Redis(一)
1、redis
Redis是一个完全开源免费的高性能(NOSQL)的key-value数据库。它遵守BSD协议,使用ANSI C语言编写,并支持网络和持久化。Redis拥有极高的性能,每秒可以进行11万次的读取操作和8.1万次的写入操作。它支持丰富的数据类型,包括String、Hash、List、Set和Ordered Set,并且所有的操作都是原子性的。此外,Redis还提供了多种特性,如发布/订阅、通知、key过期等。Redis采用自己实现的分离器来实现高速的读写操作,效率非常高。Redis是一个简单、高效、分布式、基于内存的缓存工具,通过网络连接提供Key-Value式的缓存服务。
特性
-
分布式缓存
-
内存存储
-
持久化
-
高可用架构搭配
-
缓存穿透、击穿、雪崩
-
分布式锁
-
队列
1.1、下载安装
1.1.1、window版本
是这样的,redis的开发者没有提供redis的windows版本,但是有大佬在github提供啦window版本的redis,所以就先说一下哦window版的下载安装,下载地址Releases · tporadowski/redis (github.com),然后解到你指定的目录就可以。

然后启动的话可以直接双击,先启动redis的服务端,然后是访客端。也可以使用命令的方式,在当前目录下打开命令行窗口。
D:\Redis>redis-server.exe redis.windows.conf然后访客端的启动
#没有修改配置文件中的代码的启动方式
redis-cli -h localhost -p 6379
#修改后
redis-cli -h localhost -p 6379 -a 123456端口号其实可以不指定,默认也是6379,这里的-a就是你修改配置文件中指定的密码,想要修改密码的话可以打开配置文件。

1.1.2、linux版本
然后linux系统的安装有一定的前置条件,比如拥有gcc编译程序,查看当前系统是否拥有gcc编译程序,使用命令gcc -v查看 。
 这里已经安装了,如果是centos7应该是内置的叭,然后如果没有的话可以安装gcc,使用以下命令。
这里已经安装了,如果是centos7应该是内置的叭,然后如果没有的话可以安装gcc,使用以下命令。
[root@localhost redis]# yum -y install gcc-c++然后就是linux版本的下载和安装,下载地址Download | Redis,下载后上传到你的linux系统,这里建议弄一个统一的目录去管理你所安装的软件:
将上传的文件解压到你指定的目录
[root@localhost redis]# tar -zxvf redis-7.2.3.tar.gz 切换到你解压后的文件
[root@localhost redis]# cd redis-7.2.3/然后编译安装
[root@localhost redis-7.2.3]# make && make install
查看安装后的目录:
cd usr/loacl/bin
-
redis-benchmark:性能测试工具
-
redis-check-aof:修复有问题的aof文件
-
redis-check-dump:修复有问题的dump.rdp文件
-
redis-cli:redis的客户端
-
redis-setinel:redis集群使用
-
redis-server:redis的服务器启动命令
修改配置文件:
这里不建议直接在原本的配置文件中修改数据,我们可以在当前的文件夹下创建一个存放我们配置文件的地方,然后将原本的配置文件复制一份然后进行数据的修改。
#创建目录
mkdir redisconf#复制文件
cp redis.conf redisconf接下来就是修改配置文件了,redis.conf配置文件,改完后确保生效,记得重启,记得重启
-
1 默认daemonize no 改为 daemonize yes
-
2 默认protected-mode yes 改为 protected-mode no
-
3 默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问)或改成本机IP地址,否则影响远程IP连接
-
4 添加redis密码 改为 requirepass 你自己设置的密码
这里要使用vim编辑器,使用中的可能会用到的命令
#显示行号
set nu#快速查找
/ 查找的关键字#对于查询结果的查看
使用 快捷键 n/N 两个都可以,一个向上一个向下修改过后,然后就是启动测试
#这里的配置文件是要我们指定,就是刚刚修改后的配置文件
[root@localhost redisconf]# redis-server /software/redis/redis-7.2.3/redisconf/redis.conf #查看启动情况
ps -ef|grep redis|grep -v grep#然后启动客户端 这里端口可以不指定,然后ip的话,我刚刚指定的是自己ip
redis-cli -a 密码 -p 6379 -h 192.168.200.88#当然不指定-a 后的密码的话,也可以进入界面,但是执行操作的时候会显示没有权限,然后可以使用
auth 密码 来进行认证!#测试
ping
#输出PONG,ok!!!#客户端退出命令
exit#单实例关闭
redis-cli -a 密码 shutdown#多实例关闭,指定端口关闭
redis-cli -p 6379 shutdown1.1.3、卸载
卸载就很简单,首先关闭服务,然后就是删除/usr/local/bin 下的所有关于redis的文件
rm -rf /usr/local/bin redis*2、redis中的数据类型
首先要明白的是,redis中的数据类型指的是value,对于key的话只有一个String类型,先总体的了解一下!
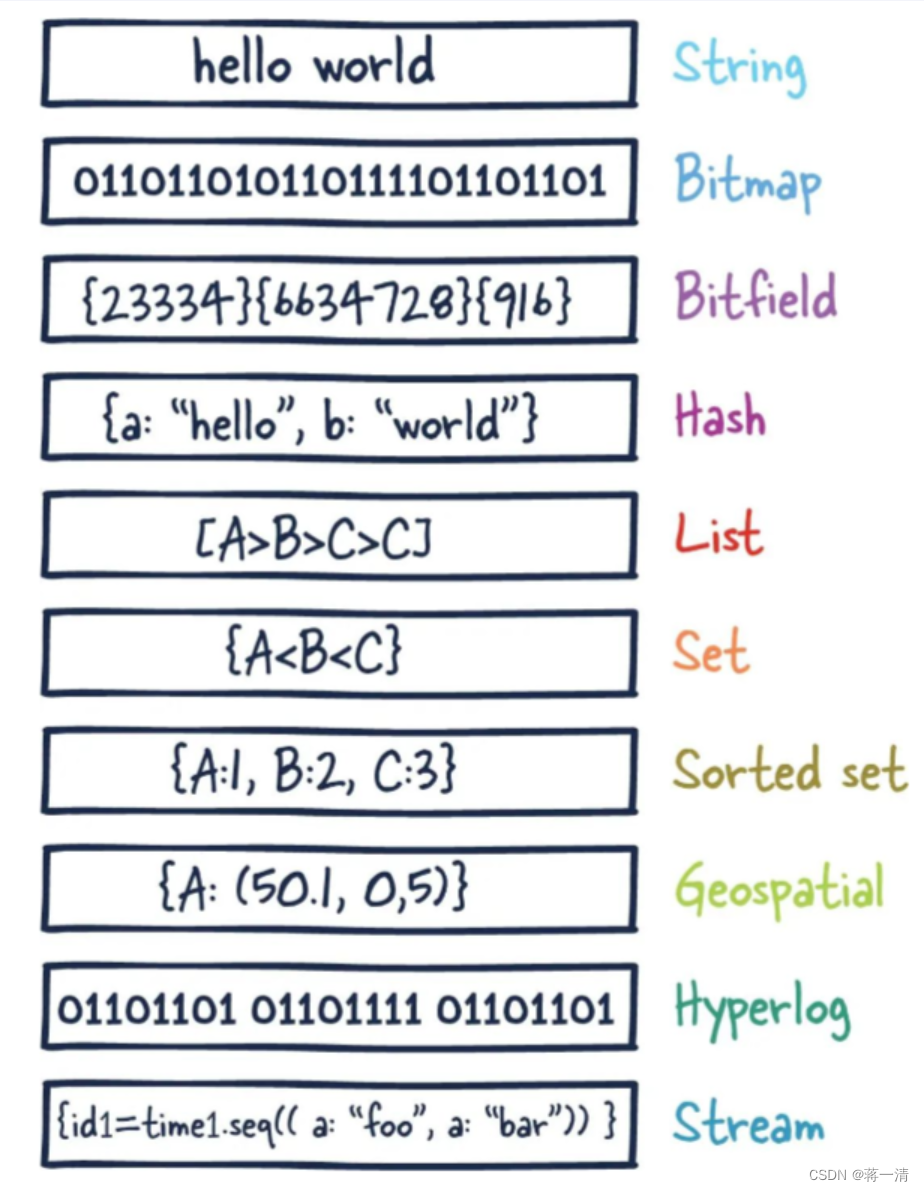
2.1、redis字符串
string是redis最基本的类型,一个key对应一个value。string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象 。一个redis中字符串value最多可以是512M。
操作命令
2.1.1、set、setnx、get
SET 命令用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型。
例子:
set key valuesetnx命令在指定的 key 不存在时,为 key 设置指定的值。如果存在则失败
例子
setnx k1 v1
#ok
setnx k1 v11
#integer 1get命令返回 key 的值,如果 key 不存在时,返回 nil。 如果 key 不是字符串类型,那么返回一个错误。
例子:
get key2.1.2、mset、mget、msetnx
mset命令用于同时设置一个或多个 key-value 对,就是很牛如果 key 已经存储其他值, SET 就覆写旧值,且无视类型。就是每一次都是ok!!!
例子:
Mset k1 v1 k2 v2
Mset k1 v1111 k3 v3
#查询
get k1 是v1111Mget 命令返回所有(一个或多个)给定 key 的值。 如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil。
例子
mget k1 k2msetnx所有给定 key 都不存在时,同时设置一个或多个 key-value 对。如果批量中有已经存在的key,那么这次批量就都不成功
例子
msetnx k1 v1 k2 v2
#返回ok
msetnx k1 v11 k3 v3
#返回(integer) 02.1.3、getrange、setrange
Getrange 命令用于获取存储在指定 key 中字符串的子字符串。字符串的截取范围由 start 和 end 两个偏移量决定(包括 start 和 end 在内),当start为0,end 为-1的时候取全部的字符串。
语法: GETRANGE KEY_NAME start end
例子
SET mykey "This is my test key"
getrange 0 3
#输出This
getrange 0 -1
#输出This is my test keySetrange 命令用指定的字符串覆盖给定 key 所储存的字符串值,覆盖的位置从偏移量 offset 开始。
语法:SETRANGE KEY_NAME OFFSET VALUE
例子
SET mykey "This is my test key"
#假设想让my替换成you
setrange 8 you
> get mykey
This is youtest key2.1.4、incr、incrby、incrbyfloat
incr命令将 key 中储存的数字值增一。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
语法:INCR KEY_NAME
例子:
> set num 1
OK
> incr num
2
> incr num
3
#非数值
> set num2 sss
OK
> incr num2
ERR value is not an integer or out of rangeIncrby 命令将 key 中储存的数字加上指定的增量值。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCRBY 命令。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
语法: INCRBY KEY_NAME INCR_AMOUNT
例子
> incrby num 50
53
#不存在
> incrby num3 50
50
#不是数值
> incrby num2 50
ERR value is not an integer or out of rangeincrbyfloat命令为 key 中所储存的值加上指定的浮点数增量值。如果 key 不存在,那么 INCRBYFLOAT 会先将 key 的值设为 0 ,再执行加法操作。
语法:INCRBYFLOAT KEY_NAME INCR_AMOUNT
例子
> incrbyfloat mun4 0.1
0.12.1.5、decr、decrby
Decr 命令将 key 中储存的数字值减一。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 DECR 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
语法:DECR KEY_NAME
例子
# 对存在的数字值 key 进行 DECR
redis> SET failure_times 10
OK
redis> DECR failure_times
(integer) 9# 对不存在的 key 值进行 DECR
redis> EXISTS count
(integer) 0
redis> DECR count
(integer) -1# 对存在但不是数值的 key 进行 DECR
redis> SET company YOUR_CODE_SUCKS.LLC
OK
redis> DECR company
(error) ERR value is not an integer or out of rangeDecrby 命令将 key 所储存的值减去指定的减量值。如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 DECRBY 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
语法:DECRBY KEY_NAME DECREMENT_AMOUNT
例子
# 对已存在的 key 进行 DECRBYredis> SET count 100
OKredis> DECRBY count 20
(integer) 80# 对不存在的 key 进行DECRBYredis> EXISTS pages
(integer) 0redis> DECRBY pages 10
(integer) -102.1.6、其他特殊命令
Strlen命令用于获取指定 key 所储存的字符串值的长度。当 key 储存的不是字符串值时,返回一个错误。
语法:STRLEN KEY_NAME
例子:
> strlen mykey
19Redis Append 命令用于为指定的 key 追加值。如果 key 已经存在并且是一个字符串, APPEND 命令将 value 追加到 key 原来的值的末尾。如果 key 不存在, APPEND 就简单地将给定 key 设为 value ,就像执行 SET key value 一样。
语法:APPEND KEY_NAME NEW_VALUE
例子
> get mykey
This is youtest key
> append mykey aaa
22
> append mykey 哈哈哈哈
34
> append mykey1 啊啊啊啊
12
> get mykey
This is youtest keyaaa哈哈哈哈
> get mykey1
啊啊啊啊Getset 命令用于设置指定 key 的值,并返回 key 旧的值。 当 key 没有旧值时,即 key 不存在时,返回 nil 。
当 key 存在但不是字符串类型时,返回一个错误。
语法:GETSET KEY_NAME VALUE
例子:
> getset num 224
53
> getset num22 224
null2.2、redis列表
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)它的底层实际是个双端链表,最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
主要功能有push/pop等,一般用在栈、队列、消息队列等场景。left、right都可以插入添加,如果键不存在,创建新的链表;如果键已存在,新增内容;如果值全移除,对应的键也就消失了。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
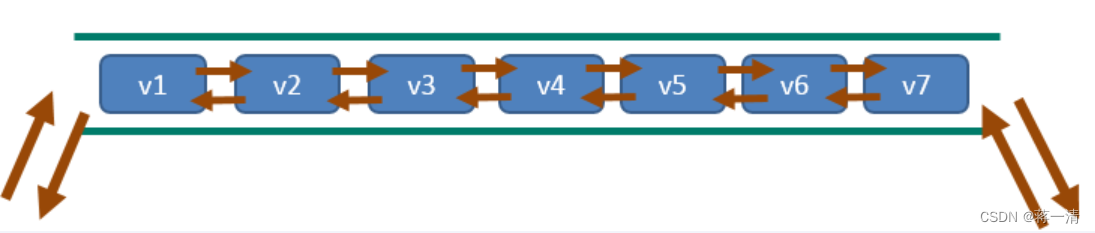
2.2.1、lpush、rpush、lpushx、rpushx
Redis Lpush 命令将一个或多个值插入到列表头部。 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。 当 key 存在但不是列表类型时,返回一个错误。执行 LPUSH 命令后返回的是列表的长度。
语法:LPUSH KEY_NAME VALUE1.. VALUEN
例子:
> lpush num 1 2 3 4 5 6
6
> lrange num 0 -1
6
5
4
3
2
1Redis Rpush 命令用于将一个或多个值插入到列表的尾部(最右边)。如果列表不存在,一个空列表会被创建并执行 RPUSH 操作。 当列表存在但不是列表类型时,返回一个错误。执行 RPUSH 操作后,返回的是列表的长度。
语法:RPUSH KEY_NAME VALUE1..VALUEN
例子:
> rpush letter a b c d e
5
> lrange letter 0 -1
a
b
c
d
eRedis Lpushx 将一个或多个值插入到已存在的列表头部,列表不存在时操作无效。执行成功放回的是列表的长度
语法:LPUSHX KEY_NAME VALUE1.. VALUEN
例子:
> lpushx num1 1 2 3
0
> keys *
letter
numRedis Rpushx 命令用于将一个或多个值插入到已存在的列表尾部(最右边)。如果列表不存在,操作无效。执行成功返回的是列表的长度。
语法: RPUSHX KEY_NAME VALUE1..VALUEN
例子:
> rpushx num1 1 2 3
0
> keys *
letter
num2.2.2、lindex、linsert 、lset
Redis Lindex 命令用于通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。返回列表中下标为指定索引值的元素。 如果指定索引值不在列表的区间范围内,返回 nil 。
语法:LINDEX KEY_NAME INDEX_POSITION
例子:
> lrange num 0 -1
6
5
4
3
2
1
> lindex num 0
6
> lindex num -1
1Redis Linsert 命令用于在列表的元素前或者后插入元素。 当指定元素不存在于列表中时,不执行任何操作。 当列表不存在时,被视为空列表,不执行任何操作。 如果 key 不是列表类型,返回一个错误。如果命令执行成功,返回插入操作完成之后,列表的长度。 如果没有找到指定元素 ,返回 -1 。 如果 key 不存在或为空列表,返回 0 。
语法:LINSERT KEY_NAME BEFORE|AFTER EXISTING_VALUE NEW_VALUE
例子:
> rpush word 你 好 呀 臭 狗 屎
6
> LINSERT word after 呀 !
7
> lrange word 0 -1
你
好
呀
!
臭
狗
屎
> LINSERT word before 臭 臭
8
> lrange word 0 -1
你
好
呀
!
臭
臭
狗
屎Redis Lset 通过索引来设置元素的值。当索引参数超出范围,或对一个空列表进行 LSET 时,返回一个错误。操作成功返回 ok
语法: LSET KEY_NAME INDEX VALUE
语法:
> lrange word 0 -1
你
好
呀
!
臭
臭
狗
屎
> lset word 7 狗
OK
> lrange word 0 -1
你
好
呀
!
臭
臭
狗
狗2.2.3、lpop、rpop、ltrim、lrem、rpoplpush
Redis Lpop 命令用于移除并返回列表的第一个元素。 当列表 key 不存在时,返回 nil 。
语法:LPOP KEY_NAME
例子:
> lrange num 0 -1
5
4
3
2
1
> lpop num
5
> lpop num
4
> lrange num 0 -1
3
2
1Redis Rpop 命令用于移除并返回列表的最后一个元素。当列表不存在时,返回 nil 。
语法:RPOP KEY_NAME
例子:
> rpop letter
e
> lrange letter 0 -1
a
b
c
dRedis Ltrim 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。命令执行成功时,返回 ok 。下标 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
语法:LTRIM KEY_NAME START STOP
例子:
> lrange word 0 -1
你
好
呀
!
臭
臭
狗
狗
> ltrim word 0 3
OK
> lrange word 0 -1
你
好
呀
!Redis Lrem 根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。
COUNT 的值可以是以下几种:
-
count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
-
count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
-
count = 0 : 移除表中所有与 VALUE 相等的值。
语法: LREM KEY_NAME COUNT VALUE
例子:
> rpush list 1 1 1 1 2 2 3 3 3 4 5 6 6 6 1 1 1 3 3 3 4 4
#前
> lrem list 2 1
2
> Lrange list 0 -1
1 1 2 2 3 3 3 4 5 6 6 6 1 1 1 3 3 3 4 4
#后
> lrem list -2 1
2
> Lrange list 0 -1
1 1 2 2 3 3 3 4 5 6 6 6 1 3 3 3 4 4
#所有
> lrem list 0 1
3
> Lrange list 0 -1
2 2 3 3 3 4 5 6 6 6 3 3 3 4 4Redis Rpoplpush 命令用于移除列表的最后一个元素,并将该元素添加到另一个列表并返回。返回值是被弹出的元素。
语法:RPOPLPUSH SOURCE_KEY_NAME DESTINATION_KEY_NAME
例子:
> rpush list 1 2 3 4 5
5
> rpush list1 6 7 8 9
4
> lrange list 0 -1
1
2
3
4
5
> lrange list1 0 -1
6
7
8
9
> rpopLpush list list1
5
> lrange list 0 -1
1
2
3
4
> lrange list1 0 -1
5
6
7
8
92.2.4、其他的操作
Redis Llen 命令用于返回列表的长度。 如果列表 key 不存在,则 key 被解释为一个空列表,返回 0 。 如果 key 不是列表类型,返回一个错误。
语法:LLEN KEY_NAME
例子:
> llen list
42.3、redis哈希表
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
2.3.1、hset、hget、hmset、hmget、hgetall、hsetnx
Redis Hset 命令用于为哈希表中的字段赋值 。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。如果字段已经存在于哈希表中,旧值将被覆盖。
语法:HSET KEY_NAME FIELD VALUE
Redis Hget 命令用于返回哈希表中指定字段的值,返回给定字段的值。如果给定的字段或 key 不存在时,返回 nil 。
语法:HGET KEY_NAME FIELD_NAME
例子:
> hset user name 张三
1
> hset user name 李四
0
> hget user name
李四
> hget user age
nullRedis Hmset 命令用于同时将多个 field-value (字段-值)对设置到哈希表中。此命令会覆盖哈希表中已存在的字段。如果哈希表不存在,会创建一个空哈希表,并执行 HMSET 操作。
语法:HMSET KEY_NAME FIELD1 VALUE1 ...FIELDN VALUEN
Redis Hmget 命令用于返回哈希表中,一个或多个给定字段的值。如果指定的字段不存在于哈希表,那么返回一个 nil 值。返回的是一个包含多个给定字段关联值的表,表值的排列顺序和指定字段的请求顺序一样。
语法: HMGET KEY_NAME FIELD1...FIELDN
例子:
> hmset user name 王五 age 25 sex 男
OK
> hmget user name age sex
王五
25
男Redis Hgetall 命令用于返回哈希表中,所有的字段和值。在返回值里,紧跟每个字段名(field name)之后是字段的值(value),所以返回值的长度是哈希表大小的两倍。 若 key 不存在,返回空列表。
语法:HGETALL KEY_NAME
例子:
> hgetall user
name
王五
age
25
sex
男
> hgetall studentRedis Hsetnx 命令用于为哈希表中不存在的的字段赋值 。如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。如果字段已经存在于哈希表中,操作无效。如果 key 不存在,一个新哈希表被创建并执行 HSETNX 命令。设置成功,返回 1 。 如果给定字段已经存在且没有操作被执行,返回 0 。
语法:HSETNX KEY_NAME FIELD VALUE
例子:
#key不存在
> hsetnx student name 小狗
1
#key存在但是字段
> hsetnx student name 大狗
0
#key存在但是字段不存在
> hsetnx student age 23
1
> hgetall student
name
小狗
age
232.3.2、hexists、hlen、hvals、hkeys、hdel
Redis Hexists 命令用于查看哈希表的指定字段是否存在。如果哈希表含有给定字段,返回 1 。 如果哈希表不含有给定字段,或 key 不存在,返回 0 。
语法:HEXISTS KEY_NAME FIELD_NAME
例子:
> hexists user email
0
> hexists user name
1Redis Hlen 命令用于获取哈希表中字段的数量。哈希表中字段的数量。 当 key 不存在时,返回 0 。
语法:HLEN KEY_NAME
例子:
> hlen goods
0
> hlen user
3Redis Hvals 命令返回哈希表所有字段的值,一个包含哈希表中所有值的表。 当 key 不存在时,返回一个空表。
语法:HVALS KEY_NAME
例子:
> hvals user
王五
25
男Redis Hkeys 命令用于获取哈希表中的所有字段名。包含哈希表中所有字段的列表。 当 key 不存在时,返回一个空列表。
语法:HKEYS KEY_NAME
例子:
> hkeys user
name
age
sexRedis Hdel 命令用于删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略。被成功删除字段的数量,不包括被忽略的字段。
语法:HDEL KEY_NAME FIELD1.. FIELDN
例子:
> hmset letter 1 啊 2 喔 3 额
OK
> hdel letter 2 3
2
> hgetall letter
1
啊2.3.3、hincrby、hincrbyfloat
Redis Hincrby 命令用于为哈希表中的字段值加上指定增量值。增量也可以为负数,相当于对指定字段进行减法操作。如果哈希表的 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。对一个储存字符串值的字段执行 HINCRBY 命令将造成一个错误。本操作的值被限制在 64 位(bit)有符号数字表示之内。
语法:HINCRBY KEY_NAME FIELD_NAME INCR_BY_NUMBER
例子:
> hmset num a 1 b 2 c 3 d 4
OK
> hincrby num e 2
2
> hgetall num
a
1
b
2
c
3
d
4
e
2
> hincrby num a 2
3
> hset num f 你好
1
> hincrby num f 2
ERR hash value is not an integerRedis Hincrbyfloat 命令用于为哈希表中的字段值加上指定浮点数增量值。如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。执行 Hincrbyfloat 命令之后,哈希表中字段的值。
语法:HINCRBYFLOAT KEY_NAME FIELD_NAME INCR_BY_NUMBER
例子:
> hmset float a 1.2 b 2
OK
> hincrbyfloat float 1 0.1
0.1
> hincrbyfloat float a 0.1
1.3
> hincrbyfloat float b 0.1
2.12.4、redis集合
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是 intset 或者 hashtable。Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
2.4.1、sadd、spop、srem、scard、smove
Redis Sadd 命令将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。假如集合 key 不存在,则创建一个只包含添加的元素作成员的集合。当集合 key 不是集合类型时,返回一个错误。自动去重!
语法:SADD KEY_NAME VALUE1..VALUEN
例子:
> sadd set 1 1 1 2 2 3 4 5 6
6
> smembers set
1
2
3
4
5
6Redis Spop 命令用于移除并返回集合中的一个随机元素。被移除的随机元素。 当集合不存在或是空集时,返回 nil 。
语法:SPOP KEY
例子:
> smembers set
1
2
3
4
5
6
> spop set
5
> smembers set
1
2
3
4
6
> spop set1
nullRedis Srem 命令用于移除集合中的一个或多个成员元素,不存在的成员元素会被忽略。当 key 不是集合类型,返回一个错误。
语法:SREM KEY MEMBER1..MEMBERN
例子:
> srem set 1 2
2
> smembers set
3
4
6Redis Scard 命令返回集合中元素的数量。集合的数量。 当集合 key 不存在时,返回 0 。
语法: SCARD KEY_NAME
例子:
> scard set
3
> scard set1
0Redis Smove 命令将指定成员 member 元素从 source 集合移动到 destination 集合。SMOVE 是原子性操作。
-
如果 source 集合不存在或不包含指定的 member 元素,则 SMOVE 命令不执行任何操作,仅返回 0 。否则, member 元素从 source 集合中被移除,并添加到 destination 集合中去。
-
当 destination 集合已经包含 member 元素时, SMOVE 命令只是简单地将 source 集合中的 member 元素删除。
-
当 source 或 destination 不是集合类型时,返回一个错误。
语法: SMOVE SOURCE DESTINATION MEMBER
例子:
> smove set set1 3
1
> smembers set1
3
> smove set set1 5
0
> smembers set1
32.4.2、smembers、srandmember、sismembers
Redis Smembers 命令返回集合中的所有的成员。 不存在的集合 key 被视为空集合。返回集合中的所有成员。
语法:SMEMBERS KEY
例子:
> smembers set
1
2
3
4
5
6Redis Srandmember 命令用于返回集合中的一个随机元素。从 Redis 2.6 版本开始, Srandmember 命令接受可选的 count 参数:
-
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合。
-
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值。
该操作和 SPOP 相似,但 SPOP 将随机元素从集合中移除并返回,而 Srandmember 则仅仅返回随机元素,而不对集合进行任何改动。
语法:SRANDMEMBER KEY [count]
例子:
> srandmember set -1
4
> srandmember set -2
2
1
> srandmember set 2
1
4
> srandmember set 5
1
2
3
4
6Redis Sismember 命令判断成员元素是否是集合的成员。如果成员元素是集合的成员,返回 1 。 如果成员元素不是集合的成员,或 key 不存在,返回 0 。
语法:SISMEMBER KEY VALUE
例子:
> sismember set 5
0
> sismember set 1
12.4.3、sdiff、sdffstore
Redis Sdiff 命令返回给定集合之间的差集。不存在的集合 key 将视为空集,包含差集成员的列表。大概的意思是判断集合之间,我有你没有的。有点像对对碰,对局结束后还剩什么!
语法:SDIFF FIRST_KEY OTHER_KEY1..OTHER_KEYN
例子:
> smembers set1
a b c d 1 2 3 5 6
> smembers set2
c d 5 6 7 8 e f
> sdiff set1 set2
a b 1 2 3
> sdiff set2 set1
7 8 e fRedis Sdiffstore 命令将给定集合之间的差集存储在指定的集合中。如果指定的集合 key 已存在,则会被覆盖。返回结果集中的元素数量。
语法:SDIFFSTORE DESTINATION_KEY KEY1..KEYN
例子:
> sdiffstore set set1 set2
5
> smembers set
a b 1 2 32.4.4、sunion、sunionstore
Redis Sunion 命令返回给定集合的并集。不存在的集合 key 被视为空集,返回值并集成员的列表。
语法:SUNION KEY KEY1..KEYN
例子:
> sunion set1 set2
a b c d 1 2 3 5 6 7 8 e fRedis Sunionstore 命令将给定集合的并集存储在指定的集合 destination 中。返回结果集中的元素数量。
语法: SUNIONSTORE DESTINATION KEY KEY1..KEYN
例子:
> sunionstore set set1 set2
13
> smembers set
a b c d 1 2 3 5 6 7 8 e f2.4.5、sinter、sinterstore
Redis Sinter 命令返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。返回值交集成员的列表。
语法:SINTER KEY KEY1..KEYN
例子:
> sinter set1 set2
c d 5 6 Redis Sinterstore 命令将给定集合之间的交集存储在指定的集合中。如果指定的集合已经存在,则将其覆盖。返回交集成员的列表。
语法:SINTERSTORE DESTINATION_KEY KEY KEY1..KEYN
例子:
> sinterstore set set1 set2
4
> smembers set
c d 5 62.5、redis有序集合
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32 - 1。
2.5.1、zadd、zrem、zcard、zcount
Redis Zadd 命令用于将一个或多个成员元素及其分数值加入到有序集当中。如果某个成员已经是有序集的成员,那么更新这个成员的分数值,并通过重新插入这个成员元素,来保证该成员在正确的位置上。分数值可以是整数值或双精度浮点数。如果有序集合 key 不存在,则创建一个空的有序集并执行 ZADD 操作。当 key 存在但不是有序集类型时,返回一个错误。返回值是被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
语法:ZADD KEY_NAME SCORE1 VALUE1.. SCOREN VALUEN
例子:
> zadd zset 99 张三 80 李四 100 王五 60 赵六
4
> zadd zset 77 王五
0
> zrange zset 0 -1 withscores
赵六
60
王五
77
李四
80
张三
99Redis Zrem 命令用于移除有序集中的一个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回一个错误。
语法:ZREM KEY
例子:
> zrange zset 0 -1 withscores
赵六
60
王五
77
> zrem zset 王五
1
> zrange zset 0 -1 withscores
赵六
60Redis Zcard 命令用于计算集合中元素的数量。当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0 。
语法:ZCARD KEY
例子:
> zadd zset 99 张三 80 李四 100 王五 60 赵六
4
> zcard zset
4Redis Zcount 命令用于计算有序集合中指定分数区间的成员数量。返回值分数值在 min 和 max 之间的成员的数量。
语法: ZCOUNT key min max
例子:
> zadd zset 99 张三 80 李四 100 王五 60 赵六
4
> zcard zset
4
> zcount zset 80 100
32.5.2、zrange,zrevrange
Redis Zrange 返回有序集中,指定区间内的成员。其中成员的位置按分数值递增(从小到大)来排序。具有相同分数值的成员按字典序(lexicographical order )来排列。返回指定区间内,带有分数值(可选)的有序集成员的列表。
下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
语法:ZRANGE key start stop [WITHSCORES]
例子:
> zrange zset 0 -1 withscores
赵六
60
王五
77
李四
80
张三
99Redis Zrevrange 命令返回有序集中,指定区间内的成员。其中成员的位置按分数值递减(从大到小)来排列。具有相同分数值的成员按字典序的逆序(reverse lexicographical order)排列。
语法:ZREVRANGE key start stop [WITHSCORES]
例子:
> zrevrange zset 0 -1 withscores
张三
99
李四
80
王五
77
赵六
602.5.3、zrangebyscore,zrevrangebysorce、zremrangebysorce
Redis Zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。具有相同分数值的成员按字典序来排列(该属性是有序集提供的,不需要额外的计算)。默认情况下,区间的取值使用闭区间 (小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
举个例子:
ZRANGEBYSCORE zset (1 5返回所有符合条件 1 < score <= 5 的成员,而
ZRANGEBYSCORE zset (5 (10则返回所有符合条件 5 < score < 10 的成员。
语法: ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
例子:
> zrangebyscore zset 80 100 withscores
李四
80
张三
99Redis Zrevrangebyscore 返回有序集中指定分数区间内的所有的成员。有序集成员按分数值递减(从大到小)的次序排列。具有相同分数值的成员按字典序的逆序(reverse lexicographical order )排列。
语法: ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
例子:
> zrevrangebyscore zset 80 100 withscores
张三
99
李四
80Redis Zremrangebyscore 命令用于移除有序集中,指定分数(score)区间内的所有成员。返回值是被移除成员的数量。
语法: ZREMRANGEBYSCORE key min max
例子:
> zremrangebyscore zset 80 100
22.5.4、zincrby、zscore
Redis Zincrby 命令对有序集合中指定成员的分数加上增量 increment,可以通过传递一个负数值 increment ,让分数减去相应的值,比如 ZINCRBY key -5 member ,就是让 member 的 score 值减去 5 。
-
当 key 不存在,或分数不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。
-
当 key 不是有序集类型时,返回一个错误。
分数值可以是整数值或双精度浮点数。
语法: ZINCRBY key increment member
例子:
> zincrby zset 10 赵六
70
> zincrby zset 1.2 赵六
71.2
> zincrby zset 88 孙琪
88
> zrange zset 0 -1 withscores
赵六
71.2
李四
80
孙琪
88
张三
99
王五
100Redis Zscore 命令返回有序集中,成员的分数值,以字符串形式表示。 如果成员元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
语法: ZSCORE key member
例子:
> zscore zset 赵六
71.22.5.5、zrank、zrevrank(从零开始的排名)
Redis Zrank 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。如果成员是有序集 key 的成员,返回 member 的排名。 如果成员不是有序集 key 的成员,返回 nil
语法: ZRANK key member
Redis Zrevrank 命令返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序。
排名以 0 为底,也就是说, 分数值最大的成员排名为 0 。
语法:ZREVRANK key member
例子:
> zrange zset 0 -1 withscores
赵六
71.2
李四
80
孙琪
88
张三
99
王五
100
> zrank zset 赵六
0
> zrank zset 张三
3
> zrank zset 赵六
0
> zrevrank zset 张三
1
> zrevrank zset 赵六
42.6、redis地理空间
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,包括
-
添加地理位置的坐标。
-
获取地理位置的坐标。
-
计算两个位置之间的距离。
-
根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
2.6.1、geoadd、geopos
Redis GEOADD 命令将指定的地理空间位置(纬度、经度、名称)添加到指定的key中。这些数据将会存储到sorted set这样的目的是为了方便使用GEORADIUS或者GEORADIUSBYMEMBER命令对数据进行半径查询等操作。
该命令以采用标准格式的参数x,y,所以经度必须在纬度之前。这些坐标的限制是可以被编入索引的,区域面积可以很接近极点但是不能索引。具体的限制,由EPSG:900913 / EPSG:3785 / OSGEO:41001 规定如下:
-
有效的经度从-180度到180度。
-
有效的纬度从-85.05112878度到85.05112878度。
当坐标位置超出上述指定范围时,该命令将会返回一个错误。
语法:GEOADD KEY 经度 纬度 位置......
例子:
> GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
3
> zrange city 0 -1
天安门
故宫
长城
geopos命令是从key里返回所有给定位置元素的位置(经度和纬度)。给定一个sorted set表示的空间索引,密集使用 geoadd 命令,它以获得指定成员的坐标往往是有益的。当空间索引填充通过 geoadd 的坐标转换成一个52位Geohash,所以返回的坐标可能不完全以添加元素的,但小的错误可能会出台。
因为 GEOPOS 命令接受可变数量的位置元素作为输入, 所以即使用户只给定了一个位置元素, 命令也会返回数组回复。
语法: GEOPOS KEY ADDRESS
例子:
> GEOPOS city 天安门 故宫 长城
116.40396326780319214
39.91511970338637383
116.40341609716415405
39.92409008156928252
116.02406591176986694
40.362639932394621672.6.2、geohash
返回一个或多个位置元素的 Geohash 表示。通常使用表示位置的元素使用不同的技术,使用Geohash位置52点整数编码。由于编码和解码过程中所使用的初始最小和最大坐标不同,编码的编码也不同于标准。此命令返回一个标准的Geohash,在维基百科和geohash.org网站都有相关描述。
Geohash字符串属性该命令将返回11个字符的Geohash字符串,所以没有精度Geohash,损失相比,使用内部52位表示。返回的geohashes具有以下特性:
-
他们可以缩短从右边的字符。它将失去精度,但仍将指向同一地区。
-
它可以在
geohash.org网站使用,网址http://geohash.org/<geohash-string>。查询例子:Geohash - geohash.org/sqdtr74hyu0. -
与类似的前缀字符串是附近,但相反的是不正确的,这是可能的,用不同的前缀字符串附近。
语法:geohash key address...
例子:
> geohash city 天安门
wx4g0f6f2v02.6.3、geodist、georadius、georadiusbymember
Redis GEODIST 命令 - 返回两个给定位置之间的距离,如果两个位置之间的其中一个不存在, 那么命令返回空值。
指定单位的参数 unit 必须是以下单位的其中一个:
-
m 表示单位为米。
-
km 表示单位为千米。
-
mi 表示单位为英里。
-
ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么 GEODIST 默认使用米作为单位。GEODIST 命令在计算距离时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。
语法:GEODIST KEY ADDRESS1 ADDRESS2
例子:
> geodist city 天安门 长城
59338.9814Redis GEORADIUS 命令 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。范围可以使用以下其中一个单位:(就是计算出来当前坐标某一范围内的目标)
-
m 表示单位为米。
-
km 表示单位为千米。
-
mi 表示单位为英里。
-
ft 表示单位为英尺。
在给定以下可选项时, 命令会返回额外的信息:
-
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。 -
WITHCOORD: 将位置元素的经度和维度也一并返回。 -
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
-
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。 -
DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。
在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用 COUNT <count> 选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用 COUNT 选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用 COUNT 选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
语法:
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord withhash count 10 desc
GEORADIUS key 经度 维度 距离 距离单位 返回距离 返回经纬度 放回hash码 count 数量 排序方式
然后呐还有一个命令不用使用经纬度,只需要使用地点的名字就可以
Redis GEORADIUSBYMEMBER 命令 - 找出位于指定范围内的元素,中心点是由给定的位置元素决定、这个命令和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素, 但是 GEORADIUSBYMEMBER 的中心点是由给定的位置元素决定的, 而不是像 GEORADIUS 那样, 使用输入的经度和纬度来决定中心点,指定成员的位置被用作查询的中心。
2.7、redis基数统计
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
2.7.1、pfadd、pgmerge、pgcount
Redis Pfadd 命令将所有元素参数添加到 HyperLogLog 数据结构中。 返回整型,如果至少有个元素被添加返回 1, 否则返回 0。
语法: PFADD key element [element ...]
例子:
> PFADD mykey a b c d e f g h i j 1 a b 2
1
> pfcount mykey
12Redis Pfcount 命令返回给定 HyperLogLog 的基数估算值。返回值整数,返回给定 HyperLogLog 的基数值,如果多个 HyperLogLog 则返回基数估值之和。
语法: PFCOUNT key [key ...]
例子:
> PFADD mykey a b c d e f g h i j 1 a b 2
1
> pfcount mykey
12
> PFADD hll foo bar zap
1
> pfcount mykey hll
15Redis Pgmerge 命令将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有 给定 HyperLogLog 进行并集计算得出的。
语法: PFMERGE destkey sourcekey [sourcekey ...]
例子:
redis 127.0.0.1:6379> PFADD hll1 foo bar zap a
(integer) 1
redis 127.0.0.1:6379> PFADD hll2 a b c foo
(integer) 1
redis 127.0.0.1:6379> PFMERGE hll3 hll1 hll2
OK
redis 127.0.0.1:6379> PFCOUNT hll3
(integer) 6
redis> 2.8、redis位图

由0和1状态表现的二进制位的bit数组
2.8.1、setbit、getbit、strlen
setbit,是用于给指定key的值的第offset设置为value,大概的意思就是,我想设置某一个二进制数,然后我的offset代表的就是我设置的位数,然后value只能是0或者1。如果该位已经有值则进行覆盖。
语法:SETBIT key offset value
例子:
> setbit day 1 0
0
> setbit day 2 1
0
> setbit day 3 1
0
> setbit day 4 0
0
> setbit day 5 1
0getbit用来获取指定key的第offset位,如果没有获取没有设置的位,取出的默认值是0
语法:GETBIT key offset
> getbit day 3
1
> getbit day 6
0strlen命令可以用来统计指定key所占的字节数是少,统计的不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容。
语法:STRLEN key
例子:
> strlen day
1
> setbit day 9 1
0
> strlen day
22.8.2、bitcount、bitop
bitcount命令是用来返回指定key中[start,end]中为1的数量
语法:BITCOUNT key [start end [BYTE | BIT]]
例子:
> bitcount day
6bitop命令可以对不同的二进制存储数据进行位运算(AND、OR、NOT 、XOR)
语法:BITOP <AND | OR | XOR | NOT> destkey key [key ...]
例子:
> setbit bit1 1 1
0
> setbit bit1 2 1
0
> setbit bit1 3 0
0
> setbit bit2 1 1
0
> setbit bit2 2 1
0
> setbit bit2 3 0
0
> setbit bit2 4 0
0
> bitop and bit3 bit1 bit2
1
> getbit bit3 1
1
> getbit bit3 2
1
> getbit bit3 3
0
> getbit bit3 4
02.9、redis位域
通过bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果。说白了就是通过bitfield命令我们可以一次性对多个比特位域进行操作。
2.10、redis流
Redis Stream 是 Redis 5.0 版本新增加的数据结构。Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
它的功能:实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持ack确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
2.10.1、stream流的结构
一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容

| 序号 | 类型 | 描述 |
|---|---|---|
| 1 | Message Content | 消息内容 |
| 2 | Consumer group | 消费组,通过XGROUP CREATE 命令创建,同一个消费组可以有多个消费者 |
| 3 | Last_delivered_id | 游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。 |
| 4 | Consumer | 消费者,消费组中的消费者 |
| 5 | Pending_ids | 消费者会有一个状态变量,用于记录被当前消费已读取但未ack的消息Id,如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack它就开始减少。这个pending_ids变量在Redis官方被称之为 PEL(Pending Entries List),记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符),它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理 |
在Stream中的特殊的符号
| 符号 | 作用 |
|---|---|
| - + | 最大和最小可能出现的id |
| $ | $表示消费新的消息,当前流中最大的id,可用于将来要到来的消息 |
| > | 用于XREADGROUP命令,表示迄今为止还没有发送给组中使用者的消息,会更新消费者组的最后id |
| * | 用于XADD命令,让系统自动生成id |
2.10.2、队列相关命令
| 指令名称 | 指令作用 |
|---|---|
| XADD | 添加消息到队列的末尾 |
| XTRIM | 限制Stream长度,如果超过长度的话会进行截取 |
| XDEL | 删除消息 |
| XLEN | 获取Stream中的消息长度 |
| XRANGE | 获取消息队列(可以指定范围),id从小到大,忽略删除的消息 |
| XREVRANGE | 和XRANGRE的作用相同,但是消息的id是从大到小 |
| XREAD | 获取消息(阻塞/非阻塞),返回大于指定id的消息 |
XADD 用于向Stream 队列中添加消息,如果指定的Stream 队列不存在,则该命令执行时会新建一个Stream 队列。* 号表示服务器自动生成 MessageID,XADD是将消息添加到队列的末尾,然后要求消息的ID要比上一个的ID大,如果ID小于上一个会报错,然后使用*号的话是ID的自动生成。
语法:XADD key ID field string [field string ...]
例子:
> XADD stream * k1 v1 k2 v2 k3 v3 k4 v4
1704112841027-0
> XADD stream * k5 v5
1704113004931-0
> XADD stream * k6 v6
1704113012427-0其中生成的id由两部分组成,前一段是当前的时间戳,后一段是在该毫秒生成的第几条消息。然后消息内容是类似hash结构的key-value的形式存在。
XRANGE获取消息队列(可以指定范围),id从小到大,忽略删除的消息。
语法:XRANGE key start end [COUNT count]
例子:
> XRANGE stream - +
1704113632758-0
k1
v1
1704113644774-0
k2
v2
1704113653286-0
k3
v3
1704113663350-0
k4
v4
1704113670998-0
k5
v5
1704113677046-0
k6
v6
1704113685190-0
k7
v7
1704113691382-0
k8
v8
> XRANGE stream - + count 2
1704113632758-0
k1
v1
1704113644774-0
k2
v2XREVRANGE和XRANGRE的作用相同,但是消息的id是从大到小
语法:XREVRANGE key end start [COUNT count]
例子:
> XREVRANGE stream + -
1704113691382-0
k8
v8
1704113685190-0
k7
v7
1704113677046-0
k6
v6
1704113670998-0
k5
v5
1704113663350-0
k4
v4
1704113653286-0
k3
v3
1704113644774-0
k2
v2
1704113632758-0
k1
v1
> XREVRANGE stream + - count 2
1704113691382-0
k8
v8
1704113685190-0
k7
v7XDEL可以用于删除消息,通过主键也就是我们使用系统生成的id,可以删除一个或者多个
语法: XDEL key ID [ID ...]
例子:
> xdel stream 1704113691382-0 1704113685190-0
2
> XREVRANGE stream + -
1704113677046-0
k6
v6
1704113670998-0
k5
v5
1704113663350-0
k4
v4
1704113653286-0
k3
v3
1704113644774-0
k2
v2
1704113632758-0
k1
v1XLEN 获取Stream中的消息长度
语法: XLEN key
例子:
> XLEN stream
6- XTRIM 限制Stream长度,如果超过长度的话会进行截取,MAXLEN允许的最大长度,对流进行修剪限制长度
- MINID允许的最小id,从某个id值开始比该id值小的将会被抛弃。
语法:XTRIM key MAXLEN|MINID [~] count
例子:
#长度限制,超出的从最新的开始数,长度超过的话就删除!
> XTRIM stream MAXLEN 4
2
> XREVRANGE stream + -
1704113677046-0
k6
v6
1704113670998-0
k5
v5
1704113663350-0
k4
v4
1704113653286-0
k3
v3
#按照id最小截取
> XTRIM stream minid 1704113670998-0
2
> XREVRANGE stream + -
1704113677046-0
k6
v6
1704113670998-0
k5
v5XREAD 用于获取消息(阻塞/非阻塞),智慧返回大于指定id的消息,count表示读多少条消息,block表示是否为阻塞方式读取消息,默认不阻塞,如果milliseconds设置为0,表示永远阻塞。
语法: XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
例子:非阻塞
#$代表特殊ID,表示以当前Stream已经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil
> xread count 3 streams stream $
null
#0-0代表从最小的ID开始获取Stream中的消息,当不指定count,将会返回Stream中的所有消息,注意也可以使用0(00/000也都是可以的……)
> xread count 3 streams stream 0-0
stream
1704115717430-0
k1
v1
1704115722702-0
k2
v2
1704115730303-0
k3
v3
> xread count 3 streams stream 000
stream
1704115717430-0
k1
v1
1704115722702-0
k2
v2
1704115730303-0
k3
v3例子:阻塞
请redis-cli启动第2个客户端连接上来
xread count 1 block 0 streams stream $
#一个客户端执行后,然后一直没有结果然后再另一个客户端上执行添加后,原本阻塞的客户端立即输出!2.10.3、消费相关指令
| 指令名称 | 指令作用 |
|---|---|
| XGROUP CREATE | 创建消费者组 |
| XREADGROUP FROUP | 读取消费者组中的消息 |
| XACK | ack消息,消息被标记为“已处理” |
| XGROUP SERID | 设置消费者组最后递送消息的id |
| XGROUP DELCONSUMER | 删除消费者组 |
| XPENDING | 打印待处理消息的详细信息 |
| XCLAIM | 转移消息的归属权(长期违背处理/无法处理的消息,转交给其他的消费者组进行处理) |
| XINFO | 打印Stream/Consumer/Group的详细信息 |
| XINFO GROUPS | 打印消费者组的详情信息 |
| XINFO STREAM | 打印Stream的详情信息 |
XGROUP CREATE 创建消费者组,创建消费者组的时候必须指定 ID, ID 为 0 表示从头开始消费,为 $ 表示只消费新的消息,队尾新来。
-
$表示从Stream尾部开始消费
-
0表示从Stream头部开始消费
语法:XGROUP CREATE key groupname id|$ [MKSTREAM]
例子:
> xgroup create stream groupA $
OK
> xgroup create stream groupB 0
OKXREADGROUP FROUP 读取消费者组中的消息,“>”,表示从第一条尚未被消费的消息开始读取,他有一个特点就stream中的消息一旦被消费者读取,就不能被消费组中的其他消费者读取,也就是说同一个消费组中的消费者不能读取同一条消息,但是不同组的消费者可以读取已经被其他组读取过的消息。
消费组设置的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的
语法:XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
例子:
> xreadgroup group groupB consumer1 streams stream >
stream
1704159696960-0
k1
v1
1704159714408-0
k2
v2
1704159720488-0
k3
v3
1704159725023-0
k4
v4
1704159729560-0
k5
v5
1704159735528-0
k6
v6
1704159743280-0
k7
v7
> xreadgroup group groupB consumer2 streams stream >
null
> xreadgroup group groupc consumer1 count 3 streams stream >
stream
1704159696960-0
k1
v1
1704159714408-0
k2
v2
1704159720488-0
k3
v3
#也可以查询某一组的消费者消费的消息的具体信息
> XPENDING stream groupc - + 10 consumer1
1704159696960-0
consumer1
6145581
1
1704159714408-0
consumer1
6145581
1
1704159720488-0
consumer1
6145581
1| 1问题 | 基于 Stream 实现的消息队列,如何保证消费者在发生故障或宕机再次重启后,仍然可以读取未处理完的消息? |
|---|---|
| 2 | Streams 会自动使用内部队列(也称为 PENDING List)留存消费组里每个消费者读取的消息保底措施,直到消费者使用 XACK 命令通知 Streams“消息已经处理完成”。 |
| 3 | 消费确认增加了消息的可靠性,一般在业务处理完成之后,需要执行 XACK 命令确认消息已经被消费完成 |
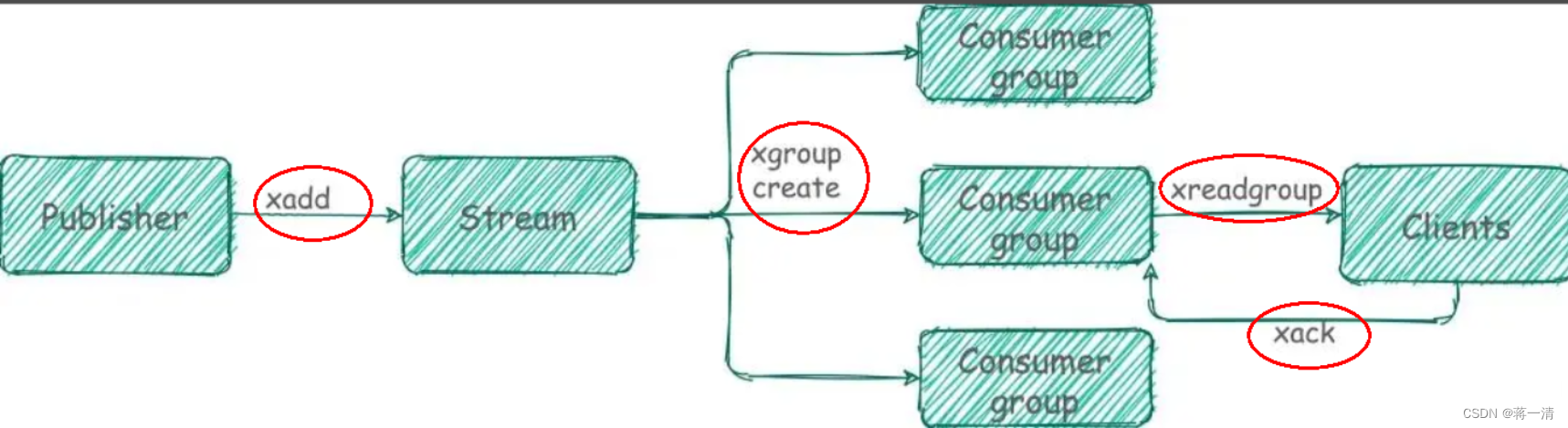
XPENDING 查询每个消费组内所有消费者,「已读取、但尚未确认」的消息。
语法:XPENDING key group [start end count] [consumer]
例子:
> XPENDING stream groupB
7
#最小的id
1704159696960-0
#最大的id
1704159743280-0
#读取信息的
consumer1
#读了多少
7
> XPENDING stream groupc
6
1704159696960-0
1704159735528-0
consumer1
3
consumer2
3XACK ack消息,消息被标记为“已处理”
语法:Xack key group id [id ...]
例子:
#初次查询
> XPENDING stream groupc - + 10 consumer1
1704159696960-0
consumer1
6145581
1
1704159714408-0
consumer1
6145581
1
1704159720488-0
consumer1
6145581
1
#确认消息
> xack stream groupc 1704159696960-0
1
#再次查询
> XPENDING stream groupc - + 10 consumer1
1704159714408-0
consumer1
6630575
1
1704159720488-0
consumer1
6630575
13、redis的操作命令
3.1、通用操作命令
| 命令 | 描述 |
|---|---|
| keys * | 查询所有的key |
| type key | 返回 key 所储存的值的类型。 |
| exist key | 检查给定 key 是否存在 |
| del key | 该命令用于在 key 存在的时候删除 key |
| unlink key | 非阻塞式删除,只是将key从keyspace元数据中删除,真正的删除会在异步中菜操作 |
| expire key | 为给定 key 设置过期时间 |
| ttl key | 以秒为单位,返回给定 key 的剩余生存时间,-1代表永不过期,-2代表已过期 |
| move key dbindex (0-15) | 将当前的数据库中的key移动到指定的数据库中 |
| select dbindex | 切换数据库(0-15),默认是0 |
| dbsize | 查看当前数据库中key的数量 |
| flushdb | 清空当前库 |
| flushall | 清空全部库 |
| help @类型 | 帮助命令,用于查看命令的使用方式 |
相关文章:
Redis(一)
1、redis Redis是一个完全开源免费的高性能(NOSQL)的key-value数据库。它遵守BSD协议,使用ANSI C语言编写,并支持网络和持久化。Redis拥有极高的性能,每秒可以进行11万次的读取操作和8.1万次的写入操作。它支持丰富的数…...
自动驾驶预测-决策-规划-控制学习(1):自动驾驶框架、硬件、软件概述
文章目录 前言:无人驾驶分级一、不同level的无人驾驶实例分析1.L2级别2.L3级别3.L4级别①如何在减少成本的情况下,实现类似全方位高精度的感知呢?②路侧终归是辅助,主车的智能才是重中之重:融合深度学习 二、无人驾驶的…...
SSM建材商城网站----计算机毕业设计
项目介绍 本项目分为前后台,前台为普通用户登录,后台为管理员登录; 管理员角色包含以下功能: 管理员登录,管理员管理,注册用户管理,新闻公告管理,建材类型管理,配货点管理,建材商品管理,建材订单管理,建材评价管理等功能。 用…...

js逆向第9例:猿人学第2题-js混淆-动态cookie1
题目2:提取全部5页发布日热度的值,计算所有值的加和,并提交答案 (感谢蔡老板为本题提供混淆方案) 既然题目已经给出了cookie问题,那就从cookie入手,控制台找到数据请求地址 可以看到如下加密字符串m类似md5,后面跟着时间戳 m=45cc41dcdb15159ebb50564635f8e362|1704301…...
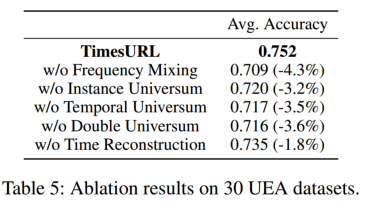
[论文分享]TimesURL:通用时间序列表示学习的自监督对比学习
论文题目:TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning 论文地址:https://arxiv.org/abs/2312.15709 代码地址:暂无 摘要 学习适用于各种下游任务的通用时间序列表示具有挑战性&…...
解决sublime中文符号乱码问题
效果图 原来 后来 问题不是出自encode文件编码,而是win10的字体问题。 解决方法 配置: { "font_face":"Microsoft Yahei", "dpi_scale": 1.0 } 参考自 Sublime 输入中文显示方框问号乱码_sublime中文问号-CSDN博…...

厚积薄发11年,鸿蒙究竟有多可怕
12月20日中国工程院等权威单位发布《2023年全球十大工程成就》。本次发布的2023全球十大工程成就包括“鸿蒙操作系统”在内。入围的“全球十大工程成就”,主要指过去五年由世界各国工程科技工作者合作或单独完成且实践验证有效的,并且已经产生全球影响…...
 pyDAL查询操作)
pyDAL一个python的ORM(4) pyDAL查询操作
1 、简单查询 rows db(db.person.dept marketing).select(db.person.id, db.person.name, db.person.dept) rows db(db.person.dept marketing).select() rows db(db.person.dept marketing).select(db.person.ALL) rows db().select(db.person.ALL) / db(db.person).se…...

如何通过Python将各种数据写入到Excel工作表
在数据处理和报告生成等工作中,Excel表格是一种常见且广泛使用的工具。然而,手动将大量数据输入到Excel表格中既费时又容易出错。为了提高效率并减少错误,使用Python编程语言来自动化数据写入Excel表格是一个明智的选择。Python作为一种简单易…...
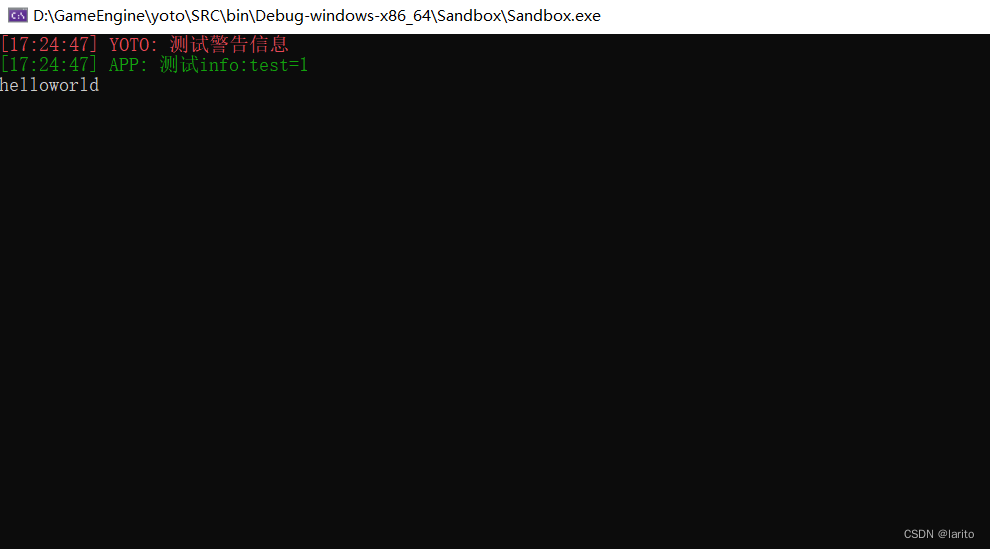
跟着cherno手搓游戏引擎【2】:日志系统spdlog和premake的使用
配置: 日志库文件github: GitHub - gabime/spdlog: Fast C logging library. 新建vendor文件夹 将下载好的spdlog放入 配置YOTOEngine的附加包含目录: 配置Sandbox的附加包含目录: 包装spdlog: 在YOTO文件夹下创建…...
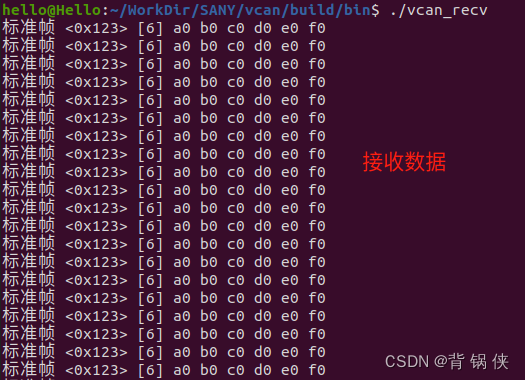
Ubuntu20.04 上启用 VCAN 用作本地调试
目录 一、启用本机的 VCAN 编辑 1.1 加载本机的 vcan 1.2 添加本机的 vcan0 1.3 查看添加的 vcan0 1.4 开启本机的 vcan0 1.5 关闭本机的 vcan0 1.6 删除本机的 vcan0 二、测试本机的 VCAN 2.1 CAN 发送数据 代码 2.2 CAN 接收数据 代码 2.3 CMakeLists.…...

LeetCode(31) 下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。 例如,arr [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。 整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地…...
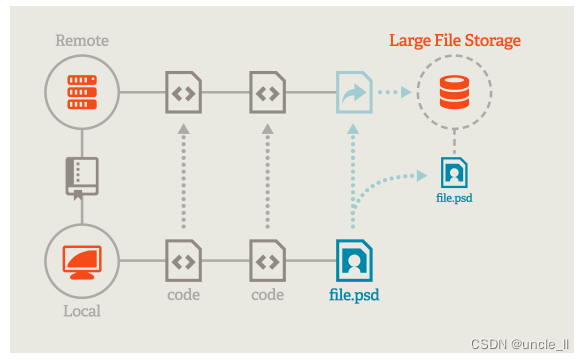
Git LFS: 简单高效的大文件版本控制
Git Large File Storage 问题 在使用git上传大文件时候,git push时候会报错: remote: error: File xxx.tar.gz is 135.17 MB; this exceeds GitHubs file size limit of 100 MB可以看到,git限制上传大小是100MB,超过的话就会报错ÿ…...

如何培养用户思维
产品开发是根据用户要求建造出系统的过程,产品开发是一项包括需求捕捉、需求分析、设计、实现和测试的系统工程,一般通过某种程序设计语言来实现。然而用户思维能够帮助企业更好地理解市场需求,进行产品的开发和完善,用户是企业产…...
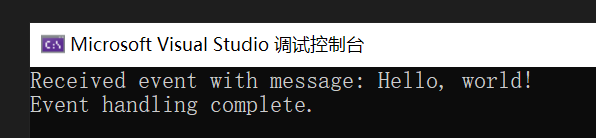
由浅入深理解C#中的事件
目录 本文较长,给大家提供了目录,可以直接看自己感兴趣的部分。 前言有关事件的概念示例 简单示例 标准 .NET 事件模式 使用泛型版本的标准 .NET 事件模式 补充总结 参考前言 前面介绍了C#中的委托,事件的很多部分都与委托…...
 配置文件详解 - server stream服务流)
Nginx(十六) 配置文件详解 - server stream服务流
本篇文章主要讲 ngx_stream_core_module 模块下各指令的使用方法,Nginx默认未配置该模块,需要用“--with-stream”配置参数重新编译Nginx。 worker_processes auto;error_log /var/log/nginx/error.log info;events {worker_connections 1024; }stream…...

Css中默认与继承
initial默认样式: initial 用于设置 Css 属性为默认值 h1 {color: initial; }如display或position不能被设置为initial,因为有默认属性。例如:display:inline inherit继承样式: inherit 用于设置 Css 属性应从父元素继承 di…...

gitee上的vue大屏项目
在 Gitee 上,有几个值得注意的 Vue 大屏项目:vue-big-screen-plugin (Gitee): 这是一个基于 Vue3、Typescript、DataV 和 ECharts5 框架的可视化大屏项目。它使用 .vue 和 .tsx 文件构建界面,并采用新版动态屏幕适配方案。这个项目支持数据的动态刷新渲染,内部的 DataV 和 …...

【LeetCode:114. 二叉树展开为链表 | 二叉树 + 递归】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

社保养老金发放计算方法
退休后养老金计算公式很复杂,自己自行百度查一下,这里说一下男性,女工人,女干部之间计算差别。 退休后,能到手的养老金多少,取决于你的个人账户里的钱,个人账户里的钱越多,到手养老…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...