Spark SQL 学习总结
文章目录
- (一)Spark SQL
- (二)SParkSession
- (三)DataFrame常见算子操作
- (四)DataFrame的sql操作
- (五)RDD转换为DataFrame
- (1)反射方式
- (2)编程方式
- (六)load和save操作
- (1)load操作
- (2)SaveMode
- (七)内置函数
(一)Spark SQL
Spark SQL和我们之前讲Hive的时候说的hive on spark是不一样的。
hive on spark是表示把底层的mapreduce引擎替换为spark引擎。
而Spark SQL是Spark自己实现的一套SQL处理引擎。
Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。
DataFrame=RDD+Schema 。
它其实和关系型数据库中的表非常类似,RDD可以认为是表中的数据,Schema是表结构信息。
DataFrame可以通过很多来源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD
Spark1.3出现的 DataFrame ,Spark1.6出现了 DataSet ,在Spark2.0中两者统一,DataFrame等于DataSet[Row]
(二)SParkSession
要使用Spark SQL,首先需要创建一个SpakSession对象
SparkSession中包含了SparkContext和SqlContext
所以说想通过SparkSession来操作RDD的话需要先通过它来获取SparkContext
这个SqlContext是使用sparkSQL操作hive的时候会用到的。
使用案例
添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
object SqlDemoScala {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local")val sparkSession=SparkSession.builder().appName("sqlDemoScala").config(conf).getOrCreate()//读取json文件,获取Dataframeval stuDf = sparkSession.read.json("D:\\student.json")//查看Dataframe中的数据stuDf.show()sparkSession.stop()}}
结果:
+---+------+------+
|age| name| sex|
+---+------+------+
| 19| jack| male|
| 18| tom| male|
| 27|jessic|female|
| 18| hehe|female|
| 15| haha| male|
+---+------+------+
(三)DataFrame常见算子操作
- printSchema()
- show()
- select()
- filter()、where()
- groupBy()
- count()
使用案例
object DataFrameOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("DataFrameOpScala")
.config(conf)
.getOrCreate()val stuDf = sparkSession.read.json("D:\\student.json")
//打印schema信息
stuDf.printSchema()
//默认显示所有数据,可以通过参数控制显示多少条
stuDf.show(2)
//查询数据中的指定字段信息
stuDf.select("name","age").show()
//在使用select的时候可以对数据做一些操作,需要添加隐式转换函数,否则语法报错
import sparkSession.implicits._
stuDf.select($"name",$"age" + 1).show()
//对数据进行过滤,需要添加隐式转换函数,否则语法报错
stuDf.filter($"age">18).show()
//where底层调用的就是filter
stuDf.where($"age">18).show()
//对数据进行分组求和
stuDf.groupBy("age").count().show()
sparkSession.stop()
}
}
(四)DataFrame的sql操作
想要实现直接支持sql语句查询DataFrame中的数据
需要两步操作
- 先将DataFrame注册为一个临时表
- 使用sparkSession中的sql函数执行sql语句
案例实现:
object DataFrameSqlScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("DataFrameSqlScala")
.config(conf)
.getOrCreate()
val stuDf = sparkSession.read.json("D:\\student.json")
//将DataFrame注册为一个临时表
stuDf.createOrReplaceTempView("student")
//使用sql查询临时表中的数据
sparkSession.sql("select age,count(*) as num from student group by age")
.show()
sparkSession.stop()
}
}
(五)RDD转换为DataFrame
为什么要将RDD转换为DataFrame?
在实际工作中我们可能会先把hdfs上的一些日志数据加载进来,然后进行一些处理,最终变成结构化的数据,希望对这些数据做一些统计分析,当然了我们可以使用spark中提供transformation算子来实现,只不过会有一些麻烦,毕竟是需要写代码的,如果能够使用sql实现,其实是更加方便的。所以可以针对我们前面创建的RDD,将它转换为DataFrame,这样就可以使用dataFrame中的一些算子或者直接写sql来操作数据了。
Spark SQL支持这两种方式将RDD转换为DataFrame
- 反射方式
- 编程方式
(1)反射方式
这种方式是使用反射来推断RDD中的元数据。
基于反射的方式,代码比较简洁,也就是说当你在写代码的时候,已经知道了RDD中的元数据,这样的话使用反射这种方式是一种非常不错的选择。
Scala具有隐式转换的特性,所以spark sql的scala接口是支持自动将包含了case class的RDD转换为DataFrame的
下面来举一个例子:
object RddToDataFrameByReflectScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("RddToDataFrameByReflectScala")
.config(conf)
.getOrCreate()
//获取SparkContext
val sc = sparkSession.sparkContext
val dataRDD = sc.parallelize(Array(("jack",18),("tom",20),("jessic",30)))
//基于反射直接将包含Student对象的dataRDD转换为DataFrame
//需要导入隐式转换
import sparkSession.implicits._
val stuDf = dataRDD.map(tup=>Student(tup._1,tup._2)).toDF()
//下面就可以通过DataFrame的方式操作dataRDD中的数据了
stuDf.createOrReplaceTempView("student")
//执行sql查询
val resDf = sparkSession.sql("select name,age from student where age > 18
//将DataFrame转化为RDD
val resRDD = resDf.rdd
//从row中取数据,封装成student,打印到控制台
resRDD.map(row=>Student(row(0).toString,row(1).toString.toInt))
.collect()
.foreach(println(_))
//使用row的getAs()方法,获取指定列名的值
resRDD.map(row=>Student(row.getAs[String]("name"),row.getAs[Int]("age")))
.collect()
.foreach(println(_))
sparkSession.stop()
}
}
//定义一个Student
case class Student(name: String,age: Int)(2)编程方式
接下来是编程的方式
这种方式是通过编程接口来创建DataFrame,你可以在程序运行时动态构建一份元数据,就是Schema,然后将其应用到已经存在的RDD上。这种方式的代码比较冗长,但是如果在编写程序时,还不知道RDD的元数据,只有在程序运行时,才能动态得知其元数据,那么只能通过这种动态构建元数据的方式。
也就是说当case calss中的字段无法预先定义的时候,就只能用编程方式动态指定元数据了
案例:
object RddToDataFrameByProgramScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("RddToDataFrameByProgramScala")
.config(conf)
.getOrCreate()
//获取SparkContext
val sc = sparkSession.sparkContext
val dataRDD = sc.parallelize(Array(("jack",18),("tom",20),("jessic",30)))
//组装rowRDD
val rowRDD = dataRDD.map(tup=>Row(tup._1,tup._2))
//指定元数据信息【这个元数据信息就可以动态从外部获取了,比较灵活】
val schema = StructType(Array(
StructField("name",StringType,true),
StructField("age",IntegerType,true)
))
//组装DataFrame
val stuDf = sparkSession.createDataFrame(rowRDD,schema)
//下面就可以通过DataFrame的方式操作dataRDD中的数据了
stuDf.createOrReplaceTempView("student")
//执行sql查询
val resDf = sparkSession.sql("select name,age from student where age > 18
//将DataFrame转化为RDD
val resRDD = resDf.rdd
resRDD.map(row=>(row(0).toString,row(1).toString.toInt))
.collect()
.foreach(println(_))
sparkSession.stop()
}
}
(六)load和save操作
对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。
load操作主要用于加载数据,创建出DataFrame;
save操作,主要用于将DataFrame中的数据保存到文件中。
(1)load操作
我们前面操作json格式的数据的时候好像没有使用load方法,而是直接使用的json方法,这是什么特殊用法吗?
查看json方法的源码会发现,它底层调用的是format和load方法
注意:如果看不到源码,需要点击idea右上角的download source提示信息下载依赖的源码。
此时如果不指定format,则默认读取的数据源格式是parquet,也可以手动指定数据源格式。Spark SQL
内置了一些常见的数据源类型,比如json, parquet, jdbc, orc, csv, text
通过这个功能,就可以在不同类型的数据源之间进行转换了。
案例:
object LoadAndSaveOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpScala")
.config(conf)
.getOrCreate()
//读取数据
val stuDf = sparkSession.read
.format("json")
.load("D:\\student.json")
//保存数据
stuDf.select("name","age")
.write
.format("csv")
.save("hdfs://bigdata01:9000/out-save001")
sparkSession.stop()
}
}
执行代码,查看结果,csv文件是使用逗号分隔的:
jack,19
tom,18
jessic,27
hehe,18
haha,15
(2)SaveMode
Spark SQL对于save操作,提供了不同的save mode。
主要用来处理,当目标位置已经有数据时应该如何处理。save操作不会执行锁操作,并且也不是原子的,因此是有一定风险出现脏数据的。
SaveMode 解释
SaveMode.ErrorIfExists (默认) 如果目标位置已经存在数据,那么抛出一个异常
SaveMode.Append 如果目标位置已经存在数据,那么将数据追加进去
SaveMode.Overwrite 如果目标位置已经存在数据,那么就将已经存在的数据删
SaveMode.Ignore 如果目标位置已经存在数据,那么就忽略,不做任何操作
在LoadAndSaveOpScala中增加SaveMode的设置,重新执行,验证结果将SaveMode设置为Append,如果目标已存在,则追加
(七)内置函数
Spark提供了很多内置函数
种类 函数
聚合函数 avg, count, countDistinct, first, last, max, mean, min, sum,
集合函数 array_contains, explode, size
日期/时间函数 datediff, date_add, date_sub, add_months, last_day, next_day,
数学函数 abs, ceil, floor, round
混合函数 if, isnull, md5, not, rand, when
字符串函数 concat, get_json_object, length, reverse, split, upper
窗口函数 denseRank, rank, rowNumber
其实这里面的函数和hive中的函数是类似的
注意:SparkSQL中的SQL函数文档不全,其实在使用这些函数的时候,大家完全可以去查看hive中sql的文档,使用的时候都是一样的。
相关文章:

Spark SQL 学习总结
文章目录(一)Spark SQL(二)SParkSession(三)DataFrame常见算子操作(四)DataFrame的sql操作(五)RDD转换为DataFrame(1)反射方式&#x…...

深度学习 - 37.TF x Keras Deep Cross Network DCN 实现
目录 一.引言 二.模型简介 1.Embedding and stacking layer 2.Cross Network 2.1 模型架构分析 2.2 计算逻辑...
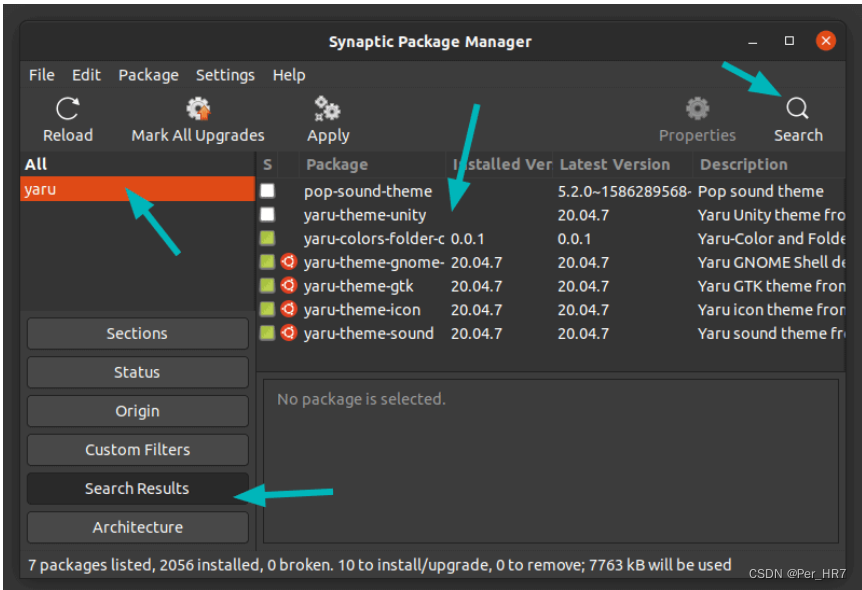
Ubuntu中使用Synaptic进行包管理
Synaptic概况 Synaptic 是一个轻量级的 apt 软件包管理器系统的 GUI 前端,所有你可以在终端中使用 apt-get 命令来做的事,都可以通过 Synaptic 来实现。优势 图形化安装界面,同时可以安装配置相关依赖,避免由于依赖问题导致的各类…...

python之selenium库安装及用法(定位法、获取文本、文本框输入、鼠标点击、滑动滚动条)
一、selenium库安装 pip install selenium二、浏览器驱动安装 谷歌浏览器驱动下载地址:https://chromedriver.storage.googleapis.com/index.html 根据你电脑的谷歌浏览器版本,下载相应的就行。我下载的是110.0.5481.XX中的chromedriver_win32.zip 下载…...

FPGA纯verilog实现图像视频旋转 串口指令控制旋转角度 提供工程源码和技术支持
目录1、前言2、理论基础3、设计思路和框架图像输入和采集图像旋转处理图像缓存图像输出4、vivado工程详解5、上板调试验证6、福利:工程代码的获取1、前言 图像旋转是一种常用的图像处理技术,其基本原理就是指图像以某一点为中心旋转一定的角度ÿ…...

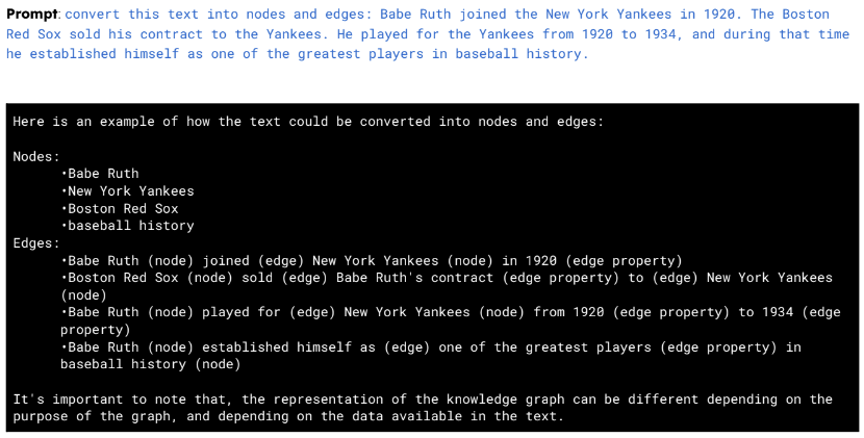
EventGraph:Event Extraction as Semantic Graph Parsing 论文解读
EventGraph: Event Extraction as Semantic Graph Parsing 论文:2022.case-1.2.pdf (aclanthology.org) 代码:huiling-y/EventGraph (github.com) 期刊/会议:CASE 2022 摘要 事件抽取涉及到事件触发词和相应事件论元的检测和抽取。现有系…...

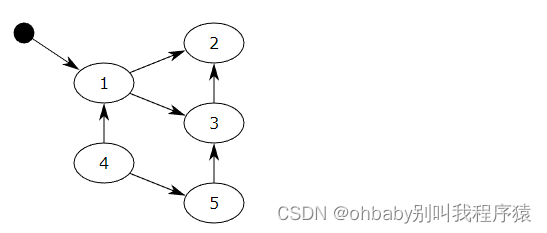
【蓝桥杯集训·每日一题】AcWing 3696. 构造有向无环图
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴拓扑排序一、题目 1、原题链接 3696. 构造有向无环图 2、题目描述 给定一个由 n 个点和 m 条边构成的图。 不保证给定的图是连通的。 图中的一部分边的方向已经确定&#…...
国内vs国外:外贸建站该如何选择?
外贸建站找国内还是国外? 答案是:国内。 随着互联网的发展,越来越多的企业开始意识到在网络上进行商业活动的重要性。 其中,建立一个专业的外贸网站是企业在国际市场上拓展业务的关键。 然而,对于选择国内还是国外…...

HLS协议有哪些特别优势
阿酷TONY / 2023-3-3 / 长沙 可以实现码率的动态自适应,清晰度动态成为可能;HLS是基于HTTP 协议的,更易于做各平台的适配与兼容;多终端跨平台的支持性: PC端, Android端, IOS 平台,微信之类的都支持&am…...

JavaScript里的回调函数属于闭包吗?
回调函数本身不一定属于闭包,但是在某些情况下,它们可能会涉及闭包。 回调函数通常是指在异步操作完成时执行的函数。它们在 JavaScript 中被广泛使用,例如在处理 AJAX 请求、定时器、事件处理程序等方面。 在使用回调函数时,如…...
编程基本概念
程序的构成 python程序由模块组成,一个模块对应一个python源文件,后缀为.py模块由语句组成,运行python程序时,按照模块中的语句顺序依次执行语句是python程序的构造单元,用于创建对象,变量赋值,…...
Azure OpenAI 官方指南02|ChatGPT 的架构设计与应用实例
ChatGPT 作为即将在微软全球 Azure 公有云平台正式发布的服务,已经迅速成为了众多用户关心的服务之一。而由 OpenAI 发布的 ChatGPT 产品,仅仅上线两个月,就成为互联网历史上最快突破一亿月活的应用。本期从技术角度深度解析 ChatGPT 的架构设…...
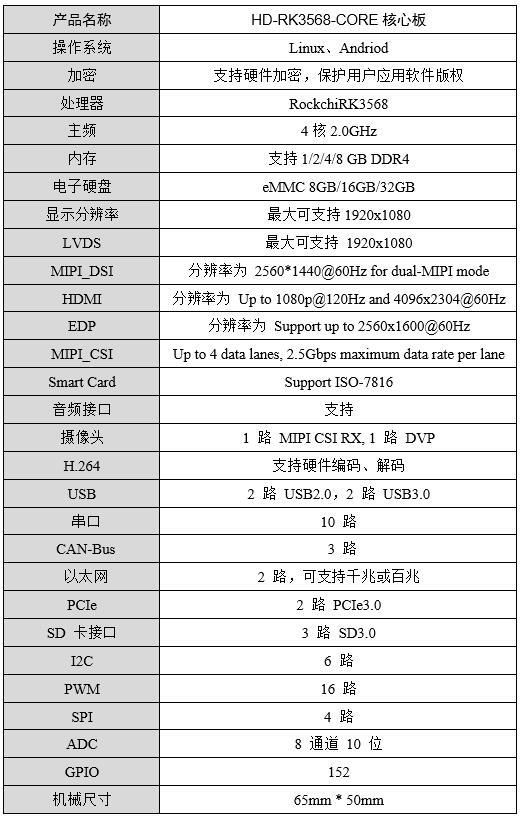
RK3568核心板以太网大数据测试报告-万象奥科
1. 测试对象HD-RK3568-IOT 底板基于HD-RK3568-CORE工业级核心板设计(双网口、双CAN、5路串口),接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。适用于工业自动化控制、人机界面、中小型医疗分析器…...

来 CSDN 三年,我写了一本Python书
大家好,我是朱小五。转眼间已经来 CSDN 3年了,其中给大家一共分享了252篇Python文章。 但这三年,最大的收获还是写了一本Python书! 在这个自动化时代,我们有很多重复无聊的工作要做。想想这些你不再需要一次又一次地做…...
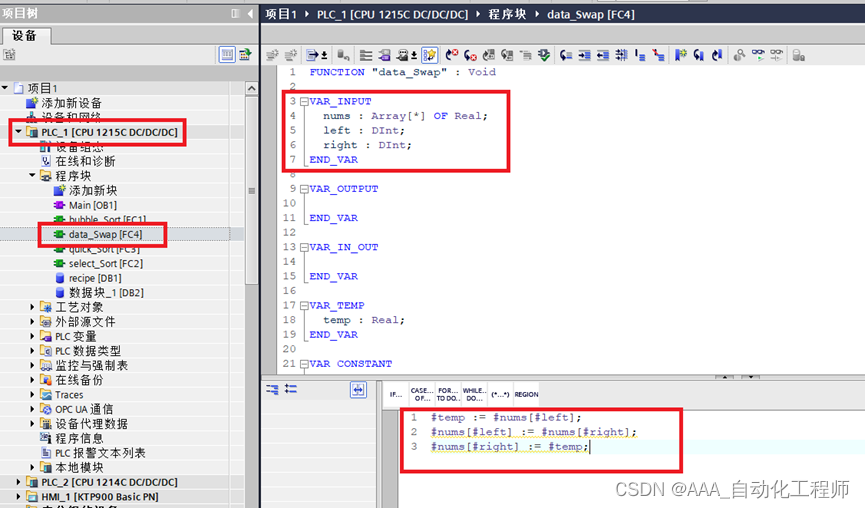
TIA博途中通过SCL语言实现快速排序的具体方法示例
TIA博途中通过SCL语言实现快速排序的具体方法示例 首先,了解一下快速排序的原理: 排序算法的思想非常简单,在待排序的数列中,我们首先要找一个数字作为基准数。为了方便,我们一般选择第 1 个数字作为基准数(其实选择第几个并没有关系)。接下来我们需要将这个待排序的数列…...

第 46 届世界技能大赛浙江省选拔赛“网络安全“项目B模块任务书
第46届世界技能大赛浙江省选拔赛"网络安全"项目B模块(网络安全事件响应、数字取证调查)第46届世界技能大赛浙江省选拔赛"网络安全"项目B模块2.1 第一部分 事件响应2.2 第二部分 数字取证调查2.3 第三部分 应用程序安全第46届世界技能…...

【C】字符串操作函数
初始化字符串 #include <string.h>void *memset(void *s, int c, size_t n); 返回值:s指向哪,返回的指针就指向哪memset函数把s所指的内存地址开始的n个字节都填充为c的值。通常c的值为0,把一块内存区清零。例如定义char buf[10];&…...

【python】 pytest自动化测试框架--selenium,requests,appium自动化工具
一、pytest简介 pytest是python的一种单元测试框架,与python自带的unittest测试框架类似,但是比unittest框架使用起来更简洁,效率更高 二、 pytest 单元测试框架 1、pytest 特点 pytest是python当中的一个单元框架,比unittest更灵…...
Spring boot 实战指南(三):配置事务,整合Elasticsearch、swagger、redis、rabbitMQ
文章目录一、配置事务依赖使用注解二、Elasticsearch创建项目配置maven完善依赖es连接配置实体映射repositoryservicecontroller三、swagger依赖启动类路径匹配配置配置类controller注解四、redis(代码实现)依赖yml配置配置类封装redisTamplate五、rabbi…...
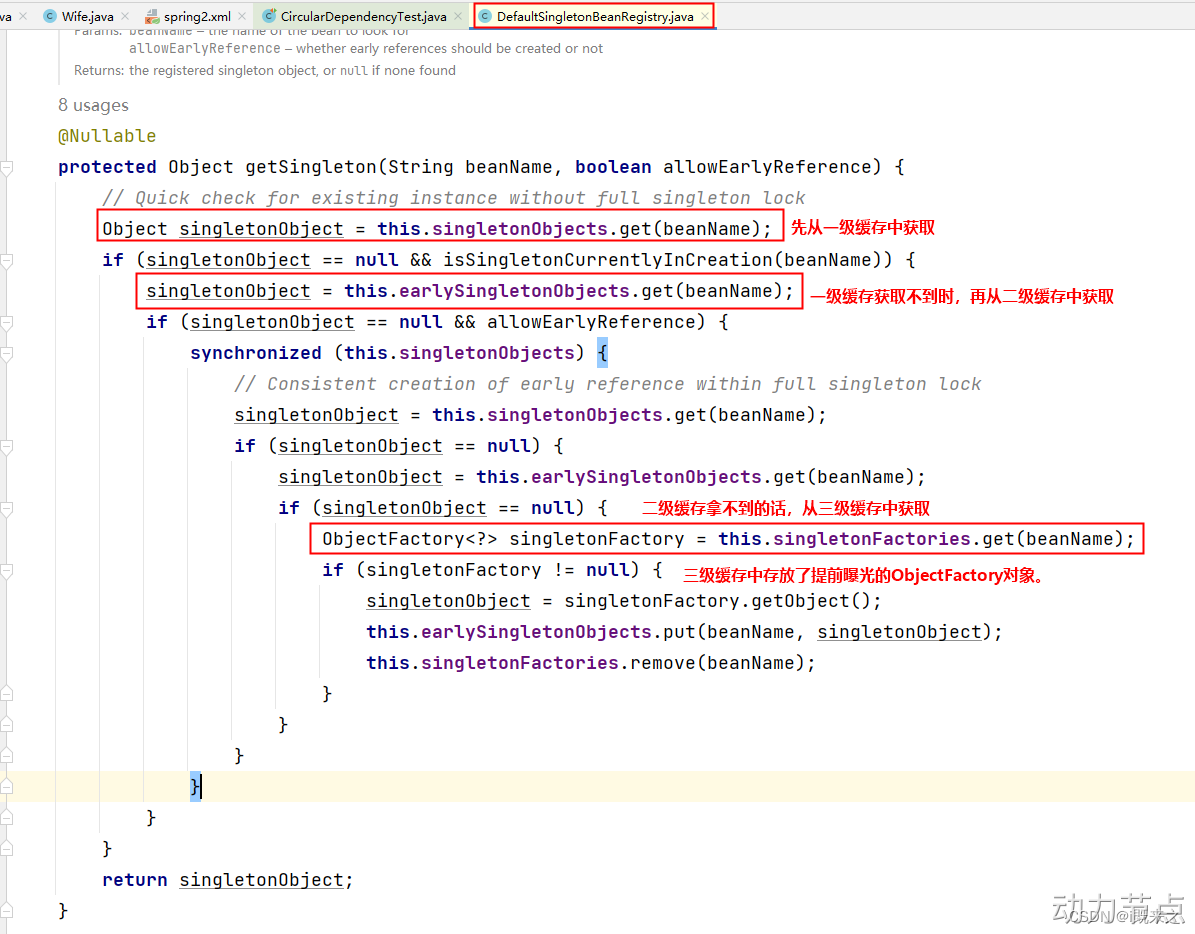
九、Bean的循环依赖问题
1 什么是Bean的循环依赖 A对象中有B属性。B对象中有A属性。这就是循环依赖。我依赖你,你也依赖我。 比如:丈夫类Husband,妻子类Wife。Husband中有Wife的引用。Wife中有Husband的引用。 2 singleton下的set注入产生的循环依赖 丈夫类 pac…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...
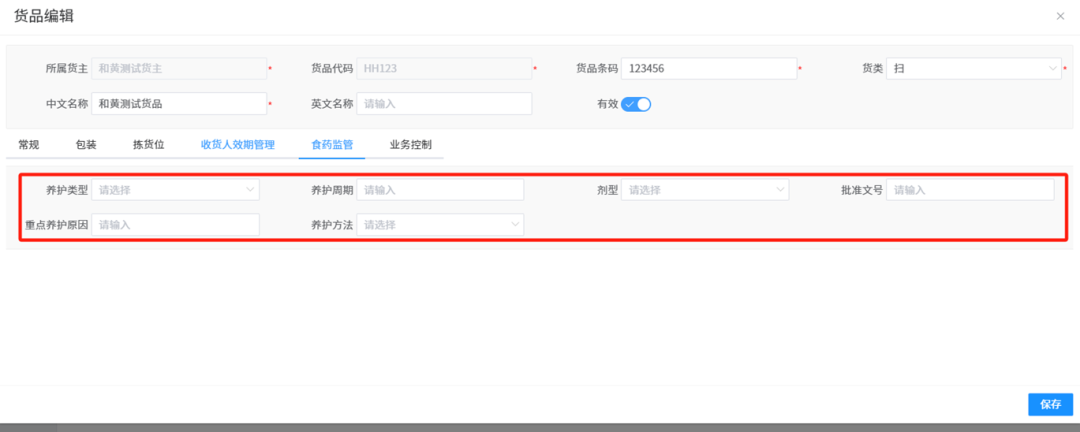
针对药品仓库的效期管理问题,如何利用WMS系统“破局”
案例: 某医药分销企业,主要经营各类药品的批发与零售。由于药品的特殊性,效期管理至关重要,但该企业一直面临效期问题的困扰。在未使用WMS系统之前,其药品入库、存储、出库等环节的效期管理主要依赖人工记录与检查。库…...