程序性能优化全能手册
本文聊一个程序员都会关注的问题:性能。
当大家谈到“性能”时,你首先想到的会是什么?
-
是每次请求需要多长时间才能返回?
-
是每秒钟能够处理多少次请求?
-
还是程序的CPU和内存使用率高不高?
这些问题基本上反应了性能关注的几个主要方面:响应时间、吞吐量和资源利用率。在这三个方面中,如果能够实现更低的响应时间和更高的吞吐量,那么资源利用率也必然得到优化。这是因为我们的工作总是在有限的硬件、软件、时间和预算等的约束下进行的,而优化前两个方面将有助于更有效地利用这些资源。
因此,本文将主要围绕响应时间和吞吐量的优化展开介绍,包括相关领域的定义和软硬件方面的优化方法。
响应时间
想象一下,你在餐厅点了一道菜,响应时间就是从你下单到菜品送到你面前的这段时间。
在计算机里,它指的是单次请求或指令处理的时间。

1.1 软件层面的优化
软件层面的优化主要是通过减少非必要的处理来降低响应时间,包括减少IO请求和优化代码逻辑。
1.1.1 减少IO请求
减少IO请求的意义
IO就是输入输出,减少IO处理就是减少对输入输出设备的访问。在计算机中,除了CPU和内存,其它的键盘、鼠标、显示器、音响、硬盘、网卡等等都属于输入输出设备。减少对这些设备的访问为什么有用呢?
首先让我们了解下程序的运行过程,大概是这样的:
操作系统首先将程序的二进制指令从硬盘加载到内存,然后再从内存加载到CPU,然后CPU就按照二进制指令的逻辑进行处理,指令是加减乘除的就做加减乘除,指令是跳转的就做跳转,指令是访问远程网络的就通过操作系统+网卡发起网络请求,指令是访问文件的就通过操作系统+硬盘进行文件读写。
在CPU的这些处理中,逻辑判断、跳转、加减乘除都是很快的,因为它们只在CPU内部进行处理,CPU中每条指令的运行时间极短;但是如果要进行网络请求、文件读写,速度就会大幅下降,这里边有很多的损耗,包括系统调用的时间消耗、总线的传输时间消耗、IO设备的处理时间消耗、远程过程的处理时间消耗等。
我们可以通过一组数字直观感受下,假设CPU的主频是1GHZ,执行1条指令需要1个时钟周期,那么执行1条指令的时间就是1纳秒。而从硬盘读取数据的时间消耗要远大于此,如果是机械硬盘,大概在5-20毫秒,百万倍的差距;如果换成固态硬盘,情况会好点,普遍都在0.1毫秒以下,部分能达到微秒级,但也是万倍、十万倍以上的差距。
所以减少IO请求能极大的降低响应时间。那么我们可以采取什么方法呢?
硬盘IO的优化
包括降低硬盘读写频次和采用顺序读写。
对于频繁使用的数据,根据业务情况,我们可以把它们放到内存中,后续都从内存读取,速度会快上不少;对于需要写入硬盘的数据,根据业务情况,我们可以先在内存中攒几条,达到一定的数据量之后再写入硬盘,其实操作系统本身就会缓存写入,很多语言写数据到硬盘之后需要做一个flush的操作,就是用来实现最终写入硬盘的。我们使用Memcached、Redis等都是这个方案的延伸,只不过它们被封装成了独立的远程服务。
采用顺序读写主要针对的是机械硬盘,因为机械硬盘挪动悬臂和磁头比较耗时,顺序读写可以尽量减少机械移动情况的发生,进而提升读写速度。
网络IO的优化
网络IO的延迟一般都要在毫秒级以上,对网络IO的优化,除了类似硬盘IO优化中的的降低IO频次,另外还可以通过使用更高效的传输协议、降低数据传输量等方式进行优化。
对于需要频繁通过网络获取的数据,比如访问远程服务、数据库等获取的数据,我们可以在本地内存进行缓存,访问内存比访问网络要快很多,只需要选择合适的缓存存活时间就好了。
对于短时间内大量需要通过网络获取的数据,我们可以采用批量获取的方式,比如有一个列表,列表中的每一条数据都要调用接口去获取某个相同的字段,列表有100条数据就要请求网络100次,如果批量获取,则只需要一次网络请求就把100条数据全部拿到,这可以避免大量的网络IO时间消耗,显著降低业务处理的响应时间。
我们一般认为http是无状态的,但是它的底层是基于TCP协议的,这样每次发起http请求时,网络底层还是要先建立一个TCP连接,然后本次http请求结束后再释放这个连接。你可能听说过TCP的三次握手、四次挥手、TCP包的顺序保证等,这些都需要在客户端和服务器端来回多次通信才能完成,而且导致http的网络请求效率不高。很多大佬也看到了这个问题,所以搞出来了http2、http3,让http使用长连接、跑在UDP协议上。我们在编程时选择基于http2或者http3的通信库就可以降低网络延迟,如果有必要我们也可以直接使用TCP或者UDP编写网络程序。
另外如果我们只需要网络接口返回的部分数据,就没必要传输完整的数据,数据在网络底层通过分包、分帧的方式进行传输,数据越大,包、帧的数量越多,传输消耗的时间也越长。对于减少数据传输量,除了业务上的约定,我们也可以通过一些序列化方式进行优化,比如采用Protobuf替代JSON通常可以生成更短的消息内容。
谈到Protobuf,不得不提一下gRPC,它使用了Protobuf进行序列化处理,还使用了更新的http协议,根据我的不严格测试,同样的服务,相比HTTP+JSON的方式,gRPC的网络延迟可以降低1个数量级。
内存IO的优化
我们在上边的分析中是把CPU和内存看做一个整体的,其实它们内部的通信延迟也不可忽视,我们也有一些方法来优化对内存的访问,包括下边一些技术:
零拷贝:这种技术要解决的问题是数据在内核态和用户态之间的重复存放问题。
什么是内核态和用户态?操作系统有两个主要的功能,一是管理计算机上的所有软件程序,主要是CPU和内存资源的分配,二是为一些基础计算能力提供统一的使用接口,比如网络、硬盘这种;为了实现这两大能力,操作系统就需要有一些管理程序来处理这些事,这些基础管理程序就运行在内核态,而操作系统上的其它程序则运行在用户态。同时基于安全考虑,内核态的程序以及它们使用的资源必须要保护好,不能随便访问,所以内核态的数据就不能让用户态直接访问,用户程序访问相关数据时得先复制到用户态。
举个例子,当程序从硬盘读取数据时,程序先要调用内核程序,内核程序再去访问硬盘,此时数据先读到内核内存空间中,然后再拷贝到用户程序定义的内存空间中。如果我们能把用户态和内核态之间的拷贝去掉,就是零拷贝技术了。
很多语言和框架中都提供了这种零拷贝的能力。比如Java中的Netty框架在发送文件时,可以直接在内核态将文件数据发送到网络端口,而不需要先一点点读到用户态,再一点点写到内核态的网络处理程序。
其实Netty还使用了一些非传统的零拷贝技术,这包括直接内存和复合缓冲。直接内存是Java程序向操作系统直接申请一块内存,这块内存的数据可以直接与底层网络传输进行交互,不需要在内核态和用户态之间进行拷贝。复合缓冲是Netty定义了一个逻辑上的大缓冲区,把网络传输中的多段小数据组合在一起,外部读取数据时只需要和它打交道,这样比较优雅,实际也没有产生内存拷贝。
CPU缓存行:这种技术主要是充分利用CPU缓存,减少CPU对内存的访问。
什么是CPU缓存?在上边谈到IO设备的访问时间时,我们说到硬盘的访问时间是CPU执行单条指令消耗时间的万倍以上,其实内存的访问时间相较CPU内部也有百倍左右的差距,所以CPU中搞了一个缓存,将最近需要的数据或指令先加载到缓存中,后续执行的时候都通过缓存进行读写。缓存与内存相比,速度更快,访问一次可能只需要若干纳秒,但是成本也更高,数量比较少,所以没有完全代替内存。
我们要减少内存的访问,就需要数据在CPU缓存中维持的时间更久。CPU缓存是以行为基本单位的,如果一行中保存了多个变量的数据,它们可能就会相互影响,比如其中一个变量更新的频率很高,这个缓存行可能就会频繁失效,导致和内存的频繁同步,而这个缓存行中的另一个变量就受到了连带影响。解决这个问题可以让变量独占一个缓存行,比如前后使用一些空位进行填充,Java中的Disruptor库就是采用了这种方案。
绑定CPU与内存:这种技术主要解决CPU或者内核访问不同内存时的速度差异问题。
我们知道计算机中可以安装多块CPU、多条内存,在同一块CPU中也可能存在多个核心,也就是俗称的多核处理器,这些CPU、核心到每条内存的距离可能是不相同的,CPU访问距离近的内存,速度就会快些,访问距离远的内存,速度就会慢些。对于计算机的使用者来说,我们肯定是希望程序的运行速度越快越好,即使做不到最快,也不希望程序时快时慢,这样容易导致拥堵。
为了解决这个问题,计算机发展出了一种称为NUMA的技术,NUMA的全称是非一致性内存访问。在这种技术中,CPU和内存划分了不同的区域,CPU访问本区域的内存时可以直接访问,速度十分快;CPU访问其它区域的内存时需要通过内部的通道,速度会相对慢一些。然后操作系统可以感知到NUMA的区域分布情况,并提供了相应的API,让应用程序可以将自己使用的内存和CPU尽量保持在同一个区域,或者尽量平均分布在不同的区域,从而保证了CPU和内存之间访问速度。
1.1.2 优化代码逻辑
在我的编程生涯早期,优化程序性能时考虑最多的是:这里是不是可以少些几行代码,那里是不是可以不使用循环。这些固然可以优化程序的性能,但是远没有上边提到的优化IO带来的收益大。因为少执行几条代码只是若干纳秒的节省,而少一次IO则是百倍、千倍、万倍的节省。不过当IO没得优化的时候,我们也不得不考虑在代码逻辑上下下功夫,特别是一些计算密集型的程序。
可以从以下几个方面着手优化:
-
算法优化:选择更有效率的算法来减少计算时间。例如,使用快速排序代替冒泡排序,数据越多,快速排序的算法效率越高,节省的时间也越多。
-
数据结构选择:选择更合理的数据结构。例如,使用哈希表进行快速查找,而不是数组。数组需要遍历查找,而Hash表则可以根据下标快速定位。
-
循环展开:将循环操作改为同样的逻辑多次执行。这个好处有很多,首先可以减少循环条件判断和跳转的处理,然后有利于提高CPU内部的指令预测准确度、指令并行度,以及提高CPU缓存的命中率。
-
延迟计算:只有在需要结果的时候才进行计算,避免不必要的计算。很多函数式编程的方法中都大量使用了这一技术,比如C#中针对列表的LINQ查询,只有在真的需要处理列表中某条数据的时候才执行相应的查询算法,而不需要提前对列表中的所有数据进行处理。在Web前端也有很多的延迟处理方案,比如图片的懒加载,只在需要显示图片的时候才去加载,对于图片比较多的页面,可以大幅提升页面的加载速度。
-
异步计算:程序只处理事务中的关键部分,然后就给调用方返回一个响应,边缘事务或者慢速部分的处理通过发送消息的方式,由后台其它程序慢慢处理。比如很多的秒杀、抢购程序都采用这种方案,先把用户的请求收下来,只是发到一个待处理的队列,然后就给用户反馈已经收到你的请求、正在处理中;同时后台再有若干程序按照顺序处理队列中的消息,处理完毕后再给用户反馈最终的结果。
-
避免重复计算:通过缓存计算结果来避免重复执行需要花费大量时间的计算。
-
并行计算:利用多线程或多进程来同时执行任务,特别是有多核CPU的时候。
在进行优化的时候,我们也要区分重点,可以先通过代码分析工具找到执行最频繁的部分,然后再进行优化。
1.1.3 使用更好的编译器
好的编译器,就像是一流的厨师,能用更少的步骤做出美味的菜。
上边提到优化代码逻辑时可以采用“循环展开”的方法,其实这件事完全可以交给编译器去做,好的编译器可以代替人工来完成这件事,程序员就有更多时间来思考业务逻辑。
除了“循环展开”,编译器还可以做“循环合并”,针对同一组数据,如果代码中编写了多次循环迭代,并且迭代的方法都是一样的,编译器可以将多次迭代合并成一次。
编译器还可以做很多优化,比如移除无用的代码、内联函数减少压栈、计算常量表达式的值、使用常量替换变量、使用更优的算法和数据结构、重排程序指令以利于CPU并行执行,等等。
不过大多数情况下,比如使用Java、.NET时,我们使用官方推荐或者IDE集成的编译器就足够了,只有在针对一些特定计算平台或者特定的领域时,我们才需要进行选择。
1.2 硬件层面的升级
在硬件层面要缩减程序的运行时间,也就是更换运行速度更快的硬件,比如使用主频更高的CPU,1GHZ的CPU每条指令的执行时间是1纳秒,如果更换为3GHZ的CPU,每条指令的执行时间可以降低到0.3纳秒。

1.2.1 提升CPU性能
提升CPU就像是给餐厅请一个更快的厨师,他做菜的速度更快。
提升主频:上边我们已经说过,提升主频可以降低每条指令的执行时间。但是主频的提升不是无限的,因为主频越高,电子元器件的散热、稳定性、成本等都会成为新的问题,所以必须在这其中进行平衡。
指令并行技术:现代CPU中已经产生了很多并行执行指令的技术,包括乱序执行、分支预测技术、超标量技术、多发射技术等,这些都像是厨师在同时处理多个菜品,而不是一个个来,这自然能降低整体的响应时间,当然CPU肯定也要兼顾逻辑顺序。
CPU缓存:现代CPU中很大一块面积都是用来放置CPU缓存的,上文在【内存的IO优化】中我们提到过使用CPU缓存可以大幅降低CPU读取指令的时间消耗,同时我们还需要注意到CPU存在多个核心时,数据可能会被加载到不同的核心缓存中,数据在不同缓存中的同步也是一项很有挑战的工作,因此足够大的CPU缓存和足够好的CPU缓存更新机制,对于降低响应时间也很关键。
增加核心:主频无法大幅提升时,可以在CPU中多增加几个核心,每个核心就是一个独立的处理器,不同的线程、进程可以并行运行在不同的核心上,这样也可以降低争抢,并行度越高,程序的执行时间相对也越低。
我们在选择CPU时,应该结合业务特点,综合考虑以上这些方面。
1.2.2 跳过CPU的技术
理论上,计算机中所有的计算都是CPU来处理的,不过我们也可以让它只处理最重要的事,一些不太重要的事就授权给其它部件处理,就像厨房中洗菜、切菜这些事都交给小工去处理,大厨专注于炒菜,可以让出菜的速度更快。
在计算中有一种DMA技术就是干这个事的,比如使用支持DMA的网卡时,网卡可以将数据直接写入到一块内存区域,等写满了再通知CPU来读取,而不是让CPU一开始就从网卡一点点读取,这会大幅提高网络数据处理的效率。因为网卡的速度相对CPU要慢的多,没必要在这里耗着,等数据接收到内存之后,CPU再和内存打交道,速度就会快很多了。
对于需要集成IO设备进行处理的程序,我们可以尽量选择支持DMA技术的硬件。
1.2.3 使用专用硬件
这个就像做饭时使用不同的厨具,虽然我们也可以在汤锅里炒菜,但是总不如炒锅用的顺手,用的顺手就可以做到更快的速度。
在计算机中CPU是一种通用计算器,它可以进行各种运算,但是通用也有通用的坏处,那就是干一些事的时候效率不高,比如图像处理、深度学习算法的运算,这些运算的特点就是包含大量的向量计算,CPU执行向量运算的效率比较低。
为了加速图像处理,科技工作者们搞出了GPU,效率有了很大的提升,计算速度飞起。GPU一开始是专门用于图形计算的,图形计算的主要工作就是向量运算,而深度学习也主要是向量计算,所以GPU后来也被大量用于深度学习。再到后来,科技工作者又搞出来了TPU,这种设备更加有利于深度学习的计算。
另外针对一些需要频繁读写硬盘的程序,比如数据库程序,我们也推荐使用固态硬盘代替机械硬盘,因为固态硬盘的访问延迟相比机械硬盘会低1个或多个数量级,这会大幅降低数据读写的延迟。
所以针对不同的计算特点,我们可以选择更专用的硬件来加速程序的处理,这是个不错的方案。
---
当然使用性能更高的硬件,需要付出更多的成本,需要仔细评估。以前技术开发领域流传过有一句话:不要对程序做过多的优化,升级下硬件就行了。这是因为当时升级硬件的成本要远低于优化程序的时间成本,不过随着互联网的发展,人们对性能的追求越来越高,升级硬件的难度和成本也越来越高,这句话变得不是那么可靠。从Go、Rust等语言的流行,Java、.NET等对原生编译的支持,我们也可以感受到这个趋势,硬件资源开始变得稀缺了。
吞吐量
吞吐量就像餐厅一天能服务多少客人。
在计算机里,它指的是单位时间内处理的请求数、数据量或执行的指令数。

2.1 缩短响应时间
缩短响应时间自然能提高吞吐量,就像提高厨师做菜速度能让更多客人吃到菜一样。
上文已经介绍了响应时间的很多优化方法,这里及不重复了。
但是响应时间对吞吐量的影响不一定总是正面的。降低响应时间有可能会增加资源的使用,比如我们把原本放在硬盘中的数据都放到了内存中,然后就没有足够的内存用来创建新的线程,服务器就无法接收更多的请求,吞吐量也就无法提升。
2.2 增加并发能力
2.2.3 增加资源
这是最直接的方法,就像买更多的炉子和锅,就能同时做更多的菜。
在计算机领域,我们可以购买更多的服务器、更强劲的CPU或GPU、更大的内存、读写能力更强的IO设备、更大的网络带宽,等等。这些可以让程序在单位时间内接收更多的请求、以及更大的并发处理能力,也就增加了系统的吞吐量。当然在具体的增加某种资源之前,我们需要先找到系统的瓶颈,比如内存使用经常达到90%,我们就增加内存空间。
需要注意,增加资源虽然可以提升系统的吞吐量,但是这也会有一个临界点,越过这个临界点之后,获得的收益将会低于为此增加的资源成本,所以我们应该仔细评估收益和成本,再决定增加多少资源。
同时本着节约的精神,我们应该追求使用更少的资源来完成更多的工作,这样也能产生更多的收益。
2.2.2 利用CPU的先进技术
上文我们在【1.2.1 提升CPU性能】中已经提到过CPU的指令并行技术,包括流水线、分支预测、乱序执行、多发射、超标量等,它们可以让CPU同时执行多条指令,提升CPU的指令吞吐量,自然也就提升了程序的处理吞吐量。
这些都是CPU内部的技术优化,只要购买性能优良的CPU,我们就可以拥有这些能力;同时我们在编程时也可以尽量触发指令的并行执行,比如上文【1.1.2 优化代码逻辑】中提到的循环展开、内联函数等,当然我更推荐选择一个更好的编译器来完成这些优化工作,程序员应该多思考下怎么运用技术满足业务需求。
除了CPU微观层面的优化,我们还可以利用下CPU的多核并行能力,在程序中使用多线程、多进程,让程序并行处理,从而提升程序的业务吞吐量。
CPU的这些能力就像是多个厨师协作,同时准备不同的菜品,就能在单位时间内把更多的菜品端上桌。
2.2.1 提高资源利用率
大家可能听说过Go的并发能力特别强,简单手撸一个服务就能轻松应对百万并发,原因就是因为Go搞出了协程。那么协程为什么这么优秀呢?
这是因为程序使用传统的线程模型时,线程消耗的时间和空间成本比较高,时间成本就是CPU的使用时间,空间成本就是内存占用,要提升吞吐量只能增加更多的CPU和内存资源,资源利用率高不起来,具体是怎么回事呢?
首先看我们编写的业务程序,其实大部分工作都是很多IO操作,比如访问数据库、请求网络接口、读写文件等,这些IO操作相比CPU指令操作慢了4、5个数量级。使用线程模型时,发起IO请求后,当前线程使用的CPU要么等着要么切换给其它线程使用,等着CPU就是空转,切换给其它线程时的成本也比较高,总之就是浪费了CPU时间;另外在等待IO返回的这段时间内,线程不会消失,会一直存在,而线程占用的内存比较大(Windows默认1M,Linux默认8M),妥妥的站着什么不拉什么。这就是线程的时间成本和空间成本问题。
解决这个问题的第一步是使用异步编程:IO操作提交后,就把线程释放掉,程序也不用在这里等着,等IO返回结果时,操作系统再分配一个新的线程进行处理。线程少了,CPU等待、切换和内存占用也就少了,计算资源自然就可以支持更多的请求了,吞吐量也就上来了。这就像是厨师在等待一个菜烤制的同时,可以去炒另一道菜。
协程则是在异步的基础上更进一步,把程序执行的最小单位由线程变成了协程,协程分配的内存更小,初始时仅为2KB,不过它可以随着任务执行按需增长,最大可达1GB。同样的8M内存,Linux中只能创建1个线程,而协程最多则可以创建4096个。我们也就能够理解Go的并发能力为什么这么强了。
总结
性能优化是一个复杂且多面的话题,涉及到代码的编写、系统的架构以及硬件的选择与配置。在追求性能的旅途中,我们需要掌握的知识有很多,既有软件方面的,也有硬件方面的,很多东西我也没有展开详细讲,只是给大家提供了一个引子,遇到问题的时候可以顺着它去寻找。
在优化过程中,还需要注意性能的提升并非总是线性的,我们应当找到系统的瓶颈点,有针对性地优化,并在资源成本和性能收益之间做出平衡。优化的最终目的是在有限的资源下,尽可能地提升程序的响应速度和处理能力。
文章转载自:萤火架构
原文链接:https://www.cnblogs.com/bossma/p/17946273
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
程序性能优化全能手册
本文聊一个程序员都会关注的问题:性能。 当大家谈到“性能”时,你首先想到的会是什么? 是每次请求需要多长时间才能返回? 是每秒钟能够处理多少次请求? 还是程序的CPU和内存使用率高不高? 这些问题基本上…...
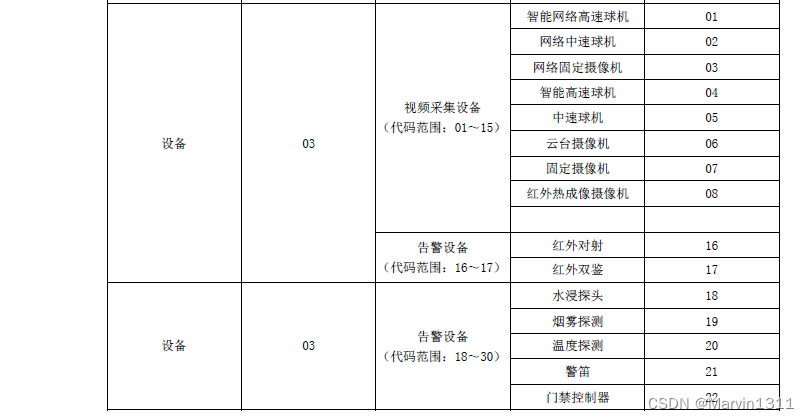
LiveSIPB流媒体国网B接口功能-国网B接口服务安装使用说明
LiveSIPB 国网B接口服务安装使用说明 1、服务说明1.1、安装包说明1.2、国网B接口信令服务1.3、国网B接口流媒体服务1.4、配置信令服务(LiveCMS)1.5、配置流媒体服务(LiveSMS) 2、服务运行2.1、Windows2.2、Linux 3、配置设备接入3.1、海康STATE_GRID接入示例 4、平台使用4.1、管…...

利用小红书笔记详情API:为内容运营提供强大的支持
利用小红书笔记详情API,内容运营者可以获得对小红书平台上的笔记内容的深入洞察,从而为其运营工作提供强大的支持。以下是该API如何支持内容运营的几个关键方面: 获取笔记内容与数据: API允许内容运营者直接获取小红书平台上的笔记…...

地理空间分析1——入门Python地理空间分析
写在开头 地理空间分析是一门涉及地球表面数据处理和解释的科学,通过对地理现象的研究,我们可以更深入地了解地球各个角落的关系。Python作为一种功能强大的编程语言,在地理空间分析领域展现了强大的潜力。本文将带您深入了解入门级别的Pyth…...

哈尔滨爆火的背后有什么值得我们学习的,2024普通人如何创业/2024风口行业
这个冬天,“南方小土豆”带火东北冰雪游。“冰城”黑龙江哈尔滨的文旅市场异常火爆,元旦假期3天,哈尔滨市累计接待游客304.79万人次,实现旅游总收入59.14亿元。旅游总收入达到历史峰值。哈尔滨旅游怎么就爆火了?背后究…...
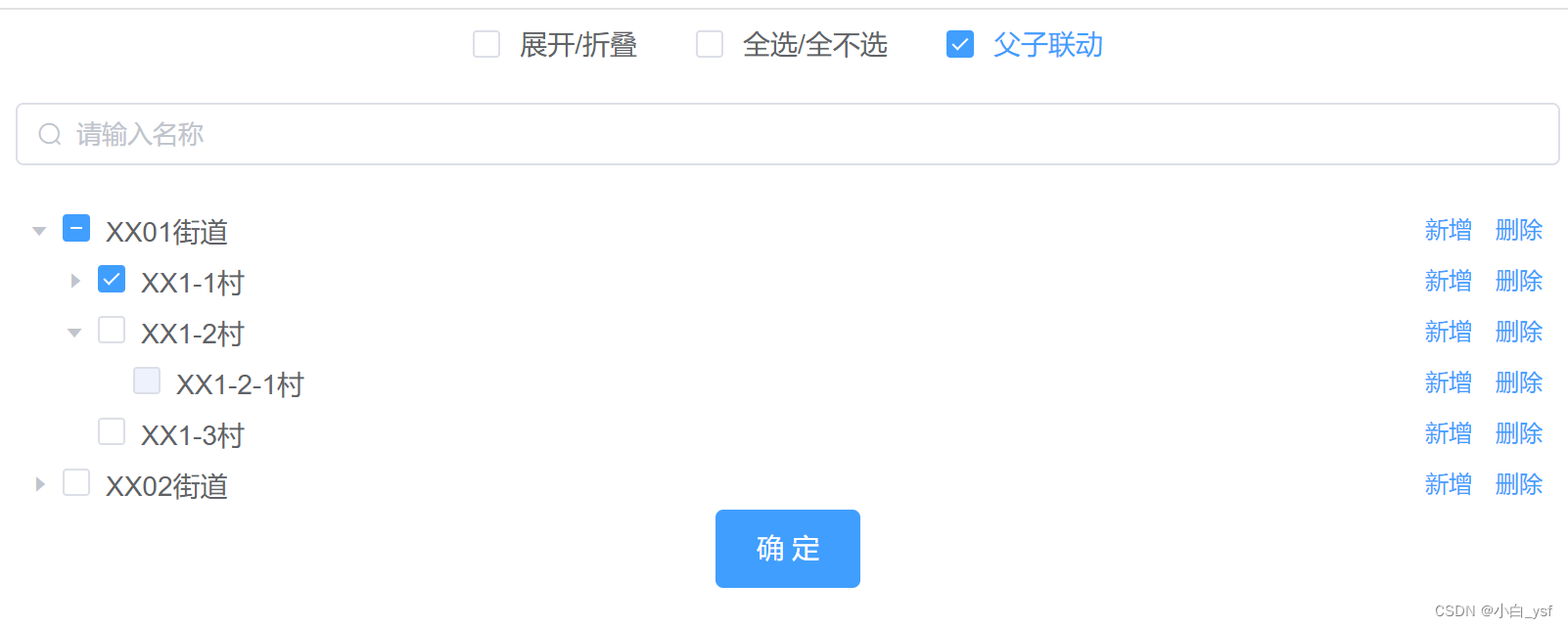
element中Tree 树形控件实现多选、展开折叠、全选全不选、父子联动、默认展开、默认选中、默认禁用、自定义节点内容、可拖拽节点、手风琴模式
目录 1.代码实现2. 效果图3. 使用到的部分属性说明4. 更多属性配置查看element官网 1.代码实现 <template><div class"TreePage"><el-checkboxv-model"menuExpand"change"handleCheckedTreeExpand($event, menu)">展开/折叠&l…...

数据结构OJ实验15-插入排序与交换排序
A. DS内排—直插排序 题目描述 给定一组数据,使用直插排序完成数据的升序排序。 --程序要求-- 若使用C只能include一个头文件iostream;若使用C语言只能include一个头文件stdio 程序中若include多过一个头文件,不看代码,作0分…...

鹿目标检测数据集VOC格式500张
鹿,一种优雅而神秘的哺乳动物,以其优美的外形和独特的生态习性而备受人们的喜爱。 鹿的体型通常中等,四肢细长,身体线条流畅。它们的头部较小,耳朵大而直立,眼睛明亮有神。鹿的毛色因品种而异,…...
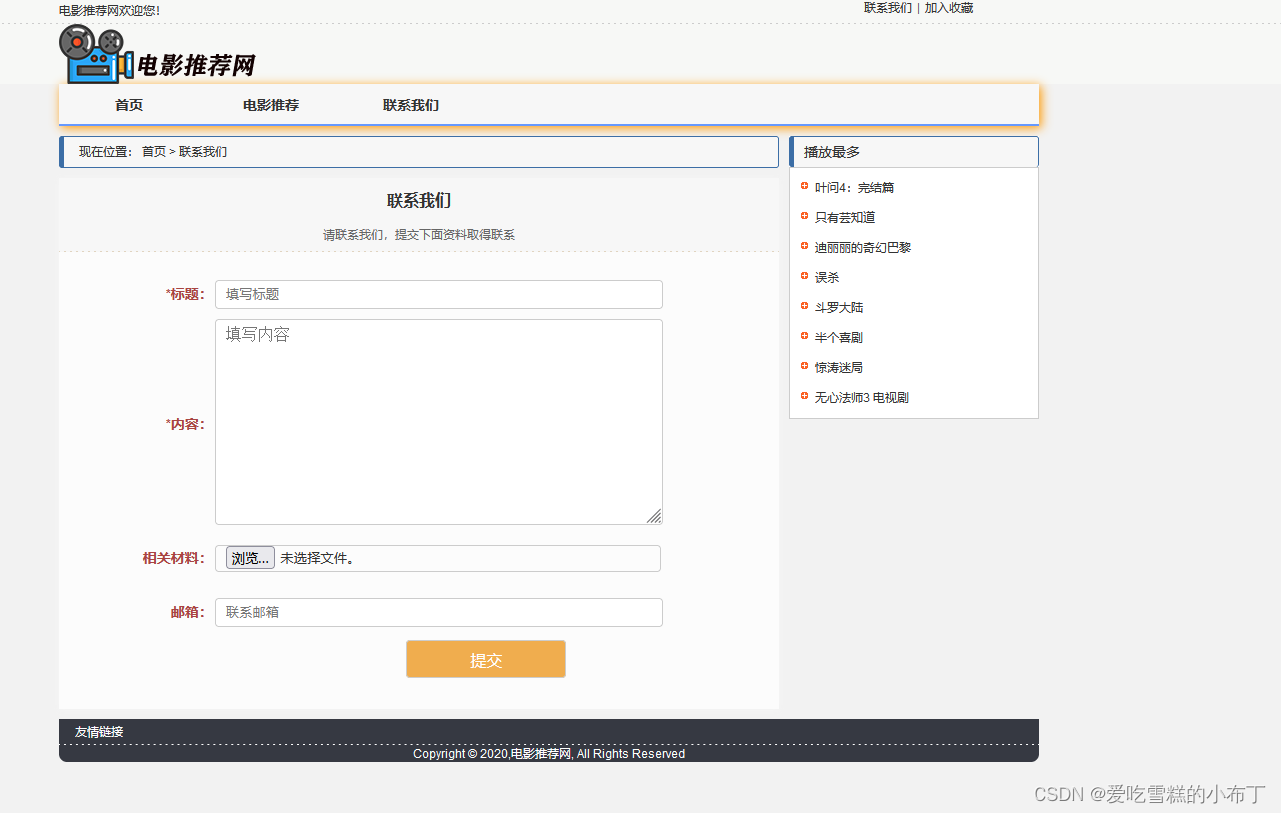
静态网页设计——电影推荐网(HTML+CSS+JavaScript)
前言 声明:该文章只是做技术分享,若侵权请联系我删除。!! 感谢大佬的视频: https://www.bilibili.com/video/BV1NK411x7oK/?vd_source5f425e0074a7f92921f53ab87712357b 使用技术:HTMLCSSJS(…...

ARM CCA机密计算架构软件栈简介
本博客描述了Arm机密计算架构(Arm CCA)的固件和软件组件。 在这篇博客中,您将学到如何: 列出组成Arm CCA软件栈的组件集了解Arm CCA引入新软件组件的原因了解监视器和领域管理监视器(RMM)的角色了解如何创建和管理领域1.1 开始之前 我们假设您熟悉AArch64异常模型、AAr…...

C#编程-使用集合
使用集合 您学习了如何使用数组来有效地存储和操作相似类型额数据。但是,以下限制于数组的使用相关联: 您必须在声明时定义数组的大小。您必须编写代码以对数组执行标准操作,如排序。让我们思考一个示例。假设您想要存储在组织工作的五个雇员的姓名。您可以使用以下语句来声…...

linux 设备模型之设备
在最低层, Linux 系统中的每个设备由一个 struct device 代表: struct device { struct device *parent; struct kobject kobj; char bus_id[BUS_ID_SIZE]; struct bus_type *bus; struct device_driver *driver; void *driver_data; void (*release)(struct device *dev); /* …...

电源滤波可采用 RC、LC、π 型滤波。电源滤波建议优选磁珠,然后才是电感。同时电阻、电感和磁珠必须考虑其电阻产生的压降。
电源滤波是为了减少电源中的噪声和干扰,确保电子设备正常工作。RC、LC、π 型滤波是常用的电源滤波器结构,其选择主要取决于需要滤波的频率范围和所需的滤波效果。 RC滤波器是由电阻和电容组成,适用于高频噪声的滤波。当电流通过电容时,电容会阻止高频噪声信号的通过,起到…...
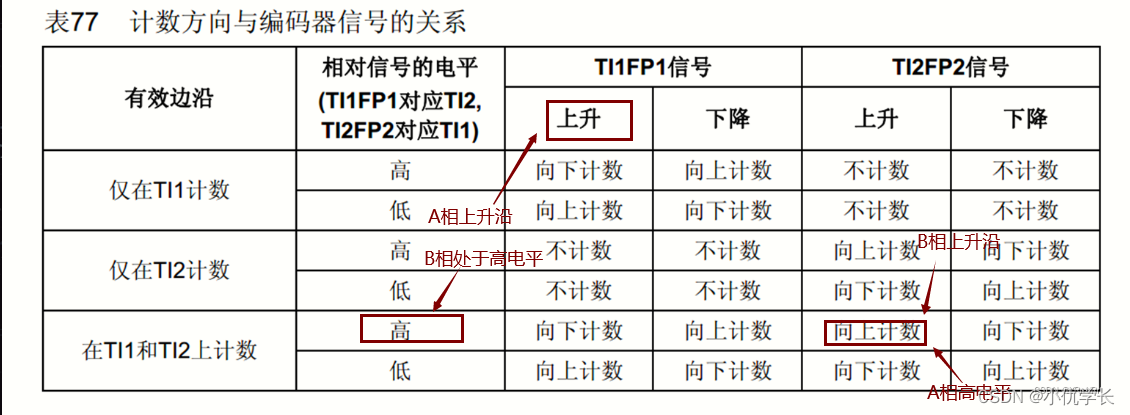
STM32通用定时器-输入捕获-脉冲计数
一、知识点 编码器 两相编码器(正交编码器):两相编码器由 A 相和 B 相组成,相位差为 90 度。当旋转方向为顺时针时,A 相先变化,然后 B 相变化;当旋转方向为逆时针时,B 相先变化…...

Flutter GetX 之 路由管理
路由管理是插件GetX常用功能之一,为什么说之一呢?因为GetX的功能远不止路由管理这么简单。 GetX的重要功能如下: 1、路由管理2、状态管理3、国际化4、主题5、GetUtil工具6、dialog 弹框7、snackbar 其实上面功能介绍的还是不够详细ÿ…...
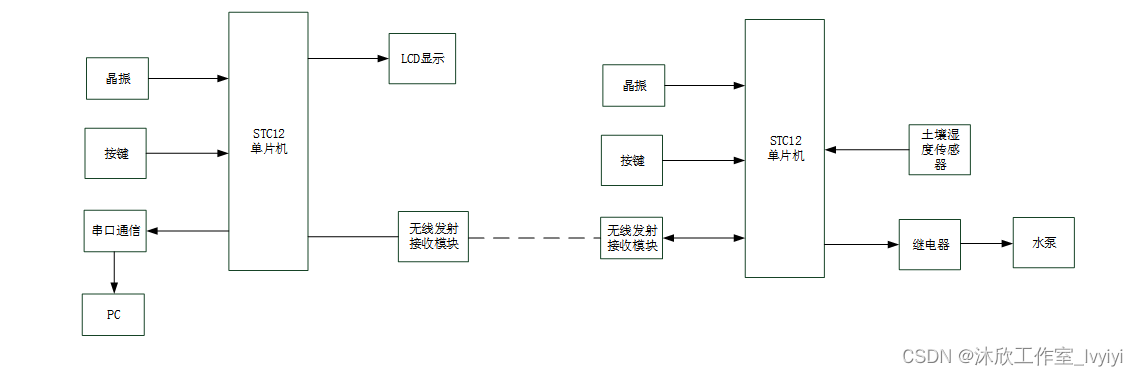
基于单片机的农田灌溉系统(论文+源码)
1.系统设计 本系统主要实现如下目标: 1.可以实时监测土壤湿度; 2.土壤湿度太低时,进行浇水操作; 3.可以按键设置湿度的触发阈值; 4. 可以实现远程操控 5.可以实现手…...
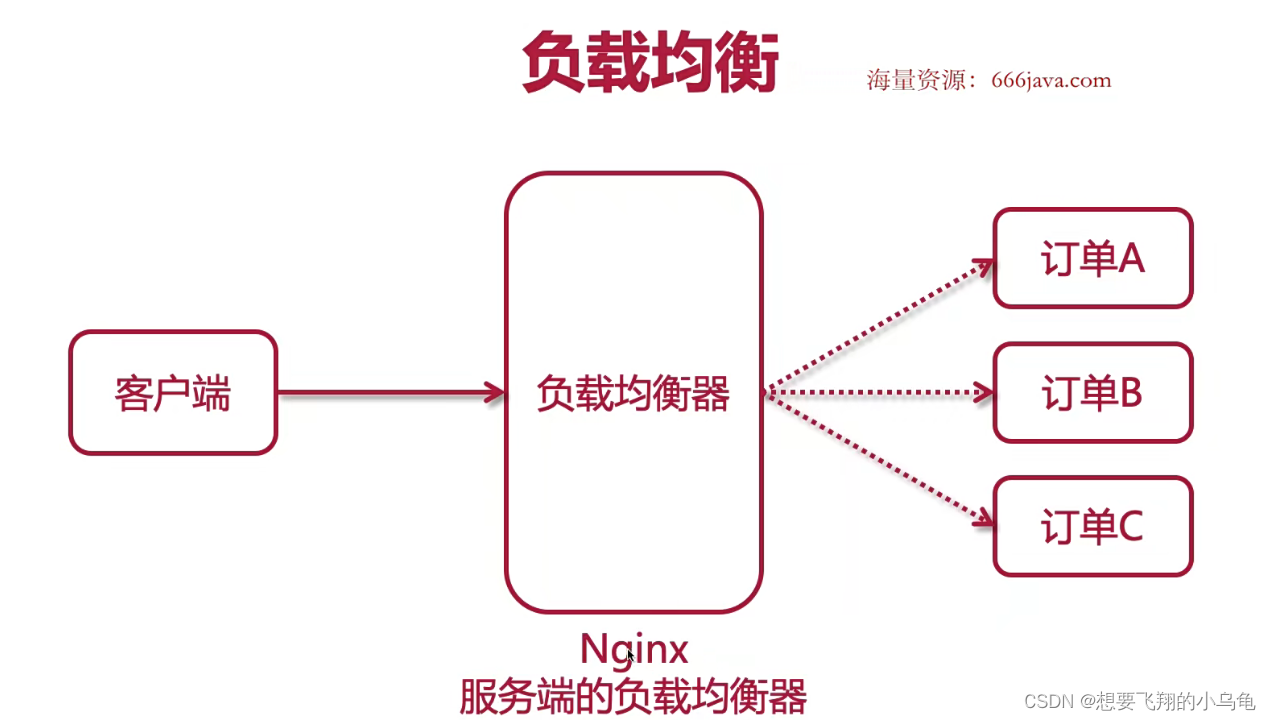
分布式缓存 -- 基础
负载均衡 Ribbon 服务间通信的负载均衡工具,提供完善的超时重试机制 客户端的负载均衡器:在客户端将各个服务的信息拿到,在客户端本地做到请求的均衡分配 Ribbon 提供 LoadBalanced 注解,外搭配RestTemplate来做客户端的负载均衡…...

云计算复习笔记--期末
1、云计算的定义和本质: 云计算是一种按使用量付费的模式。云计算是分布式计算的一种。通过计算机网络(多指因特网)形成的计算能力极强的系统,可存储、集合相关资源并可按需配置,向用户提供个性化服务。 2、云计算服…...

【WPF.NET开发】WPF中的焦点
本文内容 键盘焦点逻辑焦点键盘导航以编程方式导航焦点焦点事件 在 WPF 中,有两个与焦点有关的主要概念:键盘焦点和逻辑焦点。 键盘焦点指接收键盘输入的元素,而逻辑焦点指焦点范围中具有焦点的元素。 本概述详细介绍了这些概念。 对于创建…...
【计算机设计大赛作品】豆瓣电影数据挖掘可视化—信息可视化赛道获奖项目深入剖析【可视化项目案例-22】
文章目录 一.【计算机设计大赛作品】豆瓣电影数据挖掘可视化—信息可视化赛道获奖项目深入剖析【可视化项目案例-22】1.1 项目主题:豆瓣电影二.代码剖析2.1 项目效果展示2.2 服务端代码剖析2.3 数据分析2.4 数据评分三.寄语四.本案例完整源码下载一.【计算机设计大赛作品】豆瓣…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...