【Elasticsearch源码】 分片恢复分析
带着疑问学源码,第七篇:Elasticsearch 分片恢复分析
代码分析基于:https://github.com/jiankunking/elasticsearch
Elasticsearch 8.0.0-SNAPSHOT
目的
在看源码之前先梳理一下,自己对于分片恢复的疑问点:
- 网上对于ElasticSearch分片恢复的逻辑说法一抓一把,网上说的对不对?新版本中有没有更新?
- 在分片恢复的时候,如果收到Api _forcemerge请求,这时候,会如何处理?(因为副本恢复的第一节点是复制segment文件)
- 这部分等看/_forcemerge api的时候,再解答一下。
- 分片恢复的第二阶段是同步translog,这一步会不会加锁?不加锁的话,如何确保是同步完成了?
如果说看源码有捷径的话,那么找到网上一篇写的比较权威的源码分析文章跟着看,那不失为一种好方法。
下面源码分析部分将参考腾讯云的:Elasticsearch 底层系列之分片恢复解析,一边参考,一边印证。
源码分析
目标节点请求恢复
先找到分片恢复的入口:IndicesClusterStateService.createOrUpdateShards
在这里会判断本地节点是否在routingNodes中,如果在,说明本地节点有分片创建或更新的需求,否则跳过。
private void createOrUpdateShards(final ClusterState state) {// 节点到索引分片的映射关系,主要用于分片分配、均衡决策// 具体的内容可以看下:https://jiankunking.com/elasticsearch-cluster-state.htmlRoutingNode localRoutingNode = state.getRoutingNodes().node(state.nodes().getLocalNodeId());if (localRoutingNode == null) {return;}DiscoveryNodes nodes = state.nodes();RoutingTable routingTable = state.routingTable();for (final ShardRouting shardRouting : localRoutingNode) {ShardId shardId = shardRouting.shardId();// failedShardsCache:https://github.com/jiankunking/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/indices/cluster/IndicesClusterStateService.java#L116// 恢复过程中失败的碎片列表;我们跟踪这些碎片,以防止在每次集群状态更新时重复恢复这些碎片if (failedShardsCache.containsKey(shardId) == false) {AllocatedIndex<? extends Shard> indexService = indicesService.indexService(shardId.getIndex());assert indexService != null : "index " + shardId.getIndex() + " should have been created by createIndices";Shard shard = indexService.getShardOrNull(shardId.id());if (shard == null) { // shard不存在则需创建assert shardRouting.initializing() : shardRouting + " should have been removed by failMissingShards";createShard(nodes, routingTable, shardRouting, state);} else { // 存在则更新updateShard(nodes, shardRouting, shard, routingTable, state);}}}}
副本分片恢复走的是createShard分支,在该方法中,首先获取shardRouting的类型,如果恢复类型为PEER,说明该分片需要从远端获取,则需要找到源节点,然后调用IndicesService.createShard:
RecoverySource的Type有以下几种:
EMPTY_STORE,
EXISTING_STORE,//主分片本地恢复
PEER,//副分片从远处主分片恢复
SNAPSHOT,//从快照恢复
LOCAL_SHARDS//从本节点其它分片恢复(shrink时)
createShard代码如下:
private void createShard(DiscoveryNodes nodes, RoutingTable routingTable, ShardRouting shardRouting, ClusterState state) {assert shardRouting.initializing() : "only allow shard creation for initializing shard but was " + shardRouting;DiscoveryNode sourceNode = null;// 如果恢复方式是peer,则会找到shard所在的源节点进行恢复if (shardRouting.recoverySource().getType() == Type.PEER) {sourceNode = findSourceNodeForPeerRecovery(logger, routingTable, nodes, shardRouting);if (sourceNode == null) {logger.trace("ignoring initializing shard {} - no source node can be found.", shardRouting.shardId());return;}}try {final long primaryTerm = state.metadata().index(shardRouting.index()).primaryTerm(shardRouting.id());logger.debug("{} creating shard with primary term [{}]", shardRouting.shardId(), primaryTerm);indicesService.createShard(shardRouting,recoveryTargetService,new RecoveryListener(shardRouting, primaryTerm),repositoriesService,failedShardHandler,this::updateGlobalCheckpointForShard,retentionLeaseSyncer,nodes.getLocalNode(),sourceNode);} catch (Exception e) {failAndRemoveShard(shardRouting, true, "failed to create shard", e, state);}}/*** Finds the routing source node for peer recovery, return null if its not found. Note, this method expects the shard* routing to *require* peer recovery, use {@link ShardRouting#recoverySource()} to check if its needed or not.*/private static DiscoveryNode findSourceNodeForPeerRecovery(Logger logger, RoutingTable routingTable, DiscoveryNodes nodes,ShardRouting shardRouting) {DiscoveryNode sourceNode = null;if (!shardRouting.primary()) {ShardRouting primary = routingTable.shardRoutingTable(shardRouting.shardId()).primaryShard();// only recover from started primary, if we can't find one, we will do it next roundif (primary.active()) {// 找到primary shard所在节点sourceNode = nodes.get(primary.currentNodeId());if (sourceNode == null) {logger.trace("can't find replica source node because primary shard {} is assigned to an unknown node.", primary);}} else {logger.trace("can't find replica source node because primary shard {} is not active.", primary);}} else if (shardRouting.relocatingNodeId() != null) {// 找到搬迁的源节点sourceNode = nodes.get(shardRouting.relocatingNodeId());if (sourceNode == null) {logger.trace("can't find relocation source node for shard {} because it is assigned to an unknown node [{}].",shardRouting.shardId(), shardRouting.relocatingNodeId());}} else {throw new IllegalStateException("trying to find source node for peer recovery when routing state means no peer recovery: " +shardRouting);}return sourceNode;}
源节点的确定分两种情况,如果当前shard本身不是primary shard,则源节点为primary shard所在节点,否则,如果当前shard正在搬迁中(从其他节点搬迁到本节点),则源节点为数据搬迁的源头节点。得到源节点后调用IndicesService.createShard,在该方法中调用方法IndexShard.startRecovery开始恢复。
public void startRecovery(RecoveryState recoveryState, PeerRecoveryTargetService recoveryTargetService,PeerRecoveryTargetService.RecoveryListener recoveryListener, RepositoriesService repositoriesService,Consumer<MappingMetadata> mappingUpdateConsumer,IndicesService indicesService) {// TODO: Create a proper object to encapsulate the recovery context// all of the current methods here follow a pattern of:// resolve context which isn't really dependent on the local shards and then async// call some external method with this pointer.// with a proper recovery context object we can simply change this to:// startRecovery(RecoveryState recoveryState, ShardRecoverySource source ) {// markAsRecovery("from " + source.getShortDescription(), recoveryState);// threadPool.generic().execute() {// onFailure () { listener.failure() };// doRun() {// if (source.recover(this)) {// recoveryListener.onRecoveryDone(recoveryState);// }// }// }}// }assert recoveryState.getRecoverySource().equals(shardRouting.recoverySource());switch (recoveryState.getRecoverySource().getType()) {case EMPTY_STORE:case EXISTING_STORE:executeRecovery("from store", recoveryState, recoveryListener, this::recoverFromStore);break;case PEER:try {markAsRecovering("from " + recoveryState.getSourceNode(), recoveryState);recoveryTargetService.startRecovery(this, recoveryState.getSourceNode(), recoveryListener);} catch (Exception e) {failShard("corrupted preexisting index", e);recoveryListener.onRecoveryFailure(recoveryState,new RecoveryFailedException(recoveryState, null, e), true);}break;case SNAPSHOT:final String repo = ((SnapshotRecoverySource) recoveryState.getRecoverySource()).snapshot().getRepository();executeRecovery("from snapshot",recoveryState, recoveryListener, l -> restoreFromRepository(repositoriesService.repository(repo), l));break;case LOCAL_SHARDS:final IndexMetadata indexMetadata = indexSettings().getIndexMetadata();final Index resizeSourceIndex = indexMetadata.getResizeSourceIndex();final List<IndexShard> startedShards = new ArrayList<>();final IndexService sourceIndexService = indicesService.indexService(resizeSourceIndex);final Set<ShardId> requiredShards;final int numShards;if (sourceIndexService != null) {requiredShards = IndexMetadata.selectRecoverFromShards(shardId().id(),sourceIndexService.getMetadata(), indexMetadata.getNumberOfShards());for (IndexShard shard : sourceIndexService) {if (shard.state() == IndexShardState.STARTED && requiredShards.contains(shard.shardId())) {startedShards.add(shard);}}numShards = requiredShards.size();} else {numShards = -1;requiredShards = Collections.emptySet();}if (numShards == startedShards.size()) {assert requiredShards.isEmpty() == false;executeRecovery("from local shards", recoveryState, recoveryListener,l -> recoverFromLocalShards(mappingUpdateConsumer,startedShards.stream().filter((s) -> requiredShards.contains(s.shardId())).collect(Collectors.toList()), l));} else {final RuntimeException e;if (numShards == -1) {e = new IndexNotFoundException(resizeSourceIndex);} else {e = new IllegalStateException("not all required shards of index " + resizeSourceIndex+ " are started yet, expected " + numShards + " found " + startedShards.size() + " can't recover shard "+ shardId());}throw e;}break;default:throw new IllegalArgumentException("Unknown recovery source " + recoveryState.getRecoverySource());}}
对于恢复类型为PEER的任务,恢复动作的真正执行者为PeerRecoveryTargetService.doRecovery。在该方法中,首先调用getStartRecoveryRequest获取shard的metadataSnapshot,该结构中包含shard的段信息,如syncid、checksum、doc数等,然后封装为StartRecoveryRequest,通过RPC发送到源节点:
private void doRecovery(final long recoveryId, final StartRecoveryRequest preExistingRequest) {final String actionName;final TransportRequest requestToSend;final StartRecoveryRequest startRequest;final RecoveryState.Timer timer;try (RecoveryRef recoveryRef = onGoingRecoveries.getRecovery(recoveryId)) {if (recoveryRef == null) {logger.trace("not running recovery with id [{}] - can not find it (probably finished)", recoveryId);return;}final RecoveryTarget recoveryTarget = recoveryRef.target();timer = recoveryTarget.state().getTimer();if (preExistingRequest == null) {try {final IndexShard indexShard = recoveryTarget.indexShard();indexShard.preRecovery();assert recoveryTarget.sourceNode() != null : "can not do a recovery without a source node";logger.trace("{} preparing shard for peer recovery", recoveryTarget.shardId());indexShard.prepareForIndexRecovery();final long startingSeqNo = indexShard.recoverLocallyUpToGlobalCheckpoint();assert startingSeqNo == UNASSIGNED_SEQ_NO || recoveryTarget.state().getStage() == RecoveryState.Stage.TRANSLOG :"unexpected recovery stage [" + recoveryTarget.state().getStage() + "] starting seqno [ " + startingSeqNo + "]";// 构造recovery request startRequest = getStartRecoveryRequest(logger, clusterService.localNode(), recoveryTarget, startingSeqNo);requestToSend = startRequest;actionName = PeerRecoverySourceService.Actions.START_RECOVERY;} catch (final Exception e) {// this will be logged as warning later on...logger.trace("unexpected error while preparing shard for peer recovery, failing recovery", e);onGoingRecoveries.failRecovery(recoveryId,new RecoveryFailedException(recoveryTarget.state(), "failed to prepare shard for recovery", e), true);return;}logger.trace("{} starting recovery from {}", startRequest.shardId(), startRequest.sourceNode());} else {startRequest = preExistingRequest;requestToSend = new ReestablishRecoveryRequest(recoveryId, startRequest.shardId(), startRequest.targetAllocationId());actionName = PeerRecoverySourceService.Actions.REESTABLISH_RECOVERY;logger.trace("{} reestablishing recovery from {}", startRequest.shardId(), startRequest.sourceNode());}}// 向源节点发送请求,请求恢复transportService.sendRequest(startRequest.sourceNode(), actionName, requestToSend,new RecoveryResponseHandler(startRequest, timer));}/*** Prepare the start recovery request.** @param logger the logger* @param localNode the local node of the recovery target* @param recoveryTarget the target of the recovery* @param startingSeqNo a sequence number that an operation-based peer recovery can start with.* This is the first operation after the local checkpoint of the safe commit if exists.* @return a start recovery request*/public static StartRecoveryRequest getStartRecoveryRequest(Logger logger, DiscoveryNode localNode,RecoveryTarget recoveryTarget, long startingSeqNo) {final StartRecoveryRequest request;logger.trace("{} collecting local files for [{}]", recoveryTarget.shardId(), recoveryTarget.sourceNode());Store.MetadataSnapshot metadataSnapshot;try {metadataSnapshot = recoveryTarget.indexShard().snapshotStoreMetadata();// Make sure that the current translog is consistent with the Lucene index; otherwise, we have to throw away the Lucene index.try {final String expectedTranslogUUID = metadataSnapshot.getCommitUserData().get(Translog.TRANSLOG_UUID_KEY);final long globalCheckpoint = Translog.readGlobalCheckpoint(recoveryTarget.translogLocation(), expectedTranslogUUID);assert globalCheckpoint + 1 >= startingSeqNo : "invalid startingSeqNo " + startingSeqNo + " >= " + globalCheckpoint;} catch (IOException | TranslogCorruptedException e) {logger.warn(new ParameterizedMessage("error while reading global checkpoint from translog, " +"resetting the starting sequence number from {} to unassigned and recovering as if there are none", startingSeqNo), e);metadataSnapshot = Store.MetadataSnapshot.EMPTY;startingSeqNo = UNASSIGNED_SEQ_NO;}} catch (final org.apache.lucene.index.IndexNotFoundException e) {// happens on an empty folder. no need to logassert startingSeqNo == UNASSIGNED_SEQ_NO : startingSeqNo;logger.trace("{} shard folder empty, recovering all files", recoveryTarget);metadataSnapshot = Store.MetadataSnapshot.EMPTY;} catch (final IOException e) {if (startingSeqNo != UNASSIGNED_SEQ_NO) {logger.warn(new ParameterizedMessage("error while listing local files, resetting the starting sequence number from {} " +"to unassigned and recovering as if there are none", startingSeqNo), e);startingSeqNo = UNASSIGNED_SEQ_NO;} else {logger.warn("error while listing local files, recovering as if there are none", e);}metadataSnapshot = Store.MetadataSnapshot.EMPTY;}logger.trace("{} local file count [{}]", recoveryTarget.shardId(), metadataSnapshot.size());request = new StartRecoveryRequest(recoveryTarget.shardId(),recoveryTarget.indexShard().routingEntry().allocationId().getId(),recoveryTarget.sourceNode(),localNode,metadataSnapshot,recoveryTarget.state().getPrimary(),recoveryTarget.recoveryId(),startingSeqNo);return request;}
注意,请求的发送是异步的。
源节点处理恢复请求
源节点接收到请求后会调用恢复的入口函数PeerRecoverySourceService.messageReceived#recover:
class StartRecoveryTransportRequestHandler implements TransportRequestHandler<StartRecoveryRequest> {@Overridepublic void messageReceived(final StartRecoveryRequest request, final TransportChannel channel, Task task) throws Exception {recover(request, new ChannelActionListener<>(channel, Actions.START_RECOVERY, request));}}
recover方法根据request得到shard并构造RecoverySourceHandler对象,然后调用handler.recoverToTarget进入恢复的执行体:
private void recover(StartRecoveryRequest request, ActionListener<RecoveryResponse> listener) {final IndexService indexService = indicesService.indexServiceSafe(request.shardId().getIndex());final IndexShard shard = indexService.getShard(request.shardId().id());final ShardRouting routingEntry = shard.routingEntry();if (routingEntry.primary() == false || routingEntry.active() == false) {throw new DelayRecoveryException("source shard [" + routingEntry + "] is not an active primary");}if (request.isPrimaryRelocation() && (routingEntry.relocating() == false ||routingEntry.relocatingNodeId().equals(request.targetNode().getId()) == false)) {logger.debug("delaying recovery of {} as source shard is not marked yet as relocating to {}",request.shardId(), request.targetNode());throw new DelayRecoveryException("source shard is not marked yet as relocating to [" + request.targetNode() + "]");}RecoverySourceHandler handler = ongoingRecoveries.addNewRecovery(request, shard);logger.trace("[{}][{}] starting recovery to {}", request.shardId().getIndex().getName(), request.shardId().id(),request.targetNode());handler.recoverToTarget(ActionListener.runAfter(listener, () -> ongoingRecoveries.remove(shard, handler)));}/*** performs the recovery from the local engine to the target*/public void recoverToTarget(ActionListener<RecoveryResponse> listener) {addListener(listener);final Closeable releaseResources = () -> IOUtils.close(resources);try {cancellableThreads.setOnCancel((reason, beforeCancelEx) -> {final RuntimeException e;if (shard.state() == IndexShardState.CLOSED) { // check if the shard got closed on use = new IndexShardClosedException(shard.shardId(), "shard is closed and recovery was canceled reason [" + reason + "]");} else {e = new CancellableThreads.ExecutionCancelledException("recovery was canceled reason [" + reason + "]");}if (beforeCancelEx != null) {e.addSuppressed(beforeCancelEx);}IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e));throw e;});final Consumer<Exception> onFailure = e -> {assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[onFailure]");IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e));};final SetOnce<RetentionLease> retentionLeaseRef = new SetOnce<>();runUnderPrimaryPermit(() -> {final IndexShardRoutingTable routingTable = shard.getReplicationGroup().getRoutingTable();ShardRouting targetShardRouting = routingTable.getByAllocationId(request.targetAllocationId());if (targetShardRouting == null) {logger.debug("delaying recovery of {} as it is not listed as assigned to target node {}", request.shardId(),request.targetNode());throw new DelayRecoveryException("source node does not have the shard listed in its state as allocated on the node");}assert targetShardRouting.initializing() : "expected recovery target to be initializing but was " + targetShardRouting;retentionLeaseRef.set(shard.getRetentionLeases().get(ReplicationTracker.getPeerRecoveryRetentionLeaseId(targetShardRouting)));}, shardId + " validating recovery target ["+ request.targetAllocationId() + "] registered ",shard, cancellableThreads, logger);// 获取一个保留锁,使得translog不被清理final Closeable retentionLock = shard.acquireHistoryRetentionLock();resources.add(retentionLock);final long startingSeqNo;// 判断是否可以从SequenceNumber恢复// 除了异常检测和版本号检测,主要在shard.hasCompleteHistoryOperations()方法中判断请求的序列号是否小于主分片节点的localCheckpoint,// 以及translog中的数据是否足以恢复(有可能因为translog数据太大或者过期删除而无法恢复)final boolean isSequenceNumberBasedRecovery= request.startingSeqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO&& isTargetSameHistory()&& shard.hasCompleteHistoryOperations("peer-recovery", request.startingSeqNo())&& ((retentionLeaseRef.get() == null && shard.useRetentionLeasesInPeerRecovery() == false) ||(retentionLeaseRef.get() != null && retentionLeaseRef.get().retainingSequenceNumber() <= request.startingSeqNo()));// NB check hasCompleteHistoryOperations when computing isSequenceNumberBasedRecovery, even if there is a retention lease,// because when doing a rolling upgrade from earlier than 7.4 we may create some leases that are initially unsatisfied. It's// possible there are other cases where we cannot satisfy all leases, because that's not a property we currently expect to hold.// Also it's pretty cheap when soft deletes are enabled, and it'd be a disaster if we tried a sequence-number-based recovery// without having a complete history.if (isSequenceNumberBasedRecovery && retentionLeaseRef.get() != null) {// all the history we need is retained by an existing retention lease, so we do not need a separate retention lockretentionLock.close();logger.trace("history is retained by {}", retentionLeaseRef.get());} else {// all the history we need is retained by the retention lock, obtained before calling shard.hasCompleteHistoryOperations()// and before acquiring the safe commit we'll be using, so we can be certain that all operations after the safe commit's// local checkpoint will be retained for the duration of this recovery.logger.trace("history is retained by retention lock");}final StepListener<SendFileResult> sendFileStep = new StepListener<>();final StepListener<TimeValue> prepareEngineStep = new StepListener<>();final StepListener<SendSnapshotResult> sendSnapshotStep = new StepListener<>();final StepListener<Void> finalizeStep = new StepListener<>();// 若可以基于序列号进行恢复,则获取开始的序列号if (isSequenceNumberBasedRecovery) {// 如果基于SequenceNumber恢复,则startingSeqNo取值为恢复请求中的序列号,// 从请求的序列号开始快照translog。否则取值为0,快照完整的translog。logger.trace("performing sequence numbers based recovery. starting at [{}]", request.startingSeqNo());// 获取开始序列号startingSeqNo = request.startingSeqNo();if (retentionLeaseRef.get() == null) {createRetentionLease(startingSeqNo, sendFileStep.map(ignored -> SendFileResult.EMPTY));} else {// 发送的文件设置为空sendFileStep.onResponse(SendFileResult.EMPTY);}} else {final Engine.IndexCommitRef safeCommitRef;try {// Releasing a safe commit can access some commit files.safeCommitRef = acquireSafeCommit(shard);resources.add(safeCommitRef);} catch (final Exception e) {throw new RecoveryEngineException(shard.shardId(), 1, "snapshot failed", e);}// Try and copy enough operations to the recovering peer so that if it is promoted to primary then it has a chance of being// able to recover other replicas using operations-based recoveries. If we are not using retention leases then we// conservatively copy all available operations. If we are using retention leases then "enough operations" is just the// operations from the local checkpoint of the safe commit onwards, because when using soft deletes the safe commit retains// at least as much history as anything else. The safe commit will often contain all the history retained by the current set// of retention leases, but this is not guaranteed: an earlier peer recovery from a different primary might have created a// retention lease for some history that this primary already discarded, since we discard history when the global checkpoint// advances and not when creating a new safe commit. In any case this is a best-effort thing since future recoveries can// always fall back to file-based ones, and only really presents a problem if this primary fails before things have settled// down.startingSeqNo = Long.parseLong(safeCommitRef.getIndexCommit().getUserData().get(SequenceNumbers.LOCAL_CHECKPOINT_KEY)) + 1L;logger.trace("performing file-based recovery followed by history replay starting at [{}]", startingSeqNo);try {final int estimateNumOps = estimateNumberOfHistoryOperations(startingSeqNo);final Releasable releaseStore = acquireStore(shard.store());resources.add(releaseStore);sendFileStep.whenComplete(r -> IOUtils.close(safeCommitRef, releaseStore), e -> {try {IOUtils.close(safeCommitRef, releaseStore);} catch (final IOException ex) {logger.warn("releasing snapshot caused exception", ex);}});final StepListener<ReplicationResponse> deleteRetentionLeaseStep = new StepListener<>();runUnderPrimaryPermit(() -> {try {// If the target previously had a copy of this shard then a file-based recovery might move its global// checkpoint backwards. We must therefore remove any existing retention lease so that we can create a// new one later on in the recovery.shard.removePeerRecoveryRetentionLease(request.targetNode().getId(),new ThreadedActionListener<>(logger, shard.getThreadPool(), ThreadPool.Names.GENERIC,deleteRetentionLeaseStep, false));} catch (RetentionLeaseNotFoundException e) {logger.debug("no peer-recovery retention lease for " + request.targetAllocationId());deleteRetentionLeaseStep.onResponse(null);}}, shardId + " removing retention lease for [" + request.targetAllocationId() + "]",shard, cancellableThreads, logger);// 第一阶段deleteRetentionLeaseStep.whenComplete(ignored -> {assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[phase1]");phase1(safeCommitRef.getIndexCommit(), startingSeqNo, () -> estimateNumOps, sendFileStep);}, onFailure);} catch (final Exception e) {throw new RecoveryEngineException(shard.shardId(), 1, "sendFileStep failed", e);}}assert startingSeqNo >= 0 : "startingSeqNo must be non negative. got: " + startingSeqNo;sendFileStep.whenComplete(r -> {assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[prepareTargetForTranslog]");// 等待phase1执行完毕,主分片节点通知副分片节点启动此分片的Engine:prepareTargetForTranslog // 该方法会阻塞处理,直到分片 Engine 启动完毕。// 待副分片启动Engine 完毕,就可以正常接收写请求了。// 注意,此时phase2尚未开始,此分片的恢复流程尚未结束。// 等待当前操作处理完成后,以startingSeqNo为起始点,对translog做快照,开始执行phase2:// For a sequence based recovery, the target can keep its local translogprepareTargetForTranslog(estimateNumberOfHistoryOperations(startingSeqNo), prepareEngineStep);}, onFailure);prepareEngineStep.whenComplete(prepareEngineTime -> {assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[phase2]");/** add shard to replication group (shard will receive replication requests from this point on) now that engine is open.* This means that any document indexed into the primary after this will be replicated to this replica as well* make sure to do this before sampling the max sequence number in the next step, to ensure that we send* all documents up to maxSeqNo in phase2.*/runUnderPrimaryPermit(() -> shard.initiateTracking(request.targetAllocationId()),shardId + " initiating tracking of " + request.targetAllocationId(), shard, cancellableThreads, logger);final long endingSeqNo = shard.seqNoStats().getMaxSeqNo();logger.trace("snapshot for recovery; current size is [{}]", estimateNumberOfHistoryOperations(startingSeqNo));final Translog.Snapshot phase2Snapshot = shard.newChangesSnapshot("peer-recovery", startingSeqNo, Long.MAX_VALUE, false);resources.add(phase2Snapshot);retentionLock.close();// we have to capture the max_seen_auto_id_timestamp and the max_seq_no_of_updates to make sure that these values// are at least as high as the corresponding values on the primary when any of these operations were executed on it.final long maxSeenAutoIdTimestamp = shard.getMaxSeenAutoIdTimestamp();final long maxSeqNoOfUpdatesOrDeletes = shard.getMaxSeqNoOfUpdatesOrDeletes();final RetentionLeases retentionLeases = shard.getRetentionLeases();final long mappingVersionOnPrimary = shard.indexSettings().getIndexMetadata().getMappingVersion();// 第二阶段,发送translogphase2(startingSeqNo, endingSeqNo, phase2Snapshot, maxSeenAutoIdTimestamp, maxSeqNoOfUpdatesOrDeletes,retentionLeases, mappingVersionOnPrimary, sendSnapshotStep);}, onFailure);// Recovery target can trim all operations >= startingSeqNo as we have sent all these operations in the phase 2final long trimAboveSeqNo = startingSeqNo - 1;sendSnapshotStep.whenComplete(r -> finalizeRecovery(r.targetLocalCheckpoint, trimAboveSeqNo, finalizeStep), onFailure);finalizeStep.whenComplete(r -> {final long phase1ThrottlingWaitTime = 0L; // TODO: return the actual throttle timefinal SendSnapshotResult sendSnapshotResult = sendSnapshotStep.result();final SendFileResult sendFileResult = sendFileStep.result();final RecoveryResponse response = new RecoveryResponse(sendFileResult.phase1FileNames, sendFileResult.phase1FileSizes,sendFileResult.phase1ExistingFileNames, sendFileResult.phase1ExistingFileSizes, sendFileResult.totalSize,sendFileResult.existingTotalSize, sendFileResult.took.millis(), phase1ThrottlingWaitTime,prepareEngineStep.result().millis(), sendSnapshotResult.sentOperations, sendSnapshotResult.tookTime.millis());try {future.onResponse(response);} finally {IOUtils.close(resources);}}, onFailure);} catch (Exception e) {IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e));}}/*** Checks if we have a completed history of operations since the given starting seqno (inclusive).* This method should be called after acquiring the retention lock; See {@link #acquireHistoryRetentionLock()}*/public boolean hasCompleteHistoryOperations(String reason, long startingSeqNo) {return getEngine().hasCompleteOperationHistory(reason, startingSeqNo);}从上面的代码可以看出,恢复主要分两个阶段,第一阶段恢复segment文件,第二阶段发送translog。这里有个关键的地方,在恢复前,首先需要获取translogView及segment snapshot,translogView的作用是保证当前时间点到恢复结束时间段的translog不被删除,segment snapshot的作用是保证当前时间点之前的segment文件不被删除。接下来看看两阶段恢复的具体执行逻辑。phase1:
/*** Perform phase1 of the recovery operations. Once this {@link IndexCommit}* snapshot has been performed no commit operations (files being fsync'd)* are effectively allowed on this index until all recovery phases are done* <p>* Phase1 examines the segment files on the target node and copies over the* segments that are missing. Only segments that have the same size and* checksum can be reused*/void phase1(IndexCommit snapshot, long startingSeqNo, IntSupplier translogOps, ActionListener<SendFileResult> listener) {cancellableThreads.checkForCancel();//拿到shard的存储信息final Store store = shard.store();try {StopWatch stopWatch = new StopWatch().start();final Store.MetadataSnapshot recoverySourceMetadata;try {// 拿到snapshot的metadatarecoverySourceMetadata = store.getMetadata(snapshot);} catch (CorruptIndexException | IndexFormatTooOldException | IndexFormatTooNewException ex) {shard.failShard("recovery", ex);throw ex;}for (String name : snapshot.getFileNames()) {final StoreFileMetadata md = recoverySourceMetadata.get(name);if (md == null) {logger.info("Snapshot differs from actual index for file: {} meta: {}", name, recoverySourceMetadata.asMap());throw new CorruptIndexException("Snapshot differs from actual index - maybe index was removed metadata has " +recoverySourceMetadata.asMap().size() + " files", name);}}// 如果syncid相等,再继续比较下文档数,如果都相同则不用恢复if (canSkipPhase1(recoverySourceMetadata, request.metadataSnapshot()) == false) {final List<String> phase1FileNames = new ArrayList<>();final List<Long> phase1FileSizes = new ArrayList<>();final List<String> phase1ExistingFileNames = new ArrayList<>();final List<Long> phase1ExistingFileSizes = new ArrayList<>();// Total size of segment files that are recoveredlong totalSizeInBytes = 0;// Total size of segment files that were able to be re-usedlong existingTotalSizeInBytes = 0;// Generate a "diff" of all the identical, different, and missing// segment files on the target node, using the existing files on// the source node// 找出target和source有差别的segment// https://github.com/jiankunking/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/index/store/Store.java#L971final Store.RecoveryDiff diff = recoverySourceMetadata.recoveryDiff(request.metadataSnapshot());for (StoreFileMetadata md : diff.identical) {phase1ExistingFileNames.add(md.name());phase1ExistingFileSizes.add(md.length());existingTotalSizeInBytes += md.length();if (logger.isTraceEnabled()) {logger.trace("recovery [phase1]: not recovering [{}], exist in local store and has checksum [{}]," +" size [{}]", md.name(), md.checksum(), md.length());}totalSizeInBytes += md.length();}List<StoreFileMetadata> phase1Files = new ArrayList<>(diff.different.size() + diff.missing.size());phase1Files.addAll(diff.different);phase1Files.addAll(diff.missing);for (StoreFileMetadata md : phase1Files) {if (request.metadataSnapshot().asMap().containsKey(md.name())) {logger.trace("recovery [phase1]: recovering [{}], exists in local store, but is different: remote [{}], local [{}]",md.name(), request.metadataSnapshot().asMap().get(md.name()), md);} else {logger.trace("recovery [phase1]: recovering [{}], does not exist in remote", md.name());}phase1FileNames.add(md.name());phase1FileSizes.add(md.length());totalSizeInBytes += md.length();}logger.trace("recovery [phase1]: recovering_files [{}] with total_size [{}], reusing_files [{}] with total_size [{}]",phase1FileNames.size(), new ByteSizeValue(totalSizeInBytes),phase1ExistingFileNames.size(), new ByteSizeValue(existingTotalSizeInBytes));final StepListener<Void> sendFileInfoStep = new StepListener<>();final StepListener<Void> sendFilesStep = new StepListener<>();final StepListener<RetentionLease> createRetentionLeaseStep = new StepListener<>();final StepListener<Void> cleanFilesStep = new StepListener<>();cancellableThreads.checkForCancel();recoveryTarget.receiveFileInfo(phase1FileNames, phase1FileSizes, phase1ExistingFileNames,phase1ExistingFileSizes, translogOps.getAsInt(), sendFileInfoStep);// 将需要恢复的文件发送到target nodesendFileInfoStep.whenComplete(r ->sendFiles(store, phase1Files.toArray(new StoreFileMetadata[0]), translogOps, sendFilesStep), listener::onFailure);sendFilesStep.whenComplete(r -> createRetentionLease(startingSeqNo, createRetentionLeaseStep), listener::onFailure);createRetentionLeaseStep.whenComplete(retentionLease ->{final long lastKnownGlobalCheckpoint = shard.getLastKnownGlobalCheckpoint();assert retentionLease == null || retentionLease.retainingSequenceNumber() - 1 <= lastKnownGlobalCheckpoint: retentionLease + " vs " + lastKnownGlobalCheckpoint;// Establishes new empty translog on the replica with global checkpoint set to lastKnownGlobalCheckpoint. We want// the commit we just copied to be a safe commit on the replica, so why not set the global checkpoint on the replica// to the max seqno of this commit? Because (in rare corner cases) this commit might not be a safe commit here on// the primary, and in these cases the max seqno would be too high to be valid as a global checkpoint.cleanFiles(store, recoverySourceMetadata, translogOps, lastKnownGlobalCheckpoint, cleanFilesStep);},listener::onFailure);final long totalSize = totalSizeInBytes;final long existingTotalSize = existingTotalSizeInBytes;cleanFilesStep.whenComplete(r -> {final TimeValue took = stopWatch.totalTime();logger.trace("recovery [phase1]: took [{}]", took);listener.onResponse(new SendFileResult(phase1FileNames, phase1FileSizes, totalSize, phase1ExistingFileNames,phase1ExistingFileSizes, existingTotalSize, took));}, listener::onFailure);} else {logger.trace("skipping [phase1] since source and target have identical sync id [{}]", recoverySourceMetadata.getSyncId());// but we must still create a retention leasefinal StepListener<RetentionLease> createRetentionLeaseStep = new StepListener<>();createRetentionLease(startingSeqNo, createRetentionLeaseStep);createRetentionLeaseStep.whenComplete(retentionLease -> {final TimeValue took = stopWatch.totalTime();logger.trace("recovery [phase1]: took [{}]", took);listener.onResponse(new SendFileResult(Collections.emptyList(), Collections.emptyList(), 0L, Collections.emptyList(),Collections.emptyList(), 0L, took));}, listener::onFailure);}} catch (Exception e) {throw new RecoverFilesRecoveryException(request.shardId(), 0, new ByteSizeValue(0L), e);}}
从上面代码可以看出,phase1的具体逻辑是,首先拿到待恢复shard的metadataSnapshot从而得到recoverySourceSyncId,根据request拿到recoveryTargetSyncId,比较两边的syncid,如果相同再比较源和目标的文档数,如果也相同,说明在当前提交点之前源和目标的shard对应的segments都相同,因此不用恢复segment文件(canSkipPhase1方法中比对的)。如果两边的syncid不同,说明segment文件有差异,则需要找出所有有差异的文件进行恢复。通过比较recoverySourceMetadata和recoveryTargetSnapshot的差异性,可以找出所有有差别的segment文件。这块逻辑如下:
/*** Returns a diff between the two snapshots that can be used for recovery. The given snapshot is treated as the* recovery target and this snapshot as the source. The returned diff will hold a list of files that are:* <ul>* <li>identical: they exist in both snapshots and they can be considered the same ie. they don't need to be recovered</li>* <li>different: they exist in both snapshots but their they are not identical</li>* <li>missing: files that exist in the source but not in the target</li>* </ul>* This method groups file into per-segment files and per-commit files. A file is treated as* identical if and on if all files in it's group are identical. On a per-segment level files for a segment are treated* as identical iff:* <ul>* <li>all files in this segment have the same checksum</li>* <li>all files in this segment have the same length</li>* <li>the segments {@code .si} files hashes are byte-identical Note: This is a using a perfect hash function,* The metadata transfers the {@code .si} file content as it's hash</li>* </ul>* <p>* The {@code .si} file contains a lot of diagnostics including a timestamp etc. in the future there might be* unique segment identifiers in there hardening this method further.* <p>* The per-commit files handles very similar. A commit is composed of the {@code segments_N} files as well as generational files* like deletes ({@code _x_y.del}) or field-info ({@code _x_y.fnm}) files. On a per-commit level files for a commit are treated* as identical iff:* <ul>* <li>all files belonging to this commit have the same checksum</li>* <li>all files belonging to this commit have the same length</li>* <li>the segments file {@code segments_N} files hashes are byte-identical Note: This is a using a perfect hash function,* The metadata transfers the {@code segments_N} file content as it's hash</li>* </ul>* <p>* NOTE: this diff will not contain the {@code segments.gen} file. This file is omitted on recovery.*/public RecoveryDiff recoveryDiff(MetadataSnapshot recoveryTargetSnapshot) {final List<StoreFileMetadata> identical = new ArrayList<>();// 相同的file final List<StoreFileMetadata> different = new ArrayList<>();// 不同的filefinal List<StoreFileMetadata> missing = new ArrayList<>();// 缺失的filefinal Map<String, List<StoreFileMetadata>> perSegment = new HashMap<>();final List<StoreFileMetadata> perCommitStoreFiles = new ArrayList<>();for (StoreFileMetadata meta : this) {if (IndexFileNames.OLD_SEGMENTS_GEN.equals(meta.name())) { // legacycontinue; // we don't need that file at all}final String segmentId = IndexFileNames.parseSegmentName(meta.name());final String extension = IndexFileNames.getExtension(meta.name());if (IndexFileNames.SEGMENTS.equals(segmentId) ||DEL_FILE_EXTENSION.equals(extension) || LIV_FILE_EXTENSION.equals(extension)) {// only treat del files as per-commit files fnm files are generational but only for upgradable DVperCommitStoreFiles.add(meta);} else {perSegment.computeIfAbsent(segmentId, k -> new ArrayList<>()).add(meta);}}final ArrayList<StoreFileMetadata> identicalFiles = new ArrayList<>();for (List<StoreFileMetadata> segmentFiles : Iterables.concat(perSegment.values(), Collections.singleton(perCommitStoreFiles))) {identicalFiles.clear();boolean consistent = true;for (StoreFileMetadata meta : segmentFiles) {StoreFileMetadata storeFileMetadata = recoveryTargetSnapshot.get(meta.name());if (storeFileMetadata == null) {consistent = false;missing.add(meta);// 该segment在target node中不存在,则加入到missing} else if (storeFileMetadata.isSame(meta) == false) {consistent = false;different.add(meta);// 存在但不相同,则加入到different} else {identicalFiles.add(meta);// 存在且相同}}if (consistent) {identical.addAll(identicalFiles);} else {// make sure all files are added - this can happen if only the deletes are differentdifferent.addAll(identicalFiles);}}RecoveryDiff recoveryDiff = new RecoveryDiff(Collections.unmodifiableList(identical),Collections.unmodifiableList(different), Collections.unmodifiableList(missing));assert recoveryDiff.size() == this.metadata.size() - (metadata.containsKey(IndexFileNames.OLD_SEGMENTS_GEN) ? 1 : 0): "some files are missing recoveryDiff size: [" + recoveryDiff.size() + "] metadata size: [" +this.metadata.size() + "] contains segments.gen: [" + metadata.containsKey(IndexFileNames.OLD_SEGMENTS_GEN) + "]";return recoveryDiff;}
这里将所有的segment file分为三类:identical(相同)、different(不同)、missing(target缺失)。然后将different和missing的segment files作为第一阶段需要恢复的文件发送到target node。发送完segment files后,源节点还会向目标节点发送消息以通知目标节点清理临时文件,然后也会发送消息通知目标节点打开引擎准备接收translog。
第二阶段的逻辑比较简单,只需将translog view到当前时间之间的所有translog发送给源节点即可。
第二阶段使用当前translog的快照,而不获取写锁(但是,translog快照是translog的时间点视图)。然后,它将每个translog操作发送到目标节点,以便将其重播到新的shard中。
/*** Perform phase two of the recovery process.* <p>* Phase two uses a snapshot of the current translog *without* acquiring the write lock (however, the translog snapshot is* point-in-time view of the translog). It then sends each translog operation to the target node so it can be replayed into the new* shard.** @param startingSeqNo the sequence number to start recovery from, or {@link SequenceNumbers#UNASSIGNED_SEQ_NO} if all* ops should be sent* @param endingSeqNo the highest sequence number that should be sent* @param snapshot a snapshot of the translog* @param maxSeenAutoIdTimestamp the max auto_id_timestamp of append-only requests on the primary* @param maxSeqNoOfUpdatesOrDeletes the max seq_no of updates or deletes on the primary after these operations were executed on it.* @param listener a listener which will be notified with the local checkpoint on the target.*/void phase2(final long startingSeqNo,final long endingSeqNo,final Translog.Snapshot snapshot,final long maxSeenAutoIdTimestamp,final long maxSeqNoOfUpdatesOrDeletes,final RetentionLeases retentionLeases,final long mappingVersion,final ActionListener<SendSnapshotResult> listener) throws IOException {if (shard.state() == IndexShardState.CLOSED) {throw new IndexShardClosedException(request.shardId());}logger.trace("recovery [phase2]: sending transaction log operations (from [" + startingSeqNo + "] to [" + endingSeqNo + "]");final StopWatch stopWatch = new StopWatch().start();final StepListener<Void> sendListener = new StepListener<>();final OperationBatchSender sender = new OperationBatchSender(startingSeqNo, endingSeqNo, snapshot, maxSeenAutoIdTimestamp,maxSeqNoOfUpdatesOrDeletes, retentionLeases, mappingVersion, sendListener);sendListener.whenComplete(ignored -> {final long skippedOps = sender.skippedOps.get();final int totalSentOps = sender.sentOps.get();final long targetLocalCheckpoint = sender.targetLocalCheckpoint.get();assert snapshot.totalOperations() == snapshot.skippedOperations() + skippedOps + totalSentOps: String.format(Locale.ROOT, "expected total [%d], overridden [%d], skipped [%d], total sent [%d]",snapshot.totalOperations(), snapshot.skippedOperations(), skippedOps, totalSentOps);stopWatch.stop();final TimeValue tookTime = stopWatch.totalTime();logger.trace("recovery [phase2]: took [{}]", tookTime);listener.onResponse(new SendSnapshotResult(targetLocalCheckpoint, totalSentOps, tookTime));}, listener::onFailure);sender.start();}
目标节点开始恢复
接收segment
对应上一小节源节点恢复的第一阶段,源节点将所有有差异的segment发送给目标节点,目标节点接收到后会将segment文件落盘。segment files的写入函数为RecoveryTarget.writeFileChunk:
真正执行的位置:MultiFileWriter.innerWriteFileChunk
public void writeFileChunk(StoreFileMetaData fileMetaData, long position, BytesReference content, boolean lastChunk, int totalTranslogOps) throws IOException {final Store store = store();final String name = fileMetaData.name();... ...if (position == 0) {indexOutput = openAndPutIndexOutput(name, fileMetaData, store);} else {indexOutput = getOpenIndexOutput(name); // 加一层前缀,组成临时文件}... ...while((scratch = iterator.next()) != null) { indexOutput.writeBytes(scratch.bytes, scratch.offset, scratch.length); // 写临时文件}... ...store.directory().sync(Collections.singleton(temporaryFileName)); // 这里会调用fsync落盘
}
打开引擎
经过上面的过程,目标节点完成了追数据的第一步。接收完segment后,目标节点打开shard对应的引擎准备接收translog,注意,这里打开引擎后,正在恢复的shard便可进行写入、删除(操作包括primary shard同步的请求和translog中的操作命令)。打开引擎的逻辑如下:
/*** Opens the engine on top of the existing lucene engine and translog.* The translog is kept but its operations won't be replayed.*/public void openEngineAndSkipTranslogRecovery() throws IOException {assert routingEntry().recoverySource().getType() == RecoverySource.Type.PEER : "not a peer recovery [" + routingEntry() + "]";recoveryState.validateCurrentStage(RecoveryState.Stage.TRANSLOG);loadGlobalCheckpointToReplicationTracker();innerOpenEngineAndTranslog(replicationTracker);getEngine().skipTranslogRecovery();}private void innerOpenEngineAndTranslog(LongSupplier globalCheckpointSupplier) throws IOException {assert Thread.holdsLock(mutex) == false : "opening engine under mutex";if (state != IndexShardState.RECOVERING) {throw new IndexShardNotRecoveringException(shardId, state);}final EngineConfig config = newEngineConfig(globalCheckpointSupplier);// we disable deletes since we allow for operations to be executed against the shard while recovering// but we need to make sure we don't loose deletes until we are done recoveringconfig.setEnableGcDeletes(false);// 恢复过程中不删除translogupdateRetentionLeasesOnReplica(loadRetentionLeases());assert recoveryState.getRecoverySource().expectEmptyRetentionLeases() == false || getRetentionLeases().leases().isEmpty(): "expected empty set of retention leases with recovery source [" + recoveryState.getRecoverySource()+ "] but got " + getRetentionLeases();synchronized (engineMutex) {assert currentEngineReference.get() == null : "engine is running";verifyNotClosed();// we must create a new engine under mutex (see IndexShard#snapshotStoreMetadata).final Engine newEngine = engineFactory.newReadWriteEngine(config);// 创建engineonNewEngine(newEngine);currentEngineReference.set(newEngine);// We set active because we are now writing operations to the engine; this way,// we can flush if we go idle after some time and become inactive.active.set(true);}// time elapses after the engine is created above (pulling the config settings) until we set the engine reference, during// which settings changes could possibly have happened, so here we forcefully push any config changes to the new engine.onSettingsChanged();assert assertSequenceNumbersInCommit();recoveryState.validateCurrentStage(RecoveryState.Stage.TRANSLOG);}
接收并重放translog
打开引擎后,便可以根据translog中的命令进行相应的回放动作,回放的逻辑和正常的写入、删除类似,这里需要根据translog还原出操作类型和操作数据,并根据操作数据构建相应的数据对象,然后再调用上一步打开的engine执行相应的操作,这块逻辑如下:
IndexShard#runTranslogRecovery
=>
IndexShard#applyTranslogOperation
// 重放translog快照中的translog操作到当前引擎。
// 在成功回放每个translog操作后,会通知回调onOperationRecovered。/*** Replays translog operations from the provided translog {@code snapshot} to the current engine using the given {@code origin}.* The callback {@code onOperationRecovered} is notified after each translog operation is replayed successfully.*/int runTranslogRecovery(Engine engine, Translog.Snapshot snapshot, Engine.Operation.Origin origin,Runnable onOperationRecovered) throws IOException {int opsRecovered = 0;Translog.Operation operation;while ((operation = snapshot.next()) != null) {try {logger.trace("[translog] recover op {}", operation);Engine.Result result = applyTranslogOperation(engine, operation, origin);switch (result.getResultType()) {case FAILURE:throw result.getFailure();case MAPPING_UPDATE_REQUIRED:throw new IllegalArgumentException("unexpected mapping update: " + result.getRequiredMappingUpdate());case SUCCESS:break;default:throw new AssertionError("Unknown result type [" + result.getResultType() + "]");}opsRecovered++;onOperationRecovered.run();} catch (Exception e) {// TODO: Don't enable this leniency unless users explicitly opt-inif (origin == Engine.Operation.Origin.LOCAL_TRANSLOG_RECOVERY && ExceptionsHelper.status(e) == RestStatus.BAD_REQUEST) {// mainly for MapperParsingException and Failure to detect xcontentlogger.info("ignoring recovery of a corrupt translog entry", e);} else {throw ExceptionsHelper.convertToRuntime(e);}}}return opsRecovered;}private Engine.Result applyTranslogOperation(Engine engine, Translog.Operation operation,Engine.Operation.Origin origin) throws IOException {// If a translog op is replayed on the primary (eg. ccr), we need to use external instead of null for its version type.final VersionType versionType = (origin == Engine.Operation.Origin.PRIMARY) ? VersionType.EXTERNAL : null;final Engine.Result result;switch (operation.opType()) {// 还原出操作类型及操作数据并调用engine执行相应的动作case INDEX:final Translog.Index index = (Translog.Index) operation;// we set canHaveDuplicates to true all the time such that we de-optimze the translog case and ensure that all// autoGeneratedID docs that are coming from the primary are updated correctly.result = applyIndexOperation(engine, index.seqNo(), index.primaryTerm(), index.version(),versionType, UNASSIGNED_SEQ_NO, 0, index.getAutoGeneratedIdTimestamp(), true, origin,new SourceToParse(shardId.getIndexName(), index.id(), index.source(),XContentHelper.xContentType(index.source()), index.routing()));break;case DELETE:final Translog.Delete delete = (Translog.Delete) operation;result = applyDeleteOperation(engine, delete.seqNo(), delete.primaryTerm(), delete.version(), delete.id(),versionType, UNASSIGNED_SEQ_NO, 0, origin);break;case NO_OP:final Translog.NoOp noOp = (Translog.NoOp) operation;result = markSeqNoAsNoop(engine, noOp.seqNo(), noOp.primaryTerm(), noOp.reason(), origin);break;default:throw new IllegalStateException("No operation defined for [" + operation + "]");}return result;}
通过上面的步骤,translog的重放完毕,此后需要做一些收尾的工作,包括,refresh让回放后的最新数据可见,打开translog gc:
/*** perform the last stages of recovery once all translog operations are done.* note that you should still call {@link #postRecovery(String)}.*/public void finalizeRecovery() {recoveryState().setStage(RecoveryState.Stage.FINALIZE);Engine engine = getEngine();engine.refresh("recovery_finalization");engine.config().setEnableGcDeletes(true);}
到这里,replica shard恢复的两个阶段便完成了,由于此时shard还处于INITIALIZING状态,还需通知master节点启动已恢复的shard:
IndicesClusterStateService#RecoveryListener
@Overridepublic void onRecoveryDone(final RecoveryState state, ShardLongFieldRange timestampMillisFieldRange) {shardStateAction.shardStarted(shardRouting,primaryTerm,"after " + state.getRecoverySource(),timestampMillisFieldRange,SHARD_STATE_ACTION_LISTENER);}
至此,shard recovery的所有流程都已完成。
小结
疑问点1:网上说的对不对?新版本中有没有更新?
到这里完整跟着腾讯云的文档走了一遍,主体的流程在Elasticsearch 8.0.0-SNAPSHOT中基本一样,只是部分方法有些调整。
所以下面这个流程还是正确的:
ES副本分片恢复主要涉及恢复的目标节点和源节点,目标节点即故障恢复的节点,源节点为提供恢复的节点。目标节点向源节点发送分片恢复请求,源节点接收到请求后主要分两阶段来处理。第一阶段,对需要恢复的shard创建snapshot,然后根据请求中的metadata对比如果 syncid 相同且 doc 数量相同则跳过,否则对比shard的segment文件差异,将有差异的segment文件发送给target node。第二阶段,为了保证target node数据的完整性,需要将本地的translog发送给target node,且对接收到的translog进行回放。整体流程如下图所示:

疑问点2:在分片恢复的时候,如果收到Api _forcemerge请求,这时候,会如何处理?
这部分等看/_forcemerge api的时候,再解答一下。
疑问点3:片恢复的第二阶段是同步translog,这一步会不会加锁?不加锁的话,如何确保是同步完成了?
完整性
首先,phase1阶段,保证了存量的历史数据可以恢复到从分片。phase1阶段完成后,从分片引擎打开,可以正常处理index、delete请求,而translog覆盖完了整个phase1阶段,因此在phase1阶段中的index/delete操作都将被记录下来,在phase2阶段进行translog回放时,副本分片正常的index和delete操作和translog是并行执行的,这就保证了恢复开始之前的数据、恢复中的数据都会完整的写入到副本分片,保证了数据的完整性。如下图所示:

一致性
由于phase1阶段完成后,从分片便可正常处理写入操作,而此时从分片的写入和phase2阶段的translog回放时并行执行的,如果translog的回放慢于正常的写入操作,那么可能会导致老的数据后写入,造成数据不一致。ES为了保证数据的一致性在进行写入操作时,会比较当前写入的版本和lucene文档版本号,如果当前版本更小,说明是旧数据则不会将文档写入lucene。相关代码如下:
// https://github.com/jiankunking/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/index/engine/InternalEngine.java#L993
final OpVsLuceneDocStatus opVsLucene = compareOpToLuceneDocBasedOnSeqNo(index);
if (opVsLucene == OpVsLuceneDocStatus.OP_STALE_OR_EQUAL) {plan = IndexingStrategy.processAsStaleOp(index.version(), 0);
}
拓展:如何保证副分片和主分片一致
整理自:《Elasticsearch源码解析与优化实战》
索引恢复过程的一个难点在于如何维护主副分片的一致性。假设副分片恢复期间一直有写操作,如何实现一致呢?
我们先看看早期的做法:在2.0版本之前,副分片恢复要经历三个阶段。
- phase1:将主分片的 Lucene 做快照,发送到 target。期间不阻塞索引操作,新增数据写到主分片的translog。
- phase2:将主分片translog做快照,发送到target重放,期间不阻塞索引操作。
- phase3:为主分片加写锁,将剩余的translog发送到target。此时数据量很小,写入过程的阻塞很短。
从理论上来说,只要流程上允许将写操作阻塞一段时间,实现主副一致是比较容易的。
但是后来(从2.0版本开始),也就是引入translog.view概念的同时,phase3被删除。
phase3被删除,这个阶段是重放操作(operations),同时防止新的写入 Engine。这是不必要的,因为自恢复开始,标准的 index 操作会发送所有的操作到正在恢复中的分片。重放恢复开始时获取的view中的所有操作足够保证不丢失任何操作。
阻塞写操作的phase3被删除,恢复期间没有任何写阻塞过程。接下来需要处理的就是解决phase1和phase2之间的写操作与phase2重放操作之间的时序和冲突问题。在副分片节点,phase1结束后,假如新增索引操作和 translog 重放操作并发执行,因为时序的关系会出现新老数据交替。如何实现主副分片一致呢?
假设在第一阶段执行期间,有客户端索引操作要求将docA的内容写为1,主分片执行了这个操作,而副分片由于尚未就绪所以没有执行。第二阶段期间客户端索引操作要求写 docA 的内容为2,此时副分片已经就绪,先执行将docA写为2的新增请求,然后又收到了从主分片所在节点发送过来的translog重复写docA为1的请求该如何处理?具体流程如下图所示。

答案是在写流程中做异常处理,通过版本号来过滤掉过期操作。写操作有三种类型:索引新文档、更新、删除。索引新文档不存在冲突问题,更新和删除操作采用相同的处理机制。每个操作都有一个版本号,这个版本号就是预期doc版本,它必须大于当前Lucene中的doc版本号,否则就放弃本次操作。对于更新操作来说,预期版本号是Lucene doc版本号+1。主分片节点写成功后新数据的版本号会放到写副本的请求中,这个请求中的版本号就是预期版本号。
这样,时序上存在错误的操作被忽略,对于特定doc,只有最新一次操作生效,保证了主副分片一致。
我们分别看一下写操作三种类型的处理机制。
1.索引新文档
不存在冲突问题,不需要处理。
2.更新
判断本次操作的版本号是否小于Lucene中doc的版本号,如果小于,则放弃本次操作。
Index、Delete都继承自Operation,每个Operation都有一个版本号,这个版本号就是doc版本号。对于副分片的写流程来说,正常情况下是主分片写成功后,相应doc写入的版本号被放到转发写副分片的请求中。对于更新来说,就是通过主分片将原doc版本号+1后转发到副分片实现的。在对比版本号的时候:
expectedVersion = 写副分片请求中的 version = 写主分片成功后的version
通过下面的方法判断当前操作的版本号是否低于Lucene中的版本号:
// VersionType#isVersionConflictForWritesEXTERNAL((byte) 1) {@Overridepublic boolean isVersionConflictForWrites(long currentVersion, long expectedVersion, boolean deleted) {if (currentVersion == Versions.NOT_FOUND) {return false;}if (expectedVersion == Versions.MATCH_ANY) {return true;}if (currentVersion >= expectedVersion) {return true;}return false;}}
如果translog重放的操作在写一条"老"数据,则compareOpToLuceneDocBasedOnSeqNo会返回OpVsLuceneDocStatus.OP_STALE_OR_EQUAL。
private OpVsLuceneDocStatus compareOpToLuceneDocBasedOnSeqNo(final Operation op) throws IOException {assert op.seqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO : "resolving ops based on seq# but no seqNo is found";final OpVsLuceneDocStatus status;VersionValue versionValue = getVersionFromMap(op.uid().bytes());assert incrementVersionLookup();if (versionValue != null) {status = compareOpToVersionMapOnSeqNo(op.id(), op.seqNo(), op.primaryTerm(), versionValue);} else {// load from indexassert incrementIndexVersionLookup();try (Searcher searcher = acquireSearcher("load_seq_no", SearcherScope.INTERNAL)) {final DocIdAndSeqNo docAndSeqNo = VersionsAndSeqNoResolver.loadDocIdAndSeqNo(searcher.getIndexReader(), op.uid());if (docAndSeqNo == null) {status = OpVsLuceneDocStatus.LUCENE_DOC_NOT_FOUND;} else if (op.seqNo() > docAndSeqNo.seqNo) {status = OpVsLuceneDocStatus.OP_NEWER;} else if (op.seqNo() == docAndSeqNo.seqNo) {assert localCheckpointTracker.hasProcessed(op.seqNo()) :"local checkpoint tracker is not updated seq_no=" + op.seqNo() + " id=" + op.id();status = OpVsLuceneDocStatus.OP_STALE_OR_EQUAL;} else {status = OpVsLuceneDocStatus.OP_STALE_OR_EQUAL;}}}return status;}
副分片在InternalEngine#index函数中通过plan判断是否写到Lucene:
// non-primary mode (i.e., replica or recovery)
final IndexingStrategy plan = indexingStrategyForOperation(index);
在 indexingStrategyForOperation函数中,plan的最终结果就是plan =IndexingStrategy.processButSkipLucene,后面会跳过写Lucene和translog的逻辑。
3. 删除
判断本次操作中的版本号是否小于Lucene中doc的版本号,如果小于,则放弃本次操作。
通过compareOpToLuceneDocBasedOnSeqNo方法判断本次操作是否小于Lucenne中doc的版本号,与Index操作时使用相同的比较函数。
类似的,在InternalEngine#delete函数中判断是否写到Lucene:
final DeletionStrategy plan = deletionStrategyForOperation(delete);
如果translog重放的是一个"老"的删除操作,则compareOpToLuceneDocBasedOnSeqNo会返回OpVsLuceneDocStatus.OP_STALE_OR_EQUAL。
plan的最终结果就是plan=DeletionStrategy.processButSkipLucene,后面会跳过Lucene删除的逻辑。
/*** the status of the current doc version in lucene, compared to the version in an incoming* operation*/enum OpVsLuceneDocStatus {/** the op is more recent than the one that last modified the doc found in lucene*/OP_NEWER,/** the op is older or the same as the one that last modified the doc found in lucene*/OP_STALE_OR_EQUAL,/** no doc was found in lucene */LUCENE_DOC_NOT_FOUND}
相关文章:
【Elasticsearch源码】 分片恢复分析
带着疑问学源码,第七篇:Elasticsearch 分片恢复分析 代码分析基于:https://github.com/jiankunking/elasticsearch Elasticsearch 8.0.0-SNAPSHOT 目的 在看源码之前先梳理一下,自己对于分片恢复的疑问点: 网上对于E…...
elasticsearch如何操作索引库里面的文档
上节介绍了索引库的CRUD,接下来操作索引库里面的文档 目录 一、添加文档 二、查询文档 三、删除文档 四、修改文档 一、添加文档 新增文档的DSL语法如下 POST /索引库名/_doc/文档id(不加id,es会自动生成) { "字段1":"值1", "字段2&q…...
opencv期末练习题(2)附带解析
图像插值与缩放 %matplotlib inline import cv2 import matplotlib.pyplot as plt def imshow(img,grayFalse,bgr_modeFalse):if gray:img cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)plt.imshow(img,cmap"gray")else:if not bgr_mode:img cv2.cvtColor(img,cv2.COLOR_B…...

【Mybatis】深入学习MyBatis:高级特性与Spring整合
🍎个人博客:个人主页 🏆个人专栏: Mybatis ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 高级特性 1 一级缓存和二级缓存 一级缓存 二级缓存 2 延迟加载 5 整合Spring 1 MyBatis-Spring模块 2 事务管理 结…...

C语言与人生函数的对比,使用,参数详解
各位少年,大家好,我是博主那一脸阳光。,今天给大家分享函数的定义,和数学的函数的区别和使用 前言:C语言中的函数和数学中的函数在概念上有相似之处,但也存在显著的区别。下面对比它们的主要特点ÿ…...

机器人动力学一些笔记
动力学方程中,Q和q的关系(Q是sita) Q其实是一个向量,q(Q1,Q2,Q3,Q4,Q5,Q6)(假如6个关节) https://zhuanlan.zhihu.com/p/25789930 举个浅显易懂的例子,你在房…...
Plantuml之甘特图语法介绍(二十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
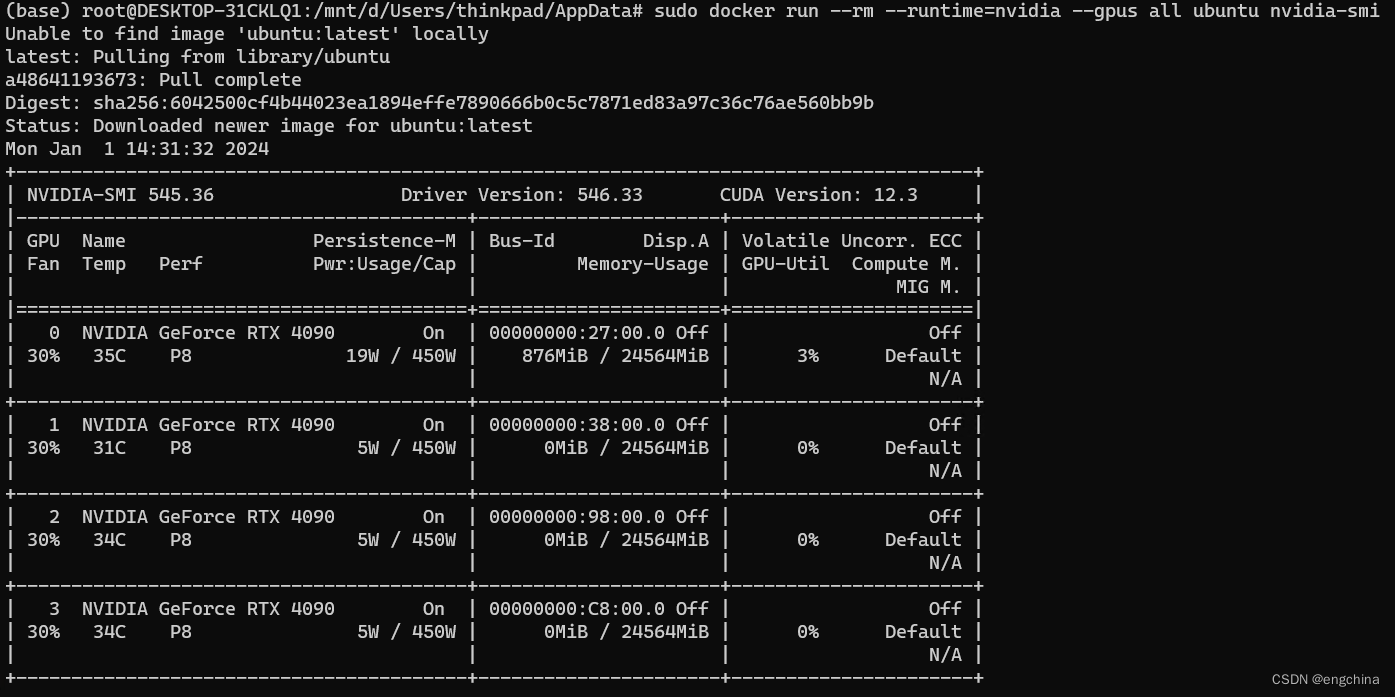
Docker support for NVIDIA GPU Accelerated Computing on WSL 2
Docker support for NVIDIA GPU Accelerated Computing on WSL 2 0. 背景1. 安装 Docker Desktop2. 配置 Docker Desktop3. WLS Ubuntu 配置4. 安装 Docker-ce5. 安装 NVIDIA Container Toolkit6. 配置 Docker7. 运行一个 Sample Workload 0. 背景 今天尝试一下 NVIDIA GPU 在…...
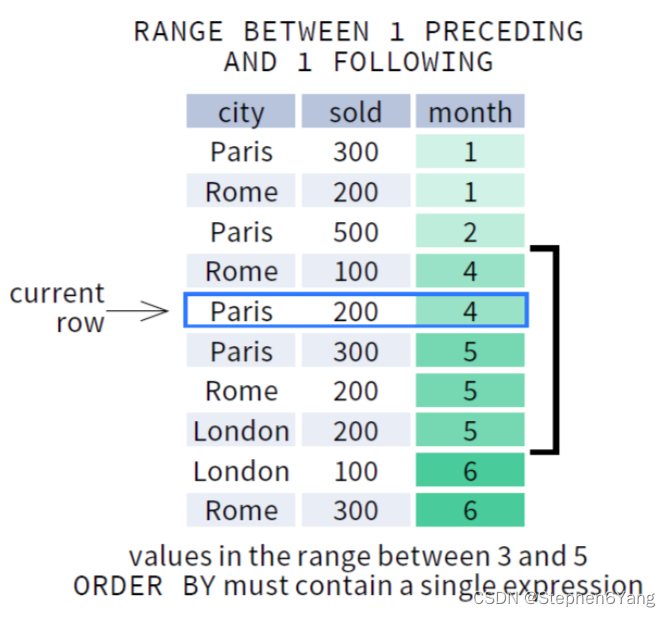
SQL窗口函数大小详解
窗口大小 OVER 子句中的 frame_clause 选项用于指定一个滑动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。 指定窗口大小的语法如下: ROWS…...

C#上位机与欧姆龙PLC的通信06---- HostLink协议(FINS版)
1、介绍 对于上位机开发来说,欧姆龙PLC支持的主要的协议有Hostlink协议,FinsTcp/Udp协议,EtherNetIP协议,本项目使用Hostlink协议。 Hostlink协议是欧姆龙PLC与上位机链接的公开协议。上位机通过发送Hostlink命令,可…...

认识SpringBoot项目中的Starter
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 循序渐进学SpringBoot ✨特色专栏&…...

ChatGPT 4.0真的值得花钱买入吗?
性能提升: ChatGPT 4.0的推出不仅意味着更先进的技术,还代表着更强大的性能。相较于3.5,4.0在处理任务时更为高效,响应更迅速。 更智能的理解: 随着版本的升级,ChatGPT 4.0对语境的理解能力得到了进一步的…...

vue3对比vue2是怎样的
一、前言 Vue 3通过引入Composition API、升级响应式系统、优化性能等一系列的改进和升级,提供了更好的开发体验和更好的性能,使得开发者能够更方便地开发出高质量的Web应用。它在Vue.js 2的基础上进行了一系列的改进和升级,以提供更好的性能、更好的开发体验和更好的扩展性…...

openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证
文章目录 openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证184.1 验证项目的检查表184.2 升级版本查询184.2.1 验证步骤 184.3 检查升级数据库状态184.3.1 验证步骤 openGauss学习笔记-184 openGauss 数据库运维-升级-升级验证 本章介绍升级完成后的验证操作。给出验…...
)
[Verilog语言入门教程] Verilog 减法器 (半减器, 全减器, 加减共用)
依公知及经验整理,原创保护,禁止转载。 专栏 《元带你学Verilog》 <<<< 返回总目录 <<<< “逻辑设计是一门艺术,它需要创造力和想象力。” - 马克张伯伦(Mark Zwolinski) 减法器是数字电路中常见的组件,用于减去两个二进制数的和。 在Verilog中…...

预编译仓库中的 Helm Chart
背景 内网部署项目, 没法直接hlem install , 需要提前看看有哪些镜像, 拉到本地看看 要使用预编译仓库中的 Helm Chart,你可以使用 helm fetch 命令来将 Chart 下载到本地,并使用 helm template 命令来预编译该 Chart。 首先,你可以使用以…...

Python requests get和post方法发送HTTP请求
requests.get() requests.get() 方法用于发送 HTTP GET 请求。下面介绍 requests.get() 方法的常用参数: url: 发送请求的 URL 地址。params: URL 中的查询参数,可以是字典或字符串。headers: 请求头信息。可以是字典类型,也可以是自定义的…...

在Cadence中单独添加或删除器件与修改网络的方法
首先需要在设置中使能 ,添加或修改逻辑选项。 添加或删除器件,点击logic-part,选择需要添加或删除的器件,这里的器件必须是PCB中已经有的器件,Refdes中输入添加或删除的器件标号,点击Add添加。 添加完成后就会显示在R1…...

轻松调整视频时长,创意与技术的新篇章
传统的视频剪辑工具往往难以精确控制时间,而【媒体梦工厂】凭借其先进的算法和界面设计,让视频时长的调整变得简单而精确,助你释放无限的创意,用技术为你的创意插上翅膀,让每一秒都有意义。 所需工具: 一…...

树与二叉树笔记整理
摘自小红书 ## 树与二叉树 ## 排序总结...

记录,借助git bash使用脚本批量删除远程tag
在长期的项目开发中,Git 仓库积累大量的标签(Tags),不仅占用空间,加载还卡顿。项目中采用 YYYYMMDD 格式命名标签,这给使用脚本批量删除标签提供了条件。 目录 核心简述 脚本原理解析 安全的执行模式控…...

GCC -flto究竟多危险?——某车规MCU因启用全局链接时优化引发CAN总线丢帧的全链路复现与6步规避法
第一章:GCC -flto的本质与车规MCU的编译语义鸿沟 GCC 的 -flto(Link-Time Optimization)并非简单地延迟优化时机,而是将中间表示(GIMPLE)嵌入目标文件,使链接器(如 GNU ld 配合 plu…...

优化Wan2.2-T2V-A5B推理效率:数据结构与算法层面的调优实践
优化Wan2.2-T2V-A5B推理效率:数据结构与算法层面的调优实践 最近在项目里深度用了一阵子Wan2.2-T2V-A5B这个文生视频模型,效果确实惊艳,但跑起来也是真“吃”资源。生成一个几秒的视频,显存占用动不动就十几个G,推理时…...
)
从零开始玩转SUMO TraCI:手把手教你获取车辆排放数据(含完整代码)
从零开始玩转SUMO TraCI:手把手教你获取车辆排放数据(含完整代码) 在智能交通系统研究中,排放数据分析正成为评估城市可持续性的关键指标。SUMO(Simulation of Urban MObility)作为开源微观交通仿真工具&am…...
;HSDGIFTDSYSRYRKQMAVKKYLAAVL-NH₂)
PACAP-27 (human, ovine, rat);HSDGIFTDSYSRYRKQMAVKKYLAAVL-NH₂
一、基本信息名称: Pituitary Adenylate Cyclase-Activating Polypeptide 27简称: PACAP-27来源种属: 人 / 绵羊 / 大鼠(序列完全一致)三字母序列:His-Ser-Asp-Gly-Ile-Phe-Thr-Asp-Ser-Tyr-Ser-Arg-Tyr-Ar…...

3步突破限制:开源激活工具实现软件功能永久解锁
3步突破限制:开源激活工具实现软件功能永久解锁 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在数字化工作流中,专业软件的功能限制往往成为效率瓶颈。开源激活工具通过…...
)
从Raw到YUV:图解摄像头数据格式转换全流程(含ISP处理关键步骤)
从Raw到YUV:图解摄像头数据格式转换全流程(含ISP处理关键步骤) 在嵌入式视觉系统和智能摄像头的开发中,图像传感器输出的原始数据需要经过复杂的处理流程才能转化为可用的YUV格式。这个转换过程不仅关系到图像质量,还直…...
)
RISC-V C语言驱动调试最后防线:自研轻量级printf-free日志注入框架(仅237行代码,支持CSR实时dump,业内首次开源)
第一章:RISC-V C语言驱动调试最后防线:自研轻量级printf-free日志注入框架(仅237行代码,支持CSR实时dump,业内首次开源)在裸机RISC-V驱动开发中,传统printf依赖完整libc与UART初始化栈ÿ…...

LaTeX科技论文写作:深度学习实验结果可视化技巧
LaTeX科技论文写作:深度学习实验结果可视化技巧 论文图表的质量直接影响审稿人对研究成果的第一印象,好的可视化能让复杂数据一目了然。 1. 为什么LaTeX是深度学习论文的首选 写深度学习论文最头疼的就是处理那些复杂的实验结果。模型性能对比、损失曲线…...

MiniCPM-V-2_6 Ubuntu 20.04一键部署教程:从环境配置到模型调用
MiniCPM-V-2_6 Ubuntu 20.04一键部署教程:从环境配置到模型调用 想试试那个能看懂图片还能跟你聊天的AI模型MiniCPM-V-2_6吗?但一看到什么CUDA、Docker、环境配置这些词就头疼?别担心,这篇教程就是为你准备的。咱们今天不谈复杂的…...