Python访问ElasticSearch
ElasticSearch是广受欢迎的NoSQL数据库,其分布式架构提供了极佳的数据空间的水平扩展能力,同时保障了数据的可靠性;反向索引技术使得数据检索和查询速度非常快。更多功能参见官网介绍
https://www.elastic.co/cn/elasticsearch/
下面简单罗列了通过Python访问ES的方法。
注:本文不是Elasticsearch的入门介绍,需要有ES基本知识。
Python - ElasticSearch 接口
Elastic提供的Python ElasticSearch原生接口,源代码托管在Github上。项目链接和文档链接如下:
https://github.com/elastic/elasticsearch-py
https://www.elastic.co/guide/en/elasticsearch/client/python-api/7.17/examples.html#examples
下面是常见操作示例:
建立ES连接
from elasticsearch import Elasticsearch, helpers
from elasticsearch.exceptions import ConnectionError, ConnectionTimeout, TransportError
...try :#es = Elasticsearch(es_server, retry_on_timeout=True)es = Elasticsearch(es_server, http_auth=(es_user, es_pass), timeout=30, max_retries=10, retry_on_timeout=True) print("Connection failed, exit ...")sys.exit(1)创建ES数据
doc = {'author': 'author_name','text': 'Interesting content...','timestamp': datetime.now(),
}
res = es.index(index="test-index", id=1, body=doc)获取ES数据
res = es.get(index="test-index", id=1)通过查询获取ES数据
query={"match_all":{}}try :result = es.search(index=index, query=query, size=10000)except([ConnectionError, ConnectionTimeout, TransportError]):print("Connection failed, exit ...")sys.exit(1)data=[]for item in result['hits']['hits'] :data.push(item['_source'])
更新ES数据
doc = {'author': 'author_name','text': 'Interesting modified content...','timestamp': datetime.now(),
}
res = es.update(index="test-index", id=1, body=doc)删除ES数据
es.delete(index="test-index", id=1)ElasticSearch-DSL python接口
原生ES python接口在查询时需要编写复杂的DSL查询语句,Elastic提供的ElasticSearch-DSL库极大地简化了查询语法,方便编写查询语句。相关项目和文档的URL:
https://github.com/elastic/elasticsearch-dsl-py
https://elasticsearch-dsl.readthedocs.io/en/latest/
示例代码如下:
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Searchclient = Elasticsearch()s = Search(using=client, index="my-index") \.filter("term", category="search") \.query("match", title="python") \.exclude("match", description="beta")s.aggs.bucket('per_tag', 'terms', field='tags') \.metric('max_lines', 'max', field='lines')response = s.execute()for hit in response:print(hit.meta.score, hit.title)for tag in response.aggregations.per_tag.buckets:print(tag.key, tag.max_lines.value)ElasticSearch - Pandas 接口
Pandas是流行的大数据处理Python库,Elastic提供了Pandas DataFrame的接口 ,可以直接将索引(数据表)中的数据放到 pandas 的 dataframe 中,非常方便。相关项目和文档URL如下:
https://github.com/elastic/eland
https://eland.readthedocs.io/en/latest/reference/dataframe.html
注意:返回的并不是原生Pandas DataFrame,而是Elastic自己的实现,但并没有实现所有DataFrame的功能。
示例代码如下:
import eland as ed# Connecting to an Elasticsearch instance running on 'localhost:9200'
df = ed.DataFrame("localhost:9200", es_index_pattern="flights")
也可以先建立 ES 连接
# Connecting to an Elastic Cloud instance
from elasticsearch import Elasticsearches = Elasticsearch("localhost:9200",http_auth=("elastic", "<password>")
)
df = ed.DataFrame(es, es_index_pattern="flights")
第三方 ElasticSearch - Pandas 接口
eland虽然可以方便将 Elastic 中的数据转换为 dataframe,但没有提供将 dataframe 保存到 Elastic的接口。这时我们需要使用第三方的接口。es_pandas是开源的 ES Pandas接口,可以直接将ES查询得到的数据以Pandas DataFrame的方式返回,也可将 dataframe 保存到 Elastic 中。
https://github.com/fuyb1992/es_pandas
初始化与ES的连接
import pandas as pd
from es_pandas import es_pandas...
epcon = None
try :epcon = es_pandas(esurl)
except Exception as e:logger.error("Initializa DB connection failed! Error[{}]".format(str(e)))从ES表中获取数据,返回格式为Pandas DataFrame
# 从ES表中获取数据返回DataFrame
try: if query is None:data = epcon.to_pandas(dbname, infer_dtype=True, show_progress=False)else:data = epcon.to_pandas(dbname, infer_dtype=True, show_progress=False, query_rule=query)
except exceptions.NotFoundError:logger.debug("Not found data. Params: dbname[{}] query[{}]".format(dbname, query))将Pandas DataFrame中的数据写入ES表中
# 将DataFrame中的数据写入ES表中
ret = True
try:epcon.to_es(df, dbname, use_index=True, _op_type='create', thread_count=2, chunk_size=10000, show_progress=False)
except ConnectionError:ret = Falselogger.error("Save data failed! Params: dbname[{}] data[{}],, connection error!".format(dbname, df))将Pandas DataFrame中的数据更新到ES表中
# 将DataFrame中的更新到ES表中
ret = True
try:epcon.to_es(df, dbname, use_index=True, _op_type='update', thread_count=2, chunk_size=10000, show_progress=False)
except ConnectionError:ret = Falselogger.error("Update data failed! Params: dbname[{}] data[{}],, connection error!".format(dbname, df))将Pandas DataFrame中的数据从ES表中删除
# 将DataFrame中的数据从ES表中删除
ret = True
try:epcon.to_es(df, dbname, use_index=True, _op_type='delete', thread_count=2, chunk_size=10000, show_progress=False)
except ConnectionError:ret = Falselogger.error("Delete data failed! Params: dbname[{}] data[{}],, connection error!".format(dbname, df))相关文章:

Python访问ElasticSearch
ElasticSearch是广受欢迎的NoSQL数据库,其分布式架构提供了极佳的数据空间的水平扩展能力,同时保障了数据的可靠性;反向索引技术使得数据检索和查询速度非常快。更多功能参见官网介绍 https://www.elastic.co/cn/elasticsearch/ 下面简单罗列…...

Flutter 混合开发 - 动态下发 libflutter.so libapp.so
背景 最近在做包体积优化,在完成代码混淆、压缩,裁剪ndk支持架构,以及资源压缩(如图片转webp、mp3压缩等)后发现安装包的中占比较大的仍是 so 动态库依赖。 具体查看发现 libflutter.so 和 libapp.so 的体积是最大的&…...

Peter算法小课堂—动态规划
Peter推荐算法书:《算法导论》 图示: 目录 钢条切割 打字怪人 钢条切割 算法导论(第四版)第十四章第一节:钢条切割 题目描述: 给定一根长度为 n 英寸的钢条和一个价格表 ,其中 i1,2,…,n …...

2022–2023学年2021级计算机科学与技术专业数据库原理 (A)卷
一、单项选择题(每小题1.5分,共30分) 1、构成E—R模型的三个基本要素是( B )。 A.实体、属性值、关系 B.实体、属性、联系 C.实体、实体集、联系 D.实体、实体…...

Clojure 实战(4):编写 Hadoop MapReduce 脚本
Hadoop简介 众所周知,我们已经进入了大数据时代,每天都有PB级的数据需要处理、分析,从中提取出有用的信息。Hadoop就是这一时代背景下的产物。它是Apache基金会下的开源项目,受Google两篇论文的启发,采用分布式的文件…...
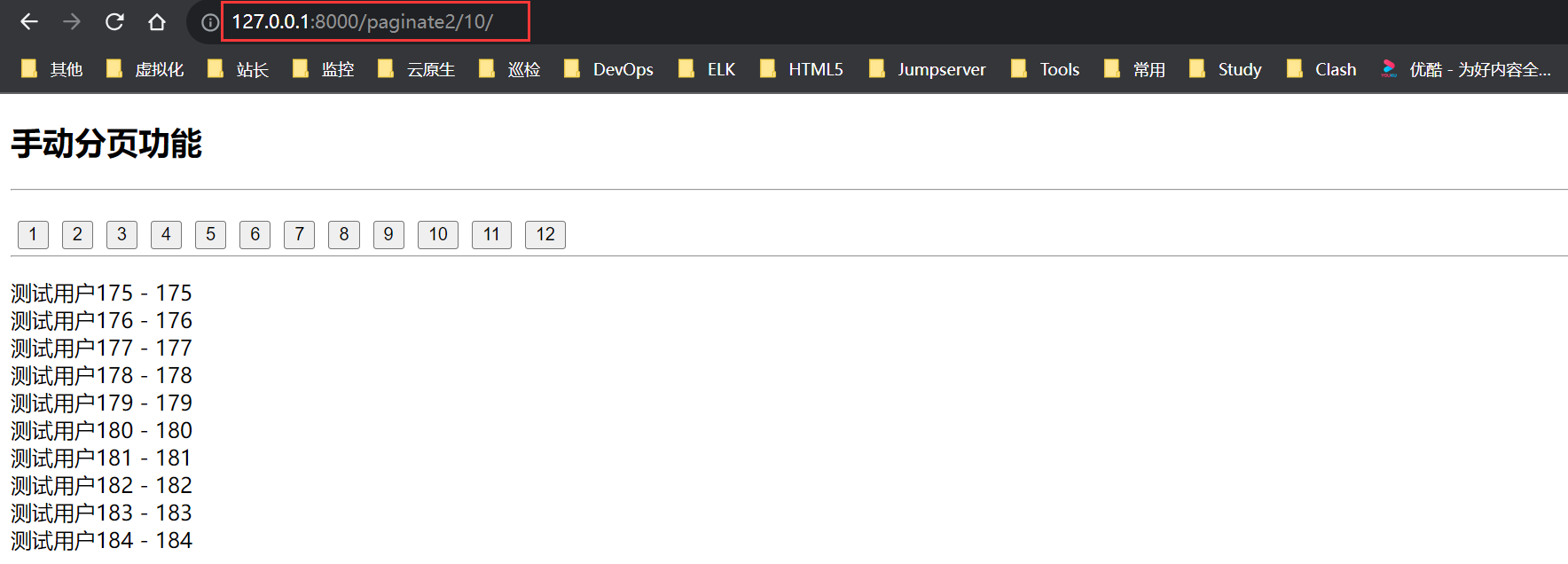
Django 分页(表单)
目录 一、手动分页二、分页器分页 一、手动分页 1、概念 页码:很容易理解,就是一本书的页码每页数量:就是一本书中某一页中的内容(数据量,比如第二页有15行内容),这 15 就是该页的数据量 每一…...
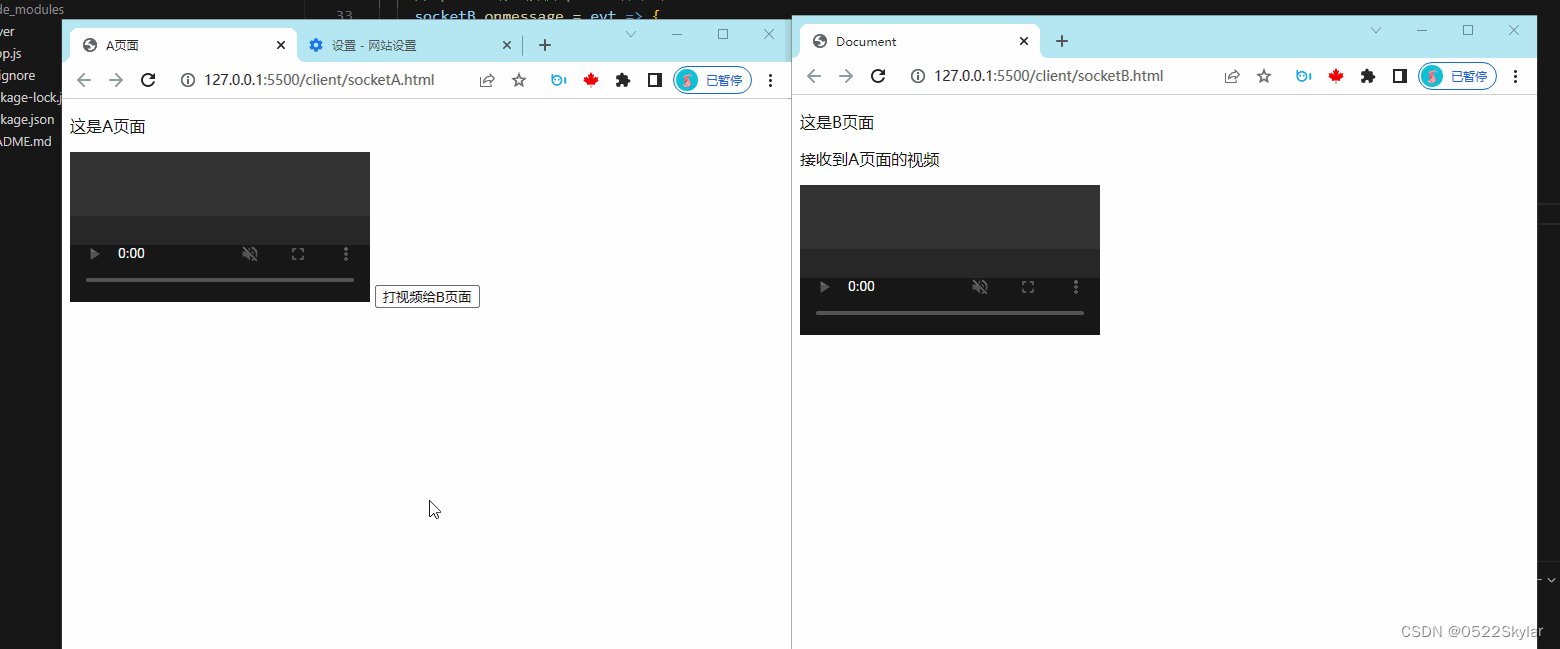
socket实现视频通话-WebRTC
最近喜欢研究视频流,所以思考了双向通信socket,接下来我们就一起来看看本地如何实现双向视频通讯的功能吧~ 客户端获取视频流 首先思考如何获取视频流呢? 其实跟录音的功能差不多,都是查询电脑上是否有媒体设备,如果…...
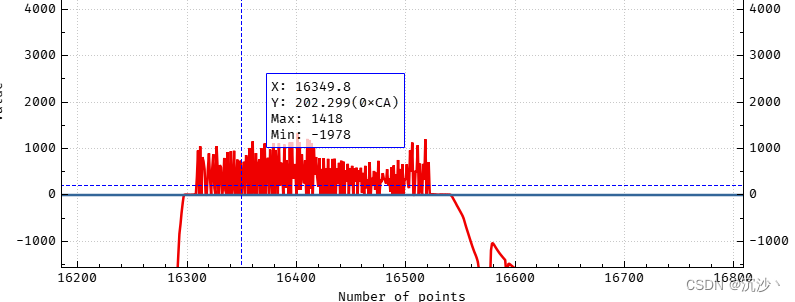
simulink代码生成(九)—— 串口显示数据(纸飞机联合调试)
纸飞机里面的协议是固定的,必须按照协议配置; (1)使用EasyHEX协议,测试int16数据类型 测试串口发出的数据是否符合? 串口接收数据为: 打开纸飞机绘图侧: (1)…...
——增删改查的学习(全面,详细))
Mysql数据库(中)——增删改查的学习(全面,详细)
上一篇主要对查询操作进行了详细的总结,本篇主要对增删改操作以及一些常用的函数进行总结,包括流程控制等;以下的代码可以直接复制到数据库可视化软件中,便于理解和练习; 常用的操作: #函数: S…...

test dbtest-03-对比 Liquibase、flyway、dbDeploy、dbsetup
详细对比 Liquibase、flyway、dbDeploy、dbsetup,给出对比表格 下面是一个简要的对比表格,涵盖了 Liquibase、Flyway、dbDeploy 和 DbSetup 这四个数据库变更管理工具的一些主要特点。 特点/工具LiquibaseFlywaydbDeployDbSetup开发语言Java࿰…...

力导向图与矩阵排序
Graph-layout force directed(力导向图布局)是一种用于可视化网络图的布局算法。它基于物理模型,模拟了图中节点之间的相互排斥和连接弹性,以生成具有良好可读性和美观性的图形布局。 在力导向图布局中,每个节点被视为…...

word 常用功能记录
word手册 多行文字对齐标题调整文字间距打钩方框插入三线表插入参考文献自动生成目录 多行文字对齐 标题调整文字间距 打钩方框 插入三线表 插入一个最基本的表格把整个表格设置为无框线设置上框线【实线1.5磅】设置下框线【实线1.5磅】选中第一行,设置下框线【实线…...

C#线程基础(线程启动和停止)
目录 一、关于线程 二、示例 三、生成效果 一、关于线程 在使用多线程前要先引用命名空间System.Threading,引用命名空间后就可以在需要的地方方便地创建并使用线程。 创建线程对象的构造方法中使用了ThreadStart()委托,当线程开始执行时,…...

如何利用ChatGPT来提高编程效率
如何利用ChatGPT来提高编程效率 在当今这个信息爆炸和技术快速发展的时代,程序员们面临着巨大的压力,既要保证代码的质量,又要提高工作效率。幸运的是,人工智能(AI)正在改变我们编写和维护代码的方式,而OpenAI的ChatGPT是其中的佼佼者。本文将讨论如何利用ChatGPT以及结合…...

java智慧工地源码,互联网+建筑工地,实现对工程项目内人员、车辆、安全、设备、材料等的智能化管理
智慧工地全套源码,微服务JavaSpring Cloud UniApp MySql;支持多端展示(大屏端、PC端、手机端、平板端)演示自主版权。 智慧工地概念: 智慧工地就是互联网建筑工地,是将互联网的理念和技术引入建筑工地&…...
)
创建并使用自己的C++模块(Windows10+MSVC)
module是C20种新引入的特性,关于module的介绍和好处,网上已有大量的文章,此处也不再赘述,本文仅记录在个人的环境上创建一个简单的module并使用这个module。 环境同上一篇文章( windows10,MSVC C工具链&am…...
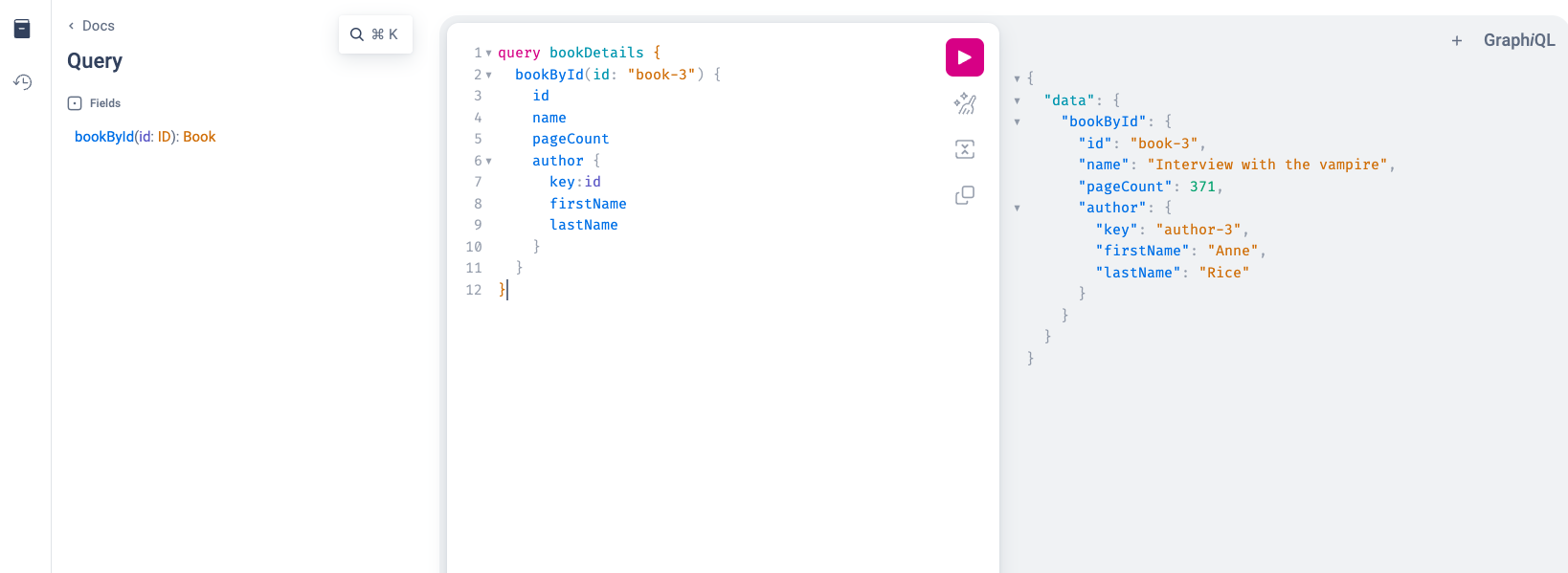
Spring Boot 2.7.11 集成 GraphQL
GraphQL介绍 GraphQL(Graph Query Language)是一种用于API的查询语言和运行时环境,由Facebook于2012年创建并在2015年公开发布。与传统的RESTful API相比,GraphQL提供了更灵活、高效和强大的数据查询和操作方式。 以下是GraphQL…...
软件工程期末总结
软件工程期末总结 软件危机出现的原因软件生命周期软件生命周期的概念生命周期的各个阶段 软件开发模型极限编程 可行性研究与项目开发计划需求分析结构化分析的方法结构化分析的图形工具软件设计的原则用户界面设计结构化软件设计面向对象面向对象建模 软件危机出现的原因 忽视…...

MidTool图文创作-GPT-4与DALL·E 3的结合
GPT-4与DALLE 3的结合 GPT-4是由OpenAI开发的最新一代语言预测模型,它在前代模型的基础上进行了大幅度的改进,不仅在文本生成的连贯性、准确性上有了显著提升,还在理解复杂语境和执行多步骤指令方面表现出了更高的能力。而DALLE 3则是一个创…...

Python将两个或多个列表合并为一个列表,并根据每个输入列表中的元素的位置将其组合在一起
将两个或多个列表合并为一个列表,并根据每个输入列表中的元素的位置将其组合在一起。 这个需求在实际开发过程中应该说非常常见,当然python也给我们内置了相关方法! zip(*iterables, strictFalse) 在多个迭代器上并行迭代,从每…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...