Spark---RDD算子(单值类型Value)
文章目录
- 1.RDD算子介绍
- 2.转换算子
- 2.1 Value类型
- 2.1.1 map
- 2.1.2 mapPartitions
- 2.1.3 mapPartitionsWithIndex
- 2.1.4 flatMap
- 2.1.5 glom
- 2.1.6 groupBy
- 2.1.7 filter
- 2.1.8 sample
- 2.1.9 distinct
- 2.1.10 coalesce
- 2.1.11 repartition
- 2.1.12 sortBy
1.RDD算子介绍
RDD算子是用于对RDD进行转换(Transformation)或行动(Action)操作的方法或函数。通俗来讲,RDD算子就是RDD中的函数或者方法,根据其功能,RDD算子可以分为两大类:
转换算子(Transformation): 转换算子用于从一个RDD生成一个新的RDD,但是原始RDD保持不变。常见的转换算子包括map、filter、flatMap等,它们通过对RDD的每个元素执行相应的操作来生成新的RDD。
行动算子(Action): 行动算子触发对RDD的实际计算,并返回计算结果或将结果写入外部存储系统。与转换算子不同,行动算子会导致Spark作业的执行。如collect方法。
2.转换算子
RDD 根据数据处理方式的不同将算子整体上分为:
Value 类型:对一个RDD进行操作或行动,生成一个新的RDD。
双 Value 类型:对两个RDD进行操作或行动,生成一个新的RDD。
Key-Value类型:对键值对进行操作,如reduceByKey((x, y),按照key对value进行合并。
2.1 Value类型
2.1.1 map
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
函数定义
def map[U: ClassTag](f: T => U): RDD[U]
代码实现:
//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val mapRdd: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))//对mapRdd进行转换val mapRdd1 = mapRdd.map(num => num * 2)//对mapRdd1进行转换val mapRdd2 = mapRdd1.map(num => num + "->")mapRdd2.collect().foreach(print)sparkRdd.stop();//关闭连接

2.1.2 mapPartitions
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。
函数定义
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作。
mapPartitions在处理数据的时候因为是批处理,相对于map来说处理效率较高,但是如果数据量较大的情况下使用mapPartitions可能会造成内存溢出,因为mapPartitions会将分区内的数据全部加载到内存中。此时更推荐使用map。
2.1.3 mapPartitionsWithIndex
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
函数定义
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
实现只保留第二个分区的数据
val mapRdd: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4),2)val newRdd: RDD[Int] = mapRdd.mapPartitionsWithIndex((index, iterator) => {if (index == 1) iteratorelse Nil.iterator})newRdd.collect().foreach(println)
2.1.4 flatMap
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
//建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val rdd1: RDD[List[Int]] = sparkRdd.makeRDD(List(List(1, 2), List(3, 4)))val rdd2: RDD[String] = sparkRdd.makeRDD(List("Hello Java", "Hello Scala"), 2)val frdd1: RDD[Int] =rdd1.flatMap(list=>{list})val frdd2: RDD[String] =rdd2.flatMap(str=>str.split(" "))frdd1.collect().foreach(println)frdd2.collect().foreach(println)sparkRdd.stop();//关闭连接

2.1.5 glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变,glom函数的作用就是将一组数据转换为数组。
函数定义
def glom(): RDD[Array[T]]
/建立与Spark框架的连接val rdd = new SparkConf().setMaster("local[*]").setAppName("RDD") //配置文件val sparkRdd = new SparkContext(rdd) //读取配置文件val rdd1: RDD[Any] = sparkRdd.makeRDD(List(1,2,3,4),2)val value: RDD[Array[Any]] = rdd1.glom()value.collect().foreach(data=> println(data.mkString(",")))sparkRdd.stop();//关闭连接

2.1.6 groupBy
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。 极限情况下,数据可能被分在同一个分区中
函数定义
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
//按照奇偶分组val rdd1: RDD[Int] = sparkRdd.makeRDD(List(1,2,3,4),2)val value = rdd1.groupBy(num => num % 2)value.collect().foreach(println)//将 List("Hello", "hive", "hbase", "Hadoop")根据单词首写字母进行分组。val rdd2: RDD[String] = sparkRdd.makeRDD(List("Hello", "hive", "hbase", "Hadoop"))val value1: RDD[(Char, Iterable[String])] = rdd2.groupBy(str => {str.charAt(0)})value1.collect().foreach(println)

2.1.7 filter
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。
函数定义
def filter(f: T => Boolean): RDD[T]
//获取偶数val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4), 1)val value1 = dataRDD.filter(_ % 2 == 0)
2.1.8 sample
函数定义
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
根据指定的规则从数据集中抽取数据
参数具体意义:
1.抽取数据不放回withReplacement: Boolean, 该参数表示抽取不放回,此时采用伯努利算法(false)fraction: Double,该参数表示抽取的几率,范围在[0,1]之间,0:全不取;1:全取;seed: Long = Utils.random.nextLong): RDD[T] 该参数表示随机数种子2.抽取数据放回withReplacement: Boolean, 该参数表示抽取放回,此时采用泊松算法(true)fraction: Double,该参数表示重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数seed: Long = Utils.random.nextLong): RDD[T] 该参数表示随机数种子
2.1.9 distinct
将数据集中重复的数据去重
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 6)val value = dataRDD.distinct()

2.1.10 coalesce
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本
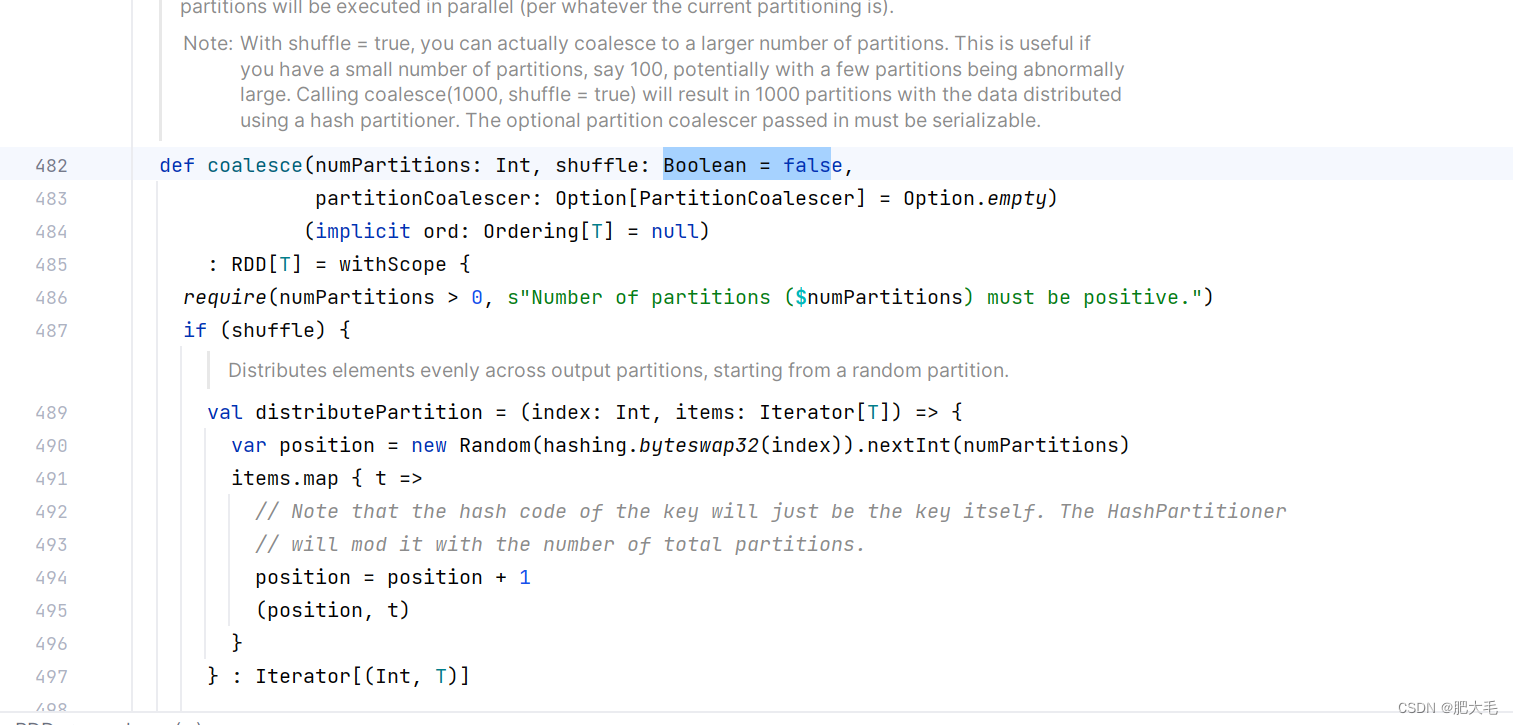
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]
//初始Rdd采用6个分区val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 6)//将分区数量缩减至2个val value = dataRDD.coalesce(2)
在coalesce中默认不开启shuffle,在进行分区缩减的时候,数据不会被打散。
2.1.11 repartition
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
repartition内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition操作都可以完成,因为无论如何都会经 shuffle 过程。
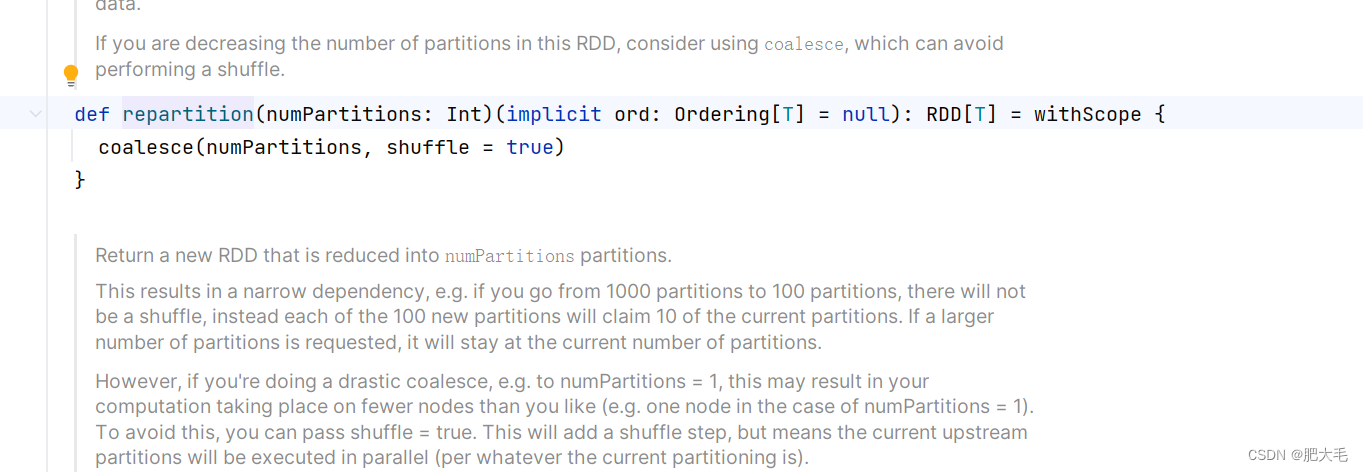
//将分区数量从2个提升至4个val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 2)val dataRDD1 = dataRDD.repartition(4)
2.1.12 sortBy
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。中间存在 shuffle 的过程
def sortBy[K](
f: (T) => K, 该参数表述用于处理的函数
ascending: Boolean = true, 该参数表示是否升序排序
numPartitions: Int = this.partitions.length) 该参数表示设置分区数量
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
val dataRDD = sparkRdd.makeRDD(List(1, 2, 3, 4, 1, 2), 2)//按照初始数据降序排列val dataRDD1 = dataRDD.sortBy(num => num, false, 4)
相关文章:
Spark---RDD算子(单值类型Value)
文章目录 1.RDD算子介绍2.转换算子2.1 Value类型2.1.1 map2.1.2 mapPartitions2.1.3 mapPartitionsWithIndex2.1.4 flatMap2.1.5 glom2.1.6 groupBy2.1.7 filter2.1.8 sample2.1.9 distinct2.1.10 coalesce2.1.11 repartition2.1.12 sortBy 1.RDD算子介绍 RDD算子是用于对RDD进…...

数据库中的MVCC--多版本并发控制
一、前言 1、定义:MVCC(Multi-Version Concurrency Control),多版本并发控制,主要为了提高数据库 的并发性能。是MySQL的InnoDB存储引擎实现隔离级别的一种具体方式。用于实现提交读和可重 复读这两种隔离级别。 2…...

wps将姓名处理格式为:姓**
1.打开wps,在要处理数据右侧一个单元格 输入公式:LEFT(A1,1)&"**",然后回车 2.按住ctrl和处理好的数据的右下角小方框,往下拖动即可生成格式为:姓** 格式的数据 3.复制生成的数据,右键选择 “…...

2023年我的编程之旅:技术演进与自我成长的纪录
2023年我的编程之旅:技术演进与自我成长的纪录 转眼间,2023年已经悄然走到了尾声。这一年,对我来说既是挑战也是机遇的一年。我的编程之旅如同坐上了一辆高速前进的列车,从新技术的学习探索到项目实战的沉浸经历,再到…...
好用免费的WAF---如何安装雷池社区版
什么是雷池 雷池(SafeLine)是长亭科技耗时近 10 年倾情打造的 WAF,核心检测能力由智能语义分析算法驱动。 Slogan: 不让黑客越雷池半步。 什么是 WAF WAF 是 Web Application Firewall 的缩写,也被称为 Web 应用防火墙。 …...

看似 bug 又非 bug 的一个 bug
最近的一个项目中,对于 CSS 的一些属性一些选择符可以大胆使用,然后很意外得撞上一个 iOS 中 Safari 的一个解析问题。 <Component style{{height: "calc(100vh - 46px)"}}>一个组件</Component> 这样的一段代码很简单ÿ…...

mysql常见问题
批量导入SQL 数据库结构 数据时,如果数据是批量插入的话会报错:2006 - MySQL server has gone away。 解决办法:找到你的 mysql 目录下的 my.ini 配置文件,加入以下代码 max_allowed_packet500M wait_timeout288000 interactiv…...
QT上位机开发(串口界面设计)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 如果上位机要和嵌入式设备进行打交道的话,那么串口可能就是我们遇到的第一个硬件设备。串口的物理接线很简单,基本上就是收…...

k8s之pod
1、pod:k8s中最小的资源管理组件,最小化运行容器化应用的资源管理对象 (1)pod是一个抽象的概念,可以理解为一个或者多个容器化应用的集合 (2)一个pod中运行一个容器是最常用的方式 ÿ…...

第二百四十三回 再分享一个Json工具
文章目录 1. 概念介绍2. 分析与比较2.1 分析问题2.2 比较差异 3. 使用方法4. 内容总结 我们在上一章回中介绍了"分享三个使用TextField的细节"相关的内容,本章回中将再 分享一个Json插件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我…...
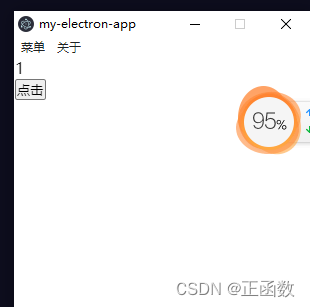
electron自定义菜单
创建menu.js const { app, Menu } require("electron"); const createMenu () > {const menu [{label: "菜单",submenu: [{label: "新增",click: () > {},}, ],},{label: "关于",submenu: [{label: "新增",click:…...
)
变量和函数提升(js的问题)
• js解释执行 • 变量和函数提升 变量声明提前,函数声明提前 • 变量声明提前:值停留在本地 • 函数声明提前:整个函数体提前 如果是var赋值声明的函数,变量提前,函数体停留在本地 1、变量提…...
Excel 插件:ASAP Utilities Crack
ASAP Utilities是一款功能强大的 Excel 插件,填补了 Excel 的空白。在过去的 20 年里,我们的加载项已经发展成为世界上最受欢迎的 Microsoft Excel 加载项之一。 ASAP Utilities 中的功能数量(300 多个)可能看起来有点令人眼花缭乱…...

hyperf 十九 数据库 二 模型
教程:Hyperf 一、命令行 symfony/console-CSDN博客 hypery 十一、命令行-CSDN博客 hyperf console 执行-CSDN博客 根据之前应该能了解到命令行的基本实现,和hyperf中命令行的定义。 1.1 命令初始化 hyperf.php中系统初始化中通过ApplicationFacto…...
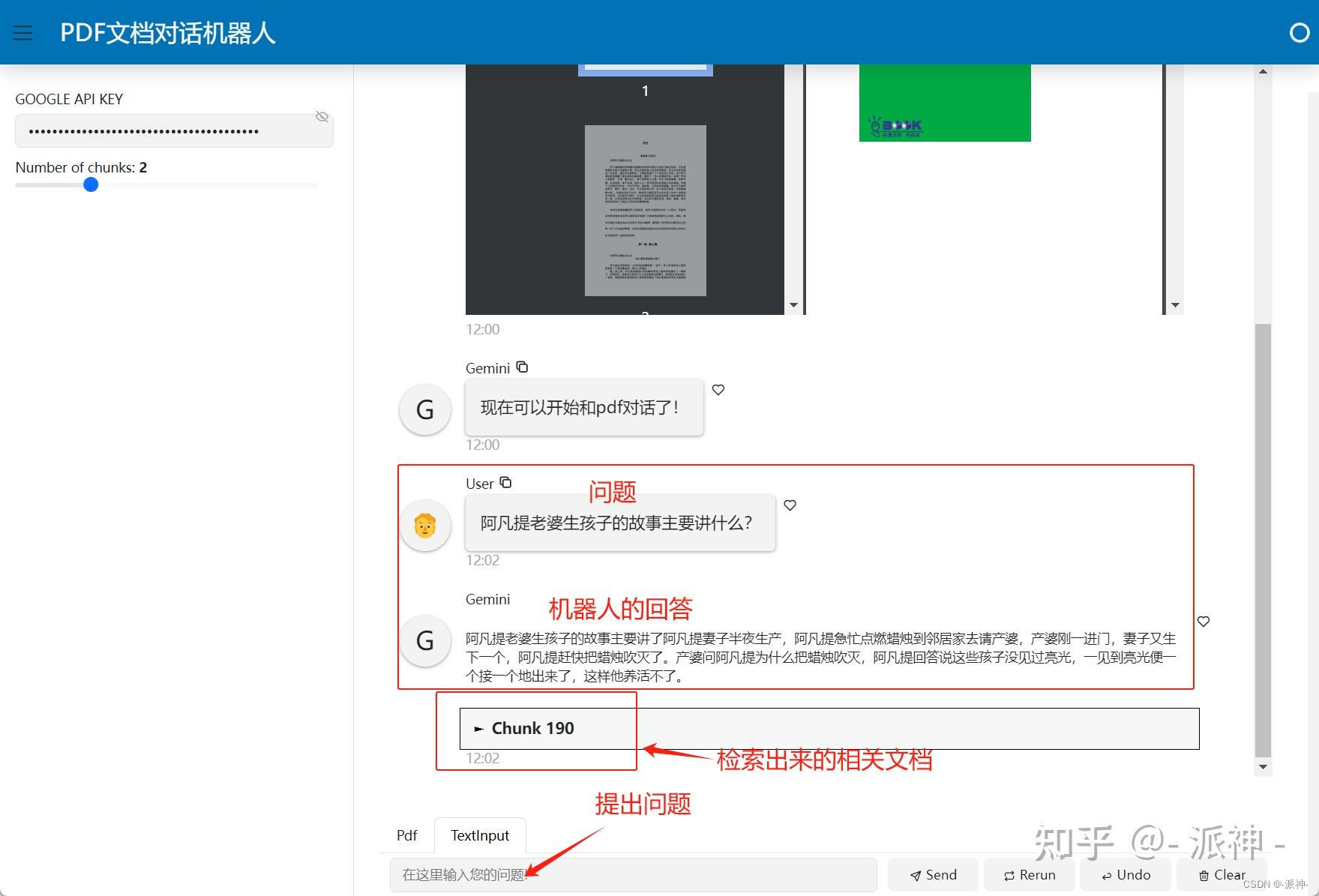
使用python快速开发与PDF文档对话的Gemini聊天机器人
检索增强生成(Retrieval-augmented generation,RAG)使得我们可以让大型语言模型(LLMs)访问外部知识库数据(如pdf,word、text等),从而让人们可以更加方便的通过LLM来学习外部数据的知识。今天我们将利用之前学习到的RAG方法,谷歌Gemini模型和l…...
Spring Cloud Gateway集成Knife4j
1、前提 网关路由能够正常工作。 案例 基于 Spring Cloud Gateway Nacos 实现动态路由拓展的参考地址:Spring Cloud Gateway Nacos 实现动态路由 详细官网案例:https://doc.xiaominfo.com/docs/middleware-sources/spring-cloud-gateway/spring-gatewa…...

Hive10_窗口函数
窗口函数(开窗函数) 1 相关函数说明 普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。简单理解,就是对查询的结果多出一列…...

ipvsadm命令详解
ipvsadm命令详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨一个在Linux系统网络管理中极具威力的命令——ipvsadm,通过详细解析…...
zabbix通过自动发现-配置监控项、触发器(小白教程)
自动发现配置参考链接(不小白,不友好) zabbix-get介绍 1配置 zabbix server:版本7(不影响),IP地址:192.168.0.60zabbix agent:版本agent1(不影响)ÿ…...

Dockerfile文件介绍
0 Preface/Foreword 0.1 Docker docker用来自制镜像。 1 Introduction 1.1 Dockerfile Dockerfile是用于定义Docker镜像的构建过程,它包含一系列的指令用于安装 软件包、配置环境等操作。 Dockerfile文件的格式如下: FROM base_image RUN apt-get up…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...