Spark Shuffle解析
1 Shuffle的核心要点
1.1 ShuffleMapStage与ResultStage
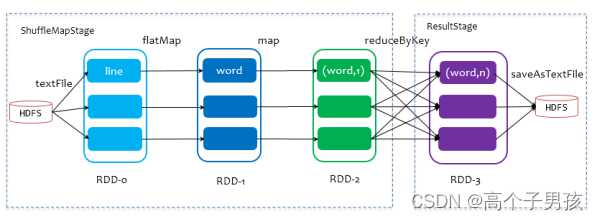
ShuffleMapStage与ResultStage
在划分stage时,最后一个stage称为finalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
ShuffleMapStage的结束伴随着shuffle文件的写磁盘。
ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
1.2 Shuffle中的任务个数
我们知道,Spark Shuffle分为map阶段和reduce阶段,或者称之为ShuffleRead阶段和ShuffleWrite阶段,那么对于一次Shuffle,map过程和reduce过程都会由若干个task来执行,那么map task和reduce task的数量是如何确定的呢?
假设Spark任务从HDFS中读取数据,那么初始RDD分区个数由该文件的split个数决定,也就是一个split对应生成的RDD的一个partition,我们假设初始partition个数为N。
初始RDD经过一系列算子计算后(假设没有执行repartition和coalesce算子进行重分区,则分区个数不变,仍为N,如果经过重分区算子,那么分区个数变为M),我们假设分区个数不变,当执行到Shuffle操作时,map端的task个数和partition个数一致,即map task为N个。
reduce端的stage默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置,则以map端的最后一个RDD的分区数作为其分区数(也就是N),那么分区数就决定了reduce端的task的个数。
1.3 reduce端数据的读取
根据stage的划分我们知道,map端task和reduce端task不在相同的stage中,map task位于ShuffleMapStage,reduce task位于ResultStage,map task会先执行,那么后执行的reduce task如何知道从哪里去拉取map task落盘后的数据呢?
reduce端的数据拉取过程如下:
- map task 执行完毕后会将计算状态以及磁盘小文件位置等信息封装到MapStatus对象中,然后由本进程中的MapOutPutTrackerWorker对象将mapStatus对象发送给Driver进程的MapOutPutTrackerMaster对象;
- 在reduce task开始执行之前会先让本进程中的MapOutputTrackerWorker向Driver进程中的MapoutPutTrakcerMaster发动请求,请求磁盘小文件位置信息;
- 当所有的Map task执行完毕后,Driver进程中的MapOutPutTrackerMaster就掌握了所有的磁盘小文件的位置信息。此时MapOutPutTrackerMaster会告诉MapOutPutTrackerWorker磁盘小文件的位置信息;
- 完成之前的操作之后,由BlockTransforService去Executor0所在的节点拉数据,默认会启动五个子线程。每次拉取的数据量不能超过48M(reduce task每次最多拉取48M数据,将拉来的数据存储到Executor内存的20%内存中)。
2 HashShuffle解析
以下的讨论都假设每个Executor有1个CPU core。
1. 未经优化的HashShuffleManager
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“划分”。所谓“划分”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个task,总共有10个Executor,每个Executor执行5个task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read阶段,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,map task给下游stage的每个reduce task都创建了一个磁盘文件,因此shuffle read的过程中,每个reduce task只要从上游stage的所有map task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
未优化的HashShuffleManager工作原理如图1-7所示:
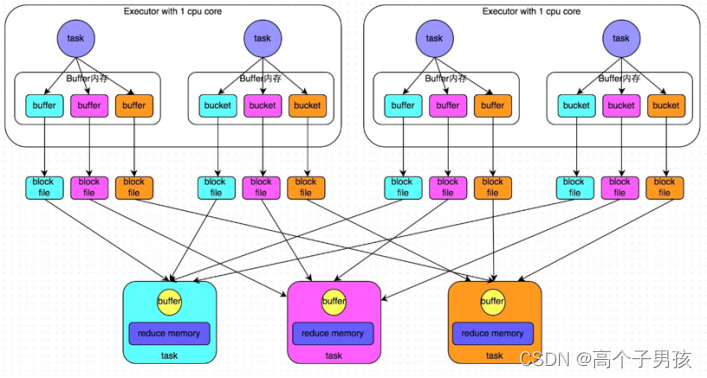
图1-7 未优化的HashShuffleManager工作原理
2. 优化后的HashShuffleManager
为了优化HashShuffleManager我们可以设置一个参数,spark.shuffle. consolidateFiles,该参数默认值为false,将其设置为true即可开启优化机制,通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了,此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件,也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor(Executor CPU个数为1),每个Executor执行5个task。那么原本使用未经优化的HashShuffleManager时,每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core的数量 * 下一个stage的task数量,也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
优化后的HashShuffleManager工作原理如图1-8所示:
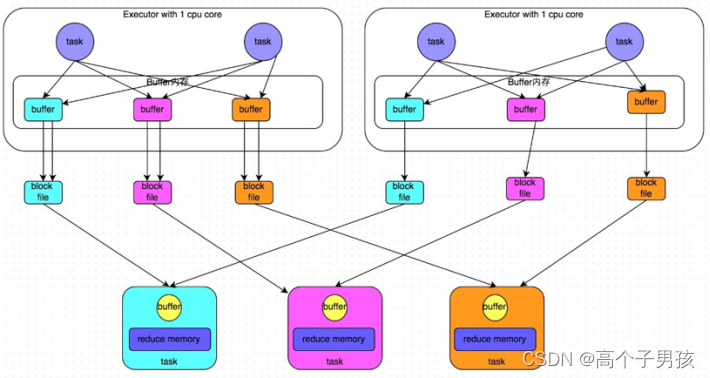
图1-8 优化后的HashShuffleManager工作原理
3 SortShuffle解析
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort. bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
- 普通运行机制
在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
普通运行机制的SortShuffleManager工作原理如图1-9所示:
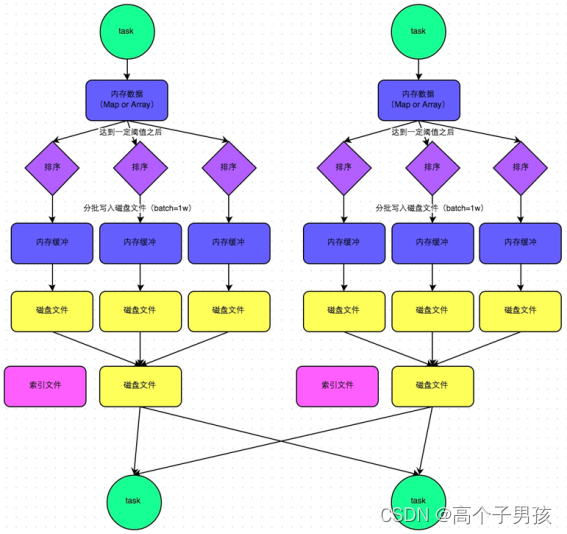
图1-9 普通运行机制的SortShuffleManager工作原理
- bypass运行机制
bypass运行机制的触发条件如下:
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
- 不是聚合类的shuffle算子。
此时,每个task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
bypass运行机制的SortShuffleManager工作原理如图1-10所示:
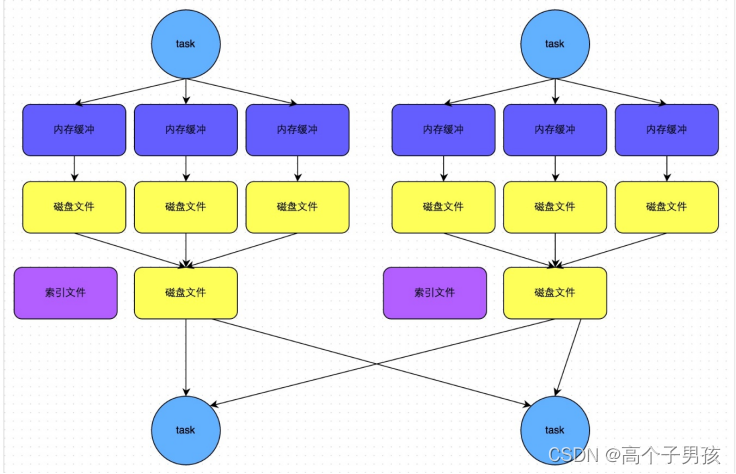
图1-10 bypass运行机制的SortShuffleManager工作原理
相关文章:
Spark Shuffle解析
1 Shuffle的核心要点 1.1 ShuffleMapStage与ResultStage ShuffleMapStage与ResultStage 在划分stage时,最后一个stage称为finalStage,它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。 ShuffleMapStage的结束伴随着…...

Qt 解决程序全屏运行弹窗引发任务栏显示
文章目录摘要在VM虚拟机器中测试setWindowFlags()关键字: Qt、 Qt::WindowStayOnTopHint、 setWindowFlags、 Qt::Window、 Qt::Tool摘要 今天眼看项目就要交付了,结果在测试程序的时候,发现在程序全品情况下,点击输入框&#x…...
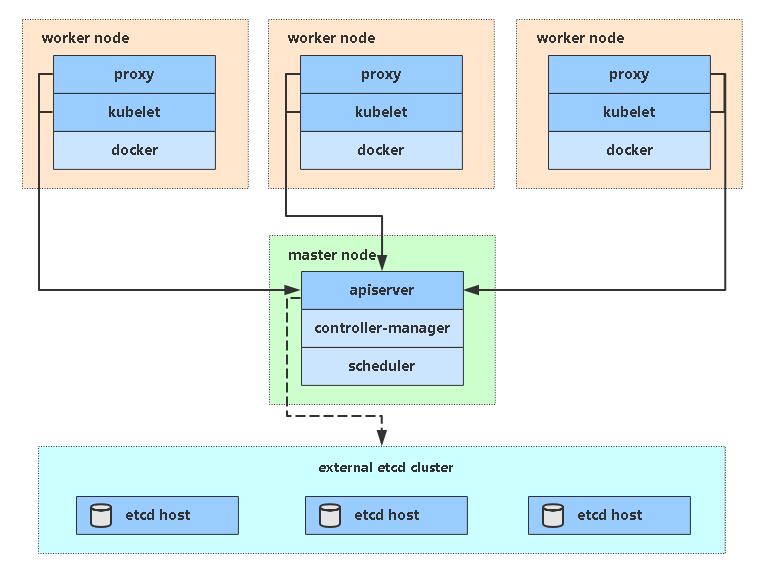
【进阶】2、搭建K8s集群【v1.23】
[toc] 一、安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多集群中所有机器之间网络…...
:一切皆服务,服务基于协议)
11面向接口编程(下):一切皆服务,服务基于协议
服务容器的实现 一个服务容器主要的功能是:为服务提供注册绑定、提供获取服务实例,所以服务容器至少有两个方法:注册方法 Bind、获取实例方法 Make。 对于注册的方法,直接将一个服务提供者注册到容器中,参数是之前定…...
不要以没时间来说测试用例写不好
工作当中,总会有人为自己的测试用例写得不够好去找各种理由,时间不够是我印象当中涉及到最多的,也是最反感。想写好测试用例,前提是测试分析和需求拆解做的足够好,通过xmind或者UML图把需求和开发设计提供的产品信息提炼出来。 我个人的提炼标准一般是&…...

day57-day58【代码随想录】二刷数组
文章目录前言一、螺旋矩阵||(力扣59)二、螺旋矩阵(力扣54)三、顺时针打印矩阵(剑指 Offer29)四、在排序数组中查找元素的第一个和最后一个位置(力扣34)【二分查找】五、有多少小于当…...
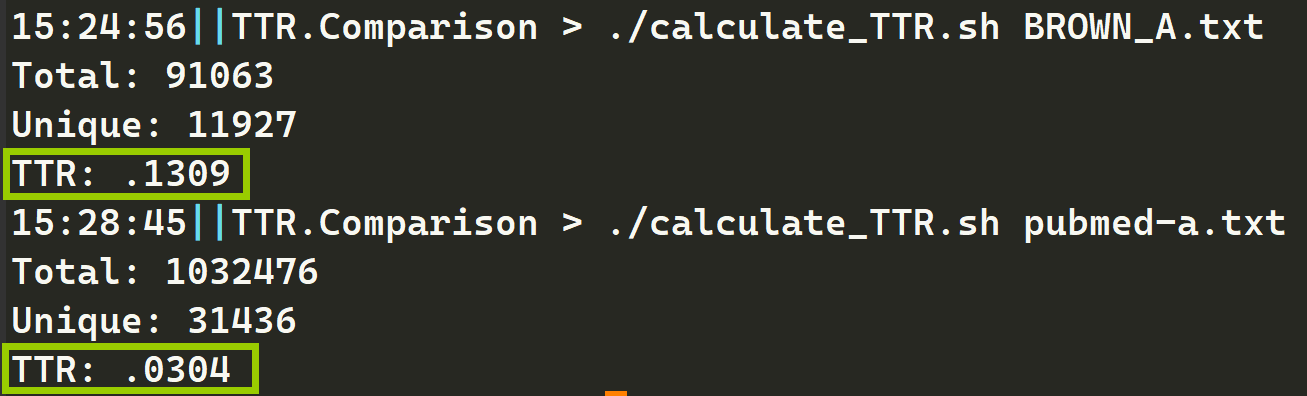
【NLP】自动化计算文本文件TTR的bash脚本
自动化计算文本文件TTR的bash脚本 简介 这是一个可以计算文本文件TTR的bash脚本,文件名为:calculate_TTR.sh。它会接收一个文件名作为参数,并输出总单词数、特异单词数和TTR。 TTR是什么 TTR(Type-Token Ratio)是用…...

蓝桥杯单片机组省赛十二届第一场(关于矩阵,温度ds18b20,时间ds1302的学习,以及继电器等外设的综合利用)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录一、该题目如下二、使用步骤1.矩阵键盘实现2.温度传感器ds18b20的实现总结提示:以下是本篇文章正文内容,下面案例可供参考 一、该题目如下 分…...
Ubuntu 新人上手 Microk8s 指南
文章目录1. 什么是 Ubuntu 核心2. 什么是 Kubernetes3. 什么是MicroK8s4. 为什么选择 Microk8s on Core5. 安装Ubuntu Core6. Ubuntu Core上安装 MicroK8S7. 启动 Microk8s8. 启用必要的 MicroK8s 插件9. 部署示例容器工作负载10. 检查部署状态并访问您的应用程序11. 管理镜像1…...

初阶C语言——实用调试技巧【详解】
文章目录1. 什么是bug?2. 调试是什么?有多重要?2.1 调试是什么?2.2 调试的基本步骤2.3 Debug和Release的介绍3.学会使用快捷键4.调试的时候查看程序当前信息4.1 查看临时变量的值4.2 查看内存信息4.3 查看调用堆栈4.4 查看汇编信息…...
Android 绘图基础:Canvas画布——自定义View基础(绘制表盘、矩形、圆形、弧、渐变)
Canvas画布,通过它我们可以自定义一个View,设置View的相关效果之类的。感觉用法差不多,重要的是要理解方法中传入的参数的含义,比如float类型的参数,传递的是坐标,已开是没有注意传入的参数时坐标,导致我迷…...

js拷贝数组对象:浅拷贝深拷贝
前言 js拷贝数组对象:浅拷贝&深拷贝,包括:Object.assign、concat、slice、JSON.parse(JSON.stringify()) 场景:弹窗选择组织结构(树形结构),选择后显示相关数据至输入框中(每次选…...
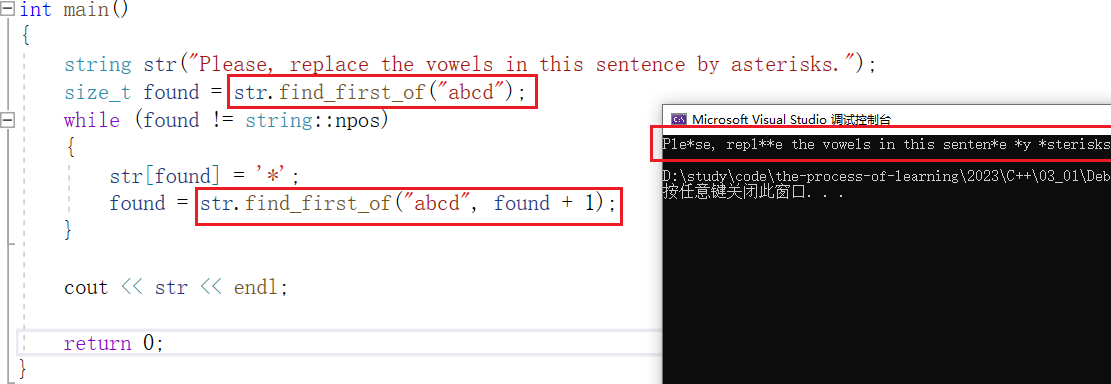
【C++】string类的使用
目录 一、标准库中的string类 二、string类的常用接口 1、string类对象的常见构造 2、string类对象的容量操作 2.1、size 与 length 2.2、capacity 与 reserve 2.3、resize 2.4、总结 3、string类对象的访问及遍历操作 3.1、operator[] 与 at 3.2、begin end 3.3、…...

微服务架构简介
微服务 软件架构是一个包含各种组织的系统组织,这些组件包括 Web服务器, 应用服务器, 数据库,存储, 通讯层), 它们彼此或和环境存在关系。系统架构的目标是解决利益相关者的关注点。 image Conway’s law: Organizations which design systems[...] are constrained…...
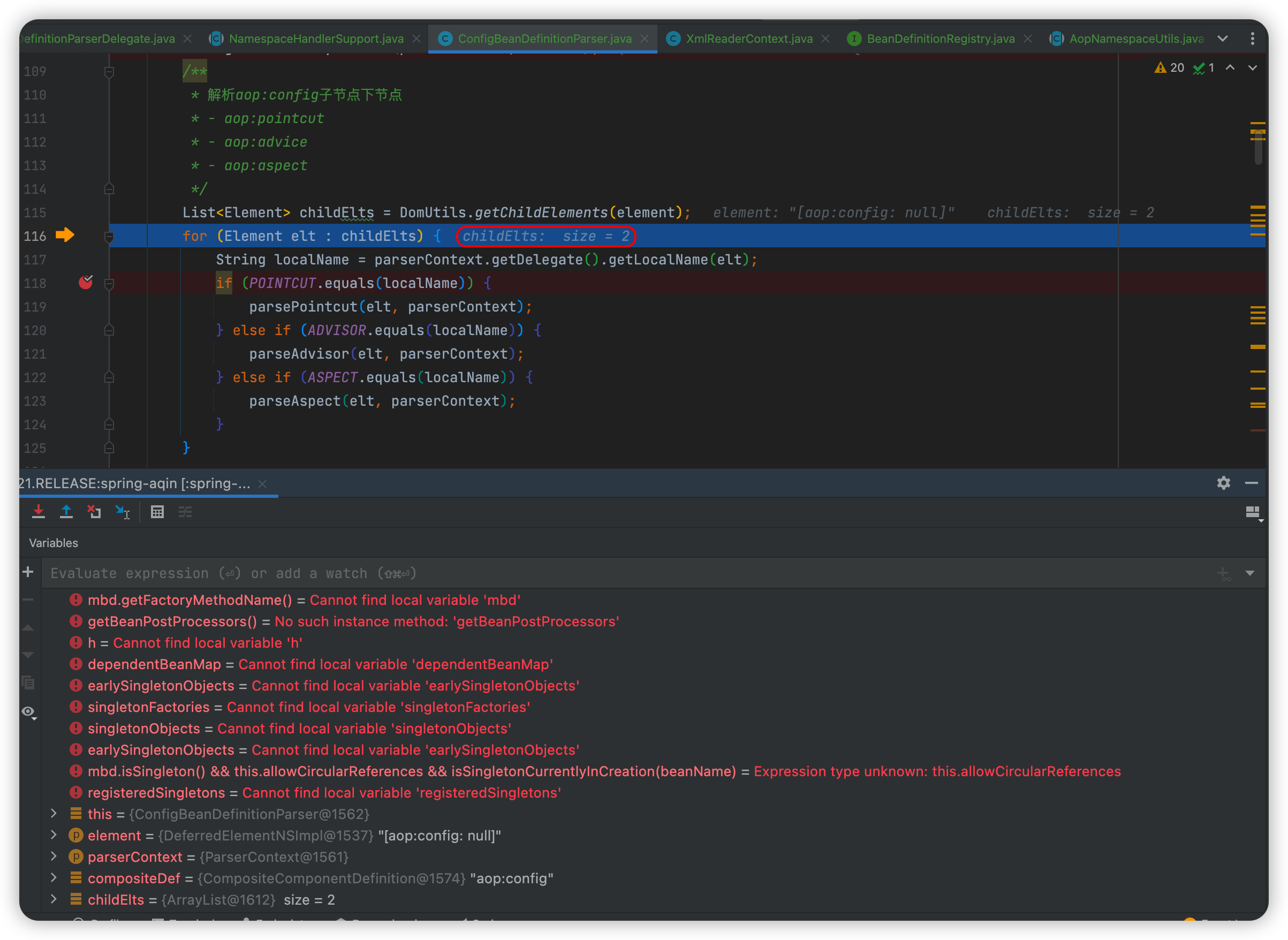
【Spring源码】AOP的开端:核心对象创建的准备工作
AOP的核心成员是如何被被加载的?本篇我们主要分析使用xml的逻辑,如果使用注解,增加注解处理类即可(ConfigurationClassPostProcessor)拿之前分析循环的时候举的例子🌰,它的日志切面就是通过xml进…...
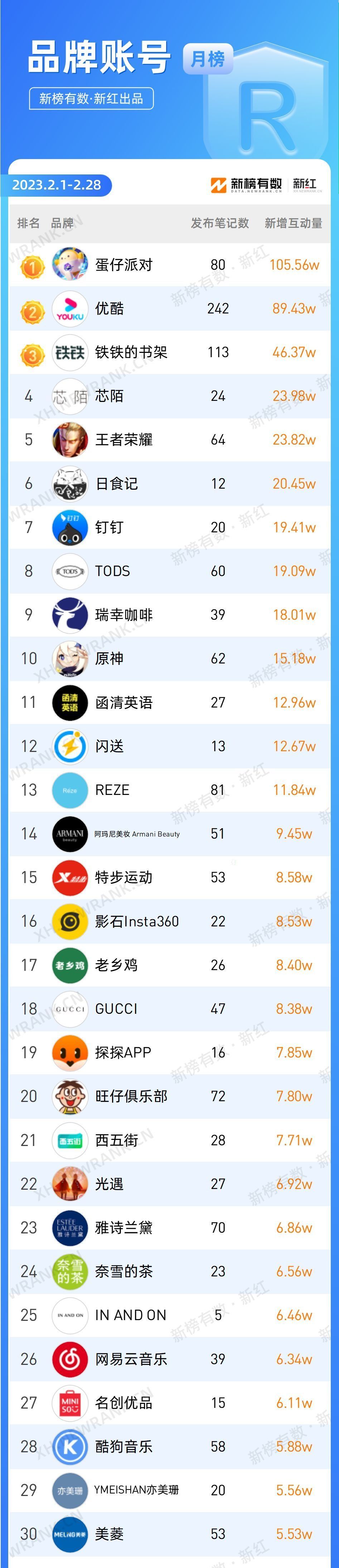
新号涨粉22w,搞笑博主再次爆火,小红书近期创作趋势是什么?
2月借势元宵、情人节,小红书平台又涌现出哪些黑马博主?品牌在投放种草方面有何亮眼表现?为洞察小红书平台的内容创作趋势及品牌营销策略,新红推出2月月度榜单,从创作者及品牌两方面入手,解析月榜数据&#…...

【C++】30h速成C++从入门到精通(内存管理、函数/类模板)
C内存分布我们先来看一下下面的一段代码相关问题int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";char* pChar3 "abcd";int* ptr1 (int*)mal…...
自动驾驶决策概况
文章目录1. 第一章行为决策在自动驾驶系统架构中的位置2. 行为决策算法的种类2.1 基于规则的决策算法2.1.1 决策树2.1.2 有限状态机(FSM)2.1.3 基于本体论(Ontologies-based)2.2 基于统计的决策算法2.2.1 贝叶斯网络(B…...

金山轻维表项目进展自动通知
项目经理作为项目全局把控者,经常要和时间“赛跑”。需要实时了解到目前进展如何,跟进人是那些?哪些事项还未完成?项目整体会不会逾期?特别是在一些大型公司中,优秀的项目经理已经学会使用金山轻维表做项目…...

基于上下文分析的 Python 实时 API 推荐
原文来自微信公众号“编程语言Lab”:基于上下文分析的 Python 实时 API 推荐 搜索关注 “编程语言Lab”公众号(HW-PLLab)获取更多技术内容! 欢迎加入 编程语言社区 SIG-程序分析 参与交流讨论(加入方式:添加…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...