Spark中使用DataFrame进行数据转换和操作
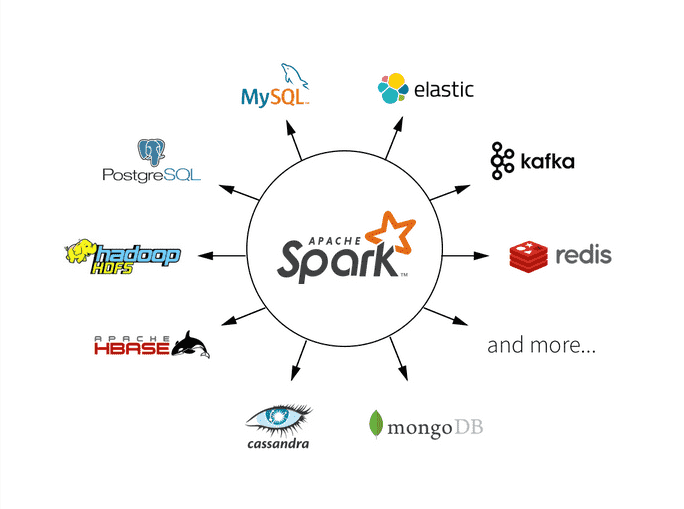
Apache Spark是一个强大的分布式计算框架,其中DataFrame是一个核心概念,用于处理结构化数据。DataFrame提供了丰富的数据转换和操作功能,使数据处理变得更加容易和高效。本文将深入探讨Spark中如何使用DataFrame进行数据转换和操作,包括数据加载、数据筛选、聚合、连接和窗口函数等方面的内容。
DataFrame简介
DataFrame是一种分布式数据集,它以表格形式组织数据,每一列都有名称和数据类型。DataFrame是强类型的,这意味着它可以在编译时捕获错误,提供更好的类型安全性。可以将DataFrame视为关系型数据库表或Excel表格,但它具有分布式计算的能力。
数据加载
在使用DataFrame进行数据转换和操作之前,首先需要加载数据。Spark支持多种数据源,包括文本文件、JSON文件、Parquet文件、CSV文件、关系型数据库、Hive表等。以下是一些常见的数据加载示例:
1 从文本文件加载数据
from pyspark.sql import SparkSession# 创建SparkSession
spark = SparkSession.builder.appName("DataLoadingExample").getOrCreate()# 从文本文件加载数据
text_data = spark.read.text("data.txt")# 显示数据
text_data.show()
2 从JSON文件加载数据
# 从JSON文件加载数据
json_data = spark.read.json("data.json")# 显示数据
json_data.show()
3 从Parquet文件加载数据
# 从Parquet文件加载数据
parquet_data = spark.read.parquet("data.parquet")# 显示数据
parquet_data.show()
4 从关系型数据库加载数据
# 配置数据库连接信息
jdbc_url = "jdbc:mysql://localhost:3306/mydb"
connection_properties = {"user": "username","password": "password","driver": "com.mysql.jdbc.Driver"
}# 从数据库加载数据
db_data = spark.read.jdbc(url=jdbc_url, table="mytable", properties=connection_properties)# 显示数据
db_data.show()
数据转换和操作
一旦加载了数据,可以使用DataFrame进行各种数据转换和操作。以下是一些常见的数据转换和操作示例:
1 数据筛选
可以使用filter方法筛选满足条件的数据行:
# 筛选年龄大于30的数据
filtered_data = df.filter(df["age"] > 30)# 显示筛选结果
filtered_data.show()
2 列选择
可以使用select方法选择要保留的列:
# 选择"name"和"age"列
selected_data = df.select("name", "age")# 显示选择的列
selected_data.show()
3 列重命名
可以使用withColumnRenamed方法为列重命名:
# 将"name"列重命名为"full_name"
renamed_data = df.withColumnRenamed("name", "full_name")# 显示重命名后的数据
renamed_data.show()
4 数据聚合
可以使用groupBy和聚合函数进行数据聚合:
from pyspark.sql import functions as F# 按性别分组,并计算每组的平均年龄
aggregated_data = df.groupBy("gender").agg(F.avg("age").alias("average_age"))# 显示聚合结果
aggregated_data.show()
5 数据连接
可以使用join方法连接不同的DataFrame:
# 连接两个DataFrame
joined_data = df1.join(df2, "id", "inner")# 显示连接结果
joined_data.show()
6 窗口函数
窗口函数可以在DataFrame中执行聚合计算,同时保留原始行的信息。以下是一个窗口函数的示例:
from pyspark.sql.window import Window# 定义窗口规范
window_spec = Window.partitionBy("department").orderBy("salary")# 计算每个部门中工资最高的员工
max_salary_employee = df.withColumn("max_salary", F.max("salary").over(window_spec)) \.filter(df["salary"] == df["max_salary"]) \.drop("max_salary")# 显示结果
max_salary_employee.show()
数据保存
在对数据进行转换和操作后,通常需要将结果保存回不同的数据源或文件中。Spark支持多种数据保存方式,以下是一些常见的数据保存方式:
1 保存数据到文本文件
# 保存数据到文本文件
text_data.write.text("output.txt")
2 保存数据到JSON文件
# 保存数据到JSON文件
json_data.write.json("output.json")
3 保存数据到Parquet文件
# 保存数据到Parquet文件
parquet_data.write.parquet("output.parquet")
4 保存数据到关系型数据库
# 保存数据到数据库
db_data.write.jdbc(url=jdbc_url, table="newtable", mode="overwrite", properties=connection_properties)
性能优化和注意事项
在使用DataFrame进行数据转换和操作时,性能优化是一个重要的考虑因素。以下是一些性能优化和注意事项:
1 数据分区
合理分区数据可以提高数据操作的并行性和性能。
# 重新分区数据
data.repartition(4)
2 数据缓存
对于频繁使用的DataFrame,可以使用cache或persist方法将数据缓存到内存中,以避免重复计算。
# 缓存数据到内存中
data.cache()
3 合并转换操作
合并多个数据转换操作可以减少数据扫描和计算开销,提高性能。
总结
Spark中的DataFrame是一个强大的工具,用于处理结构化数据,并提供了丰富的数据转换和操作功能。本文深入探讨了DataFrame的基本概念、数据加载、数据筛选、列选择、数据聚合、数据连接、窗口函数、数据保存以及性能优化和注意事项等方面的内容。
希望本文能够帮助大家更好地理解和使用DataFrame,在数据处理和分析任务中取得更好的效果和性能。
相关文章:
Spark中使用DataFrame进行数据转换和操作
Apache Spark是一个强大的分布式计算框架,其中DataFrame是一个核心概念,用于处理结构化数据。DataFrame提供了丰富的数据转换和操作功能,使数据处理变得更加容易和高效。本文将深入探讨Spark中如何使用DataFrame进行数据转换和操作࿰…...
windows11新装机,简单评测系统自带软件(基本涵盖日常所需应用)
新年将近,由于当年安排的失误,系统盘(100G)和照片视频盘(4T)容量不够了,大容量的那块机械盘放在机箱里就在耳朵根吵吵,烦得很,于是狠狠心决定扩容后重配重装。 2023年最后…...

概念解析 | Shapley值及其在深度学习中的应用
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:Shapley值及其在深度学习中的应用。 1 背景介绍 在机器学习和数据分析中,理解模型的预测是非常重要的。尤其是在深度学习黑盒模型中,我们往往难以直观地理解模型的预测行为。为…...

ajax的完整写法——success/error/complete+then/catch/done+设置请求头两种方法——基础积累
ajax的完整写法——success/error/completethen/catch/done设置请求头两种方法——基础积累 1.完整写法——success/error/complete1.1 GET/DELETE——query传参1.2 GET/DELETE——JSON对象传参1.3 PUT/POST——JSON对象传参 2.简化写法——then/catch/done2.1 GET/DELETE——q…...

《Linux详解:深入探讨计算机基础》
《Linux详解:深入探讨计算机基础》 引言: 在计算机科学领域,操作系统是一个至关重要的概念,而Linux作为一种开源的Unix-like操作系统,不仅在服务器领域广泛应用,也在嵌入式系统、超级计算机等多个领域发挥…...
HarmonyOS 实践之应用状态变量共享
平时在开发的过程中,我们会在应用中共享数据,在不同的页面间共享信息。虽然常用的共享信息,也可以通过不同页面中组件间信息共享的方式,但有时使用应用级别的状态管理会让开发工作变得简单。 根据不同的使用场景,ArkTS…...

ThreadLocal共享变量
一、ThreadLocal 我们知道多线程访问同一个共享变量时,会出现线程安全问题,为了保证线程安全开发者需要对共享变量的访问操作进行适当的同步操作,如加锁等同步操作。 除此之外,Java提供了ThreadLocal类,当一个共享变…...

前端crypto-js 库: MD5
文章目录 什么是crypto-js安装依赖MD5 什么是crypto-js github地址: https://github.com/brix/crypto-js cryptojs文档: https://cryptojs.gitbook.io/docs/#encoders CryptoJS (crypto.js) 为 JavaScript 提供了各种各样的加密算法。 CryptoJS是一个JavaScript加密算法库&a…...

2024新年快乐
2024-1-1 祝福大家和自己健康喜乐,升职加薪,新年快乐 页面加载事件load 我们页面加载事件的触发是等所有的资源加载完毕时触发该事件。和click一样是事件,但是触发时机是等资源加载(浏览器)完毕。这个事件我们可以将…...

OpenCV-Python(21):轮廓特征及周长、面积凸包检测和形状近似
2. 轮廓特征 轮廓特征是指由轮廓形状和结构衍生出来的一些特征参数。这些特征参数可以用于图像识别、目标检测和形状分析等应用中。常见的轮廓特征包括: 面积:轮廓所包围的区域的面积。周长:轮廓的周长,即轮廓线的长度。弧长&…...
连接progressql报错Cannot load JDBC driver class ‘org.postgresql.Driver‘,亲测有效!!!
Jmeter连接progressql报错Cannot load JDBC driver class ‘org.postgresql.Driver’ 1.到官方下载驱动注意:根据项目的JDK版本来下载对应的驱动Download | pgJDBC 2.将postgresql-42.2.27.jar复制到lib目录下面, 然后重新启动 连接driver信息如下&#…...

SQLAlchemy快速入门
安装依赖 pip install sqlalchemy pip install pymysql创建数据库和表 # 创建数据库 drop database if exists sqlalchemy_demo; create database sqlalchemy_demo character set utf8mb4; use sqlalchemy_demo;# 创建表 drop table if exists user; create table user (id …...
java 纯代码导出pdf合并单元格
java 纯代码导出pdf合并单元格 接上篇博客 java导出pdf(纯代码实现) 后有一部分猿友叫我提供一下源码,实际上我的源码已经贴在帖子上了,都是同样的步骤,只是加多一点设置就可以了。今天我再次上传一下相对情况比较完整…...

Linux自己的应用商店yum
💫Linux系统如何安装软件 在Linux系统中我们可以通过多种方式安装软件,常见方式有以下三种: 1.源代码安装 2.rpm包安装 3.使用yum软件包管理器安装 早期人们通过下载软件源代码,然后再经过交叉编译等一系列工作下…...

集成电路模拟设计——【基于Serdes 应用的 串化/解串器 时钟与数据恢复电路CDR】
串化/解串器 & 时钟与数据恢复电路CDR(可提供实现过程、仿真波形与具体参数细节 本文内容摘要背景串化/解串器全速树形串化器半速树形串化器全速移位寄存器串化器多级树形解串器 PLL型CDR整体架构实现结果 Bang-Bang型CDR整体架构 PS/PI型CDR电路PS电路设计PI电…...

OpenWrt 编译入门(小白版)
编译环境 示例编译所用系统为 Ubuntu 22.04,信息如下 编译时由于网络问题,部分软件包可能出现下载问题,还请自备网络工具或尝试重新运行命令 编译步骤 下图为官网指示 编译环境设置(Build system setup) 这里根据我…...
嵌入式视频播放器(mplayer)
1.文件准备: MPlayer-1.0rc2.tar.bz2 libmad-0.15.1b.tar.gz 直接Git到本地 git clone https://gitee.com/zxz_FINE/mplayer_tarball.git 2.文件夹准备: src存放解压后的源码文件,target_Mplayer存放编译安装的目标文件 mkdir src targe…...

对房价数据集进行处理和数据分析
大家好,我是带我去滑雪,每天教你一个小技巧! 房价数据集通常包含各种各样的特征,如房屋面积、地理位置、建造年份等。通过对数据进行处理和分析,可以更好地理解这些特征之间的关系,以及它们对房价的影响程度…...

BERT的学习
BERT 1.前言 self-supervised learning是一种无监督学习的特殊形式,算法从数据本身生成标签或者目标,然后利用这些生成的目标来进行学习。(也就是说数据集的标签是模型自动生成的,不是由人为提供的。)例如࿰…...

数据结构OJ实验9-图存储结构和遍历
A. 图综合练习--构建邻接表 题目描述 已知一有向图,构建该图对应的邻接表。 邻接表包含数组和单链表两种数据结构,其中每个数组元素也是单链表的头结点,数组元素包含两个属性,属性一是顶点编号info,属性二是指针域n…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...