pulsar原来是这样操作topic的
本篇主要讲述pulsar topic部分,主要从设计以及源码的视角进行讲述。在pulsar中,一个Topic的新建、扩容以及删除操作都是由Broker来处理的,而Topic相关的数据是存储在zookeeper上的。本篇文章模拟一个高效的学习流程进行展开
- 介绍使用方式(Topic操作指令)
- 从高纬度俯视调用流程(从服务层面看Topic的调用流程)
- 逐步切入某个具体的操作进一步展开内部的调用流程(从代码层面看具体的调用流程)
- 看具体的实现(看代码具体的实现)
Topic操作指令
在日常对pulsar Topic操作时,咱们常常会用到以下指令
//1. Topic创建
pulsar-admin topics create-partitioned-topic \persistent://my-tenant/my-namespace/my-topic \--partitions 4
//2. Topic扩容
pulsar-admin topics update-partitioned-topic \persistent://my-tenant/my-namespace/my-topic \--partitions 8
//3. Topic删除
pulsar-admin topics delete persistent://test-tenant/ns1/tp1
//4. Topic unload
pulsar-admin topics unload persistent://test-tenant/ns1/tp1
更多的操作可以参考 https://pulsar.apache.org/docs/3.0.x/admin-api-topics/
在这里列举了针对分区并存储Topic的四个操作指令
- Topic创建,通过指令可以在指定的租户以及命名空间下创建Topic并指定分区数
- Topic扩容,这是业务场景为了提升性能时通常会用到的操作,增加指定Topic的分区数
- Topic删除,删除不用的Topic,在删之前一定要在监控上确保此Topic的上下游都没有被使用
- Topic unload,重制Topic状态
以上就是使用方式,打个比方就是猪可以用来烹饪,猪脑可以用来烤脑花等等
服务层面调用流程

Pulsar用户(管理员) 跟Pulsar集群的交互流程可以提炼成上面这张表,从左往右看
- 用户是集群管理员或者Pulsar的用户,在跟Pulsar集群交互时,可以通过Pulsar提供的上面三种方式。上面提供的操作指令就是第一种shell命令的方式,还可以直接通过http访问rest接口方式以及使用Pulsar针对各个编程语言提供的sdk包进行操作
- Pulsar集群Topic相关的元数据全部存储在Zookeeper中,同时为了避免高频访问Zookeeper导致的性能瓶颈,Pulsar在自身服务增加了Cache,在本地内存进行元数据的存储。同时在Pulsar Broker启动时会在Zookeeper添加Watcher来感知元数据的变动,如果有变动会同步更新本地Cache。在有Topic元数据相关的查操作时,会优先查询本地Cache
- Pulsar Topic里的数据会存在Bookkeeper中,在对Topic新增/删除时,会调用Bookkeeper来创建/删除 Bookkeeper中相关的数据
以上就是高纬度俯视调用流程,打个比方就是猪的骨架以及神经脉络的构成,这个设计/调用流程在大的方向上已经将Pulsar定型了。在学习的过程中切忌一下子就钻入细节(除非是急着解决问题),一定要有一个清晰的全貌认识,在根据需要逐步切入具体的细节
代码层调用流程
在对全貌有了解后,咱们开始从代码实现层面来看调用流程
首先先看通用的,无论是新增、扩容、卸载还是删除,Pulsar都需要让所有Broker节点感知到元数据的变化。通过下图来看看Pulsar是怎么做的

如上图所示,Pulsar Broker在启动的时候,会通过ZooKeeperCache对象的构造函数中创建一个ZookeeperClient对象,其通过watcher方式来监听 Zookeeper中 /brokers/topics 路径下数据的变动;在Topic新建时,本质上就是在 /brokers/topics目录下新建一个 Topic名称的子目录,Topic删除本质就是删除此目录,而扩容的本质就是变更 /brokers/topics/topic名称 中分区的信息。因此Pulsar中Topic的变更感知其实就是通过Zookeeper提供的一致性写入以及watcher来实现的,这也是大部分组件元数据变更的实现方案。通过上述可以看到Pulsar在感知到Topic元数据的变动后只做了一件事,就是同步刷新本地的缓存。
在知道Pulsar是怎么实现的Topic变更感知后,接下来看看它的Topic新建流程

如上图所示,在我们通过指令调用Pulsar创建Topic后,Pulsar Broker会调用ZKMetadataStore的put方法进行处理,其内部罪关键的操作就是调用Zookeeper的客户端在 Zookeeper的服务端 /brokers/topics目录下创建Topic名称的新目录,同时更新本地缓存AsyncLoadingCache。至此Topic创建的流程就结束了,可以负责消息的读写操作。其他扩容、删除等操作也类似,在这里就不一一例举了。
以上就是代码的调用流程,打个比方就是猪的心脏、猪蹄的构成,在深入细节时要不断的在头脑或者笔记中梳理细节的脉络,否则很容易迷失在这里。
代码实现
在对各个操作的调用流程了解了之后,咱们的脑海中已经有一副Pulsar Topic相关操作的地图了,现在就让咱们根据地图去探索具体的“宝藏”吧。
咱们先来看看Topic创建的代码实现,为了避免迷路,博主在下面先整理调用栈,之后再针对具体的核心代码进行讲解
PersistentTopics#createPartitionedTopic //Topic创建 服务端代码入口,仅做了Topic相关的格式、权限的校验AdminResource#internalCreatePartitionedTopic //异步检查Topic是否存在以及异步调用创建TopicAdminResource#tryCreatePartitionsAsync //根据分区数循环调用异步方法tryCreatePartitionAsyncAdminResource#tryCreatePartitionAsync //调用zk服务端来创建Topic具体的某个分区ZKMetadataStore#putZKMetadataStore#storePutZKMetadataStore#storePutInternalZooKeeper#setData //这里就是创建Topic最关键的地方,也就是在Zookeeper服务端创建新Topic目录下的分区信息
整个调用链路还是非常清晰的,因为相比kafka而言,Pulsar是无主架构,不需要做选主、一致性相关的操作,所以代码难度整体并不算高。不过pulsar为了性能大量使用了异步处理搭配lambda操作,对于不熟悉的读者会有点难度。
下面让咱们深入看下实现细节,首先是入口 PersistentTopics#createPartitionedTopic
public void createPartitionedTopic(...) {try {validateGlobalNamespaceOwnership(tenant, namespace); //校验当前Topic的租户-namespace二级目录是否有效validatePartitionedTopicName(tenant, namespace, encodedTopic); //未知校验什么//判断当前操作是否允许validateTopicPolicyOperation(topicName, PolicyName.PARTITION, PolicyOperation.WRITE); validateCreateTopic(topicName); //校验Topic命名,避免跟服务内部Topic冲突//真正调用创建Topic的方法internalCreatePartitionedTopic(asyncResponse, numPartitions, createLocalTopicOnly);} catch (Exception e) {//}}
因此我们可以看到主要就是做相关的校验,主要的逻辑交给下一层AdminResource#internalCreatePartitionedTopic,进一步看实现
protected void internalCreatePartitionedTopic(AsyncResponse asyncResponse, int numPartitions,boolean createLocalTopicOnly) {Integer maxTopicsPerNamespace = null;try {//获取当前Namespace的策略,用于校验Policies policies = getNamespacePolicies(namespaceName);maxTopicsPerNamespace = policies.max_topics_per_namespace;} catch (RestException e) {//....}try {if (maxTopicsPerNamespace > 0) {List<String> partitionedTopics = getTopicPartitionList(TopicDomain.persistent);//校验当前namespace下的Topic数量已经达到限额,到的话则创建新Topic失败if (partitionedTopics.size() + numPartitions > maxTopicsPerNamespace) {log.error("[{}] Failed to create partitioned topic {}, "+ "exceed maximum number of topics in namespace", clientAppId(), topicName);resumeAsyncResponseExceptionally(asyncResponse, new RestException(Status.PRECONDITION_FAILED,"Exceed maximum number of topics in namespace."));return;}}} catch (Exception e) {//....}final int maxPartitions = pulsar().getConfig().getMaxNumPartitionsPerPartitionedTopic();try {//对namespace的操作进行校验validateNamespaceOperation(topicName.getNamespaceObject(), NamespaceOperation.CREATE_TOPIC);} catch (Exception e) {//....}//对分区数进行下界校验if (numPartitions <= 0) {asyncResponse.resume(new RestException(Status.NOT_ACCEPTABLE,"Number of partitions should be more than 0"));return;}//对分区数进行上界校验if (maxPartitions > 0 && numPartitions > maxPartitions) {asyncResponse.resume(new RestException(Status.NOT_ACCEPTABLE,"Number of partitions should be less than or equal to " + maxPartitions));return;}List<CompletableFuture<Void>> createFutureList = new ArrayList<>();CompletableFuture<Void> createLocalFuture = new CompletableFuture<>();createFutureList.add(createLocalFuture);//异步调用检查Topic是否已存在checkTopicExistsAsync(topicName).thenAccept(exists -> {if (exists) {log.warn("[{}] Failed to create already existing topic {}", clientAppId(), topicName);asyncResponse.resume(new RestException(Status.CONFLICT, "This topic already exists"));return;}//核心操作,异步调用创建Topic操作provisionPartitionedTopicPath(asyncResponse, numPartitions, createLocalTopicOnly).thenCompose(ignored -> tryCreatePartitionsAsync(numPartitions)).whenComplete((ignored, ex) -> {if (ex != null) {createLocalFuture.completeExceptionally(ex);return;}createLocalFuture.complete(null);});}).exceptionally(ex -> {//....});//如果这个Topic是全局的,那么还会调用其他pulsar集群异步创建这个Topic//这里控制多个并发请求结束处理的设计值得借鉴,通过轮训异步对象容器进行结果处理if (!createLocalTopicOnly && topicName.isGlobal() && isNamespaceReplicated(namespaceName)) {getNamespaceReplicatedClusters(namespaceName).stream().filter(cluster -> !cluster.equals(pulsar().getConfiguration().getClusterName())).forEach(cluster -> createFutureList.add(((TopicsImpl) pulsar().getBrokerService().getClusterPulsarAdmin(cluster).topics()).createPartitionedTopicAsync(topicName.getPartitionedTopicName(), numPartitions, true)));}FutureUtil.waitForAll(createFutureList).whenComplete((ignored, ex) -> {if (ex != null) {log.error("[{}] Failed to create partitions for topic {}", clientAppId(), topicName, ex.getCause());if (ex.getCause() instanceof RestException) {asyncResponse.resume(ex.getCause());} else {resumeAsyncResponseExceptionally(asyncResponse, ex.getCause());}return;}log.info("[{}] Successfully created partitions for topic {} in cluster {}",clientAppId(), topicName, pulsar().getConfiguration().getClusterName());asyncResponse.resume(Response.noContent().build());});}
这个方法的逻辑有些多,但整体也是比较清晰的,接下来进一步看看AdminResource#tryCreatePartitionsAsync的代码
protected CompletableFuture<Void> tryCreatePartitionsAsync(int numPartitions) {//如果Topic不需要持久化,直接结束if (!topicName.isPersistent()) {return CompletableFuture.completedFuture(null);}List<CompletableFuture<Void>> futures = new ArrayList<>(numPartitions);//针对Topic的每个分区单独发起各自的创建请求for (int i = 0; i < numPartitions; i++) {futures.add(tryCreatePartitionAsync(i, null));}//等待多个异步任务处理好return FutureUtil.waitForAll(futures);}
继续看AdminResource#tryCreatePartitionAsync的实现
private CompletableFuture<Void> tryCreatePartitionAsync(final int partition, CompletableFuture<Void> reuseFuture) {CompletableFuture<Void> result = reuseFuture == null ? new CompletableFuture<>() : reuseFuture;//获取元数据存储对象,pulsar默认都是zookeeper的实现,没有其他选项,但支持自定义拓展Optional<MetadataStoreExtended> localStore = getPulsarResources().getLocalMetadataStore();if (!localStore.isPresent()) {result.completeExceptionally(new IllegalStateException("metadata store not initialized"));return result;}//核心代码,往元数据对象中新增这个分区的信息localStore.get().put(ZkAdminPaths.managedLedgerPath(topicName.getPartition(partition)), new byte[0], Optional.of(-1L)).thenAccept(r -> {if (log.isDebugEnabled()) {log.debug("[{}] Topic partition {} created.", clientAppId(), topicName.getPartition(partition));}result.complete(null);}).exceptionally(ex -> {//....});return result;}
继续跟踪,进入到ZKMetadataStore#put
public CompletableFuture<Stat> put(String path, byte[] value, Optional<Long> optExpectedVersion) {return put(path, value, optExpectedVersion, EnumSet.noneOf(CreateOption.class));}public final CompletableFuture<Stat> put(String path, byte[] data, Optional<Long> optExpectedVersion,EnumSet<CreateOption> options) {// Ensure caches are invalidated before the operation is confirmedreturn storePut(path, data, optExpectedVersion, options).thenApply(stat -> {NotificationType type = stat.getVersion() == 0 ? NotificationType.Created: NotificationType.Modified;if (type == NotificationType.Created) {existsCache.synchronous().invalidate(path);String parent = parent(path);if (parent != null) {childrenCache.synchronous().invalidate(parent);}}metadataCaches.forEach(c -> c.invalidate(path));return stat;});}
继续看ZKMetadataStore#storePut操作
public CompletableFuture<Stat> storePut(String path, byte[] value, Optional<Long> optExpectedVersion,EnumSet<CreateOption> options) {CompletableFuture<Stat> future = new CompletableFuture<>();//核心方法storePutInternal(path, value, optExpectedVersion, options, future);return future;}进去看ZKMetadataStore#storePutInternal实现
private void storePutInternal(String path, byte[] value, Optional<Long> optExpectedVersion,EnumSet<CreateOption> options, CompletableFuture<Stat> future) {boolean hasVersion = optExpectedVersion.isPresent();int expectedVersion = optExpectedVersion.orElse(-1L).intValue();try {if (hasVersion && expectedVersion == -1) {CreateMode createMode = getCreateMode(options);ZkUtils.asyncCreateFullPathOptimistic(zkc, path, value, ZooDefs.Ids.OPEN_ACL_UNSAFE,createMode, (rc, path1, ctx, name) -> {execute(() -> {Code code = Code.get(rc);if (code == Code.OK) {future.complete(new Stat(name, 0, 0, 0, createMode.isEphemeral(), true));} else if (code == Code.NODEEXISTS) {// We're emulating a request to create node, so the version is invalidfuture.completeExceptionally(getException(Code.BADVERSION, path));} else if (code == Code.CONNECTIONLOSS) {// There is the chance that we caused a connection reset by sending or requesting a batch// that passed the max ZK limit. Retry with the individual operationslog.warn("Zookeeper connection loss, storePut {}, retry after 100ms", path);executor.schedule(() ->storePutInternal(path, value, optExpectedVersion, options, future),100, TimeUnit.MILLISECONDS);} else {future.completeExceptionally(getException(code, path));}}, future);}, null);} else {//核心操作zkc.setData(path, value, expectedVersion, (rc, path1, ctx, stat) -> {execute(() -> {Code code = Code.get(rc);if (code == Code.OK) {future.complete(getStat(path1, stat));} else if (code == Code.NONODE) {if (hasVersion) {// We're emulating here a request to update or create the znode, depending on// the versionfuture.completeExceptionally(getException(Code.BADVERSION, path));} else {// The z-node does not exist, let's create it firstput(path, value, Optional.of(-1L)).thenAccept(s -> future.complete(s)).exceptionally(ex -> {future.completeExceptionally(ex.getCause());return null;});}} else if (code == Code.CONNECTIONLOSS) {// There is the chance that we caused a connection reset by sending or requesting a batch// that passed the max ZK limit. Retry with the individual operationslog.warn("Zookeeper connection loss, storePut {}, retry after 100ms", path);executor.schedule(() -> storePutInternal(path, value, optExpectedVersion, options, future),100, TimeUnit.MILLISECONDS);} else {future.completeExceptionally(getException(code, path));}}, future);}, null);}} catch (Throwable t) {future.completeExceptionally(new MetadataStoreException(t));}}
继续进入看ZooKeeper#setData的逻辑
public void setData(String path, byte[] data, int version, StatCallback cb, Object ctx) {PathUtils.validatePath(path);String serverPath = this.prependChroot(path);RequestHeader h = new RequestHeader();h.setType(5);SetDataRequest request = new SetDataRequest();request.setPath(serverPath);request.setData(data);request.setVersion(version);SetDataResponse response = new SetDataResponse();this.cnxn.queuePacket(h, new ReplyHeader(), request, response, cb, path, serverPath, ctx, (ZooKeeper.WatchRegistration)null);}
走到这里基本就差不多结束了,就是调用zookeeper创建
接下来看看Topic删除的代码实现,为了避免迷路,一样先看看调用栈
删除
校验
删除Topic相关策略
调用BK删除schema数据
调用BK删除Topic数据
删副本
删producers
删subscriptions没找到删zk数据的地方,是否有定时任务一起删?PersistentTopics#deleteTopicPersistentTopic#delete疑问以及答案
在学习的过程中咱们的脑海中会诞生很多宝贵的疑问,以下是博主的想法也当作是留给读者的一份“考核”,可以尝试解答以及深入思考
Topic存在zk如何避免 zk成为性能瓶颈
对Topic进行变更后,如何同步给其他的Broker,分区分配给Broker的策略是
创建Topic的模型(包含创建流程、同步给其他服务流程、选定owner流程)
zk和 MetadataCache的关系是什么
bk是以什么样的数据模型存的Topic数据,删的时候是如何删的
如果是跨集群多副本的Topic,删除过程如何回收其他集群的副本?
pulsar的Topic可以被close吗,什么场景下会被使用?
pulsar如何避免大量删Topic时对线上稳定性有影响
pulsar可否像kafka一样指定分区分配方案,可以的话应该如何操作
没找到删zk数据的地方,是否有定时任务一起删?
Topic存在zk如何避免 zk成为性能瓶颈答:加Cache
对Topic进行变更后,如何同步给其他的Broker,分区分配给Broker的策略是
创建Topic的模型(包含创建流程、同步给其他服务流程、选定owner流程)
zk和 MetadataCache的关系是什么答:MetadataCache是为了避免高频访问zk导致的性能瓶颈从而增加的一层本地缓存
bk是以什么样的数据模型存的Topic数据,删的时候是如何删的
如果是跨集群多副本的Topic,删除过程如何回收其他集群的副本?
pulsar的Topic可以被close吗,什么场景下会被使用?
pulsar如何避免大量删Topic时对线上稳定性有影响
写在最后
参考资料
- http://matt33.com/2018/06/18/topic-create-alter-delete/
相关文章:
pulsar原来是这样操作topic的
本篇主要讲述pulsar topic部分,主要从设计以及源码的视角进行讲述。在pulsar中,一个Topic的新建、扩容以及删除操作都是由Broker来处理的,而Topic相关的数据是存储在zookeeper上的。本篇文章模拟一个高效的学习流程进行展开 介绍使用方式(To…...

日常工作 经验总结
1,在使用vue2开发项目时,快捷有效的组件化component 若有参数传递时,可以通过这样传递 在component中: 2,上拉加载,下拉刷新 若是使用局部进行上拉加载 下拉刷新 且需要用到scroll-view时 那么需要切记scroll-view在内被mescroll-uni包裹。若场景有限 对于无数据显示…...

【Proteus仿真】【Arduino单片机】水箱液位监控系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真Arduino单片机控制器,使用LCD1602液晶、按键、蜂鸣器、液位传感器、ADC转换器、水泵等。 主要功能: 系统运行后,LCD1602显示当前水位、上下限阈…...
【已解决】若依系统前端打包后,部署在nginx上,点击菜单错误:@/views/system/role/index
上面错误,是因为/views/system/role/index动态路由按需加载时候,错误导致。 解决办法: 如果您的前端项目访问时候,需要带有项目名称的话,参考凯哥上一篇文章:【已解决】若依前后端分离版本࿰…...

Java中compareTo方法使用
compareTo方法 1. compareTo方法参数2. compareTo方法返回值3. String类型使用CompareTo方法进行比较 compareTo 是实例方法,只能对象调用。所以不能比较基本类型 1. compareTo方法参数 public int compareTo(参数类型 值) {... }参数类型可以是一个 Byte, Double…...

【霹雳吧啦】手把手带你入门语义分割の番外11:U2-Net 源码讲解(PyTorch)—— 代码的使用
目录 前言 Preparation 一、U2-Net 网络结构图 二、U2-Net 网络源代码 1、train.py (1)parse_args 参数 (2)SODPresetTrain 类 (3)SODPresetEval 类 (4)main 函数 &#x…...

威尔仕2023年的统计数据
威尔仕健身房更新了2023年的统计数据,大家可以猜一猜我是哪一个称号?虽然小伙伴们的健身时长各有不同,有时候在课程中我也会分享自己健身的案例,看似一个简单的增强环路,旁边会有很多的调节环路来限制增强环路的增长&a…...
Spring——Spring基于注解的IOC配置
基于注解的IOC配置 学习基于注解的IOC配置,大家脑海里首先得有一个认知,即注解配置和xml配置要实现的功能都是一样的,都是要降低程序间的耦合。只是配置的形式不一样。 1.创建工程 1.1 pom.xml <?xml version"1.0" encoding…...
springbean生命周期类)
spring常用注解(一)springbean生命周期类
一、PostConstruct: 被PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器调用一次,类似于servlet的inti()方法。被PostConstruct修饰的方法会在构造函数之后,init()方法之前运行。...
【软件测试】2024年准备中/高级测试岗技术面试...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、软件测试基础知…...
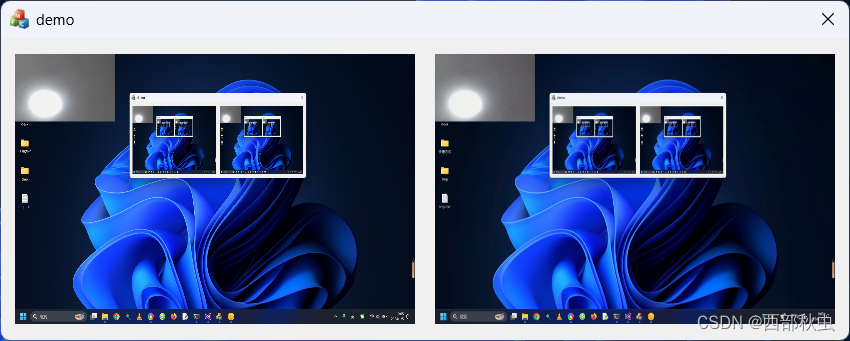
第11课 实现桌面与摄像头叠加
在上一节,我们实现了桌面捕获功能,并成功把桌面图像和麦克风声音发送给对方。在实际应用中,有时候会需要把桌面与摄像头图像叠加在一起发送,这节课我们就来看下如何实现这一功能。 1.备份与修改 备份demo10并修改demo10为demo11…...
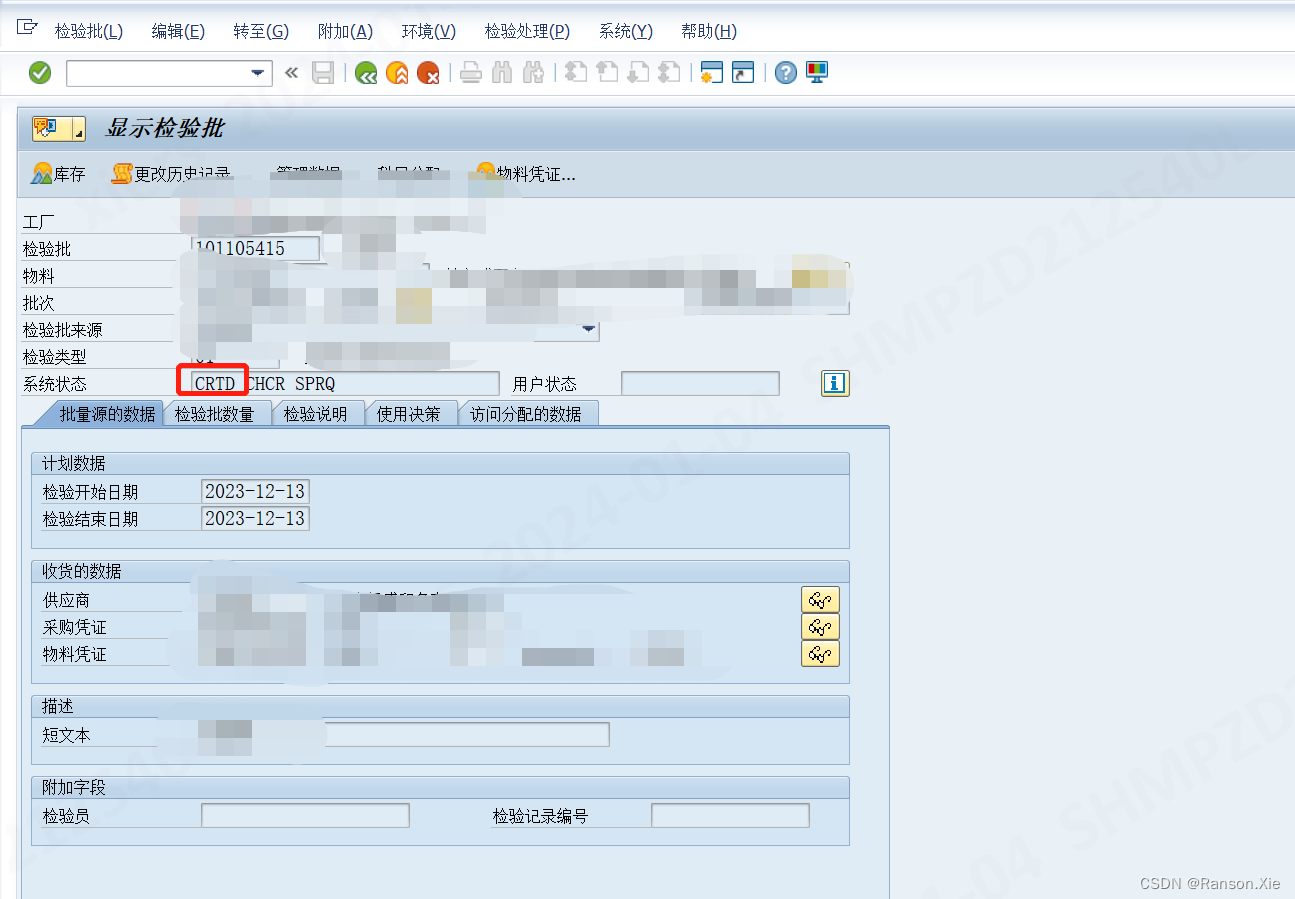
SAP 检验批状态修改(QA32质检放行报错:BS002 不允许 “访问使用决定“ (INL 101105415 ))
问题:在做QA32进行使用决策处理的时候发现这个报错: BS002 不允许 "访问使用决定" (INL 101105415 ) 原因:是因为这个检验批的状态已经变成Relase的状态了,但是决策还没有做 解决方案:将这个检验批的REL状态…...

华为交换机如何同时配置多个端口参数
知识改变命运,技术就是要分享,有问题随时联系,免费答疑,欢迎联系! 华为交换机如何批量配置端口 使用端口组功能可以实现一次配置多个端口,以减少重复配置工作。端口组分为如下两种方式: 永久端口组。如果用户需要多次…...
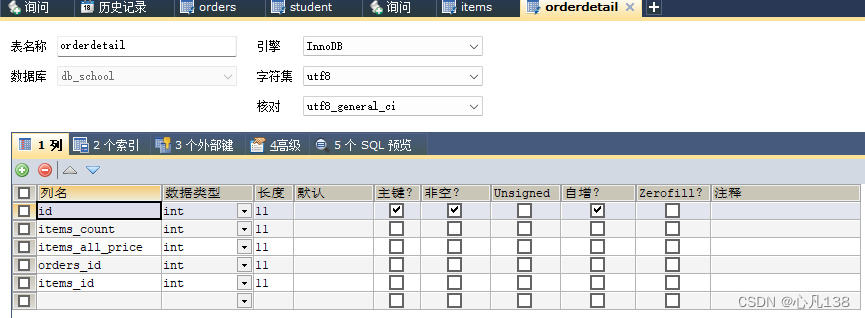
Mybatis之多表查询
目录 一、简介 1、使用嵌套查询: 2、使用多个 SQL 语句: 3、使用关联查询: 4、使用自定义映射查询: 二、业务场景 三、示例 1、一对一查询 2、一对多查询 一、简介 MyBatis 是一个优秀的持久层框架,它提供了强大的支持来执…...
部署node.js+express+mongodb(更新中)
1-Linux服务器部署MongoDB 1.升级 yum -y update 2.下载MongoDB安装包 3.上传安装包 上传目录 : /usr/local/ 2-配置MongoDB环境变量并启动 1.配置环境变量全局启动 vi ~/.bash_profile 使用i命令进入编辑模式 添加: export PATH/usr/local/mongodb/bin:$P…...

百度CTO王海峰:文心一言用户规模破1亿
“文心一言用户规模突破1亿。”12月28日,百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰在第十届WAVE SUMMIT深度学习开发者大会上宣布。会上,王海峰以《文心加飞桨,翩然赴星河》为题作了主旨演讲,分享了飞桨和文…...

简单最短路径算法
前言 图的最短路径算法主要包括: 有向无权图的单源最短路径 宽度优先搜索算法(bfs) 有向非负权图的单源最短路径 迪杰斯特拉算法(Dijkstra) 有向有权图的单源最短路径 贝尔曼福特算法(Bellman-Ford&#…...

答案解析——C语言—第3次作业—算术操作符与关系操作符
本次作业链接如下: C语言—第3次作业—算术操作符与关系操作符 1.在C语言中,表达式 7 / 2 的结果是多少? - A) 3.5 - B) 3 - C) 4 - D) 编译错误 答案:B) 3 解析: 在C语言中,当两个整数进行除法运算时&…...
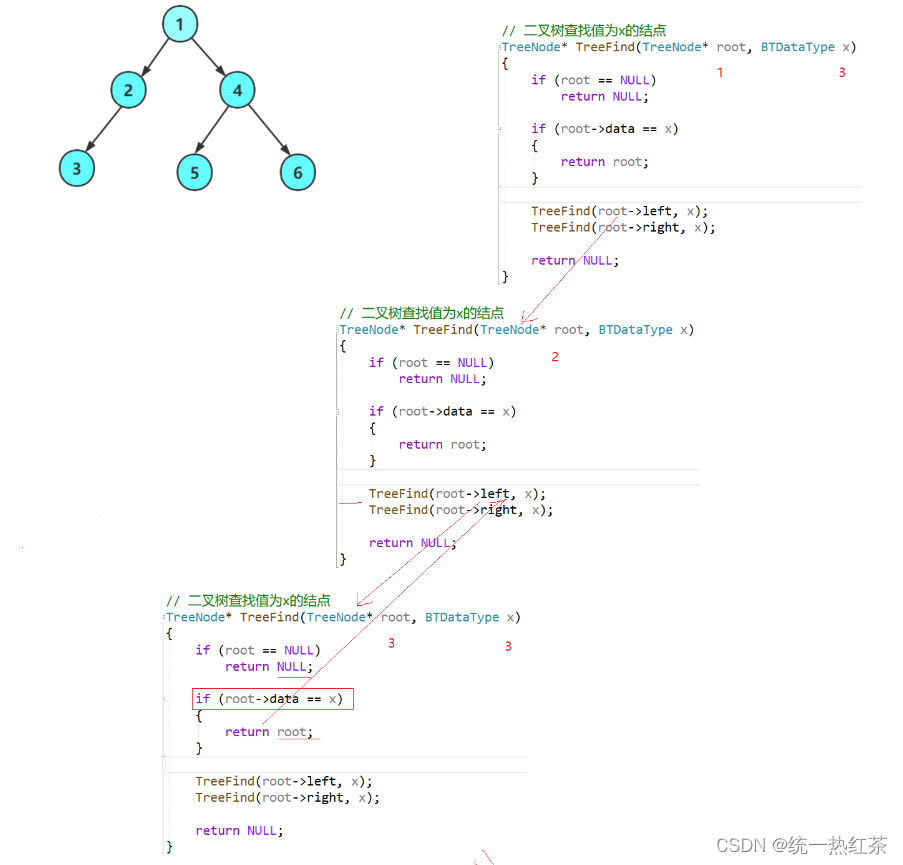
【数据结构】二叉树的链式实现
树是数据结构中非常重要的一种,在计算机的各方个面都有他的身影 此篇文章主要介绍二叉树的基本操作 目录 二叉树的定义:二叉树的创建:二叉树的遍历:前序遍历:中序遍历:后序遍历: 二叉树节点个数…...
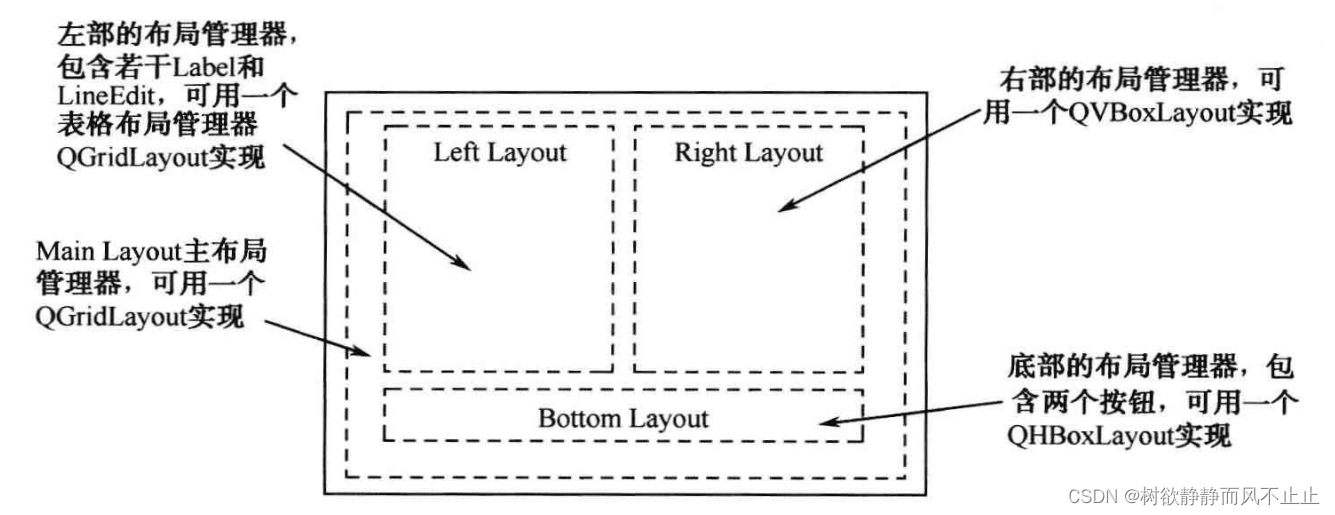
八、QLayout 用户基本资料修改(Qt5 GUI系列)
目录 一、设计需求 二、实现代码 三、代码解析 四、总结 一、设计需求 在很多应用程序中会有用户注册或用户编辑信息等界面。本文就设计一个用户信息编辑界面。要求包含用户名、姓名、性别、部门、年龄、头像、个人说明等信息。 二、实现代码 #ifndef DIALOG_H #define D…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...