Havenask 分布式索引构建服务 --Build Service
Havenask 是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了 Havenask 分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系统提升竞争力的一大利器。
一、Havenask 介绍
Havenask 是阿里巴巴广泛使用的自研大规模分布式检索系统,是过去十多年阿里在电商领域积累下来的核心竞争力产品,广泛应用在搜推广和大数据检索等典型场景,在 2022 年云栖大会-云计算加速开源创新论坛上完成开源首发,同时作为阿里云开放搜索 OpenSearch 底层搜索引擎,OpenSearch 自 2014 年商业化,目前已有千余家外部客户。
下图展示了 Havenask 中一个完整的搜索服务:在线系统、索引系统、管控系统、扩展插件,且包括了查询流、数据流、控制流。其中,索引系统负责索引数据生成的过程,还包含有文档处理与本文的主角索引构建服务 Build Service。索引构建分为三个步骤,对数据进行前置处理(例如分词、向量计算等)、产出索引、合并索引文件的处理。

Havenask 支持千亿级别数据实时检索、百万 QPS 查询,百万 TPS 高时效性写入保障,毫秒级查询延迟和数据更新,并具有良好的分布式架构、极致的性能优化,能够实现比现有技术方案更低的成本,普惠更多的开发者和企业。
二、Build Service 简介
Build Service 是一个分布式索引构建服务,用于 Havenask 中的全量表的索引构建。它可以对接本地存储、HDFS 等多种数据源,快速的将原始数据构建成全量索引,并以流式工作模式进行增量索引构建。Build Service 是 Havenask 读写分离架构的重要组成部分,独立的索引构建服务使 Havenask 具有下面优势:
在线系统更加稳定:将索引构建从在线系统分离,避免了索引构建对在线系统的影响,使在线系统更加稳定。
索引构建更快:特有的全量流程,使全量数据导入更快;独立的资源控制,进一步提升索引构建速度。
多版本索引管理:多版本独立的构建流程管理,使索引重建更方便,更安全。
三、Build Service 架构
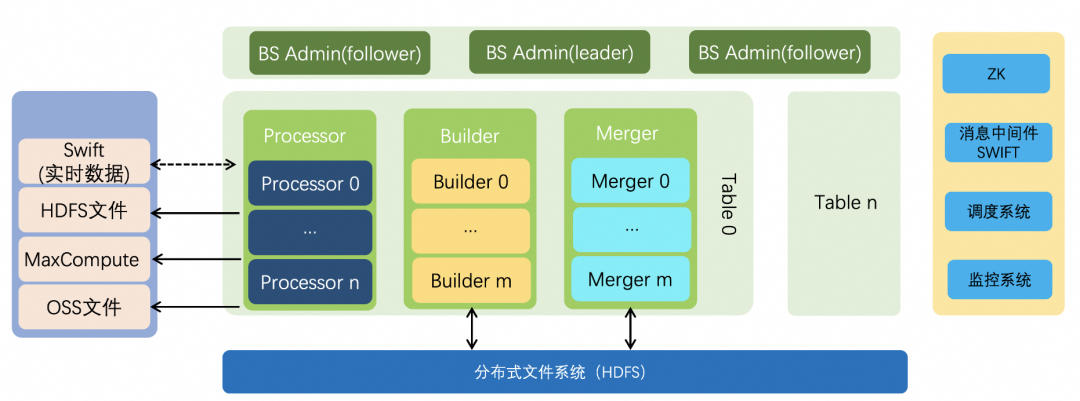
Build Service 架构图
上图是 Build Service 的架构,在 Build Service 中主要有下面几个角色:
BS Admin:BS Admin 负责整个集群的任务调度和资源管理。BS Admin 提供丰富的接口进行索引构建任务的启停,资源的调整等,BS Admin 接收到这些请求之后会进行任务的调度,并配合调度系统,调度任务的执行,并维护任务的状态。
Processor:Processor 从数据源中拉取数据进行处理,Processor 可以支持多种数据源,比如 HDFS、OSS 等分布式文件系统,也可以对接 Swift 消息中间件处理实时数据。在 Processor 中主要是对数据进行分词、简单的数据转换等处理,开发者可以通过定制数据源 reader 插件和数据处理 DocumentProcessor 插件来扩展支持不同的数据源和数据处理逻辑。
Builder:Builder 负责索引的构建,它将经过 Processor 处理的数据按照 Schema 的配置构建成倒排、正排、摘要索引。Builder 与 Processor 的数据交互是通过 Swift 消息中间件来实现的,即 Processor 将处理之后的数据写到 Swift,Build 从 Swift 中读取这些数据进行索引构建。
Merger:Merger 负责索引的定期整理,定期索引整理使索引文件更加紧凑,可以降低在线集群索引加载的内存开销,提升检索性能。索引整理时会清理已经删除的数据,将小的索引文件合并成大的索引文件,也可以按照配置在整理时根据某个字段进行离线排序,这样可以进一步提升检索性能。
在一个 Build Service 服务中可以有一个或者多个 BS Admin,它们通过 ZK 进行 leader 选举,只有 leader 才会管理整个 Build Service 服务,其他 Admin 作为 fllower,使服务更加稳定。一个 Build Service 服务可以同时管理多个表或者同一个表的不同版本的索引构建任务,每个任务都是相互隔离的,互不影响。每个索引构建任务都有各自的 Processor、Builder、Merger 节点进行数据的处理,索引的构建。每个索引构建任务可以独立进行资源控制,比如调整 Processor 节点的个数,Builder 和 Meger 的并发度,以及这些节点的 CPU 和内存等。
对于 Processor、Builer 和 Meger 节点,它们只有分片(Shard)的概念,没有备份的概念。比如对于 Processor,每个分片处理不同的数据,一个分片只会启动一个节点,如果某些原因启动了多个节点,多个节点之间通过 ZK 进行 leader 选举,只有 leader 节点才会存活并工作,非 leader 节点的进程会自动退出。Builder 和 Merger 的情况与 Processor 类似,唯一不同的是分片数是在创建表时就确定的,它们只能基于分片数据调节并发度,因此 Builder 和 Meger 节点真实启动的个数是分片数乘以并发度。
四、索引构建流程
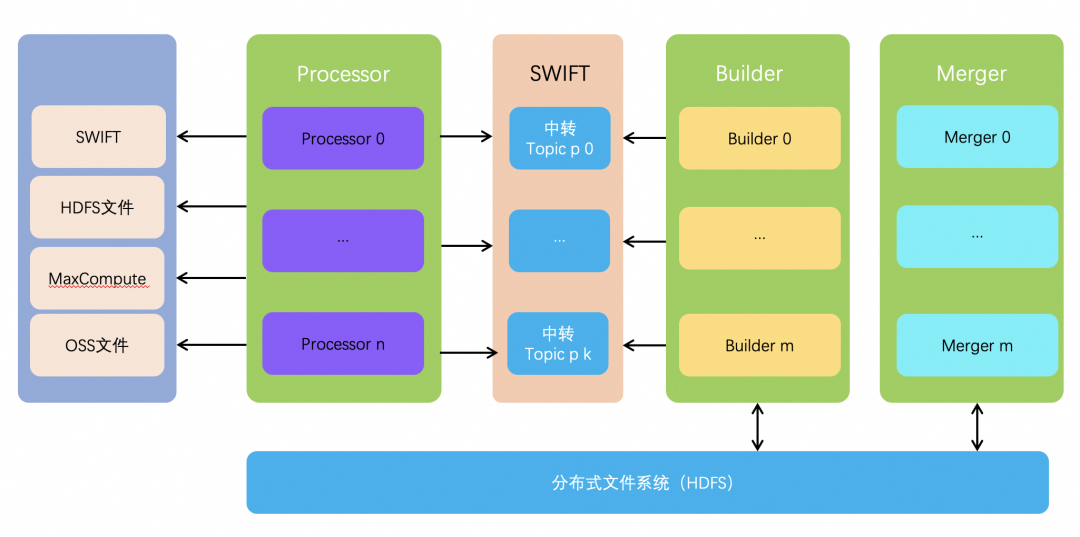
索引构建流程示意图
Build Service 的索引构建分为两个阶段:全量索引构建和增量索引构建。每个索引构建任务都会先进行全量索引构建,全量结束之后会自动切换到增量索引构建阶段,增量索引构建任务会一直执行,直至这次索引构建任务停止。全量索引构建任务会首先从分布式文件系统读取原始数据构建成索引(如果没有配置,这步会跳过),全量文件处理完成之后,会继续从 Swift 中读取数据继续构建全量索引。这样等全量流程结束之后,全量索引中的数据已经通过消费 Swift 追到距离当前比较靠近的时间了,索引切上线之后不会出现较长时间的时效性延迟。
无论是全量索引构建还是增量索引构建,它们的索引构建流程是类似的。首先 Processor 节点会从数据源中(包括 Swift)读取原始数据,然后对数据进行分词或者其他处理,处理之后的数据会转发到 Swift 的中。Builder 和 Merger 的任务是交替执行的,首先 Builder 从 Swift 中读取处理之后的数据,构建成索引,索引产出在分布式文件系统中。对于全量索引构建,全量数据被全部构建为索引之后 Builder 就会结束;对于增量索引构建,Builder 接受 BS Admin 的调度,将数据处理到某个时间点就会退出。Builder 结束之后,Meger 节点就会执行,Meger 会对构建的索引按照一定的策略进行整理,整理好的索引也会写回分布式文件系统。
需要注意的是,增量索引构建时,Processor 处理之后的数据不仅仅供 Builder 消费,在线的 Searcher 节点也会直接消费,将其构建成实时索引。
五、Build Service 定制能力
为了满足不同业务的需求,Build Service 在构建索引时支持下面三种定制能力:分析器的定制、数据源插件的定制、数据处理插件的定制。开发者可以直接修改代码将定制逻辑与 Havenask 一起编译成一个 Binary 生效,也可以建立单独的目录将其编译成动态库,通过插件的方式生效。
分析器定制:分析器主要用于对文档进行分词,开发者可以通过定制分析器定制自己的分词逻辑,分析器不仅会在构建索引时生效,在查询时也会生效。
数据源插件定制:Havenask 主要支持 HDFS、OSS、MaxCompute、Swift 等数据源,如果要支持更多的数据源比如 kafka,可以定制 Processor 的 Reader 插件。
数据处理定制:数据在 Processor 中是由一个 DocumentProcessor 链进行处理的,用户可以定制自己的 DocumentProcessor 处理类来扩展数据处理逻辑。
六、Build Service 与 Indexlib(核心索引库)的关系
Indexlib 是 Havenask 的核心索引库,提供正排、倒排、摘要等索引的实现,并在此基础上抽象出了各种表模型,比如 normal 表、kv 等、kkv 表等。但是 Indexlib 无法独立提供索引构建服务,必须通过 Build Service 才能进行索引构建。可以说,Indexlib 提供了各种索引的定义,并提供了索引构建的接口,Build Service 定义了流式索引构建的框架,两者相结合才使 Havenask 具有了强大的索引构建能力。
七、总结
Build Service 是一个流式的索引构建服务,能够轻松完成海量数据的索引构建,对在线系统没有任何影响,极大提高了整个集群的稳定性。独立的索引构建任务管理,可以方便、安全的对同一张表进行多次索引构建,特别适用于智能搜索场景下需要定期索引重建的场景。当然,Build Service 的引入也使得整个系统的架构更加复杂,数据生效链路变长,资源开销变大,大家在使用时请根据业务情况认真选择。
Havenask 开源官网:
https://havenask.net/
Havenask 开源项目地址:
https://github.com/alibaba/havenask
阿里云 OpenSearch 官网:
https://www.aliyun.com/product/opensearch

相关文章:
Havenask 分布式索引构建服务 --Build Service
Havenask 是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了 Havenask 分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系…...
vscode软件安装步骤
目录 一、下载软件安装包 二、运行安装包后 一、下载软件安装包 打开vscode官方网址,找到下载界面 链接如下:Download Visual Studio Code - Mac, Linux, Windows 我是windows电脑,各位小伙伴自己选择合适的版本,点击下载按钮…...

C语言中灵活多变的动态内存,malloc函数 free函数 calloc函数 realloc函数
文章目录 🚀前言🚀管理动态内存的函数✈️malloc函数✈️free函数✈️calloc函数✈️realloc函数 🚀在使用动态内存函数时的常见错误✈️对NULL指针的解引用✈️ 对动态开辟空间的越界访问✈️对非动态开辟内存使用free释放✈️使用free释放一…...

小细节处理
重载运算符:重载<运算符。 bool operator<(const Edge&s)const{return w<s.w;}...

【42页动态规划学习笔记分享】动态规划核心原理详解及27道LeetCode相关经典题目汇总
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…...

Python正则的匹配与替换
import re 查找时的注意事项,要查找的内容左右两边打出来,用真正的字符,不要用.*?,离查找内容远一点,再用.*? a /aksj<a>哈哈哈<a><p>拉阿鲁<p>\.askjp b re.findall(<a>(.*?)<…...
解决ELement-UI懒加载三级联动数据不回显(天坑)
最老是遇到这类问题头有点大,最后也是解决了,为铁铁们总结了一下几点 一.查看数据类型是否一致 未选择下 选择下 二.处理数据时使用this.$set方法来动态地设置实例中的属性,以确保其响应式 三.绑定v-if 确保每次重新加载 四.绑定key 五.完整代码...
【数据结构和算法】找出两数组的不同
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、题目描述 二、题解 2.1 哈希类算法题注意事项 2.2 方法一:哈希法 三、代码 3.1 方法一:哈希法 四…...

基于Python的B站排行榜大数据分析与可视化系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本文介绍了一项基于Python的B站排行榜大数据分析与可视化系统的研究。通过网络爬虫技术,系统能够自动分析B站网址,提取大量相关文本信息并存储在系统中。通过对这些信息进行…...

MySQL一些常用命令
1、登录本地MySQL #一种是 mysql -u root -p; #(输入密码后回车)#另一种是 mysql -uroot -p123456; #(在-p后面直接带上密码)2、启动MySQL服务 net start mysql; 3、关闭MySQL服务: net stop mysql; 4、创建数据库 create database 数据库名; 5、创建数据…...
WPF 新手指引弹窗
新手指引弹窗介绍 我们在第一次使用某个软件时,通常会有一个“新手指引”教学引导。WPF实现“新手指引”非常方便,且非常有趣。接下来我们就开始制作一个简单的”新手指引”(代码简单易懂,便于移植),引用到我们的项目中又可添加一…...

py注册登录界面
代码分析 引入tkinter库,并从中导入messagebox模块。 read_users()函数用于读取存储用户信息的文本文件"users.txt"。它打开文件并逐行读取,将每行的用户名和密码以空格分隔后存储在一个列表中,最后返回该列表。 login(username,…...
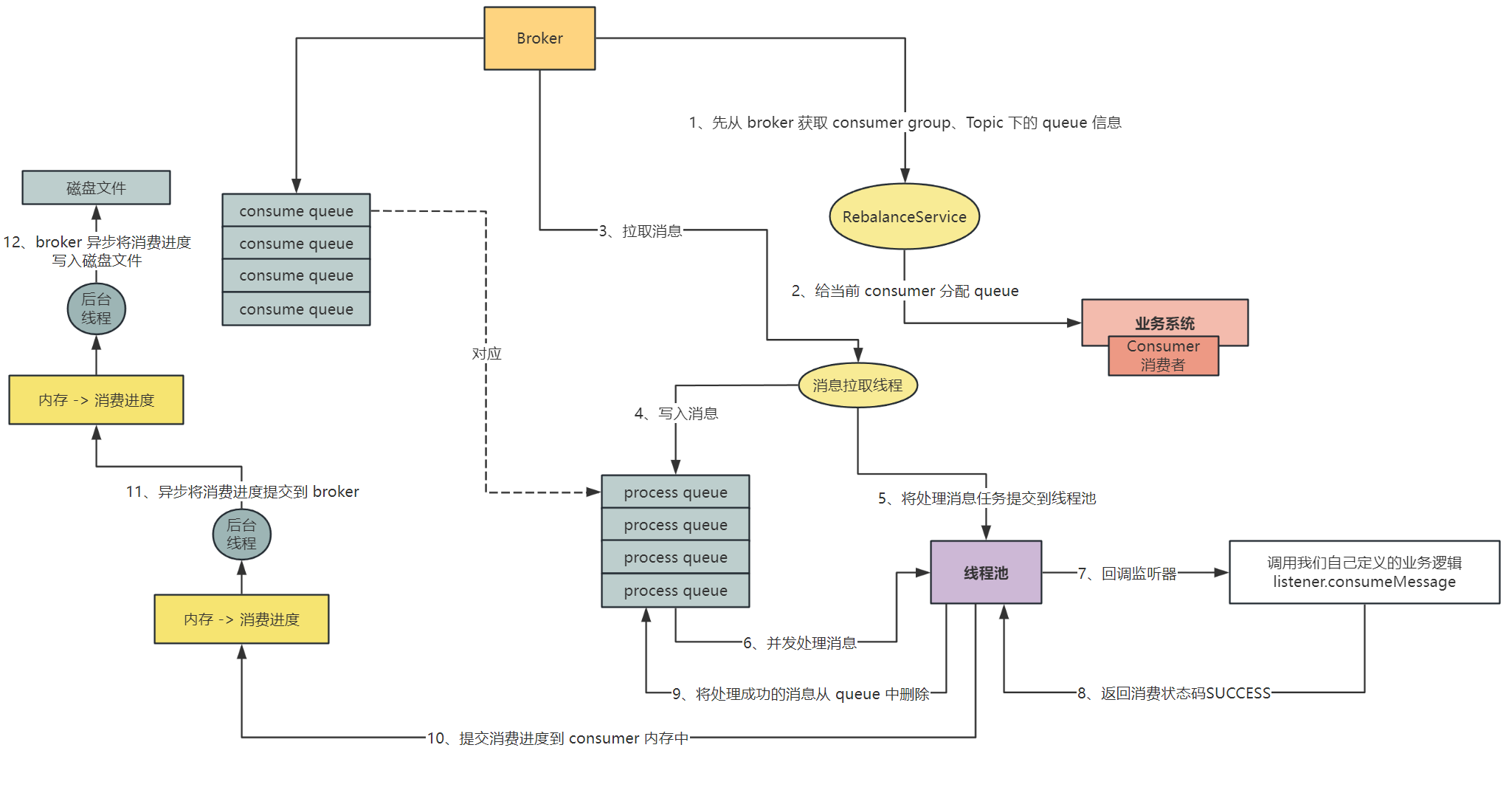
基于电商场景的高并发RocketMQ实战-Consumer端队列负载均衡分配机制、并发消费以及消费进度提交
🌈🌈🌈🌈🌈🌈🌈🌈 【11来了】文章导读地址:点击查看文章导读! 🍁🍁🍁🍁🍁🍁dz…...
【Java开发岗面试】八股文—数据库MySQLRedis
声明: 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试…...
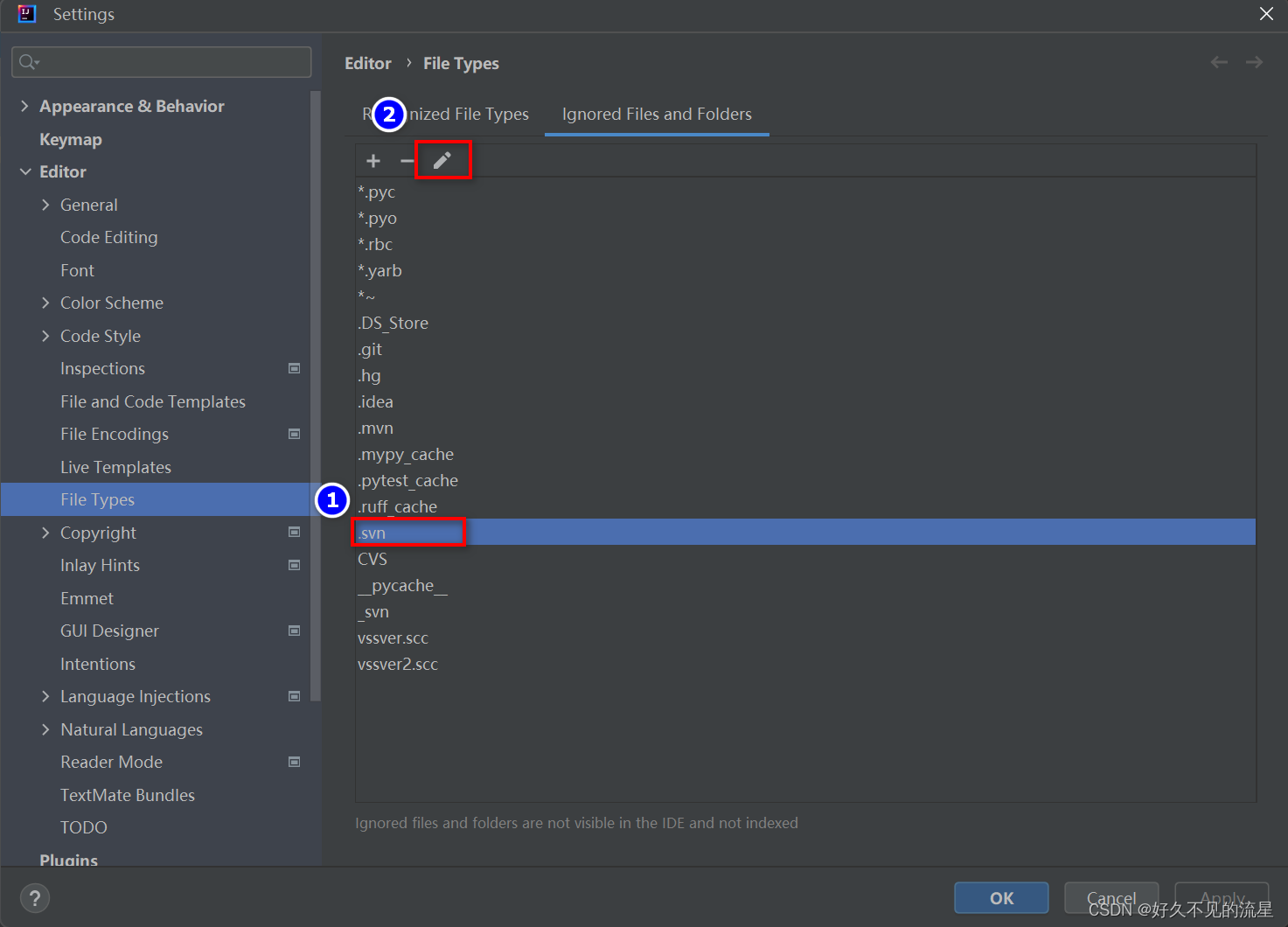
IntelliJ IDEA [设置] 隐藏 .idea 等 .XXX 文件夹
文章目录 1. 问题描述2. 解决办法3. 最后效果4. 特殊处理(正常不需要此步骤)总结 我们使用 IntelliJ IDEA 导入项目的时候,经常会看到一些 .XXX 的文件夹(例如:.idea,.mvn,.gradle 等࿰…...

每日一题——LeetCode961
方法一 排序法: 2*n长度的数组里面有一个元素重复了n次,那么将数组排序,求出排序后数组的中间值(因为长度是偶数,没有刚好的中间值,默认求的中间值是偏左边的那个)那么共有三种情况:…...

基于Unity Editor开发一个技能编辑器可能涉及到的内容
基于Unity Editor开发一个技能编辑器,涉及到的方面较多,涵盖了Unity自身的GUI框架、序列化系统、自定义编辑器、脚本调用与数据存储等。下面是几个关键点和你可能会用到的类以及API: 自定义Inspector: 使用Editor类来重写组件的I…...
Ubuntu 22.04 安装ftp实现与windows文件互传
Ubuntu 22.04 安装ftp实现与windows文件互传 1、配置安装 安装: sudo apt install vsftpd -y使能开机自启: sudo systemctl enable vsftpd 启动: sudo systemctl start vsftpd创建ftp工作目录: sudo mkdir -p /home/ftp/uftp…...

EasyPoi使用案例
EasyPoi使用案例 easypoi旨在简化Excel和Word的操作。基于注解的导入导出,修改注解就可以修改Excel;支持常用的样式自定义;基于map可以灵活定义表头字段;支持一对多的导入导出;支持模板的导出;支持HTML/Exc…...

分布式系统架构设计之分布式数据存储的分类和组合策略
在现下科技发展迅猛的背景下,分布式系统已经成为许多大规模应用和服务的基础架构。分布式架构的设计不仅仅是一项技术挑战,更是对数据存储、管理和处理能力的严峻考验。随着云原生、大数据、人工智能等技术的崛起,分布式系统对于数据的高效存…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
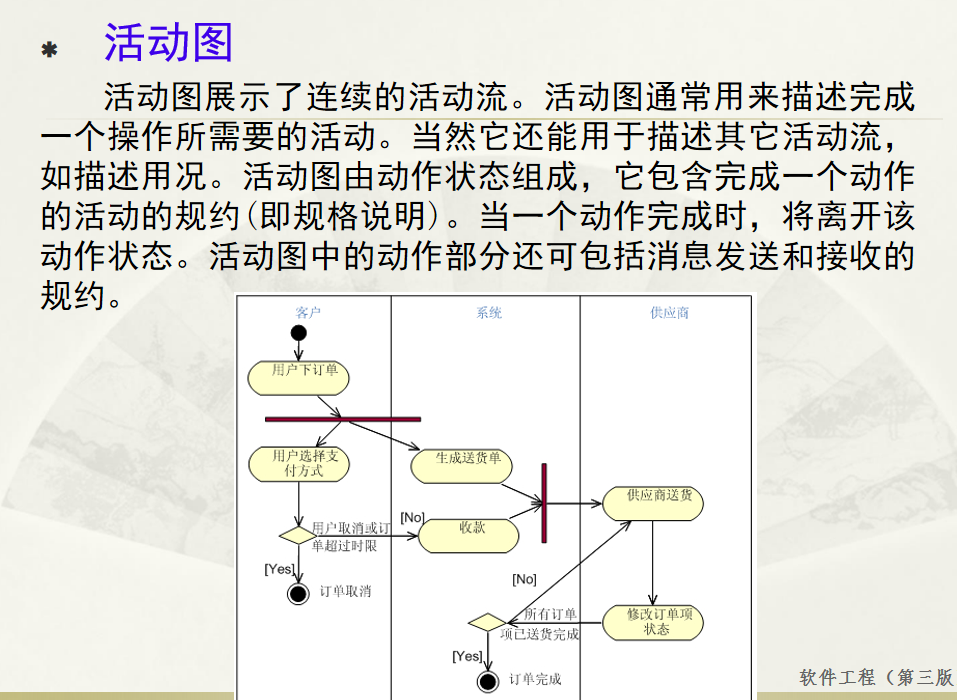
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...