分类模型评估方法
1.数据集划分¶
1.1 为什么要划分数据集?¶
思考:我们有以下场景:
-
将所有的数据都作为训练数据,训练出一个模型直接上线预测
-
每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别
存在问题:
-
上线之前,如何评估模型的好坏?
-
模型使用所有数据训练,使用哪些数据来进行模型评估?
结论:不能将所有数据集全部用于训练
为了能够评估模型的泛化能力,可以通过实验测试对学习器的泛化能力进行评估,进而做出选择。因此需要使用一个 "测试集" 来测试学习器对新样本的判别能力,以测试集上的 "测试误差" 作为泛化误差的近似。
一般测试集满足:
- 能代表整个数据集
- 测试集与训练集互斥
- 测试集与训练集建议比例: 2比8、3比7 等
1.2 数据集划分的方法¶
留出法:将数据集划分成两个互斥的集合:训练集,测试集
- 训练集用于模型训练
- 测试集用于模型验证
- 也称之为简单交叉验证
交叉验证:将数据集划分为训练集,验证集,测试集
- 训练集用于模型训练
- 验证集用于参数调整
- 测试集用于模型验证
留一法:每次从训练数据中抽取一条数据作为测试集
自助法:以自助采样(可重复采样、有放回采样)为基础
- 在数据集D中随机抽取m个样本作为训练集
- 没被随机抽取到的D-m条数据作为测试集
1.3 留出法(简单交叉验证)
留出法 (hold-out) 将数据集 D 划分为两个互斥的集合,其中一个集合作为训练集 S,另一个作为测试集 T。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import ShuffleSplit
from collections import Counter
from sklearn.datasets import load_irisdef test01():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))# 2. 留出法(随机分割)x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)print('随机类别分割:', Counter(y_train), Counter(y_test))# 3. 留出法(分层分割)x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)print('分层类别分割:', Counter(y_train), Counter(y_test))def test02():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 多次划分(随机分割)spliter = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('随机多次分割:', Counter(y[test]))print('*' * 40)# 3. 多次划分(分层分割)spliter = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('分层多次分割:', Counter(y[test]))if __name__ == '__main__':test01()test02()1.4 交叉验证法
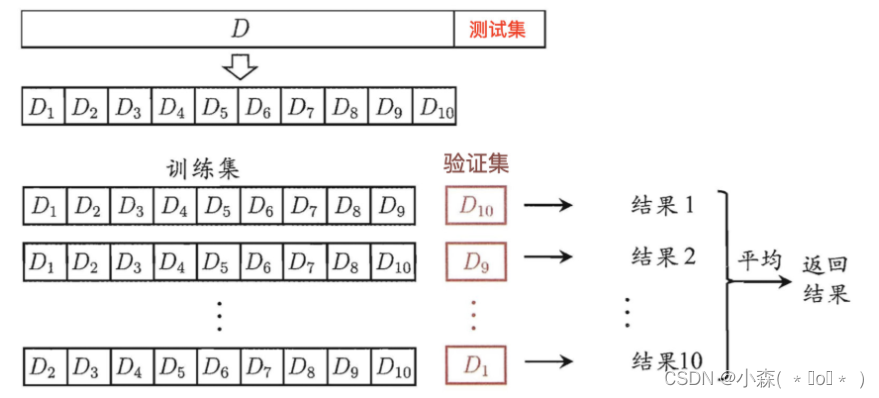
K-Fold交叉验证,将数据随机且均匀地分成k分,如上图所示(k为10),假设每份数据的标号为0-9
- 第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率
- 第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率
- 以此类推,每次使用9份数据作为训练,而使用剩下的一份数据进行测试
- 共进行10次训练,最后模型的准确率为10次准确率的平均值
- 这样可以避免了数据划分而造成的评估不准确的问题。
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from collections import Counter
from sklearn.datasets import load_irisdef test():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 随机交叉验证spliter = KFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('随机交叉验证:', Counter(y[test]))print('*' * 40)# 3. 分层交叉验证spliter = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('分层交叉验证:', Counter(y[test]))if __name__ == '__main__':test()1.5 留一法
留一法( Leave-One-Out,简称LOO),即每次抽取一个样本做为测试集。
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import LeavePOut
from sklearn.datasets import load_iris
from collections import Counterdef test01():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 留一法spliter = LeaveOneOut()for train, test in spliter.split(x, y):print('训练集:', len(train), '测试集:', len(test), test)print('*' * 40)# 3. 留P法spliter = LeavePOut(p=3)for train, test in spliter.split(x, y):print('训练集:', len(train), '测试集:', len(test), test)if __name__ == '__main__':test01()1.6 自助法
每次随机从D中抽出一个样本,将其拷贝放入D,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被抽到; 这个过程重复执行m次后,我们就得到了包含m个样本的数据集D′,这就是自助采样的结果。
import pandas as pdif __name__ == '__main__':# 1. 构造数据集data = [[90, 2, 10, 40],[60, 4, 15, 45],[75, 3, 13, 46],[78, 2, 64, 22]]data = pd.DataFrame(data)print('数据集:\n',data)print('*' * 30)# 2. 产生训练集train = data.sample(frac=1, replace=True)print('训练集:\n', train)print('*' * 30)# 3. 产生测试集test = data.loc[data.index.difference(train.index)]print('测试集:\n', test)2.分类算法的评估标准¶
2.1 分类算法的评估¶
如何评估分类算法?
-
利用训练好的模型使用测试集的特征值进行预测
-
将预测结果和测试集的目标值比较,计算预测正确的百分比
-
这个百分比就是准确率 accuracy, 准确率越高说明模型效果越好
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载鸢尾花数据
X,y = datasets.load_iris(return_X_y = True)
#训练集 测试集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
# 创建KNN分类器对象 近邻数为6
knn_clf = KNeighborsClassifier(n_neighbors=6)
#训练集训练模型
knn_clf.fit(X_train,y_train)
#使用训练好的模型进行预测
y_predict = knn_clf.predict(X_test)计算准确率:
sum(y_predict==y_test)/y_test.shape[0]
2.2 SKlearn中模型评估API介绍
sklearn封装了计算准确率的相关API:
- sklearn.metrics包中的accuracy_score方法: 传入预测结果和测试集的标签, 返回预测准去率
- 分类模型对象的 score 方法:传入测试集特征值,测试集目标值
#计算准确率
from sklearn.metrics import accuracy_score
#方式1:
accuracy_score(y_test,y_predict)
#方式2:
knn_classifier.score(X_test,y_test)3. 小结¶
- 留出法每次从数据集中选择一部分作为测试集、一部分作为训练集
- 交叉验证法将数据集等份为 N 份,其中一部分做验证集,其他做训练集
- 留一法每次选择一个样本做验证集,其他数据集做训练集
- 自助法通过有放回的抽样产生训练集、验证集
- 通过accuracy_score方法 或者分类模型对象的score方法可以计算分类模型的预测准确率用于模型评估
相关文章:
分类模型评估方法
1.数据集划分 1.1 为什么要划分数据集? 思考:我们有以下场景: 将所有的数据都作为训练数据,训练出一个模型直接上线预测 每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别 存在问题&…...

RabbitMQ高级
文章目录 一.消息可靠性1.生产者消息确认 MQ的一些常见问题 1.消息可靠性问题:如何确保发送的消息至少被消费一次 2.延迟消息问题:如何实现消息的延迟投递 3.高可用问题:如何避免单点的MQ故障而导致的不可用问题 4.消息堆积问题:如何解决数百万消息堆积,无法及时…...
SonarQube 漏洞扫描
SonarQube 漏洞扫描 一、部署服务 1.1 docker方式部署 #安装docker curl -L download.beyourself.org.cn/shell-project/os/get-docker-latest.sh | sh yum install -y docker-compose #进去输入:set paste可以保证不穿行 [rootlocalhost sonar]# vim docker-compose.yml v…...

Web前端篇——ElementUI的Backtop 不显示问题
在使用ElementUI的Backtop回到顶部组件时,单独复制这一行代码 <el-backtop :right"100" :bottom"100" /> 发现页面在向下滚动时,并未出现Backtop组件。 可从以下3个方向进行分析: 指定target属性,且…...

MySQL 管理工具
1、MySQL 管理 系统数据库 a. mysql 命令 语法:mysql [options] [database] -u,--username 指定用户名-p,--password[name] 指定密码-h, --hostname 指定服务器IP或域名-P, --portport 指定连接端-e,--executename 执行SQL语句并退出 mysql -h192.168.200.202 -…...

LeetCode 33 搜索旋转排序数组
题目描述 搜索旋转排序数组 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., num…...
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测 目录 分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 基于SVM-RFE-LSTM的特征…...
JetBrains Rider使用总结
简介: JetBrains Rider 诞生于2016年,一款适配于游戏开发人员,是JetBrains旗下一款非常年轻的跨平台 .NET IDE。目前支持包括.NET 桌面应用、服务和库、Unity 和 Unreal Engine 游戏、Xamarin 、ASP.NET 和 ASP.NET Core web 等多种应用程序…...
C# Emgu.CV4.8.0读取rtsp流录制mp4可分段保存
【官方框架地址】 https://github.com/emgucv/emgucv 【算法介绍】 EMGU CV(Emgu Computer Vision)是一个开源的、基于.NET框架的计算机视觉库,它提供了对OpenCV(开源计算机视觉库)的封装。EMGU CV使得在.NET应用程序…...
java碳排放数据信息管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 java Web碳排放数据信息管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环 境为TOMCAT7.0,Myeclipse8.5开发,数据库为…...
K8S陈述式资源管理(1)
命令行: kubectl命令行工具 优点: 90%以上的场景都可以满足对资源的增,删,查比较方便,对改不是很友好 缺点:命令比较冗长,复杂,难记声明式 声明式:K8S当中的yaml文件来实现资源管理 GUI:图形…...
STL map容器与pair类模板(解决扫雷问题)
CSTL之Map容器 - 数据结构教程 - C语言网 (dotcpp.com)https://www.dotcpp.com/course/118CSTL之Pair类模板 - 数据结构教程 - C语言网 (dotcpp.com)https://www.dotcpp.com/course/119 刷到一个扫雷的题目,之前没有玩怎么过扫雷,于是我就去玩了玩…...

【React系列】Portals、Fragment
本文来自#React系列教程:https://mp.weixin.qq.com/mp/appmsgalbum?__bizMzg5MDAzNzkwNA&actiongetalbum&album_id1566025152667107329) Portals 某些情况下,我们希望渲染的内容独立于父组件,甚至是独立于当前挂载到的DOM元素中&am…...

ByteTrack算法流程的简单示例
ByteTrack ByteTrack算法是将t帧检测出来的检测框集合 D t {\mathcal{D}_{t}} Dt 和t-1帧预测轨迹集合 T ~ t − 1 {\tilde{T}_{t-1}} T~t−1 进行匹配关联得到t帧的轨迹集合 T t {T_{t}} Tt。 首先使用检测器检测t帧的图像得到检测框集合 D t {\mathcal{D}_{t}} …...
免费的GPT4来了,你还不知道吗?
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
win10报错“zlib.dll文件丢失,软件无法启动”,修复方法,亲测有效
zlib.dll文件是一个由Zlib创建的动态链接库文件,它是用于Windows操作系统的数据压缩和解压缩的软件。Zlib是一个广泛使用的软件库,广泛应用在许多不同类型的软件中,包括游戏、浏览器和操作系统。 zlib.dll的主要作用是提供数据压缩和解压缩的…...

MFC中如何使用CListCtrl可以编辑,并添加鼠标右键及双击事件。
要在MFC中使用CListCtrl来实现编辑功能,可以按照以下步骤进行操作: 在对话框资源中添加CListCtrl控件,并设置合适的属性。在对话框类的头文件中添加成员变量来管理CListCtrl控件,例如: CListCtrl m_listCtrl; 3. 在O…...

[每周一更]-(第81期):PS抠图流程(扭扭曲曲的身份证修正)
应朋友之急,整理下思路,分享一下~~ 分两步走:先用磁性套索工具圈出要处理的图;然后使用透视剪裁工具,将扭曲的图片拉平即可;(macbook pro) 做事有规则,才能更高效;用什么工具,先列举…...
Kafka安全认证机制详解之SASL_PLAIN
一、概述 官方文档: https://kafka.apache.org/documentation/#security 在官方文档中,kafka有五种加密认证方式,分别如下: SSL:用于测试环境SASL/GSSAPI (Kerberos) :使用kerberos认证,密码是…...

2023南京理工大学通信工程818信号系统及数电考试大纲
注:(Δ)表示重点内容。具体内容详见博睿泽信息通信考研论坛 参考书目: [1] 钱玲,谷亚林,王海青. 信号与系统(第五版). 北京:电子工业出版社 [2] 郑君里,应…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

WebRTC调研
WebRTC是什么,为什么,如何使用 WebRTC有什么优势 WebRTC Architecture Amazon KVS WebRTC 其它厂商WebRTC 海康门禁WebRTC 海康门禁其他界面整理 威视通WebRTC 局域网 Google浏览器 Microsoft Edge 公网 RTSP RTMP NVR ONVIF SIP SRT WebRTC协…...
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...