【大数据面试知识点】Spark的DAGScheduler
Spark数据本地化是在哪个阶段计算首选位置的?
先看一下DAGScheduler的注释,可以看到DAGScheduler除了Stage和Task的划分外,还做了缓存的跟踪和首选运行位置的计算。
DAGScheduler注释:
The high-level scheduling layer that implements stage-oriented scheduling. It computes a DAG of stages for each job, keeps track of which RDDs and stage outputs are materialized, and finds a minimal schedule to run the job. It then submits stages as TaskSets to an underlying TaskScheduler implementation that runs them on the cluster. A TaskSet contains fully independent tasks that can run right away based on the data that's already on the cluster (e.g. map output files from previous stages), though it may fail if this data becomes unavailable.
Spark stages are created by breaking the RDD graph at shuffle boundaries. RDD operations with "narrow" dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage, but operations with shuffle dependencies require multiple stages (one to write a set of map output files, and another to read those files after a barrier). In the end, every stage will have only shuffle dependencies on other stages, and may compute multiple operations inside it. The actual pipelining of these operations happens in the RDD.compute() functions of various RDDs
In addition to coming up with a DAG of stages, the DAGScheduler also determines the preferred locations to run each task on, based on the current cache status, and passes these to the low-level TaskScheduler. Furthermore, it handles failures due to shuffle output files being lost, in which case old stages may need to be resubmitted. Failures *within* a stage that are not caused by shuffle file loss are handled by the TaskScheduler, which will retry each task a small number of times before cancelling the whole stage.
When looking through this code, there are several key concepts:
- Jobs (represented by ActiveJob) are the top-level work items submitted to the scheduler. For example, when the user calls an action, like count(), a job will be submitted through submitJob. Each Job may require the execution of multiple stages to build intermediate data.
- Stages (Stage) are sets of tasks that compute intermediate results in jobs, where each task computes the same function on partitions of the same RDD. Stages are separated at shuffle boundaries, which introduce a barrier (where we must wait for the previous stage to finish to fetch outputs). There are two types of stages: ResultStage, for the final stage that executes an action, and ShuffleMapStage, which writes map output files for a shuffle. Stages are often shared across multiple jobs, if these jobs reuse the same RDDs.
- Tasks are individual units of work, each sent to one machine.
- Cache tracking: the DAGScheduler figures out which RDDs are cached to avoid recomputing them and likewise remembers which shuffle map stages have already produced output files to avoid redoing the map side of a shuffle.
- Preferred locations: the DAGScheduler also computes where to run each task in a stage based on the preferred locations of its underlying RDDs, or the location of cached or shuffle data.
- Cleanup: all data structures are cleared when the running jobs that depend on them finish, to prevent memory leaks in a long-running application.
To recover from failures, the same stage might need to run multiple times, which are called "attempts". If the TaskScheduler reports that a task failed because a map output file from a previous stage was lost, the DAGScheduler resubmits that lost stage. This is detected through a CompletionEvent with FetchFailed, or an ExecutorLost event. The DAGScheduler will wait a small amount of time to see whether other nodes or tasks fail, then resubmit TaskSets for any lost stage(s) that compute the missing tasks. As part of this process, we might also have to create Stage objects for old (finished) stages where we previously cleaned up the Stage object. Since tasks from the old attempt of a stage could still be running, care must be taken to map any events received in the correct Stage object.
Here's a checklist to use when making or reviewing changes to this class:
- All data structures should be cleared when the jobs involving them end to avoid indefinite accumulation of state in long-running programs.
- When adding a new data structure, update DAGSchedulerSuite.assertDataStructuresEmpty to include the new structure. This will help to catch memory leaks.
DAGScheduler的运行时机
DAGScheduler运行时机:Driver端初始化SparkContext时。DAGScheduler是在整个Spark Application的入口即 SparkContext中声明并实例化的。在实例化DAGScheduler之前,巳经实例化了SchedulerBackend和底层调度器 TaskScheduler。
如果是SQL任务的话,SparkSQL通过Catalyst(Spark SQL的核心是Catalyst优化器)将SQL先翻译成逻辑计划再翻译成物理计划,再转换成RDD的操作。之后运行时再通过DAGScheduler做RDD任务的划分和调度。
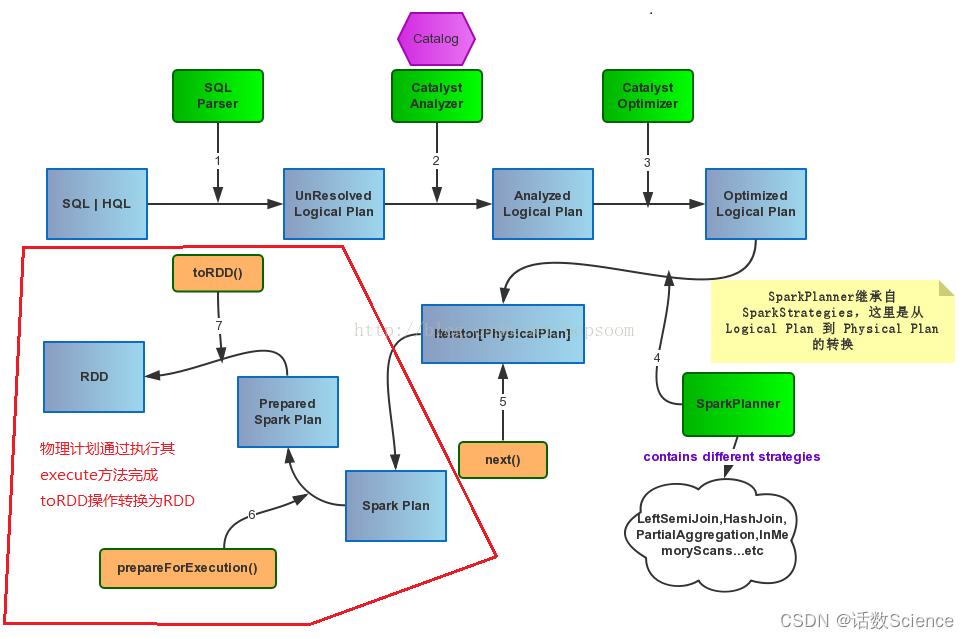
DAGScheduler如何划分Stage的?
用户提交的计算任务是一个由RDD依赖构成的DAG,Spark会把RDD的依赖以shuffle依赖为边界划分成多个Stage,这些Stage之间也相互依赖,形成了Stage的DAG。然后,DAGScheduler会按依赖关系顺序执行这些Stage。
要是把RDD依赖构成的DAG看成是逻辑执行计划(logic plan),那么,可以把Stage看成物理执行计划,为了更好的理解这个概念,我们来看一个例子。
下面的代码用来对README.md文件中包含整数值的单词进行计数,并打印RDD之间的依赖关系(Lineage):
scala> val counts = sc.textFile("README.md").flatMap(x=>x.split("\\W+")).filter(_.matches(".*\\d.*")).map(x=>(x,1)).reduceByKey(_+_)// 调用一个action函数,用来触发任务的提交和执行scala> counts.collect()// 打印RDD的依赖关系(Lineage)scala> counts.toDebugStringres7: String =(2) ShuffledRDD[17] at reduceByKey at <console>:24 []+-(2) MapPartitionsRDD[16] at map at <console>:24 []| MapPartitionsRDD[15] at filter at <console>:24 []| MapPartitionsRDD[14] at flatMap at <console>:24 []| README.md MapPartitionsRDD[13] at textFile at <console>:24 []| README.md HadoopRDD[12] at textFile at <console>:24 []DAGScheduler会根据Shuffle划分前后两个Stage:即StageShuffleMapStage和ResultStage
ShuffleMapStage
先看下ShuffleMapStage的注释,核心就是再讲ShuffleMapStage是做ShuffleWrite的Stage,Stage中是算子的pipline。
ShuffleMapStages are intermediate stages in the execution DAG that produce data for a shuffle.
They occur right before each shuffle operation, and might contain multiple pipelined operations before that (e.g. map and filter). When executed, they save map output files that can later be fetched by reduce tasks. The `shuffleDep` field describes the shuffle each stage is part of, and variables like `outputLocs` and `numAvailableOutputs` track how many map outputs are ready.
ShuffleMapStages can also be submitted independently as jobs with DAGScheduler.submitMapStage.
For such stages, the ActiveJobs that submitted them are tracked in `mapStageJobs`. Note that there can be multiple ActiveJobs trying to compute the same shuffle map stage.
ShuffleMapStages是在DAG执行过程中产生的Stage,用来为Shuffle产生数据。ShuffleMapStages发生在每个Shuffle操作之前,在Shuffle之前可能有多个窄转换操作,比如:map,filter,这些操作可以形成流水线(pipeline)。当执行ShuffleMapStages时,会产生Map的输出文件,这些文件会被随后的Reduce任务使用。
ShuffleMapStages也可以作为Jobs,通过DAGScheduler.submitMapStage函数单独进行提交。对于这样的Stages,会在变量mapStageJobs中跟踪提交它们的ActiveJobs。 要注意的是,可能有多个ActiveJob尝试计算相同的ShuffleMapStages。
它为一个shuffle过程产生map操作的输出文件。它也可能是自适应查询规划/自适应调度工作的最后阶段。
ResultStage
再看ResultStage的注释
ResultStages apply a function on some partitions of an RDD to compute the result of an action.
The ResultStage object captures the function to execute, `func`, which will be applied to each partition, and the set of partition IDs, `partitions`. Some stages may not run on all partitions of the RDD, for actions like first() and lookup().
ResultStage是Job的最后一个Stage,该Stage是基于执行action函数的rdd来创建的。该Stage用来计算一个action操作的结果。该类的声明如下:
private[spark] class ResultStage(id: Int,rdd: RDD[_],val func: (TaskContext, Iterator[_]) => _,val partitions: Array[Int],parents: List[Stage], //依赖的父StagefirstJobId: Int,callSite: CallSite)extends Stage(id, rdd, partitions.length, parents, firstJobId, callSite) {为了计算action操作的结果,ResultStage会在目标RDD的一个或多个分区上使用函数:func。需要计算的分区id集合保存在成员变量:partitions中。但对于有些action操作,比如:first(),take()等,函数:func可能不会在所有分区上使用。
另外,在提交Job时,会先创建ResultStage。但在提交Stage时,会先递归找到该Stage依赖的父级Stage,并先提交父级Stage。如下图所示:

举个例子:
思考题
如下rdd运算,为什么最终只划分了3个Stage
scala> val rdd1 = sc.textFile("/root/tmp/a.txt",3).flatMap(x=>x.split(",")).map(x=>(x,1)).reduceByKey((a,b)=>a+b)
val rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:1scala> val rdd2 = sc.textFile("/root/tmp/a.txt",3).flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
val rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:1scala> val rdd3 = rdd1.join(rdd2)
val rdd3: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[12] at join at <console>:1scala> val rdd4 = rdd3.groupByKey()
val rdd4: org.apache.spark.rdd.RDD[(String, Iterable[(Int, Int)])] = MapPartitionsRDD[13] at groupByKey at <console>:1scala> rdd4.collect().foreach(println)
(c,Seq((2,2)))
(d,Seq((1,1)))
(a,Seq((2,2)))
(b,Seq((1,1)))scala> rdd4.toDebugString
val res8: String =
(3) MapPartitionsRDD[13] at groupByKey at <console>:1 []| MapPartitionsRDD[12] at join at <console>:1 []| MapPartitionsRDD[11] at join at <console>:1 []| CoGroupedRDD[10] at join at <console>:1 []| ShuffledRDD[4] at reduceByKey at <console>:1 []+-(3) MapPartitionsRDD[3] at map at <console>:1 []| MapPartitionsRDD[2] at flatMap at <console>:1 []| /root/tmp/a.txt MapPartitionsRDD[1] at textFile at <console>:1 []| /root/tmp/a.txt HadoopRDD[0] at textFile at <console>:1 []| ShuffledRDD[9] at reduceByKey at <console>:1 []+-(3) MapPartitionsRDD[8] at map at <console>:1 []| MapPartitionsRDD[7] at flatMap at <console>:1 []| /root/tmp/a.txt MapPartitionsRDD[6] at textFile at <console>:1 []| /root/t...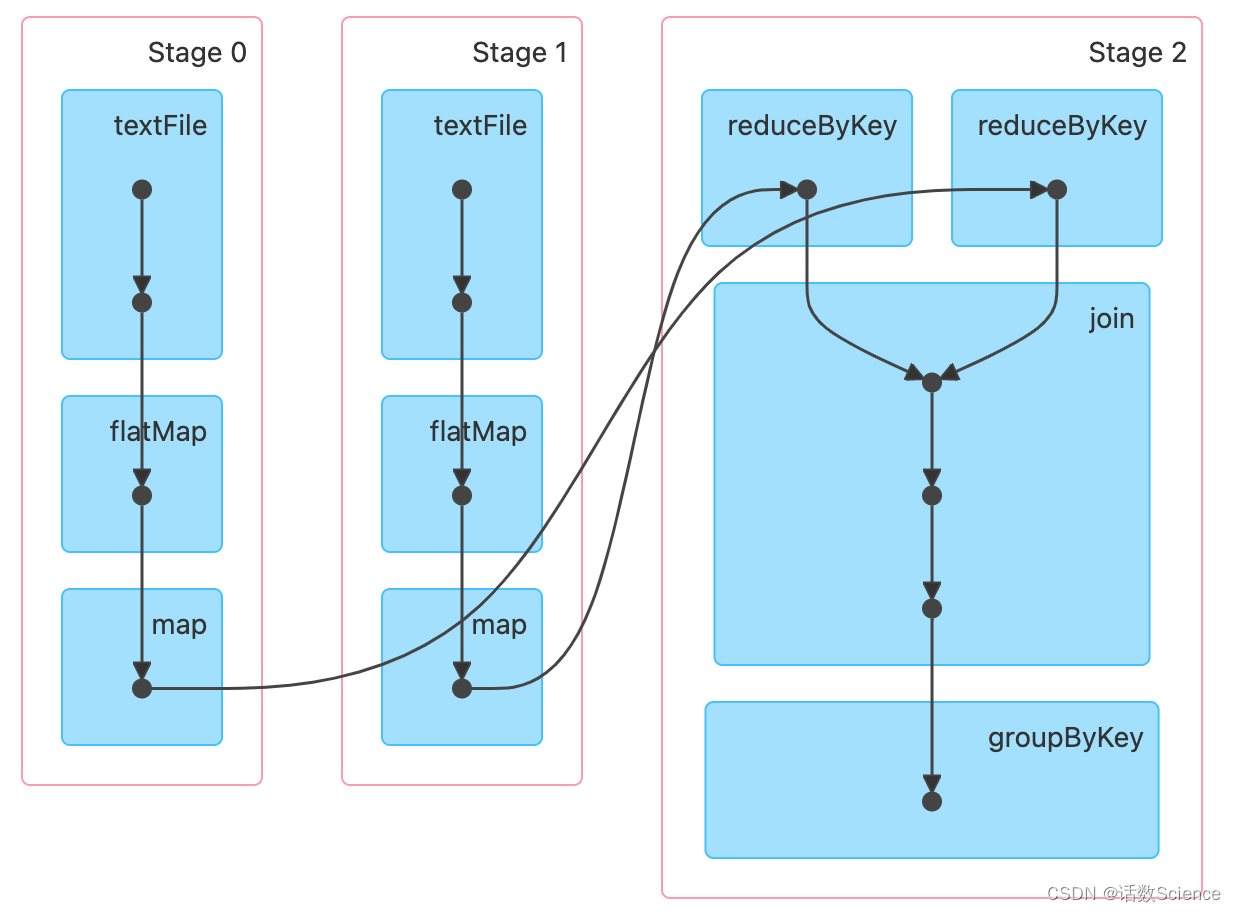
参考:DAGScheduler-Stage的划分与提交 - 知乎Spark SQL 源码分析之Physical Plan 到 RDD的具体实现_physicalplan到rdd的具体实现-CSDN博客
一文搞定Spark的DAG调度器(DAGScheduler)_spark dagscheduler-CSDN博客
相关文章:
【大数据面试知识点】Spark的DAGScheduler
Spark数据本地化是在哪个阶段计算首选位置的? 先看一下DAGScheduler的注释,可以看到DAGScheduler除了Stage和Task的划分外,还做了缓存的跟踪和首选运行位置的计算。 DAGScheduler注释: The high-level scheduling layer that i…...
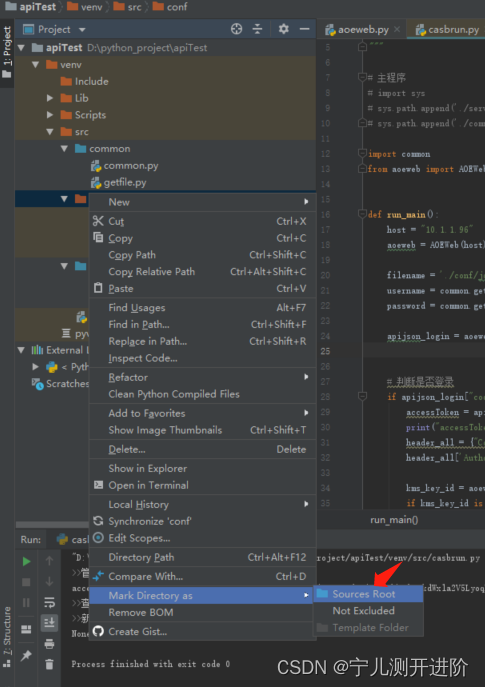
Pycharm引用其他文件夹的py
Pycharm引用其他文件夹的py 方式1:包名设置为Sources ROOT 起包名的时候,需要在该文件夹上:右键 --> Mark Directory as --> Sources ROOT 标记目录为源码目录,就可以了。 再引用就可以了 import common from aoeweb impo…...
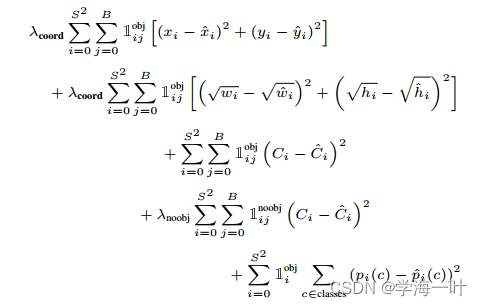
目标检测-One Stage-YOLOv1
文章目录 前言一、YOLOv1的网络结构和流程二、YOLOv1的损失函数三、YOLOv1的创新点总结 前言 前文目标检测-Two Stage-Mask RCNN提到了Two Stage算法的局限性: 速度上并不能满足实时的要求 因此出现了新的One Stage算法簇,YOLOv1是目标检测中One Stag…...
PHP序列化总结3--反序列化的简单利用及案例分析
反序列化中生成对象里面的值,是由反序列化里面的值决定,与原类中预定义的值的值无关,穷反序列化的对象可以使用类中的变量和方法 案例分析 反序列化中的值可以覆盖原类中的值 我们创建一个对象,对象创建的时候触发了construct方…...
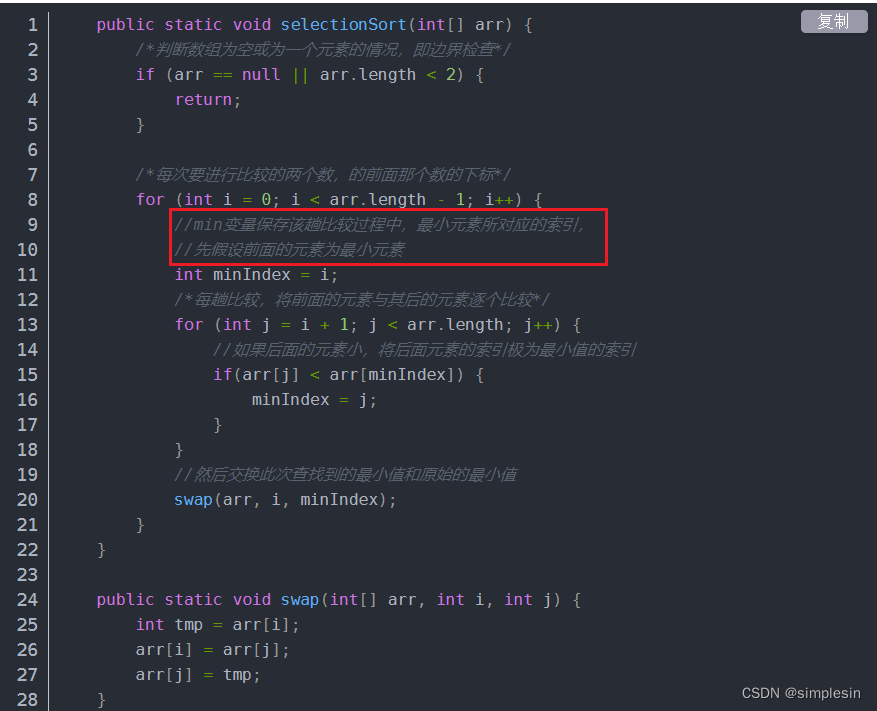
大一C语言程序细节复盘2
7-4 学生成绩排序 分数 27 全屏浏览题目 切换布局 作者 张泳 单位 浙大城市学院 假设学生的基本信息包括学号、姓名、三门课程成绩以及个人平均成绩,定义一个能够表示学生信息的结构类型。输入n(n<50)个学生的成绩信息,按照学生…...

【QT】跨平台区分32位和64位的宏
目录 0.背景 1.详细 0.背景 项目用到,原用的是 “WIN32”和“WIN64”,但是发现在64位下的时候,进了表示32位的代码,上网查找,原来是宏写错了,特此记录,适用windows和linux 1.详细 修改前: #…...

对抗AUTOMIXUP
文章目录 摘要1、简介2、相关工作3、ADAUTOMIX3.1、深度学习分类器3.2、生成器3.3 对抗增强3.3.1 对抗损失 3.4 对抗优化 4、实验4.1、分类结果4.1.1、数据集分类4.1.2、精细分类 4.2、校准4.3、鲁棒性4.4、遮挡鲁棒性4.5、迁移学习4.6、消融实验 5、结论附录AA.1 数据集信息A.…...

AMEYA360:什么是热敏电阻 热敏电阻基础知识详解
热敏电阻(thermistor)是对温度敏感的一种电子器件,其电阻值会随着温度的变化而发生改变。 热敏电阻按照温度系数不同分为正温度系数热敏电阻(PTC thermistor,即 Positive Temperature Coefficient thermistor)和负温度系数热敏电阻(NTC thermistor&#…...

RedisTemplate自增时保证原子性的lua脚本限制接口请求频率
场景:限制请求后端接口的频率,例如1秒钟只能请求次数不能超过10次,通常的写法是: 1.先去从redis里面拿到当前请求次数 2.判断当前次数是否大于或等于限制次数 3.当前请求次数小于限制次数时进行自增 这三步在请求不是很密集的时…...

《通信基站绿色低碳服务评价技术要求》团体标准顺利通过技术审查
2023年12月14日团体标准《通信基站绿色低碳服务评价技术要求》召开了技术审查视频会议。来自节能权威机构、科研院校、通信行业企业的专家以及标准编制组代表参加了本次会议。 技术审查专家组由郑州大学能动学院教授赵金辉、国家节能中心节能技术推广处处长辛升、中国标准化研…...
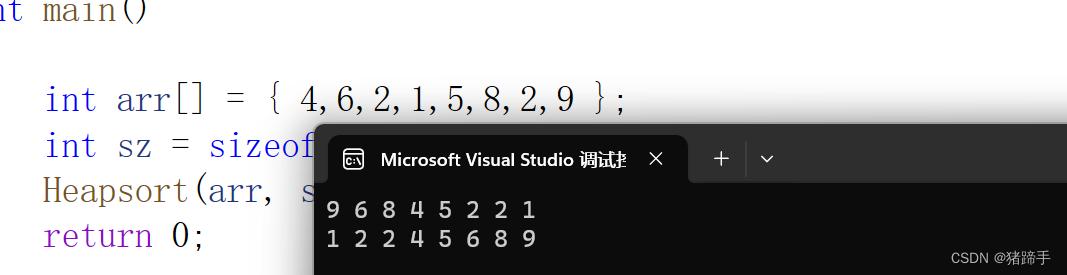
堆排序(C语言版)
一.堆排序 堆排序即利用堆的思想来进行排序,总共分为两个步骤: 1. 建堆 升序:建大堆 降序:建小堆 2. 利用堆删除思想来进行排序 1.1.利用上下调整法实现堆排序 第一步:建堆 好了,每次建堆都要问自己…...
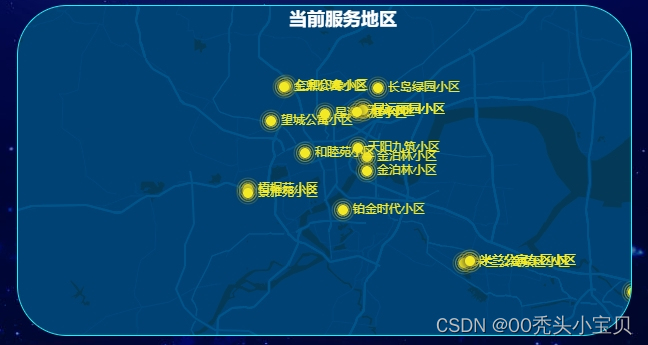
实现区域地图散点图效果,vue+echart地图+散点图
需求:根据后端返回的定位坐标数据实现定位渲染 1.效果图 2.准备工作,在main.js和index.js文件中添加以下内容 main.js app.use(BaiduMap, {// ak 是在百度地图开发者平台申请的密钥 详见 http://lbsyun.baidu.com/apiconsole/key */ak: sRDDfAKpCSG5iF1rvwph4Q95M…...
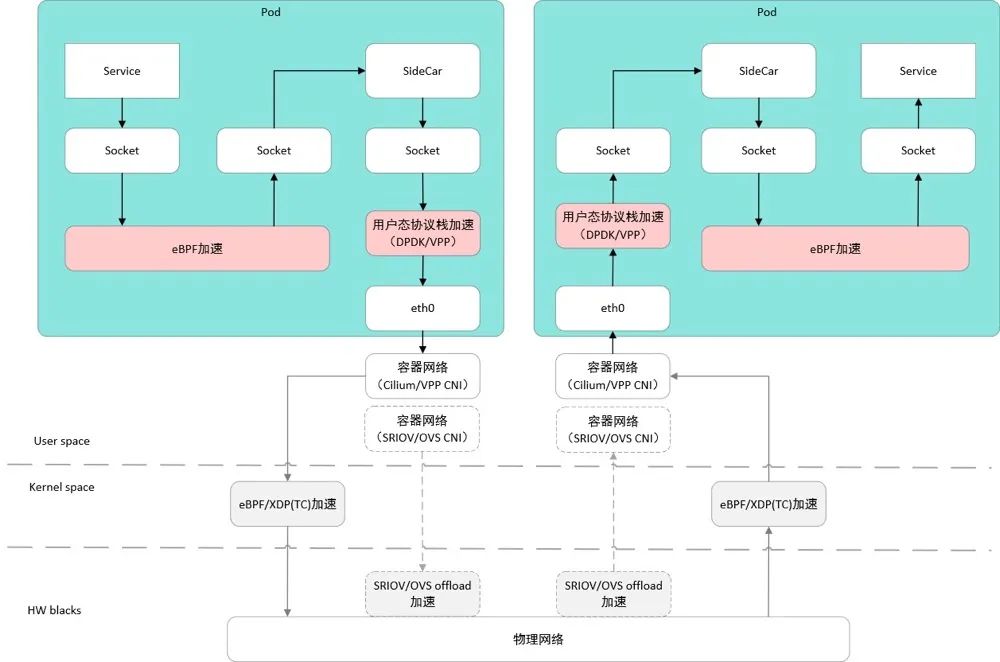
Kubernetes 学习总结(41)—— 云原生容器网络详解
背景 随着网络技术的发展,网络的虚拟化程度越来越高,特别是云原生网络,叠加了物理网络、虚机网络和容器网络,数据包在网络 OSI 七层网络模型、TCP/IP 五层网络模型的不同网络层进行封包、转发和解包。网络数据包跨主机网络、容器…...
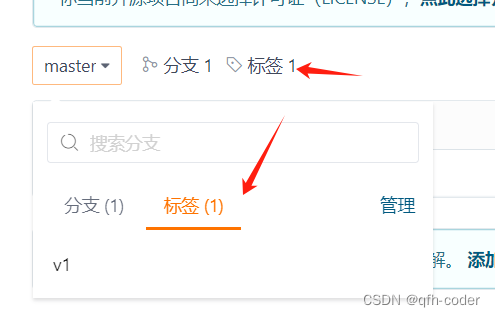
多人协同开发git flow,创建初始化项目版本
文章目录 多人协同开发git flow,创建初始化项目版本1.gitee创建组织模拟多人协同开发2.git tag 打标签3.git push origin --tags 多人协同开发git flow,创建初始化项目版本 1.gitee创建组织模拟多人协同开发 组织中新建仓库 推送代码到我们组织的仓库 2…...

「Kafka」入门篇
「Kafka」入门篇 基础架构 Kafka 快速入门 集群规划 集群部署 官方下载地址:http://kafka.apache.org/downloads.html 解压安装包: [atguiguhadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/修改解压后的文件名称: [a…...
编译器是什么?)
PHP8的JIT(Just-In-Time)编译器是什么?
PHP8的JIT(Just-In-Time)编译器是什么? PHP8是最新的PHP版本,引入了JIT(Just-In-Time)编译器,以进一步提高性能和执行速度。 JIT编译器是一种在运行时将解释性语言转化为机器码的技术。在过去…...

【C++对于C语言的扩充】C++与C语言的联系,命名空间、C++中的输入输出以及缺省参数
文章目录 🚀前言🚀C有何过C之处?🚀C中的关键字🚀命名空间✈️为什么要引入命名空间?✈️命名空间的定义✈️如何使用命名空间中的内容呢? 🚀C中的输入和输出✈️C标准库的命名空间✈…...
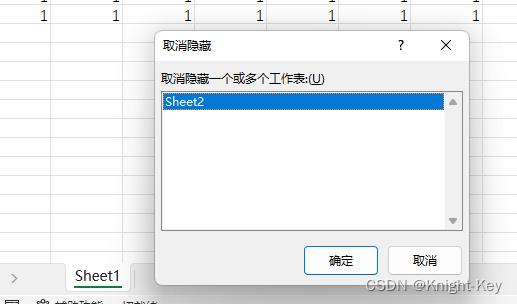
Excel中部分sheet页隐藏并设置访问密码
1、新建sheet1 2、新建sheet2 3、隐藏sheet2 4、保护工作簿、输密码 5、密码二次确认 6、隐藏的sheet2已经查看不了 7、想要查看时,按图示输入原密码即可 8、查看sheet2内容...
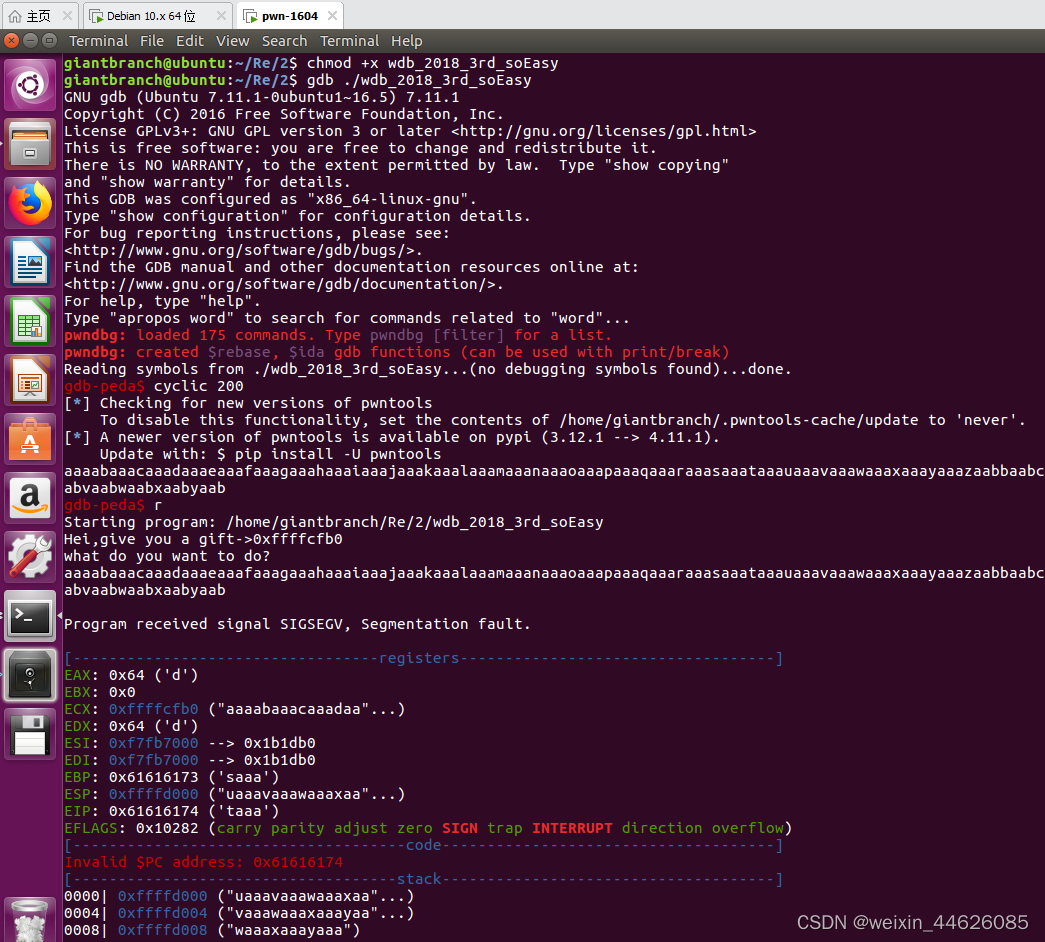
从零开始配置pwn环境:CTF PWN 做题环境
前期在kali2023环境安装的pwndocker使用发现不好用,so找了网上配置好pwn环境的虚拟机。 GitHub - giantbranch/pwn-env-init: CTF PWN 做题环境一键搭建脚本 可以直接下载我配置好的Ubuntu 16.04,为VMware导出的ovf格式 链接:百度网盘 请输…...

Vue3复习笔记
目录 挂载全局属性和方法 v-bind一次绑定多个值 v-bind用在样式中 Vue指令绑定值 Vue指令绑定属性 动态属性的约束 Dom更新时机 ”可写的“计算属性 v-if与v-for不建议同时使用 v-for遍历对象 数组变化检测 事件修饰符 v-model用在表单类标签上 v-model还可以绑定…...

【安卓开发实战指南】Google Play服务集成与常见问题排查
1. Google Play服务集成基础 作为安卓开发者,你可能经常遇到需要集成Google Play服务的情况。无论是地图定位、身份验证还是应用内支付,这些功能都离不开Google Play服务的支持。但说实话,第一次集成时我也踩了不少坑,今天就和大家…...
)
校园网福音:用UU加速器+PC热点搞定Switch联机(附详细广播原理分析)
校园网环境下Switch联机加速的终极方案:PC热点与广播机制深度解析 每次在宿舍想和室友来一局《Splatoon 3》时,最怕看到的就是那个令人绝望的"NAT类型:D"。校园网环境下没有路由器,Switch联机成了老大难问题。但你可能没…...

拒绝从入门到放弃:自学C语言前的“必修课”——一些重要基础概念的解析
C语言基础教程:变量和数据类型 大家好!我本身作为C语言的初学者,深知学习过程中对一些问题和概念的理解只停留在知其然而不知其所以然的状态,因而在系统性的查找文献和询问业内从业者后写出了这篇推文。这是我将新学的知识内化的…...

OSS Index API深度使用指南:如何用coordinates批量扫描项目依赖漏洞?
OSS Index API深度使用指南:如何用coordinates批量扫描项目依赖漏洞? 在当今快速迭代的软件开发环境中,依赖管理已成为安全防护的第一道防线。一个中型Java项目平均包含150-300个直接依赖,而每个直接依赖又会引入5-10个传递依赖&a…...

Alpamayo-R1-10B环境部署:32GB内存+30GB存储+CUDA驱动全检查清单
Alpamayo-R1-10B环境部署:32GB内存30GB存储CUDA驱动全检查清单 1. 项目概述 Alpamayo-R1-10B是NVIDIA推出的自动驾驶专用开源视觉-语言-动作(VLA)模型,核心为100亿参数规模。该模型结合AlpaSim模拟器与Physical AI AV数据集,构成完整的自动…...

RMBG-2.0从部署到应用:电商运营人员也能用的零代码抠图工作流
RMBG-2.0从部署到应用:电商运营人员也能用的零代码抠图工作流 电商运营每天都要处理大量商品图片,抠图是最耗时的工作之一。传统方法要么花钱找设计师,要么自己用PS一点点抠,费时费力效果还不好。现在有了RMBG-2.0,这一…...

VIVADO 2023.1闪退后Launcher Time Out?360误杀恢复全记录
VIVADO 2023.1闪退与Launcher Time Out问题深度解析与实战修复指南 当VIVADO 2023.1突然闪退并出现Launcher Time Out错误时,许多开发者会陷入反复重启却无法解决问题的困境。这种情况在国内尤为常见,特别是当安全软件误判VIVADO关键组件为威胁时。本文将…...

DeepSpeed多机多卡训练避坑指南:从环境变量配置到hostfile实战
DeepSpeed多机多卡训练实战:从零搭建到性能调优全解析 当你从单机多卡切换到多机多卡训练时,就像从单人驾驶升级为车队协同作战——每个环节的配合都至关重要。我曾在一个跨三地数据中心的项目中,因为一个环境变量配置错误导致整个集群训练停…...
)
应用统计期末考试复习总结-(江农版)
本文习题来自江农学习通考试后台原题型 完整版习题和标准答案 请在评论区留言 添加图片注释,不超过 140 字(可选) 编辑添加图片注释,不超过 140 字(可选)添加图片注释,不超过 140 字&…...

嵌入式网络丢包故障的分层诊断与工程实践
1. 网络通信数据丢包故障分析:嵌入式系统工程师视角的工程化诊断方法在网络设备开发与现场部署过程中,数据丢包是嵌入式系统工程师最常遭遇、却也最容易被表象误导的底层通信故障。当一个基于ESP32或STM32的物联网终端在接入企业局域网后出现MQTT连接频繁…...