PyTorch的Tensor(张量)
一、Tensor概念
什么是张量?
张量是一个多维数组,它是标量、向量、矩阵的高维拓展
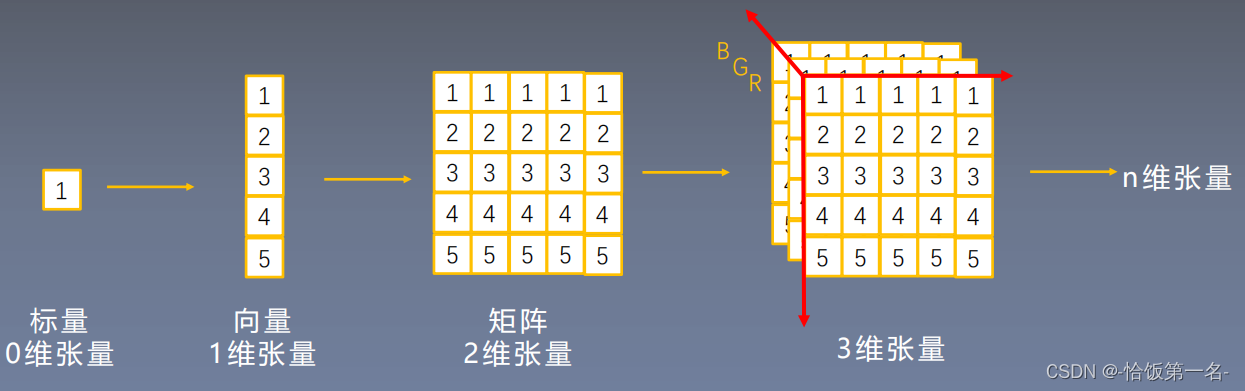
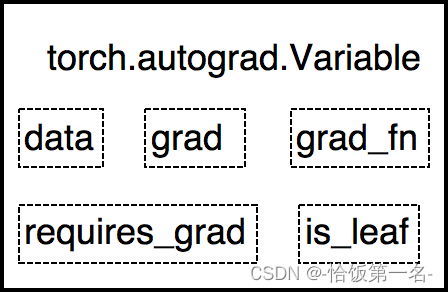
Tensor与Variable
Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。
- data: 被包装的Tensor
- grad: data的梯度(梦回数一)
- grad_fn: 创建Tensor的Function,是自动求导的关键
- requires_grad: 指示是否需要梯度
- is_leaf: 指示是否是叶子节点(张量)
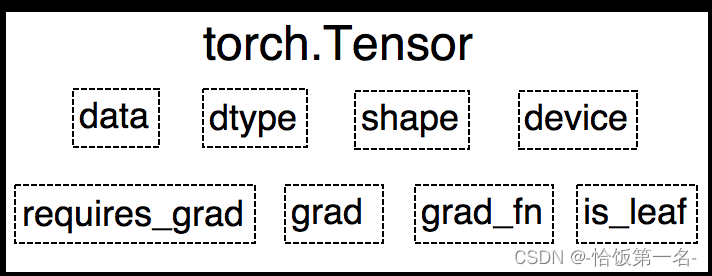
Tensor
PyTorch 0.4.0版本开始,Variable已并入Tensor。
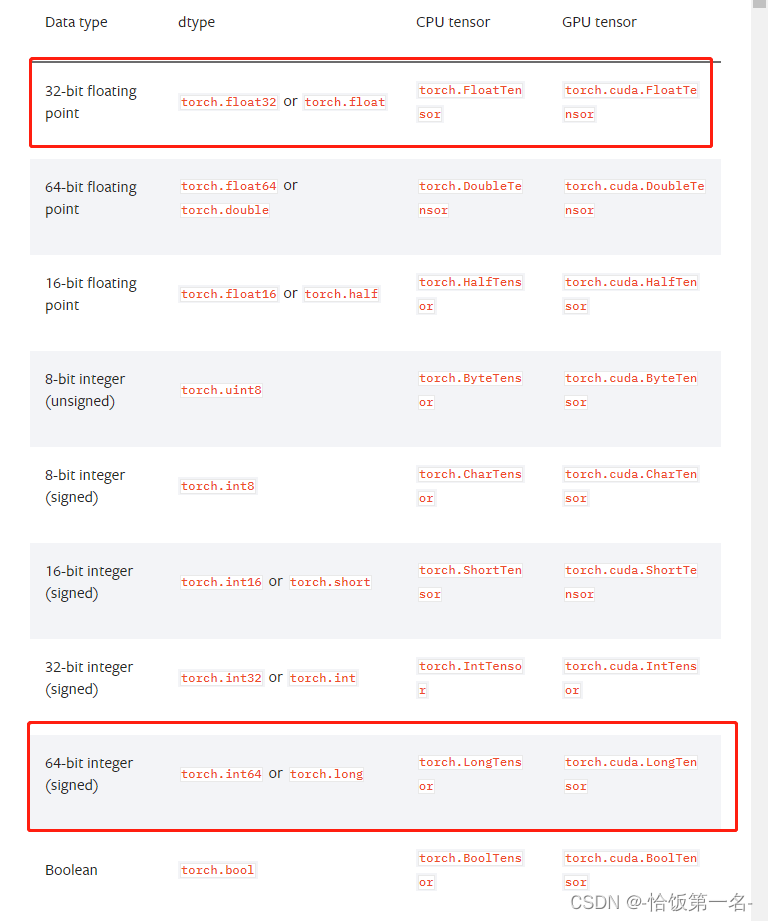
- dtype: 张量的数据类型,例如torch.FloatTensor, torch.cuda.FloatTensor
- shape: 张量的形状,例如 (64, 3, 224, 224)
- device: 张量所在设备,GPU/CPU,是加速的关键
二、 Create Tensor
1、直接创建
torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False
)
功能:从data创建tensor
• data: 数据, 可以是list, numpy
• dtype : 数据类型,默认与data的一致
• device : 所在设备, cuda/cpu
• requires_grad:是否需要梯度
• pin_memory:是否存于锁页内存
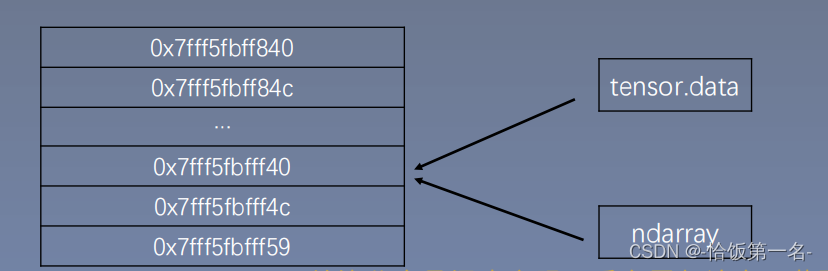
torch.from_numpy(ndarray)
功能:从numpy创建tensor。
注意事项:从torch.from_numpy创建的 tensor 与原始 ndarray 共享内存。
当修改其中一个的数据时,另一个也会被改动。
2、依据数值创建
torch.zeros(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
功能:依照size创建全0张量
• size: 张量的形状, 如(3, 3)、(3, 224,224)
• out : 输出的张量
• layout : 内存中布局形式, 有strided,sparse_coo等
• device : 所在设备, gpu/cpu
• requires_grad:是否需要梯度
torch.zeros_like(input,dtype=None,layout=None,device=None,requires_grad=False
)功能:依照 input 形状创建全0张量
参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None(即与输入张量相同)。
- layout(可选): 新创建张量的布局,默认为 None(即与输入张量相同)。
- device(可选): 新创建张量所在设备,默认为 None(即与输入张量相同)。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones_like(input,dtype=None,layout=None,device=None,requires_grad=False
)参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None,即与输入张量相同。
- layout(可选): 新创建张量的布局,默认为 None,即与输入张量相同。
- device(可选): 新创建张量所在设备,默认为 None,即与输入张量相同。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
- torch.ones() 用于创建所有元素值为1的张量,而 torch.ones_like() 则创建与输入张量形状相同的张量,但所有元素的值都为1。这两个函数都可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.full(size,fill_value,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- fill_value: 填充张量的值,可以是标量或与指定数据类型相同的张量。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建指定形状并用指定值填充的张量。填充值可以是一个标量或与指定数据类型相同的张量。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.arange(start=0,end,step=1,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值,默认为 0。
- end: 序列结束值(不包含),创建的序列不包含该值。
- step: 序列中相邻值之间的步长,默认为 1。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建一个从 start 到 end(不包含 end)的数值序列,并以 step 为步长。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.linspace(start,end,steps=100,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值。
- end: 序列结束值。
- steps: 序列中的元素数量,默认为 100。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在指定范围内(从 start 到 end)以均匀间隔的方式生成的数值序列,并且序列的元素数量由 steps 参数指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.logspace(start,end,steps=100,base=10.0,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值的指数。
- end: 序列结束值的指数。
- steps: 序列中的元素数量,默认为 100。
- base: 序列中的数值以此为底进行指数计算,默认为 10.0。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在对数刻度上以均匀间隔分布的数值序列,start 和 end 参数指定序列起始值和结束值的指数,base 参数确定对数的底。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.eye(n,m=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- n: 矩阵的行数。
- m(可选): 矩阵的列数,默认为 None,如果为 None,则创建的是 n x n 的方阵。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数可以创建一个单位矩阵。如果提供了 m 参数,则创建的是一个 n x m 的矩阵,否则创建的是 n x n 的方阵。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
3、依概率分布创建张量
torch.normal(mean,std,out=None
)torch.normal() 是 PyTorch 中用于生成服从指定均值和标准差的正态分布随机数的函数。以下是该函数的参数说明:
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(mean,std,out=None
)用于生成服从指定均值和标准差的正态分布随机数。
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(mean,std,size,out=None
)- mean: 正态分布的均值。
- std: 正态分布的标准差。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机数。
四种模式:
mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量
这个函数与前一个函数类似,但是多了一个 size 参数,用于指定生成张量的形状。返回一个形状为 size 的张量,其中的元素服从均值为 mean、标准差为 std 的正态分布。可以选择性地提供一个输出张量 out 用于保存生成的随机数。
torch.randn(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)torch.rand() 是 PyTorch 中用于生成服从标准正态分布(均值为0,标准差为1)的随机数的函数。以下是该函数的参数说明:
torch.rand(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量,用于保存生成的随机数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [0, 1) 上均匀分布的随机数,形状由参数 *size 指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.randint(low=0,high,size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
- low: 区间的下界(包含在内)。
- high: 区间的上界(不包含在内)。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机整数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [low, high) 上均匀分布的随机整数,形状由参数 size 指定。
这个函数用于生成随机排列和按照伯努利分布生成随机二元数。
torch.randperm(n,out=None,dtype=torch.int64,layout=torch.strided,device=None,requires_grad=False
)
参数说明:
- n: 生成随机排列的长度。
- out(可选): 输出张量,用于保存生成的随机排列。
- dtype(可选): 张量的数据类型,默认为 torch.int64。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个长度为 n 的张量,包含从 0 到 n-1 的随机排列整数。
torch.bernoulli(input,*,generator=None,out=None
)- input: 输入张量,用于指定伯努利分布的概率值。
- generator(可选): 随机数生成器,默认为 None。
- out(可选): 输出张量,用于保存生成的随机二元数。
这个函数返回一个张量,其中的元素按照输入张量中的概率值在伯努利分布上进行采样生成随机二元数(0 或 1)。
相关文章:
PyTorch的Tensor(张量)
一、Tensor概念 什么是张量? 张量是一个多维数组,它是标量、向量、矩阵的高维拓展 Tensor与Variable Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。 data: 被包装的Tensorgrad: data的梯度&…...
spug发布问题汇总记录
问题导览 1. [vite]: Rollup failed to resolve import "element-plus" from "src/main.js". 项目框架简介 vue3viteelement-plus 解决方案 - 1. 配置淘宝镜像源:npm config set registry https://registry.npm.taobao.org/ - 2. npm inst…...
SpringBoot-搭建集成Mybatis的项目
本文介绍了如何在IntelliJ IDEA中使用SpringBoot和Mybatis构建Java Web应用程序。通过本文的学习,读者将了解如何使用IntelliJ IDEA快速搭建一个基于SpringBoot和Mybatis的Java Web应用程序,提高开发效率。IntelliJ IDEA是一款功能强大的Java集成开发环境…...

mysql隐式转换规则
MySQL 中的隐式类型转换发生在比较操作或者其他一些需要特定数据类型参数的上下文中,如果参与操作的表达式或列的数据类型不匹配,MySQL 就会自动进行数据类型转换以适配预期的数据类型。 以下是 MySQL 的一些常见隐式转换规则: 字符串和数字…...

怎么解决 Nginx反向代理加载速度慢?
Nginx反向代理加载速度慢可能由多种原因引起,以下是一些可能的解决方法: 1,网络延迟: 检查目标服务器的网络状况,确保其网络连接正常。如果目标服务器位于不同的地理位置,可能会有较大的网络延迟。考虑使用…...

Eureka工作原理超详细讲解介绍
Eureka 是 Netflix 开源的一款服务注册与发现框架,主要用于构建分布式系统中的服务治理和负载均衡。下面是关于 Eureka 工作原理的详细介绍:1.Eureka 架构: Eureka 采用了客户端-服务器架构,包括 Eureka Server 和 Eureka Client …...
)
SQL WHERE 语句(条件选择)
WHERE 子句用于过滤记录。 SQL WHERE 子句 WHERE 子句用于提取那些满足指定条件的记录。 SQL WHERE 语法 SELECT column1, column2, ... FROM table_name WHERE condition; 参数说明: column1, column2, ...:要选择的字段名称,可以为多…...
用UCLI(TCL)控制verdi dump 波形
UCLI(Unified Command-line Interface)为Synopsys验证工具了提供一组通用命令,通过UCLI可以执行任意TCL(Tool Command Language)命令。在我们的验证环境中,通常跟ucli打交道的地方是用来控制开始dump和结束…...

如何使用 Python+selenium 进行 web 自动化测试?
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击、输入、选择等等。它支持多种浏览器,包括Chrome、Firefox、Safari等等,并且可以在多个平台上运行。 安装和配置Selenium 在使用Selenium之前,…...

约瑟夫问题
约瑟夫问题 题目描述 n n n 个人围成一圈,从第一个人开始报数,数到 m m m 的人出列,再由下一个人重新从 1 1 1 开始报数,数到 m m m 的人再出圈,依次类推,直到所有的人都出圈,请输出依次出圈人的编号。…...

文件管理方法:利用文件大小进行筛选,高效移动文件至目标文件夹
在日常工作中,文件管理是一项至关重要的任务。为了更高效地管理文件,可以利用文件大小进行筛选,并将文件快速移动至目标文件夹。接下来一起来看看云炫文件管理器如何利用文件大小进行筛选,以及如何高效移动文件至目标文件夹的方法…...

python报错:TypeError: Descriptors cannot be created directly.
问题 报错提示: TypeError:不能直接创建描述符。 如果此调用来自 _pb2.py 文件,则您生成的代码已过期,必须使用 protoc > 3.19.0 重新生成。 如果您不能立即重新生成原型,其他一些可能的解决方法是: 1.…...

Linux 内核调试
文章目录 一、方法论 一、方法论 qemu 虚拟机 Linux内核学习 Linux 内核调试 一:概述 Linux 内核调试 二:ubuntu20.04安装qemu Linux 内核调试 三:《QEMU ARM guest support》翻译 Linux 内核调试 四:qemu-system-arm功能选项整…...
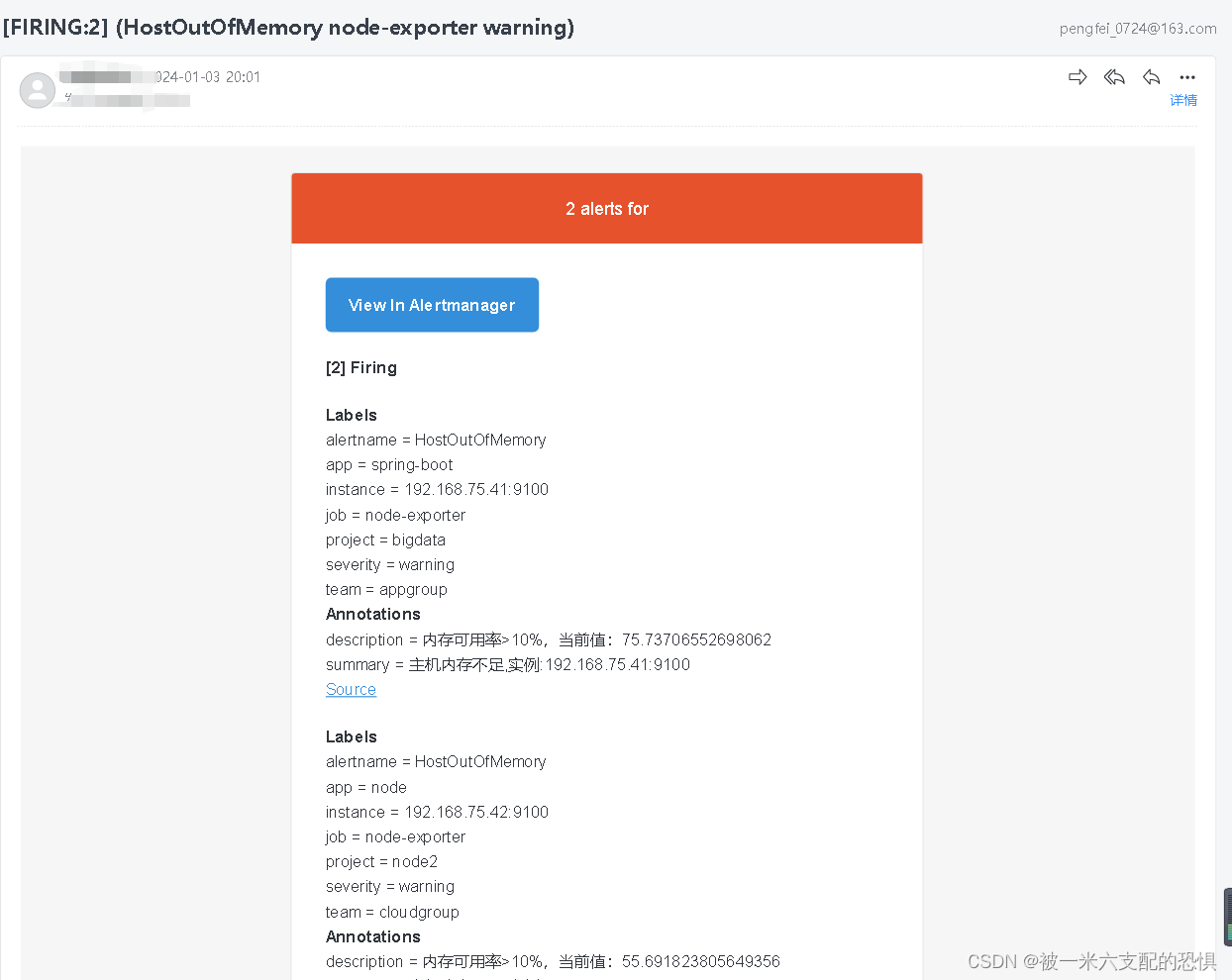
Prometheus-AlertManager 邮件告警
环境,软件准备 本次演示环境,我是在虚拟机上安装 Linux 系统来执行操作,以下是安装的软件及版本: System: CentOS Linux release 7.6Docker: 24.0.5Prometheus: v2.37.6Consul: 1.6.1 docker 安装prometheus,alertmanage,说明一下这里直接将…...

Volcano Controller控制器源码解析
Volcano Controller控制器源码解析 本文从源码的角度分析Volcano Controller相关功能的实现。 本篇Volcano版本为v1.8.0。 Volcano项目地址: https://github.com/volcano-sh/volcano controller命令main入口: cmd/controller-manager/main.go controller相关代码目录: pkg/co…...
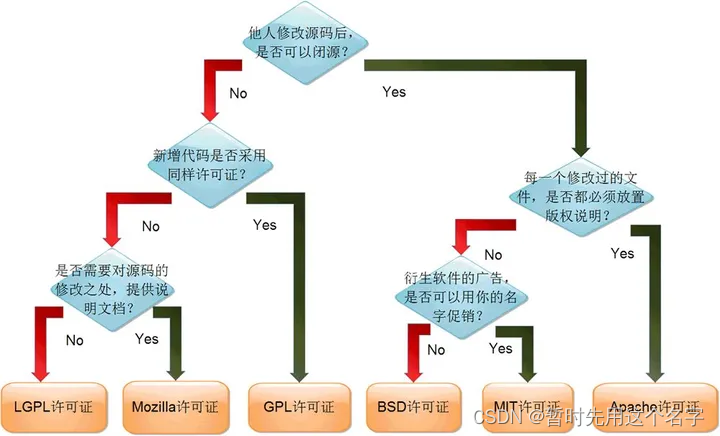
开源协议简介和选择
软件国产化已经提到日程上了,先来研究一下开源协议。 引言 在追求“自由”的开源软件领域的同时不能忽视程序员的权益。为了激发程序员的创造力,现今世界上有超过60种的开源许可协议被开源促进组织(Open Source Initiative)所认可…...

大创项目推荐 深度学习卫星遥感图像检测与识别 -opencv python 目标检测
文章目录 0 前言1 课题背景2 实现效果3 Yolov5算法4 数据处理和训练5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **深度学习卫星遥感图像检测与识别 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
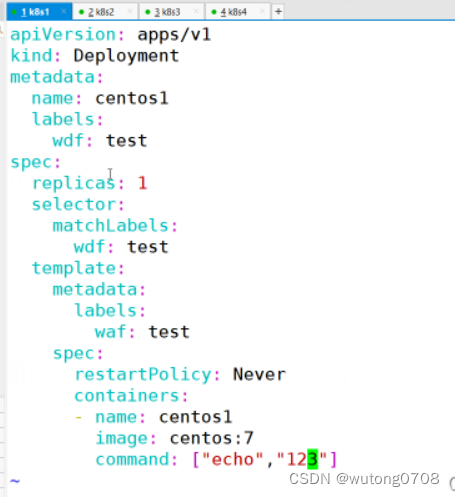
pod的环节
pod 是k8s当中最小的资源管理组件 Pod也是最小化运行容器化的应用的资源管理对象 Pod是一个抽象化的概念,可以理解为一个或多个容器化的集合 在一个pod当中运行一个容器,是最常用的方式 在一个pod当中同时运行多个容器,在一个pod当中可以…...
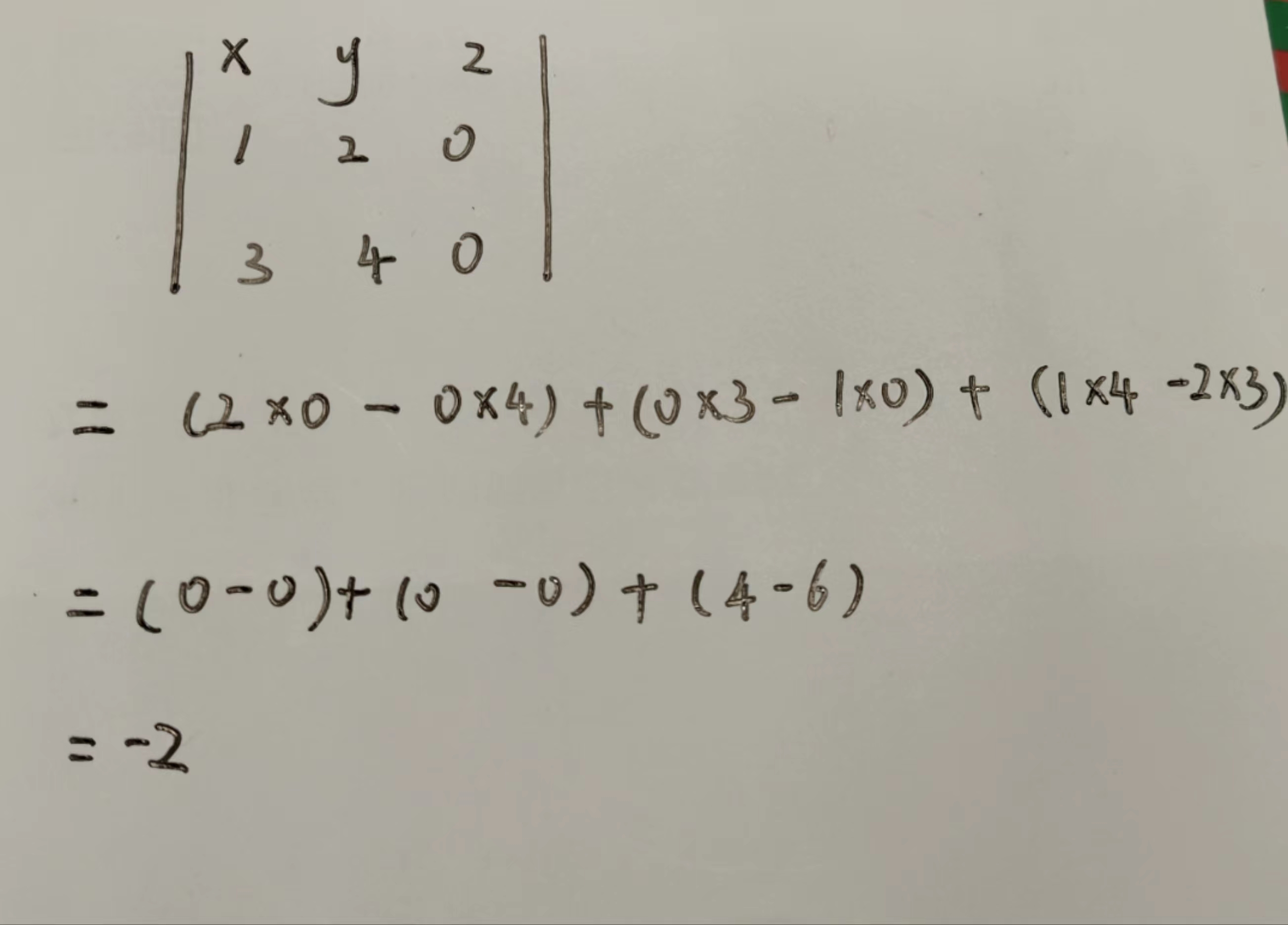
Unity | Shader基础知识番外(向量数学知识速成)
目录 一、向量定义 二、计算向量 三、向量的加法(连续行走) 四、向量的长度 五、单位向量 六、向量的点积 1 计算 2 作用 七、向量的叉乘 1 承上启下 2 叉乘结论 3 叉乘的计算(这里看不懂就百度叉乘计算) 八、欢迎收…...

一个小白的微不足道的见解关于未来
随着科技的不断发展,IT行业日益壮大,运维工程师在其中扮演着至关重要的角色。他们负责维护和管理企业的技术基础设施,确保系统的正常运行。然而,随着技术的进步和行业的变化,运维工程师的未来将面临着一系列挑战和机遇…...

AI率从90%降到合格线,我踩了3个坑后找到的方法
我的论文AI率在知网检出了91%。 最后我把AI率降到了9%,但在这之前踩了3个坑,多花了将近两天时间。这篇文章不是炫成绩,是把这3个坑说清楚,让后来的人少走一段弯路。 坑一:花了一天手动改写,基本没用 拿到…...

SeaTunnel Web安装踩坑记:从MySQL驱动到Hazelcast配置,我都经历了什么
SeaTunnel Web安装踩坑记:从MySQL驱动到Hazelcast配置,我都经历了什么 那天下午,当我第一次尝试在Linux服务器上部署SeaTunnel Web时,完全没想到会开启一段长达6小时的"排雷之旅"。作为一款强大的数据集成平台ÿ…...

FNF-PsychEngine完全指南:从零开始打造你的音乐游戏
FNF-PsychEngine完全指南:从零开始打造你的音乐游戏 【免费下载链接】FNF-PsychEngine Engine originally used on Mind Games mod 项目地址: https://gitcode.com/gh_mirrors/fn/FNF-PsychEngine FNF-PsychEngine是一款功能强大的Friday Night Funkin开源游…...

PHP反序列化漏洞实战:从NewStarCTF题目看私有属性的坑
PHP反序列化漏洞实战:私有属性处理中的隐藏陷阱 在CTF竞赛和实际渗透测试中,PHP反序列化漏洞一直是Web安全领域的重点研究对象。而其中关于类属性可见性(特别是private修饰符)的处理机制,往往成为解题的关键突破口。去…...

OpenClaw人人养虾:企业财务自动化
通过 OpenClaw 的 Cron(定时任务) Hooks(钩子)组合,实现发票附件的自动发现、OCR(光学字符识别)信息提取、数据校验和财务系统录入的全自动化流程。每月可为财务人员节省 80% 以上的发票处理时间…...
的隐藏功能与安全机制深度解读)
别再只看电流了!航模电调(ESC)的隐藏功能与安全机制深度解读
航模电调(ESC)的隐藏功能与安全机制深度解析 当你的航模飞机在高速俯冲时突然失去动力,或是悬停表演中电机莫名停转,这些惊险时刻往往与电调的保护机制密切相关。大多数玩家只把电调当作简单的"油门开关",却…...

如何高效提取Unity游戏资源:AssetStudio的完整实战指南
如何高效提取Unity游戏资源:AssetStudio的完整实战指南 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional…...

新手福音:无需下载安装,在快马平台直接上手体验wsl开发
作为一个刚接触WSL的新手,最头疼的就是漫长的下载安装过程。记得我第一次尝试在Windows上安装WSL时,光是等待wsl --install命令完成就花了近一个小时,中间还因为网络问题失败了好几次。这种体验对初学者来说真的很劝退。 后来我发现了一个更简…...

高效部署全能屏幕工具:eSearch实战安装与配置指南
高效部署全能屏幕工具:eSearch实战安装与配置指南 【免费下载链接】eSearch 截屏 离线OCR 搜索翻译 以图搜图 贴图 录屏 万向滚动截屏 屏幕翻译 Screenshot Offline OCR Search Translate Search for picture Paste the picture on the screen Screen recorder Omni…...

Obsidian本地图片终极管理指南:5步打造永不失效的笔记图片库
Obsidian本地图片终极管理指南:5步打造永不失效的笔记图片库 【免费下载链接】obsidian-local-images-plus This repo is a reincarnation of obsidian-local-images plugin which main aim was downloading images in md notes to local storage. 项目地址: http…...