竞赛保研 基于机器视觉的银行卡识别系统 - opencv python
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的银行卡识别算法设计
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 算法设计流程
银行卡卡号识别技术原理是先对银行卡图像定位,保障获取图像绝对位置后,对图像进行字符分割,然后将分割完成的信息与模型进行比较,从而匹配出与其最相似的数字。主要流程图如图

1.银行卡号图像
由于银行卡卡号信息涉及个人隐私,作者很难在短时间内获取大量的银行卡进行测试和试验,本文即采用作者个人及模拟银行卡进行卡号识别测试。
2.图像预处理
图像预处理是在获取图像后必须优先进行的技术性处理工作,先对银行卡卡号图像进行色彩处理,具体做法与流程是先将图像灰度化,去掉图像识别上无用的信息,然后利用归一化只保留有效的卡号信息区域。
3.字符分割
字符分割是在对图像进行预处理后,在获取有效图像后对有效区域进行进一步细化处理,将图像分割为最小识别字符单元。
4.字符识别
字符识别是在对银行卡卡号进行字符分割后,利用图像识别技术来对字符进行分析和匹配,本文作者利用的模板匹配方法。
2.1 颜色空间转换
由于银行卡卡号识别与颜色无关,所以银行卡颜色是一个无用因素,我们在图像预处理环节要先将其过滤掉。另外,图像处理中还含有颜色信息,不仅会造成空间浪费,增加运算量,降低系统的整体效率,还会给以后的图像分析和处理带来干扰。因此,有必要利用灰度处理来滤除颜色信息。
灰度处理的实质是将颜色信息转化为亮度信息,即将原始的三维颜色信息还原为一维亮度信息。灰度化的思想是用灰度值g来表示原始彩色图像的R(绿色)、g(红色)和B(蓝色)分量的值,具体的流程设计如图
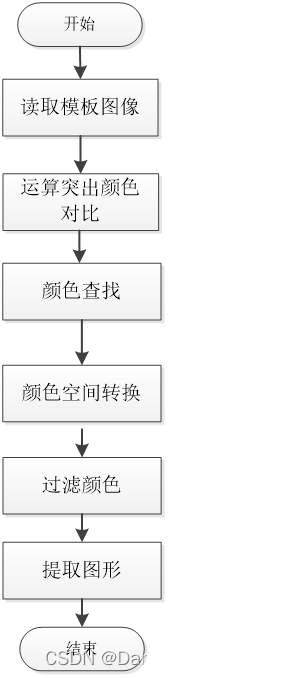
2.2 边缘切割
对于采集到的银行卡号图像,由于背景图案的多样性和卡号字体的不同,无法直接对卡号图像进行分割。分割前要准确定位卡号,才能得到有效区域。数字字符所在的区域有许多像素。根据该特征,通过设置阈值来确定原始图像中卡号图像的区域。银行卡图像的切边处理设计如图
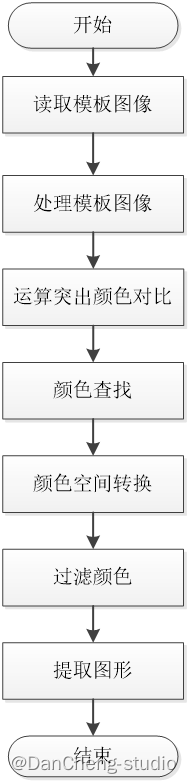
2.3 模板匹配
模板匹配是一种将需要识别的字符与已有固定模板进行匹配的算法技术,该技术是将已经切割好的字符图像逐个与模板数字图像进行对比分析,其原理就是通过数字相似度来衡量两个字符元素,将目标字符元素逐个与模板数字图像进行匹配,找到最接近的数字元素即可。匹配计算量随特征级别的增加而减少。根据第一步得到的特征,选择第二种相关计算方法来解决图像匹配问题。银行卡模板匹配流程设计如图
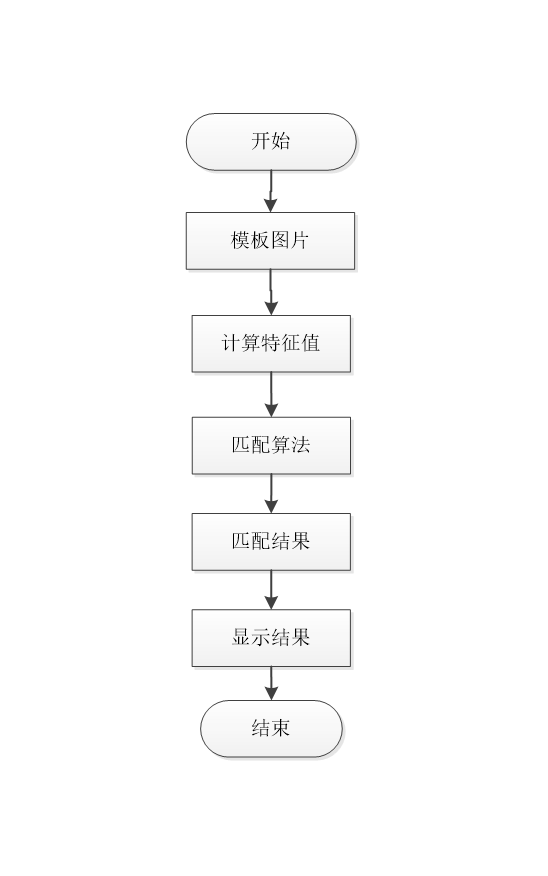
2.4 卡号识别
银行卡卡号识别有其独有的特性,因为目前市面上大多数银行卡卡号是凹凸不平的数字形式,如果使用传统的计算机字符识别技术已显然不适用,本文针对银行卡此类特点,研究了解决此类问题的识别方案。从银行卡待识别的凸凹字符进行预处理,然后根据滑块算法逐个窗口对银行卡字符进行匹配识别,卡号识别一般从切割后的图像最左端开始,设定截图选定框大小为64*48像素,因为银行卡所需要识别的字符一般为45像素左右。故而以此方式循环对卡片上所有数字进行匹配、识别,如果最小值大于设置的阈值,我们将认为这里没有字符,这是一个空白区域,并且不输出字符。同时,窗口位置J向下滑动,输出f<19&&j;+20<图像总长度并判断,最后循环得到字符数f、j。
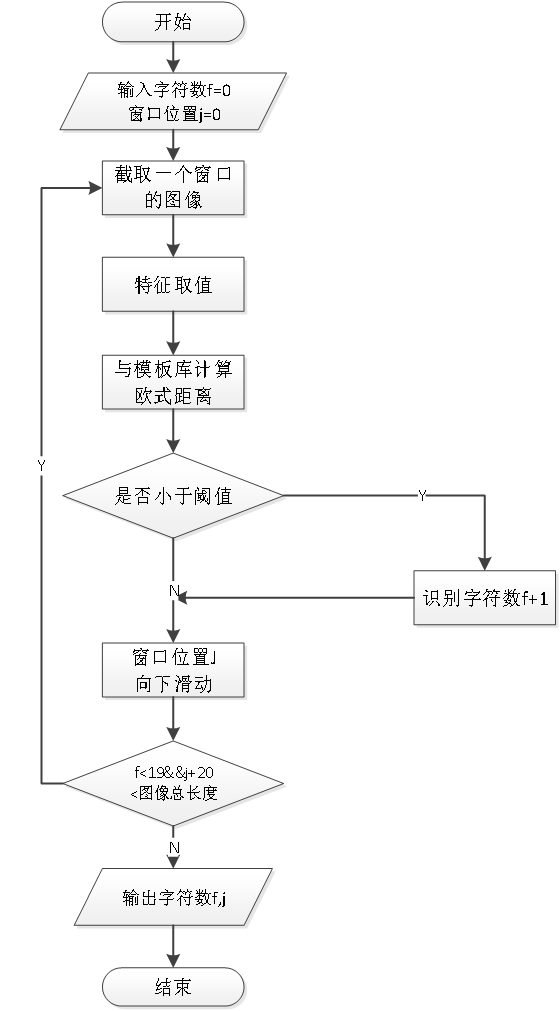
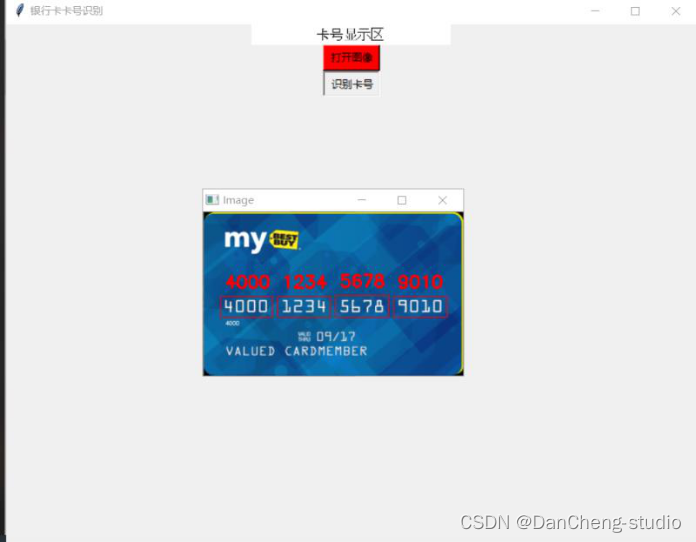
3 银行卡字符定位 - 算法实现
首先就是将整张银行卡号里面的银行卡号部分进行识别,且分出来,这一个环节学长用的技术就是faster-rcnn的方法
将目标识别部分的银行卡号部门且分出来,进行保存
主程序的代码如下(非完整代码):
#!/usr/bin/env pythonfrom __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport argparseimport osimport cv2import matplotlib.pyplot as pltimport numpy as npimport tensorflow as tffrom lib.config import config as cfgfrom lib.utils.nms_wrapper import nmsfrom lib.utils.test import im_detectfrom lib.nets.vgg16 import vgg16from lib.utils.timer import Timeros.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用config = tf.ConfigProto()config.gpu_options.per_process_gpu_memory_fraction = 0.8 # 程序最多只能占用指定gpu50%的显存config.gpu_options.allow_growth = True #程序按需申请内存sess = tf.Session(config = config)CLASSES = ('__background__','lb')NETS = {'vgg16': ('vgg16_faster_rcnn_iter_70000.ckpt',), 'res101': ('res101_faster_rcnn_iter_110000.ckpt',)}DATASETS = {'pascal_voc': ('voc_2007_trainval',), 'pascal_voc_0712': ('voc_2007_trainval+voc_2012_trainval',)}def vis_detections(im, class_name, dets, thresh=0.5):"""Draw detected bounding boxes."""inds = np.where(dets[:, -1] >= thresh)[0]if len(inds) == 0:returnim = im[:, :, (2, 1, 0)]fig, ax = plt.subplots(figsize=(12, 12))ax.imshow(im, aspect='equal')sco=[]for i in inds:score = dets[i, -1]sco.append(score)maxscore=max(sco)# print(maxscore)成绩最大值for i in inds:# print(i)score = dets[i, -1]if score==maxscore:bbox = dets[i, :4]# print(bbox)#目标框的4个坐标img = cv2.imread("data/demo/"+filename)# img = cv2.imread('data/demo/000002.jpg')sp=img.shapewidth = sp[1]if bbox[0]>20 and bbox[2]+20<width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]-20):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]if bbox[0]<20 and bbox[2]+20<width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]if bbox[0] > 20 and bbox[2] + 20 > width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0] - 20):int(bbox[2])] # 裁剪坐标为[y0:y1, x0:x1]path = 'cut1/'# 重定义图片的大小res = cv2.resize(cropped, (1000, 100), interpolation=cv2.INTER_CUBIC) # dsize=(2*width,2*height)cv2.imwrite(path+str(i)+filename, res)ax.add_patch(plt.Rectangle((bbox[0], bbox[1]),bbox[2] - bbox[0],bbox[3] - bbox[1], fill=False,edgecolor='red', linewidth=3.5))ax.text(bbox[0], bbox[1] - 2,'{:s} {:.3f}'.format(class_name, score),bbox=dict(facecolor='blue', alpha=0.5),fontsize=14, color='white')ax.set_title(('{} detections with ''p({} | box) >= {:.1f}').format(class_name, class_name,thresh),fontsize=14)plt.axis('off')plt.tight_layout()plt.draw()def demo(sess, net, image_name):"""Detect object classes in an image using pre-computed object proposals."""# Load the demo imageim_file = os.path.join(cfg.FLAGS2["data_dir"], 'demo', image_name)im = cv2.imread(im_file)# Detect all object classes and regress object boundstimer = Timer()timer.tic()scores, boxes = im_detect(sess, net, im)timer.toc()print('Detection took {:.3f}s for {:d} object proposals'.format(timer.total_time, boxes.shape[0]))# Visualize detections for each classCONF_THRESH = 0.1NMS_THRESH = 0.1for cls_ind, cls in enumerate(CLASSES[1:]):cls_ind += 1 # because we skipped backgroundcls_boxes = boxes[:, 4 * cls_ind:4 * (cls_ind + 1)]cls_scores = scores[:, cls_ind]# print(cls_scores)#一个300个数的数组#np.newaxis增加维度 np.hstack将数组拼接在一起dets = np.hstack((cls_boxes,cls_scores[:, np.newaxis])).astype(np.float32)keep = nms(dets, NMS_THRESH)dets = dets[keep, :]vis_detections(im, cls, dets, thresh=CONF_THRESH)def parse_args():"""Parse input arguments."""parser = argparse.ArgumentParser(description='Tensorflow Faster R-CNN demo')parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16 res101]',choices=NETS.keys(), default='vgg16')parser.add_argument('--dataset', dest='dataset', help='Trained dataset [pascal_voc pascal_voc_0712]',choices=DATASETS.keys(), default='pascal_voc')args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()# model pathdemonet = args.demo_netdataset = args.dataset#tfmodel = os.path.join('output', demonet, DATASETS[dataset][0], 'default', NETS[demonet][0])tfmodel = r'./default/voc_2007_trainval/cut1/vgg16_faster_rcnn_iter_8000.ckpt'# 路径异常提醒if not os.path.isfile(tfmodel + '.meta'):print(tfmodel)raise IOError(('{:s} not found.\nDid you download the proper networks from ''our server and place them properly?').format(tfmodel + '.meta'))# set configtfconfig = tf.ConfigProto(allow_soft_placement=True)tfconfig.gpu_options.allow_growth = True# init sessionsess = tf.Session(config=tfconfig)# load networkif demonet == 'vgg16':net = vgg16(batch_size=1)# elif demonet == 'res101':# net = resnetv1(batch_size=1, num_layers=101)else:raise NotImplementedErrornet.create_architecture(sess, "TEST", 2,tag='default', anchor_scales=[8, 16, 32])saver = tf.train.Saver()saver.restore(sess, tfmodel)print('Loaded network {:s}'.format(tfmodel))# # 文件夹下所有图片进行识别# for filename in os.listdir(r'data/demo/'):# im_names = [filename]# for im_name in im_names:# print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')# print('Demo for data/demo/{}'.format(im_name))# demo(sess, net, im_name)## plt.show()# 单一图片进行识别filename = '0001.jpg'im_names = [filename]for im_name in im_names:print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')print('Demo for data/demo/{}'.format(im_name))demo(sess, net, im_name)plt.show()效果如下:


4 字符分割
将切分出来的图片进行保存,然后就是将其进行切分:
主程序的代码和上面第一步的步骤原理是相同的,不同的就是训练集的不同设置
效果图如下:
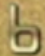
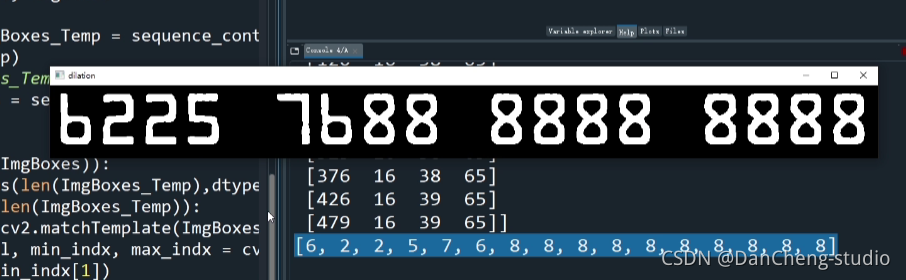
5 银行卡数字识别
仅部分代码:
import osimport tensorflow as tffrom PIL import Imagefrom nets2 import nets_factoryimport numpy as npimport matplotlib.pyplot as plt# 不同字符数量CHAR_SET_LEN = 10# 图片高度IMAGE_HEIGHT = 60# 图片宽度IMAGE_WIDTH = 160# 批次BATCH_SIZE = 1# tfrecord文件存放路径TFRECORD_FILE = r"C:\workspace\Python\Bank_Card_OCR\demo\test_result\tfrecords/1.tfrecords"# placeholderx = tf.placeholder(tf.float32, [None, 224, 224])os.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用config = tf.ConfigProto()config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 程序最多只能占用指定gpu50%的显存config.gpu_options.allow_growth = True #程序按需申请内存sess = tf.Session(config = config)# 从tfrecord读出数据def read_and_decode(filename):# 根据文件名生成一个队列filename_queue = tf.train.string_input_producer([filename])reader = tf.TFRecordReader()# 返回文件名和文件_, serialized_example = reader.read(filename_queue)features = tf.parse_single_example(serialized_example,features={'image' : tf.FixedLenFeature([], tf.string),'label0': tf.FixedLenFeature([], tf.int64),})# 获取图片数据image = tf.decode_raw(features['image'], tf.uint8)# 没有经过预处理的灰度图image_raw = tf.reshape(image, [224, 224])# tf.train.shuffle_batch必须确定shapeimage = tf.reshape(image, [224, 224])# 图片预处理image = tf.cast(image, tf.float32) / 255.0image = tf.subtract(image, 0.5)image = tf.multiply(image, 2.0)# 获取labellabel0 = tf.cast(features['label0'], tf.int32)return image, image_raw, label0# 获取图片数据和标签image, image_raw, label0 = read_and_decode(TFRECORD_FILE)# 使用shuffle_batch可以随机打乱image_batch, image_raw_batch, label_batch0 = tf.train.shuffle_batch([image, image_raw, label0], batch_size=BATCH_SIZE,capacity=50000, min_after_dequeue=10000, num_threads=1)# 定义网络结构train_network_fn = nets_factory.get_network_fn('alexnet_v2',num_classes=CHAR_SET_LEN * 1,weight_decay=0.0005,is_training=False)with tf.Session() as sess:# inputs: a tensor of size [batch_size, height, width, channels]X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])# 数据输入网络得到输出值logits, end_points = train_network_fn(X)# 预测值logits0 = tf.slice(logits, [0, 0], [-1, 10])predict0 = tf.argmax(logits0, 1)# 初始化sess.run(tf.global_variables_initializer())# 载入训练好的模型saver = tf.train.Saver()saver.restore(sess, '../Cmodels/model/crack_captcha1.model-6000')# saver.restore(sess, '../1/crack_captcha1.model-2500')# 创建一个协调器,管理线程coord = tf.train.Coordinator()# 启动QueueRunner, 此时文件名队列已经进队threads = tf.train.start_queue_runners(sess=sess, coord=coord)for i in range(6):# 获取一个批次的数据和标签b_image, b_image_raw, b_label0 = sess.run([image_batch,image_raw_batch,label_batch0])# 显示图片img = Image.fromarray(b_image_raw[0], 'L')plt.imshow(img)plt.axis('off')plt.show()# 打印标签print('label:', b_label0)# 预测label0 = sess.run([predict0], feed_dict={x: b_image})# 打印预测值print('predict:', label0[0])# 通知其他线程关闭coord.request_stop()# 其他所有线程关闭之后,这一函数才能返回coord.join(threads)最终实现效果:
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛保研 基于机器视觉的银行卡识别系统 - opencv python
1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的银行卡识别算法设计 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng…...

书摘:C 嵌入式系统设计模式 04
本书的原著为:《Design Patterns for Embedded Systems in C ——An Embedded Software Engineering Toolkit 》,讲解的是嵌入式系统设计模式,是一本不可多得的好书。 本系列描述我对书中内容的理解。 实现类的最简单方法是使用文件作为封装…...

C 练习实例16 - 最大公约数和最小公倍数
题目:输入两个正整数a和b,求其最大公约数和最小公倍数 数学:最大公约数*最小公倍数a*b 例如:a16,b20。最小公倍数80,最大公约数4。80*416*20。 算法:辗转相除法,又称欧几里德算法…...

GAN-概念和应用场景
概念和应用 生成对抗网络 (GAN) 的 18 个令人印象深刻的应用 by 杰森布朗利 on July 12, 2019 in 生成对抗网络110 鸣叫 共享 生成对抗网络 (GAN) 是一种用于生成建模的神经网络架构。 生成式建模涉及使用模型生成可…...

LeetCode(36)有效的数独 ⭐⭐
请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。 数字 1-9 在每一行只能出现一次。数字 1-9 在每一列只能出现一次。数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图) 注…...

用LCD显示字符‘A‘
#include<reg51.h> //包含单片机寄存器的头文件 #include<intrins.h> //包含_nop_()函数定义的头文件 sbit RSP2^0; //寄存器选择位,将RS位定义为P2.0引脚 sbit RWP2^1; //读写选择位,将RW位定义为P2.1引脚 sbit EP2^2; //使能…...
)
Zookeeper相关问题及答案(2024)
1、ZooKeeper是什么?它的主要用途是什么? ZooKeeper 是一个由 Apache 预先开发和维护的开源服务器,用于协调分布式应用程序。它是一个集中式服务,为分布式应用提供一致性保障,配置管理,命名,同…...

1.大数据概述
目录 概述hadoophadoop 模块hadoop 发行版apache社区版本CDP(CDHHDP)其它云产商框架选择 hadoop 安装 结束 概述 先了解几个常用的网站 apache 官网hadoop 官网hadoop githubhttps://github.com/apache/xxx [https://github.com/apache/spark (example)] hadoop hadoop 模块…...

NGUI基础-Widget
目录 Widget是什么 Widget组件包含的属性 Pivot Depth Size snap Aspect Free Based on Width Based on Height Widget是什么 在Unity UI系统中,"Widget"是指UI元素的基类,它为UI元素提供了位置、大小和锚点等基本属性。通过使用&qu…...

SpringBoot集成沙箱支付
前言 支付宝沙箱支付(Alipay Sandbox Payment)是支付宝提供的一个模拟支付环境,用于开发和测试支付宝支付功能的开发者工具。在真实的支付宝环境中进行支付开发和测试可能涉及真实资金和真实用户账户,而沙箱环境则提供了一个安全…...
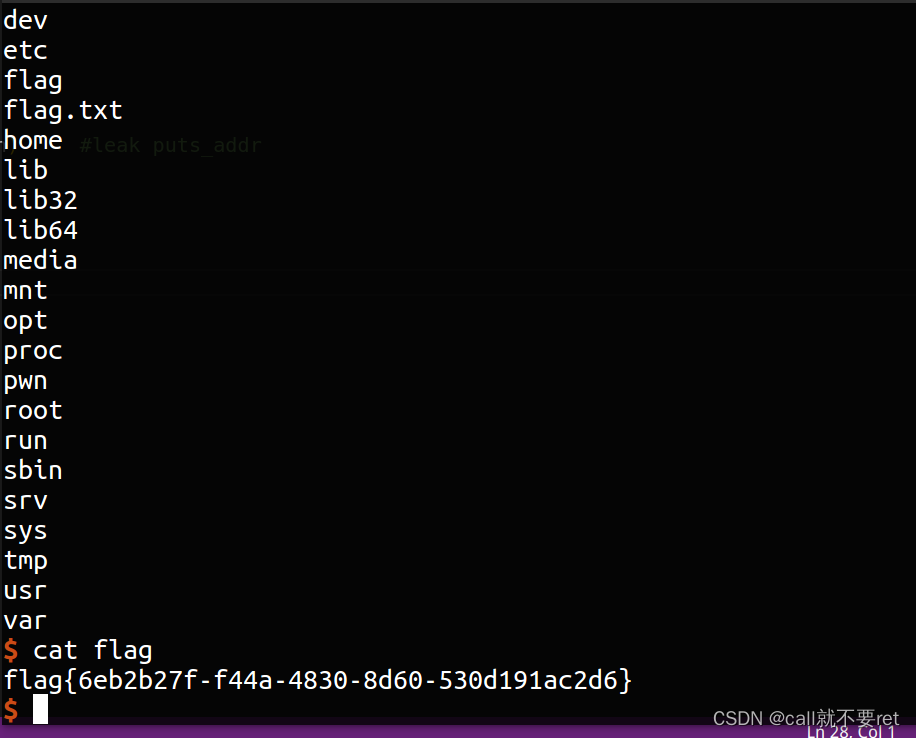
BUUCTF--gyctf_2020_borrowstack1
这是一题栈迁移的题目,先看看保护: 黑盒测试: 用户可输入两次内容,接着看看IDA中具体程序流程: 我们看到溢出内容只有0x10的空间给我们布局,这显然是不足以我们布置rop的。因此肯定就是栈迁移了。迁到什么地…...

图像分割-Grabcut法(C#)
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 本文的VB版本请访问:图像分割-Grabcut法-CSDN博客 GrabCut是一种基于图像分割的技术,它可以用于将图像中的…...

C# WPF上位机开发(Web API联调)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 很多时候,客户需要开发的不仅仅是一个上位机系统,它还有其他很多配套的系统或设备,比如物流小车、立库、数字孪…...

c语言:用结构体求平均分|练习题
一、题目 用c语言的结构体,求4位学生成绩的平均分 如图: 二、代码截图【带注释】 三、源代码【带注释】 #include <stdio.h> float aver();//声明平均分函数 void printScore();//声明打印函数 //设置结构体, struct student { …...

echarts 仪表盘进度条 相关配置
option {series: [{type: gauge,min: 0,//最大值max: 100, //最小值startAngle: 200,//仪表盘起始角度。圆心 正右手侧为0度,正上方为90度,正左手侧为180度。endAngle: -20,//仪表盘结束角度splitNumber: 100, //仪表盘刻度的分割段数itemStyle: {color…...

Simpy:Python之离散时间序列仿真
Simpy:Python之离散时间序列仿真 文章目录 Simpy:Python之离散时间序列仿真简介基本使用语法简单案例在数据中心中的应用案例 简介 下载地址网站: https://pypi.org/project/simpy/ 有关教程网站: https://simpy.readthedocs.…...

连接GaussDB(DWS)报错:Invalid or unsupported by client SCRAM mechanisms
用postgres方式连接GaussDB(DWS)报错:Invalid or unsupported by client SCRAM mechanisms 报错内容 [2023-12-27 21:43:35] Invalid or unsupported by client SCRAM mechanisms org.postgresql.util.PSQLException: Invalid or unsupported by client SCRAM mec…...
--标定数据固化方法简介)
汽车标定技术(十四)--标定数据固化方法简介
目录 1.标定数据固化方法 1.1 基于XCP固化 1.2 基于UDS固化 2. 具体实现形式 2.1 CAN...

2024年关键技术发展战略趋势前瞻
技术趋势在不断变化,但总的趋势是技术日益深入人类生活的方方面面,这些趋势可能会对未来的科技发展和人类生活产生深远影响,以下是预计今年将塑造未来的一些关键技术趋势。 更多的人将采用人工智能和机器学习 人工智能(AI)和机器学习(ML)不…...
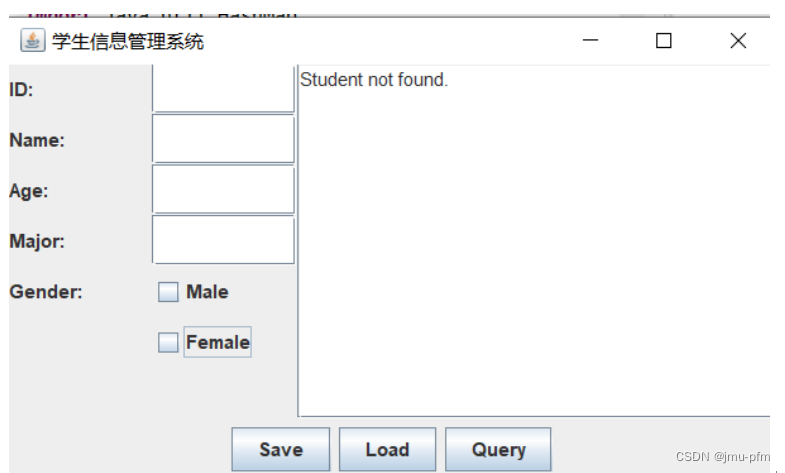
Java程序设计——GUI设计
一、目的 通过用户图形界面设计,掌握JavaSwing开发的基本方法。 二、实验内容与设计思想 实验内容: 课本验证实验: Example10_6 图 1 Example10_7 图 2 图 3 Example10_15 图 4 设计思想: ①学生信息管理系统:…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...