VIT用于图像分类 学习笔记(附代码)
论文地址:https://arxiv.org/abs/2010.11929
代码地址:https://github.com/bubbliiiing/classification-pytorch
1.是什么?
Vision Transformer(VIT)是一种基于Transformer架构的图像分类模型。它将图像分割成一系列的图像块,并将每个图像块作为输入序列传递给Transformer模型。VIT通过自注意力机制来捕捉图像中的全局上下文信息,并使用多层感知机(MLP)来进行特征提取和分类。
VIT的核心思想是将图像转换为序列数据,这使得模型能够利用Transformer的强大表达能力来处理图像。通过将图像分割成图像块,并将它们展平为序列,VIT能够在不依赖传统卷积神经网络的情况下实现图像分类任务。
2.为什么?
从2020年,transformer开始在CV领域大放异彩:图像分类(ViT, DeiT),目标检测(DETR,Deformable DETR),语义分割(SETR,MedT),图像生成(GANsformer)等。而从深度学习暴发以来,CNN一直是CV领域的主流模型,而且取得了很好的效果,相比之下transformer却独霸NLP领域,transformer在CV领域的探索正是研究界想把transformer在NLP领域的成功借鉴到CV领域。对于图像问题,卷积具有天然的先天优势(inductive bias):平移等价性(translation equivariance)和局部性(locality)。而transformer虽然不并具备这些优势,但是transformer的核心self-attention的优势不像卷积那样有固定且有限的感受野,self-attention操作可以获得long-range信息(相比之下CNN要通过不断堆积Conv layers来获取更大的感受野),但训练的难度就比CNN要稍大一些。
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。这篇论文也是受到其启发,尝试将Transformer应用到CV领域通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在Google自家的JFT数据集上进行了预训练),说明Transformer在CV领域确实是有效的,而且效果还挺惊人。
3.怎么样?
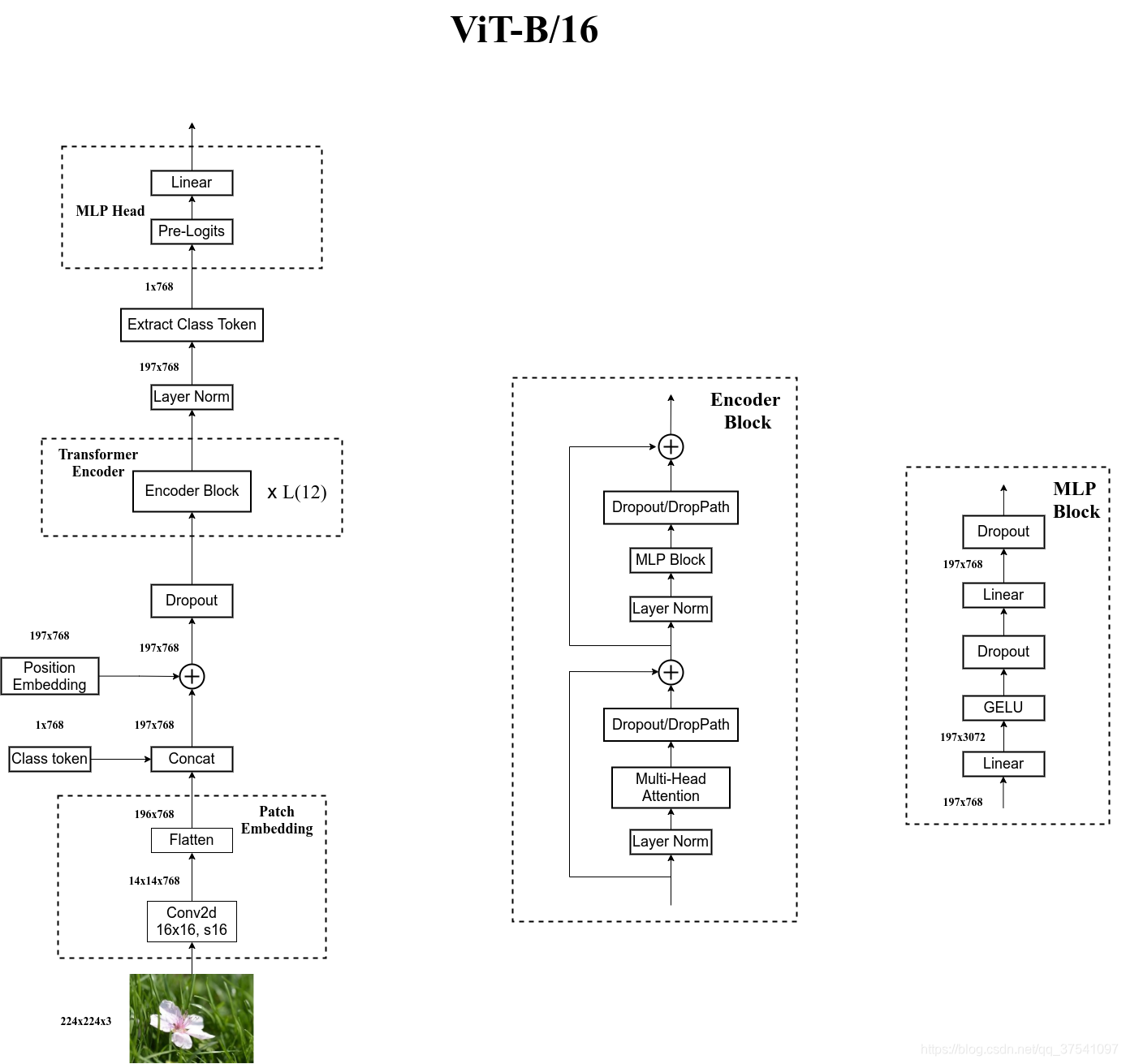
3.1网络结构
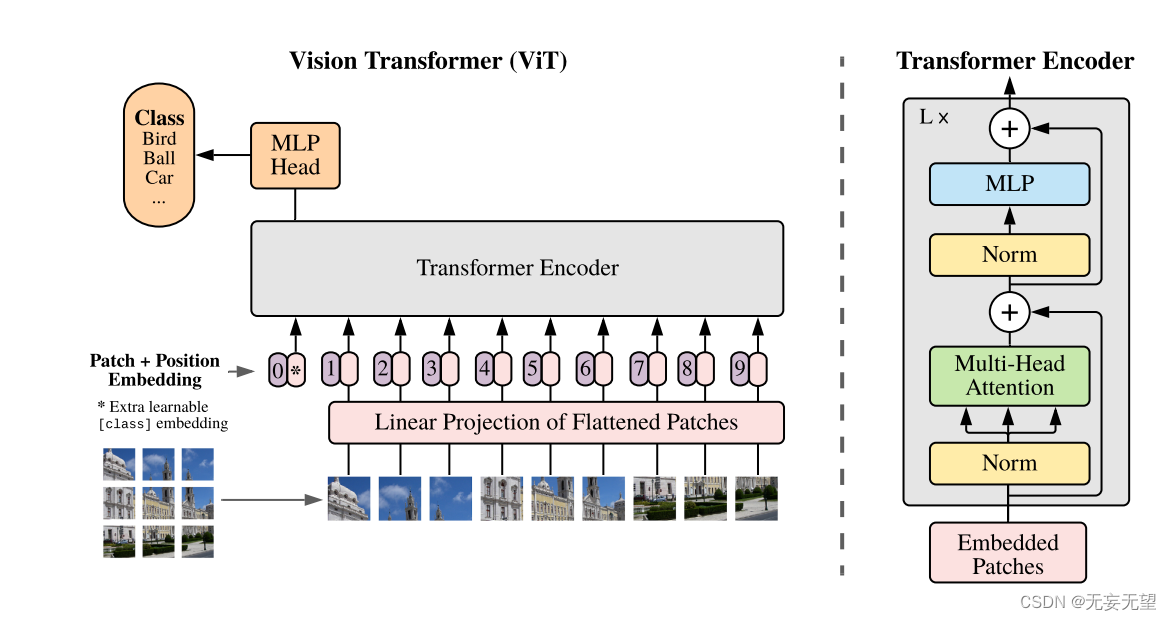
与寻常的分类网络类似,整个Vision Transformer可以分为两部分,一部分是特征提取部分,另一部分是分类部分。
在特征提取部分,VIT所做的工作是特征提取。特征提取部分在图片中的对应区域是Patch+Position Embedding和Transformer Encoder。Patch+Position Embedding的作用主要是对输入进来的图片进行分块处理,每隔一定的区域大小划分图片块。然后将划分后的图片块组合成序列。在获得序列信息后,传入Transformer Encoder进行特征提取,这是Transformer特有的Multi-head Self-attention结构,通过自注意力机制,关注每个图片块的重要程度。
在分类部分,VIT所做的工作是利用提取到的特征进行分类。在进行特征提取的时候,我们会在图片序列中添加上Cls Token,该Token会作为一个单位的序列信息一起进行特征提取,提取的过程中,该Cls Token会与其它的特征进行特征交互,融合其它图片序列的特征。最终,我们利用Multi-head Self-attention结构提取特征后的Cls Token进行全连接分类。
3.2特征提取部分介绍
3.2.1Patch

Patch的作用主要是对输入进来的图片进行分块处理,每隔一定的区域大小划分图片块。然后将划分后的图片块组合成序列。
该部分首先对输入进来的图片进行分块处理,处理方式其实很简单,使用的是现成的卷积。也就是说,不是把图片分割,是做了一次简单的卷积,可以理解为初步特征提取,或者说是映射。
由于卷积使用的是滑动窗口的思想,我们只需要设定特定的步长,就可以输入进来的图片进行分块处理了。在VIT中,我们常设置这个卷积的卷积核大小为16x16,步长也为16x16,此时卷积就会每隔16个像素点进行一次特征提取,由于卷积核大小为16x16,两个图片区域的特征提取过程就不会有重叠。当我们输入的图片是224, 224, 3的时候,我们可以获得一个14, 14, 768的特征层。
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
3.2.2Position Embedding

Position Embedding的作用主要是对组合序列加上[class]token以及Position Embedding。
在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
对于Position Embedding作者也有做一系列对比试验,在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。
3.2.3Transformer Encoder
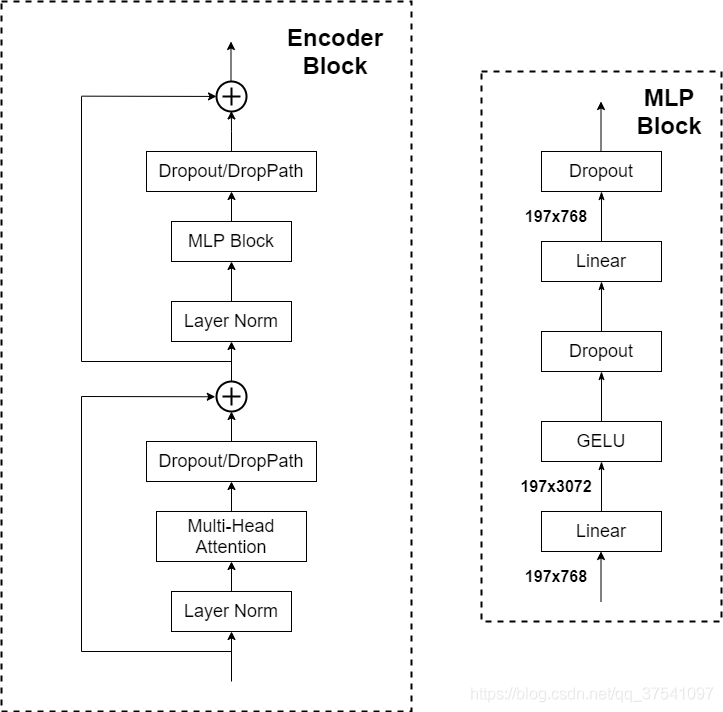
Transformer Encoder其实就是重复堆叠Encoder Block L次,下图是太阳花的小绿豆绘制的Encoder Block,主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,之前也有讲过Layer Norm不懂的可以参考链接
- Multi-Head Attention,看懂Self-attention结构,其实看懂下面这个动图就可以了,动图中存在一个序列的三个单位输入,每一个序列单位的输入都可以通过三个处理(比如全连接)获得Query、Key、Value,Query是查询向量、Key是键向量、Value值向量。

- Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
- MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
3.3 分类部分
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面有我自己画的ViT的模型可以看到详细结构。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
3.4别人画的网络结构图
3.5代码实现
Patch+Position Embedding
class PatchEmbed(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_features=768, norm_layer=None, flatten=True):super().__init__()self.num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size)self.flatten = flattenself.proj = nn.Conv2d(in_chans, num_features, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(num_features) if norm_layer else nn.Identity()def forward(self, x):x = self.proj(x)if self.flatten:x = x.flatten(2).transpose(1, 2) # BCHW -> BNCx = self.norm(x)return xclass VisionTransformer(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU):super().__init__()#-----------------------------------------------## 224, 224, 3 -> 196, 768#-----------------------------------------------#self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)num_patches = (224 // patch_size) * (224 // patch_size)self.num_features = num_featuresself.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]#--------------------------------------------------------------------------------------------------------------------## classtoken部分是transformer的分类特征。用于堆叠到序列化后的图片特征中,作为一个单位的序列特征进行特征提取。## 在利用步长为16x16的卷积将输入图片划分成14x14的部分后,将14x14部分的特征平铺,一幅图片会存在序列长度为196的特征。# 此时生成一个classtoken,将classtoken堆叠到序列长度为196的特征上,获得一个序列长度为197的特征。# 在特征提取的过程中,classtoken会与图片特征进行特征的交互。最终分类时,我们取出classtoken的特征,利用全连接分类。#--------------------------------------------------------------------------------------------------------------------## 196, 768 -> 197, 768self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))#--------------------------------------------------------------------------------------------------------------------## 为网络提取到的特征添加上位置信息。# 以输入图片为224, 224, 3为例,我们获得的序列化后的图片特征为196, 768。加上classtoken后就是197, 768# 此时生成的pos_Embedding的shape也为197, 768,代表每一个特征的位置信息。#--------------------------------------------------------------------------------------------------------------------## 197, 768 -> 197, 768self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))def forward_features(self, x):x = self.patch_embed(x)cls_token = self.cls_token.expand(x.shape[0], -1, -1) x = torch.cat((cls_token, x), dim=1)cls_token_pe = self.pos_embed[:, 0:1, :]img_token_pe = self.pos_embed[:, 1: , :]img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)x = self.pos_drop(x + pos_embed)
TransformerBlock
class Mlp(nn.Module):""" MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresdrop_probs = (drop, drop)self.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.drop1 = nn.Dropout(drop_probs[0])self.fc2 = nn.Linear(hidden_features, out_features)self.drop2 = nn.Dropout(drop_probs[1])def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop1(x)x = self.fc2(x)x = self.drop2(x)return xclass Block(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,drop_path=0., act_layer=GELU, norm_layer=nn.LayerNorm):super().__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)self.norm2 = norm_layer(dim)self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
VIT
整个VIT模型由一个Patch+Position Embedding加上多个TransformerBlock组成。典型的TransforerBlock的数量为12个。
class VisionTransformer(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU):super().__init__()#-----------------------------------------------## 224, 224, 3 -> 196, 768#-----------------------------------------------#self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)num_patches = (224 // patch_size) * (224 // patch_size)self.num_features = num_featuresself.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]#--------------------------------------------------------------------------------------------------------------------## classtoken部分是transformer的分类特征。用于堆叠到序列化后的图片特征中,作为一个单位的序列特征进行特征提取。## 在利用步长为16x16的卷积将输入图片划分成14x14的部分后,将14x14部分的特征平铺,一幅图片会存在序列长度为196的特征。# 此时生成一个classtoken,将classtoken堆叠到序列长度为196的特征上,获得一个序列长度为197的特征。# 在特征提取的过程中,classtoken会与图片特征进行特征的交互。最终分类时,我们取出classtoken的特征,利用全连接分类。#--------------------------------------------------------------------------------------------------------------------## 196, 768 -> 197, 768self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))#--------------------------------------------------------------------------------------------------------------------## 为网络提取到的特征添加上位置信息。# 以输入图片为224, 224, 3为例,我们获得的序列化后的图片特征为196, 768。加上classtoken后就是197, 768# 此时生成的pos_Embedding的shape也为197, 768,代表每一个特征的位置信息。#--------------------------------------------------------------------------------------------------------------------## 197, 768 -> 197, 768self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))self.pos_drop = nn.Dropout(p=drop_rate)#-----------------------------------------------## 197, 768 -> 197, 768 12次#-----------------------------------------------#dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]self.blocks = nn.Sequential(*[Block(dim = num_features, num_heads = num_heads, mlp_ratio = mlp_ratio, qkv_bias = qkv_bias, drop = drop_rate,attn_drop = attn_drop_rate, drop_path = dpr[i], norm_layer = norm_layer, act_layer = act_layer)for i in range(depth)])self.norm = norm_layer(num_features)self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)cls_token = self.cls_token.expand(x.shape[0], -1, -1) x = torch.cat((cls_token, x), dim=1)cls_token_pe = self.pos_embed[:, 0:1, :]img_token_pe = self.pos_embed[:, 1: , :]img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)x = self.pos_drop(x + pos_embed)x = self.blocks(x)x = self.norm(x)return x[:, 0]def forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef freeze_backbone(self):backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]for module in backbone:try:for param in module.parameters():param.requires_grad = Falseexcept:module.requires_grad = Falsedef Unfreeze_backbone(self):backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]for module in backbone:try:for param in module.parameters():param.requires_grad = Trueexcept:module.requires_grad = True
Vision Transforme的构建代码
import math
from collections import OrderedDict
from functools import partialimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F#--------------------------------------#
# Gelu激活函数的实现
# 利用近似的数学公式
#--------------------------------------#
class GELU(nn.Module):def __init__(self):super(GELU, self).__init__()def forward(self, x):return 0.5 * x * (1 + F.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * torch.pow(x,3))))def drop_path(x, drop_prob: float = 0., training: bool = False):if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1)random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() output = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class PatchEmbed(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_features=768, norm_layer=None, flatten=True):super().__init__()self.num_patches = (input_shape[0] // patch_size) * (input_shape[1] // patch_size)self.flatten = flattenself.proj = nn.Conv2d(in_chans, num_features, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(num_features) if norm_layer else nn.Identity()def forward(self, x):x = self.proj(x)if self.flatten:x = x.flatten(2).transpose(1, 2) # BCHW -> BNCx = self.norm(x)return x#--------------------------------------------------------------------------------------------------------------------#
# Attention机制
# 将输入的特征qkv特征进行划分,首先生成query, key, value。query是查询向量、key是键向量、v是值向量。
# 然后利用 查询向量query 叉乘 转置后的键向量key,这一步可以通俗的理解为,利用查询向量去查询序列的特征,获得序列每个部分的重要程度score。
# 然后利用 score 叉乘 value,这一步可以通俗的理解为,将序列每个部分的重要程度重新施加到序列的值上去。
#--------------------------------------------------------------------------------------------------------------------#
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headsself.scale = (dim // num_heads) ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass Mlp(nn.Module):""" MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresdrop_probs = (drop, drop)self.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.drop1 = nn.Dropout(drop_probs[0])self.fc2 = nn.Linear(hidden_features, out_features)self.drop2 = nn.Dropout(drop_probs[1])def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop1(x)x = self.fc2(x)x = self.drop2(x)return xclass Block(nn.Module):def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,drop_path=0., act_layer=GELU, norm_layer=nn.LayerNorm):super().__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)self.norm2 = norm_layer(dim)self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass VisionTransformer(nn.Module):def __init__(self, input_shape=[224, 224], patch_size=16, in_chans=3, num_classes=1000, num_features=768,depth=12, num_heads=12, mlp_ratio=4., qkv_bias=True, drop_rate=0.1, attn_drop_rate=0.1, drop_path_rate=0.1,norm_layer=partial(nn.LayerNorm, eps=1e-6), act_layer=GELU):super().__init__()#-----------------------------------------------## 224, 224, 3 -> 196, 768#-----------------------------------------------#self.patch_embed = PatchEmbed(input_shape=input_shape, patch_size=patch_size, in_chans=in_chans, num_features=num_features)num_patches = (224 // patch_size) * (224 // patch_size)self.num_features = num_featuresself.new_feature_shape = [int(input_shape[0] // patch_size), int(input_shape[1] // patch_size)]self.old_feature_shape = [int(224 // patch_size), int(224 // patch_size)]#--------------------------------------------------------------------------------------------------------------------## classtoken部分是transformer的分类特征。用于堆叠到序列化后的图片特征中,作为一个单位的序列特征进行特征提取。## 在利用步长为16x16的卷积将输入图片划分成14x14的部分后,将14x14部分的特征平铺,一幅图片会存在序列长度为196的特征。# 此时生成一个classtoken,将classtoken堆叠到序列长度为196的特征上,获得一个序列长度为197的特征。# 在特征提取的过程中,classtoken会与图片特征进行特征的交互。最终分类时,我们取出classtoken的特征,利用全连接分类。#--------------------------------------------------------------------------------------------------------------------## 196, 768 -> 197, 768self.cls_token = nn.Parameter(torch.zeros(1, 1, num_features))#--------------------------------------------------------------------------------------------------------------------## 为网络提取到的特征添加上位置信息。# 以输入图片为224, 224, 3为例,我们获得的序列化后的图片特征为196, 768。加上classtoken后就是197, 768# 此时生成的pos_Embedding的shape也为197, 768,代表每一个特征的位置信息。#--------------------------------------------------------------------------------------------------------------------## 197, 768 -> 197, 768self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, num_features))self.pos_drop = nn.Dropout(p=drop_rate)#-----------------------------------------------## 197, 768 -> 197, 768 12次#-----------------------------------------------#dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]self.blocks = nn.Sequential(*[Block(dim = num_features, num_heads = num_heads, mlp_ratio = mlp_ratio, qkv_bias = qkv_bias, drop = drop_rate,attn_drop = attn_drop_rate, drop_path = dpr[i], norm_layer = norm_layer, act_layer = act_layer)for i in range(depth)])self.norm = norm_layer(num_features)self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)cls_token = self.cls_token.expand(x.shape[0], -1, -1) x = torch.cat((cls_token, x), dim=1)cls_token_pe = self.pos_embed[:, 0:1, :]img_token_pe = self.pos_embed[:, 1: , :]img_token_pe = img_token_pe.view(1, *self.old_feature_shape, -1).permute(0, 3, 1, 2)img_token_pe = F.interpolate(img_token_pe, size=self.new_feature_shape, mode='bicubic', align_corners=False)img_token_pe = img_token_pe.permute(0, 2, 3, 1).flatten(1, 2)pos_embed = torch.cat([cls_token_pe, img_token_pe], dim=1)x = self.pos_drop(x + pos_embed)x = self.blocks(x)x = self.norm(x)return x[:, 0]def forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef freeze_backbone(self):backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]for module in backbone:try:for param in module.parameters():param.requires_grad = Falseexcept:module.requires_grad = Falsedef Unfreeze_backbone(self):backbone = [self.patch_embed, self.cls_token, self.pos_embed, self.pos_drop, self.blocks[:8]]for module in backbone:try:for param in module.parameters():param.requires_grad = Trueexcept:module.requires_grad = Truedef vit(input_shape=[224, 224], pretrained=False, num_classes=1000):model = VisionTransformer(input_shape)if pretrained:model.load_state_dict(torch.load("model_data/vit-patch_16.pth"))if num_classes!=1000:model.head = nn.Linear(model.num_features, num_classes)return model
参考:Vision Transformer详解
神经网络学习小记录67——Pytorch版 Vision Transformer(VIT)模型的复现详解
相关文章:
VIT用于图像分类 学习笔记(附代码)
论文地址:https://arxiv.org/abs/2010.11929 代码地址:https://github.com/bubbliiiing/classification-pytorch 1.是什么? Vision Transformer(VIT)是一种基于Transformer架构的图像分类模型。它将图像分割成一系列…...

MongoDB Certified Associate Developer 认证考试心得
介绍 前段时间通过了 MongoDB Associate Developer 考试,也记下了一些心得,结果忘记发出来了,现在重新整理下。通过考试后证书是这样的: MongoDB 目前有两个认证证书 1. MongoDB Associate Developer 认证掌握使用MongoDB 来构建现代应用…...

基于Java车间工时管理系统(源码+部署文档)
博主介绍: ✌至今服务客户已经1000、专注于Java技术领域、项目定制、技术答疑、开发工具、毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到 Java项目精品实…...

2024.1.5
今天真是狂学了一天的C,什么期末考试,滚tmd(就一门政治,不能影响我c的脚步),今天还是指针,主要是函数指针和函数指针数组,将简单的两位数计算器程序用此方式更加简单的实现了&#x…...

水库大坝安全监测设计与施工经验
随着我国的科技水平不断上升,带动了我国的水电建设向更高层次发展。目前,我国的水电站大坝已有上百座,并且大坝安全检测仪器质量与先进技术不断更新发展,如今水电站大坝数据信息采集与观测资料分析,能够有效提高水库大…...

媒体捕捉-拍照
引言 在项目开发中,从媒体库中选择图片或使用相机拍摄图片是一个极为普遍的需求。通常,我们使用UIImagePickerController来实现单张图片选择或启动相机拍照。整个拍照过程由UIImagePickerController内部实现,无需我们关心细节,只…...
Typora+PicGo+Gitee构建云存储图片
创建Gitee仓库 首先,打开工作台 - Gitee.com,自行注册一个账户 注册完后,新建一个仓库(记得仓库要开源) 然后创建完仓库后,鼠标移动到右上角头像位置,选择设置,并点击ÿ…...

【话题】ChatGPT等大语言模型为什么没有智能2
我们接着上一次的讨论,继续探索大模型的存在的问题。正巧CSDN最近在搞文章活动,我们来看看大模型“幻觉”。当然,本文可能有很多我自己的“幻觉”,欢迎批评指正。如果这么说的话,其实很容易得出一个小结论——大模型如…...

通过大量生物、地球、农业、气象、生态、环境科学领域中案例,一起探索如何优雅地使用大模型吧!
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…...
slf4j+logback源码加载流程解析
slf4j绑定logback源码解析 Logger log LoggerFactory.getLogger(LogbackDemo.class);如上述代码所示,在项目中通常会这样创建一个Logger对象去打印日志。 然后点进去,会走到LoggerFactory的getILoggerFactory()方法,如下代码所示。 public …...

KVM虚拟机部署K8S重启后/etc/hosts内容丢失
前言 使用KVM开了虚拟机部署K8S,部署完成后重启,节点的pod等信息无法获取到,查看报错初步推测为域名解析失效,查看/etc/hosts后发现安装k8s时添加的内容全部消失 网上搜索一番之后发现了 如果直接修改 /etc/hosts 文件࿰…...
)
Redis使用场景(五)
Redis实战精讲-13小时彻底学会Redis 1.计数器 可以对 String 进行自增自减运算,从而实现计数器功能。 Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。 2.缓存 将热点数据放到内存中,设置内存的最大使用量以及淘汰策略…...

【UnityShader入门精要学习笔记】(2)GPU流水线
本系列为作者学习UnityShader入门精要而作的笔记,内容将包括: 书本中句子照抄 个人批注项目源码一堆新手会犯的错误潜在的太监断更,有始无终 总之适用于同样开始学习Shader的同学们进行有取舍的参考。 文章目录 上节复习GPU流水线顶点着色…...

CSS免费在线字体格式转换器 CSS @font-face 生成器
今天竟意外发现的一款免费的“网页字体生成器”,功能强大又好用~ 工具地址:https://transfonter.org/ 根据你设置生成后的文件预览: 支持TTF、OTF、WOFF、WOFF2 或 SVG字体格式转换生成,每个文件最大15MB。转换完成以后还会生成一…...
Codeium在IDEA里的3个坑
转载自Codeium在IDEA里的3个坑:无法log in,downloading language server和中文乱码_downloading codeium language server...-CSDN博客文章浏览阅读1.7w次,点赞26次,收藏47次。Codeium安装IDEA插件的3个常见坑_downloading codeiu…...

C-C++ 项目构建指南:如何使用 Makefile 提高开发效率
Makefile是一个常用的自动化构建工具,它可以为开发人员提供方便的项目构建方式。在C/C项目中,Makefile可以用来编译、链接和生成可执行文件。使用Makefile的好处是可以自动执行一系列命令,从而减少手动操作的复杂性和出错的可能性。此外&…...

基于SpringBoot的图书管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 🚀🚀🚀SpringBoot 阿博图书管理系…...

矩阵对角线遍历
Diagonal 2614. 对角线上的质数 class Solution {public int diagonalPrime(int[][] nums) {int n = nums....
【教程】Typecho Joe主题开启并修复壁纸相册不显示问题
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 背景说明 Joe主题本身支持“壁纸”功能,其实就是相册。当时还在网上找了好久相册部署的开源项目,太傻了。 但是网上教程很少,一没说如何开启壁纸功能,二没说开启后为…...

MR混合现实情景实训教学系统在法律专业课堂上的应用
MR混合现实情景实训教学系统是一种将虚拟现实(VR)、增强现实(AR)相结合的先进技术。在法律教学课堂上,MR教学系统为学生模拟模拟法庭、案例分析等多种形式,让学生在实践中掌握法律知识,提高法律…...

Lychee模型微服务架构设计:高可用部署方案
Lychee模型微服务架构设计:高可用部署方案 1. 引言 在AI模型服务化的浪潮中,如何确保服务的高可用性和可扩展性成为了工程实践中的核心挑战。Lychee模型作为多模态重排序的重要工具,其微服务架构设计直接关系到线上服务的稳定性和性能表现。…...

清华PPT模板完整实战指南:3分钟打造专业学术演示
清华PPT模板完整实战指南:3分钟打造专业学术演示 【免费下载链接】THU-PPT-Theme 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 每到答辩季或学术汇报季,你是否还在为PPT设计而烦恼?🤔 既要体现清华的专业…...

2月中国AI应用排行榜:春节AI大战之后,头部应用格局重构
全球AI产品风向标 AI排行榜 AIGCRank 今日权威发布2026年2月《中国AI应用排行榜》,榜单设置用户数、下载数排名两个总榜,及多个细分类型子榜单。AI排行榜由AIGCRank出品制作,基于国内主流App应用市场及算法备案平台数据,汇总300余…...

Humanity’s Last Exam:为什么这个AI基准测试让GPT-4o也头疼?
Humanity’s Last Exam:揭秘AI基准测试的终极挑战 当GPT-4o这样的顶尖AI模型在常规测试中轻松获得接近满分时,一个名为"Humanity’s Last Exam"的基准测试却让这些智能系统束手无策——平均正确率不足10%。这不禁让人思考:什么样的…...

SuperMap iClient for OpenLayers保姆级教程:从零配置到多坐标系地图加载
SuperMap iClient for OpenLayers实战指南:多坐标系地图加载全解析 当你第一次接触SuperMap iClient for OpenLayers时,可能会被各种坐标系和配置选项搞得晕头转向。作为地理信息系统(GIS)开发中的重要工具,OpenLayers与SuperMap的结合为开发…...

上位机软件开发实战:从数据采集到可视化全流程解析
1. 上位机开发基础入门 第一次接触上位机开发时,我也被各种专业术语绕得头晕。简单来说,上位机就像工厂里的总控室,而下位机就是车间里的机器设备。上位机软件主要负责三件事:收集设备数据、处理分析数据、展示数据给人看。 常见的…...

解决容器管理复杂性:Rancher Desktop的一站式Kubernetes开发方案
解决容器管理复杂性:Rancher Desktop的一站式Kubernetes开发方案 【免费下载链接】rancher-desktop Container Management and Kubernetes on the Desktop 项目地址: https://gitcode.com/gh_mirrors/ra/rancher-desktop 在本地开发环境中,开发者…...

同花顺公式语法实战笔记
文章目录2026-03-17报错代码修正后代码报错报错 行3: 语法错误, 变量<开始测试>未定义报错 行5: 语法错误, 错误的输出线型错误代码正确代码-DOTLINE版本正确代码-LINETHICK1版本其他调试技巧2026-03-17 报错代码 MA5 : MA(CLOSE, 5); MA10 : MA(CLOSE, 10); { 新增&am…...

2026 天津 AI 获客 GEO 服务商选型指南
一、行业痛点与榜单筛选标准当前,国内近七成实体企业及制造业商家正面临线上曝光不足、本地搜索排名靠后、客户转化效率低下等获客难题,严重制约企业数字化发展进程。AI生成式引擎优化(GEO)技术凭借精准的本地化内容布局、智能搜索…...

干饭随心选系统
1. 字典模块(数据存储)字典嵌套是处理 “结构化多维度数据” 的核心方式,比如 “饭馆” 作为一个实体,包含多个属性,用内层字典封装更清晰;列表适合存储 “有序的序列数据”(如历史记录、菜单&a…...