【HDFS联邦(2)】HDFS Router-based Federation官网解读:HDFSRouterFederation的架构、各组件基本原理
文章目录
- 一. 介绍
- 二、HDFS Router-based Federation 架构
- 1. 示例说明
- 2. Router
- 2.1. Federated interface
- 2.2. Router heartbeat
- 2.3. NameNode heartbeat
- 2.4. Availability and fault tolerance
- Interfaces
- 3. Quota management
- 4. State Store
- 三、部署 ing
本文主要参考官网:HDFSRouterFederation 对HDFSRouterFederation进行了解:
- viewfs会带来的问题,HDFSRouterFederation是如何解决的
- HDFSRouterFederation的架构、各组件基本原理说明
一. 介绍
NameNodes have scalability limits because of the metadata overhead comprised of inodes (files and directories) and file blocks, the number of Datanode heartbeats, and the number of HDFS RPC client requests. The common solution is to split the filesystem into smaller subclusters HDFS Federation and provide a federated view ViewFs. The problem is how to maintain the split of the subclusters (e.g., namespace partition), which forces users to connect to multiple subclusters and manage the allocation of folders/files to them.
因为元数据(文件和目录、文件块)的开销、datanode心跳管理以及HDFS RPC请求,namenode有对于datanode的拓展有限制。我们将文件系统分为几个子HDFS联邦系统,然后提供一个联邦的 ViewFs 。但会出现维护子集群的分裂(例如,namespace分区)的问题,这强制用户连接到多个子集群并管理文件夹/文件的分配。
二、HDFS Router-based Federation 架构
我们可以对联邦分区扩展可以添加一个管理namespace联邦的软件层。
架构特性
- 这个额外层允许用户透明的访问任何子系统,让子集群独立地管理自己的块池,并且将支持子集群之间的数据rebalancing。
- Router-based Federation下的子集群不需要是独立的HDFS集群,也可以是普通的federation集群(包含多个块池),或者是federation和独立集群的混合集群。
- 为了实现这些目标,联邦层需要将块访问引导到适当的子集群,维护名称空间的状态,并提供数据再平衡机制。所以这一层必须具有可伸缩性、高可用性和容错性。
架构组成
This federation layer comprises multiple components. The Router component that has the same interface as a NameNode, and forwards the client requests to the correct subcluster, based on ground-truth information from a State Store. The State Store combines a remote Mount Table (in the flavor of ViewFs, but shared between clients) and utilization (load/capacity) information about the subclusters. This approach has the same architecture as YARN federation.
该联邦层由多个组件组成。
- Router组件具有与NameNode相同的接口,并根据来自State Store的真实信息将客户端请求转发到正确的子集群。
- State Store包含了一个远程挂载表(类似于视图,但在客户端之间共享)和关于子集群的利用率(负载/容量)信息。这种方法具有与YARN联合相同的体系结构。
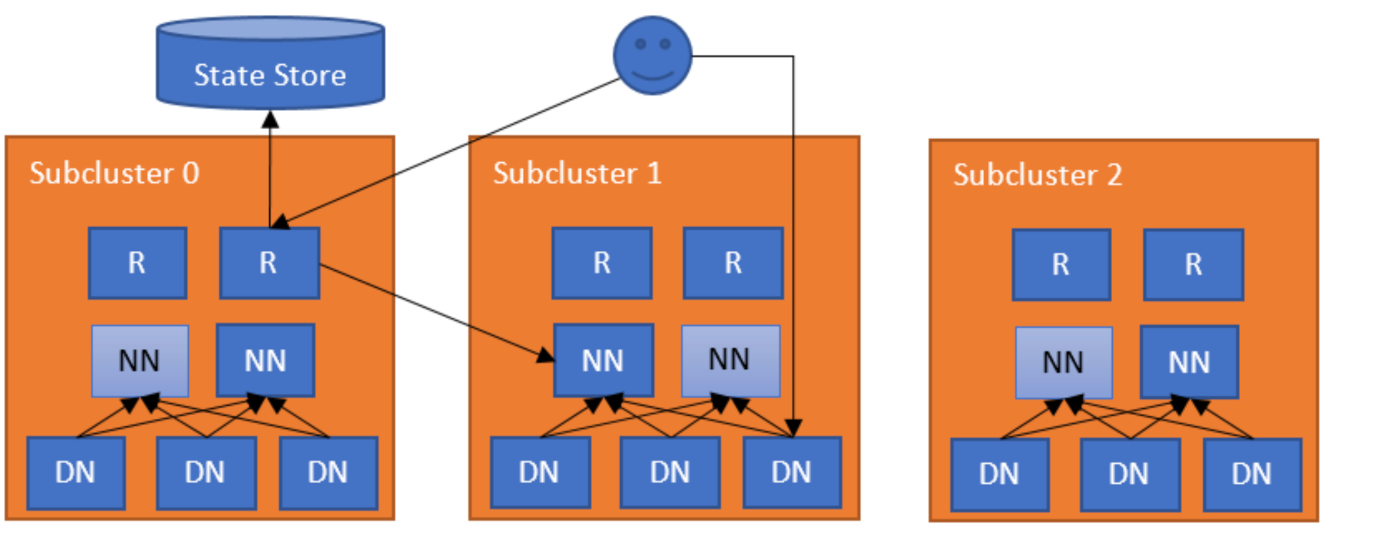
1. 示例说明
The simplest configuration deploys a Router on each NameNode machine. The Router monitors the local NameNode and its state and heartbeats to the State Store. The Router monitors the local NameNode and heartbeats the state to the State Store. When a regular DFS client contacts any of the Routers to access a file in the federated filesystem, the Router checks the Mount Table in the State Store (i.e., the local cache) to find out which subcluster contains the file. Then it checks the Membership table in the State Store (i.e., the local cache) for the NameNode responsible for the subcluster. After it has identified the correct NameNode, the Router proxies the request. The client accesses Datanodes directly. ing
client通过Router方式请求文件过程
- nn状态定期维护:
Router监控本地namenode的状态、并定期(心跳)给State Store。- 找到子集群:当一个普通的DFS客户机通过任意的Router访问
federated filesystem中的文件时,Router检查State Store(即本地缓存)中的Mount Table,来找出哪个子集群包含该文件。- 找到负责的nn:然后,它检查
State Store中的Membership表,查找负责子集群的NameNode。在它识别了正确的NameNode之后,Router代理请求。客户端直接访问datanode。(参考client向namenode读写文件过程)
2. Router
There can be multiple Routers in the system with soft state. Each Router has two roles:
- Federated interface: expose a single, global NameNode interface to the clients and forward the requests to the active NameNode in the correct subcluster
- NameNode heartbeat: maintain the information about a NameNode in the State Store
系统中可以有多个(soft state的)Router,每个Router都有两个作用;
- 联邦接口:暴露单个、全局的namenode接口给客户端,将请求转发到正确子集群的active NameNode
- NameNode heartbeat:维护namenode的状态信息在 State Store。
2.1. Federated interface
The Router receives a client request, checks the State Store for the correct subcluster, and forwards the request to the active NameNode of that subcluster. The reply from the NameNode then flows in the opposite direction. The Routers are stateless and can be behind a load balancer. For health checking, you can use /isActive endpoint as a health probe (e.g. http://ROUTER_HOSTNAME:ROUTER_PORT/isActive). For performance, the Router also caches remote mount table entries and the state of the subclusters. To make sure that changes have been propagated to all Routers, each Router heartbeats its state to the State Store.
The communications between the Routers and the State Store are cached (with timed expiration for freshness). This improves the performance of the system.
Router接收到client的请求,确认正确子集群的State Store,然后将请求发送给指定子集群的namenode,然后接收namenode的response。路由器是无状态的,可以在负载均衡器后面。
- 对于健康检查,你可以使用
/isActive作为一个健康探针。- 对于性能方面,Router缓存远程挂载表入口和子集群的状态。为了保证改变能同步到所有的Routers,每个Routers给State Store层汇报其心跳。
Routers和State Store之间的通信被缓存(有一个刷新时间)。这样可以提高系统的性能。
2.2. Router heartbeat
Router周期性的汇报心跳给State Store。
2.3. NameNode heartbeat
For this role, the Router periodically checks the state of a NameNode (usually on the same server) and reports their high availability (HA) state and load/space status to the State Store. Note that this is an optional role, as a Router can be independent of any subcluster. For performance with NameNode HA, the Router uses the high availability state information in the State Store to forward the request to the NameNode that is most likely to be active. Note that this service can be embedded into the NameNode itself to simplify the operation.
Router周期性的检查namenode的状态,并将高可用状态、空间、负载等汇报给State Store。
注意:此功能不是必须的,Router可以独立于任何的子集群。
考虑到NameNode HA的使用性能,Router使用State Store中的高可用性状态信息将请求转发到最有可能处于活动状态的NameNode。注意,可以将此服务嵌入到NameNode本身以简化操作。
2.4. Availability and fault tolerance
The Router operates with failures at multiple levels.
- Federated interface HA: The Routers are stateless and metadata operations are atomic at the NameNodes. If a Router becomes unavailable, any Router can take over for it. The clients configure their DFS HA client (e.g., ConfiguredFailoverProvider or RequestHedgingProxyProvider) with all the Routers in the federation as endpoints.
- Unavailable State Store: If a Router cannot contact the State Store, it will enter into a Safe Mode state which disallows it from serving requests. Clients will treat Routers in Safe Mode as it was an Standby NameNode and try another Router. There is a manual way to manage the Safe Mode for the Router.
- Expired NameNodes: If a NameNode heartbeat has not been recorded in the State Store for a multiple of the heartbeat interval, the monitoring Router will record that the NameNode has expired and no Routers will attempt to access it. If an updated heartbeat is subsequently recorded for the NameNode, the monitoring Router will restore the NameNode from the expired state.
Router失败的几个级别
- 联邦接口高可用:router是无状态的,元数据操作在namenode操作时原子性的。如果一个router不可用,其他router将会接管。客户端(flink sql等)可以配置(比如
ConfiguredFailoverProvider或RequestHedgingProxyProvider)联邦中所有Router作为端点来实现HA客户端。- State Store不可用:如果Router不能与State Store通讯,router将会进入安全模式状态,即不允许处理请求。客户端将会将处于安全模式的Routers 看成 Standby NameNode,router将会尝试其他Router。这里有手工的方式管理Router的安全模式。
- 过期的NameNode:如果State Store 连续几次心跳间隔后没有接收到namenode的心跳,Router的监控将会记录NameNode已经过期,将不会有 Routers 访问它。
Interfaces
Router暴露了几个接口,以便与用户、管理员进行交互:
- RPC:Router RPC实现了客户端与HDFS交互最常见的接口
- Admin:管理员可以通过RPC添加或移除挂载表。
- Web UI :Router暴露了一个联邦状态的可视化界面。
- WebHDFS:除了 RPC 接口之外,路由器还提供 HDFS REST 接口 (WebHDFS)。
- JMX:通过JMX模仿namenode来暴露指标,Web UI 使用它来获取集群状态。
Router不支持以下操作,当遇见以下操作时将会抛出异常:
- 重命名、复制文件/文件夹在两个不同的namespace
- 写入正在重新平衡的文件/文件夹
3. Quota management
在挂载表级别,联邦支持全局quota(份额)的控制。考虑到性能方面,Router缓存quota的使用情况,并定时更新。当调用RouterRPCSever中的写RPC请求时,会进行quota使用情况的检查。
详细的见:See HDFS Quotas Guide for the quota detail.
4. State Store
State Store维护的内容:
- 维护子集群中块加载、磁盘可用率、HA情况等状态。
- 维护远程挂载表:子集群与文件夹/文件之间的映射。
State Store后端是可插拔的。以下是State Store主要的存储信息,以及其实现:
- Membership: 成员信息对namenodes的状态进行了编码,包括:子集群的存储容量、node的数量等。Router定期获取一个或多个namenode的信息。鉴于多个Routers可以监控同一个Namenode。当从State Store查询信息时,Router会从数据层面来仲裁,具体的:Router将会淘汰超过某个阈值的条目(例如,10个Router的心跳周期)。
- Mount Table: 包含了文件夹和子集群之间的映射。类似于ViewFS的映射表:指定联邦文件夹、目标子集群和该文件夹中的路径。
三、部署 ing
涉及到Router启动、挂载表管理、废除nameservice、Router定时刷新、客户端配置、namenode、Router配置与指标配置等。
参考官网:[[https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs-rbf/HDFSRouterFederation.html#Deployment]]
相关文章:
【HDFS联邦(2)】HDFS Router-based Federation官网解读:HDFSRouterFederation的架构、各组件基本原理
文章目录 一. 介绍二、HDFS Router-based Federation 架构1. 示例说明2. Router2.1. Federated interface2.2. Router heartbeat2.3. NameNode heartbeat2.4. Availability and fault toleranceInterfaces 3. Quota management4. State Store 三、部署 ing 本文主要参考官网&am…...

【头歌实训】Spark 完全分布式的安装和部署
文章目录 第1关: Standalone 分布式集群搭建任务描述相关知识课程视频Spark分布式安装模式示例集群信息配置免密登录准备Spark安装包配置环境变量修改 spark-env.sh 配置文件修改 slaves 文件分发安装包启动spark验证安装 编程要求测试说明答案代码报错问题基本过程…...
Leetcode—86.分隔链表【中等】
2023每日刷题(六十九) Leetcode—86.分隔链表 实现代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* partition(struct ListNode* head, int x) {struct ListNode…...

淘宝/天猫商品API:实时数据获取与安全隐私保护的指南
一、引言 随着电子商务的快速发展,淘宝/天猫等电商平台已成为商家和消费者的重要交易场所。对于电商企业而言,实时掌握店铺商品的销售情况、库存状态等信息至关重要。然而,手动管理和更新商品信息既费时又费力。因此,淘宝/天猫提…...
使用 SSH 方式实现 Git 远程连接GitHub
git是目前世界上最先进的分布式版本控制系统,相比于SVN,分布式版本系统的最大好处之一是在本地工作完全不需要考虑远程库的存在,也就是有没有联网都可以正常工作!当有网络的时候,再把本地提交推送一下就完成了同步&…...

Centos7部署Keepalived+lvs服务
IP规划: 服务器IP地址主服务器20.0.0.22/24从服务器20.0.0.24/24Web-120.0.0.26/24Web-220.0.0.27/24 一、主服务器安装部署keepalivedlvs服务 1、调整/proc响应参数 关闭Linux内核的重定向参数,因为LVS负载服务器和两个页面服务器需要共用一个VIP地…...
12/31
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract文献阅读:用于密集预测的多路径视觉Transformer1、研究背景2、方法提出3、相关方法3.1、Vision Transformers for dense predictions3.2、C…...
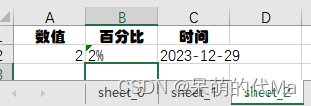
python使用openpyxl为excel模版填充数据,生成多个Sheet页面
目标:希望根据一个给定的excel模版,生成多个Sheet页面,比如模版: 示例程序 import openpyxlexcel_workbook openpyxl.load_workbook("模版.xlsx") for _i in range(3): # 比如填充3个页面# 复制模版sheet页&#x…...
基于ssm的4S店预约保养系统开发+vue论文
目 录 目 录 I 摘 要 III ABSTRACT IV 1 绪论 1 1.1 课题背景 1 1.2 研究现状 1 1.3 研究内容 2 2 系统开发环境 3 2.1 vue技术 3 2.2 JAVA技术 3 2.3 MYSQL数据库 3 2.4 B/S结构 4 2.5 SSM框架技术 4 3 系统分析 5 3.1 可行性分析 5 3.1.1 技术可行性 5 3.1.2 操作可行性 5 3…...
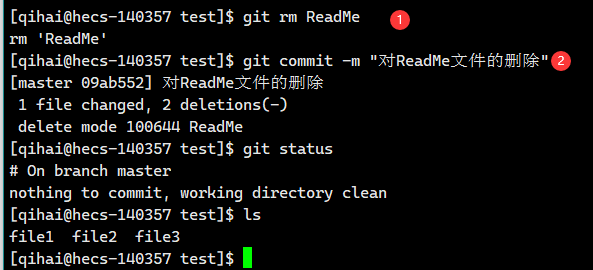
【Git】Git的基本操作
前言 Git是当前最主流的版本管理器,它可以控制电脑上的所有格式的文件。 它对于开发人员,可以管理项目中的源代码文档。(可以记录不同提交的修改细节,并且任意跳转版本) 本篇博客基于最近对Git的学习,简单介…...
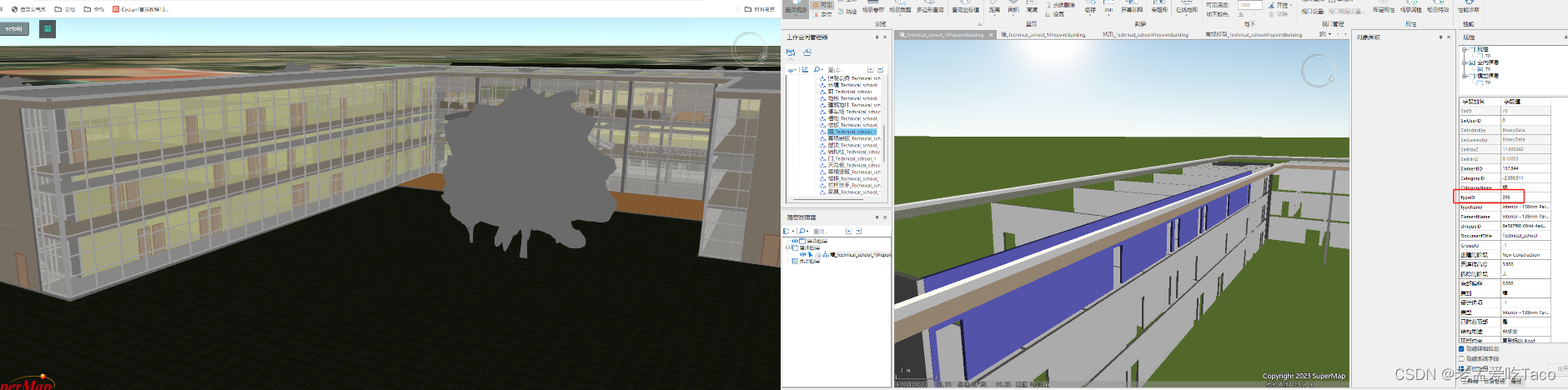
【超图】SuperMap iClient3D for WebGL/WebGPU —— 数据集合并缓存如何控制对象样式
作者:taco 最近在支持的过程中,遇到了一个新问题!之前研究功能的时候竟然没有想到。通常我们控制单个对象的显隐、颜色、偏移的参数都是根据对象所在的图层以及对象单独的id来算的。那么问题来了,合并后的图层。他怎么控制单个对象…...
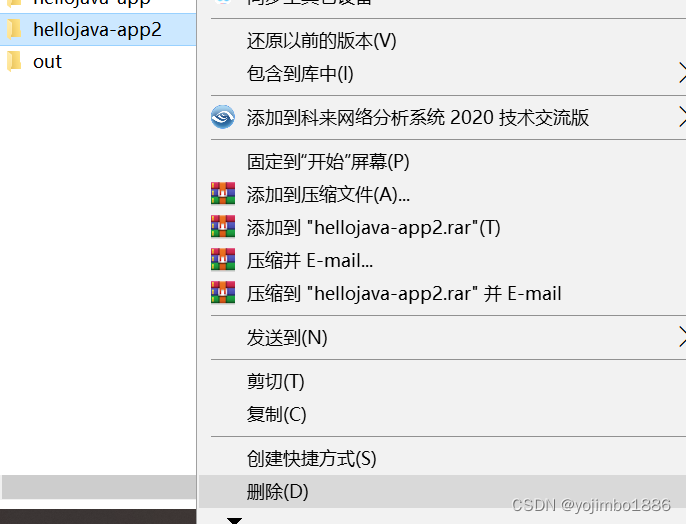
intellij IDEA开发工具的使用(打开/关闭工程;删除类文件;修改类/包/模块/项目名称;导入/删除模块)
1,打开工程 打开IDEA,会看到如下界面 1栏目里是自己曾经打开过的project(工程),直接点击就好。如果需要打开其他工程,则点击open,会出下以下界面。 选择需要加载的project(工程&…...
抖音详情API:开发环境搭建与工具选择
随着短视频的流行,抖音已经成为了一个备受欢迎的社交媒体平台。对于开发人员而言,利用抖音详情API开发定制化的抖音应用具有巨大的潜力。本文将为你详细介绍开发抖音应用的开发环境搭建与工具选择,帮助你顺利地开始开发工作。 一、开发环境搭…...
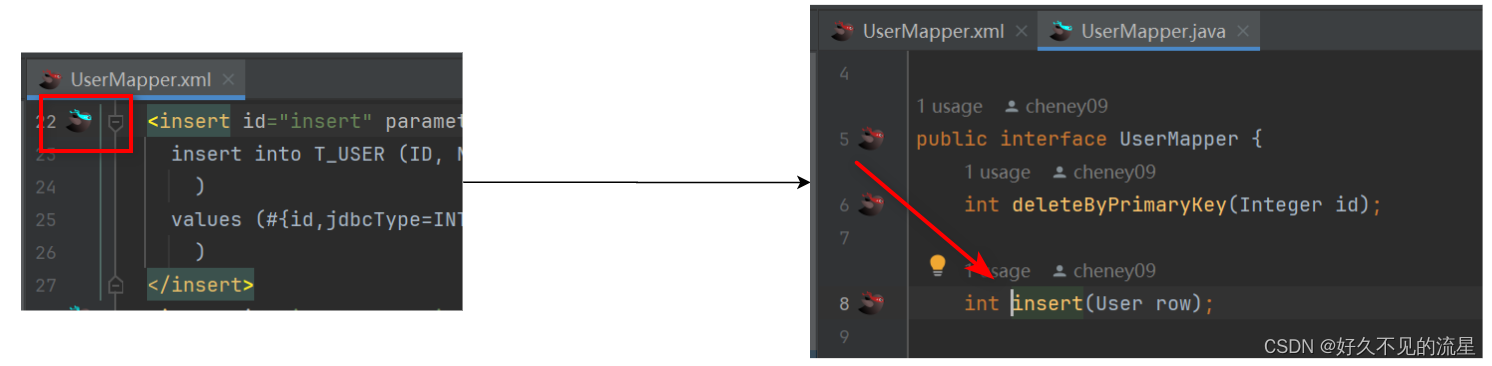
IntelliJ IDEA [插件 MybatisX] mapper和xml间跳转
文章目录 1. 安装插件2. 如何使用3. 主要功能总结 MybatisX 是一款为 IntelliJ IDEA 提供支持的 MyBatis 开发插件 它通过提供丰富的功能集,大大简化了 MyBatis XML 文件的编写、映射关系的可视化查看以及 SQL 语句的调试等操作。本文将介绍如何安装、配置和使用 In…...

Havenask 分布式索引构建服务 --Build Service
Havenask 是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了 Havenask 分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系…...
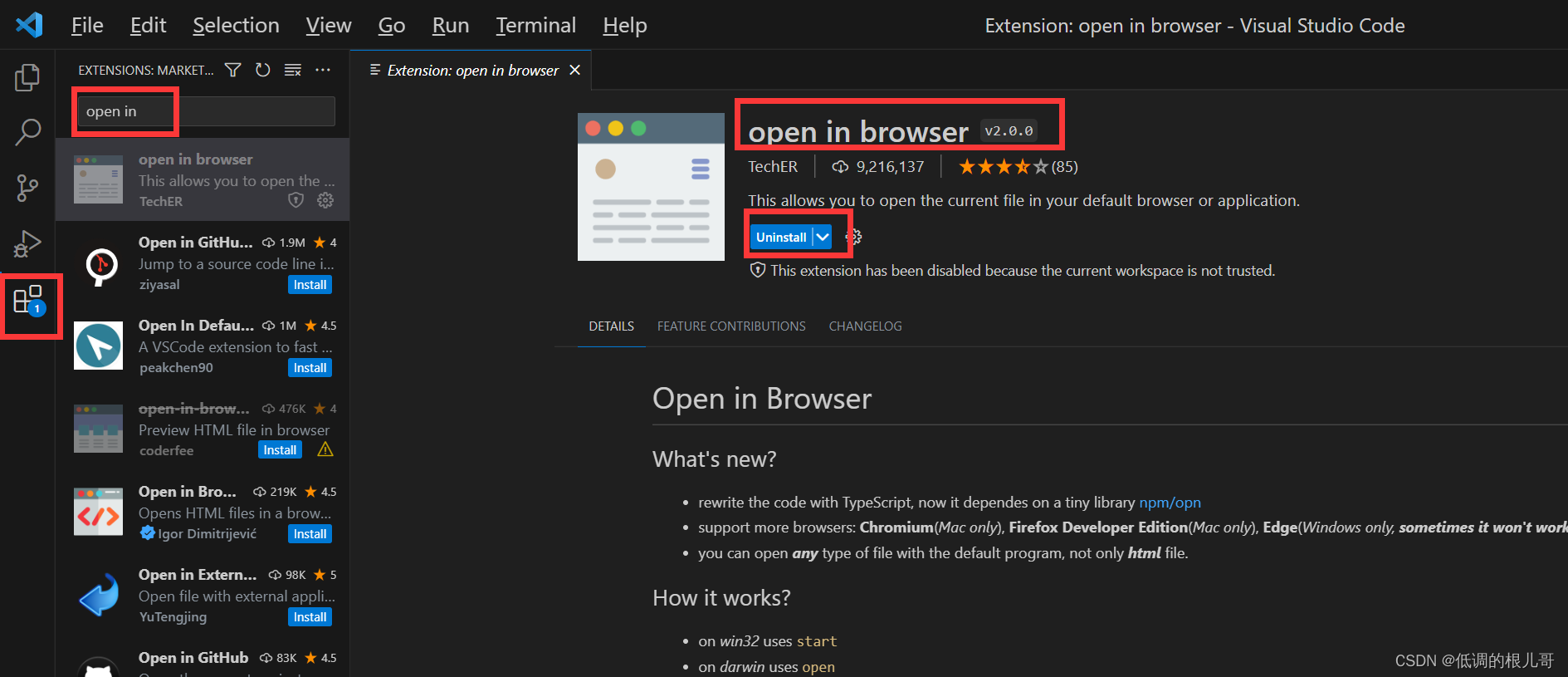
vscode软件安装步骤
目录 一、下载软件安装包 二、运行安装包后 一、下载软件安装包 打开vscode官方网址,找到下载界面 链接如下:Download Visual Studio Code - Mac, Linux, Windows 我是windows电脑,各位小伙伴自己选择合适的版本,点击下载按钮…...

C语言中灵活多变的动态内存,malloc函数 free函数 calloc函数 realloc函数
文章目录 🚀前言🚀管理动态内存的函数✈️malloc函数✈️free函数✈️calloc函数✈️realloc函数 🚀在使用动态内存函数时的常见错误✈️对NULL指针的解引用✈️ 对动态开辟空间的越界访问✈️对非动态开辟内存使用free释放✈️使用free释放一…...

小细节处理
重载运算符:重载<运算符。 bool operator<(const Edge&s)const{return w<s.w;}...

【42页动态规划学习笔记分享】动态规划核心原理详解及27道LeetCode相关经典题目汇总
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…...

Python正则的匹配与替换
import re 查找时的注意事项,要查找的内容左右两边打出来,用真正的字符,不要用.*?,离查找内容远一点,再用.*? a /aksj<a>哈哈哈<a><p>拉阿鲁<p>\.askjp b re.findall(<a>(.*?)<…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...