2023-12-30 AIGC-LangChain介绍
摘要:
2023-12-30 AIGC-LangChain介绍
LangChain介绍
1. https://youtu.be/Ix9WIZpArm0?t=353
2. https://www.freecodecamp.org/news/langchain-how-to-create-custom-knowledge-chatbots/
3. https://www.pinecone.io/learn/langchain-conversational-memory/
4. https://dev.to/reaminated/run-chatgpt-style-questions-over-your-own-files-using-the-openai-api-and-langchain-1ii7
https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
https://juejin.cn/post/7234787766151872571
1、LangChain介绍
LangChain 就是一个 LLM 编程框架,你想开发一个基于 LLM 应用,需要什么组件它都有,直接使用就行;甚至针对常规的应用流程,它利用链(LangChain中Chain的由来)这个概念已经内置标准化方案了。下面我们从新兴的大语言模型(LLM)技术栈的角度来看看为何它的理念这么受欢迎。
其官方的定义
LangChain是一个基于语言模型开发应用程序的框架。它可以实现以下应用程序:
- 数据感知:将语言模型连接到其他数据源
- 自主性:允许语言模型与其环境进行交互
LangChain的主要价值在于:
- 组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论您是否使用LangChain框架的其余部分。
- 现成的链:结构化的组件集合,用于完成特定的高级任务
现成的链使得入门变得容易。对于更复杂的应用程序和微妙的用例,组件化使得定制现有链或构建新链变得更容易。

新兴 LLM 技术栈
大语言模型技术栈由四个主要部分组成:
- 数据预处理流程(data preprocessing pipeline)
- 嵌入端点(embeddings endpoint )+向量存储(vector store)
- LLM 终端(LLM endpoints)
- LLM 编程框架(LLM programming framework)

数据预处理流程
该步骤包括与数据源连接的连接器(例如S3存储桶或CRM)、数据转换层以及下游连接器(例如向矢量数据库)。通常,输入到LLM中的最有价值的信息也是最难处理的(如PDF、PPTX、HTML等),但同时,易于访问文本的文档(例如.DOCX)中也包含用户不希望发送到推理终端的信息(例如广告、法律条款等)。
因为涉及的数据源繁杂(数千个PDF、PPTX、聊天记录、抓取的HTML等),这步也存在大量的 dirty work,使用OCR模型、Python脚本和正则表达式等方式来自动提取、清理和转换关键文档元素(例如标题、正文、页眉/页脚、列表等),最终向外部以API的方式提供JSON数据,以便嵌入终端和存储在向量数据库中。
嵌入端点和向量存储
使用嵌入端点(用于生成和返回诸如词向量、文档向量等嵌入向量的 API 端点)和向量存储(用于存储和检索向量的数据库或数据存储系统)代表了数据存储和访问方式的重大演变。以前,嵌入主要用于诸如文档聚类之类的特定任务,在新的架构中,将文档及其嵌入存储在向量数据库中,可以通过LLM端点实现关键的交互模式。直接存储原始嵌入,意味着数据可以以其自然格式存储,从而实现更快的处理时间和更高效的数据检索。此外,这种方法可以更容易地处理大型数据集,因为它可以减少训练和推理过程中需要处理的数据量。
LLM终端
LLM终端是接收输入数据并生成LLM输出的终端。LLM终端负责管理模型的资源,包括内存和计算资源,并提供可扩展和容错的接口,用于向下游应用程序提供LLM输出。
LLM编程框架
LLM编程框架提供了一套工具和抽象,用于使用语言模型构建应用程序。在现代技术栈中出现了各种类型的组件,包括:LLM提供商、嵌入模型、向量存储、文档加载器、其他外部工具(谷歌搜索等),这些框架的一个重要功能是协调各种组件。
关键组件解释
Prompts
Prompts用来管理 LLM 输入的工具,在从 LLM 获得所需的输出之前需要对提示进行相当多的调整,最终的Promps可以是单个句子或多个句子的组合,它们可以包含变量和条件语句。
Chains
是一种将LLM和其他多个组件连接在一起的工具,以实现复杂的任务。
Agents
是一种使用LLM做出决策的工具,它们可以执行特定的任务并生成文本输出。Agents通常由三个部分组成:Action、Observation和Decision。Action是代理执行的操作,Observation是代理接收到的信息,Decision是代理基于Action和Observation做出的决策。
Memory
是一种用于存储数据的工具,由于LLM 没有任何长期记忆,它有助于在多次调用之间保持状态。
典型应用场景
- 特定文档的问答:从Notion数据库中提取信息并回答用户的问题。
- 聊天机器人:使用Chat-LangChain模块创建一个与用户交流的机器人。
- 代理:使用GPT和WolframAlpha结合,创建一个能够执行数学计算和其他任务的代理。
- 文本摘要:使用外部数据源来生成特定文档的摘要。
Langchain 竞品
(个人认为)在商业化上,基于大模型业务分为三个层次:
- 基础设施层:通用的大模型底座
- 垂直领域层:基于大模型底座+领域场景数据微调形成更强垂直能力
- 应用层:基于前两者,瘦前端的方式提供多样化应用体验
类似 LangChain 这种工具框架可以做到整合各个层能力,具备加速应用开发和落地验证的优势,因此也出现了很多竞争者。
| 名称 | 语言 | 特点 |
|---|---|---|
| LangChain | Python/JS | 优点:提供了标准的内存接口和内存实现,支持自定义大模型的封装。 缺点:评估生成模型的性能比较困难。 |
| Dust.tt | Rust/TS | 优点:提供了简单易用的API,可以让开发者快速构建自己的LLM应用程序。 缺点:文档不够完善。 |
| Semantic-kernel | TypeScript | 优点:轻量级SDK,可将AI大型语言模型(LLMs)与传统编程语言集成在一起。 缺点:文档不够完善。 |
| Fixie.ai | Python | 优点:开放、免费、简单,多模态(images, audio, video...) 缺点:PaaS平台,需要在平台部署 |
| Brancher AI | Python/JS | 优点:链接所有大模型,无代码快速生成应用, Langchain产品) 缺点:- |
LangChain 主体分为 6 个模块,分别是对(大语言)模型输入输出的管理、外部数据接入、链的概念、(上下文记忆)存储管理、智能代理以及回调系统,通过文档的组织结构,你可以清晰了解到 LangChain的侧重点,以及在大语言模型开发生态中对自己的定位。
2、LLM输入输出管理
Model I/O
这部分包括对大语言模型输入输出的管理,输入环节的提示词管理(包含模板化提示词和提示词动态选择等),处理环节的语言模型(包括所有LLMs的通用接口,以及常用的LLMs工具;Chat模型是一种与LLMs不同的API,用来处理消息),输出环节包括从模型输出中提取信息。

提示词管理
- 提示模板 动态提示词=提示模板+变量,通过引入给提示词引入变量的方式,一方面保证了灵活性,一方面又能保证Prompt内容结构达到最佳
系统设置了三种模板:固定模板不需要参数,单参数模板可以替换单个词,双参数模板可以替换两个词。比如单参数模板可以提问"告诉一个形容词笑话"。运行时传入"有意思"作为参数,就变成"告诉一个有意思的笑话"。双参数模板可以提问"某个形容词关于某内容的笑话"。运行时传入"有趣","鸡"作为参数,就变成"告诉一个有趣的关于鸡的笑话"。通过设置不同模板和参数,一套系统就可以自动生成各种问题,实现智能对话与用户互动。- 聊天提示模板 聊天场景中,消息可以与AI、人类或系统角色相关联,模型应该更加密切地遵循系统聊天消息的指示。这个是对 OpenAI gpt-3.5-tubor API中role字段(role 的属性用于显式定义角色,其中 system 用于系统预设,比如”你是一个翻译家“,“你是一个写作助手”,user 表示用户的输入, assistant 表示模型的输出)的一种抽象,以便应用于其他大语言模型。SystemMessage对应系统预设,HumanMessage用户输入,AIMessage表示模型输出,使用 ChatMessagePromptTemplate 可以使用任意角色接收聊天消息。
系统会先提示“我是一个翻译助手,可以把英文翻译成中文”这样的系统预设消息。然后用户输入需要翻译的内容,比如“我喜欢大语言模型”。系统会根据预先定义的对话模板,自动接受翻译语种和用户输入作为参数,并生成对应的用户输入消息。最后,系统回复翻译结果给用户。通过定制不同对话角色和动态输入参数,实现了模型自动回复用户需求的翻译对话。- 其他
- 基于 StringPromptTemplate 自定义提示模板StringPromptTemplate
- 将Prompt输入与特征存储关联起来(FeaturePromptTemplate)
- 少样本提示模板(FewShotPromptTemplate)
- 从示例中动态提取提示词✍️
LLMs
- LLMs 将文本字符串作为输入并返回文本字符串的模型(纯文本补全模型),这里重点说下做项目尽量用异步的方式,体验会更好,下面的例子连续10个请求,时间相差接近5s。
该系统使用语言模型为用户提供文本输出功能。代码测试了串行和并行请求两个模式。串行模式一个一个发起10个请求,响应时间总计需要5秒。并行模式通过asyncio模块同时发起10个请求任务。 tasks列表存放每个请求,await等待它们都结束。与串行只有1.4秒响应时间相比,并行模式大大提升了效率。- 缓存 如果多次请求的返回一样,就可以考虑使用缓存,一方面可以减少对API调用次数节省token消耗,一方面可以加快应用程序的速度。
首先定义一个内存缓存,用来临时保存请求结果。然后对语言模型发送同一条"告诉我一个笑话"的请求两次。第一次请求耗时2.18秒,结果和响应通过缓存保存起来。第二次请求就直接从缓存中获取结果。- 流式传输功能,能即时逐字返回生成内容,还原聊天过程
- 回调追踪token使用,了解模型耗费情况
- ChatModel支持聊天消息作为输入,生成回应完成对话
- 配置管理可以读取保存LLM设置,方便重复使用
- 提供模拟工具代替真实模型,在测试中减少成本
- 与其他AI基础设施无缝融合
输出解析器
输出解析器用于构造大语言模型的响应格式,具体通过格式化指令和自定义方法两种方式。
需要对机器人回复进行结构化处理。代码测试了两种输出解析方式。一是使用内置的解析器,识别指定格式如逗号分隔列表的输出。二是通过定义ResponseSchema来定制输出结构,比如需要包含答案和来源两个字段。它会提示模型按照格式要求进行回复,比如“答案,来源”。解析器可以分析模型输出,判断是否符合预期结构。smallCoder明白了,输出解析器可以规范化模型响应,一个是使用内置规则,一个可以全自定义,都有助于结构化对话与后续处理。Data Connection
打通外部数据的管道,包含文档加载,文档转换,文本嵌入,向量存储几个环节。

文档加载
重点包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂,重点推荐按需去查看与各种数据源 集成的章节说明,Discord、Notion、Joplin,Word等数据源。
文档拆分
重点关注按照字符递归拆分的方式 RecursiveCharacterTextSplitter ,这种方式会将语义最相关的文本片段放在一起。
文本嵌入
嵌入包含两个方法,一个用于嵌入文档,接受多个文本作为输入;一个用于嵌入查询,接受单个文本。文档中示例使用了OpenAI的嵌入模型text-embedding-ada-002,但提供了很多第三方嵌入模型集成可以按需查看。
需要根据文本内容进行相似匹配查找。它利用了语言嵌入技术来实现。首先定义好嵌入模型,这里使用OpenAI提供的文本嵌入模型。然后有两种方法可以获取文本向量:传入多篇文本,同时获取所有文本的嵌入向量表示。仅传入单篇文本,获取其嵌入向量。嵌入向量可以用于计算文本间的相似程度,从而实现内容查找。向量存储
这个就是对常用矢量数据库(FAISS,Milvus,Pinecone,PGVector等)封装接口的说明,详细的可以前往嵌入专题查看。大概流程都一样:初始化数据库连接信息——>建立索引——>存储矢量——>相似性查询,下面以 Pinecone为例:
文本搜索系统需要对大量文档进行索引,以实现相关性搜索。它首先使用文本加载器读取文本内容,然后用分词器将长文本分割成短语。接着调用嵌入模型为每段文本生成向量表示。系统利用Pinecone这类向量数据库创建索引,并存入所有文本向量。后续只需传入查询词语,调用相似性搜索接口,就可以快速找到与查询最相关的文本片段。数据查询
这节重点关注数据压缩,目的是获得相关性最高的文本带入prompt上下文,这样既可以减少token消耗,也可以保证LLM的输出质量。
问答系统需要从大量文本快速检索与用户问题相关的内容。它先采用向量检索技术获取初步文档,然后利用LLM迭代提取相关段落进行数据压缩。另外,系统也可以在压缩结果上再进行向量相似度过滤,进一步优化结果。同时,为提升效率,系统还实现了基于结构化metadata和概要进行主动查询,而不是索引所有文本内容。针对基础检索得到的文档再做一次向量相似性搜索进行过滤,也可以取得不错的效果。
最后一点就是自查询(SelfQueryRetriever)的概念,其实就是结构化查询元数据,因为对文档的元信息查询和文档内容的概要描述部分查询效率肯定是高于全部文档的。
Memory
Chain和Agent是无状态的,只能独立地处理每个传入的查询,Memory 可以管理和操作历史消息。一个带存储的Agent例子如下:
一个基于问答历史记录的聊天agent。它首先定义了搜索工具,并使用ZeroShotAgent生成 prompts。然后创建一个ConversationBufferMemory对象保存历史消息。将agent、搜索工具和内存对象封装成AgentExecutor。每次处理用户问题时,都会查询内存中的历史记录,充当聊天上下文。同时问题响应也会添加到内存,形成持续互动。3、数据接入层
Data Connection
打通外部数据的管道,包含文档加载,文档转换,文本嵌入,向量存储几个环节。
文档加载
重点包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂,重点推荐按需去查看与各种数据源 集成的章节说明,Discord、Notion、Joplin,Word等数据源。
文档拆分
重点关注按照字符递归拆分的方式 RecursiveCharacterTextSplitter ,这种方式会将语义最相关的文本片段放在一起。
文本嵌入
嵌入包含两个方法,一个用于嵌入文档,接受多个文本作为输入;一个用于嵌入查询,接受单个文本。文档中示例使用了OpenAI的嵌入模型text-embedding-ada-002,但提供了很多第三方嵌入模型集成可以按需查看。
需要根据文本内容进行相似匹配与提取。它利用多种NLP技术来实现。首先使用递归字符拆分器将长文本根据语义语境分割成短段。然后采用文本嵌入模型,为每个文本和查询获得其向量表示。嵌入模型可以为系统提供多篇文本和单篇文本的向量,为后续匹配检索打下基础。系统通过计算和比对这些向量,可以找到与查询最相似的文本片段。向量存储
这个就是对常用矢量数据库(FAISS,Milvus,Pinecone,PGVector等)封装接口的说明,详细的可以前往嵌入专题查看。大概流程都一样:初始化数据库连接信息——>建立索引——>存储矢量——>相似性查询,下面以 Pinecone为例:
问答系统需要对大量文本进行索引,实现快速相关搜索。它先用文本加载器读取文本,字符级分词器切分为短段。然后调用嵌入模型为每段文本生成矢量表示。利用Pinecone向量数据库创建索引,将所有文本向量存入。只需传入查询,调用相似搜索接口,即可快速找到与查询最相关的文本段。数据查询
这节重点关注数据压缩,目的是获得相关性最高的文本带入prompt上下文,这样既可以减少token消耗,也可以保证LLM的输出质量。
问答系统需要从大量文档快速检索与询问相关内容。它先通过向量检索获取初步文档,然后利用深度学习模型从中取出最相关文本进行数据压缩。同时,系统还采用向量相似度过滤进一步优化检索结果。此外,通过建立在结构化元数据和概要上的主动查询,而非全文匹配,也可以提升检索效率。针对基础检索得到的文档再做一次向量相似性搜索进行过滤,也可以取得不错的效果。
最后一点就是自查询(SelfQueryRetriever)的概念,其实就是结构化查询元数据,因为对文档的元信息查询和文档内容的概要描述部分查询效率肯定是高于全部文档的。
4、Embedding专题
文本嵌入是什么
向量是一个有方向和长度的量,可以用数学中的坐标来表示。例如,可以用二维坐标系中的向量表示一个平面上的点,也可以用三维坐标系中的向量表示一个空间中的点。在机器学习中,向量通常用于表示数据的特征。
而文本嵌入是一种将文本这种离散数据映射到连续向量空间的方法,嵌入技术可以将高维的离散数据降维到低维的连续空间中,并保留数据之间的语义关系,从而方便进行机器学习和深度学习的任务。
例如:
"机器学习"表示为 [1,2,3]
"深度学习"表示为[2,3,3]
"英雄联盟"表示为[9,1,3]
使用余弦相似度(余弦相似度是一种用于衡量向量之间相似度的指标,可以用于文本嵌入之间的相似度)在计算机中来判断文本之间的距离:
“机器学习”与“深度学习”的距离:
![]()
"机器学习”与“英雄联盟“的距离":
![]()
“机器学习”与“深度学习”两个文本之间的余弦相似度更高,表示它们在语义上更相似。
文本嵌入算法
文本嵌入算法是指将文本数据转化为向量表示的具体算法,通常包括以下几个步骤:
- 分词:将文本划分成一个个单词或短语。
- 构建词汇表:将分词后的单词或短语建立词汇表,并为每个单词或短语赋予一个唯一的编号。
- 计算词嵌入:使用预训练的模型或自行训练的模型,将每个单词或短语映射到向量空间中。
- 计算文本嵌入:将文本中每个单词或短语的向量表示取平均或加权平均,得到整个文本的向量表示。
常见的文本嵌入算法包括 Word2Vec、GloVe、FastText 等。这些算法通过预训练或自行训练的方式,将单词或短语映射到低维向量空间中,从而能够在计算机中方便地处理文本数据。
文本嵌入用途
文本嵌入用于测量文本字符串的相关性,通常用于:
- 搜索(结果按与查询字符串的相关性排序)
- 聚类(其中文本字符串按相似性分组)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别出相关性很小的异常值)
- 多样性测量(分析相似性分布)
- 分类(其中文本字符串按其最相似的标签分类)
使用文本嵌入模型
- 可以使用 HuggingFace上能够处理文本嵌入的开源模型,例如:uer/sbert-base-chinese-nli
问答系统利用文本嵌入技术将输入内容转换为数字向量表示。它使用了开源库SentenceTransformer,选择预训练模型'uer/sbert-base-chinese-nli'进行中文文本向量化。这个模型可以高效对一批文本进行编码,输出每个文本的嵌入向量。系统也可以使用OpenAI提供的文本嵌入API,选用text-embedding-ada-002模型进行处理。OpenAI的API支持多种预训练模型,不同模型在处理效果和性能上会有差异。通过文本向量化,系统可以实现内容的深层理解,比如对文本进行分类、相似度计算等,为后续问答提供技术支撑。- 使用之前介绍的 OpenAI 文本嵌入API 可以将文本转换为向量,OpenAI API提供了多个文本嵌入模型,这篇博客对它们的性能进行了比较,这里是性能最好的
text-embedding-ada-002说明:
| 模型名称 | 价格 | 分词器 | 最大输入 token | 输出 |
|---|---|---|---|---|
| text-embedding-ada-002 | $0.000/1k tokens | cl100k_base | 8191 | 1536 |
支持文本嵌入的其他模型
- nghuyong/ernie-3.0-nano-zh
- shibing624/text2vec-base-chinese
- GanymedeNil/text2vec-large-chinese
- moka-ai/m3e-base
- 用于句子、文本和图像嵌入的Python库
矢量数据库
- 为了快速搜索多个矢量,建议使用矢量数据库,下面是一些可选的矢量数据库:
- Pinecone,一个完全托管的矢量数据库
- Weaviate,一个开源的矢量搜索引擎
- Redis作为矢量数据库
- Qdrant,一个矢量搜索引擎
- Milvus,一个为可扩展的相似性搜索而构建的矢量数据库
- Chroma,一个开源嵌入式商店
- Typesense,快速的开源矢量搜索引擎
- Zilliz,数据基础设施,由Milvus提供技术支持
- FAISS 是Meta开源的用于高效搜索大规模矢量数据集的库
性能优化:
和传统数据库一样,可以使用工程手段优化矢量数据库搜索性能,最直接的就是更新索引算法 ,对索引数据进行分区优化。
平面索引(FLAT):将向量简单地存储在一个平面结构中,最基本的向量索引方法。
- 欧式距离(Euclidean Distance)
- 余弦相似度(Cosine Similarity)
分区索引(IVF):将向量分配到不同的分区中,每个分区建立一个倒排索引结构,最终通过倒排索引实现相似度搜索。
- 欧式距离(Euclidean Distance)
- 余弦相似度(Cosine Similarity)
量化索引(PQ):将高维向量划分成若干子向量,将每个子向量量化为一个编码,最终将编码存储在倒排索引中,利用倒排索引进行相似度搜索。
- 欧式距离(Euclidean Distance)
- 汉明距离(Hamming Distance)
HNSW (Hierarchical Navigable Small World):通过构建一棵层次化的图结构,从而实现高效的相似度搜索。
- 内积(Inner Product)
- 欧式距离(Euclidean Distance)
NSG (Navigating Spreading-out Graph):通过构建一个分层的无向图来实现快速的相似度搜索。
- 欧式距离(Euclidean Distance)
Annoy (Approximate Nearest Neighbors Oh Yeah):通过将高维空间的向量映射到低维空间,并构建一棵二叉树来实现高效的近似最近邻搜索。
- 欧式距离(Euclidean Distance)
- 曼哈顿距离(Manhattan Distance)
LSH (Locality-Sensitive Hashing):通过使用哈希函数将高维的向量映射到低维空间,并在低维空间中比较哈希桶之间的相似度,实现高效的相似度搜索。
- 内积(Inner Product)
- 欧式距离(Euclidean Distance)
5、Chain模块
Chain链定义
链定义为对组件的一系列调用,也可以包括其他链,这种在链中将组件组合在一起的想法很简单但功能强大,极大地简化了复杂应用程序的实现并使其更加模块化,这反过来又使调试、维护和改进应用程序变得更加容易。 Chain基类是所有chain对象的基本入口,与用户程序交互,处理用户的输入,准备其他模块的输入,提供内存能力,chain的回调能力,其他所有的 Chain 类都继承自这个基类,并根据需要实现特定的功能。
Chain定义和自定义Chain的主要作用:Chain定义了一系列组件的调用顺序,可以包含子Chain,实现复杂应用的模块化。Chain基类是所有Chain对象的起点,处理输入、输出、内存和回调等功能。自定义Chain需要继承Chain基类,实现_call/_acall方法定义调用逻辑。例如,根据prompt生成文字会使用语言模型生成响应,同时支持回调处理。Chain支持同步和异步调用,内部组件也可以通过回调进行交互。这极大简化了应用开发,通过组合小组件构建复杂系统。模块化设计也促进了代码维护、扩展和重用等。继承Chain的子类主要有两种类型:
通用工具 chain: 控制chain的调用顺序, 是否调用,他们可以用来合并构造其他的chain。 专门用途 chain: 和通用chain比较来说,他们承担了具体的某项任务,可以和通用的chain组合起来使用,也可以直接使用。有些 Chain 类可能用于处理文本数据,有些可能用于处理图像数据,有些可能用于处理音频数据等。
从 LangChainHub 加载链
LangChainHub 托管了一些高质量Prompt、Agent和Chain,可以直接在langchain中使用。
LangChainHub加载链主要作用:LangChainHub提供了量大质精的Prompt、Agent和Chain模板,可以直接在langchain中使用。例如加载"math"链,它是一个基于LLM实现的计算器链。运行 LLM 链的五种方式
运行LLM链的主要作用:LangChainHub提供了量大质精的Prompt、Agent和Chain模板,可以直接在langchain中使用。例如加载"math"链,它是一个基于LLM实现的计算器链。LLM链可以通过5种方式运行:1.调用对象 2. run方法 3. apply方法
generate方法 5. predict方法
它们接受格式不同的输入参数,但都可以输出响应结果。这大大简化了开发流程 - 直接使用高质量模板,只需少量代码即可构建应用。运行LLM链也提供便利的接口。通用工具chain
以下概述几种通用工具链的主要功能:
- MultiPromptChain通过Embedding匹配选择最相关提示回答问题。
- EmbeddingRouterChain使用嵌入判断选择下一链。
- LLMRouterChain使用LLM判断选择下一链。
- SimpleSequentialChain/SequentialChain将多个链组成流水线传递上下文。
- TransformChain通过自定义函数转换输入,动态改变数据流向。
它们提供了动态路由、数据转换、链串联等功能,大大提升了链的灵活性。
例如,通过TransformChain截取文本,SequentialChain联合链对文本进行摘要。
这些通用工具chains可以帮助开发者快速构建复杂应用,实现不同业务需求。
只需进行少量定制就可以满足个性需求,真正实现“取而代之”的开发模式。
合并文档的链(专门用途chain)
BaseCombineDocumentsChain 有四种不同的模式
以下概括合并文档链的主要功能:该链专门用于问答场景下从多篇文档中提取答案。它提供四种模式来合并多个文档:1. stuff模式:直接将所有文档合成一段文字 2. map_reduce模式:每个文档提取答案候选,最后整合答案3. map_rerank模式:每个文档提取答案候选,通过LLM进行重新排序4. refine模式:首先用LLM优化每个文档,然后进行上述处理开发者只需选择合适模式,便可以搭建出问答链。四种模式分别注重不同因素,如效率、质量等。这大大简化了定制问答类应用的难度。StuffDocumentsChain
获取一个文档列表,带入提示上下文,传递给LLM(适合小文档)
StuffDocumentsChain的主要功能是:接受一个包含多个文档的列表作为输入将所有文档使用特定分割符连接成一个长文本将长文本通过prompt模板格式化,传入到LLM生成响应它适用于文档数量和大小比较小的场景。
RefineDocumentsChain
在Studff方式上进一步优化,循环输入文档并迭代更新其答案,以获得最好的最终结果。具体做法是将所有非文档输入、当前文档和最新的中间答案组合传递给LLM。(适合LLM上下文大小不能容纳的小文档)
系统需从多个文档中为用户提供准确答案。它先采用修正链模式:将问题和当前文档及初步答案输入语言模型校验模型根据上下文回复更精准答案系统循环每篇文档,迭代优化答案质量结束后获得最优答案输出给用户
MapReduceDocumentsChain
将LLM链应用于每个单独的文档(Map步骤),将链的输出视为新文档。然后,将所有新文档传递给单独的合并文档链以获得单一输出(Reduce步骤)。在执行Map步骤前也可以对每个单独文档进行压缩或合并映射,以确保它们适合合并文档链;可以将这个步骤递归执行直到满足要求。(适合大规模文档的情况)
为提升问答效率,系统采取如下流程:将问题输入每个文件,语言模型给出初步答案系统自动收集各文件答案,形成新文件集将答案文件集输入语言模型,整合产出最终答案如文件体积过大,还可分批处理缩小文件体积通过分布式“映射-规约”模式,系统高效 parallel 地从海量文件中找到答案:映射工作使每个文件独立处理,提高效率;规约环节再整合答案,精度不恨损失。这样既利用了分布技术,又保证了答案质量,帮助用户快速解决问题。
MapRerankDocumentsChain
每个文档上运行一个初始提示,再给对应输出给一个分数,返回得分最高的回答。
为能从海量文件中快速给出最好答案,系统采用“映射-重新排序”流程:将问题输入每个文件,语言模型给出多个答案候选系统针对每个候选答案给出一个匹配分数按分数从高到低重新排序所有文件答案取排在前列的高分答案作为最优答案这使系统从每个文件中高效挖掘答案,并利用匹配度快速定位最好答案。
获取领域知识的链(专门用途chain)
APIChain使得可以使用LLMs与API进行交互,以检索相关信息。通过提供与所提供的API文档相关的问题来构建链。 下面是与播客查询相关的
为帮助用户更全面解答问题,系统利用外部API获取关联知识:系统将问题输入到基于API文档构建的链中链自动调用外部播客API搜索相关节目根据用户需求筛选超30分钟的一条播客结果系统返回相关节目信息,丰富了解答内容通过对接第三方API,系统解答能力得到极大扩展:API提供传输知识,系统转化为答案;用户只需简单问题,即可获取相关外部资源。这有效弥补了单一模型不足,助用户全面解决问题需求。合并文档的链的高频使用场景举例
对话场景(最广泛)
ConversationalRetrievalChain 对话式检索链的工作原理:将聊天历史记录(显式传入或从提供的内存中检索)和问题合并到一个独立的问题中,然后从检索器查找相关文档,最后将这些文档和问题传递给问答链以返回响应。
用户在系统提问时,往往与之前对话上下文相关。为给出最合理答复,系统采用以下对话式处理流程:保存所有历史对话为内存将新问题和历史对话合成一个问题从大量文档中寻找相关段落将答卷和问题输入语言模型获得兼顾上下文的最佳答案这样系统可以深入理解用户意图,结合历史信息给出情境化的响应。基于数据库问答场景
通过数据库链将结构化数据连接到语言模型,实现问答功能。此外,它还支持:实体链接 知识图谱问答文档分类聚类对象检测机器翻译等总结场景
对输入文本进行总结,比如提取关键信息并连接成简介。问答场景
读取文件内容,利用文档搜索及联合链从多个文档中给出最佳答案。6、代理模块
某些应用程序需要基于用户输入的对LLM和其他工具的灵活调用链。Agents为此类应用程序提供了灵活性。代理可以访问单一工具,并根据用户输入确定要使用的工具。代理可以使用多个工具,并使用一个工具的输出作为下一个工具的输入。
主要有两种类型的代理:Plan-and-Execute Agents 用于制定动作计划;Action Agents 决定实施何种动作。
Agents模块还包含配合代理执行的工具(代理可以执行的操作。为代理提供哪些工具在很大程度上取决于希望代理做什么)和工具包(一套工具集合,这些工具可以与特定用例一起使用。例如,为了使代理与SQL数据库进行交互,它可能需要一个工具来执行查询,另一个工具来检查表)。
下面对不同的Agent类型进行说明
CONVERSATIONAL_REACT_DESCRIPTION
针对对话场景优化的代理
为优化对话系统的智能化能力,langchain采用代理模式:系统定义了不同工具函数,如搜索引擎查询接口用户提问时,代理首先检查是否需要调用工具函数如果调用搜索查询,就利用接口搜索答案否则将问题通过语言模型进行自然对话全过程与历史对话上下文保持一致通过这种设计:系统可以动态选择调用内外部功能回答不仅限于语言模型,更加智能用户获得更全面更自动化的对话体验Agent执行过程
系统处理流程如下:用户提问系统总人口数量时,系统开始分析系统判断是否需要调用外部工具寻找答案系统决定调用搜索工具,搜索“中国人口数量”搜索结果告知中国2020人口数据及民族构成系统分析搜索结果已得到需要答案所以不需要调用其他工具,直接据搜索结果回复用户整个流程从问题理解到答案回复都是逻辑清晰的CHAT_CONVERSATIONAL_REACT_DESCRIPTION 针对聊天场景优化的代理
OpenAI Functions Agent
这个是 LangChain对 OpenAI Function Call 的封装。关于 Function Calling的能力,可以看我这篇文章:OpenAI Function Calling 特性有什么用
OpenAI Functions Agent的工作流程:1. 用户提问,语言模型判断是否需要调用功能函数2. 如果需要,调用定义好的Calculator函数 3. Calculator函数通过LLM计算公式结果4. 将公式执行结果返回给语言模型5. 语言模型将结果翻译成自然语言给用户通过这种模式:- 语言模型可以调用外部函数完成更复杂任务- 用户提问范围不限于纯对话,可以求解数学等问题 - whole process是一体化的,用户体验更好计划和执行代理
计划和执行代理通过首先计划要做什么,然后执行子任务来实现目标。这个想法很大程度上受到BabyAGI的启发。
计划与执行代理通过分步实现:1. 首先使用聊天规划器对问题进行解析分解,得到执行计划2. 计划内容可能包括调用不同工具函数获取子结果:- Search接口查询美国GDP - Calculator计算日本GDP- Calculator计算两国GDP差值3. 然后执行器依次调用相关函数运行计划任务4. 将子结果整合返回给用户通过这种分层设计:- 规划器可以针对不同类型问题制定个性化计划- 执行器负责统一调用运行子任务 - 用户问题可以一步到位高效解决ZERO_SHOT_REACT_DESCRIPTION
给LLM提供一个工具名称列表,包括它们的效用描述以及有关预期输入/输出的详细信息。指示LLM在必要时使用提供的工具来回答用户给出的提示。指令建议模型遵循ReAct格式:思考、行动、行动输入、观察,下面是一个例子:
这个流程描述了系统利用外部工具高效解答用户问题的体验过程:1. 系统提前定义好各种常用工具名称和功能 2. 当用户提问时,系统会理解问题所需信息3. 然后选择调用合适工具,明确工具名称和预期输出4. 通过工具搜索相关数据,观察结果5. 根据观察得出确切答案6. 整个流程分步可追踪,结果一目了然其他
- AgentType.SELF_ASK_WITH_SEARCH:自我进行对话迭代的代理
- REACT_DOCSTORE:基于文档做ReAct的代理
- STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION:在聊天过程中接入工具性代理,相当于OpenAI Plugin
7、Callback模块
回调模块允许接到LLM应用程序的各个阶段,鉴于LLM的幻觉问题,这对于日志记录、监视、流式处理和其他任务非常有用,现在也有专用的工具Helicone,Arize AI等产品可用,下面我们开始看代码:
自定义回调对象
所有的回调对象都是基于这个基类来声明的
系统定义了统一的回调处理基类:基类定义了各种标准回调接口如开始/结束回调这些回调适用于不同子模块如NLP模型/链/工具等开发者只需扩展基类,实现自己的回调处理逻辑然后在运行过程中注册这些回调对象系统就能在各个节点调用对应的回调方法例如:开发日志记录回调类 extend 基类注册到 chains/models日志就能自动记录运行细节这样设计优点很明显:统一标准化回调定义高扩展性,任何子模块均支持定制回调开发维护成本低使用回调的两种方式
- 构造函数时定义回调:在构造函数中定义,例如
LLMChain(callbacks=[handler], tags=['a-tag']),它将被用于对该对象的所有调用,并且将只针对该对象,例如,如果你向LLMChain构造函数传递一个handler,它将不会被附属于该链的Model使用。 - 请求函数时传入回调:定义在用于发出请求的call()/run()/apply()方法中,例如
chain.call(inputs, callbacks=[handler]),它将仅用于该特定请求,以及它所包含的所有子请求(例如,对LLMChain的调用会触发对Model的调用,Model会使用call()方法中传递的相同 handler)。
下面这是采用构造函数定义回调的例子:
两种方式的区别在于:- 构造函数回调作用于对象所有调用 - 请求函数回调只针对单次调用两者都可以实现回调功能,选择时就看追求统一还是 situational 了。执行效果
LLM调用开始....
Hi! I just woke up. Your llm is starting
同步回调被调用: token:
同步回调被调用: token: 好
同步回调被调用: token: 的
同步回调被调用: token: ,
同步回调被调用: token: 我
同步回调被调用: token: 来
同步回调被调用: token: 给
同步回调被调用: token: 你
同步回调被调用: token: 讲
同步回调被调用: token: 个
同步回调被调用: token: 笑
同步回调被调用: token: 话
同步回调被调用: token: :同步回调被调用: token: 有
同步回调被调用: token: 一
同步回调被调用: token: 天
同步回调被调用: token: ,
同步回调被调用: token: 小
同步回调被调用: token: 明
同步回调被调用: token: 上
同步回调被调用: token: 学
同步回调被调用: token: 迟
同步回调被调用: token: 到
同步回调被调用: token: 了
同步回调被调用: token:
LLM调用结束....
Hi! I just woke up. Your llm is ending参考链接:
LangChain指南:打造LLM的垂域AI框架
一文了解:打造垂域的大模型应用ChatGPT
爱吃牛油果的璐璐:(万字长文)手把手教你认识学会LangChain
更多细节内容参考官方文档:
️ Langchain
相关文章:
2023-12-30 AIGC-LangChain介绍
摘要: 2023-12-30 AIGC-LangChain介绍 LangChain介绍 1. https://youtu.be/Ix9WIZpArm0?t353 2. https://www.freecodecamp.org/news/langchain-how-to-create-custom-knowledge-chatbots/ 3. https://www.pinecone.io/learn/langchain-conversational-memory/ 4. https://de…...

pytorch01:概念、张量操作、线性回归与逻辑回归
目录 一、pytorch介绍1.1pytorch简介1.2发展历史1.3pytorch优点 二、张量简介与创建2.1什么是张量?2.2Tensor与Variable2.3张量的创建2.3.1 直接创建torch.tensor()2.3.2 从numpy创建tensor 2.4根据数值创建2.4.1 torch.zeros()2.4.2 torch.zeros_like()2.4.3 torch…...

storyBook play学习
场景 在官方给出的案例中, Page.stories.js import { within, userEvent } from storybook/testing-library import MyPage from ./Page.vueexport default {title: Example/Page,component: MyPage,parameters: {// More on how to position stories at: https:/…...
Android Matrix画布Canvas旋转Rotate,Kotlin
Android Matrix画布Canvas旋转Rotate,Kotlin private fun f1() {val originBmp BitmapFactory.decodeResource(resources, R.mipmap.pic).copy(Bitmap.Config.ARGB_8888, true)val newBmp Bitmap.createBitmap(originBmp.width, originBmp.height, Bitmap.Config.…...
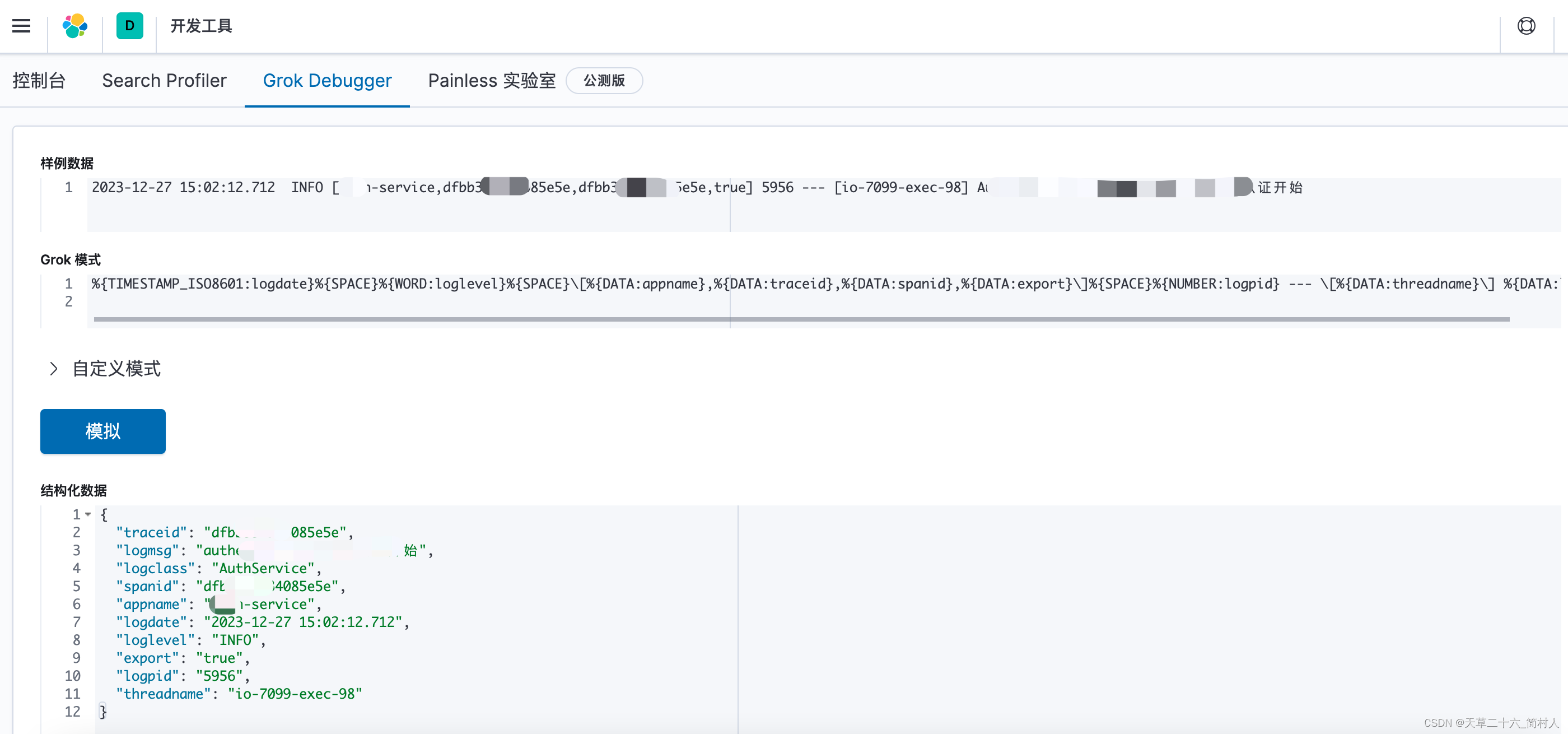
私有部署ELK,搭建自己的日志中心(三)-- Logstash的安装与使用
一、部署ELK 上文把采集端filebeat如何使用介绍完,现在随着数据的链路,继续~~ 同样,使用docker-compose部署: version: "3" services:elasticsearch:container_name: elasticsearchimage: elastic/elasticsearch:7.9…...

2023就这样过去了,2024会更好吗?
2023年,不是很好 2023年是疫情后的第一年,疫情过去了,大家都有大多的希望,希望经济可以恢复,希望信心可以恢复,但是整体都是远远低于预期的。年初的一片热潮,年中的一片哀嚎,年底基…...

SpringBoot加载配置的6种方式
从配置文件中获取属性应该是SpringBoot开发中最为常用的功能之一,简单回顾一下这六种的使用方式: 说明Environment对象Environment是springboot核心的环境配置接口,它提供了简单的方法来访问应用程序属性,包括系统属性、操作系统…...
大语言模型(LLM)训练平台与工具
LLM 是利用深度学习和大数据训练的人工智能系统,专门 设计来理解、生成和回应自然语言。 大模型训练平台和工具提供了强大且灵活的基础设施,使得开发和训练复杂的语言模型变得可行且高效。 平台和工具提供了先进的算法、预训练模型和优化技术,…...

docker配置buildx插件
一、介绍 Docker buildx是docker的一个插件 支持Moby BuildKit的所有特性 可以跨CPU架构编译镜像 可以在多节点编译镜像 二、前提 使用 buildx 作为 docker CLI 插件需要使用 Docker 19.03 或更新版本。 三、配置步骤 1)客户端:在客户端的配置文…...

mysql 空间函数
ST_GeomFromText:将文本表示的几何对象转换为几何对象。 SELECT ST_GeomFromText(POINT(1 1)); ST_AsText:将几何对象转换为文本表示。 SELECT ST_AsText(ST_GeomFromText(POINT(1 1))); ST_Contains:判断一个几何对象是否包含另一个几何对象…...
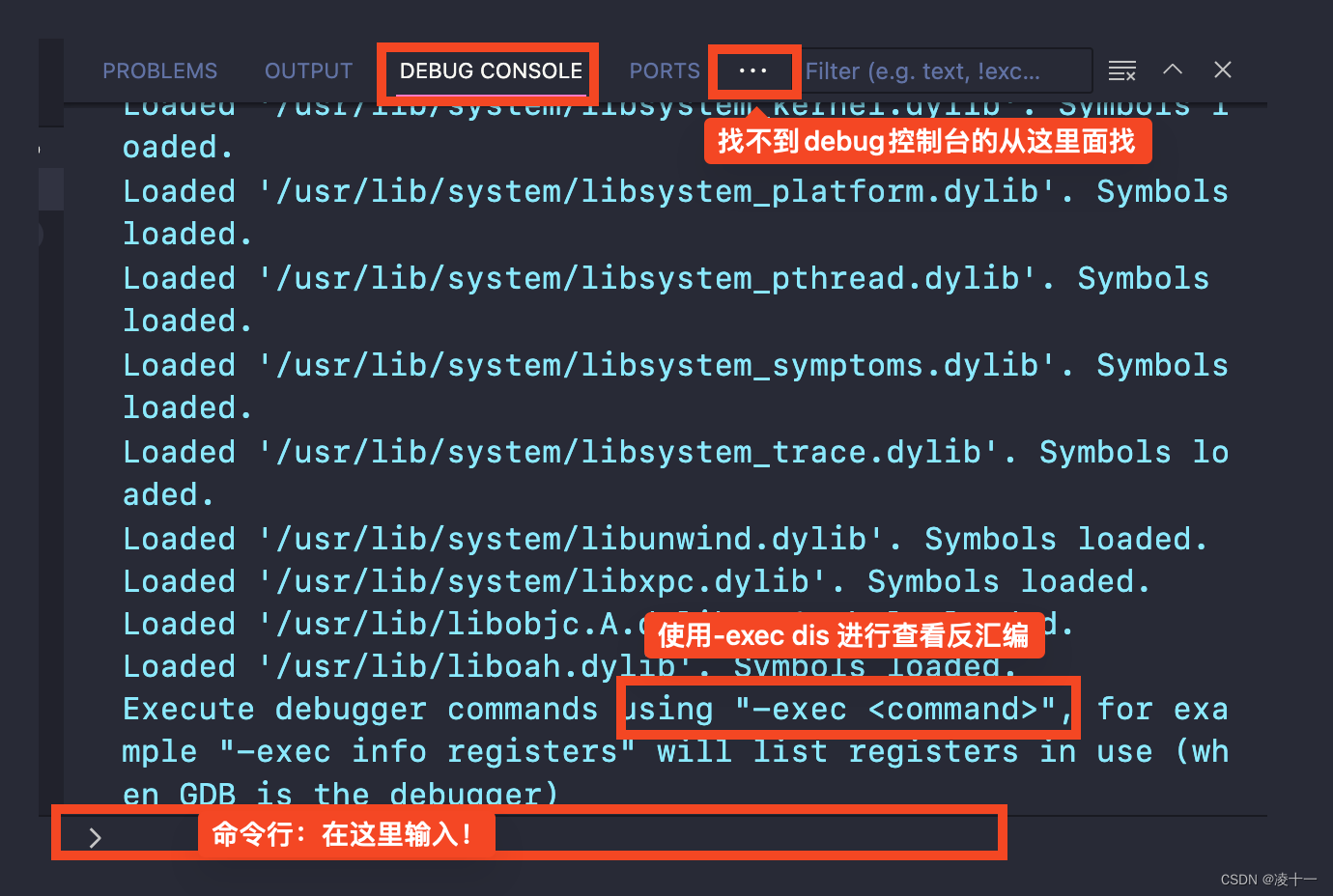
vscode调试 反汇编c/c++ 查看汇编代码gdb/lldb
先看下流程! 先看下流程! 有问题请留言! 文章目录 必备F5开启调试左侧侧边栏->确保打开回调栈右键函数栈->查看反汇编 方法二:手动输入命令查看 必备 使用c/c 插件,这应该是必备的。 F5开启调试 左侧侧边栏-&…...
)
总结项目中oauth2模块的配置流程及实际业务oauth2认证记录(Spring Security)
文章目录 简单示例添加oauth2的依赖配置认证服务器配置资源服务器配置安全使用http或者curl命令测试 实际业务中工具类(记录):认证服务器资源服务器、配置安全用户验证登录控制层配置文件application.yml 项目中用过的spring security&#x…...

传感器原理与应用复习
测量与误差 传感器原理与应用复习—测量概述与测量误差 传感器特性与应变式传感器 传感器原理与应用复习–传感器基本特性与应变式传感器 电感式传感器 传感器原理与应用复习–电感式传感器 电容式与电压式传感器 传感器原理与应用复习–电容式与压电式传感器 电磁式与…...
)
蓝桥杯python比赛历届真题99道经典练习题 (8-12)
【程序8】 题目:输出9*9口诀。 1.程序分析:分行与列考虑,共9行9列,i控制行,j控制列。 2.程序源代码: #include "stdio.h" main() {int i,j,result;printf("\n");for (i=1;i<10;i++){ for(j=1;j<10;j++){result=i*j;printf("%d*%d=%-3…...

八个理由:从java8升级到Java17
目录 前言 1. 局部变量类型推断 2.switch表达式 3.文本块 4.Records 5.模式匹配instanceof 6. 密封类 7. HttpClient 8.性能和内存管理能力提高 前言 从Java 8 到 Java 20,Java 已经走过了漫长的道路,自 Java 8 以来,Java 生态系统…...

使用poi将pptx文件转为图片详解
目录 项目需求 后端接口实现 1、引入poi依赖 2、代码编写 1、controller 2、service层 测试出现的bug 小结 项目需求 前端需要上传pptx文件,后端保存为图片,并将图片地址保存数据库,最后大屏展示时显示之前上传的pptx的图片。需求看上…...
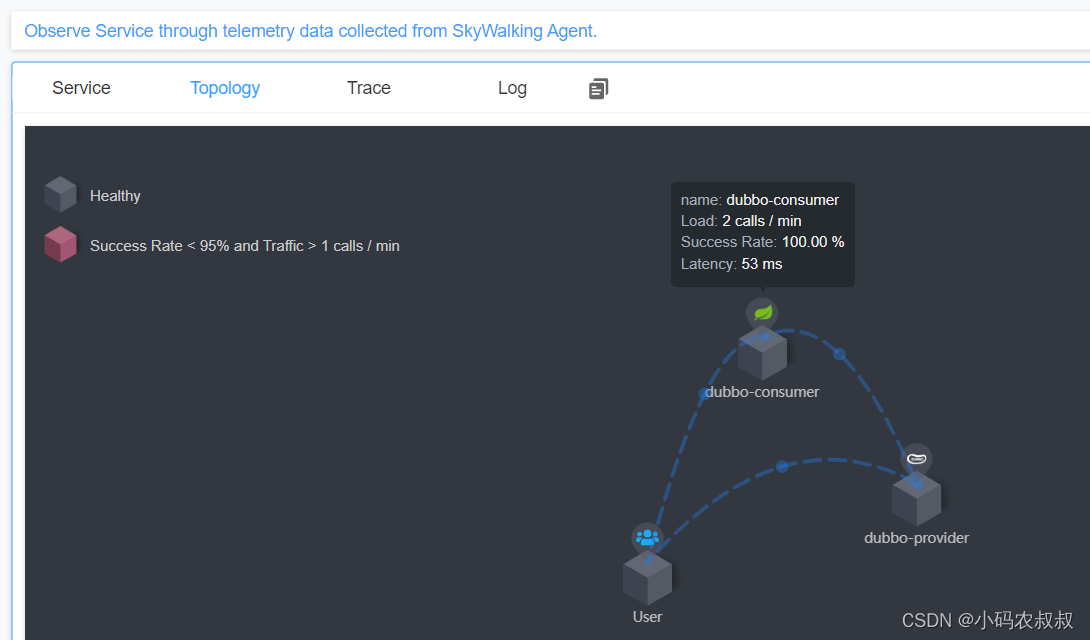
【微服务】springboot整合skywalking使用详解
目录 一、前言 二、SkyWalking介绍 2.1 SkyWalking是什么 2.2 SkyWalking核心功能 2.3 SkyWalking整体架构 2.4 SkyWalking主要工作流程 三、为什么选择SkyWalking 3.1 业务背景 3.2 常见监控工具对比 3.3 为什么选择SkyWalking 3.3.1 代码侵入性极低 3.3.2 功能丰…...

electron——查看electron的版本(代码片段)
electron——查看electron的版本(代码片段)1.使用命令行: npm ls electron 操作如下: 2.在软件内使用代码,如下: console.log(process) console.log(process.versions.electron) process 里包含很多信息: process详…...

【Electron】富文本编辑器之文本粘贴
由于这个问题导致,从其他地方复制来的内容 粘贴发送之后都会多一个 换行 在发送的时候如果直接,发送innerHTML 就 可以解决 Electron h5 Andriod 都没问题,但是 公司的 IOS 端 不支持,且不提供支持(做不了。ÿ…...

【哈希数组】697. 数组的度
697. 数组的度 解题思路 首先创建一个IndexMap 键表示元素 值表示一个列表List list存储该元素在数组的所有索引之后再次创建一个map1 针对上面的List 键表示列表的长度 值表示索引的差值遍历indexmap 将所有的list的长度 和 索引的差值存储遍历map1 找到最大的key 那么这个Ke…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...