diffusers 源码待理解之处
一、训练DreamBooth时,相关代码的细节小计

**
class_labels = timesteps 时,模型的前向传播怎么走?待深入去看
**
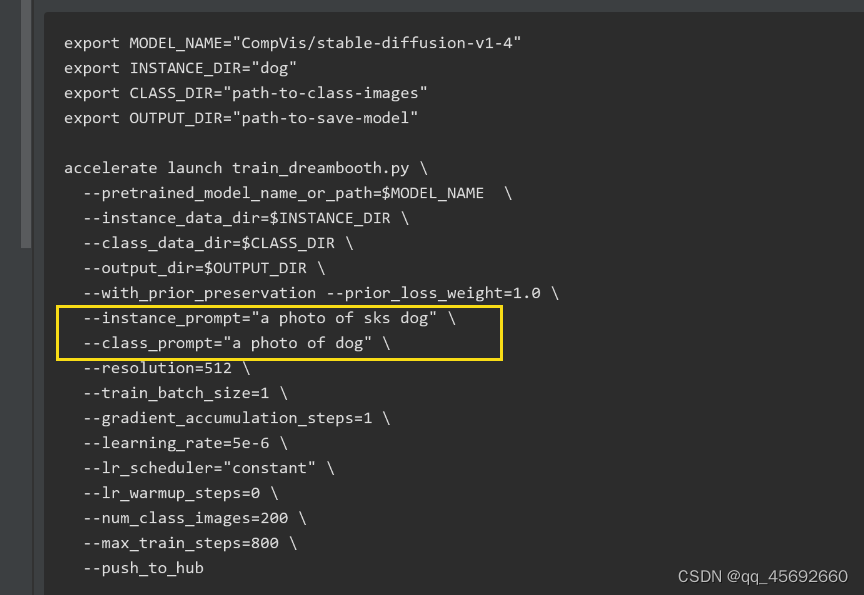
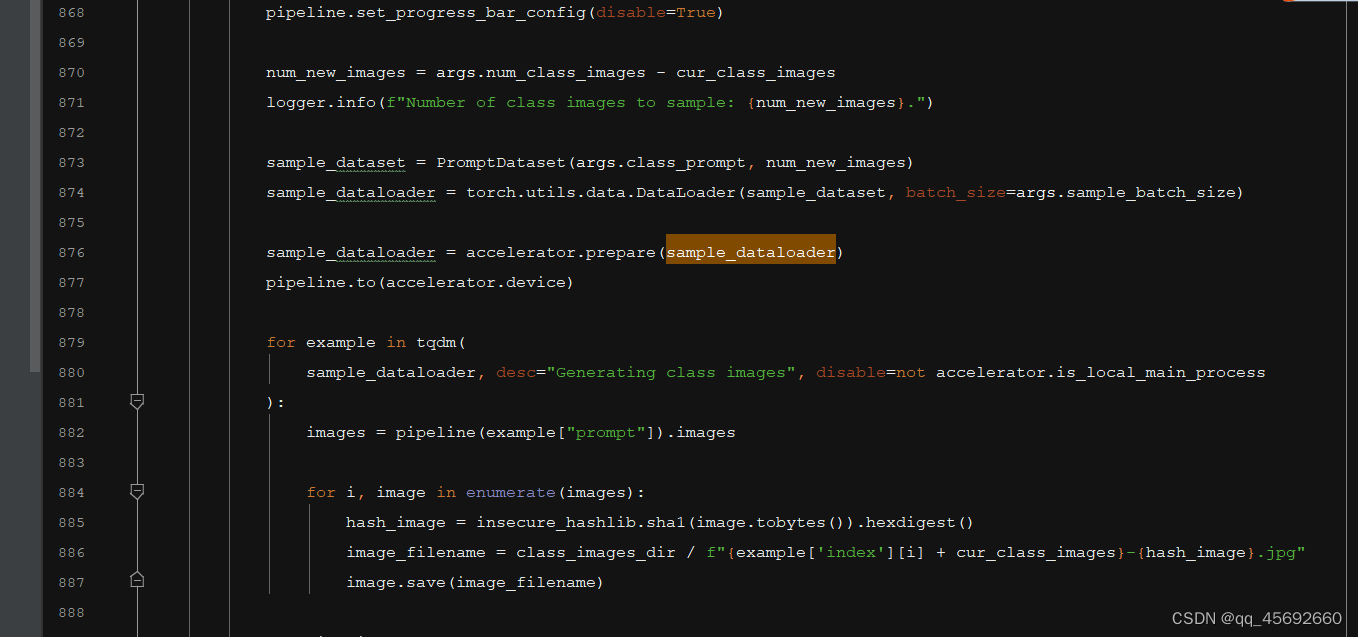
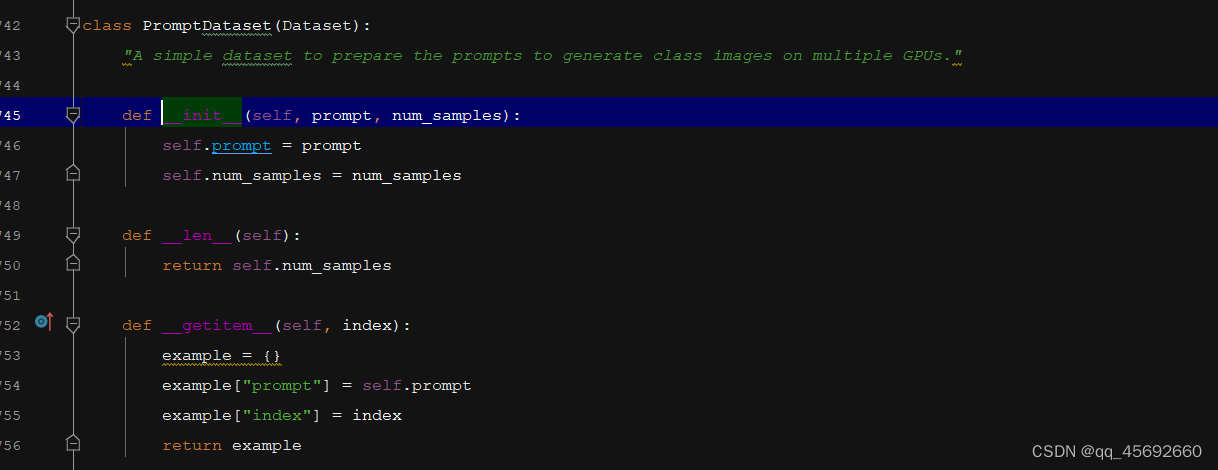
利用class_prompt去生成数据,而不是instance_prompt
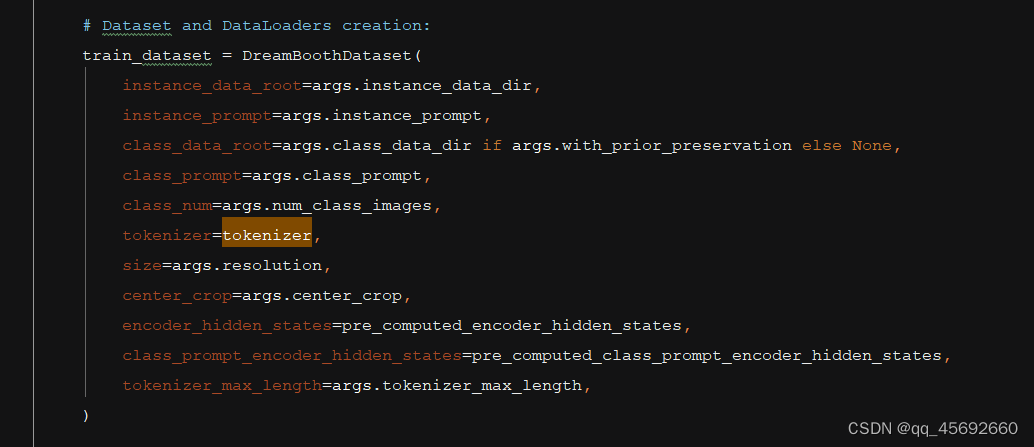
class DreamBoothDataset(Dataset):"""A dataset to prepare the instance and class images with the prompts for fine-tuning the model.It pre-processes the images and the tokenizes prompts."""def __init__(self,instance_data_root,instance_prompt,tokenizer,class_data_root=None,class_prompt=None,class_num=None,size=512,center_crop=False,encoder_hidden_states=None,class_prompt_encoder_hidden_states=None,tokenizer_max_length=None,):self.size = sizeself.center_crop = center_cropself.tokenizer = tokenizerself.encoder_hidden_states = encoder_hidden_statesself.class_prompt_encoder_hidden_states = class_prompt_encoder_hidden_statesself.tokenizer_max_length = tokenizer_max_lengthself.instance_data_root = Path(instance_data_root)if not self.instance_data_root.exists():raise ValueError(f"Instance {self.instance_data_root} images root doesn't exists.")self.instance_images_path = list(Path(instance_data_root).iterdir())self.num_instance_images = len(self.instance_images_path)self.instance_prompt = instance_promptself._length = self.num_instance_imagesif class_data_root is not None:self.class_data_root = Path(class_data_root)self.class_data_root.mkdir(parents=True, exist_ok=True)self.class_images_path = list(self.class_data_root.iterdir())if class_num is not None:self.num_class_images = min(len(self.class_images_path), class_num)else:self.num_class_images = len(self.class_images_path)self._length = max(self.num_class_images, self.num_instance_images)self.class_prompt = class_promptelse:self.class_data_root = Noneself.image_transforms = transforms.Compose([transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])def __len__(self):return self._lengthdef __getitem__(self, index):example = {}instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])instance_image = exif_transpose(instance_image)if not instance_image.mode == "RGB":instance_image = instance_image.convert("RGB")example["instance_images"] = self.image_transforms(instance_image)if self.encoder_hidden_states is not None:example["instance_prompt_ids"] = self.encoder_hidden_stateselse:text_inputs = tokenize_prompt(self.tokenizer, self.instance_prompt, tokenizer_max_length=self.tokenizer_max_length)example["instance_prompt_ids"] = text_inputs.input_idsexample["instance_attention_mask"] = text_inputs.attention_maskif self.class_data_root:class_image = Image.open(self.class_images_path[index % self.num_class_images])class_image = exif_transpose(class_image)if not class_image.mode == "RGB":class_image = class_image.convert("RGB")example["class_images"] = self.image_transforms(class_image)if self.class_prompt_encoder_hidden_states is not None:example["class_prompt_ids"] = self.class_prompt_encoder_hidden_stateselse:class_text_inputs = tokenize_prompt(self.tokenizer, self.class_prompt, tokenizer_max_length=self.tokenizer_max_length)example["class_prompt_ids"] = class_text_inputs.input_idsexample["class_attention_mask"] = class_text_inputs.attention_maskreturn example
def tokenize_prompt(tokenizer, prompt, tokenizer_max_length=None):if tokenizer_max_length is not None:max_length = tokenizer_max_lengthelse:max_length = tokenizer.model_max_lengthtext_inputs = tokenizer(prompt,truncation=True,padding="max_length",max_length=max_length,return_tensors="pt",)return text_inputs
def collate_fn(examples, with_prior_preservation=False):has_attention_mask = "instance_attention_mask" in examples[0]input_ids = [example["instance_prompt_ids"] for example in examples]pixel_values = [example["instance_images"] for example in examples]if has_attention_mask:attention_mask = [example["instance_attention_mask"] for example in examples]# Concat class and instance examples for prior preservation.# We do this to avoid doing two forward passes.if with_prior_preservation:input_ids += [example["class_prompt_ids"] for example in examples]pixel_values += [example["class_images"] for example in examples]if has_attention_mask:attention_mask += [example["class_attention_mask"] for example in examples]pixel_values = torch.stack(pixel_values)pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.cat(input_ids, dim=0)batch = {"input_ids": input_ids,"pixel_values": pixel_values,}if has_attention_mask:attention_mask = torch.cat(attention_mask, dim=0)batch["attention_mask"] = attention_maskreturn batch
Dataset和Dataloader的构成
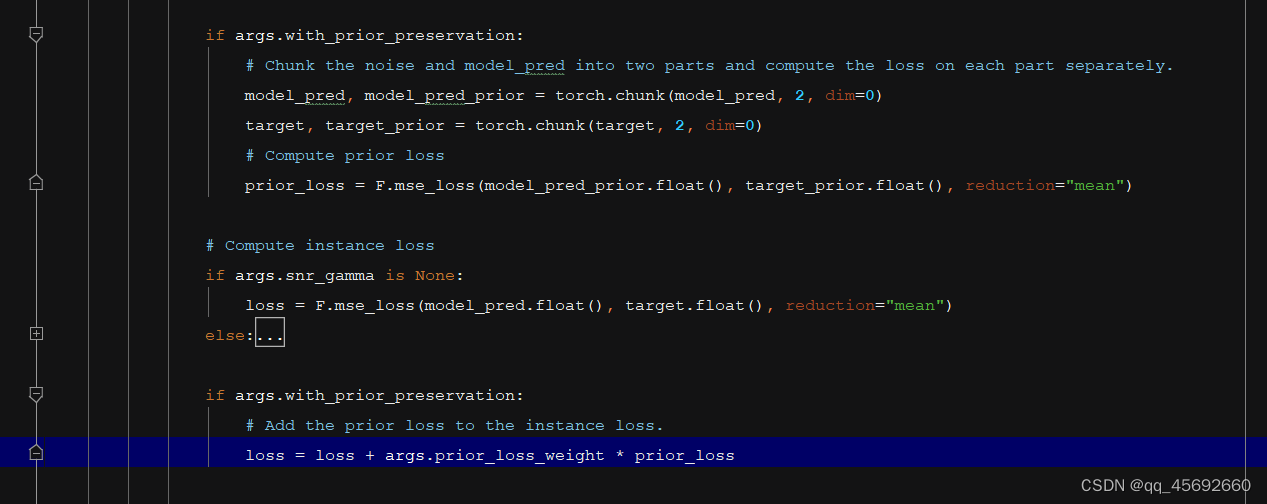
为了避免模型过拟合或者是说语言漂移的情况,需要用模型去用一个普通的prompt先生成样本。
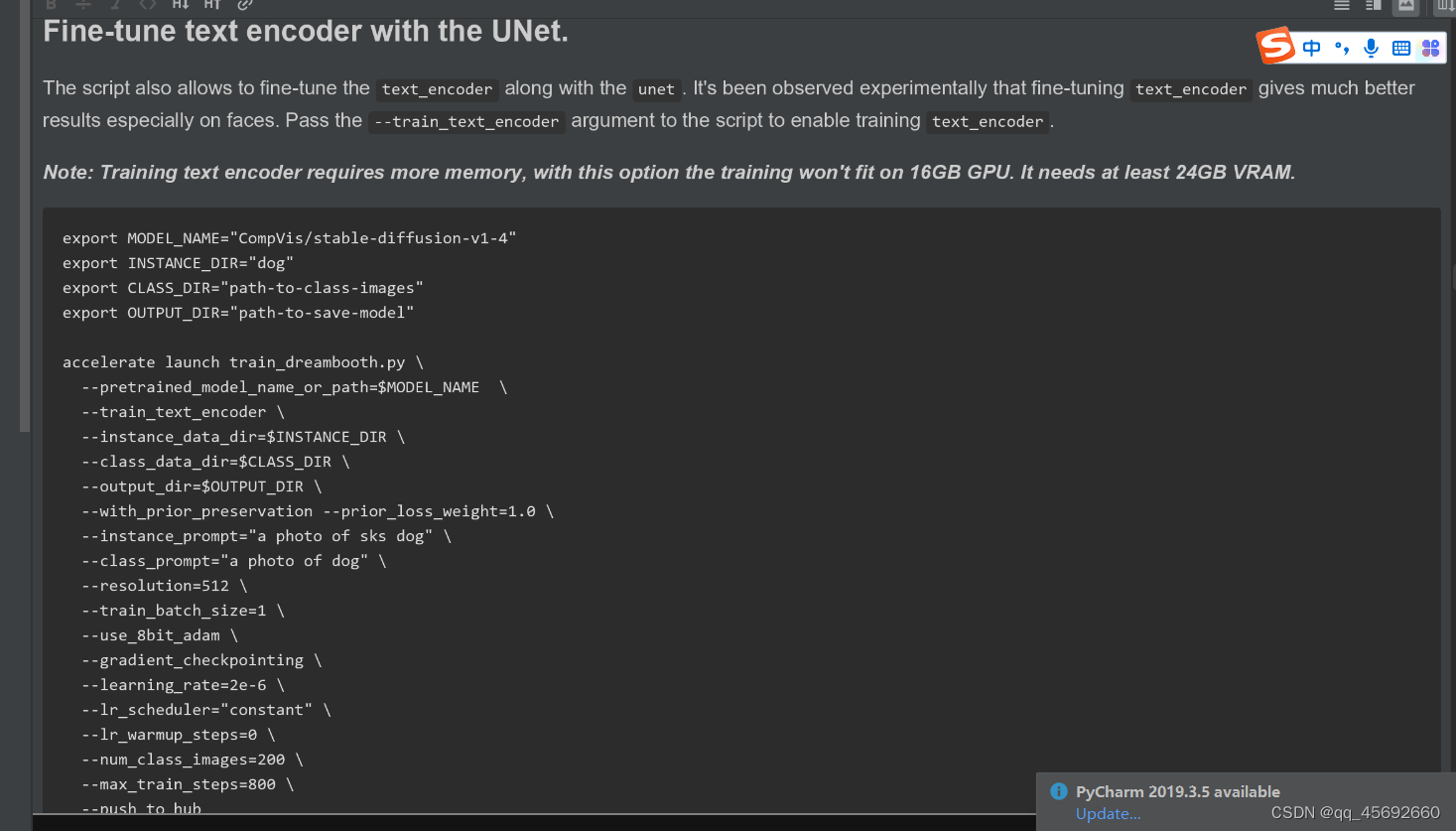
fine-tune text-encoder,但是对显存要求更高
二、训练text to image,相关代码的细节小计
**
1、Dataloader的构建如下,但是为啥没有attention_mask呢?训练DreamBooth时有
2、训练或者微调模型时需要图文数据对,如果没有文本数据,可以用BLIP去生成图像描述的文本,但是文本描述不一定可靠
**
# Get the datasets: you can either provide your own training and evaluation files (see below)# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).# In distributed training, the load_dataset function guarantees that only one local process can concurrently# download the dataset.if args.dataset_name is not None:# Downloading and loading a dataset from the hub.dataset = load_dataset(args.dataset_name,args.dataset_config_name,cache_dir=args.cache_dir,data_dir=args.train_data_dir,)else:data_files = {}if args.train_data_dir is not None:data_files["train"] = os.path.join(args.train_data_dir, "**")dataset = load_dataset("imagefolder",data_files=data_files,cache_dir=args.cache_dir,)# See more about loading custom images at# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder# Preprocessing the datasets.# We need to tokenize inputs and targets.column_names = dataset["train"].column_names# 6. Get the column names for input/target.dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)if args.image_column is None:image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]else:image_column = args.image_columnif image_column not in column_names:raise ValueError(f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}")if args.caption_column is None:caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]else:caption_column = args.caption_columnif caption_column not in column_names:raise ValueError(f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}")# Preprocessing the datasets.# We need to tokenize input captions and transform the images.def tokenize_captions(examples, is_train=True):captions = []for caption in examples[caption_column]:if isinstance(caption, str):captions.append(caption)elif isinstance(caption, (list, np.ndarray)):# take a random caption if there are multiplecaptions.append(random.choice(caption) if is_train else caption[0])else:raise ValueError(f"Caption column `{caption_column}` should contain either strings or lists of strings.")inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt")return inputs.input_ids# Preprocessing the datasets.train_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])def preprocess_train(examples):images = [image.convert("RGB") for image in examples[image_column]]examples["pixel_values"] = [train_transforms(image) for image in images]examples["input_ids"] = tokenize_captions(examples)# images text pixel_values input_ids 4种keyreturn exampleswith accelerator.main_process_first():if args.max_train_samples is not None:dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))# Set the training transformstrain_dataset = dataset["train"].with_transform(preprocess_train)def collate_fn(examples):pixel_values = torch.stack([example["pixel_values"] for example in examples])pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.stack([example["input_ids"] for example in examples])return {"pixel_values": pixel_values, "input_ids": input_ids}# DataLoaders creation:train_dataloader = torch.utils.data.DataLoader(train_dataset,shuffle=True,collate_fn=collate_fn,batch_size=args.train_batch_size,num_workers=args.dataloader_num_workers,)
三、训ControlNet
Dataloader的搭建的代码如下:
1、新增conditioning_pixel_values图像数据,用于做可控的生成
2、输入中依旧没有attention-mask,待思考
def make_train_dataset(args, tokenizer, accelerator):# Get the datasets: you can either provide your own training and evaluation files (see below)# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).# In distributed training, the load_dataset function guarantees that only one local process can concurrently# download the dataset.if args.dataset_name is not None:# Downloading and loading a dataset from the hub.dataset = load_dataset(args.dataset_name,args.dataset_config_name,cache_dir=args.cache_dir,)else:if args.train_data_dir is not None:dataset = load_dataset(args.train_data_dir,cache_dir=args.cache_dir,)# See more about loading custom images at# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script# Preprocessing the datasets.# We need to tokenize inputs and targets.column_names = dataset["train"].column_names# 6. Get the column names for input/target.if args.image_column is None:image_column = column_names[0]logger.info(f"image column defaulting to {image_column}")else:image_column = args.image_columnif image_column not in column_names:raise ValueError(f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")if args.caption_column is None:caption_column = column_names[1]logger.info(f"caption column defaulting to {caption_column}")else:caption_column = args.caption_columnif caption_column not in column_names:raise ValueError(f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")if args.conditioning_image_column is None:conditioning_image_column = column_names[2]logger.info(f"conditioning image column defaulting to {conditioning_image_column}")else:conditioning_image_column = args.conditioning_image_columnif conditioning_image_column not in column_names:raise ValueError(f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}")def tokenize_captions(examples, is_train=True):captions = []for caption in examples[caption_column]:if random.random() < args.proportion_empty_prompts:captions.append("")elif isinstance(caption, str):captions.append(caption)elif isinstance(caption, (list, np.ndarray)):# take a random caption if there are multiplecaptions.append(random.choice(caption) if is_train else caption[0])else:raise ValueError(f"Caption column `{caption_column}` should contain either strings or lists of strings.")inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt")return inputs.input_idsimage_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),])conditioning_image_transforms = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution),transforms.ToTensor(),])def preprocess_train(examples):images = [image.convert("RGB") for image in examples[image_column]]images = [image_transforms(image) for image in images]conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]examples["pixel_values"] = imagesexamples["conditioning_pixel_values"] = conditioning_imagesexamples["input_ids"] = tokenize_captions(examples)return exampleswith accelerator.main_process_first():if args.max_train_samples is not None:dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))# Set the training transformstrain_dataset = dataset["train"].with_transform(preprocess_train)return train_datasetdef collate_fn(examples):pixel_values = torch.stack([example["pixel_values"] for example in examples])pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()input_ids = torch.stack([example["input_ids"] for example in examples])return {"pixel_values": pixel_values,"conditioning_pixel_values": conditioning_pixel_values,"input_ids": input_ids,}
相关文章:
diffusers 源码待理解之处
一、训练DreamBooth时,相关代码的细节小计 ** class_labels timesteps 时,模型的前向传播怎么走?待深入去看 ** 利用class_prompt去生成数据,而不是instance_prompt class DreamBoothDataset(Dataset):"""A dat…...
正则表达式 详解,10分钟学会
大家好,欢迎来到停止重构的频道。 本期我们讨论正则表达式。 正则表达式是一种用于匹配和操作文本的工具,常用于文本查找、文本替换、校验文本格式等场景。 正则表达式不仅是写代码时才会使用,在平常使用的很多文本编辑软件,都…...

【排序算法】归并排序与快速排序:深入解析与比较
文章目录 1. 引言2. 归并排序(Merge Sort)3. 快速排序(Quick Sort)4. 归并排序与快速排序的比较5. 结论 1. 引言 排序算法是计算机科学中最基本且至关重要的概念之一。它们不仅是理解更复杂算法和数据结构的基石,而且…...

万字长文谈自动驾驶bev感知(一)
文章目录 prologuepaper listcamera bev :1. Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D2. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation3. BEVDet: High-Pe…...
)
cfa一级考生复习经验分享系列(十七)
考场经验: 1.本人在Prometric广州考试中心,提前一天在附近住下,地方比较好找,到了百汇广场北门,进去就可以看见电梯直达10楼。进去之后需要现场检查行程卡和健康码,然后会问最近你有没有发烧咳嗽等问题&…...

机器人活动区域 - 华为OD统一考试
OD统一考试 题解: Java / Python / C++ 题目描述 现有一个机器人,可放置于 M x N 的网格中任意位置,每个网格包含一个非负整数编号,当相邻网格的数字编号差值的绝对值小于等于 1 时机器人可以在网格间移动。 问题: 求机器人可活动的最大范围对应的网格点数目。 说明: 网格…...

三、HTML元素
一、HTML元素 HTML 文档由 HTML 元素定义。 *开始标签常被称为起始标签(opening tag),结束标签常称为闭合标签(closing tag)。 二、HTML 元素语法 HTML 元素以开始标签起始。HTML 元素以结束标签终止。元素的内容是…...

置顶> 个人学习记录一览
个人学习记录一览表 写个说明 知识学的好,不如笔记记得好,知识点的遗忘在所难免,这里记录我个人的学习过程,以备后面二次学习使用。 Linux 操作系统 Linux 操作系统 001-介绍 Linux 操作系统 002-VMware Workstation的相关操…...

c++重载操作符
支持重载操作符是c的一个特性,先不管好不好用,这起码能让它看起来比其他语言NB很多,但真正了解重载操作符后,就会发现这个特性...就这?本文分两个部分 重载操作符简介和使用——适用新手重载操作符的原理和sao操作——…...
C# 如何读取Excel文件
当处理Excel文件时,从中读取数据是一个常见的需求。通过读取Excel数据,可以获取电子表格中包含的信息,并在其他应用程序或编程环境中使用这些数据进行进一步的处理和分析。本文将分享一个使用免费库来实现C#中读取Excel数据的方法。具体如下&…...

Vue2面试题:说一下对vuex的理解?
五种状态: state: 存储公共数据 this.$store.state mutations:同步操作,改变store的数据 this.$store.commit() actions: 异步操作,让mutations中的方法能在异步操作中起作用 this.$store.dispatch() getters: 计算属性 th…...

elasticsearch系列五:集群的备份与恢复
概述 前几篇咱们讲了es的语法、存储的优化、常规运维等等,今天咱们看下如何备份数据和恢复数据。 在传统的关系型数据库中我们有多种备份方式,常见有热备、冷备、全量定时增量备份、通过开发程序备份等等,其实在es中是一样的。 官方建议采用s…...

【Elasticsearch源码】 分片恢复分析
带着疑问学源码,第七篇:Elasticsearch 分片恢复分析 代码分析基于:https://github.com/jiankunking/elasticsearch Elasticsearch 8.0.0-SNAPSHOT 目的 在看源码之前先梳理一下,自己对于分片恢复的疑问点: 网上对于E…...
elasticsearch如何操作索引库里面的文档
上节介绍了索引库的CRUD,接下来操作索引库里面的文档 目录 一、添加文档 二、查询文档 三、删除文档 四、修改文档 一、添加文档 新增文档的DSL语法如下 POST /索引库名/_doc/文档id(不加id,es会自动生成) { "字段1":"值1", "字段2&q…...
opencv期末练习题(2)附带解析
图像插值与缩放 %matplotlib inline import cv2 import matplotlib.pyplot as plt def imshow(img,grayFalse,bgr_modeFalse):if gray:img cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)plt.imshow(img,cmap"gray")else:if not bgr_mode:img cv2.cvtColor(img,cv2.COLOR_B…...

【Mybatis】深入学习MyBatis:高级特性与Spring整合
🍎个人博客:个人主页 🏆个人专栏: Mybatis ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 高级特性 1 一级缓存和二级缓存 一级缓存 二级缓存 2 延迟加载 5 整合Spring 1 MyBatis-Spring模块 2 事务管理 结…...

C语言与人生函数的对比,使用,参数详解
各位少年,大家好,我是博主那一脸阳光。,今天给大家分享函数的定义,和数学的函数的区别和使用 前言:C语言中的函数和数学中的函数在概念上有相似之处,但也存在显著的区别。下面对比它们的主要特点ÿ…...

机器人动力学一些笔记
动力学方程中,Q和q的关系(Q是sita) Q其实是一个向量,q(Q1,Q2,Q3,Q4,Q5,Q6)(假如6个关节) https://zhuanlan.zhihu.com/p/25789930 举个浅显易懂的例子,你在房…...
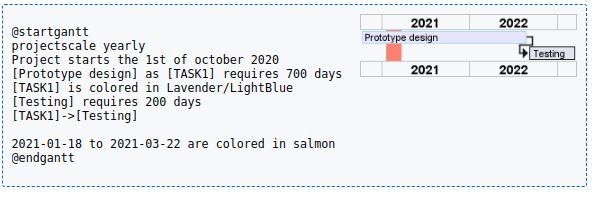
Plantuml之甘特图语法介绍(二十八)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
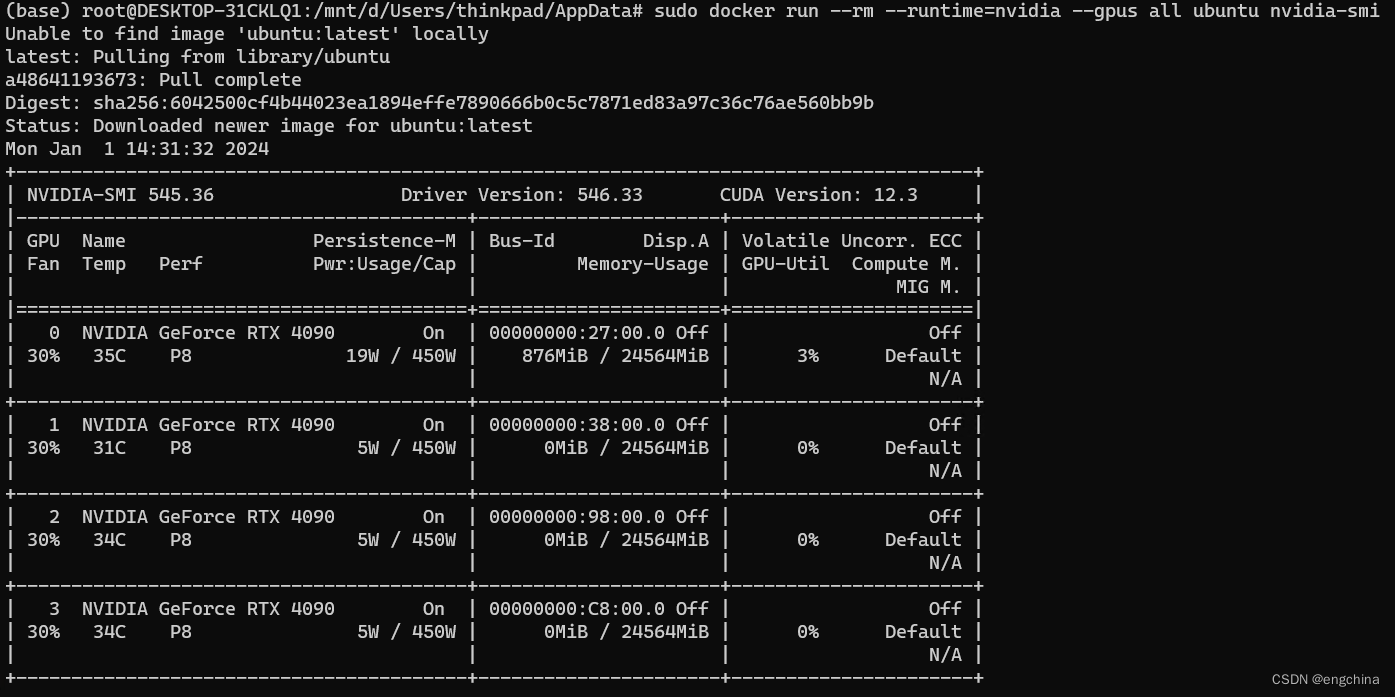
Docker support for NVIDIA GPU Accelerated Computing on WSL 2
Docker support for NVIDIA GPU Accelerated Computing on WSL 2 0. 背景1. 安装 Docker Desktop2. 配置 Docker Desktop3. WLS Ubuntu 配置4. 安装 Docker-ce5. 安装 NVIDIA Container Toolkit6. 配置 Docker7. 运行一个 Sample Workload 0. 背景 今天尝试一下 NVIDIA GPU 在…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...