LLM之RAG实战(九)| 高级RAG 03:多文档RAG体系结构
在RAG(检索和生成)这样的框架内管理和处理多个文档有很大的挑战。关键不仅在于提取相关内容,还在于选择包含用户查询所寻求的信息的适当文档。基于用户查询对齐的多粒度特性,需要动态选择文档,本文将介绍结构化层次检索来解决多文档RAG问题。
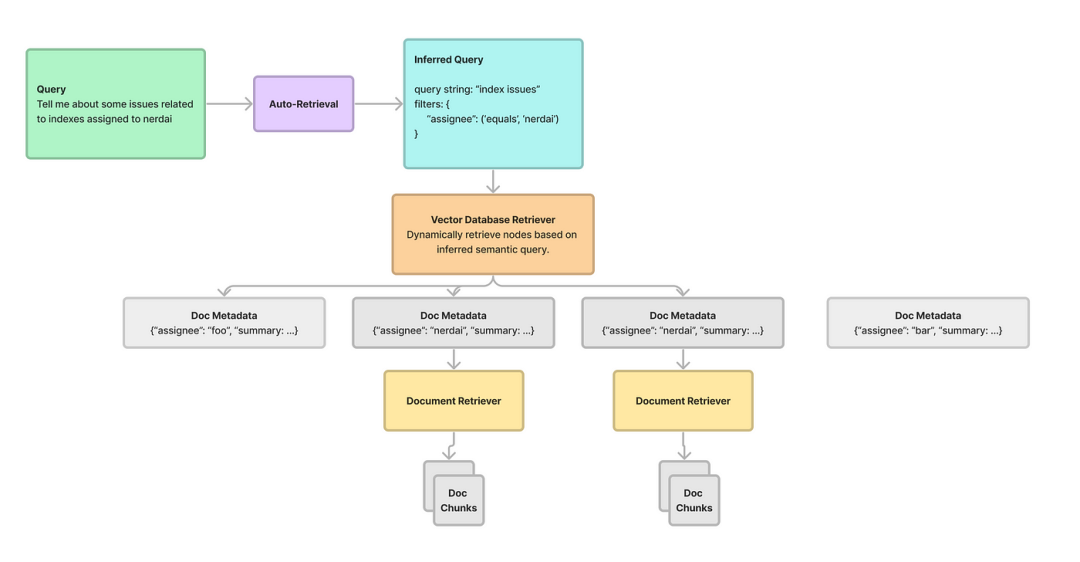
一、Llamaindex结构化检索介绍
Llamaindex支持多层次信息检索。它不只是筛选文档,而是利用元数据过滤来简化选择过程。通过使用自动检索机制,这些过滤器可以根据用户查询检索出最相关的文档。这个过程包括推断语义查询,在矢量数据库中确定最佳过滤器集,有效地将文本到SQL和语义搜索的能力结合起来。
二、结构化层次检索的优点
下面介绍Llamaindex提供的结构化分层检索的一些好处:
-
增强相关性:通过利用元数据驱动的过滤器,可以准确地识别和检索符合用户查询细微要求的文档。这确保了内容选择中更高的相关性和准确性;
-
动态文档选择:与传统的静态文档检索是不同,Llamaindex支持动态文档选择。Llamaindex通过根据相关文档的属性和结构化元数据灵活选择相关文档,智能地适应不同的用户查询;
-
高效信息检索:结构化层次检索显著提高了信息检索的效率。通过将文档预处理到元数据字典中并将其存储在矢量数据库中,该系统简化了检索过程,最大限度地减少了计算开销并优化了搜索效率;
-
语义查询优化:文本到SQL和语义搜索的融合使系统能够更好地理解用户意图。Llamaindex的自动检索机制将用户查询细化为语义结构,从而能够从文档存储库中精确而细致地检索信息。
三、结构化层次检索代码实现
下面使用Python代码来展示Llamaindex的基本概念,并实现一个结构化的分层检索系统。使用Llamaindex类初始化来管理矢量数据库中的文档元数据。
- 文档添加:add_document方法通过创建包含摘要和关键字等关键信息的元数据字典,将文档添加到Llamaindex;
- 检索逻辑:retrieve_documents方法通过将用户查询与矢量数据库中的元数据过滤器进行匹配来处理用户查询。为了演示目的,使用了一个基本的模拟匹配逻辑;
- 匹配机制:match_metadata方法模拟用户查询和文档元数据之间的匹配过程。这是一个简化的演示逻辑,通常会使用更高级的NLP或语义分析技术。
本示例旨在说明Llamaindex的核心概念,展示如何通过Python中的简化实现来存储文档元数据并基于用户查询检索相关文档。
步骤1:安装库
!pip install llama-index wandb llama_hub weaviate-client --quiet步骤2:导入库
import osimport openaiimport loggingimport sysfrom IPython.display import Markdown, displayfrom llama_index.llms import OpenAIfrom llama_index.callbacks import CallbackManager, WandbCallbackHandlerfrom llama_index import load_index_from_storageimport pandas as pdfrom llama_index.query_engine import PandasQueryEnginefrom pprint import pprintfrom llama_index import (VectorStoreIndex,SimpleKeywordTableIndex,SimpleDirectoryReader,StorageContext,ServiceContext,)import nest_asyncionest_asyncio.apply()#Setup OPEN API Keyos.environ["OPENAI_API_KEY"] = ""# openai_key = "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" #<--- Your API KEY# openai.api_key = openai_keylogging.basicConfig(stream=sys.stdout, level=logging.INFO)logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))# initialise WandbCallbackHandler and pass any wandb.init argswandb_args = {"project":"llama-index-report"}wandb_callback = WandbCallbackHandler(run_args=wandb_args)# pass wandb_callback to the service contextcallback_manager = CallbackManager([wandb_callback])service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-3.5-turbo-0613", temperature=0), chunk_size=1024, callback_manager=callback_manager)
步骤3:下载Github issues
os.environ["GITHUB_TOKEN"] = ""from llama_hub.github_repo_issues import (GitHubRepositoryIssuesReader,GitHubIssuesClient,)github_client = GitHubIssuesClient()loader = GitHubRepositoryIssuesReader(github_client,owner="run-llama",repo="llama_index",verbose=True,)orig_docs = loader.load_data()limit = 100docs = []for idx, doc in enumerate(orig_docs):doc.metadata["index_id"] = doc.id_if idx >= limit:breakdocs.append(doc)# OutputFound 100 issues in the repo page 1Resulted in 100 documentsFound 100 issues in the repo page 2Resulted in 200 documentsFound 100 issues in the repo page 3Resulted in 300 documentsFound 8 issues in the repo page 4Resulted in 308 documentsNo more issues found, stopping
from copy import deepcopyimport asynciofrom tqdm.asyncio import tqdm_asynciofrom llama_index import SummaryIndex, Document, ServiceContextfrom llama_index.llms import OpenAIfrom llama_index.async_utils import run_jobsasync def aprocess_doc(doc, include_summary: bool = True):"""Process doc."""print(f"Processing {doc.id_}")metadata = doc.metadatadate_tokens = metadata["created_at"].split("T")[0].split("-")year = int(date_tokens[0])month = int(date_tokens[1])day = int(date_tokens[2])assignee = ("" if "assignee" not in doc.metadata else doc.metadata["assignee"])size = ""if len(doc.metadata["labels"]) > 0:size_arr = [l for l in doc.metadata["labels"] if "size:" in l]size = size_arr[0].split(":")[1] if len(size_arr) > 0 else ""new_metadata = {"state": metadata["state"],"year": year,"month": month,"day": day,"assignee": assignee,"size": size,"index_id": doc.id_,}# now extract out summarysummary_index = SummaryIndex.from_documents([doc])query_str = "Give a one-sentence concise summary of this issue."query_engine = summary_index.as_query_engine(service_context=ServiceContext.from_defaults(llm=OpenAI(model="gpt-3.5-turbo")))summary_txt = str(query_engine.query(query_str))new_doc = Document(text=summary_txt, metadata=new_metadata)return new_docasync def aprocess_docs(docs):"""Process metadata on docs."""new_docs = []tasks = []for doc in docs:task = aprocess_doc(doc)tasks.append(task)new_docs = await run_jobs(tasks, show_progress=True, workers=5)# new_docs = await tqdm_asyncio.gather(*tasks)return new_docsnew_docs = await aprocess_docs(docs)# OutputProcessing 9398Processing 9427Processing 9613Processing 9417Processing 9612Processing 8832Processing 9609Processing 9353Processing 9431Processing 9426Processing 9425Processing 9435Processing 9419Processing 9571Processing 9373Processing 9383Processing 9408Processing 9405Processing 9372Processing 9546Processing 9565Processing 9664Processing 9560Processing 9470Processing 9343Processing 9518Processing 9358Processing 8536Processing 9385Processing 9380Processing 9510Processing 9352Processing 9368Processing 7457Processing 8893Processing 9583Processing 9312Processing 7720Processing 9219Processing 9481Processing 9469Processing 9655Processing 9477Processing 9670Processing 9475Processing 9667Processing 9665Processing 9348Processing 9471Processing 9342Processing 9488Processing 9338Processing 9523Processing 9416Processing 7726Processing 9522Processing 9652Processing 9520Processing 9651Processing 7244Processing 9650Processing 9519Processing 9649Processing 9492Processing 9603Processing 9509Processing 9269Processing 9491Processing 8802Processing 9525Processing 9611Processing 9543Processing 8551Processing 9627Processing 9450Processing 9658Processing 9421Processing 9394Processing 9653Processing 9439Processing 9604Processing 9413Processing 9507Processing 9625Processing 9490Processing 9626Processing 9483Processing 9638Processing 7744Processing 9472Processing 8475Processing 9244Processing 9618100%|██████████| 100/100 [02:07<00:00, 1.27s/it]
步骤4:将数据加载到Weaviate Vector Store
from llama_index.vector_stores import WeaviateVectorStorefrom llama_index.storage import StorageContextfrom llama_index import VectorStoreIndeximport weaviate# cloudauth_config = weaviate.AuthApiKey(api_key="")client = weaviate.Client("https://<weaviate-cluster>.weaviate.network",auth_client_secret=auth_config,)class_name = "LlamaIndex_auto"vector_store = WeaviateVectorStore(weaviate_client=client, index_name=class_name)storage_context = StorageContext.from_defaults(vector_store=vector_store)# Since "new_docs" are concise summaries, we can directly feed them as nodes into VectorStoreIndexindex = VectorStoreIndex(new_docs, storage_context=storage_context)docs[0].metadata# Output{'state': 'open','created_at': '2023-12-21T20:18:03Z','url': 'https://api.github.com/repos/run-llama/llama_index/issues/9655','source': 'https://github.com/run-llama/llama_index/pull/9655','labels': ['size:L'],'index_id': '9655'}
步骤5:对原始文档建立Weaviate Index
vector_store = WeaviateVectorStore(weaviate_client=client, index_name=doc_class_name)storage_context = StorageContext.from_defaults(vector_store=vector_store)doc_index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
步骤6:建立自动检索机制
自动检索器的设置过程通过分为以下几个关键步骤:
-
定义Schema:定义向量数据库模式,包括元数据字段;
-
VectorIndexAutoRetriever初始化:实例化此类将创建一个利用压缩元数据索引的检索器。需要定义的Schema作为其输入;
-
创建Wrapper Retriever:该步骤主要将每个节点后处理为IndexNode。此转换包含一个链接回源文档的索引ID,此链接支持在后面的部分中进行递归检索,依靠IndexNode对象与下游检索器、查询引擎或其他节点连接。
6(a)定义Schema
from llama_index.vector_stores.types import MetadataInfo, VectorStoreInfovector_store_info = VectorStoreInfo(content_info="Github Issues",metadata_info=[MetadataInfo(name="state",description="Whether the issue is `open` or `closed`",type="string",),MetadataInfo(name="year",description="The year issue was created",type="integer",),MetadataInfo(name="month",description="The month issue was created",type="integer",),MetadataInfo(name="day",description="The day issue was created",type="integer",),MetadataInfo(name="assignee",description="The assignee of the ticket",type="string",),MetadataInfo(name="size",description="How big the issue is (XS, S, M, L, XL, XXL)",type="string",),],)
6(b)实例化 VectorIndexAutoRetriever
from llama_index.retrievers import VectorIndexAutoRetrieverretriever = VectorIndexAutoRetriever(index,vector_store_info=vector_store_info,similarity_top_k=2,empty_query_top_k=10, # if only metadata filters are specified, this is the limitverbose=True,)
nodes = retriever.retrieve("Tell me about some issues on 12/11")print(f"Number retrieved: {len(nodes)}")print(nodes[0].metadata)# OutputUsing query str:Using filters: [('month', '==', 12), ('day', '==', 11)]Number retrieved: 6{'state': 'open', 'year': 2023, 'month': 12, 'day': 11, 'assignee': '', 'size': 'XL', 'index_id': '9431'}
6(c)定义Wrapper Retriever
from llama_index.retrievers import BaseRetrieverfrom llama_index.indices.query.schema import QueryBundlefrom llama_index.schema import IndexNode, NodeWithScoreclass IndexAutoRetriever(BaseRetriever):"""Index auto-retriever."""def __init__(self, retriever: VectorIndexAutoRetriever):"""Init params."""self.retriever = retrieverdef _retrieve(self, query_bundle: QueryBundle):"""Convert nodes to index node."""retrieved_nodes = self.retriever.retrieve(query_bundle)new_retrieved_nodes = []for retrieved_node in retrieved_nodes:index_id = retrieved_node.metadata["index_id"]index_node = IndexNode.from_text_node(retrieved_node.node, index_id=index_id)new_retrieved_nodes.append(NodeWithScore(node=index_node, score=retrieved_node.score))return new_retrieved_nodesindex_retriever = IndexAutoRetriever(retriever=retriever)
步骤7:建立递归检索机制
这种类型的检索器将检索器的每个节点连接到另一个检索器、查询引擎或节点。该设置包括将每个汇总的元数据节点链接到与相应文档对应的RAG管道对齐的检索器。
配置过程如下:
-
为每个文档定义一个检索器,并把他们添加到字典中;
-
定义递归检索器:在参数中定义包括root检索器(汇总元数据检索器)和其他文档检索器。
from llama_index.vector_stores.types import (MetadataFilter,MetadataFilters,FilterOperator,)retriever_dict = {}query_engine_dict = {}for doc in docs:index_id = doc.metadata["index_id"]# filter for the specific doc idfilters = MetadataFilters(filters=[MetadataFilter(key="index_id", operator=FilterOperator.EQ, value=index_id),])retriever = doc_index.as_retriever(filters=filters)query_engine = doc_index.as_query_engine(filters=filters)retriever_dict[index_id] = retrieverquery_engine_dict[index_id] = query_engine
from llama_index.retrievers import RecursiveRetriever# note: can pass `agents` dict as `query_engine_dict` since every agent can be used as a query enginerecursive_retriever = RecursiveRetriever("vector",retriever_dict={"vector": index_retriever, **retriever_dict},# query_engine_dict=query_engine_dict,verbose=True,)nodes = recursive_retriever.retrieve("Tell me about some issues on 12/11")print(f"Number of source nodes: {len(nodes)}")nodes[0].node.metadata# OutputRetrieving with query id None: Tell me about some issues on 12/11Using query str:Using filters: [('month', '==', 12), ('day', '==', 11)]Retrieved node with id, entering: 9431Retrieving with query id 9431: Tell me about some issues on 12/11Retrieving text node: Dev awiss# DescriptionTry to use clickhouse as vectorDB.Try to chunk docs with independent parser service.Special designed schema and tricks for better query and retriever.Fixes # (issue)## Type of ChangePlease delete options that are not relevant.- [ ] Bug fix (non-breaking change which fixes an issue)- [ ] New feature (non-breaking change which adds functionality)- [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected)- [ ] This change requires a documentation update# How Has This Been Tested?Please describe the tests that you ran to verify your changes. Provide instructions so we can reproduce. Please also list any relevant details for your test configuration- [ ] Added new unit/integration tests- [ ] Added new notebook (that tests end-to-end)- [ ] I stared at the code and made sure it makes sense# Suggested Checklist:- [ ] I have performed a self-review of my own code- [ ] I have commented my code, particularly in hard-to-understand areas- [ ] I have made corresponding changes to the documentation- [ ] I have added Google Colab support for the newly added notebooks.- [ ] My changes generate no new warnings- [ ] I have added tests that prove my fix is effective or that my feature works- [ ] New and existing unit tests pass locally with my changes- [ ] I ran `make format; make lint` to appease the lint godsRetrieved node with id, entering: 9435Retrieving with query id 9435: Tell me about some issues on 12/11Retrieving text node: [Bug]: [nltk_data] Error loading punkt: <urlopen error [WinError 10060] A### Bug DescriptionI am using a vector Index which connects to a chromaDB client as my database. I have initialized the index as a chat engine. When the query the chat engine, two things happen:1. The response time is nearly 2-3mins.2. It throws the below warning```[nltk_data] Error loading punkt: <urlopen error [WinError 10060] A[nltk_data] connection attempt failed because the connected party[nltk_data] did not properly respond after a period of time, or[nltk_data] established connection failed because connected host[nltk_data] has failed to respond>```### Version0.9.8.post1### Steps to ReproduceClone, setup and run the below repository: (Follow readme for instructions)https://github.com/umang299/document-gpt### Relevant Logs/Tracbacks_No response_Retrieved node with id, entering: 9426Retrieving with query id 9426: Tell me about some issues on 12/11Retrieving text node: Slack Loader with large lack channels### Question Validation- [X] I have searched both the documentation and discord for an answer.### QuestionHi team,I am using the [Slack Loader ](https://llamahub.ai/l/slack)from Llama Hub. For smaller Slack channels it works fine. However, for larger channels with lots of messages created over months, I keep seeing this message:`Rate limit error reached, sleeping for: 10 seconds`Is there a recommended / idiomatic way to load larger Slack channels to avoid this issue?Retrieved node with id, entering: 9425Retrieving with query id 9425: Tell me about some issues on 12/11Retrieving text node: [Feature Request]: Make llama-index compartible with models finetuned and hosted on modal.com### Feature DescriptionModal.com is a cloud computing service that allows you to finetune and host models on their workers. They provide inference points for any models finetuned on their platform.### ReasonI have not tried implementing the feature. I just read about the capabilities on modal.com and thought it would be a good integration feature for llama-index to allow for more configuration.### Value of FeatureAn integration feature to allow users who host their models on modal to use llama-index for their RAG and prompt engineering pipelines.Retrieved node with id, entering: 9439Retrieving with query id 9439: Tell me about some issues on 12/11Retrieving text node: [Bug]: Metadata filter not working with Elastic search indexing### Bug DescriptionWhile retrieving from ES with multiple metadatafilter condition(OR/AND) its not taking it into account. It always performs an AND operation even if its explicitly mentioned OR.Example below code should filter and retrieve only 'mafia' or "Stephen King" bit its not doing as expected.filters = MetadataFilters(filters=[MetadataFilter(key="theme", value="Mafia"),MetadataFilter(key="author", value="Stephen King"),],condition=FilterCondition.OR,)retriever = index.as_retriever(filters=filters)### Version0.9.13### Steps to Reproducenodes = [TextNode(text="The Shawshank Redemption",metadata={"author": "Stephen King","theme": "Friendship",},),TextNode(text="The Godfather",metadata={"director": "Francis Ford Coppola","theme": "Mafia",},),TextNode(text="Inception",metadata={"director": "Christopher Nolan",},),]filters = MetadataFilters(filters=[MetadataFilter(key="theme", value="Mafia"),MetadataFilter(key="author", value="Stephen King"),],condition=FilterCondition.OR,)retriever = index.as_retriever(filters=filters)### Relevant Logs/Tracbacks_No response_Retrieved node with id, entering: 9427Retrieving with query id 9427: Tell me about some issues on 12/11Retrieving text node: [Feature Request]: Postgres BM25 support### Feature DescriptionFeature: add a variation of PGVectorStore which uses ParadeDB's BM25 extension.BM25 is now possible in Postgres with a Rust extension [pg_bm25): https://github.com/paradedb/paradedb/tree/dev/pg_bm25Unsure if it might be better to use [pg_search](https://github.com/paradedb/paradedb/tree/dev/pg_search) and get HNSW at the same time..I'm interested in contributing on this myself, but am just starting to look into it. Interested to hear others' thoughts.### ReasonAlthough the code comments for the PGVectorStore class currently suggest BM25 search is present in Postgres - it is not.### Value of FeatureBM25 retrieval hit rate and MRR is measurable better than Postgres full text search with tsvector and tsquery. Indexing is also supposed to be faster with pg_bm25.Number of source nodes: 6{'state': 'open','created_at': '2023-12-11T10:17:52Z','url': 'https://api.github.com/repos/run-llama/llama_index/issues/9431','source': 'https://github.com/run-llama/llama_index/pull/9431','labels': ['size:XL'],'index_id': '9431'}
步骤8:插入RetrieverQueryEngine
from llama_index.query_engine import RetrieverQueryEnginefrom llama_index import ServiceContextllm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(llm=llm)query_engine = RetrieverQueryEngine.from_args(recursive_retriever, llm=llm)response = query_engine.query("Tell me about some open issues related to agents")print(str(response))# OutputThere were several issues created on 12/11. One of them is a bug where the metadata filter is not working correctly with Elastic search indexing. Another bug involves an error loading the 'punkt' module in the NLTK library. There are also a couple of feature requests, one for adding Postgres BM25 support and another for making llama-index compatible with models finetuned and hosted on modal.com. Additionally, there is a question about using the Slack Loader with large Slack channels.
四、结论
总之,将Llamaindex集成到多文档RAG架构的结构中预示着信息检索的新时代。它能够基于结构化元数据动态选择文档,再加上语义查询优化的技巧,重塑了我们如何利用庞大文档存储库中的知识,提高了检索过程的效率、相关性和准确性。
参考文献:
[1] https://ai.gopubby.com/structured-hierarchical-retrieval-revolutionizing-multi-document-rag-architectures-f101463db689
[2] https://weaviate.io/developers/wcs/quickstart
[3] https://docs.llamaindex.ai/en/stable/examples/query_engine/multi_doc_auto_retrieval/multi_doc_auto_retrieval.html
相关文章:
LLM之RAG实战(九)| 高级RAG 03:多文档RAG体系结构
在RAG(检索和生成)这样的框架内管理和处理多个文档有很大的挑战。关键不仅在于提取相关内容,还在于选择包含用户查询所寻求的信息的适当文档。基于用户查询对齐的多粒度特性,需要动态选择文档,本文将介绍结构化层次检索…...

Windows电脑引导损坏?按照这个教程能修复
前言 Windows系统的引导一般情况下是不会坏的,小伙伴们可以不用担心。发布这个帖子是因为要给接下来的文章做点铺垫。 关注小白很久的小伙伴应该都知道,小白的文章都讲得比较细。而且文章与文章之间的关联度其实还是蛮高的。在文章中,你会遇…...

记Android字符串资源支持的参数类型
参数以%开头,后拼接对应的参数类型名称,如下所示: <string name"tips">Hello, %s! You have some new messages.</string> 类型名称如下所示: s字符串格式用于插入字符串值。例如,"Hel…...
Java实现树结构(为前端实现级联菜单或者是下拉菜单接口)
Java实现树结构(为前端实现级联菜单或者是下拉菜单接口) 我们常常会遇到这样一个问题,就是前端要实现的样式是一个级联菜单或者是下拉树,如图 这样的数据接口是怎么实现的呢,是什么样子的呢? 我们可以看看 …...

MySQL中常用的数据类型
整型 int 有符号范围: -2147483648 ~ 2147483647 int unsigned 无符号范围: 0 ~ 4294967295 int(5) zerofill 仅用于显示,当不满足5位时,按照左边补0,例如: 00002满足时,正常显示 tinyint[(m)] [unsigned] [zerofill] 有符号&a…...

HTML+CSS+JS制作三款雪花酷炫特效
🎀效果展示 🎀代码展示 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html...
[C#]使用ONNXRuntime部署一种用于边缘检测的轻量级密集卷积神经网络LDC
源码地址: github.com/xavysp/LDC LDC: Lightweight Dense CNN for Edge Detection算法介绍: 由于深度学习方法的快速发展,近年来,用于执行图像边缘检测的卷积神经网络(CNN)模型爆炸性地传播。但边缘检测…...

ZigBee案例笔记 - 无线点灯
文章目录 无线点灯实验概述工程关键字工程文件夹介绍Basic RF软件设计框图简单说明工程操作Basic RF启动流程Basic RF发送流程Basic RF接收流程 无线点灯案例无线点灯现象 无线点灯实验概述 ZigBee无线点灯实验(即Basic RF工程),由TI公司提供…...
Debezium日常分享系列之:向 Debezium 连接器发送信号
Debezium日常分享系列之:向 Debezium 连接器发送信号 一、概述二、激活源信号通道三、信令数据集合的结构四、创建信令数据集合五、激活kafka信号通道六、数据格式七、激活JMX信号通道八、自定义信令通道九、Debezium 核心模块依赖项十、部署自定义信令通道十一、信…...

《C#程序设计教程》总复习
一、单项选择题 1.short 类型的变量在内存中占据的位数是 ( )。 A. 8 B. 16 C. 32 D. 64 2.对千 int[ 4,5]型的数组 a, 数组元素 a[2,3] 存在数组第 ( )个位置上。 A. 11 B. 12 C. 14 D. 15 3.设 int 类型变量 x,y,z 的值分别是2、3、6 , 那么…...

为什么ChatGPT选择了SSE,而不是WebSocket?
我在探索ChatGPT的使用过程中,发现了一个有趣的现象:ChatGPT在实现流式返回的时候,选择了SSE(Server-Sent Events),而非WebSocket。 那么问题来了:为什么ChatGPT选择了SSE,而不是We…...
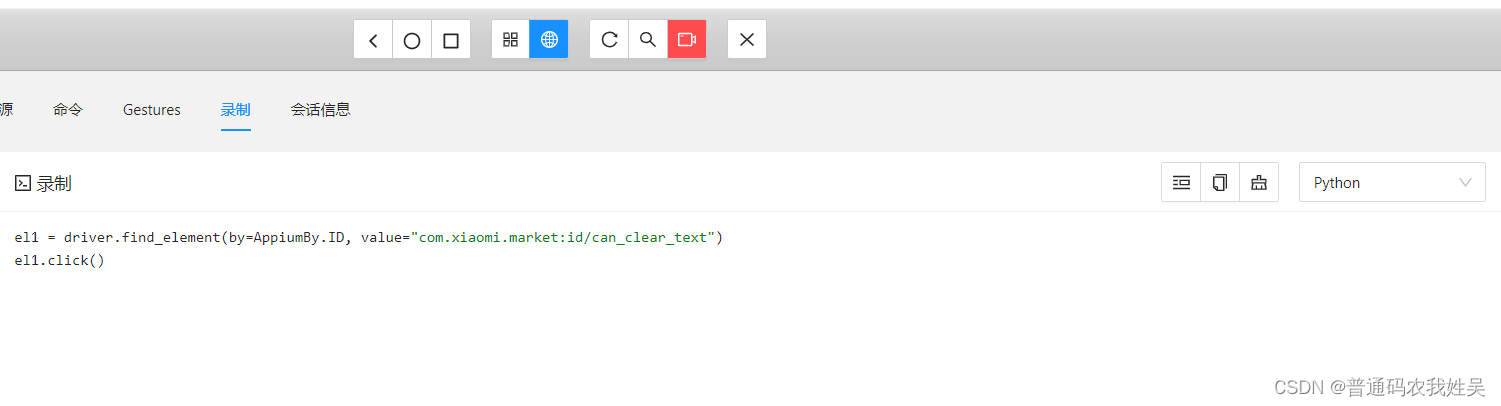
appium入门基础
介绍 appium支持在不同平台的UI自动化,如web,移动端,桌面端等。还支持使用java,python,js等语言编写自动化代码。主要用于自动化测试脚本,省去重复的手动操作。 Appium官网 安装 首先必须环境有Node.js用于安装Appium。 总体来…...
jsp介绍
JSP 一种编写动态网页的语言,可以嵌入java代码和html代码,其底层本质上为servlet,html部分为输出流,编译为java文件 例如 源jsp文件 <% page contentType"text/html; charsetutf-8" language"java" pageEncoding&…...

Debian安装k8s记录
Debian安装k8s记录 在master和node上安装kube安装master安装node遇到的问题汇总1、kubelet.service报错 failed to pull image "registry.k8s.io/pause:3.6"2、node重启后报错,failed: open /run/flannel/subnet.env: no such file or directory 在master…...
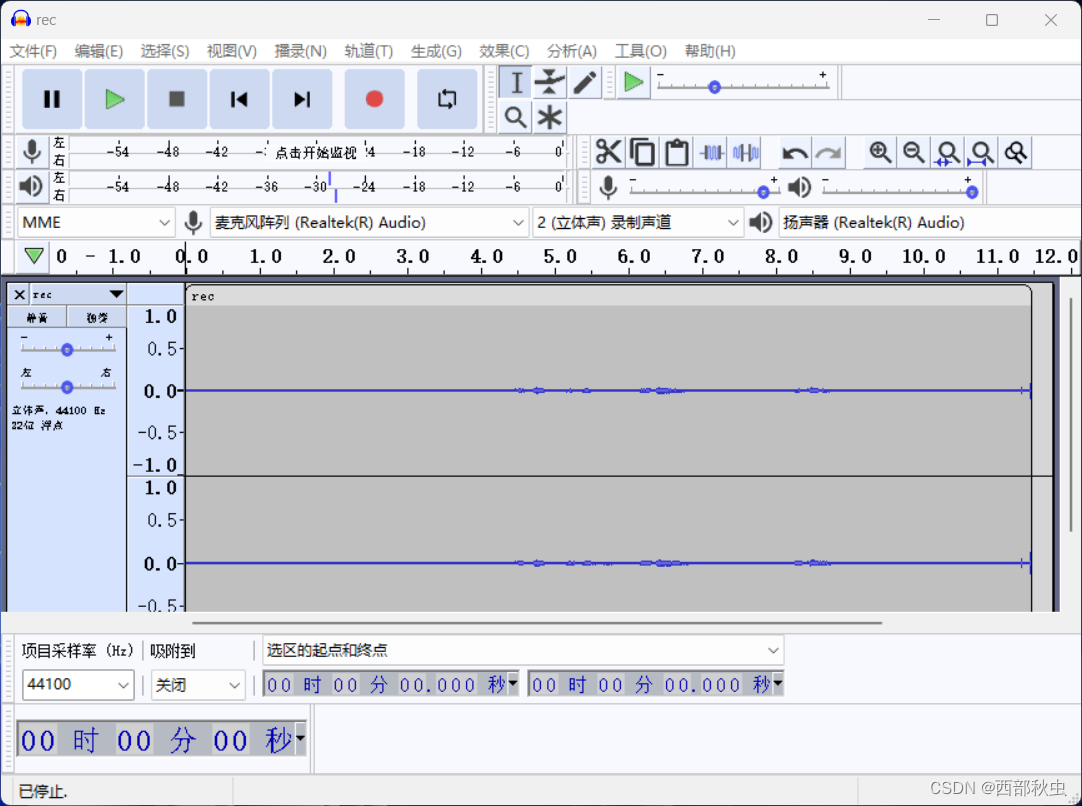
第6课 用window API捕获麦克风数据并加入队列备用
今天是2024年1月1日,新年的第一缕阳光已经普照大地,祝愿看到这篇文章的所有程序员或程序爱好者都能在新的一年里持之以恒,事业有成。 今天也是我加入CSDN的第4100天,但回过头看一看,这么长的时间也没有在CSDN写下几篇…...
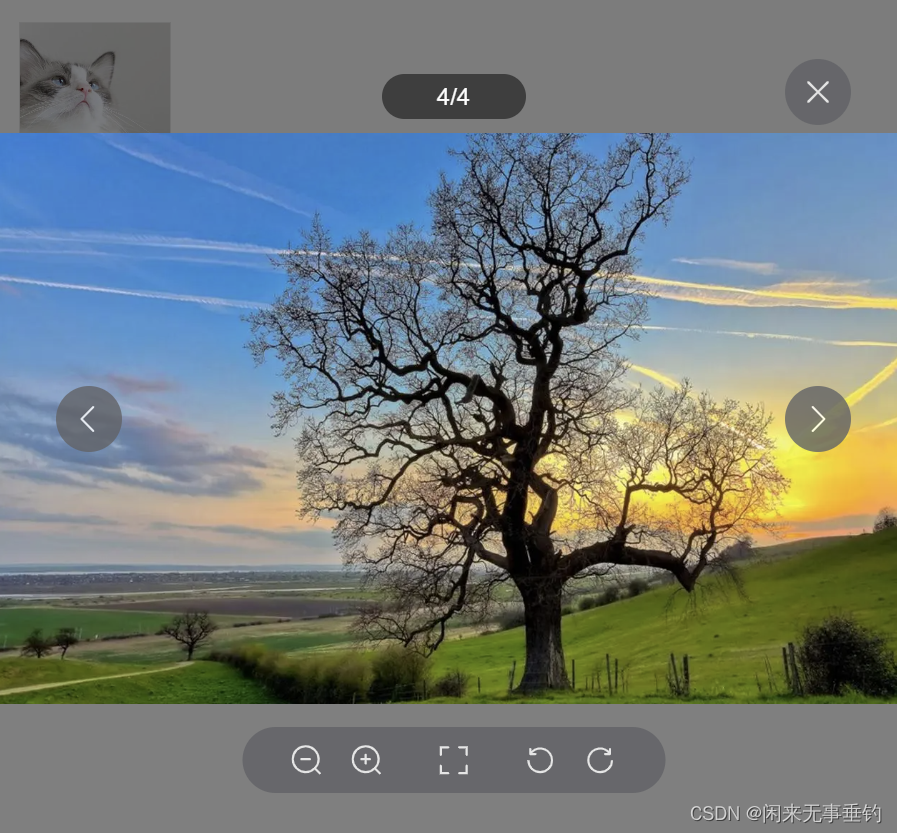
图片预览 element-plus 带页码
vue3、element-plus项目中,点击预览图片,并显示页码效果如图 安装 | Element Plus <div class"image__preview"><el-imagestyle"width: 100px; height: 100px":src"imgListArr[0]":zoom-rate"1.2":max…...

【小白专用】winform启动界面+登录窗口 更新2024.1.1
需求场景:先展示启动界面,然后打开登录界面,如果登录成功就跳转到主界面 首先在程序的入口路径加载启动界面,使用ShowDialog显示界面, 然后在启动界面中添加定时器,来实现显示一段时间的效果,等…...
自动化网络故障修复管理
什么是故障管理 故障管理是网络管理的组成部分,涉及检测、隔离和解决问题。如果实施得当,网络故障管理可以使连接、应用程序和服务保持在最佳水平,提供容错能力并最大限度地减少停机时间。专门为此目的设计的平台或工具称为故障管理系统。 …...
Git:常用命令(二)
查看提交历史 1 git log 撤消操作 任何时候,你都有可能需要撤消刚才所做的某些操作。接下来,我们会介绍一些基本的撤消操作相关的命令。请注意,有些操作并不总是可以撤消的,所以请务必谨慎小心,一旦失误,…...

Oracle 12c rac 搭建 dg
环境 rac 环境 (主)byoradbrac 系统版本:Red Hat Enterprise Linux Server release 6.5 软件版本:Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit byoradb1:172.17.38.44 byoradb2:…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...