鲜花数据集实验结果总结
从read_split_data中得到:训练数据集,验证数据集,训练标签,验证标签。的所有的具体详细路径
数据集位置:https://download.csdn.net/download/guoguozgw/87437634
import os
#一种轻量级的数据交换格式,
import json
#文件读/写操作
import pickle
import random
import matplotlib.pyplot as plt
def read_split_data(root:str,val_rate:float = 0.2):random.seed(0)#保证随机结果可重复出现assert os.path.exists(root),'dataset root:{} does not exist.'.format(root)#遍历文件夹,一个文件夹对应一个类别flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root,cla))]#排序,保证顺序一致flower_class.sort()#生成类别名称以及对应的数字索引,将数据转换为字典的类型。将标签分好类之后,其类别是key,对应的唯一值是valueclass_indices = dict((k,v) for v,k in enumerate(flower_class))#将数据编写成json文件json_str = json.dumps(class_indices,indent=4)with open('json_str','w') as json_file:json_file.write(json_str)train_images_path = [] #存储训练集的所有图片路径train_images_label = [] #存储训练集所有图片的标签val_images_path = [] #存储验证机所有图片的路径val_images_label = [] #存储验证机所有图片的标签every_class_num = [] #存储每个类别的样本总数supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型#遍历每一个文件夹下的文件for cla in flower_class:cla_path = os.path.join(root,cla)#遍历获取supported支持的所有文件路径,得到所有图片的路径地址。针对的是某一个类别。images = [os.path.join(root,cla,i) for i in os.listdir(cla_path) if os.path.splitext(i)[-1] in supported]#获取该类别对应的索引,此时对应就是数字了。对应的只是一个数字image_class = class_indices[cla]#记录该类别的样本数量every_class_num.append(len(images))#按比例随机采样验证样本,按照0.2的比例来作为测试集。val_path = random.sample(images,k=int(len(images)*val_rate))for img_path in images:#如果该路径在采样的验证集样本中则存入验证集。否则的话存入到训练集当中。其中label和image是相互对应的。if img_path in val_path:val_images_path.append(img_path)val_images_label.append(image_class)else:train_images_path.append(img_path)train_images_label.append(image_class)print('该数据集一共有{}多张图片。'.format(sum(every_class_num)))print('一共有{}张图片是训练集'.format(len(train_images_path)))print('一共有{}张图片是验证集'.format(len(val_images_path)))#输出每一个类别对应的图片个数for i in every_class_num:print(i)plot_image = Falseif plot_image:#绘制每一种类别个数柱状图plt.bar(range(len(flower_class)),every_class_num,align='center')#将横坐标0,1,2,3,4替换成相应类别的名称plt.xticks(range(len(flower_class)),flower_class)#在柱状图上添加数值标签for i,v in enumerate(every_class_num):plt.text(x=i,y=v+5,s=str(v),ha='center')#设置x坐标plt.xlabel('image class')plt.ylabel('number of images')#plt.title('flower class distribution')plt.show()return train_images_path,train_images_label,val_images_path,val_images_label
if __name__ == '__main__':root = '../11Flowers_Predict/flower_photos'read_split_data(root)
最后得到的数据信息分别如此,代码中的路径需要进行更换(替换为自己的路径)。
从写Dataset类
from PIL import Image
import torch
from torch.utils.data import Datasetclass MyDataSet(Dataset):'''自定义数据集'''def __init__(self,images_path:list,images_classes:list,transform = None):super(MyDataSet, self).__init__()self.images_path = images_pathself.images_classes = images_classesself.transform = transformdef __len__(self):return len(self.images_path)def __getitem__(self, item):img = Image.open(self.images_path[item])#RGB为彩色图片,L为灰度图片if img.mode != 'RGB':#直接在这里终止程序的运行raise ValueError('image :{} is not RGB mode.'.format(self.images_path[item]))label = self.images_classes[item]if self.transform is not None:img = self.transform(img)return img , label对数据集的预处理部分
import os
import torch
from torchvision import transforms
from utils import read_split_data
from my_dataset import MyDataSet
#数据集所在的位置
root = '../11Flowers_Predict/flower_photos'
def main():device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')print('using {} device.'.format(device))#接下来这一行是对数据的读取train_images_path,train_images_label,val_images_path,val_images_label = read_split_data(root)#设置transform,compose立main必须是列表data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"val": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}train_data_set = MyDataSet(images_path=train_images_path,images_classes=train_images_label,transform=data_transform['train'])val_data_set = MyDataSet(images_path=val_images_path,images_classes=val_images_label,transform=data_transform['val'])batch_size = 32#number of workers#nw = min([os.cpu_count() , batch_size if batch_size>1 else 0,8])#print('Using {} dataloader workers'.format(nw))train_loader = torch.utils.data.DataLoader(train_data_set,batch_size=batch_size,shuffle=True,num_workers = 0)val_loader = torch.utils.data.DataLoader(val_data_set,batch_size=batch_size,shuffle=True,num_workers = 0)for step,data in enumerate(train_loader):images,labels = data#print(images.shape)#print(labels)#print(labels.shape)return train_loader,val_loader
if __name__ == '__main__':main()
开始对数据集进行训练
import torch
from torch import nn
import torchvision
from torchvision import transforms,models
from tqdm import tqdm
from main import *
import time
HP = {'epochs':25,'batch_size':32,'learning_rate':1e-3,'momentum':0.9,'test_size':0.05,'seed':1
}#创建一个残差网络34层结果,使用预训练参数
model = models.resnet34(pretrained=True)
model.fc = torch.nn.Sequential(torch.nn.Dropout(0.1),torch.nn.Linear(model.fc.in_features,5)
)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':torch.backends.cudnn.benchmark = True
print(f'using {device} device')
#将模型添加到gpu当中
model = model.to(device)#分类问题使用交叉熵函数损失
criterion = torch.nn.CrossEntropyLoss()
#优化器使用SGD随机梯度下降法
optimizer = torch.optim.SGD(model.parameters(),lr=HP['learning_rate'],momentum=HP['momentum'])train_loader,val_loader = main()def train(model,criterion,optimizer,train_loader,val_loader):#设置总的训练损失和验证损失,以及训练准确度和验证准确度。total_train_loss = 0total_val_loss = 0total_train_accracy = 0total_val_accracy = 0model.train()#设置为训练模式loop = tqdm(enumerate(train_loader),total=len(train_loader))loop.set_description(f'training')for step,data in loop:images,labels = data#将数据添加到GPU当中images = images.to(device)labels = labels.to(device)output = model(images)#单个损失loss = criterion(output,labels)#计算准确率accracy = (output.argmax(1)==labels).sum()#将所有的损失进行相加total_train_loss += loss.item()#将所有正确的全部相加起来total_train_accracy += accracy#开始进行层数更新optimizer.zero_grad()loss.backward()optimizer.step()model.eval()loop_val = tqdm(enumerate(val_loader),total=len(val_loader))loop_val.set_description(f'valuing')for step,data in loop_val:images,labels = dataimages = images.to(device)labels = labels.to(device)output = model(images)loss = criterion(output,labels)accracy_val = (output.argmax(1)==labels).sum()total_val_loss += loss.item()total_val_accracy += accracy_valtrain_acc = total_train_accracy/(2939)val_acc = total_val_accracy/(731)train_loss = total_train_loss/(2939)val_loss = total_val_loss/(731)print(f'训练集损失率: {train_loss:.4f} 训练集准确率: {train_acc:.4f}')print(f'验证集损失率: {val_loss:.4f} 验证集准确率: {val_acc:.4f}')if __name__ == '__main__':time_start = time.time()for i in range(HP['epochs']):print(f"Epoch {i+1}/{HP['epochs']}")train(model, criterion, optimizer, train_loader, val_loader)time_end = time.time()print(time_end-time_start)
json_str
{"daisy": 0,"dandelion": 1,"roses": 2,"sunflowers": 3,"tulips": 4
}
训练结束之后,可以得出来训练出来的结果。
总结部分:
一:针对全部是目录,且目录里面是已经分好类的数据集,且数据没有分成训练集和测试集
1:函数参数设置为:路径,划分的概率
2:设置一定的随机结果
3:判断该路径是否存在,使用assert
4:根据传过来的root,来判断当前路径下所有的文件夹,如果是文件夹将其写入到列表当中
5:同时这个列表也是所有的类别,将该列表进行排序
6:使用enumerate来使其成为字典,其中key对应的是分类,value对应的是数值
7:(可以选择)使用json可以将其写入到文件当中
8:创建训练集图片路径,训练集标签路径,验证集图片路径,验证集标签路径,每个类别的数目,都是列表形式
9:开始对文件进行遍历,然后将其存放到上面的集合当中
10:以根据类别以及root使用join将其连接起来。根据类别来进行循环,然后进行拼接
11:接这这个类别循环的时候,使用随机数来将其划分验证数据集和训练数据集
二:如果数据已经分好训练集和测试集的情况下,如果存在csv的文件情况下,可以使用pandas来进行数据处理
(shuffle函数是sklearn utils里面的类),
(对csv文件读取,主要使用到的是pandas库)
1:对读取到的csv文件可以首先使用head查看前几个数据
2:使用sklearn里面的shuffle方法来进行打乱顺序
3:使用pandas里面的factorize对标签进行数据化显示(把复杂计算分解为基本运算),其返回值为元祖
4:使用unique返回的是列表,将标签封装成列表
5:再将其相互对应封装为字典:key是类别,value是数字
6:使用sklearn中的train_test_split方法来对数据集进行划分,传入参数为(DataFrame,比例)
7:使用value_count来对标签进行计数
对DataSet的重写:
1:主要是实现其中的三个方法,init,getitem,len
2:init主要是接受参数,路径,类别,以及transforms,在这里一定要吧image处理到对应的每一张图片的身上
3:返回的是image格式的图片,以及一个标签数字
部分测试代码
#
import osdef main(root:int,images_class: list,transform = None):print('root:',root)print('int:', int)print('images_class:', images_class)print('list:', list)def read_split_data(root:str,val_rate:float = 0.2):print('root:', root)print('str:', str)print('val_rate:', val_rate)print('float:', float)root = '../11Flowers_Predict/flower_photos'
#遍历文件夹
'''
os.listdir是展示当前所在层的所有文件
os.isdir判断当前这个文件是否属于文件夹
os.path.join()将两个字符串进行连接中间用/
os.path.splittext()返回的是一个元祖
'''
flowers_classes = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root,cla))]
print(flowers_classes)
flowers_classes_copy = flowers_classes.copy()
flowers_classes.sort()
print(os.path.isdir('../11Flowers_Predict/flower_photos'))
print(os.path.join(root,'roses'))
print(flowers_classes)
class_ind = dict((k, v) for v, k in enumerate(flowers_classes))
for v,k in enumerate(flowers_classes):print('此时标号{},对应的类别是{}.'.format(v,k))
for v,k in class_ind.items():print(v,k)
import json
json_str = json.dumps(class_ind,indent=2)
print(json_str)
with open('json_str','w') as json_file:json_file.write(json_str)AA = os.path.splitext('123.jpg')
print(type(os.path.splitext('123.jpg')))
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
print(AA[-1] in supported)
list = [1,2,3,4]
#main(root,list)
for cla in flowers_classes:image_class = class_ind[cla]print(image_class)
import matplotlib.pyplot as plt
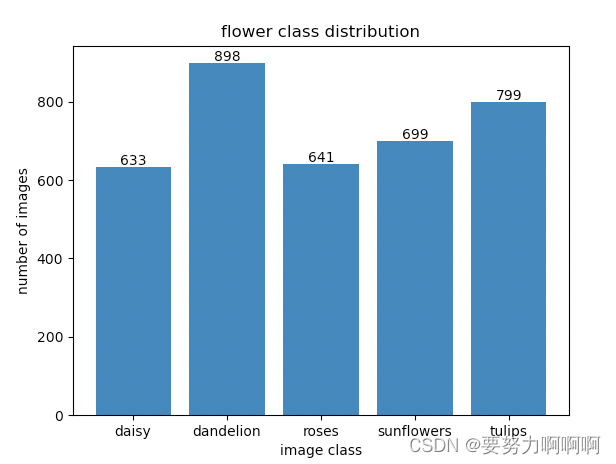
every_class_num = [633,898,641,699,799]
plt.bar(flowers_classes,every_class_num,align='center')
# 这个东西就是用来替换的
#plt.xticks(range(len(flowers_classes)),[10,11,12,13,14])
for i,v in enumerate(every_class_num):plt.text(x=i,y=v,s=str(v))
plt.show()
相关文章:
鲜花数据集实验结果总结
从read_split_data中得到:训练数据集,验证数据集,训练标签,验证标签。的所有的具体详细路径 数据集位置:https://download.csdn.net/download/guoguozgw/87437634 import os #一种轻量级的数据交换格式, …...
ElasticJob-Lite架构篇 - 认知分布式任务调度ElasticJob-Lite
前言 本文基于 ElasticJob-Lite 3.x 版本展开分析。 如果 Quartz 集群中有多个服务端节点,任务决定在哪个服务端节点上执行的呢? Quartz 采用随机负载,通过 DB 抢占下一个即将触发的 Trigger 绑定的任务的执行权限。 在 Quartz 的基础上&…...

【直击招聘C++】2.6 对象之间的复制
2.6 对象之间的复制一、要点归纳1. 对象之间的复制操作1.1 运算符1.2 拷贝构造函数2. 对象之间的浅复制和深复制2.1 对象的浅复制2.2 对象的深复制二、面试真题解析面试题1面试题2一、要点归纳 1. 对象之间的复制操作 同一个类的对象之间可以进行复制操作,即将一个…...

学了这么久python,不会连自己啥python版本都不知道吧?
人生苦短,我用Python 源码资料电子书:点击此处跳转文末名片获取 查看 Python 版本 我们可以在命令窗口(Windows 使用 winR 调出 cmd 运行框)使用以下命令查看我们使用的 Python 版本: python -V 或 python --version 以上命令执行结果如下: …...

Revive:从间谍软件进化成银行木马
2022 年 6 月,Cleafy 研究人员发现了一个新的安卓银行木马 Revive。之所以选择 Revive 这个名称,是因为恶意软件为防止停止工作启用的一项功能名为 revive。 Revive 属于持续潜伏的那一类恶意软件,因为它是为特定目标开发和定制的。这种类型…...
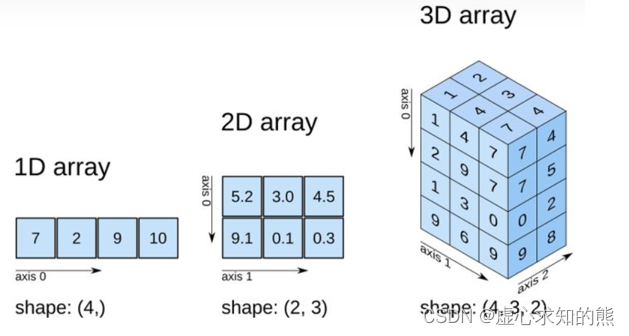
Python 之 NumPy 简介和创建数组
文章目录一、NumPy 简介1. 为什么要使用 NumPy2. NumPy 数据类型3. NumPy 数组属性4. NumPy 的 ndarray 对象二、numpy.array() 创建数组1. 基础理论2. 基础操作演示3. numpy.array() 参数详解三、numpy.arange() 生成区间数组四、numpy.linspace() 创建等差数列五、numpy.logs…...
与六年测试工程师促膝长谈,他分享的这些让我对软件测试工作有了全新的认知~
不知不觉已经从事软件测试六年了,2016年毕业到进入外包公司外包给微软做软件测试, 到现在加入著名的外企。六年的时间过得真快。长期的测试工作也让我对软件测试有了比较深入的认识。但是我至今还是一个底层的测试人员,我的看法都比较狭隘&am…...

裕太微在科创板上市:市值约186亿元,哈勃科技和小米基金为股东
2月10日,裕太微电子股份有限公司(下称“裕太微”,SH:688515)在上海证券交易所上市。本次上市,裕太微的发行价为92元/股,发行2000万股,发行市盈率不适用,发行后总股本8000万股。 根据…...

毕业后5年,我终于变成了月薪13000的软件测试工程师
我用了近2个月的时间转行,在今年1月底顺利入职了一家北京的互联网公司,从事的是软件测试的工作。 和大家看到的一样,我求职的时间花费的比较短,求职过程非常顺利,面试了一周就拿到了3家offer,3家offer的薪…...

实践指南|如何在 Jina 中使用 OpenTelemetry 进行应用程序的监控和跟踪
随着软件和云技术的普及,越来越多的企业开始采用微服务架构、容器化、多云部署和持续部署模式,这增加了因系统失败而给运维/ SRE / DevOps 团队带来的压力,从而增加了开发团队和他们之间的摩擦,因为开发团队总是想尽快部署新功能&…...
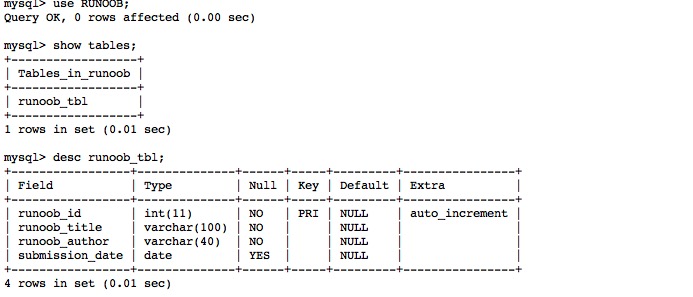
MySQL 创建数据表
在创建数据库之后,接下来就要在数据库中创建数据表。所谓创建数据表,指的是在已经创建的数据库中建立新表。 创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性(包括实体完整性、引用完整性和域完整性)…...

一文详解网络安全事件的防护与响应
网络安全事件的发生,往往意味着一家企业的生产经营活动受到影响,甚至数据资产遭到泄露。日益复杂的威胁形势使现代企业面临更大的网络安全风险。因此,企业必须提前准备好响应网络安全事件的措施,并制定流程清晰、目标明确的事件响…...

vue directive 注册局部指令
注册局部指令 vue directive 在注册局部指令时,是通过在组件 options 选项中设置 directives 属性。如下: directives: {focus: {// 指令的定义inserted: function (el) {el.focus()}} }在模板中的任何元素上都可以使用新的 v-focus propertyÿ…...
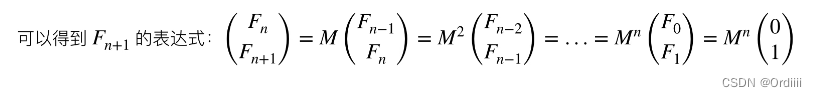
LC-70-爬楼梯
原题链接:爬楼梯 个人解法 思路: 动态规划 状态表示:f[i]表示走到第n阶台阶有几种方法 状态转移:f[i] f[i -1] f[i - 2] 这实际上就是斐波那契数列,通过转移可以看到,我们只用了三个变量,故…...

Scratch少儿编程案例-可爱的简约贪吃蛇
专栏分享 点击跳转=>Unity3D特效百例点击跳转=>案例项目实战源码点击跳转=>游戏脚本-辅助自动化点击跳转=>Android控件全解手册点击跳转=>Scratch编程案例👉关于作者...

编译 Android 时如何指定输出目录?
文章目录0. 导读1. 指定 Android 编译输出目录2. 指定 Android dist 编译输出目录3. 指定 Android 模块编译输出目录4. Android 源码中编译相关的文档0. 导读 偶尔会有朋友问编译 Android 时如何指定输出目录? 这里有两种情况: 一是如何将 Android 默认的输出目…...

CF1574C Slay the Dragon 题解
CF1574C Slay the Dragon 题解题目链接字面描述题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示代码实现题目 链接 https://www.luogu.com.cn/problem/CF1574C 字面描述 题面翻译 给定长度为 nnn 的序列 aaa,mmm 次询问,每次询…...
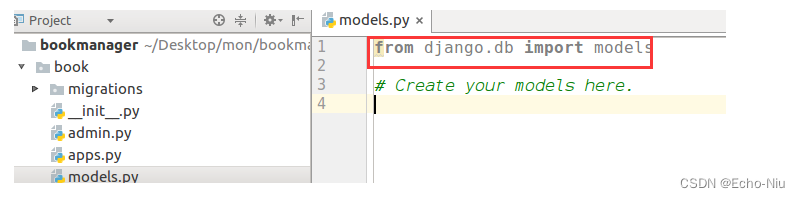
创建Django项目
创建Django项目 步骤 创建Django项目 django-admin startproject name 创建子应用 python manager.py startapp name创建工程 在使用Flask框架时,项目工程目录的组织与创建是需要我们自己手动创建完成的。 在django中,项目工程目录可以借助django提供…...
CUDA中的统一内存
文章目录1. Unified Memory Introduction1.1. System Requirements1.2. Simplifying GPU Programming1.3. Data Migration and Coherency1.4. GPU Memory Oversubscription1.5. Multi-GPU1.6. System Allocator1.7. Hardware Coherency1.8. Access Counters2. Programming Mode…...

利用机器学习(mediapipe)进行人脸468点的3D坐标检测--视频实时检测
上期文章,我们分享了人脸468点的3D坐标检测的图片检测代码实现过程,我们我们介绍一下如何在实时视频中,进行人脸468点的坐标检测。 import cv2 import mediapipe as mp mp_drawing = mp.solutions.drawing_utils mp_face_mesh = mp.solutions.face_mesh face_mesh = mp_fac…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...