python爬虫--beautifulsoup模块简介
BeautifulSoup 的引入
我们学习了正则表达式的相关用法,但是一旦正则写的有问题,可能得到的就不是我们想要的结果了,而且对于一个网页来说,都有一定的特殊的结构和层级关系,而且很多标签都有 id 或 class 来对作区分,所以我们借助于它们的结构和属性来提取不也是可以的吗?
所以,这一节我们就介绍一个强大的解析工具,叫做 BeautiSoup,它就是借助网页的结构和属性等特性来解析网页的工具,有了它我们不用再去写一些复杂的正则,只需要简单的几条语句就可以完成网页中某个元素的提取。
废话不多说,接下来我们就来感受一下 BeautifulSoup 的强大之处吧。
BeautifulSoup 简介
简单来说,BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据,官方的解释如下:
BeautifulSoup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。BeautifulSoup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。BeautifulSoup 已成为和 lxml、html6lib 一样出色的 python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
所以说,利用它我们可以省去很多繁琐的提取工作,提高解析效率。
BeautifulSoup 的安装
使用之前,我们当然需要首先说明一下它的安装方式。目前 BeautifulSoup 的最新版本是 4.x 版本,之前的版本已经停止开发了,推荐使用 pip 来安装,安装命令如下:
pip install beautifulsoup4
好,安装完成之后可以验证一下,写一段 Python 程序试验一下。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>', 'html.parser')print(soup.p.string)
运行结果
Hello
如果没有报错,则证明安装没有问题。
解析器:
BeautifulSoup 在解析的时候实际上是依赖于解析器的,它除了支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器比如 lxml,下面我们对 BeautifulSoup 支持的解析器及它们的一些优缺点做一个简单的对比。
解析器使用方法优势劣势
Python 标准库 BeautifulSoup (markup, "html.parser") Python 的内置标准库、执行速度适中 、文档容错能力强 Python 2.7.3 or 3.2.2) 前的版本中文容错能力差
lxml HTML 解析器 BeautifulSoup (markup, "lxml") 速度快、文档容错能力强需要安装 C 语言库
lxml XML 解析器 BeautifulSoup (markup, "xml") 速度快、唯一支持 XML 的解析器需要安装 C 语言库
html5libBeautifulSoup (markup, "html5lib") 最好的容错性、以浏览器的方式解析文档、生成 HTML5 格式的文档速度慢、不依赖外部扩展
所以通过以上对比可以看出,lxml 这个解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强,所以推荐使用这个库来进行解析,但是这里的劣势是必须安装一个 C 语言库,它叫做 lxml,我们在这里依然使用 pip 安装即可,命令如下:
pip3 install lxml
安装完成之后,我们就可以使用 lxml 这个解析器来解析了,在初始化的时候我们可以把第二个参数改为 lxml,如下:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>', 'lxml')
print(soup.p.string)
运行结果是完全一致的。
基本使用:
下面我们首先用一个实例来感受一下 BeautifulSoup 的基本使用:
html = """<html><head><title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse' s story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http ://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>""" from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') # lxml写成html.parser也可以,同样的效果,都是解析器 print(soup.prettify()) print("#"*30) print(soup.title.string)
运行结果
<html><head><title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse' s story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http :="" class="sister" elsie"="" example.com="" id="link1"><!-- Elsie -->,<a href="http: class="sister" example.com="" id="link2" lacie"="">Lacieand<a href="http: class="sister" example.com="" id="link3" tillie"="">Tillie;and they lived at the bottom of a well.<p class="story">...</p class="story"></a href="http:></a href="http:></a href="http></p class="story"></body> </html> ############################## The Dormouse's story
首先我们声明了一个变量 html,它是一个 HTML 字符串,但是注意到,它并不是一个完整的 HTML 字符串,<body> 和 <html> 标签都没有闭合,但是我们将它当作第一个参数传给 BeautifulSoup 对象,第二个参数传入的是解析器的类型,在这里我们使用 lxml,这样就完成了 BeaufulSoup 对象的初始化,将它赋值给 soup 这个变量。
那么接下来我们就可以通过调用 soup 的各个方法和属性对这串 HTML 代码解析了。
我们首先调用了 prettify () 方法,这个方法可以把要解析的字符串以标准的缩进格式输出,在这里注意到输出结果里面包含了 </body> 和 </html> 标签,也就是说对于不标准的 HTML 字符串 BeautifulSoup 可以自动更正格式,这一步实际上不是由 prettify () 方法做的,这个更正实际上在初始化 BeautifulSoup 时就完成了。
然后我们调用了 soup.title.string,这个实际上是输出了 HTML 中 <title> 标签的文本内容。所以 soup.title 就可以选择出 HTML 中的 <title> 标签,再调用 string 属性就可以得到里面的文本了,所以我们就可以通过简单地调用几个属性就可以完成文本的提取了,是不是非常方便?
标签选择器:
刚才我们选择元素的时候直接通过调用标签的名称就可以选择节点元素了,然后再调用 string 属性就可以得到标签内的文本了,这种选择方式速度非常快,如果单个标签结构话层次非常清晰,可以选用这种方式来解析。
选择元素
下面我们再用一个例子详细说明一下它的选择方法。
html = """<html><head><title>The Dormouse's story</title></head><body><p class="title" name="dromouse"><b>The Dormouse' s story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http: //example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" class="sister"id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""from bs4 import BeautifulSoupsoup = BeautifulSoup(html, 'lxml')print(soup.title)print(type(soup.title))print(soup.title.string)print(soup.head)print(soup.p)
运行结果
<title>The Dormouse's story</title> <class 'bs4.element.Tag'> The Dormouse's story <head><title>The Dormouse's story</title></head> <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
在这里我们依然选用了刚才的 HTML 代码,我们首先打印输出了 title 标签的选择结果,输出结果正是 title 标签加里面的文字内容。接下来输出了它的类型,是 bs4.element.Tag 类型,这是 BeautifulSoup 中的一个重要的数据结构,经过选择器选择之后,选择结果都是这种 Tag 类型,它具有一些属性比如 string 属性,调用 Tag 的 string 属性,就可以得到节点的文本内容了,所以接下来的输出结果正是节点的文本内容。
接下来我们又尝试选择了 head 标签,结果也是标签加其内部的所有内容,再接下来选择了 p 标签,不过这次情况比较特殊,我们发现结果是第一个 p 标签的内容,后面的几个 p 标签并没有选择到,也就是说,当有多个标签时,这种选择方式只会选择到第一个匹配的标签,其他的后面的标签都会忽略。
提取信息:
在上面我们演示了调用 string 属性来获取文本的值,那我们要获取标签属性值怎么办呢?获取标签名怎么办呢?下面我们来统一梳理一下信息的提取方式
获取名称:
可以利用 name 属性来获取标签的名称。还是以上面的文本为例,我们选取 title 标签,然后调用 name 属性就可以得到标签名称。
print(soup.title.name)
运行结果
title
属性获取:
每个标签可能有多个属性,比如 id,class 等等,我们选择到这个节点元素之后,可以调用 attrs 获取所有属性。
print(soup.p.attrs) print(soup.p.attrs['name'])
运行结果
{'class': ['title'], 'name': 'dromouse'}
dromouse
BeautifulSoup 案例
基本流程:
# 创建BeautifulSoup对象
from bs4 import BeautifulSoup
# 根据HTML网页字符创建BeautifulSoup对象soup=BeautifulSoup("html_doc", # HTML文档字符串"html.parser", # HTML解析器from_encoding="utf-8" # HTML文档的编码
)
# 搜索节点(find_all,find)
# 方法:find_all(name,attrs,string)
# 查找所有标签为a的节点
soup.find_all("a")
# 查找所有标签为a,链接符合/view/123.htm形式的节点
soup.find_all("a",href="/view/123.htm")
# 查找所有标签为div,class为abc,文字为Python的节点
soup.find_all("div",class_="abc",string="Python")获取疯狂的蚂蚁网站首页的文章:
url="http://www.crazyant.net"
import requests
r=requests.get(url)
if r.status_code!=200:raise Exception
html_doc=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,"html.parser")
h2_nodes=soup.find_all("h2",class_="entry-title")
for h2_node in h2_nodes:link=h2_node.find("a")print(link["href"],link.get_text())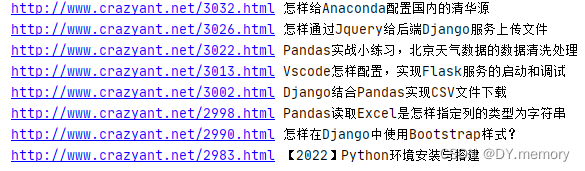
爬取三国演义小说所有文章:
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).content.decode("utf-8")
soup = BeautifulSoup(page_text,'html.parser')
li_list = soup.select('.book-mulu > ul > li')
fp = open('./三国演义小说.txt','w',encoding='utf-8')for li in li_list:title = li.a.stringdetail_url = 'https://www.shicimingju.com'+li.a['href']detail_page_text = requests.get(url=detail_url,headers=headers).content.decode("utf-8")detail_soup = BeautifulSoup(detail_page_text, 'html.parser')div_tag = detail_soup.find('div',class_='chapter_content')content = div_tag.textfp.write('\n' + title + ':' + content +'\n')print(title,'爬取成功')
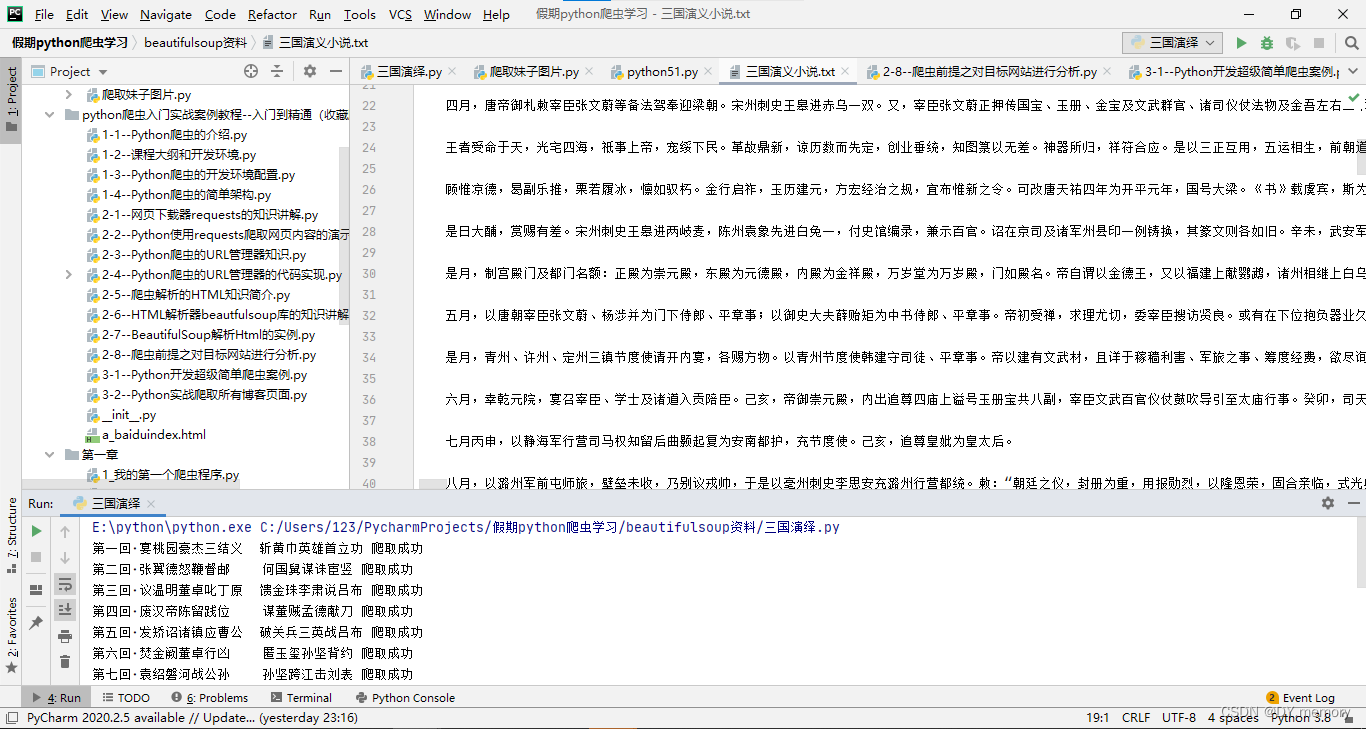

相关文章:
python爬虫--beautifulsoup模块简介
BeautifulSoup 的引入 我们学习了正则表达式的相关用法,但是一旦正则写的有问题,可能得到的就不是我们想要的结果了,而且对于一个网页来说,都有一定的特殊的结构和层级关系,而且很多标签都有 id 或 class 来对作区分&…...

Swfit Copy On Write 原理解析
1. Swift Copy On write 原理是什么 Swift 中的 Copy On Write (COW) 技术是一种内存优化技术,其原理是在需要修改数据时才进行拷贝,以避免不必要的内存消耗。 COW 的实现主要依赖于 Swift 中的结构体和类的特性。对于结构体而言,它是值类型…...

【面试题】经典面试题:让 a == 1 a == 2 a == 3 成立?
一、问题解析 if (a == 1 && a == 2 && a == 3) {console.log(Win) } 复制代码 如何打印除Win? 看到题目的第一眼,我是蒙蔽的.怎么可能会有如此矛盾的情况发生呢?就相当于一个人怎么可能即是小孩,又是成年人,还是老年人呢? 冷静下来,发现一些端倪。...

我是歌手-C语言
“我是歌手”是成名歌手之间的比赛节目,2轮比赛中观众支持率最低者出局。 这里我们假设有n个歌手进行了m轮比赛,请求出局者(m轮总分最低者)。 输入n个歌手(编号依次为1,2,......n)…...

Acwing---112.雷达设备
雷达设备1.题目2.基本思想3.代码实现1.题目 假设海岸是一条无限长的直线,陆地位于海岸的一侧,海洋位于另外一侧。 每个小岛都位于海洋一侧的某个点上。 雷达装置均位于海岸线上,且雷达的监测范围为 d,当小岛与某雷达的距离不超…...

SSJ-21A AC220V静态【时间继电器】
系列型号: SSJ-11B静态时间继电器;SSJ-21B静态时间继电器 SSJ-21A静态时间继电器;SSJ-22A静态时间继电器 SSJ-22B静态时间继电器SSJ-42B静态时间继电器 SSJ-42A静态时间继电器SSJ-41A静态时间继电器 SSJ-41B静态时间继电器SSJ-32B静态时间继电…...

m序列发生器——Verilog设计
引言 本篇文章利用Verilog编写一个m序列发生器模块。本文会给出具体的设计、测试源码。 设计说明 模块功能说明: 支持任意位宽的随机数生成;支持本原多项式配置;支持初始种子配置;设计环境: 设计语言:Verilog HDL 设计验证平台:MATLAB R20222a、Vivado 2018.3 m 序列…...
Mysql—触发器
触发器 简介 触发器用于直接在某种操作后(数据的增删改查等),通过事件执行设置触发器时的 sql 语句,具有原子性。 可通过 sql 语句直接编写,关键词:CREATE TRIGGER 触发器名称。 例如:在表 st…...
DVWA靶场通关和源码分析
文章目录一、Brute Force1.low2、medium3、High4、Impossible二、Command Injection1、Low2、Medium3、High三、CSRF1、Low2、Medium3、High4、Impossible四、File Inclusion1、Low2、Medium3、High五、File Upload1、Low2、Medium3、High4、Impossible六、 SQL注入1、Low2、Me…...
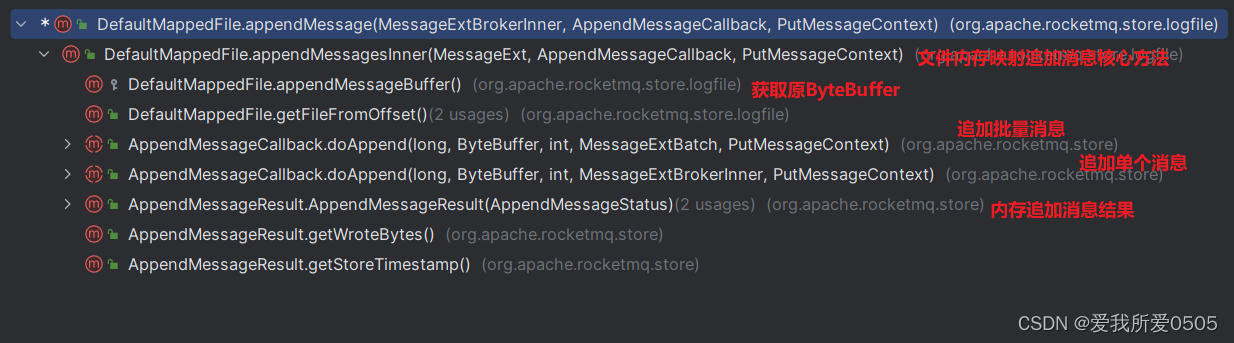
RocketMQ5.0.0消息存储<二>_消息存储流程
目录 一、消息存储概览 二、Broker接收消息 三、消息存储流程 1. DefaultMessageStore类 2. 存储流程 1):同步与异步存储 2):CommitLog异步存储消息 3):提交消息(Commit) 四、参考资料 一、消息存储概览 如下图所…...

【单片机方案】蓝牙体温计方案介绍
蓝牙体温计方案的工作原理利用了温度传感器输出电信号,直接输出数字信号或者再将电流信号(模拟信号)转换成能够被内部集成的电路识别的数字信号,然后通过显示器(如液晶、数码管、LED矩阵等)显示以数字形式的温度,能记录、读取被测温度的最高值…...

React 的受控组件和非受控组件有什么不同
大家好,我是前端西瓜哥,今天我们来看看 React 的受控组件和非受控组件有什么不同。 受控组件 受控组件,指的是将表单元素的值交给组件的 state 来保存。 例子: import ./styles.css import { useState } from reactconst App …...

【逐步剖C】-第六章-结构体初阶
一、结构体的声明 1. 结构体的基本概念 结构体是一些值的集合,这些值称为成员变量。结构体的每个成员可以是不同类型的变量。结构体使得C语言有能力描述复杂类型。 如学生,有姓名、学号、性别等;如书,有作者,出版日期…...
Java 并发在项目中的使用场景
1、并发编程的三个核心问题:(1)分工:所谓分工指的是如何高效地拆解任务并分配给线程(2)同步:而同步指的是线程之间如何协作(3)互斥:互斥则是保证同一时刻只允…...

15.面向对象程序设计
文章目录面向对象程序设计15.1OOP:概述继承动态绑定15.2定义基类和派生类15.2.1定义基类成员函数与继承访问控制与继承15.2.2定义派生类派生类对象及派生类向基类的类型转换派生类构造函数派生类使用基类的成员继承与静态成员派生类的声明被用作基类的类防止继承的发…...

Element UI框架学习篇(一)
Element UI框架学习篇(一) 1.准备工作 1.1 下载好ElementUI所需要的文件 ElementUI官网 1.2 插件的安装 1.2.1 更改标签的时实现自动修改 1.2.2 element UI提示插件 1.3 使用ElementUI需要引入的文件 <link rel"stylesheet" href"../elementUI/element…...

【算法】【C语言】
差分算法力扣1094题目描述学习代码思考力扣1094 题目描述 车上最初有 capacity 个空座位。车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向) 给定整数 capacity 和一个数组 trips , trip[i] [numPassengersi, fromi, toi] 表示第 …...
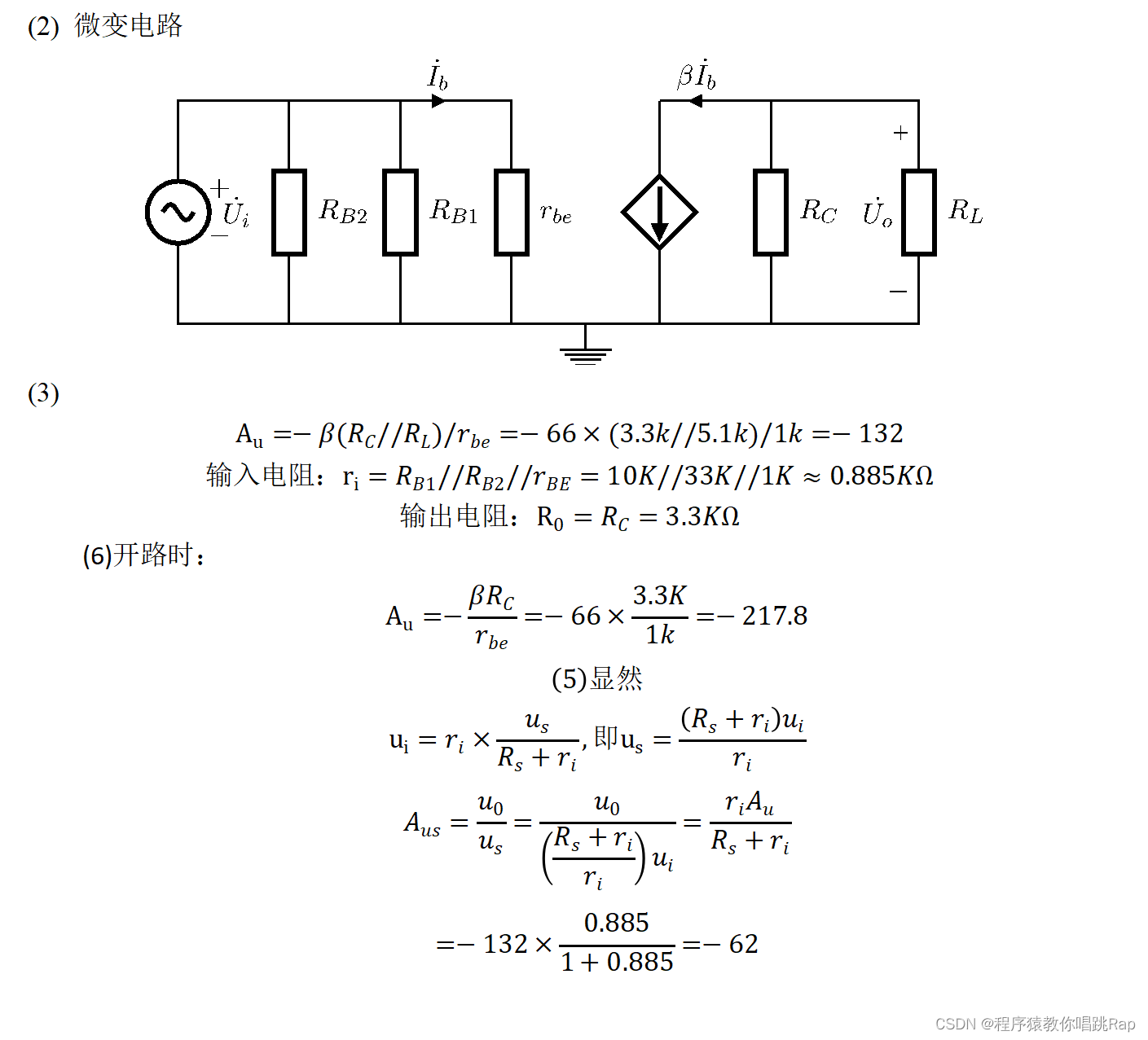
【✨十五天搞定电工基础】基本放大电路
本章要求1. 理解放大电路的放大作用和共发射极放大电路的性能特点; 2. 掌握静态工作点的估算方法和放大电路的微变等效电路分析法; 3. 了解放大电路输入、输出电阻和电压放大倍数的计算方法,了解放大电路的频率特性、 互补功率放大…...

MyBatis 入门教程详解
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
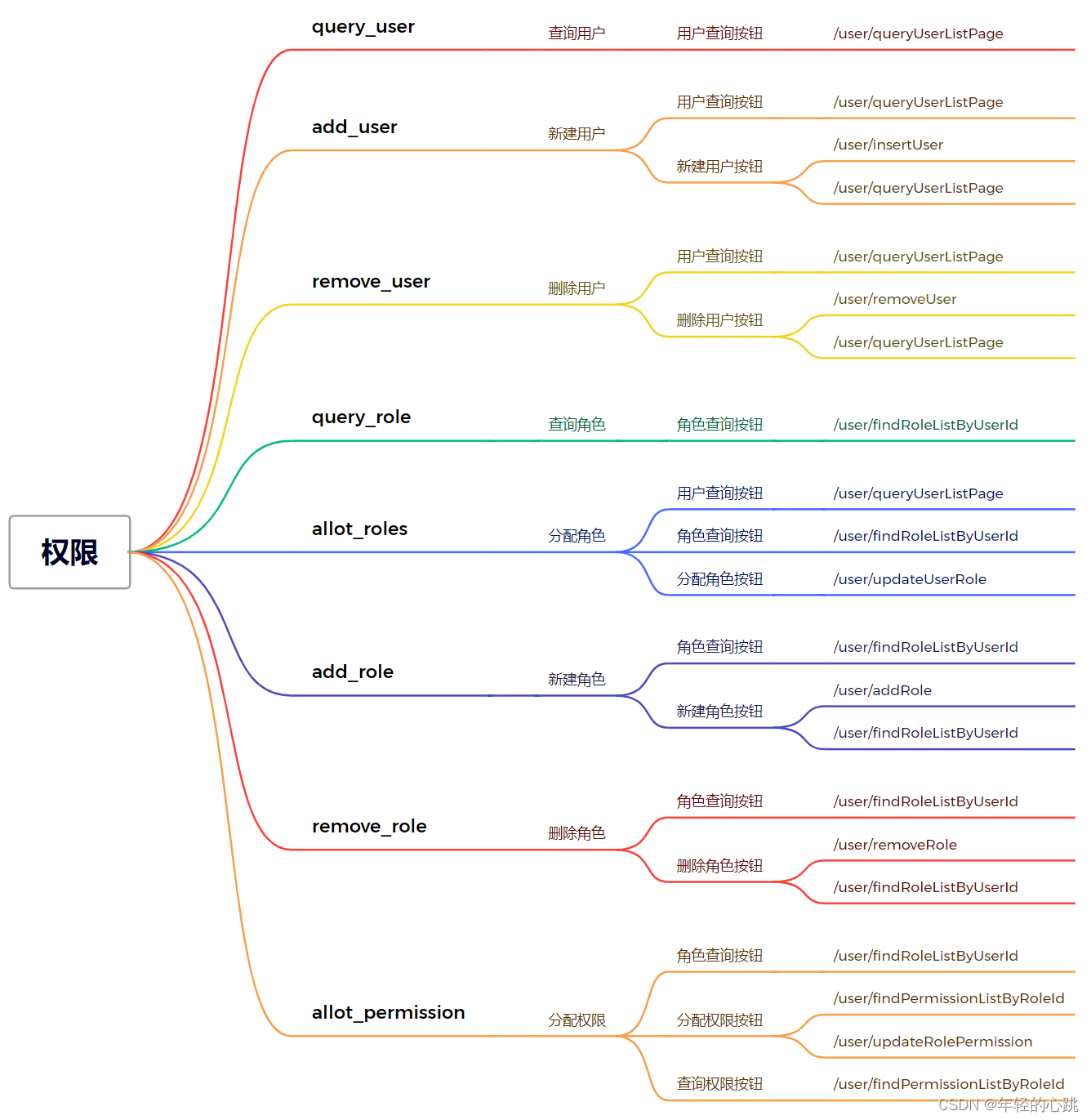
shiro、springboot、vue、elementUI CDN模式前后端分离的权限管理demo 附源码
shiro、springboot、vue、elementUI CDN模式前后端分离的权限管理demo 附源码 源码下载地址 https://github.com/Aizhuxueliang/springboot_shiro.git 前提你电脑的安装好这些工具:jdk8、idea、maven、git、mysql; shiro的主要概念 Shiro是一个强大…...

2025届最火的五大AI论文网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在生成式人工智能技术于学术写作里被广泛施行当下,维普平台正式推出了AIGC内容检…...
)
告别虚拟机!在WSL2的Ubuntu 20.04上搞定OpenCV 4.5+完整开发环境(含GUI显示配置)
在WSL2的Ubuntu 20.04上构建OpenCV 4.5全功能开发环境 当计算机视觉开发者第一次尝试在Windows系统上搭建OpenCV环境时,往往会面临两个选择:要么忍受虚拟机沉重的性能开销,要么在原生Windows环境中与各种兼容性问题搏斗。而今天,我…...

聊一聊 C# 中的闭包陷阱:foreach 循环的坑你还记得吗?直
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...

Java final关键字与抽象类深度解析
二、final关键字各位同学,接下来我们学习一个在面向对象编程中偶尔会用到的一个关键字叫final,也是为后面学习抽象类和接口做准备的。2.1 final修饰符的特点(面试题)我们先来认识一下final的特点,final关键字是最终的意思,可以修饰…...

Universal ADB Driver:Windows平台终极Android设备驱动解决方案
Universal ADB Driver:Windows平台终极Android设备驱动解决方案 【免费下载链接】UniversalAdbDriver One size fits all Windows Drivers for Android Debug Bridge. 项目地址: https://gitcode.com/gh_mirrors/un/UniversalAdbDriver 还在为Android设备连接…...

CppJieba中文分词实战指南:从环境搭建到企业级应用
CppJieba中文分词实战指南:从环境搭建到企业级应用 【免费下载链接】cppjieba "结巴"中文分词的C版本 项目地址: https://gitcode.com/gh_mirrors/cp/cppjieba 在处理中文文本时,如何高效、准确地进行词语切分是NLP任务的基础挑战。Cpp…...
)
别再只用localhost了!手把手教你用路由侠把本地宝塔面板‘搬’到公网(Windows版)
突破局域网限制:Windows下宝塔面板安全外网访问实战指南 你是否遇到过这样的困境?——在本地环境调试得心应手的项目,当需要向异地同事演示或临时交付客户预览时,却因为网络隔离而束手无策。传统解决方案要么要求部署到正式服务器…...

如何快速实现PyTorch语义分割:编码器-解码器架构完整指南
如何快速实现PyTorch语义分割:编码器-解码器架构完整指南 【免费下载链接】semantic-segmentation-pytorch Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset 项目地址: https://gitcode.com/gh_mirrors/se/semantic-segme…...

SEO_ 低成本高效进行SEO推广的实战策略
低成本高效进行SEO推广的实战策略 在当今数字化时代,SEO(搜索引擎优化)已经成为了每个企业网站流量获取的重要手段。SEO推广的成本往往让人望而却步。本文将为您揭示低成本高效进行SEO推广的实战策略,帮助您在有限的预算内最大化…...
LumiPixel Canvas Quest多模态探索:结合文本描述生成特定场景人像
LumiPixel Canvas Quest多模态探索:结合文本描述生成特定场景人像 1. 效果亮点预览 LumiPixel Canvas Quest在理解复杂文本描述并生成对应场景人像方面展现出惊人的能力。输入一段详细的场景描述,模型就能生成高度符合文本意境且细节丰富的图像。比如输…...