SpringBoot集成DruidDataSource实现监控 SQL 性能

一、快速入门
1.1 基本概念
我们都使用过连接池,比如C3P0、DBCP、hikari、Druid,虽然 HikariCP 的速度稍快,但 Druid 能够提供强大的监控和扩展功能。Druid DataSource 是阿里巴巴开发的号称为监控而生的数据库连接池,它不仅可以获取数据库连接,还把这些数据库连接管理了起来,也就是所谓的数据库连接池。在功能、性能、扩展性方面,都超过其他数据库连接池,可以说是 Java 语言中最好的数据库连接池。
Spring Boot 2.0 以上默认使用 Hikari 数据源,而Druid已经在阿里巴巴部署了超过600个应用,经过好几年生产环境大规模部署的严苛考验!Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
- Github项目地址 https://github.com/alibaba/druid
- 文档 https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
- 下载 http://repo1.maven.org/maven2/com/alibaba/druid/
- 监控DEMO http://120.26.192.168/druid/index.html
1.2 如何使用 DruidDataSource
首先看一下怎么使用 DruidDataSource。
// 配置一个 DruidDataSource 实例 bean 交由 Spring 容器管理
@Configuration
public class DataSourceConfig {@Beanpublic DataSource dataSource() {DruidDataSource dataSource = new DruidDataSource();dataSource.setUsername("root");dataSource.setPassword("123456");dataSource.setUrl("jdbc:mysql://localhost:3306/transaction?useSSL=false");dataSource.setDriverClassName("com.mysql.jdbc.Driver");//连接池最小空闲的连接数dataSource.setMinIdle(5);//连接池最大活跃的连接数dataSource.setMaxActive(20);//初始化连接池时创建的连接数dataSource.setInitialSize(10);return dataSource;}
}//测试类
public class DataSourceMain {public static void main(String[] args) {AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(DataSourceConfig.class);//获取 dataSource 实例DataSource dataSource = (DataSource) applicationContext.getBean("dataSource");try {//通过数据源获取数据库连接Connection connection = dataSource.getConnection();Statement statement = connection.createStatement();statement.execute("update AccountInfo set balance = balance + 1 where id = 1");} catch (SQLException throwables) {throwables.printStackTrace();}}
}
从上可以看出,通过数据源访问跟 jdbc 方式相比,省略了实例化数据库连接驱动 Driver 驱动这一步,此外调用 getConnection() 获取连接的时候,并没有传用户名和密码,说明 dataSource 把这些配置信息都管理起来了。总结来说,DruidDataSource 管理了数据库连接的一些配置信息,还帮助我们创建了连接驱动 Driver,剩下的逻辑就跟 jdbc 一毛一样了。
1.3 通用配置
DruidDataSource大部分属性都是参考DBCP的,个别配置的语意有所区别。如果你原来就是使用DBCP,迁移是十分方便的。
com.alibaba.druid.pool.DruidDataSource
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 如果存在多个数据源,监控的时候可以通过名字来区分开来 | |
| url | 连接数据库的url,不同数据库不一样 | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。 如果不希望密码直接写在配置文件中,可以使用ConfigFilter | |
| driverClassName | 这一项可配可不配,根据url自动识别 | |
| maxActive | 8 | 最大连接池数量 |
| initialSize | 0 | 初始化时建立连接的个数 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。 | |
| filters | 监控统计拦截的filters | |
| timeBetweenEvictionRunsMillis | 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 | |
| minEvictableIdleTimeMillis | 一个连接在池中最小生存的时间,单位是毫秒 | |
| maxEvictableIdleTimeMillis | 一个连接在池中最大生存的时间,单位是毫秒 | |
| validationQuery | 用来检测连接是否有效的sql。 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用 | |
| validationQueryTimeout | 检测连接是否有效的超时时间,单位:秒 | |
| testWhileIdle | 如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,配置后会降低性能 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,配置后会降低性能 |
| keepAlive | false | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| poolPreparedStatements | false | 是否缓存preparedStatement |
| maxOpenPreparedStatements | -1 | 是否要启用PSCache。当大于0时,启用。 |
| asyncInit | false | |
| connectionInitSqls | 物理连接初始化的时候执行的sql |
1.4 内置Filter的别名
在META-INF/druid-filter.properties文件中配置Filter的别名。
| Filter类名 | 别名 |
|---|---|
| default | com.alibaba.druid.filter.stat.StatFilter |
| stat | com.alibaba.druid.filter.stat.StatFilter |
| mergeStat | com.alibaba.druid.filter.stat.MergeStatFilter |
| encoding | com.alibaba.druid.filter.encoding.EncodingConvertFilter |
| log4j | com.alibaba.druid.filter.logging.Log4jFilter |
| log4j2 | com.alibaba.druid.filter.logging.Log4j2Filter |
| slf4j | com.alibaba.druid.filter.logging.Slf4jLogFilter |
| commonlogging | com.alibaba.druid.filter.logging.CommonsLogFilter |
| wall | com.alibaba.druid.wall.WallFilter |
二、相关配置
2.1 添加依赖
首先我们需要在应用的 pom.xml 文件中添加上 Druid 数据源依赖,可以从 Maven 仓库官网 中获取。
<!-- Druid 数据源依赖,集成了 Spring boot ,方便配置 druid 属性 -->
<!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot-starter -->
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version>
</dependency><!-- Mysql 数据库驱动,spring boot 2.1.3 时,mysql 驱动版本为 8.0.15 -->
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope>
</dependency><!--引用 log4j2 spring boot 启动器,内部依赖了 slf4j、log4j;排除项目中的 logback-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId>
</dependency><!-- mybatis,引入了 SpringBoot的 JDBC 模块,所以,默认是使用 hikari 作为数据源 -->
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.0.1</version><exclusions><!-- 排除默认的 HikariCP 数据源 --><exclusion><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId></exclusion></exclusions>
</dependency>
2.2 配置数据源相关属性
2.2.1 配置Druid 数据源
从 Spring Boot 2.0 开始,默认使用 com.zaxxer.hikari.HikariDataSource 数据源,但其中有一个十分重要的条件,如下图。

@ConditionalOnMissingBean(DataSource.class) 的含义是:当容器中没有 DataSource 时,Spring Boot 才会使用 HikariCP 作为其默认数据源。 也就是说,若向容器中添加 Druid 数据源类的对象时,Spring Boot 就会使用 Druid 作为其数据源,而不再使用 HikariCP。在配置文件 application.yml 中添加以下数据源配置,它们会与与 Druid 数据源中的属性进行绑定,如下所示:
spring:datasource:username: rootpassword: root# driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=trueplatform: mysqltype: com.alibaba.druid.pool.DruidDataSource
com.alibaba.druid.pool.DruidDataSource 基本配置参数,如下所示:
| 配置 | 说明 |
|---|---|
| jdbcUrl | 连接数据库的url,多数据源时使用,不同数据库不一样 |
| url | 连接数据库的url,单数据源时使用,不同数据库不一样 |
| username | 连接数据库的用户名 |
| password | 连接数据库的密码 |
| driverClassName | 这一项可配可不配,不配置时druid会根据url自动识别dbType,然后选择相应的driverClassName |
| connectionInitSqls | 连接初始化的时候执行的sql |
| exceptionSorter | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
注:配置类创建 Druid 数据源对象时,应该尽量避免将数据源信息硬编码到代码中,而应该通过@ConfigurationProperties(“spring.datasource”) 注解,将 Druid 数据源对象的属性与配置文件中的以“spring.datasource”开头的配置进行绑定。
至此,我们就已经将数据源从 HikariCP 切换到了 Druid 了。
2.2.2 Druid 数据源测试
当数据源配置之后,我们需要来验证数据源类型是否为 Druid 以及是否能正常获取数据库连接、访问数据库,代码如下。
import com.alibaba.druid.pool.DruidDataSource;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import javax.annotation.Resource;
import javax.sql.DataSource;
import java.sql.*;/*** 把今天最好的表现当作明天最新的起点..~* <p>* Today the best performance as tomorrow the newest starter!** @类描述: 数据源测试,测试 spring.datasource.xx 的 druid 属性配置是否正常,数据库是否能连接上等等* @author: <a href="mailto:duleilewuhen@sina.com">独泪了无痕</a>* @创建时间: 2023-02-28 00:48* @版本: V 1.0.1* @since: JDK 1.8*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class DataSourceTest {/*** Spring Boot 默认已经配置好了数据源,可以直接 DI 注入然后使用即可*/@Resourceprivate DataSource dataSource;@Testpublic void contextLoads() throws SQLException {System.out.println("数据源>>>>>>" + dataSource.getClass());Connection connection = dataSource.getConnection();System.out.println("连接>>>>>>>>>" + connection);System.out.println("连接地址>>>>>" + connection.getMetaData().getURL());if (dataSource instanceof DruidDataSource) {DruidDataSource druidDataSource = (DruidDataSource) dataSource;System.out.println("druidDataSource 数据源最大连接数:" + druidDataSource.getMaxActive());System.out.println("druidDataSource 数据源初始化连接数:" + druidDataSource.getInitialSize());System.out.println("version=" + druidDataSource.getVersion());System.out.println("name=" + druidDataSource.getName());}connection.close();}
}
2.3 自定义 Druid 数据源
2.3.1 Druid 数据源参数配置
如同以前 c3p0、dbcp 数据源可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等一样,Druid 数据源同理可以进行设置。Druid Spring Boot Starter 配置属性的名称完全遵照 Druid,可以通过 Spring Boot 配置文件来配置Druid数据库连接池和监控,如果没有配置则使用默认值,如下在 application.yml 配置相关属性:
spring:datasource:# druid 数据源专有配置,对应的是 com.alibaba.druid.pool.DruidDataSource 中的属性druid:# 数据源名称:当存在多个数据源时,设置名字可以很方便的来进行区分,默认自动生成名称,格式是:"DataSource-" + System.identityHashCode(this)name: druid-db1# 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时,默认0initialSize: 10# 最大连接池数量,默认8maxActive: 200# 最小连接池数量minIdle: 10# 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁maxWait: 60000# 1)Destroy线程会检测连接的间隔时间 2)testWhileIdle的判断依据(详细看testWhileIdle属性的说明)timeBetweenEvictionRunsMillis: 60000# 设置连接最小可收回空闲时间(毫秒),默认为 1000L * 60L * 30LminEvictableIdleTimeMillis: 300000# 设置连接最大可收回空闲时间(毫秒),默认为 1000L * 60L * 60L * 7maxEvictableIdleTimeMillis: 900000# 用来检测连接是否有效的sql,求是一个查询语句。默认为null,此时testOnBorrow、testOnReturn、testWhileIdle都不会其作用validationQuery: SELECT 1 FROM DUAL# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效,默认为truetestWhileIdle: true# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能,默认falsetestOnBorrow: false# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能,默认falsetestOnReturn: false# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。poolPreparedStatements: true# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true,# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100maxOpenPreparedStatements: 20# 连接池中的 minIdle 数量以内的连接,空闲时间超过 minEvictableIdleTimeMillis,则会执行 keepAlive 操作keepAlive: true# 每个连接大小的最大池准备语句数maxPoolPreparedStatementPerConnectionSize: 20# 是否使用全局数据源统计,默认falseuseGlobalDataSourceStat: true# 连接属性connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500# 配置监控统计的内置过滤器:# stat-监控统计(必须配置,否则监控不到sql)# wall-防御sql注入# log4j2-日志记录框架(值与应用中的日志框架保持一致,如 log4j、log4j、logback、slf4j)filters: stat,wall,log4j2
现在可以重新测试 Druid 数据源,查看配置文件中的参数是否已经生效,也可以直接 Debug 查看 DruidDataSource 的属性。
2.3.2 配置 Druid 数据源监控
这个过滤器的作用就是统计 web 应用请求中所有的数据库信息,比如 发出的 sql 语句,sql 执行的时间、请求次数、请求的 url 地址、以及seesion 监控、数据库表的访问次数 等等。可以通过 spring.datasource.druid.filters=stat,wall,log4j ...的方式来启用相应的内置Filter,不过这些Filter都是默认配置。如果默认配置不能满足需求,可以放弃这种方式,通过配置文件来配置Filter,下面是例子。
########## JDBC基本配置 ##########spring.datasource.username=developer
# spring.datasource.druid.username
spring.datasource.password=developer
# mysql的连接驱动
# spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# spring.datasource.druid.url
spring.datasource.url=jdbc:mysql://localhost:3306/opensource?useUnicode=true&characterEncoding=UTF-8&useSSL=true
# 数据库类型
spring.datasource.platform=mysql
# 指定数据源类型
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource########## druid数据源专有配置,对应的是com.alibaba.druid.pool.DruidDataSource中的属性
# 配置监控统计的内置过滤器:
spring.datasource.druid.filters=stat,wall,slf4j##########自定义过滤器配置:stat、slf4j、log4j、log4j2、commons-log、wal
# 内置Filter都是默认配置,无法满足需求时,则可以自定义Filter,自定义的过滤器默认都是没有开启的# 开启DruidDataSource的状态监控,必须配置,否则监控不到sql
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.db-type=mysql
# 开启慢sql监控,超过2s就认为是慢sql,记录到日志中
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=2000########## 日志监控,使用slf4j进行日志输出spring.datasource.druid.filter.slf4j.enabled=true
spring.datasource.druid.filter.slf4j.statement-log-error-enabled=true
spring.datasource.druid.filter.slf4j.statement-create-after-log-enabled=false
spring.datasource.druid.filter.slf4j.statement-close-after-log-enabled=false
spring.datasource.druid.filter.slf4j.result-set-open-after-log-enabled=false
spring.datasource.druid.filter.slf4j.result-set-close-after-log-enabled=false# 防火墙过滤器,防御sql注入
spring.datasource.druid.filter.wall.enabled=true
# 不允许删除数据
spring.datasource.druid.filter.wall.config.delete-allow=false##########配置WebStatFilter,用于采集web关联监控的数据########### 是否启用StatFilter默认值false
spring.datasource.druid.web-stat-filter.enabled=true
# 过滤所有url
spring.datasource.druid.web-stat-filter.url-pattern=/*
# 排除一些不必要的url
spring.datasource.druid.web-stat-filter.exclusions="*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"
# 开启session统计功能
spring.datasource.druid.web-stat-filter.session-stat-enable=true
# session的最大个数,默认100
spring.datasource.druid.web-stat-filter.session-stat-max-count=1000
# 使得druid能够知道当前的session的用户是谁
# spring.datasource.druid.web-stat-filter.principal-session-name=
# 如果你的user信息保存在cookie中,你可以配置principalCookieName,使得druid知道当前的user是谁
# spring.datasource.druid.web-stat-filter.principal-cookie-name=
# 配置profileEnable能够监控单个url调用的sql列表
# spring.datasource.druid.web-stat-filter.profile-enable=########## 配置StatViewServlet(监控页面),用于展示Druid的统计信息 ########### 是否启用StatViewServlet(监控页面)默认值为false
spring.datasource.druid.stat-view-servlet.enabled=true
# 访问内置监控页面的路径,内置监控页面的首页是/druid/index.html
spring.datasource.druid.stat-view-servlet.url-pattern=/druid/*
# 不允许清空统计数据,重新计算
spring.datasource.druid.stat-view-servlet.reset-enable=false
# 配置监控页面访问用户名
spring.datasource.druid.stat-view-servlet.loginUsername=root
# 配置监控页面访问密码
spring.datasource.druid.stat-view-servlet.loginPassword=123
# 允许访问的地址,如果allow没有配置或者为空,则允许所有访问
spring.datasource.druid.stat-view-servlet.allow=127.0.0.1
# 拒绝访问的地址,deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝
spring.datasource.druid.stat-view-servlet.deny=
不想使用内置的 Filters,要想使自定义 Filter 配置生效需要将对应 Filter 的 enabled 设置为 true ,Druid Spring Boot Starter 默认禁用 StatFilter,可以将其 enabled 设置为 true 来启用它。
2.3.3 Druid 内置 Filter 配置
Druid Spring Boot Starter 对以下 Druid 内置 Filter,都提供了默认配置StatFilter、WallFilter、ConfigFilter、EncodingConvertFilter、Slf4jLogFilter、Log4jFilter、Log4j2Filter、CommonsLogFilter。我们可以通过 spring.datasource.druid.filters=stat,wall … 的方式来启用相应的内置 Filter,不过这些 Filter 使用的都是默认配置。如果默认配置不能满足我们的需求,我们还可以在配置文件使用 spring.datasource.druid.filter.* 对这些 Filter 进行配置,示例代码如下。
# ####################################################### Druid 监控配置信息 ##########################################
spring:datasource:druid:# 对配置已开启的 filters 即 stat(sql 监控) wall(防火墙)filter:#配置StatFilter (SQL监控配置)stat:enabled: true #开启 SQL 监控slow-sql-millis: 1000 #慢查询log-slow-sql: true #记录慢查询 SQL#配置WallFilter (防火墙配置)wall:enabled: true #开启防火墙config:update-allow: true #允许更新操作drop-table-allow: false #禁止删表操作insert-allow: true #允许插入操作delete-allow: true #删除数据操作
在配置 Druid 内置 Filter 时,需要先将对应 Filter 的 enabled 设置为 true,否则内置 Filter 的配置不会生效。
2.4 Druid 内置监控页面
Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装路由器时,人家也提供了一个默认的 web 页面。首先需要设置 Druid 的后台管理页面的属性,比如登录账号、密码等。
2.4.1 开启 Druid 内置监控
Druid 内置提供了一个名为 StatViewServlet 的 Servlet,这个 Servlet 可以开启 Druid 的内置监控页面功能, 展示 Druid 的统计信息,它的主要用途可以提供监控信息展示的 html 页面、提供监控信息的 JSON API等。StatViewServlet 是一个标准的 javax.servlet.http.HttpServlet,想要开启 Druid 的内置监控页面,我们可以在配置类中,通过 ServletRegistrationBean 将 StatViewServlet 注册到容器中,来开启 Druid 的内置监控页面。
spring:datasource:druid:stat-view-servlet:enabled: true # 启用StatViewServleturl-pattern: /druid/* # 访问内置监控页面的路径,内置监控页面的首页是/druid/index.htmlreset-enable: false # 不允许清空统计数据,重新计算loginUsername: root # 配置监控页面访问用户login-password: 123 # 配置监控页面访问密码allow: 127.0.0.1 # 允许访问的地址,如果allow没有配置或者为空,则允许所有访问deny: # 拒绝访问的地址,deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝
启动 Spring Boot 项目后,浏览器访问 http://localhost:8080/druid/login.html ,即可访问 Druid 的内置监控页面的登录页,如下图所示。

在登录页中,分别输入自定义的用户名和密码,用户和密码对应我们的配置文件中设置的用户名(loginUsername)和密码(loginPassword)。输入用户名密码登录进去可以看到里面有很多监控,如下所示:

2.4.2 数据源
数据源页面是当前DataSource配置的基本信息,上述配置的Filter可以在里面找到,如果没有配置Filter(一些信息会无法统计,例如“SQL监控”,会无法获取JDBC相关的SQL执行信息)

2.4.3 SQL 监控
Druid 内置提供了一个 StatFilter,通过它可以开启 Druid 的 SQL 监控功能,对 SQL 进行监控。SQL监控页面统计了所有SQL语句的执行情况,执行时间、读取行数、更新行数都有区间分布,如下图所示。

StatFilter 的别名是 stat,这个别名的映射配置信息保存在 druid-xxx.jar!/META-INF/druid-filter.properties 中。Druid 官方文档-配置_StatFilter 中给出了在 Spring 中配置该别名(stat)开启 Druid SQL 监控的方式,配置如下。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">... ...<property name="filters" value="stat" />
</bean>
根据以上配置我们可以看出,只要在 dataSource 的 Bean 中添加一个取值为“stat”的“filters”属性,就能开启 Druid SQL 监控。
spring:datasource:druid:filter:stat:enabled: true # 开启DruidDataSource状态监控db-type: mysql # 数据库的类型log-slow-sql: true # 开启慢SQL记录功能slow-sql-millis: 2000 # 默认3000毫秒,这里超过2s,就是慢,记录到日志
2.4.4 Web 应用
Druid 还内置提供了一个名为 WebStatFilter 的过滤器,它可以用来监控与采集 web-jdbc 关联监控的数据。根据 Druid 官方文档-配置_配置WebStatFilter,想要开启 Druid 的 Web-JDBC 关联监控,只需要将 WebStatFilter 配置在 Web 应用中的 WEB-INF/web.xml 中即可,web.xml 配置如下。
<filter><filter-name>DruidWebStatFilter</filter-name><filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class><init-param><param-name>exclusions</param-name><param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value></init-param>
</filter>
<filter-mapping><filter-name>DruidWebStatFilter</filter-name><url-pattern>/*</url-pattern>
</filter-mapping>
Spring Boot 项目中是没有 WEB-INF/web.xml 的,但是我们可以在配置类中,通过 FilterRegistrationBean 将 WebStatFilter 注入到容器中,来开启 Druid 的 Web-JDBC 关联监控。
spring:datasource:druid:web-stat-filter:enabled: true # 启动 StatFilterurl-pattern: /* # 过滤所有urlexclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除一些不必要的urlsession-stat-enable: true # 开启session统计功能session-stat-max-count: 1000 # session的最大个数,默认100
浏览器访问系统的任意页面,然后再访问 Druid 的内置监控页面,切换到 Web 应用模块,可以看到 Druid 的 Web 监控已经开启,与此同时,URI 监控和 Session 监控也都被开启。
2.4.5 URL 监控
URL监控页面统计了所有Controller接口的访问以及执行情况。这里可以很清晰的看到,每个url涉及到的数据库执行的信息。

2.4.6 Session 监控
Session监控页面 可以看到当前的session状况,创建时间、最后活跃时间、请求次数、请求时间等详细参数。
2.4.7 Spring 监控
Spring 监控页面,利用aop 对指定接口的执行时间,jdbc数进行记录

访问之后 Spring 监控默认是没有数据的,Spring 监控是用于通过 aop 切面对指定类及方法进行监控,这需要导入SprngBoot的AOP的Starter,如下所示:
<!--SpringBoot 的aop 模块-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId>
</dependency>
然后在 application.yml 配置 Spring 监控 AOP 切入点,如 com.springboot.template.dao.*,配置多个英文逗号分隔,例如如下所示:
spring:datasource:druid:aop-patterns:"com.springboot.template.dao.*" # Spring监控AOP切入点,多个时用英文逗号分隔

2.4.8 SQL 防火墙
Druid 内置提供了一个 WallFilter,使用它可以开启防火墙功能,防御 SQL 注入攻击。WallFilter 的别名是 wall,这个别名映射配置信息保存在 druid-xxx.jar!/META-INF/druid-filter.properties 中。Druid 官方文档-配置 wallfilter 中给出了在 Spring 中使用该别名(wall)开启防火墙的方式,配置如下。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">... ...<property name="filters" value="wall" />
</bean>
WallFilter 可以结合其他 Filter 一起使用,例如:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">...<property name="filters" value="wall,stat"/>
</bean>
根据以上配置我们可以看出,只要在 dataSource 的 Bean 中添加一个取值为“wall”的“filters”属性,就能开启 Druid 的防火墙功能,因此我们只需要在配置类中为 dataSource 的 filters 属性再添加一个“wall”即可(多个属性值之间使用逗号“,”隔开),代码如下。
spring:datasource:druid:filters: stat,wall,slf4j
访问 Druid 的内置监控页面,切换到 SQL 防火墙,可以看到 Druid 防火墙已经开启。SQL防火墙页面 druid提供了黑白名单的访问,可以清楚的看到sql防护情况。
2.4.9 JSON API
JSONAPI 页面 通过api的形式访问Druid的监控接口,api接口返回Json形式数据。
三、自定义DruidDataSource
3.1 去广告
访问监控页面的时候,可能会在页面底部(footer)看到内置的广告,如下所示。这是因为引入的druid的 druid-x.y.z.jar 包中的 common.js(里面有一段js代码是给页面的footer追加广告的)。如果想去掉,有两种方式:

-
直接手动注释这段代码
如果是使用Maven,直接到本地仓库中,查找这个 druid-x.y.z.jar 包,然后用压缩工具打开,找到 support/http/resources/js/common.js,然后注释掉里面的代码 或者修改为自己的页脚内容。
// this.buildFooter();
-
使用过滤器过滤
注册一个过滤器,过滤
common.js的请求,使用正则表达式替换相关的广告内容,如下代码所示:@Configuration @ConditionalOnWebApplication @AutoConfigureAfter(DruidDataSourceAutoConfigure.class) @ConditionalOnProperty(name = "spring.datasource.druid.stat-view-servlet.enabled", havingValue = "true", matchIfMissing = true) public class RemoveDruidAdConfig {/*** 除去页面底部的广告*/@Beanpublic FilterRegistrationBean removeDruidAdFilterRegistrationBean(DruidStatProperties properties) {// 获取web监控页面的参数DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();// 提取common.js的配置路径String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*";String commonJsPattern = pattern.replaceAll("\\*", "js/common.js");final String filePath = "support/http/resources/js/common.js";//创建filter进行过滤Filter filter = new Filter() {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {chain.doFilter(request, response);// 重置缓冲区,响应头不会被重置response.resetBuffer();// 获取common.jsString text = Utils.readFromResource(filePath);// 正则替换banner, 除去底部的广告信息text = text.replaceAll("<a.*?banner\"></a><br/>", "");text = text.replaceAll("powered.*?shrek.wang</a>", "");response.getWriter().write(text);}@Overridepublic void destroy() {}};FilterRegistrationBean registrationBean = new FilterRegistrationBean();registrationBean.setFilter(filter);registrationBean.addUrlPatterns(commonJsPattern);return registrationBean;} }
两种方式都可以,建议使用的是第一种,从根源解决。
3.2 取 Druid 的监控数据
Druid 的监控数据不仅可以在页面上查看,在 开启 StatFilter 后 ,也可以通过 DruidStatManagerFacade 类进行获取。其中 getDataSourceStatDataList 方法可以获取所有数据源的监控数据,除此之外 DruidStatManagerFacade 还提供了一些其他方法,可以按需选择使用。
@RestController
@RequestMapping(value = "/druid")
public class DruidStatController {/*** Spring Boot 默认已经配置好了数据源,程序员可以直接 DI 注入然后使用即可*/@Resourceprivate DataSource dataSource;/*** 获取 druid 数据监控信息,其中统计了所有数据源的所有详细信息。*/@GetMapping("/stat")public List<Map<String, Object>> druidStat(){// 获取数据源的监控数据return DruidStatManagerFacade.getInstance().getDataSourceStatDataList();}/*** 使用 DruidDataSource API 获取具体数据源的指定的监控信息。*/@GetMapping("/druidDataSource")public Map<String, Object> druidDataSource() {Map<String, Object> dataMap = new HashMap<>();dataMap.put("class", dataSource.getClass());if (dataSource instanceof DruidDataSource) {DruidDataSource druidDataSource = (DruidDataSource) dataSource;dataMap.put("version", druidDataSource.getVersion());dataMap.put("name", druidDataSource.getName());dataMap.put("initialSize", druidDataSource.getInitialSize());dataMap.put("maxActive", druidDataSource.getMaxActive());dataMap.put("minIdle", druidDataSource.getMinIdle());dataMap.put("activeCount", druidDataSource.getActiveCount());dataMap.put("activePeak", druidDataSource.getActivePeak());dataMap.put("activePeakTime", druidDataSource.getActivePeakTime());dataMap.put("poolingCount", druidDataSource.getPoolingCount());dataMap.put("poolingPeak", druidDataSource.getPoolingPeak());dataMap.put("poolingPeakTime", druidDataSource.getPoolingPeakTime());}return dataMap;}
}
获取 druid 数据监控信息
| 参数名 | 描述 |
|---|---|
| ActiveCount | 当前连接池中活跃连接数 |
| ActivePeak | 连接池中活跃连接数峰值 |
| ActivePeakTime | 活跃连接池峰值出现的时间 |
| BlobOpenCount | Blob 打开数 |
| ClobOpenCount | Clob 打开数 |
| CommitCount | 提交数 |
| DbType | 数据库类型 |
| DefaultAutoCommit | 是否默认提交 |
| DiscardCount | 放弃/丢弃的个数 |
| DriverClassName | 驱动类 |
| ErrorCount | 错误数 |
| ExceptionSorterClassName | 异常分类器类名 |
| ExecuteBatchCount | 执行批次计数 |
| ExecuteCount | 执行总数 |
| ExecuteQueryCount | 执行查询计数 |
| ExecuteUpdateCount | 执行更新计数 |
| FailFast | 是否快速失败 |
| FilterClassNames | 过滤器类名称 |
| Identity | |
| InitGlobalVariants | 初始全局变量 |
| InitVariants | 初始变量 |
| InitialSize | 连接池建立时创建的初始化连接数 |
| KeepAlive | 是否保持活跃 |
| KeepAliveCheckCount | 保持活动检查计数 |
| LogDifferentThread | 记录不同的线程 |
| LogicCloseCount | 产生的逻辑连接关闭总数 |
| LogicConnectCount | 产生的逻辑连接建立总数 |
| LogicConnectErrorCount | 产生的逻辑连接出错总数 |
| LoginTimeout | 数据库客户端登录超时时间 |
| MaxActive | 连接池中最大的活跃连接数 |
| MaxEvictableIdleTimeMillis | 最大可收回空闲时间(毫秒) |
| MaxWait | 最大等待时间 |
| MaxWaitThreadCount | 最大等待线程计数 |
| MinEvictableIdleTimeMillis | 最小可执行时间Mill |
| MinIdle | 连接池中最小的活跃连接数 |
| Name | 数据源名称 |
| NotEmptyWaitCount | 获取连接时最多等待多少次 |
| NotEmptyWaitMillis | 获取连接时最多等待多长时间,毫秒为单位 |
| PSCacheAccessCount | PSCache访问总数 |
| PSCacheHitCount | PSCache命中次数 |
| PSCacheMissCount | PSCache未命中次数 |
| PhysicalCloseCount | 产生的物理关闭总数 |
| PhysicalConnectCount | 产生的物理连接建立总数 |
| PhysicalConnectErrorCount | 产生的物理连接失败总数 |
| PoolPreparedStatements | 预编译准备语句 |
| PoolingCount | 当前连接池中的连接数 |
| PoolingPeak | 连接池中连接数的峰值 |
| PoolingPeakTime | 连接池数目峰值出现的时间 |
| PreparedStatementClosedCount | 预编译准备语句关闭计数 |
| PreparedStatementOpenCount | 准备语句打开计数 |
| QueryTimeout | 查询超时数 |
| RecycleErrorCount | 回收错误计数 |
| RemoveAbandoned | 已删除 |
| RollbackCount | 回滚数 |
| StartTransactionCount | 事务开始的个数 |
| TestOnBorrow | |
| TestOnReturn | |
| TestWhileIdle | |
| TransactionQueryTimeout | 事务查询超时数 |
| URL | 数据库连接地址 |
| UseUnfairLock | 使用不公平锁定 |
| UserName | 数据库连接账号 |
| WaitThreadCount | 当前等待获取连接的线程数 |
3.3 使用log4j2进行日志输出
-
log4j2.xml文件中的日志配置
<?xml version="1.0" encoding="UTF-8"?> <configuration status="OFF"><appenders><Console name="Console" target="SYSTEM_OUT"><!--只接受程序中DEBUG级别的日志进行处理--><ThresholdFilter level="DEBUG" onMatch="ACCEPT" onMismatch="DENY"/><PatternLayout pattern="[%d{HH:mm:ss.SSS}] %-5level %class{36} %L %M - %msg%xEx%n"/></Console><!--处理DEBUG级别的日志,并把该日志放到logs/debug.log文件中--><!--打印出DEBUG级别日志,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档--><RollingFile name="RollingFileDebug" fileName="./logs/debug.log"filePattern="logs/$${date:yyyy-MM}/debug-%d{yyyy-MM-dd}-%i.log.gz"><Filters><ThresholdFilter level="DEBUG"/><ThresholdFilter level="INFO" onMatch="DENY" onMismatch="NEUTRAL"/></Filters><PatternLayoutpattern="[%d{yyyy-MM-dd HH:mm:ss}] %-5level %class{36} %L %M - %msg%xEx%n"/><Policies><SizeBasedTriggeringPolicy size="500 MB"/><TimeBasedTriggeringPolicy/></Policies></RollingFile><!--处理INFO级别的日志,并把该日志放到logs/info.log文件中--><RollingFile name="RollingFileInfo" fileName="./logs/info.log"filePattern="logs/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log.gz"><Filters><!--只接受INFO级别的日志,其余的全部拒绝处理--><ThresholdFilter level="INFO"/><ThresholdFilter level="WARN" onMatch="DENY" onMismatch="NEUTRAL"/></Filters><PatternLayoutpattern="[%d{yyyy-MM-dd HH:mm:ss}] %-5level %class{36} %L %M - %msg%xEx%n"/><Policies><SizeBasedTriggeringPolicy size="500 MB"/><TimeBasedTriggeringPolicy/></Policies></RollingFile><!--处理WARN级别的日志,并把该日志放到logs/warn.log文件中--><RollingFile name="RollingFileWarn" fileName="./logs/warn.log"filePattern="logs/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log.gz"><Filters><ThresholdFilter level="WARN"/><ThresholdFilter level="ERROR" onMatch="DENY" onMismatch="NEUTRAL"/></Filters><PatternLayoutpattern="[%d{yyyy-MM-dd HH:mm:ss}] %-5level %class{36} %L %M - %msg%xEx%n"/><Policies><SizeBasedTriggeringPolicy size="500 MB"/><TimeBasedTriggeringPolicy/></Policies></RollingFile><!--处理error级别的日志,并把该日志放到logs/error.log文件中--><RollingFile name="RollingFileError" fileName="./logs/error.log"filePattern="logs/$${date:yyyy-MM}/error-%d{yyyy-MM-dd}-%i.log.gz"><ThresholdFilter level="ERROR"/><PatternLayoutpattern="[%d{yyyy-MM-dd HH:mm:ss}] %-5level %class{36} %L %M - %msg%xEx%n"/><Policies><SizeBasedTriggeringPolicy size="500 MB"/><TimeBasedTriggeringPolicy/></Policies></RollingFile><!--druid的日志记录追加器--><RollingFile name="druidSqlRollingFile" fileName="./logs/druid-sql.log"filePattern="logs/$${date:yyyy-MM}/api-%d{yyyy-MM-dd}-%i.log.gz"><PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss}] %-5level %L %M - %msg%xEx%n"/><Policies><SizeBasedTriggeringPolicy size="500 MB"/><TimeBasedTriggeringPolicy/></Policies></RollingFile></appenders><loggers><root level="DEBUG"><appender-ref ref="Console"/><appender-ref ref="RollingFileInfo"/><appender-ref ref="RollingFileWarn"/><appender-ref ref="RollingFileError"/><appender-ref ref="RollingFileDebug"/></root><!--记录druid-sql的记录--><logger name="druid.sql.Statement" level="debug" additivity="false"><appender-ref ref="druidSqlRollingFile"/></logger><logger name="druid.sql.Statement" level="debug" additivity="false"><appender-ref ref="druidSqlRollingFile"/></logger><!--log4j2 自带过滤日志--><Logger name="org.apache.catalina.startup.DigesterFactory" level="error" /><Logger name="org.apache.catalina.util.LifecycleBase" level="error" /><Logger name="org.apache.coyote.http11.Http11NioProtocol" level="warn" /><logger name="org.apache.sshd.common.util.SecurityUtils" level="warn"/><Logger name="org.apache.tomcat.util.net.NioSelectorPool" level="warn" /><Logger name="org.crsh.plugin" level="warn" /><logger name="org.crsh.ssh" level="warn"/><Logger name="org.eclipse.jetty.util.component.AbstractLifeCycle" level="error" /><Logger name="org.hibernate.validator.internal.util.Version" level="warn" /><logger name="org.springframework.boot.actuate.autoconfigure.CrshAutoConfiguration" level="warn"/><logger name="org.springframework.boot.actuate.endpoint.jmx" level="warn"/><logger name="org.thymeleaf" level="warn"/></loggers> </configuration> -
配置 application.properties
# 配置日志输出 spring.datasource.druid.filter.slf4j.enabled=true spring.datasource.druid.filter.slf4j.statement-create-after-log-enabled=false spring.datasource.druid.filter.slf4j.statement-close-after-log-enabled=false spring.datasource.druid.filter.slf4j.result-set-open-after-log-enabled=false spring.datasource.druid.filter.slf4j.result-set-close-after-log-enabled=false
相关文章:
SpringBoot集成DruidDataSource实现监控 SQL 性能
一、快速入门 1.1 基本概念 我们都使用过连接池,比如C3P0、DBCP、hikari、Druid,虽然 HikariCP 的速度稍快,但 Druid 能够提供强大的监控和扩展功能。Druid DataSource 是阿里巴巴开发的号称为监控而生的数据库连接池,它不仅可以…...
maven镜像源及代理配置
在公司使用网络一般需要设置代理, 我在idea中创建springboot工程时,发现依赖下载不了,原以为只要浏览器设置代理,其他的网络访问都会走代理,经过查资料设置了以下几个地方后工程创建正常,在此记录给大家参考…...
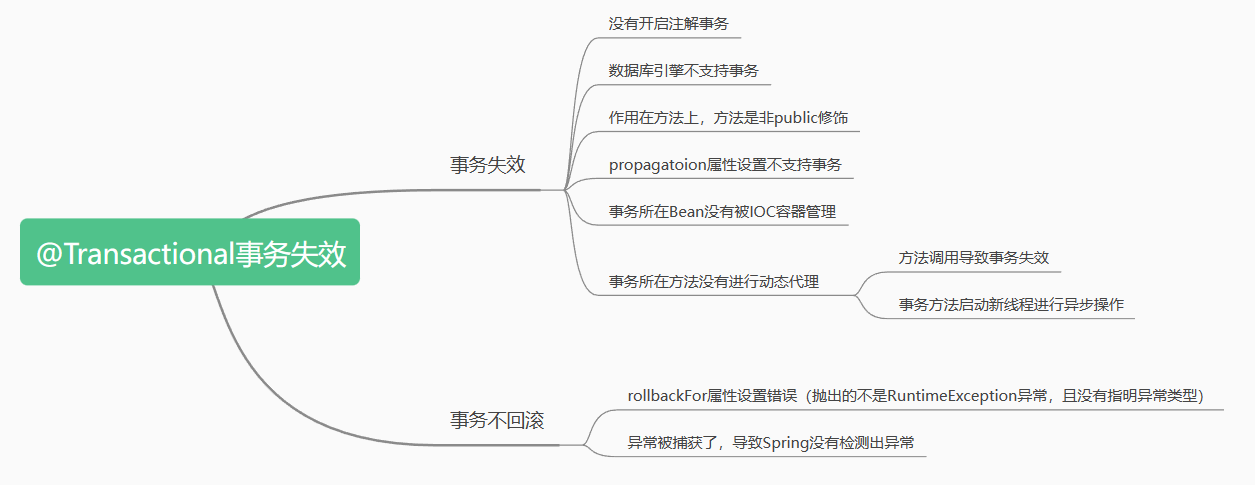
【Java面试篇】Spring中@Transactional注解事务失效的常见场景
文章目录Transactional注解的失效场景☁️前言🍀前置知识🍁场景一:Transactional应用在非 public 修饰的方法上🍁场景二: propagation 属性设置错误🍁场景三:rollbackFor属性设置错误dz…...

【C】分配内存的函数
#include <stdlib.h>//分配所需的内存空间,并返回一个指向它的指针。 void *malloc(size_t size);//分配所需的内存空间,并返回一个指向它的指针。并且calloc负责把这块内存空间用字节0填//充,而malloc并不负责把分配的内存空间清零 vo…...
IDEA 断点总是进入class文件没有进入源文件解决
前言 idea 断点总是进入class文件没有进入源文件解决 问题 在源文件里打了断点,断点模式启动时却进入了class文件里的断点,而没有进入到java源文件里的断点。 比如:我在 A.java 里打了断点,调试时却进入到了 jar 包里的 A.clas…...
【flink】 flink入门教程demo 初识flink
文章目录通俗解释什么是flink及其应用场景flink处理流程及核心APIflink代码快速入门flink重要概念什么是flink? 刚接触这个词的同学 可能会觉得比较难懂,网上搜教程 也是一套一套的官话, 如果大家熟悉stream流,那或许会比较好理解…...

LeetCode 1487. 保证文件名唯一
【LetMeFly】1487.保证文件名唯一 力扣题目链接:https://leetcode.cn/problems/making-file-names-unique/ 给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。 由于两个…...

详细剖析|袋鼠云数栈前端框架Antd 3.x 升级 4.x 的踩坑之路
袋鼠云数栈从2016年发布第⼀个版本开始,就始终坚持着以技术为核⼼、安全为底线、提效为⽬标、中台为战略的思想,坚定不移地⾛国产化信创路线,不断推进产品功能迭代、技术创新、服务细化和性能升级。 在数栈过去的产品迭代中受限于当前组件的…...

【C++PrimerPlus】第三章 处理数据
文章目录前言内容目录3.1 简单变量3.1.2 变量名3.1.2 整形3.1.3 整形short,int,long,long long3.1.4 无符号类型3.1.5 选择整形类型3.1.6 整形字面值3.1.7 C如何确定常量的类型3.1.8 char类型:字符和小整数3.1.9 bool类型3.2 const修饰符3.3浮点数3.3.1 书写浮点数3…...

【基础算法】单链表的OJ练习(1) # 反转链表 # 合并两个有序链表 #
文章目录前言反转链表合并两个有序链表写在最后前言 上一章讲解了单链表 -> 传送门 <- ,后面几章就对单链表进行一些简单的题目练习,目的是为了更好的理解单链表的实现以及加深对某些函数接口的熟练度。 本章带来了两个题目。一是反转链表&#x…...
命题逻辑)
离散数学笔记(1)命题逻辑
文章目录1.命题符号化及联结词基本概念本节题型2.命题公式及分类基本概念本节题型1.命题符号化及联结词 基本概念 命题的定义:能够判断真假的陈述句称为命题。 备注:感叹句、疑问句、祈使句和类似于xy>5之类真值不唯一的句子都不是命题。 真值的真假…...
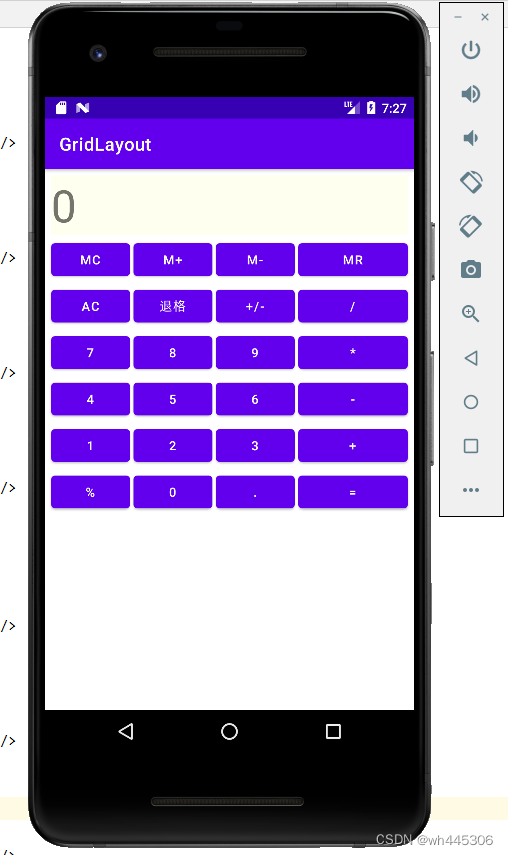
IDEA Android 网格布局(GridLayout)示例(计算器界面布局)
网格布局(GridLayout) 示例程序效果(实现类似vivo手机自带计算器UI) 真机和模拟器运行效果: 简述: GridLayout(网格布局)和TableLayout(表格布局)有类似的地方,通俗来讲可以理解为…...

【蓝桥杯嵌入式】拓展板之数码管显示
文章目录硬件电路连接方式函数实现文章福利硬件电路 通过上述原理图,可知拓展板上的数码管是一个共阴数码管,也就是说某段数码管接上高电平时,就会点亮。 上述原理图还给出一个提示,即:三个数码管分别与三个74HC59…...
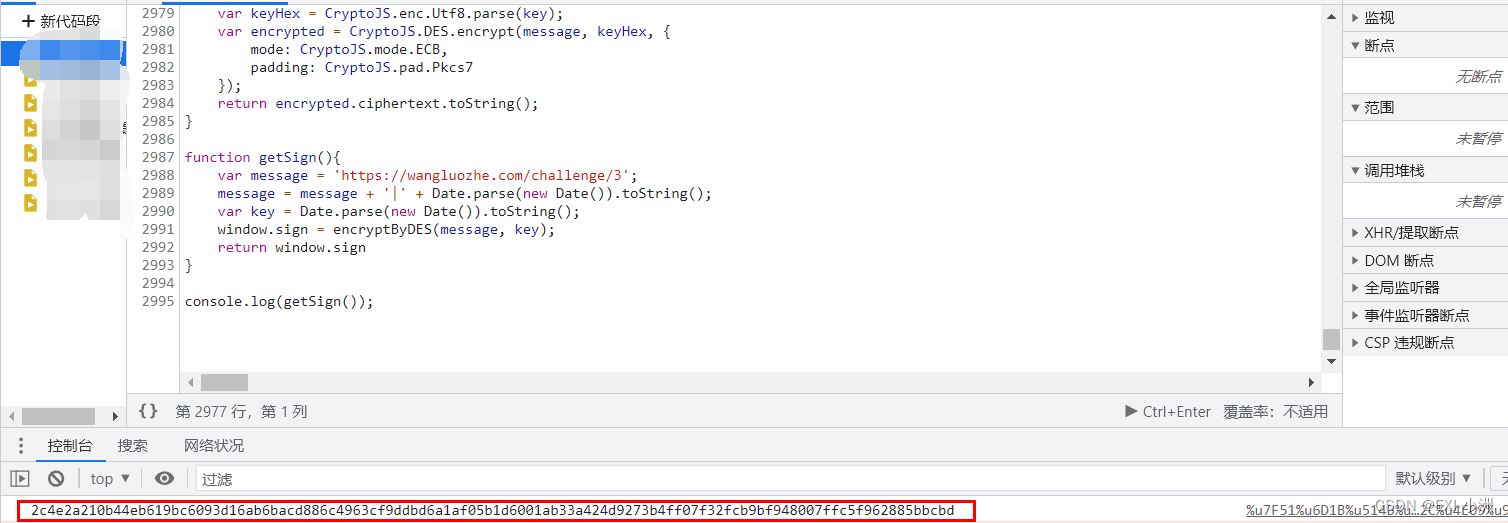
Web Spider案例 网洛克 第三题 AAEncode加密 练习(七)
声明 此次案例只为学习交流使用,抓包内容、敏感网址、数据接口均已做脱敏处理,切勿用于其他非法用途; 文章目录声明一、资源推荐二、逆向目标三、抓包分析 & 下断分析逆向3.1 抓包分析3.2 下断分析逆向拿到混淆JS代码3.3 AAEncode解决方…...
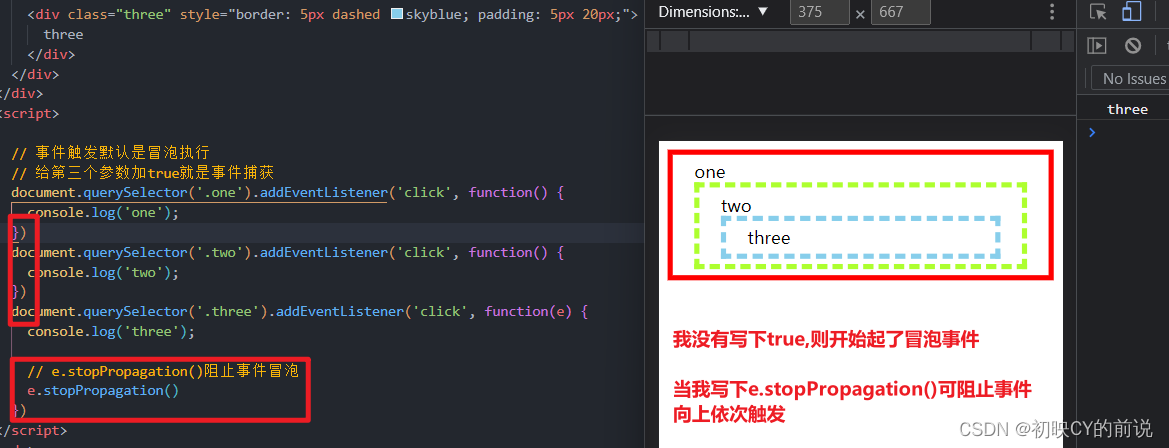
【javaScript面试题】2023前端最新版javaScript模块,高频24问
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的关于javaScript的面试题 目录 一、2023javaScript面试题精选 1.js的数据类型…...

Hadoop集群启动从节点没有DataNode
一、问题背景 之前启动hadoop集群的时候都没有问题,今天启动hadoop集群的时候,从节点的DataNode没有启动起来。 二、解决思路 遇见节点起不来的情况,可以去看看当前节点的日志文件 我进入当前从节点的hadoop安装目录的Logs文件下去查看日…...
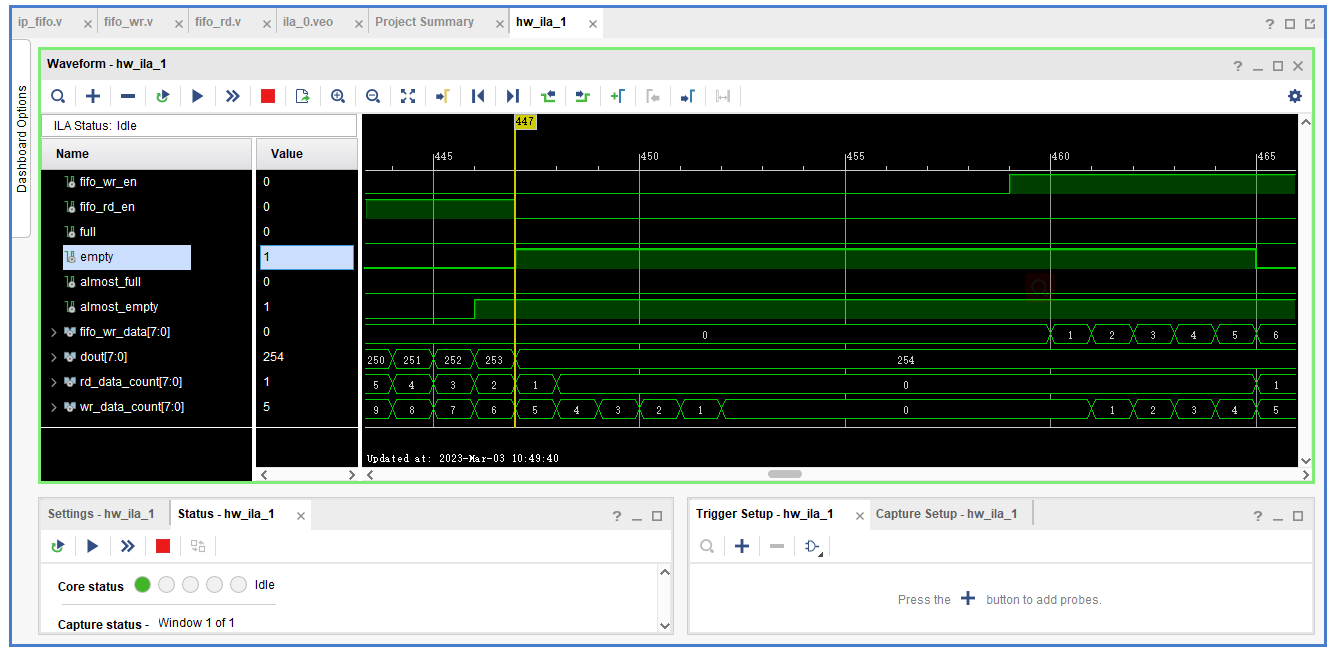
FIFO IP Core
FIFO IP Core 先进先出的缓存器常常被用于数据的缓存,或者高速异步数据交互(跨时钟信号传递)和RAM和ROM的区别是没有地址线,无法指定地址 写时钟(Write Clock Domain),读时钟写复位(wr_rst),读…...

从FPGA说起的深度学习(四)
这是新的系列教程,在本教程中,我们将介绍使用 FPGA 实现深度学习的技术,深度学习是近年来人工智能领域的热门话题。在本教程中,旨在加深对深度学习和 FPGA 的理解。用 C/C 编写深度学习推理代码高级综合 (HLS) 将 C/C 代码转换为硬…...
pytorch入门7--自动求导和神经网络
深度学习网上自学学了10多天了,看了很多大神的课总是很快被劝退。终于,遇到了一位对小白友好的刘二大人,先附上链接,需要者自取:https://b23.tv/RHlDxbc。 下面是课程笔记。 一、自动求导 举例说明自动求导。 torch中的…...

QT 之wayland 事件处理分析基于qt5wayland5.14.2
1. Qt wayland 初始化 接收鼠标/案件,触摸屏等事件事件 QWaylandNativeInterface : public QPlatformNativeInterface 在QWaylandNativeInterface 继承qpa 接口类QPlatformNativeInterface; 1.1 初始化鼠标: void *QWaylandNativeInterface::nativeR…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

终极Windows风扇控制指南:FanControl让你的电脑安静又高效
终极Windows风扇控制指南:FanControl让你的电脑安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...
)
Claude服务治理架构升级(生产环境零停机迁移实录)
更多请点击: https://codechina.net 第一章:Claude服务治理架构升级(生产环境零停机迁移实录) 为应对日益增长的推理请求量与多租户策略精细化需求,我们对Claude服务治理层实施了从单体API网关向云原生服务网格的平滑…...

3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能
3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

AVR+ESP8266双核架构打造独立WiFi天气显示器:从硬件设计到软件实现
1. 项目概述:一个独立WiFi天气显示器的诞生几年前,我琢磨着在书桌上放一个能实时显示天气信息的小玩意儿,市面上成品要么功能单一,要么价格不菲,要么数据源依赖复杂的服务器。于是,我决定自己动手ÿ…...