)
cfa一级考生复习经验分享系列(十六)
写在前面:并不鼓励大家在考前一个月才开始复习,不过,既然已经逼到了绝境,灰心丧气也没有用,不如放手一搏! 首先说一下我的背景,工作金融机构的it,和cfa基本没关系,本硕计…...
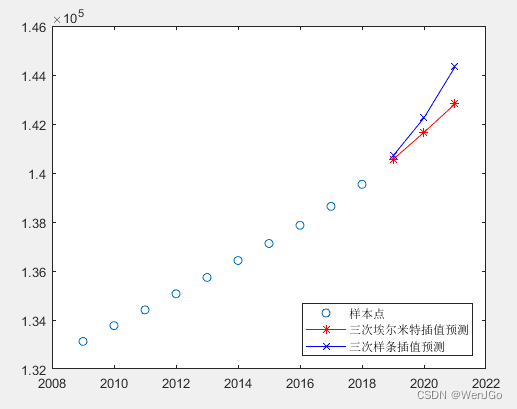
数模学习day05-插值算法
插值算法有什么作用呢? 答:数模比赛中,常常需要根据已知的函数点进行数据、模型的处理和分析,而有时候现有的数据是极少的,不足以支撑分析的进行,这时就需要使用一些数学的方法,“模拟产生”一些…...

hive中struct相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释 hive官网函数大全地址:添加链接描述 Return TypeNameDescriptionstructstruct(val1, val2, val3, …)Creates a struct with the given field values. Struct field names will be col1, col2, …structnamed_str…...
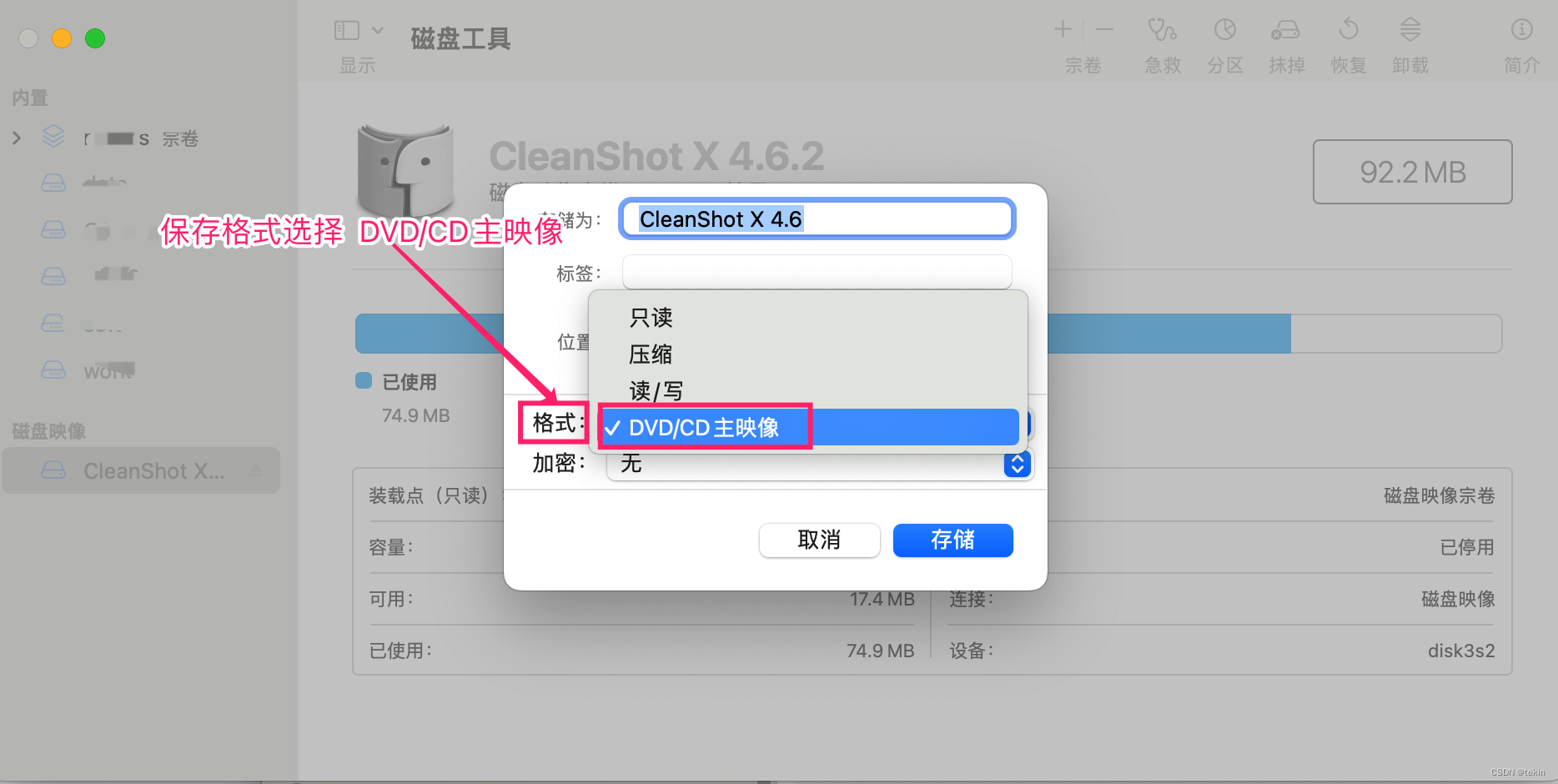
macos下转换.dmg文件为 .iso .cdr文件的简单方法
为了让镜像文件在mac 和windows平台通用, 所以需要将.dmg格式的镜像文件转换为.iso文件, 转换方法也非常简单, 一行命令即可 hdiutil convert /path/to/example.dmg -format UDTO -o /path/to/example.iso 转换完成后的文件名称默认是 example.iso.cdr 这里直接将.cdr后缀删…...
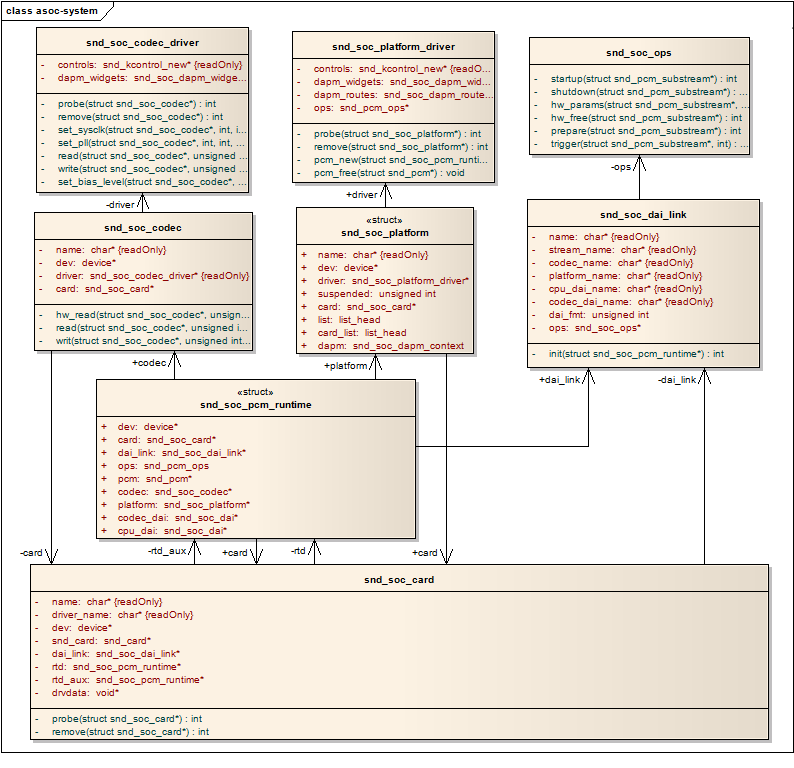
ALSA学习(5)——设备中的alsa
参考博客: https://blog.csdn.net/DroidPhone/article/details/7165482 (一下内容基本是原博主的博客转载) 文章目录 一、ASOC的由来二、硬件架构三、软件架构四、数据结构五、内核对ASoC的改进 一、ASOC的由来 ASoC–ALSA System on Chip …...

uniapp中组件库的丰富NumberBox 步进器的用法
目录 基本使用 #步长设置 #限制输入范围 #限制只能输入整数 #禁用 #固定小数位数 #异步变更 #自定义颜色和大小 #自定义 slot API #Props #Events #Slots 基本使用 通过v-model绑定value初始值,此值是双向绑定的,无需在回调中将返回的数值重…...
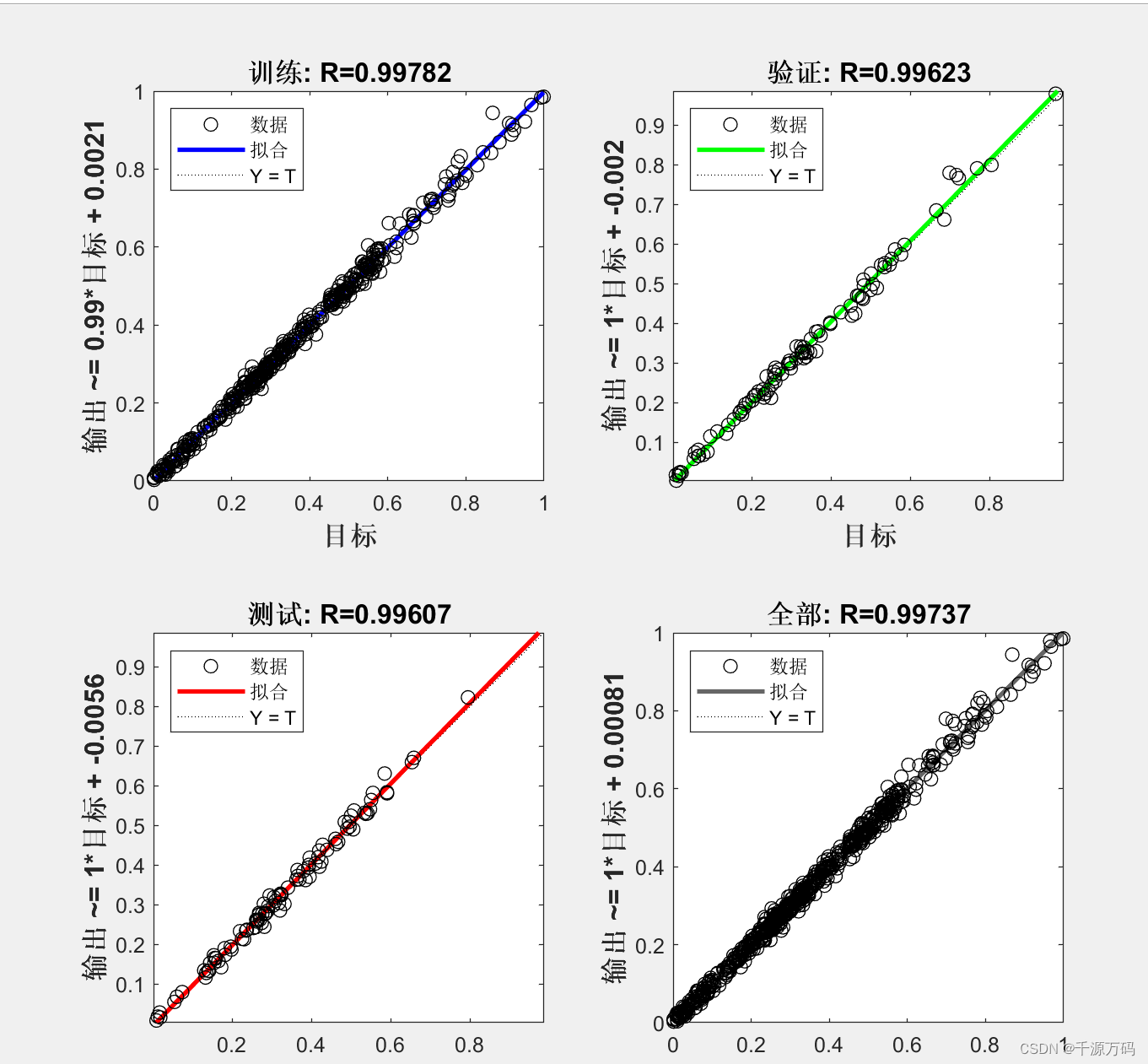
【Matlab】基于遗传算法优化BP神经网络 (GA-BP)的数据时序预测
资源下载: https://download.csdn.net/download/vvoennvv/88682033 一,概述 基于遗传算法优化BP神经网络 (GA-BP) 的数据时序预测是一种常用的机器学习方法,用于预测时间序列数据的趋势和未来值。 在使用这种方法之前,需要将时间序…...
计算机毕业设计 基于HTML5+CSS3的在线英语阅读分级平台的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...