linux stop_machine 停机机制应用及一次触发 soft lockup 分析
文章目录
- stop_mchine 引起的 soft lockup
- 触发 soft lockup 原因分析(一):
- 触发 soft lockup 原因分析(二)
- 触发 soft lockup 原因分析(三)
stop_mchine 引起的 soft lockup
某次在服务器上某节点发现系统有大量 soft lockup 打印,如下:
May 8 11:46:12 node-2 kernel: watchdog: BUG: soft lockup - CPU#116 stuck for 22s! [migration/116:733]
May 8 12:45:00 node-2 kernel: watchdog: BUG: soft lockup - CPU#104 stuck for 23s! [migration/104:659]
May 8 12:45:34 node-2 kernel: watchdog: BUG: soft lockup - CPU#21 stuck for 23s! [migration/21:139]
May 8 12:46:04 node-2 kernel: watchdog: BUG: soft lockup - CPU#121 stuck for 22s! [migration/121:764]
May 9 20:29:59 node-2 kernel: watchdog: BUG: soft lockup - CPU#91 stuck for 22s! [migration/91:574]
May 9 20:32:42 node-2 kernel: watchdog: BUG: soft lockup - CPU#7 stuck for 22s! [migration/7:53]
May 9 20:41:42 node-2 kernel: watchdog: BUG: soft lockup - CPU#17 stuck for 22s! [migration/17:115]
May 9 20:58:52 node-2 kernel: watchdog: BUG: soft lockup - CPU#102 stuck for 22s! [migration/102:647]
May 9 21:05:36 node-2 kernel: watchdog: BUG: soft lockup - CPU#119 stuck for 22s! [migration/119:751]
May 10 05:33:26 node-2 kernel: watchdog: BUG: soft lockup - CPU#29 stuck for 22s! [migration/29:188]
May 10 08:01:04 node-2 kernel: watchdog: BUG: soft lockup - CPU#111 stuck for 22s! [migration/111:702]
May 10 08:35:00 node-2 kernel: watchdog: BUG: soft lockup - CPU#95 stuck for 22s! [migration/95:604]
May 10 09:29:02 node-2 kernel: watchdog: BUG: soft lockup - CPU#1 stuck for 22s! [migration/1:17]
May 10 09:29:31 node-2 kernel: watchdog: BUG: soft lockup - CPU#49 stuck for 23s! [migration/49:317]
May 10 17:49:42 node-2 kernel: watchdog: BUG: soft lockup - CPU#17 stuck for 22s! [migration/17:115]
May 11 12:25:24 node-2 kernel: watchdog: BUG: soft lockup - CPU#107 stuck for 22s! [migration/107:678]
May 11 15:29:46 node-2 kernel: watchdog: BUG: soft lockup - CPU#30 stuck for 22s! [migration/30:194]
May 11 15:36:38 node-2 kernel: watchdog: BUG: soft lockup - CPU#35 stuck for 23s! [migration/35:225]
May 11 15:37:16 node-2 kernel: watchdog: BUG: soft lockup - CPU#104 stuck for 23s! [migration/104:659]
May 11 15:48:31 node-2 kernel: watchdog: BUG: soft lockup - CPU#59 stuck for 22s! [migration/59:378]
May 11 16:14:52 node-2 kernel: watchdog: BUG: soft lockup - CPU#115 stuck for 22s! [migration/115:727]
May 11 16:21:34 node-2 kernel: watchdog: BUG: soft lockup - CPU#39 stuck for 23s! [migration/39:249]
May 11 16:32:50 node-2 kernel: watchdog: BUG: soft lockup - CPU#45 stuck for 22s! [migration/45:286]
May 11 21:04:48 node-2 kernel: watchdog: BUG: soft lockup - CPU#107 stuck for 22s! [migration/107:678]
May 11 21:07:44 node-2 kernel: watchdog: BUG: soft lockup - CPU#122 stuck for 22s! [migration/122:770]
May 11 21:09:39 node-2 kernel: watchdog: BUG: soft lockup - CPU#90 stuck for 23s! [migration/90:568]
May 11 21:10:14 node-2 kernel: watchdog: BUG: soft lockup - CPU#17 stuck for 23s! [migration/17:115]
May 11 22:58:19 node-2 kernel: watchdog: BUG: soft lockup - CPU#68 stuck for 22s! [migration/68:433]
May 11 23:19:25 node-2 kernel: watchdog: BUG: soft lockup - CPU#0 stuck for 22s! [migration/0:12]
May 12 00:11:06 node-2 kernel: watchdog: BUG: soft lockup - CPU#35 stuck for 23s! [migration/35:225]
May 12 05:11:23 node-2 kernel: watchdog: BUG: soft lockup - CPU#47 stuck for 23s! [migration/47:304]
May 12 05:33:06 node-2 kernel: watchdog: BUG: soft lockup - CPU#26 stuck for 22s! [migration/26:170]
May 12 05:52:54 node-2 kernel: watchdog: BUG: soft lockup - CPU#24 stuck for 23s! [migration/24:157]
May 12 05:59:03 node-2 kernel: watchdog: BUG: soft lockup - CPU#75 stuck for 23s! [migration/75:476]
May 12 06:10:44 node-2 kernel: watchdog: BUG: soft lockup - CPU#113 stuck for 22s! [migration/113:715]
May 12 08:00:43 node-2 kernel: watchdog: BUG: soft lockup - CPU#51 stuck for 23s! [migration/51:329]
May 12 09:46:55 node-2 kernel: watchdog: BUG: soft lockup - CPU#59 stuck for 22s! [migration/59:378]
May 12 10:21:18 node-2 kernel: watchdog: BUG: soft lockup - CPU#34 stuck for 22s! [migration/34:219]
对应着 oom-killer 有大量如下输出:
May 7 04:41:13 node-2 kernel: Memory cgroup out of memory: Killed process 3258 (mysqld) total-vm:61977792kB, anon-rss:3997440kB, file-rss:0kB, shmem-rss:131136kB
May 7 04:45:06 node-2 kernel: Memory cgroup out of memory: Killed process 35094 (prometheus) total-vm:15836160kB, anon-rss:2320448kB, file-rss:23040kB, shmem-rss:0kB
May 7 05:20:06 node-2 kernel: Memory cgroup out of memory: Killed process 45860 (prometheus-conf) total-vm:724352kB, anon-rss:15040kB, file-rss:7744kB, shmem-rss:0kB
May 7 06:41:20 node-2 kernel: Memory cgroup out of memory: Killed process 50009 (prometheus-conf) total-vm:724096kB, anon-rss:26880kB, file-rss:7808kB, shmem-rss:0kB
May 7 06:59:29 node-2 kernel: Memory cgroup out of memory: Killed process 58459 (prometheus-conf) total-vm:723328kB, anon-rss:28864kB, file-rss:7744kB, shmem-rss:0kB
May 7 07:14:47 node-2 kernel: Memory cgroup out of memory: Killed process 55827 (prometheus-conf) total-vm:723328kB, anon-rss:35968kB, file-rss:7808kB, shmem-rss:0kB
May 7 07:33:02 node-2 kernel: Memory cgroup out of memory: Killed process 45155 (prometheus-conf) total-vm:723584kB, anon-rss:28736kB, file-rss:7744kB, shmem-rss:0kB
May 7 08:12:11 node-2 kernel: Memory cgroup out of memory: Killed process 40729 (prometheus-conf) total-vm:723840kB, anon-rss:34624kB, file-rss:7744kB, shmem-rss:0kB
May 7 09:48:26 node-2 kernel: Memory cgroup out of memory: Killed process 41554 (prometheus-conf) total-vm:723840kB, anon-rss:26432kB, file-rss:7680kB, shmem-rss:0kB
May 7 10:57:37 node-2 kernel: Memory cgroup out of memory: Killed process 32500 (prometheus-conf) total-vm:724352kB, anon-rss:44928kB, file-rss:7680kB, shmem-rss:0kB
May 8 11:46:13 node-2 kernel: Memory cgroup out of memory: Killed process 59194 (prometheus) total-vm:19494912kB, anon-rss:3146752kB, file-rss:0kB, shmem-rss:0kB
May 8 12:45:09 node-2 kernel: Memory cgroup out of memory: Killed process 14508 (prometheus) total-vm:20020800kB, anon-rss:3667776kB, file-rss:0kB, shmem-rss:0kB
May 8 12:45:42 node-2 kernel: Memory cgroup out of memory: Killed process 23826 (mysqld) total-vm:58905216kB, anon-rss:2307712kB, file-rss:0kB, shmem-rss:29504kB
May 8 12:46:15 node-2 kernel: Memory cgroup out of memory: Killed process 63570 (emla-controller) total-vm:3799424kB, anon-rss:2582912kB, file-rss:29376kB, shmem-rss:0kB
May 8 15:26:06 node-2 kernel: Memory cgroup out of memory: Killed process 11100 (prometheus-conf) total-vm:723584kB, anon-rss:39360kB, file-rss:7744kB, shmem-rss:0kB
May 8 15:34:40 node-2 kernel: Memory cgroup out of memory: Killed process 11952 (prometheus-conf) total-vm:723328kB, anon-rss:17024kB, file-rss:7808kB, shmem-rss:0kB
May 8 15:53:31 node-2 kernel: Memory cgroup out of memory: Killed process 48826 (prometheus-conf) total-vm:723584kB, anon-rss:32896kB, file-rss:7744kB, shmem-rss:0kB
May 8 16:19:09 node-2 kernel: Memory cgroup out of memory: Killed process 23747 (prometheus-conf) total-vm:723072kB, anon-rss:35264kB, file-rss:7744kB, shmem-rss:0kB
May 8 16:49:20 node-2 kernel: Memory cgroup out of memory: Killed process 40395 (prometheus-conf) total-vm:724096kB, anon-rss:26176kB, file-rss:7680kB, shmem-rss:0kB
May 8 18:07:35 node-2 kernel: Memory cgroup out of memory: Killed process 53804 (prometheus-conf) total-vm:723328kB, anon-rss:25344kB, file-rss:7744kB, shmem-rss:0kB
May 8 18:55:51 node-2 kernel: Memory cgroup out of memory: Killed process 38744 (prometheus-conf) total-vm:723840kB, anon-rss:36672kB, file-rss:7680kB, shmem-rss:0kB
May 8 19:17:05 node-2 kernel: Memory cgroup out of memory: Killed process 61735 (prometheus-conf) total-vm:724096kB, anon-rss:27840kB, file-rss:7808kB, shmem-rss:0kB
May 8 23:47:17 node-2 kernel: Memory cgroup out of memory: Killed process 24967 (prometheus-conf) total-vm:724352kB, anon-rss:32896kB, file-rss:7680kB, shmem-rss:0kB
May 9 00:14:37 node-2 kernel: Memory cgroup out of memory: Killed process 48592 (prometheus-conf) total-vm:724352kB, anon-rss:2496kB, file-rss:7808kB, shmem-rss:0kB
May 9 00:32:49 node-2 kernel: Memory cgroup out of memory: Killed process 10190 (prometheus-conf) total-vm:723584kB, anon-rss:24768kB, file-rss:7744kB, shmem-rss:0kB
May 9 00:53:59 node-2 kernel: Memory cgroup out of memory: Killed process 23075 (prometheus-conf) total-vm:724352kB, anon-rss:18176kB, file-rss:7808kB, shmem-rss:0kB
May 9 02:24:12 node-2 kernel: Memory cgroup out of memory: Killed process 26315 (prometheus-conf) total-vm:723584kB, anon-rss:30016kB, file-rss:7808kB, shmem-rss:0kB
May 9 02:57:25 node-2 kernel: Memory cgroup out of memory: Killed process 18119 (prometheus-conf) total-vm:724608kB, anon-rss:25280kB, file-rss:7808kB, shmem-rss:0kB
May 9 03:36:36 node-2 kernel: Memory cgroup out of memory: Killed process 8851 (prometheus-conf) total-vm:724608kB, anon-rss:23232kB, file-rss:7680kB, shmem-rss:0kB
May 9 03:54:45 node-2 kernel: Memory cgroup out of memory: Killed process 22739 (prometheus-conf) total-vm:722816kB, anon-rss:34496kB, file-rss:7808kB, shmem-rss:0kB
May 9 04:40:00 node-2 kernel: Memory cgroup out of memory: Killed process 14681 (prometheus-conf) total-vm:723840kB, anon-rss:35008kB, file-rss:7808kB, shmem-rss:0kB
May 9 06:07:11 node-2 kernel: Memory cgroup out of memory: Killed process 49906 (prometheus-conf) total-vm:724096kB, anon-rss:30528kB, file-rss:7808kB, shmem-rss:0kB
May 9 06:19:24 node-2 kernel: Memory cgroup out of memory: Killed process 43948 (prometheus-conf) total-vm:723328kB, anon-rss:38208kB, file-rss:7808kB, shmem-rss:0kB
May 9 07:22:47 node-2 kernel: Memory cgroup out of memory: Killed process 20244 (prometheus-conf) total-vm:723840kB, anon-rss:0kB, file-rss:7808kB, shmem-rss:0kB
May 9 07:32:05 node-2 kernel: Memory cgroup out of memory: Killed process 43764 (prometheus-conf) total-vm:723584kB, anon-rss:29632kB, file-rss:7744kB, shmem-rss:0kB
May 9 07:38:29 node-2 kernel: Memory cgroup out of memory: Killed process 13495 (prometheus-conf) total-vm:724352kB, anon-rss:29696kB, file-rss:7808kB, shmem-rss:0kB
May 9 08:27:07 node-2 kernel: Memory cgroup out of memory: Killed process 54669 (prometheus-conf) total-vm:723328kB, anon-rss:36928kB, file-rss:7808kB, shmem-rss:0kB
May 9 09:36:24 node-2 kernel: Memory cgroup out of memory: Killed process 18866 (prometheus-conf) total-vm:723840kB, anon-rss:24768kB, file-rss:7744kB, shmem-rss:0kB
May 9 10:12:31 node-2 kernel: Memory cgroup out of memory: Killed process 50598 (prometheus-conf) total-vm:724352kB, anon-rss:30400kB, file-rss:7680kB, shmem-rss:0kB
May 9 10:30:43 node-2 kernel: Memory cgroup out of memory: Killed process 44986 (prometheus-conf) total-vm:723328kB, anon-rss:35136kB, file-rss:7680kB, shmem-rss:0kB
May 9 11:22:03 node-2 kernel: Memory cgroup out of memory: Killed process 36549 (prometheus-conf) total-vm:723840kB, anon-rss:19264kB, file-rss:7744kB, shmem-rss:0kB
May 9 11:37:14 node-2 kernel: Memory cgroup out of memory: Killed process 14044 (prometheus-conf) total-vm:724096kB, anon-rss:34560kB, file-rss:7744kB, shmem-rss:0kB
May 9 15:22:29 node-2 kernel: Memory cgroup out of memory: Killed process 13164 (prometheus-conf) total-vm:723584kB, anon-rss:25792kB, file-rss:7808kB, shmem-rss:0kB
May 9 15:31:38 node-2 kernel: Memory cgroup out of memory: Killed process 20864 (prometheus-conf) total-vm:723072kB, anon-rss:23040kB, file-rss:7296kB, shmem-rss:0kB
May 9 17:08:00 node-2 kernel: Memory cgroup out of memory: Killed process 62871 (prometheus-conf) total-vm:724608kB, anon-rss:19200kB, file-rss:7808kB, shmem-rss:0kB
May 9 17:14:10 node-2 kernel: Memory cgroup out of memory: Killed process 59009 (prometheus-conf) total-vm:723840kB, anon-rss:43456kB, file-rss:7488kB, shmem-rss:0kB
May 9 18:43:49 node-2 kernel: Memory cgroup out of memory: Killed process 31849 (prometheus-conf) total-vm:724096kB, anon-rss:32064kB, file-rss:7744kB, shmem-rss:0kB
May 9 19:33:19 node-2 kernel: Memory cgroup out of memory: Killed process 54047 (prometheus-conf) total-vm:724096kB, anon-rss:32704kB, file-rss:7744kB, shmem-rss:0kB
May 9 20:30:09 node-2 kernel: Memory cgroup out of memory: Killed process 15953 (prometheus) total-vm:20143872kB, anon-rss:2332672kB, file-rss:0kB, shmem-rss:0kB
May 9 20:32:47 node-2 kernel: Memory cgroup out of memory: Killed process 63818 (emla-controller) total-vm:2364480kB, anon-rss:1497152kB, file-rss:29440kB, shmem-rss:0kB
May 9 20:41:47 node-2 kernel: Memory cgroup out of memory: Killed process 35683 (prometheus) total-vm:19514304kB, anon-rss:1760704kB, file-rss:0kB, shmem-rss:0kB
May 9 20:58:58 node-2 kernel: Memory cgroup out of memory: Killed process 39435 (prometheus) total-vm:19952640kB, anon-rss:2420416kB, file-rss:0kB, shmem-rss:0kB
May 9 21:02:38 node-2 kernel: Memory cgroup out of memory: Killed process 62596 (prometheus) total-vm:19996864kB, anon-rss:1951488kB, file-rss:24768kB, shmem-rss:0kB
May 9 21:05:14 node-2 kernel: Memory cgroup out of memory: Killed process 13355 (emla-apiserver) total-vm:2835456kB, anon-rss:1962816kB, file-rss:0kB, shmem-rss:0kB
May 9 21:05:48 node-2 kernel: Memory cgroup out of memory: Killed process 32524 (prometheus) total-vm:19192960kB, anon-rss:1502528kB, file-rss:9600kB, shmem-rss:0kB
May 10 05:26:56 node-2 kernel: Memory cgroup out of memory: Killed process 57505 (prometheus) total-vm:22541888kB, anon-rss:2512448kB, file-rss:0kB, shmem-rss:0kB
May 10 05:33:31 node-2 kernel: Memory cgroup out of memory: Killed process 56986 (mysqld) total-vm:40075712kB, anon-rss:2155520kB, file-rss:0kB, shmem-rss:101440kB
May 10 05:42:32 node-2 kernel: Memory cgroup out of memory: Killed process 7987 (prometheus-conf) total-vm:723584kB, anon-rss:26880kB, file-rss:7616kB, shmem-rss:0kB
May 10 08:01:17 node-2 kernel: Memory cgroup out of memory: Killed process 23145 (emla-controller) total-vm:3120000kB, anon-rss:1661120kB, file-rss:29632kB, shmem-rss:0kB
May 10 08:35:08 node-2 kernel: Memory cgroup out of memory: Killed process 21906 (emla-apiserver) total-vm:3783936kB, anon-rss:1656896kB, file-rss:3584kB, shmem-rss:0kB
May 10 09:29:02 node-2 kernel: Memory cgroup out of memory: Killed process 9806 (emla-apiserver) total-vm:3175616kB, anon-rss:2328640kB, file-rss:0kB, shmem-rss:0kB
May 10 09:29:35 node-2 kernel: Memory cgroup out of memory: Killed process 3020 (emla-controller) total-vm:4880320kB, anon-rss:1864128kB, file-rss:28416kB, shmem-rss:0kB
May 10 10:22:11 node-2 kernel: Memory cgroup out of memory: Killed process 18030 (prometheus-conf) total-vm:723840kB, anon-rss:32320kB, file-rss:7744kB, shmem-rss:0kB
May 10 11:43:19 node-2 kernel: Memory cgroup out of memory: Killed process 48215 (prometheus-conf) total-vm:724096kB, anon-rss:12096kB, file-rss:7680kB, shmem-rss:0kB
May 10 13:16:28 node-2 kernel: Memory cgroup out of memory: Killed process 10895 (prometheus-conf) total-vm:724096kB, anon-rss:35584kB, file-rss:7744kB, shmem-rss:0kB
May 10 13:31:36 node-2 kernel: Memory cgroup out of memory: Killed process 39436 (prometheus-conf) total-vm:723840kB, anon-rss:28032kB, file-rss:7680kB, shmem-rss:0kB
May 10 14:07:46 node-2 kernel: Memory cgroup out of memory: Killed process 37875 (prometheus-conf) total-vm:723328kB, anon-rss:32000kB, file-rss:7616kB, shmem-rss:0kB
May 10 14:34:56 node-2 kernel: Memory cgroup out of memory: Killed process 8175 (prometheus-conf) total-vm:723840kB, anon-rss:29760kB, file-rss:7680kB, shmem-rss:0kB
May 10 14:41:04 node-2 kernel: Memory cgroup out of memory: Killed process 37468 (emla-controller) total-vm:1717824kB, anon-rss:928704kB, file-rss:29120kB, shmem-rss:0kB
May 10 14:41:36 node-2 kernel: Memory cgroup out of memory: Killed process 46969 (emla-apiserver) total-vm:1872768kB, anon-rss:918976kB, file-rss:7872kB, shmem-rss:0kB
May 10 14:42:11 node-2 kernel: Memory cgroup out of memory: Killed process 7609 (mysqld) total-vm:8132736kB, anon-rss:474368kB, file-rss:0kB, shmem-rss:131072kB
May 10 15:14:11 node-2 kernel: Memory cgroup out of memory: Killed process 62989 (prometheus-conf) total-vm:724608kB, anon-rss:35840kB, file-rss:7616kB, shmem-rss:0kB
May 10 17:17:20 node-2 kernel: Memory cgroup out of memory: Killed process 53146 (prometheus-conf) total-vm:723328kB, anon-rss:27520kB, file-rss:7552kB, shmem-rss:0kB
May 10 17:39:18 node-2 kernel: Memory cgroup out of memory: Killed process 21128 (emla-controller) total-vm:2153472kB, anon-rss:1301120kB, file-rss:29184kB, shmem-rss:0kB
May 10 17:49:52 node-2 kernel: Memory cgroup out of memory: Killed process 26559 (emla-controller) total-vm:2222720kB, anon-rss:1284800kB, file-rss:27776kB, shmem-rss:0kB
May 10 17:50:25 node-2 kernel: Memory cgroup out of memory: Killed process 27221 (emla-apiserver) total-vm:1805952kB, anon-rss:783616kB, file-rss:9408kB, shmem-rss:0kB
May 10 18:01:44 node-2 kernel: Memory cgroup out of memory: Killed process 3897 (prometheus-conf) total-vm:723840kB, anon-rss:24576kB, file-rss:7744kB, shmem-rss:0kB
May 10 18:04:59 node-2 kernel: Memory cgroup out of memory: Killed process 37509 (prometheus-conf) total-vm:723584kB, anon-rss:35264kB, file-rss:7360kB, shmem-rss:0kB
May 10 18:17:25 node-2 kernel: Memory cgroup out of memory: Killed process 65243 (prometheus-conf) total-vm:723584kB, anon-rss:14784kB, file-rss:7680kB, shmem-rss:0kB
May 10 18:34:19 node-2 kernel: Memory cgroup out of memory: Killed process 54668 (prometheus-conf) total-vm:724096kB, anon-rss:32320kB, file-rss:7744kB, shmem-rss:0kB
May 10 19:22:38 node-2 kernel: Memory cgroup out of memory: Killed process 37281 (prometheus-conf) total-vm:723584kB, anon-rss:21376kB, file-rss:7680kB, shmem-rss:0kB
May 10 21:13:51 node-2 kernel: Memory cgroup out of memory: Killed process 42755 (prometheus-conf) total-vm:723840kB, anon-rss:33216kB, file-rss:7680kB, shmem-rss:0kB
May 10 22:02:07 node-2 kernel: Memory cgroup out of memory: Killed process 57616 (prometheus-conf) total-vm:724352kB, anon-rss:23936kB, file-rss:7616kB, shmem-rss:0kB
May 10 23:08:17 node-2 kernel: Memory cgroup out of memory: Killed process 10853 (prometheus-conf) total-vm:724352kB, anon-rss:34944kB, file-rss:7680kB, shmem-rss:0kB
May 10 23:11:29 node-2 kernel: Memory cgroup out of memory: Killed process 10597 (prometheus-conf) total-vm:722560kB, anon-rss:32512kB, file-rss:7488kB, shmem-rss:0kB
May 10 23:17:53 node-2 kernel: Memory cgroup out of memory: Killed process 772 (prometheus-conf) total-vm:723328kB, anon-rss:26496kB, file-rss:7488kB, shmem-rss:0kB
May 10 23:36:34 node-2 kernel: Memory cgroup out of memory: Killed process 58347 (prometheus-conf) total-vm:723840kB, anon-rss:24832kB, file-rss:7744kB, shmem-rss:0kB
May 10 23:48:47 node-2 kernel: Memory cgroup out of memory: Killed process 37046 (prometheus-conf) total-vm:723072kB, anon-rss:21184kB, file-rss:7616kB, shmem-rss:0kB
May 11 01:10:14 node-2 kernel: Memory cgroup out of memory: Killed process 12519 (emla-controller) total-vm:2089664kB, anon-rss:1366336kB, file-rss:0kB, shmem-rss:0kB
May 11 03:07:05 node-2 kernel: Memory cgroup out of memory: Killed process 14933 (prometheus-conf) total-vm:723584kB, anon-rss:18816kB, file-rss:7744kB, shmem-rss:0kB
May 11 03:34:23 node-2 kernel: Memory cgroup out of memory: Killed process 51837 (prometheus-conf) total-vm:723584kB, anon-rss:33664kB, file-rss:7616kB, shmem-rss:0kB
May 11 04:07:39 node-2 kernel: Memory cgroup out of memory: Killed process 62314 (prometheus-conf) total-vm:724096kB, anon-rss:29760kB, file-rss:7744kB, shmem-rss:0kB
May 11 04:28:48 node-2 kernel: Memory cgroup out of memory: Killed process 17231 (prometheus-conf) total-vm:723328kB, anon-rss:31744kB, file-rss:7680kB, shmem-rss:0kB
May 11 07:23:04 node-2 kernel: Memory cgroup out of memory: Killed process 6507 (prometheus-conf) total-vm:724096kB, anon-rss:32576kB, file-rss:7680kB, shmem-rss:0kB
May 11 09:02:17 node-2 kernel: Memory cgroup out of memory: Killed process 58006 (prometheus-conf) total-vm:724864kB, anon-rss:36416kB, file-rss:7744kB, shmem-rss:0kB
May 11 09:17:33 node-2 kernel: Memory cgroup out of memory: Killed process 64619 (prometheus-conf) total-vm:724352kB, anon-rss:23808kB, file-rss:7744kB, shmem-rss:0kB
May 11 09:32:52 node-2 kernel: Memory cgroup out of memory: Killed process 51541 (prometheus-conf) total-vm:724352kB, anon-rss:30016kB, file-rss:7680kB, shmem-rss:0kB
May 11 10:06:02 node-2 kernel: Memory cgroup out of memory: Killed process 30405 (prometheus-conf) total-vm:723840kB, anon-rss:0kB, file-rss:7680kB, shmem-rss:0kB
May 11 12:25:25 node-2 kernel: Memory cgroup out of memory: Killed process 37136 (emla-apiserver) total-vm:4608256kB, anon-rss:1727360kB, file-rss:0kB, shmem-rss:0kB
May 11 15:27:17 node-2 kernel: Memory cgroup out of memory: Killed process 41186 (prometheus-conf) total-vm:724608kB, anon-rss:21568kB, file-rss:7680kB, shmem-rss:0kB
May 11 15:29:57 node-2 kernel: Memory cgroup out of memory: Killed process 61022 (emla-apiserver) total-vm:2903104kB, anon-rss:1464320kB, file-rss:0kB, shmem-rss:0kB
May 11 15:36:48 node-2 kernel: Memory cgroup out of memory: Killed process 63317 (emla-controller) total-vm:2226112kB, anon-rss:1346432kB, file-rss:0kB, shmem-rss:0kB
May 11 15:37:22 node-2 kernel: Memory cgroup out of memory: Killed process 65009 (emla-apiserver) total-vm:1938240kB, anon-rss:809664kB, file-rss:7424kB, shmem-rss:0kB
May 11 15:37:22 node-2 kernel: Memory cgroup out of memory: Killed process 52630 (prometheus-conf) total-vm:723584kB, anon-rss:39424kB, file-rss:7616kB, shmem-rss:0kB
May 11 15:48:05 node-2 kernel: Memory cgroup out of memory: Killed process 33844 (emla-apiserver) total-vm:3310336kB, anon-rss:2117696kB, file-rss:10880kB, shmem-rss:0kB
May 11 15:48:37 node-2 kernel: Memory cgroup out of memory: Killed process 57758 (emla-controller) total-vm:3939712kB, anon-rss:1716480kB, file-rss:12608kB, shmem-rss:0kB
May 11 16:14:59 node-2 kernel: Memory cgroup out of memory: Killed process 34421 (emla-apiserver) total-vm:2904640kB, anon-rss:1490688kB, file-rss:0kB, shmem-rss:0kB
May 11 16:19:47 node-2 kernel: Memory cgroup out of memory: Killed process 59273 (prometheus-conf) total-vm:723584kB, anon-rss:31680kB, file-rss:7680kB, shmem-rss:0kB
May 11 16:21:37 node-2 kernel: Memory cgroup out of memory: Killed process 18404 (emla-apiserver) total-vm:2146880kB, anon-rss:1141632kB, file-rss:0kB, shmem-rss:0kB
May 11 16:32:58 node-2 kernel: Memory cgroup out of memory: Killed process 43743 (prometheus) total-vm:24000960kB, anon-rss:3756736kB, file-rss:0kB, shmem-rss:0kB
May 11 16:36:19 node-2 kernel: Memory cgroup out of memory: Killed process 16857 (prometheus) total-vm:25363328kB, anon-rss:4943104kB, file-rss:0kB, shmem-rss:0kB
May 11 16:39:50 node-2 kernel: Memory cgroup out of memory: Killed process 34741 (prometheus) total-vm:23726464kB, anon-rss:3480512kB, file-rss:0kB, shmem-rss:0kB
May 11 16:46:29 node-2 kernel: Memory cgroup out of memory: Killed process 44892 (emla-controller) total-vm:3317696kB, anon-rss:1615296kB, file-rss:0kB, shmem-rss:0kB
May 11 16:46:58 node-2 kernel: Memory cgroup out of memory: Killed process 7531 (emla-apiserver) total-vm:3039616kB, anon-rss:1467392kB, file-rss:12672kB, shmem-rss:0kB
May 11 16:49:58 node-2 kernel: Memory cgroup out of memory: Killed process 56856 (prometheus-conf) total-vm:723584kB, anon-rss:38976kB, file-rss:7808kB, shmem-rss:0kB
May 11 16:53:40 node-2 kernel: Memory cgroup out of memory: Killed process 46578 (emla-controller) total-vm:3178624kB, anon-rss:2091520kB, file-rss:0kB, shmem-rss:0kB
May 11 16:54:18 node-2 kernel: Memory cgroup out of memory: Killed process 19938 (mysqld) total-vm:43427392kB, anon-rss:1224640kB, file-rss:0kB, shmem-rss:14336kB
May 11 17:26:10 node-2 kernel: Memory cgroup out of memory: Killed process 7598 (prometheus-conf) total-vm:724096kB, anon-rss:24896kB, file-rss:7744kB, shmem-rss:0kB
May 11 17:56:20 node-2 kernel: Memory cgroup out of memory: Killed process 12749 (prometheus-conf) total-vm:723072kB, anon-rss:25536kB, file-rss:7552kB, shmem-rss:0kB
May 11 18:26:34 node-2 kernel: Memory cgroup out of memory: Killed process 49624 (prometheus-conf) total-vm:723072kB, anon-rss:27072kB, file-rss:7680kB, shmem-rss:0kB
May 11 18:41:48 node-2 kernel: Memory cgroup out of memory: Killed process 62374 (prometheus-conf) total-vm:723072kB, anon-rss:27840kB, file-rss:7744kB, shmem-rss:0kB
May 11 18:54:06 node-2 kernel: Memory cgroup out of memory: Killed process 15222 (prometheus-conf) total-vm:723840kB, anon-rss:30464kB, file-rss:7680kB, shmem-rss:0kB
May 11 20:09:26 node-2 kernel: Memory cgroup out of memory: Killed process 62856 (prometheus-conf) total-vm:723840kB, anon-rss:28224kB, file-rss:7680kB, shmem-rss:0kB
May 11 21:04:20 node-2 kernel: Memory cgroup out of memory: Killed process 12110 (mysqld) total-vm:50199680kB, anon-rss:2721728kB, file-rss:0kB, shmem-rss:113728kB
May 11 21:04:56 node-2 kernel: Memory cgroup out of memory: Killed process 55763 (emla-controller) total-vm:2155776kB, anon-rss:1342720kB, file-rss:14912kB, shmem-rss:0kB
May 11 21:06:38 node-2 kernel: Memory cgroup out of memory: Killed process 44819 (prometheus-conf) total-vm:723840kB, anon-rss:27136kB, file-rss:7680kB, shmem-rss:0kB
May 11 21:07:50 node-2 kernel: Memory cgroup out of memory: Killed process 9097 (emla-controller) total-vm:2355712kB, anon-rss:1342336kB, file-rss:0kB, shmem-rss:0kB
May 11 21:10:21 node-2 kernel: Memory cgroup out of memory: Killed process 20170 (emla-controller) total-vm:2207040kB, anon-rss:1275968kB, file-rss:11072kB, shmem-rss:0kB
May 11 22:24:48 node-2 kernel: Memory cgroup out of memory: Killed process 64813 (prometheus-conf) total-vm:724096kB, anon-rss:27456kB, file-rss:7744kB, shmem-rss:0kB
May 11 22:36:51 node-2 kernel: Memory cgroup out of memory: Killed process 54968 (emla-apiserver) total-vm:2906240kB, anon-rss:1553536kB, file-rss:0kB, shmem-rss:0kB
May 11 22:48:59 node-2 kernel: Memory cgroup out of memory: Killed process 40043 (prometheus-conf) total-vm:723840kB, anon-rss:25856kB, file-rss:7616kB, shmem-rss:0kB
May 11 22:58:29 node-2 kernel: Memory cgroup out of memory: Killed process 61711 (mysqld) total-vm:49275328kB, anon-rss:1884352kB, file-rss:0kB, shmem-rss:31872kB
May 11 23:19:35 node-2 kernel: Memory cgroup out of memory: Killed process 7959 (emla-controller) total-vm:2705024kB, anon-rss:1523392kB, file-rss:0kB, shmem-rss:0kB
May 12 00:11:11 node-2 kernel: Memory cgroup out of memory: Killed process 44446 (emla-apiserver) total-vm:3580864kB, anon-rss:2562176kB, file-rss:0kB, shmem-rss:0kB
May 12 03:02:46 node-2 kernel: Memory cgroup out of memory: Killed process 4064 (mysqld) total-vm:43367232kB, anon-rss:1239680kB, file-rss:0kB, shmem-rss:120000kB
May 12 04:19:16 node-2 kernel: Memory cgroup out of memory: Killed process 22304 (prometheus-conf) total-vm:723584kB, anon-rss:34880kB, file-rss:7744kB, shmem-rss:0kB
May 12 04:46:35 node-2 kernel: Memory cgroup out of memory: Killed process 63348 (prometheus-conf) total-vm:723072kB, anon-rss:21504kB, file-rss:7680kB, shmem-rss:0kB
May 12 05:01:54 node-2 kernel: Memory cgroup out of memory: Killed process 27348 (prometheus-conf) total-vm:723584kB, anon-rss:26112kB, file-rss:7744kB, shmem-rss:0kB
May 12 05:07:40 node-2 kernel: Memory cgroup out of memory: Killed process 50741 (emla-controller) total-vm:3442944kB, anon-rss:2492032kB, file-rss:0kB, shmem-rss:0kB
May 12 05:11:25 node-2 kernel: Memory cgroup out of memory: Killed process 26851 (emla-controller) total-vm:1866752kB, anon-rss:1147008kB, file-rss:0kB, shmem-rss:0kB
May 12 05:11:59 node-2 kernel: Memory cgroup out of memory: Killed process 21864 (emla-apiserver) total-vm:2008512kB, anon-rss:829440kB, file-rss:0kB, shmem-rss:0kB
May 12 05:33:11 node-2 kernel: Memory cgroup out of memory: Killed process 40076 (emla-controller) total-vm:2223872kB, anon-rss:1390144kB, file-rss:0kB, shmem-rss:0kB
May 12 05:52:27 node-2 kernel: Memory cgroup out of memory: Killed process 30432 (emla-apiserver) total-vm:3446528kB, anon-rss:1506432kB, file-rss:0kB, shmem-rss:0kB
May 12 05:53:01 node-2 kernel: Memory cgroup out of memory: Killed process 23365 (emla-controller) total-vm:2289856kB, anon-rss:1090752kB, file-rss:10176kB, shmem-rss:0kB
May 12 05:59:11 node-2 kernel: Memory cgroup out of memory: Killed process 52980 (emla-apiserver) total-vm:2767808kB, anon-rss:1950592kB, file-rss:4544kB, shmem-rss:0kB
May 12 06:10:45 node-2 kernel: Memory cgroup out of memory: Killed process 29581 (mysqld) total-vm:51212672kB, anon-rss:1461888kB, file-rss:0kB, shmem-rss:56576kB
May 12 06:17:14 node-2 kernel: Memory cgroup out of memory: Killed process 52710 (emla-apiserver) total-vm:3310848kB, anon-rss:2351936kB, file-rss:15296kB, shmem-rss:0kB
May 12 06:44:07 node-2 kernel: Memory cgroup out of memory: Killed process 47174 (prometheus-conf) total-vm:724608kB, anon-rss:25152kB, file-rss:7744kB, shmem-rss:0kB
May 12 06:59:17 node-2 kernel: Memory cgroup out of memory: Killed process 8650 (prometheus-conf) total-vm:723328kB, anon-rss:30336kB, file-rss:7680kB, shmem-rss:0kB
May 12 07:17:31 node-2 kernel: Memory cgroup out of memory: Killed process 13752 (prometheus-conf) total-vm:723328kB, anon-rss:29632kB, file-rss:7680kB, shmem-rss:0kB
May 12 07:26:46 node-2 kernel: Memory cgroup out of memory: Killed process 50305 (prometheus-conf) total-vm:724096kB, anon-rss:17920kB, file-rss:7680kB, shmem-rss:0kB
May 12 07:36:13 node-2 kernel: Memory cgroup out of memory: Killed process 50083 (prometheus-conf) total-vm:724096kB, anon-rss:34304kB, file-rss:7680kB, shmem-rss:0kB
May 12 07:38:35 node-2 kernel: Memory cgroup out of memory: Killed process 57073 (mysqld) total-vm:54555968kB, anon-rss:1991232kB, file-rss:0kB, shmem-rss:40192kB
May 12 07:54:49 node-2 kernel: Memory cgroup out of memory: Killed process 52332 (prometheus-conf) total-vm:723072kB, anon-rss:36480kB, file-rss:7744kB, shmem-rss:0kB
May 12 08:00:43 node-2 kernel: Memory cgroup out of memory: Killed process 58592 (emla-controller) total-vm:2156864kB, anon-rss:1377984kB, file-rss:0kB, shmem-rss:0kB
May 12 08:19:06 node-2 kernel: Memory cgroup out of memory: Killed process 18221 (mysqld) total-vm:49555520kB, anon-rss:1504192kB, file-rss:0kB, shmem-rss:17792kB
May 12 09:10:07 node-2 kernel: Memory cgroup out of memory: Killed process 46778 (mysqld) total-vm:51087680kB, anon-rss:1543744kB, file-rss:0kB, shmem-rss:24128kB
May 12 09:28:10 node-2 kernel: Memory cgroup out of memory: Killed process 52965 (emla-controller) total-vm:3666880kB, anon-rss:1593344kB, file-rss:0kB, shmem-rss:0kB
May 12 09:43:04 node-2 kernel: Memory cgroup out of memory: Killed process 58450 (prometheus-conf) total-vm:724096kB, anon-rss:0kB, file-rss:7680kB, shmem-rss:0kB
May 12 09:47:03 node-2 kernel: Memory cgroup out of memory: Killed process 51483 (emla-controller) total-vm:3183360kB, anon-rss:1477568kB, file-rss:0kB, shmem-rss:0kB
May 12 10:21:24 node-2 kernel: Memory cgroup out of memory: Killed process 63545 (emla-apiserver) total-vm:2698048kB, anon-rss:1399488kB, file-rss:0kB, shmem-rss:0kB
May 12 10:41:09 node-2 kernel: Memory cgroup out of memory: Killed process 20829 (emla-apiserver) total-vm:3174208kB, anon-rss:1476288kB, file-rss:0kB, shmem-rss:0kB
May 12 10:59:46 node-2 kernel: Memory cgroup out of memory: Killed process 54831 (emla-controller) total-vm:3324608kB, anon-rss:1537920kB, file-rss:0kB, shmem-rss:0kB
May 12 11:02:42 node-2 kernel: Memory cgroup out of memory: Killed process 1951 (emla-apiserver) total-vm:2004928kB, anon-rss:793024kB, file-rss:4736kB, shmem-rss:0kB
整理出其中一组触发的打印如下:
lockup:
May 16 15:20:02 node-2 kernel: watchdog: BUG: soft lockup - CPU#85 stuck for 22s! [migration/85:537]oom:
May 16 15:20:02 node-2 kernel: Memory cgroup out of memory: Killed process 28155 (mysqld) total-vm:52594048kB, anon-rss:1463040kB, file-rss:0kB, shmem-rss:90816kB
其中,整理后的 lockup 的详细输出如下:
May 16 15:20:02 node-2 kernel: watchdog: BUG: soft lockup - CPU#85 stuck for 22s! [migration/85:537]
...
...
May 16 15:20:02 node-2 kernel: Hardware name: WuZhou WZ-FD01S4/WZ-FD01S4, BIOS KL4.26.WZ.S.001.210803.D 08/03/21 09:17:56
May 16 15:20:02 node-2 kernel: pstate: 60000005 (nZCv daif -PAN -UAO)
May 16 15:20:02 node-2 kernel: pc : __ll_sc_atomic_add_return+0x14/0x20
May 16 15:20:02 node-2 kernel: lr : rcu_momentary_dyntick_idle+0x3c/0x58
May 16 15:20:02 node-2 kernel: sp : ffff00002482fd60
May 16 15:20:02 node-2 kernel: x29: ffff00002482fd60 x28: 0000000000000000
May 16 15:20:02 node-2 kernel: x27: ffffe582c0c7b2b8 x26: ffff00006128f428
May 16 15:20:02 node-2 kernel: x25: ffff2e2be25b6a60 x24: 0000000000000000
May 16 15:20:02 node-2 kernel: x23: 0000000000000000 x22: 0000000000000000
May 16 15:20:02 node-2 kernel: x21: ffff00006128f4c4 x20: ffff00006128f4a0
May 16 15:20:02 node-2 kernel: x19: 0000000000000001 x18: 0000000000000000
May 16 15:20:02 node-2 kernel: x17: 00000000192a0d6a x16: 0000000000000000
May 16 15:20:02 node-2 kernel: x15: 0000000000000003 x14: 0000000000000002
May 16 15:20:02 node-2 kernel: x13: 0000000000000006 x12: 0000000000000027
May 16 15:20:02 node-2 kernel: x11: 0000000000000017 x10: 0000000000000d10
May 16 15:20:02 node-2 kernel: x9 : ffff00002482fd40
May 16 15:20:02 node-2 kernel: x8 : ffffe582c0cab570
May 16 15:20:02 node-2 kernel: x7 : ffff00006128f4a0 x6 : 00000004341958ff
May 16 15:20:02 node-2 kernel: x5 : 0000b7571d4c0000 x4 : ffffe582c0caae00
May 16 15:20:02 node-2 kernel: x3 : 0000b7571d4c0000 x2 : ffffe582fff6e9c0
May 16 15:20:02 node-2 kernel: x1 : ffffe582fff6ea78 x0 : 0000000000000004
May 16 15:20:02 node-2 kernel: Call trace:
May 16 15:20:02 node-2 kernel: __ll_sc_atomic_add_return+0x14/0x20
May 16 15:20:02 node-2 kernel: multi_cpu_stop+0xf4/0x150
May 16 15:20:02 node-2 kernel: cpu_stopper_thread+0xb4/0x170
May 16 15:20:02 node-2 kernel: smpboot_thread_fn+0x154/0x1d8
May 16 15:20:02 node-2 kernel: kthread+0x130/0x138
May 16 15:20:02 node-2 kernel: ret_from_fork+0x10/0x18
可以看到报告 lockup 的点是 rcu_momentary_dyntick_idle 这个函数里面,触发 lockup 的线程是迁移线程migration/85:537。跟踪相关代码流程如下:
cpu_stopper_thread-> multi_cpu_stop-> rcu_momentary_dyntick_idle
也就是说在迁移线程中调用 rcu_momentary_dyntick_idle函数触发了 lockup。multi_cpu_stop 代码如下:
static int multi_cpu_stop(void *data)
{struct multi_stop_data *msdata = data;enum multi_stop_state newstate, curstate = MULTI_STOP_NONE;int cpu = smp_processor_id(), err = 0;unsigned long flags;bool is_active;/** When called from stop_machine_from_inactive_cpu(), irq might* already be disabled. Save the state and restore it on exit.*/local_save_flags(flags);if (!msdata->active_cpus)is_active = cpu == cpumask_first(cpu_online_mask);elseis_active = cpumask_test_cpu(cpu, msdata->active_cpus);/* Simple state machine */do {/* Chill out and ensure we re-read multi_stop_state. */cpu_relax_yield();newstate = READ_ONCE(msdata->state);if (newstate != curstate) {curstate = newstate;switch (curstate) {case MULTI_STOP_DISABLE_IRQ:local_irq_disable();hard_irq_disable();break;case MULTI_STOP_RUN:if (is_active)err = msdata->fn(msdata->data);break;default:break;}ack_state(msdata);} else if (curstate > MULTI_STOP_PREPARE) {/** At this stage all other CPUs we depend on must spin* in the same loop. Any reason for hard-lockup should* be detected and reported on their side.*/touch_nmi_watchdog();}rcu_momentary_dyntick_idle(); // 触发 soft lockup} while (curstate != MULTI_STOP_EXIT);local_irq_restore(flags);return err;
}
该函数逻辑为:在 stop machine cpu 停机的状态下执行 msdata 中指定的回调。该函数首先会关闭中断,并在这种情况下调用 msdata->fn(msdata->data),为了防止触发 watchdog 这里调用了 touch_nmi_watchdog 来复位 watchdog。所以从代码上看能够触发 soft lockup 的地方可能是 msdata->fn(msdata->data) 这个回调占用时间太久,或者是 rcu_momentary_dyntick_idle 这个调用时间太久。rcu_momentary_dyntick_idle 代码如下:
/** Let the RCU core know that this CPU has gone through the scheduler,* which is a quiescent state. This is called when the need for a* quiescent state is urgent, so we burn an atomic operation and full* memory barriers to let the RCU core know about it, regardless of what* this CPU might (or might not) do in the near future.** We inform the RCU core by emulating a zero-duration dyntick-idle period.** The caller must have disabled interrupts and must not be idle.*/
void rcu_momentary_dyntick_idle(void)
{int special;raw_cpu_write(rcu_data.rcu_need_heavy_qs, false);special = atomic_add_return(2 * RCU_DYNTICK_CTRL_CTR,&this_cpu_ptr(&rcu_data)->dynticks);/* It is illegal to call this from idle state. */WARN_ON_ONCE(!(special & RCU_DYNTICK_CTRL_CTR));rcu_preempt_deferred_qs(current);
}
这个代码主要工作是向 rcu 报告该 cpu 经历了一个静默期,在需要报告静默期时调用该函数,并且要求调用者禁用中断并且不能 cpu 不能处于空闲状态。代码具体细节目前未研究。
怀疑点1:可能导致长时间调用的点是 msdata->fn,首先看看哪些地方会注册 msdafa->fn。
multi_cpu_stop-> stop_two_cpus (注册 migrate_swap_stop 回调)-> migrate_swap(if CONFIG_NUMA_BALANCING)-> task_numa_migrate-> numa_migrate_preferred-> task_numa_fault (page fault)-> stop_machine_cpuslocked-> stop_machine-> takedown_cpu-> 启动阶段调用 aarch64_insn_patch_text_sync ...-> stop_machine_from_inactive_cpu (仅 x86 调用)
第一个是 task_numa_fault 函数会最终注册 migrate_swap_stop ,代码如下:
static int migrate_swap_stop(void *data)
{struct migration_swap_arg *arg = data;struct rq *src_rq, *dst_rq;int ret = -EAGAIN;if (!cpu_active(arg->src_cpu) || !cpu_active(arg->dst_cpu))return -EAGAIN;src_rq = cpu_rq(arg->src_cpu);dst_rq = cpu_rq(arg->dst_cpu);double_raw_lock(&arg->src_task->pi_lock,&arg->dst_task->pi_lock);double_rq_lock(src_rq, dst_rq);if (task_cpu(arg->dst_task) != arg->dst_cpu)goto unlock;if (task_cpu(arg->src_task) != arg->src_cpu)goto unlock;if (!cpumask_test_cpu(arg->dst_cpu, &arg->src_task->cpus_allowed))goto unlock;if (!cpumask_test_cpu(arg->src_cpu, &arg->dst_task->cpus_allowed))goto unlock;__migrate_swap_task(arg->src_task, arg->dst_cpu);__migrate_swap_task(arg->dst_task, arg->src_cpu);ret = 0;unlock:double_rq_unlock(src_rq, dst_rq);raw_spin_unlock(&arg->dst_task->pi_lock);raw_spin_unlock(&arg->src_task->pi_lock);return ret;
}
从代码可以看到会获取两把锁,一个 src task 的 pi_lock 以及对应 cpu 的 rq_lock,第二个是 dst task 的 pi_lock 以及对应 cpu 的 rq_lock。从逻辑来看除非 在其他地方长时间占用 任务的 pi_lock 锁,否则应该不会导致 soft lockup。pi_lock 锁的使用主要在四个地方。
- set_special_state (TASK_STOPPED, TASK_TRACED, TASK_DEAD)
- do_exit
- rt_mutext
- sched migrate → …. task_rq_lock
目前从 oom killer 测的堆栈回溯没有看到会竞争 pi_lock 的地方。
第二个是 stop_machine_cpuslocked 这个主要是在 cpus_read_lock 的保护下在停机状态执行一些回调函数。其中处理器启动阶段的替换指令,热补丁会调用,以及卸载一些 cpu(takedown_cpu)时会调用停机,这些地点也不会在运行中触发 soft lockup。
最后是 stop_machine,内核常用的停机调用回调的函数。这个在许多地方会调用:各类驱动,ftrace 等,目前暂时排除这个点。
综上所述,目前暂时在 msdata->fn 中没有到怀疑点,所以问题主要集中在 rcu_momentary_dyntick_idle 中。
接着看一下对应的最近时间点的 oom 的详细信息,中间去除了许多打印,直接找到 dump stack 的地方:
May 16 15:19:25 node-2 kernel: CPU: 121 PID: 13970 Comm: kube-apiserver Kdump: loaded Tainted: G W OEL --------- - - 4.18.0-147.5.1.es8_24.aarch64+numa64 #1
May 16 15:19:25 node-2 kernel: Hardware name: WuZhou WZ-FD01S4/WZ-FD01S4, BIOS KL4.26.WZ.S.001.210803.D 08/03/21 09:17:56
May 16 15:19:25 node-2 kernel: Call trace:
May 16 15:19:25 node-2 kernel: dump_backtrace+0x0/0x188
May 16 15:19:25 node-2 kernel: show_stack+0x24/0x30
May 16 15:19:25 node-2 kernel: dump_stack+0x90/0xb4
May 16 15:19:25 node-2 kernel: dump_header+0x70/0x238
May 16 15:19:25 node-2 kernel: oom_kill_process+0x1ac/0x1b0
May 16 15:19:25 node-2 kernel: out_of_memory+0x190/0x4e0
May 16 15:19:25 node-2 kernel: mem_cgroup_out_of_memory+0x68/0xa0
May 16 15:19:25 node-2 kernel: try_charge+0x6a0/0x730
May 16 15:19:25 node-2 kernel: mem_cgroup_try_charge+0x8c/0x208
May 16 15:19:25 node-2 kernel: __add_to_page_cache_locked+0x74/0x270
May 16 15:19:25 node-2 kernel: add_to_page_cache_lru+0x78/0x118
May 16 15:19:25 node-2 kernel: filemap_fault+0x444/0x538
May 16 15:19:25 node-2 kernel: __xfs_filemap_fault+0x74/0x230 [xfs]
May 16 15:19:25 node-2 kernel: xfs_filemap_fault+0x44/0x50 [xfs]
May 16 15:19:25 node-2 kernel: __do_fault+0x2c/0xf8
May 16 15:19:25 node-2 kernel: do_fault+0x1b0/0x4b0
May 16 15:19:25 node-2 kernel: __handle_mm_fault+0x3fc/0x4f0
May 16 15:19:25 node-2 kernel: handle_mm_fault+0xf8/0x1a0
May 16 15:19:25 node-2 kernel: do_page_fault+0x15c/0x478
May 16 15:19:25 node-2 kernel: do_translation_fault+0x9c/0xac
May 16 15:19:25 node-2 kernel: do_mem_abort+0x50/0xa8
May 16 15:19:25 node-2 kernel: do_el0_ia_bp_hardening+0x58/0x98
May 16 15:19:25 node-2 kernel: el0_ia+0x1c/0x20
May 16 15:19:25 node-2 kernel: Task in /kubepods/besteffort/podc011642f-f13a-461d-bf8e-9405572077b1/d238ef398c00af09f7d8f5c51335056894432becfc8a82c49a7d4021980eccce killed as a result of limit of /kubepods
May 16 15:19:25 node-2 kernel: memory: usage 41943104kB, limit 41943488kB, failcnt 59146173
May 16 15:19:25 node-2 kernel: memory+swap: usage 41943360kB, limit 9007199254740928kB, failcnt 0
May 16 15:19:25 node-2 kernel: kmem: usage 0kB, limit 9007199254740928kB, failcnt 0
May 16 15:19:25 node-2 kernel: Memory cgroup stats for /kubepods: cache:0KB rss:0KB rss_huge:0KB shmem:0KB mapped_file:0KB dirty:0KB writeback:0KB swap:0KB inactive_anon:0KB active_anon:0KB inactive_file:0KB active_file:0KB unevictable:0KB
...
...
May 16 15:20:02 node-2 kernel: Memory cgroup out of memory: Killed process 28155 (mysqld) total-vm:52594048kB, anon-rss:1463040kB, file-rss:0kB, shmem-rss:90816kB
通过:Task in /kubepods/besteffort/podc011642f-f13a-461d-bf8e-9405572077b1/d238ef398c00af09f7d8f5c51335056894432becfc8a82c49a7d4021980eccce killed as a result of limit of /kubepods信息,可以找到对应的 memory crgoup: /kubepods,查看其 memory 配置:
[root@node-2 kubepods]# cat memory.limit_in_bytes
42950131712
[root@node-2 kubepods]# cat memory.usage_in_bytes
42449043456
[root@node-2 kubepods]# cat memory.max_usage_in_bytes
42955702272
[root@node-2 kubepods]#
可以看到最多允许该节点及其子节点使用 40G 左右内存,当前使用了 39.5G 左右内存,最大使用过 40G 多一点的内存,符合偶尔触发 oom killer 的条件。
通过打印可以看到在 kube-apiserver 应用访问指令时触发了 el0_ia 指令同步异常从而进入内核并最终检测到是 mem_abort 从而触发了 pagefult。(不仅是 el0_ia,其他打印也有通过 el0_da 进入该流程,属于访问数据出现的异常)通过 pagefault,最终在分配内存时调用 mem_cgroup_try_charge 检测到所属memory cgroup的内存超限了,从而调用 mem_cgroup_out_of_memory 在组内 kill 进程来回收内存,这里 kill 掉的是 mysqld。
通过 soft lockup 和 oom 的时间戳可以看到 soft lockup 是在该 oom 打印期间,报告出来的。是否是 oom 的 oom_kill_process 逻辑与迁移线程中的 rcu_momentary_dyntick_idle 存在影响导致的?
构建如下测试复现脚本:
启动脚本:
// memcg_test.sh
#!/bin/sh
mount -t cgroup memory cpumkdir -p cpu/memcg_test
echo 1000M > cpu/memcg_test/memory.limit_in_bytes
echo 0-15 > cpu/memcg_test/cpuset.cpus
echo 0 > cpu/memcg_test/cpuset.mems
echo 1 > cpu/memcg_test/memory.use_hierarchyfor i in `seq 1 2000`;
domkdir -p cpu/memcg_test/test_$iecho 0-15 > cpu/memcg_test/test_$i/cpuset.cpusecho 0 > cpu/memcg_test/test_$i/cpuset.memsecho 1 > cpu/memcg_test/test_$i/memory.use_hierarchy./alloc_mem &echo $! >cpu/memcg_test/test_$i/tasks
done
创建 memcg_test cgroup memory 节点,并设置该节点可以使用 1G 内存,模拟 53 环境上kubepods 创建大量子节点,设置 use_hierarchy 为 1 共用 memcg_test 的内存。
其中 alloc_mem 程序代码如下:
// alloc_mem.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main()
{int i = 9;char *addr;addr = malloc(0x50000);char * start = addr;while (1) {addr = start;int a = 0x50000;usleep(5000000);while (a-- > 3) {*addr++ = 0x3;}}
}
首先分配 320KB 内存,接着对该内存区域遍历写操作,最后触发 pagefault 分配实际内存。
最后一个触发脚本:
// alloc.sh
#!/bin/shfor i in `seq 0 500`;
do./alloc_mem &
done
触发原理:
通过在 memcg_test 内存控制节点中创建大量分配内存任务,知道分配内存达到 memcg_test 允许的最大内存量,触发 oom killer 来回收 memcg_test 下的内存,这个时候就有概率触发 soft lockup。
如何在迁移线程触发 soft lockup?
经过大量测试,实际触发点是需要在 oom killer 遍历 process 时调用 stop_machine。所以在测试中,手动创建了一个线程,每隔一秒在任意 cpu 上执行一次 stop_machine 即可触发 bug。
stop_machine 中执行的任务是什么并不影响触发 bug。
代码大致如下:
static int update_cpu_topology(void *data)
{static unsigned long aa = 5;int i = 1000;while (i--) {aa *= i;}return 0;
}static int sathreadfn(void *data)
{while (1) {msleep(1000);stop_machine(update_cpu_topology, NULL, NULL);}return 0;
}void init(void)
{struct task_struct *tsk;tsk = kthread_create(sathreadfn, NULL, "test");wake_up_process(task);
}
qemu 启动脚本如下:
#!/bin/shsudo qemu-system-x86_64 \-cpu Skylake-Server-IBRS,ss=on,vmx=on,hypervisor=on,tsc_adjust=on,clflushopt=on,umip=on,pku=on,avx512vnni=on,md-clear=on,stibp=on,ssbd=on,xsaves=on \-drive format=raw,file=/home/miracle/play/busybox-1.35.0/test.img \-append "root=/dev/sda rootfstype=ext4 rw console=ttyS0 init=/linuxrc sched_debug" \-kernel /home/miracle/play/escore_kernel_source/arch/x86/boot/bzImage -nographic \-smp cores=4,threads=2,sockets=2 \-enable-kvm \-m 4G \-object memory-backend-ram,id=mem0,size=1G \-object memory-backend-ram,id=mem1,size=1G \-object memory-backend-ram,id=mem2,size=1G \-object memory-backend-ram,id=mem3,size=1G \-numa node,memdev=mem0,cpus=0-3,nodeid=0 \-numa node,memdev=mem1,cpus=4-8,nodeid=1 \-numa node,memdev=mem2,cpus=9-11,nodeid=2 \-numa node,memdev=mem3,cpus=12-15,nodeid=3
测试结果如下:
[ 72.584951] Code: c3 90 f3 0f 1e fa 48 c7 c0 40 1e 02 00 65 c6 05 f9 91 55 44 00 65 48 03 05 65 64 54 44 ba 04 00 00 00 f0 0f c1 90 b8 00 00 00 <83> e2 02 74 01 c3 0f 0b c3 66 66 2e 0f 1f 84 00 00 00 00 00 0ff
[ 72.584951] RSP: 0018:ffffb01b009e3e78 EFLAGS: 00000212 ORIG_RAX: ffffffffffffff13
[ 72.584951] RAX: ffff9cdb7eba1e40 RBX: 0000000000000001 RCX: 0000000000000000
[ 72.584951] RDX: 000000006063404e RSI: 0000000000000040 RDI: ffffffffbcd26ee0
[ 72.584951] RBP: ffffb01b00dbfea0 R08: 0000000000000000 R09: 0000000000020a40
[ 72.584951] R10: ffff9cdb7eba1200 R11: 0000000000000001 R12: ffffb01b00dbfec4
[ 72.584951] R13: 0000000000000000 R14: ffff9cdb7eb9c300 R15: 0000000000000282
[ 72.584951] FS: 0000000000000000(0000) GS:ffff9cdb7eb80000(0000) knlGS:0000000000000000
[ 72.584951] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 72.584951] CR2: 00007f593795e000 CR3: 00000000a660a003 CR4: 0000000000360ee0
[ 72.584951] Call Trace:
[ 72.584951] multi_cpu_stop+0xa6/0xd0
[ 72.584951] ? cpu_stop_queue_work+0xc0/0xc0
[ 72.584951] cpu_stopper_thread+0x64/0xe0
[ 72.584951] smpboot_thread_fn+0xb7/0x150
[ 72.584951] kthread+0xf7/0x130
[ 72.584951] ? sort_range+0x20/0x20
[ 72.584951] ? kthread_flush_work_fn
[ 72.507088] watchdog: BUG: soft lockup - CPU#9 stuck for 22s! [migration/9:66]
[ 72.544143] watchdog: BUG: soft lockup - CPU#10 stuck for 22s! [migration/10:73]
[ 72.544175] watchdog: BUG: soft lockup - CPU#12 stuck for 22s! [migration/12:85]
[ 72.564634] watchdog: BUG: soft lockup - CPU#13 stuck for 22s! [migration/13:92]
[ 72.568761] watchdog: BUG: soft lockup - CPU#14 stuck for 22s! [migration/14:98]
[ 72.583969] watchdog: BUG: soft lockup - CPU#15 stuck for 22s! [migration/15:104]
/ # dmesg | grep "Killed"
[ 72.593418] Out of memory: Killed process 3280 (alloc_mem) total-vm:1396kB, anon-rss:200kB, file-rss:28kB, shmem-rss:0kB
从上可以看到和服务器报错基本一致,在 watchdog: BUG: soft lockup 后紧跟着会出现 Killed process 的打印。
触发 soft lockup 原因分析(一):
首先从 soft lockup 堆栈分析:
kthread-> smpboot_thread_fn-> cpu_stopper_thread-> multi_cpu_stop-> (soft lockup)
cpu_stopper_thread 是一个迁移线程,代码如下:
static void cpu_stopper_thread(unsigned int cpu)
{struct cpu_stopper *stopper = &per_cpu(cpu_stopper, cpu);struct cpu_stop_work *work;repeat:work = NULL;raw_spin_lock_irq(&stopper->lock);if (!list_empty(&stopper->works)) {work = list_first_entry(&stopper->works,struct cpu_stop_work, list);list_del_init(&work->list);}raw_spin_unlock_irq(&stopper->lock);if (work) {cpu_stop_fn_t fn = work->fn;void *arg = work->arg;struct cpu_stop_done *done = work->done;int ret;/* cpu stop callbacks must not sleep, make in_atomic() == T */preempt_count_inc();ret = fn(arg);if (done) {if (ret)done->ret = ret;cpu_stop_signal_done(done);}preempt_count_dec();WARN_ONCE(preempt_count(),"cpu_stop: %pf(%p) leaked preempt count\n", fn, arg);goto repeat;}
}/* signal completion unless @done is NULL */
static void cpu_stop_signal_done(struct cpu_stop_done *done)
{if (atomic_dec_and_test(&done->nr_todo))complete(&done->completion);
}
首先:迁移线程从 &per_cpu(cpu_stopper, cpu) 中取出本 cpu 的 stopper 结构体,stopper->works 链表中保存了当前需要在迁移线程中执行的回调函数。并依次进行回调函数调用,并且完成后通过 cpu_stop_signal_done函数中的完成量唤醒等待该回调完成的任务。而本次触发 soft lockup 的地点正是其中的一个回调:multi_cpu_stop。
接着:迁移线程是一个 stop task,也就是最高优先级的线程,专用于一些必须停机操作的重要任务使用,比如任务迁移,ftrace 修改 text 段等。
内核中使用 stop_machine, stop_cpus, stop_one_cpu, stop_one_cpu_nowait, stop_two_cpus 等来注册在停机时调用的函数,他们最终都会调用 cpu_stop_queue_work 或者 cpu_stop_queue_two_works函数。比如 cpu_stop_queue_work 代码如下:
static bool cpu_stop_queue_work(unsigned int cpu, struct cpu_stop_work *work)
{struct cpu_stopper *stopper = &per_cpu(cpu_stopper, cpu);DEFINE_WAKE_Q(wakeq);unsigned long flags;bool enabled;preempt_disable();raw_spin_lock_irqsave(&stopper->lock, flags);enabled = stopper->enabled;if (enabled)__cpu_stop_queue_work(stopper, work, &wakeq);else if (work->done)cpu_stop_signal_done(work->done);raw_spin_unlock_irqrestore(&stopper->lock, flags);wake_up_q(&wakeq);preempt_enable();return enabled;
}static void __cpu_stop_queue_work(struct cpu_stopper *stopper,struct cpu_stop_work *work,struct wake_q_head *wakeq)
{list_add_tail(&work->list, &stopper->works);wake_q_add(wakeq, stopper->thread);
}
通过 __cpu_stop_queue_work 将回调包装的 cpu_stop_work 挂载在 stopper->works 链表中,并且唤醒迁移线程。那么就会在迁移线程中去执行注册进来的回调。
回过来看触发 bug 的回调 multi_cpu_stop,它的注册点有两个:
第一处:
handle_pte_fault-> do_numa_page-> task_numa_fault-> numa_migrate_preferred-> task_numa_migrate-> migrate_swap-> stop_two_cpus(arg.dst_cpu, arg.src_cpu, migrate_swap_stop, &arg);-> cpu_stop_queue_two_works(work1 = work2 = multi_cpu_stop)
该处为在 page fault 处理 numa 节点交换任务时,通过在两个 cpu 中的任意一个上执行 multi_cpu_stop 函数来调用 migrate_swap_stop 来交换两个 cpu 的任务。
通过测试,该处不触发 bug。
第二处:
stop_machine-> stop_machine_cpuslocked-> stop_cpus(cpu_online_mask, multi_cpu_stop, &msdata);
该处通过 stop_cpus 函数注册 multi_cpu_stop,并在 multi_cpu_stop 中调用我们通过 stop_machine 等注册的函数。因为执行 multi_cpu_stop 不保证 cpu 是否会离线(热插拔),所以调用 stop_cpus 时需要使用 cpus_read_lock 来保护,确保 cpu 不会离线,因此有 stop_machine_cpuslocked。
该条路径触发 bug。
stop_machine 函数原型:
int stop_machine(cpu_stop_fn_t fn, void *data, const struct cpumask *cpus);fn 为我们需要停机调用的回调;
data 回调使用的数据;
cpus 我们需要在哪些 cpu 上执行 fn;如果为 NULL, 则为任意一个 cpu,默认为 cpumask_first(cpu0)。
stop_machine 调用 stop_machine_cpuslocked 最终会调用 queue_stop_cpus_work 来注册回调,部分代码如下:
int stop_machine_cpuslocked(cpu_stop_fn_t fn, void *data,const struct cpumask *cpus)
{struct multi_stop_data msdata = { // 填充 multi_cpu_stop 中使用的数据结构.fn = fn, // 在 multi_cpu_stop 中调用的回调.data = data, // 回调使用的数据.num_threads = num_online_cpus(), // 当前系统上线的 cpu 数量.active_cpus = cpus, // 要在哪些 cpu 上执行 fn,为 NULL 默认为第一个。};
...
.../* Set the initial state and stop all online cpus. */set_state(&msdata, MULTI_STOP_PREPARE); // 设置 msdata 内部数据结构为 MULTI_STOP_PREPARE,multi_cpu_stop 中状态机的初始状态。return stop_cpus(cpu_online_mask, multi_cpu_stop, &msdata); // stop_cpus 最终调用 queue_stop_cpus_work
}
queue_stop_cpus_work代码如下:
static bool queue_stop_cpus_work(const struct cpumask *cpumask,cpu_stop_fn_t fn, void *arg,struct cpu_stop_done *done)
{struct cpu_stop_work *work;unsigned int cpu;bool queued = false;/** Disable preemption while queueing to avoid getting* preempted by a stopper which might wait for other stoppers* to enter @fn which can lead to deadlock.*/preempt_disable();stop_cpus_in_progress = true;barrier();for_each_cpu(cpu, cpumask) {work = &per_cpu(cpu_stopper.stop_work, cpu);work->fn = fn;work->arg = arg;work->done = done;if (cpu_stop_queue_work(cpu, work))queued = true;}barrier();stop_cpus_in_progress = false;preempt_enable();return queued;
}
在每个 cpu 的 stopper 上挂载 worker,并通过 cpu_stop_queue_work 挂入队列并唤醒迁移线程。
通过这里可知,调用 stop_machine 会使得所有 cpu 均进入停机状态,并在指定的 cpu 上完成回调,现在看看 multi_cpu_stop,代码如下:
/* This is the cpu_stop function which stops the CPU. */
static int multi_cpu_stop(void *data)
{struct multi_stop_data *msdata = data;enum multi_stop_state newstate, curstate = MULTI_STOP_NONE;int cpu = smp_processor_id(), err = 0;unsigned long flags;bool is_active;/** When called from stop_machine_from_inactive_cpu(), irq might* already be disabled. Save the state and restore it on exit.*/local_save_flags(flags); ----------------------------------------------------------(1)if (!msdata->active_cpus) ---------------------------------------------------------(2)is_active = cpu == cpumask_first(cpu_online_mask);elseis_active = cpumask_test_cpu(cpu, msdata->active_cpus);/* Simple state machine */do {/* Chill out and ensure we re-read multi_stop_state. */cpu_relax_yield();newstate = READ_ONCE(msdata->state); if (newstate != curstate) {curstate = newstate;switch (curstate) {case MULTI_STOP_DISABLE_IRQ:local_irq_disable();hard_irq_disable();break;case MULTI_STOP_RUN:if (is_active)err = msdata->fn(msdata->data);break;default:break;}ack_state(msdata);} else if (curstate > MULTI_STOP_PREPARE) {/** At this stage all other CPUs we depend on must spin* in the same loop. Any reason for hard-lockup should* be detected and reported on their side.*/touch_nmi_watchdog();}rcu_momentary_dyntick_idle();} while (curstate != MULTI_STOP_EXIT);local_irq_restore(flags);return err;
}
(1)进入 multi_cpu_stop 后首先会保存当前中断状态,有些调用在进入 multi_cpu_stop 可能会处于禁用中断状态,我们状态机中又会主动禁用中断,所以这里保存一下以便后面恢复 irq 状态。
(2)如果我们在上层传入的是 NULL 那么能够执行回调的 cpu 就是第一个 cpu,否则就是我们指定的 cpumask 的所有 cpu。
接下来是一个循环,循环内部存在一个简易状态机用于同步停机状态:
状态机有如下顺序的状态:
/* This controls the threads on each CPU. */
enum multi_stop_state {/* Dummy starting state for thread. */MULTI_STOP_NONE,/* Awaiting everyone to be scheduled. */MULTI_STOP_PREPARE,/* Disable interrupts. */MULTI_STOP_DISABLE_IRQ,/* Run the function */MULTI_STOP_RUN,/* Exit */MULTI_STOP_EXIT,
};
首先是刚进入循环的初始状态 curstate = MULTI_STOP_NONE,接着通过 READ_ONCE 读取到传入的 msdata->state 的状态,从上面知道传入的状态是 MULTI_STOP_PREPARE。
注意此时 multi_cpu_stop 是在所有 cpu 上执行着相同的操作,所以我们有 cpu_relax_yield READ_ONCE来确保读取到的数据一致和顺序一致。
此时 newstate 不等于 curstate,那么进入 if 字段,该字段根据状态执行不同 switch case,这里现在不会执行任何操作直接 break,并且调用 ack_state。ack_state代码如下:
static void set_state(struct multi_stop_data *msdata,enum multi_stop_state newstate)
{/* Reset ack counter. */atomic_set(&msdata->thread_ack, msdata->num_threads);smp_wmb();WRITE_ONCE(msdata->state, newstate);
}/* Last one to ack a state moves to the next state. */
static void ack_state(struct multi_stop_data *msdata)
{if (atomic_dec_and_test(&msdata->thread_ack))set_state(msdata, msdata->state + 1);
}对 thread_ack 值原子减一,并且判断减一后 thread_ack 是否为 0,为 0 atomic_dec_and_test 返回 true 则执行 set_state。set_state 主要是对 thread_ack 赋值为 num_threads,并且更新 msdata->state 为 newstate。
那么通过之前 stop_machine 知道,num_threads 等于 online_cpusmaks,
所以这里只有当指定的所有 cpu 都调用 ack_state 后 msdata->state 状态才会往前推进,并且将 thread_ack 恢复为 num_threads 开始新一轮状态同步。
接着调用 rcu_momentary_dyntick_idle 来上报一个静默期,因为在 stop_machine 里面,我们就是在经历一个静默期状态。
当返回循环开始时再次通过 READ_ONCE 读取 msdata->state 的状态,那么如果此时还有其他 cpu 没有进入停机状态我们就不会开始下一个状态的执行,而是进入 else if 字段,在这里,可以看到只有当我们状态推进到 MULTI_STOP_PREPARE 时,说明所有 cpu 进入停机状态并且调用了MULTI_STOP_DISABLE_IRQ,此时可以确保中断一定是关闭的,那么我们需要在关中断期间手动复位 watchdog。
同样的只有当所有 cpu 都进入下一个状态时 msdata->state 才会更新到下一个状态,此时状态来到 MULTI_STOP_RUN,这个时候 curstate 肯定和 newstate 不相等,newstate 已经来到 MULTI_STOP_RUN,curstate 还处于MULTI_STOP_DISABLE_IRQ。那么同步到 MULTI_STOP_RUN 时根据 is_active,来判断自己这个 cpu 是否需要执行这个回调,如果为 true 则说明自己需要执行,则调用 fn 回调。不需要调用的则直接 break 出去,去等待进入下一个状态。当在这里所有 cpu 都完成 fn 的调用后,cpu 同步进入 MULTI_STOP_EXIT 状态,一起退出循环,并重新恢复 irq 状态退出 multi_cpu_stop,通过完成量唤醒等待的任务。
从上述状态机可知,如果 cpu 在 MULTI_STOP_PREPARE 同步状态等待时间过久,但是实际这个状态 watchdog不会手动复位,而现在又处于迁移线程中,其他线程是无法被执行的那么就有可能触发 soft lockup,见后面 watchdog 分析。
触发 soft lockup 原因分析(二)
这里简单看看 watchdog 如何触发 soft lockup。
首先是系统支持检测 watchdog 后会在每个 cpu 上启动一个 watchdog 线程,用于监测系统运行,如下:
static struct smp_hotplug_thread watchdog_threads = {.store = &softlockup_watchdog,.thread_should_run = watchdog_should_run,.thread_fn = watchdog,.thread_comm = "watchdog/%u",.setup = watchdog_enable,.cleanup = watchdog_cleanup,.park = watchdog_disable,.unpark = watchdog_enable,
};static void watchdog(unsigned int cpu)
{__this_cpu_write(soft_lockup_hrtimer_cnt,__this_cpu_read(hrtimer_interrupts));__touch_watchdog();
}
watchdog 线程逻辑很简单,首先将本地 cpu 的 hrtimer_interrupts 同步到本地 cpu 的 soft_lockup_hrtimer_cnt 中。
最后是调用 __touch_watchdog,如下:
/* Commands for resetting the watchdog */
static void __touch_watchdog(void)
{__this_cpu_write(watchdog_touch_ts, get_timestamp());
}/** Returns seconds, approximately. We don't need nanosecond* resolution, and we don't need to waste time with a big divide when* 2^30ns == 1.074s.*/
static unsigned long get_timestamp(void)
{return running_clock() >> 30LL; /* 2^30 ~= 10^9 */
}
更新 watchdog_touch_ts 的时间戳,使其与当前时间同步(单位为秒)。
soft_lockup_hrtimer_cnt 的作用主要是判断当前 cpu 的 watchdog 线程是否需要运行:
static int watchdog_should_run(unsigned int cpu)
{return __this_cpu_read(hrtimer_interrupts) !=__this_cpu_read(soft_lockup_hrtimer_cnt);
}
即当 soft_lockup_hrtimer_cnt和 hrtimer_interrupts 不相等时说明 wachdog 定时器执行了,我们需要运行 watchdog 线程来同步两个变量。 hrtimer_interrupts 就是在 watchdog 的定时器中更新的,每触发一次 watchdog 则会调用 watchdog_interrupt_count 来自增 hrtimer_interrupts,如下:
static void watchdog_interrupt_count(void)
{__this_cpu_inc(hrtimer_interrupts);
}
可以看到 watchdog 线程每次运行都调用__touch_watchdog 来同步 watchdog_touch_ts 的时间为当前时间。
下面看一下 watchdog 定时器:
如上面结构体中的 watchdog_enable,当我们配置 smp_hotplug_thread 时会调用 setup 来配置线程,这里调用 watchdog_enable,如下:
static void watchdog_enable(unsigned int cpu)
{struct hrtimer *hrtimer = this_cpu_ptr(&watchdog_hrtimer);/** Start the timer first to prevent the NMI watchdog triggering* before the timer has a chance to fire.*/hrtimer_init(hrtimer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);hrtimer->function = watchdog_timer_fn;hrtimer_start(hrtimer, ns_to_ktime(sample_period),HRTIMER_MODE_REL_PINNED);/* Initialize timestamp */__touch_watchdog();/* Enable the perf event */if (watchdog_enabled & NMI_WATCHDOG_ENABLED)watchdog_nmi_enable(cpu);watchdog_set_prio(SCHED_FIFO, MAX_RT_PRIO - 1);
}
代码中初始化了一个 hrtimer 定时器,定时器执行 watchdog_timer_fn,周期是 sample_period,如下:
static void set_sample_period(void)
{/** convert watchdog_thresh from seconds to ns* the divide by 5 is to give hrtimer several chances (two* or three with the current relation between the soft* and hard thresholds) to increment before the* hardlockup detector generates a warning*/sample_period = get_softlockup_thresh() * ((u64)NSEC_PER_SEC / 5);watchdog_update_hrtimer_threshold(sample_period);
}
这里大约是 20s / 5 左右。
watchdog_timer_fn 定时器函数部分代码如下:
/* watchdog kicker functions */
static enum hrtimer_restart watchdog_timer_fn(struct hrtimer *hrtimer)
{unsigned long touch_ts = __this_cpu_read(watchdog_touch_ts); ---------------------------(1)struct pt_regs *regs = get_irq_regs(); -------------------------------------------------(2)int duration;
...
.../* kick the hardlockup detector */watchdog_interrupt_count(); ------------------------------------------------------------(3)/* kick the softlockup detector */wake_up_process(__this_cpu_read(softlockup_watchdog));/* .. and repeat */hrtimer_forward_now(hrtimer, ns_to_ktime(sample_period)); ------------------------------(4)if (touch_ts == 0) { -------------------------------------------------------------------(5)if (unlikely(__this_cpu_read(softlockup_touch_sync))) {/** If the time stamp was touched atomically* make sure the scheduler tick is up to date.*/__this_cpu_write(softlockup_touch_sync, false);sched_clock_tick();}/* Clear the guest paused flag on watchdog reset */kvm_check_and_clear_guest_paused();__touch_watchdog();return HRTIMER_RESTART;}/* check for a softlockup* This is done by making sure a high priority task is* being scheduled. The task touches the watchdog to* indicate it is getting cpu time. If it hasn't then* this is a good indication some task is hogging the cpu*/duration = is_softlockup(touch_ts); ----------------------------------------------------(6)if (unlikely(duration)) {
...
...pr_emerg("BUG: soft lockup - CPU#%d stuck for %us! [%s:%d]\n",smp_processor_id(), duration,current->comm, task_pid_nr(current));__this_cpu_write(softlockup_task_ptr_saved, current);print_modules();print_irqtrace_events(current);if (regs)show_regs(regs);elsedump_stack();
...
...} else__this_cpu_write(soft_watchdog_warn, false);return HRTIMER_RESTART;
}
(1)获取到watchdog_touch_ts 当前值,这个值会在 watchdog 线程中一直保持更新,或者特定的调用会让这个值为 0,见后文。
(2)获取到当前 cpu 的 regs ,如果存在 regs 说明我们处于中断,ipi 里。
(3)如上所述,这里会自增 hrtimer_interrupts 变量,以便 watchdog_should_run 知道需要运行 watchdog 线程来同步该值并更新 watchdog_touch_ts 以便知道系统正在正常运行,完成自增后会尝试唤醒 watchdog 线程,来进行同步更新。此时如果上次触发定时器的线程没有运行,则watchdog_touch_ts 值不能更新,那么如果滞后当前时间戳太久了,说明当前 cpu 的线程占用 cpu 时间太久了,可能就会报告 soft lockup。
(4)设置下一次 定时器的到期值。
(5)这里会特殊处理 touch_ts等于 0 的情况,下面几个地方会设置 watchdog_touch_ts 为 0:
touch_softlockup_watchdog_synctouch_softlockup_watchdog
...
...-> touch_softlockup_watchdog_schedtouch_all_softlockup_watchdogs
在 stop_machine 中调用的是 touch_nmi_watchdog:
static inline void touch_nmi_watchdog(void)
{arch_touch_nmi_watchdog(); // 对于 x86 和 arm64 为空touch_softlockup_watchdog();
}
也就是说在 stop_machine 中每次循环如果检测到状态没有向前推进则会把 watchdog_touch_ts 设置为 0。
这里设置为 0 我的理解是当手动关中断,并且需要进行耗时操作时,我们手动调用上述 api 来复位 watchdog_touch_ts ,这样即便我们长时间没触发 watchdog 线程的执行,也可以在定时器里检测到这种长时间关中断的状态,并作额外处理,对于现在的情况则是简单的重新将当前时间戳同步到 watchdog_touch_ts ,那么后面 soft lockup 判断时就不会误报。
(6)这里就会去检测是否是触发了 soft lockup,代码如下:
static int is_softlockup(unsigned long touch_ts)
{unsigned long now = get_timestamp();if ((watchdog_enabled & SOFT_WATCHDOG_ENABLED) && watchdog_thresh){/* Warn about unreasonable delays. */if (time_after(now, touch_ts + get_softlockup_thresh()))return now - touch_ts;}return 0;
}
可以看到,如果我们配置了激活 soft watchdog,并且超时阈值 watchdog_thresh 有值,则检测 soft lockup,获取当前时间戳并与 watchdog_touch_ts + watchdog_thresh * 2比较,如果 now 大于了它那么说明由 soft lockup,返回差值(阈值大概 20s)。
综上可以看到,如果 watchdog_touch_ts 没有被 watchdog 线程及时更新,或者没有类似 touch_softlockup_watchdog 的 api 手动复位 watchdog_touch_ts 则会触发 soft lockup。
在 stop_machine 中我们有 touch_nmi_watchdog 来复位watchdog_touch_ts 为什么还会触发 soft lockup 呢?下面看看 Cgroup memory oom killer 相关逻辑。
触发 soft lockup 原因分析(三)
通过 oom killer 的堆栈知道,在 cgroup memory 内存超限时,我们在下述路径触发 soft lockup:
pagefault_out_of_memory-> out_of_memory-> oom_kill_process-> dump_header(dump 期间触发 soft lockup)
dump_header代码如下:
static void dump_header(struct oom_control *oc, struct task_struct *p)
{pr_warn("%s invoked oom-killer: gfp_mask=%#x(%pGg), nodemask=%*pbl, order=%d, oom_score_adj=%hd\n",current->comm, oc->gfp_mask, &oc->gfp_mask,nodemask_pr_args(oc->nodemask), oc->order,current->signal->oom_score_adj);if (!IS_ENABLED(CONFIG_COMPACTION) && oc->order)pr_warn("COMPACTION is disabled!!!\n");cpuset_print_current_mems_allowed();dump_stack();if (is_memcg_oom(oc))mem_cgroup_print_oom_info(oc->memcg, p);else {show_mem(SHOW_MEM_FILTER_NODES, oc->nodemask);if (is_dump_unreclaim_slabs())dump_unreclaimable_slab();}if (sysctl_oom_dump_tasks)dump_tasks(oc->memcg, oc->nodemask);
}
该函数会 dump 出当前任务的内存信息,栈信息,以及对应的 memory cgroup 节点信息,以及所有可以被 kill 的 task。对于 mem_cgroup_print_oom_info 和 dump_tasks 都有大量的遍历动作,并且遍历期间有使用 rcu_read_lock 保护,此时任务是不能被调度走的(该环境 kubepods 节点下任务非常多)。
所以当上述逻辑触发时,如果某个 cpu 上此时执行 stop_machine 相关的 api,则会触发停机操作,并且迁移线程中还会等待同步所有 cpu 进入停机状态才能执行回调。由于本身服务器没有配置支持抢占,加上有 rcu_read_lock 存在,我们线程执行期间是不会触发调度的,那么迁移线程一定会等到 oom_kill_process的线程执行退出后才能被执行,所以当我们停机时 stop_machine 是可能处于长时间等待状态的。如果此时等待位置是 MULTI_STOP_PREPARE 状态则会触发问题。
这个是在本地进行的测试,在 multi_cpu_stop 中将else if (curstate > MULTI_STOP_PREPARE)修改为else if (curstate >= MULTI_STOP_PREPARE)后,本地不再触发 soft lockup。
这样修改的理由是,我不等 cpu 调用了 case MULTI_STOP_DISABLE_IRQ:这条路径后才去手动触发 touch_nmi_watchdog。而是让 cpu 进入停机状态后就开始触发 touch_nmi_watchdog,这样的话,每个 cpu 进入 multi_cpu_stop 只要不能进入下一个状态都会去复位watchdog_touch_ts,因为如果处于 MULTI_STOP_PREPARE 状态长时间挂起时,watchdog 线程无法被执行,无法更新 watchdog_touch_ts,也无法通过 touch_nmi_watchdog 来复位 watchdog,那么就会触发 soft lockup。
该问题目前在最新 linux-6.x 上仍然存在,或许是个潜在问题,不过能够触发上述描述的问题本身系统管理上就已经存在问题了,而因此不应该把该问题抛给内核解决,也或许是类似的因素导致社区目前仍然没有去解决该潜在的问题。
相关文章:

linux stop_machine 停机机制应用及一次触发 soft lockup 分析
文章目录 stop_mchine 引起的 soft lockup触发 soft lockup 原因分析(一):触发 soft lockup 原因分析(二)触发 soft lockup 原因分析(三) stop_mchine 引起的 soft lockup 某次在服务器上某节点…...

ARM 链接器优化功能介绍
消除公共部分组 链接器可以检测节组的多个副本,并丢弃其他副本。 Arm Compiler for Embedded 生成用于链接的完整对象。因此: 如果 C 和 C 源代码中存在内联函数,则每个对象都包含该对象所需的内联函数的外联副本。如果在 C 源代码中使用…...

动手学深度学习之卷积神经网络之池化层
池化层 卷积层对位置太敏感了,可能一点点变化就会导致输出的变化,这时候就需要池化层了,池化层的主要作用就是缓解卷积层对位置的敏感性 二维最大池化 这里有一个窗口,来滑动,每次我们将窗口中最大的值给拿出来 还是上…...
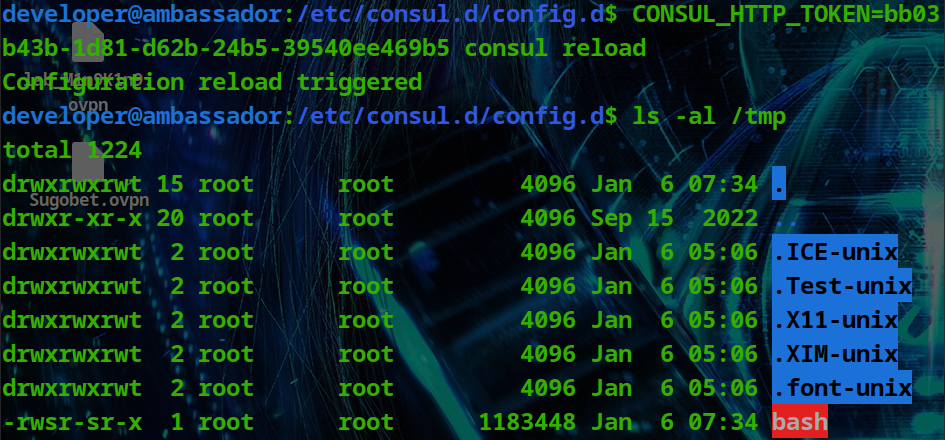
HackTheBox - Medium - Linux - Ambassador
Ambassador Ambassador 是一台中等难度的 Linux 机器,用于解决硬编码的明文凭据留在旧版本代码中的问题。首先,“Grafana”CVE (“CVE-2021-43798”) 用于读取目标上的任意文件。在研究了服务的常见配置方式后,将在其…...
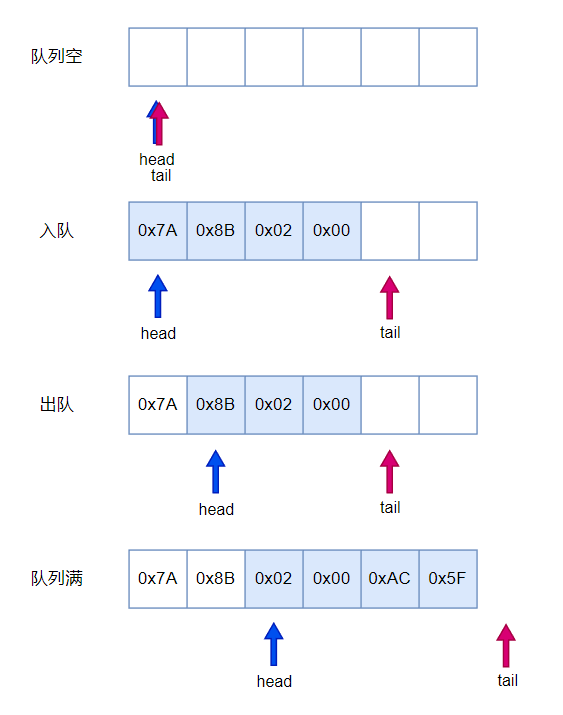
嵌入式——循环队列
循环队列 (Circular Queue) 是一种数据结构(或称环形队列、圆形队列)。它类似于普通队列,但是在循环队列中,当队列尾部到达数组的末尾时,它会从数组的开头重新开始。这种数据结构通常用于需要固定大小的队列,例如计算机内存中的缓冲区。循环队列可以通过数组或链表实现,…...

2024.1.7-实战-docker方式给自己网站部署prometheus监控ecs资源使用情况-2024.1.7(测试成功)
实战-docker方式给自己网站部署prometheus监控ecs资源使用情况-2024.1.7(测试成功) 目录 最终效果 原文链接 https://onedayxyy.cn/docs/prometheus-grafana-ecs 参考模板 https://i4t.com/ https://grafana.frps.cn 🔰 额,注意哦: 他这个是通过frp来…...

20240107 SQL基础50题打卡
20240107 SQL基础50题打卡 1978. 上级经理已离职的公司员工 表: Employees ----------------------- | Column Name | Type | ----------------------- | employee_id | int | | name | varchar | | manager_id | int | | salary | int | -…...

阿里云公网带宽出网和入网是什么?上行和下行是什么?
什么是阿里云服务器ECS的入网带宽和出网带宽?以云服务器为中心,流入云服务器占用的带宽是入网带宽,流量从云服务器流出的带宽是出网带宽。阿里云服务器网aliyunfuwuqi.com分享入网带宽和出网带宽说明表: 带宽类别说明入网带宽&am…...

eureka工作原理是什么
EUREKA 是一个基于 RESTful 风格的服务发现系统,它主要用于帮助实现在微服务架构中的服务自动发现与注册。其工作原理主要包括以下几个步骤: 注册中心:EUREKA 中有一个集中的注册中心,所有的服务都将在此注册和发现。注册中心可以…...
使用方法介绍)
Vue中的事件委托(事件代理)使用方法介绍
事件委托(事件代理) 将原本需要绑定在子元素上的事件监听器委托在父元素上,让父元素充当事件监听的职务。 事件委托是一种利用事件冒泡的特性,在父节点上响应事件,而不是在子节点上响应事件的技术。它能够改善性能&a…...

「HDLBits题解」Wire decl
本专栏的目的是分享可以通过HDLBits仿真的Verilog代码 以提供参考 各位可同时参考我的代码和官方题解代码 或许会有所收益 题目链接:Wire decl - HDLBits default_nettype none module top_module(input a,input b,input c,input d,output out,output out_n ); w…...
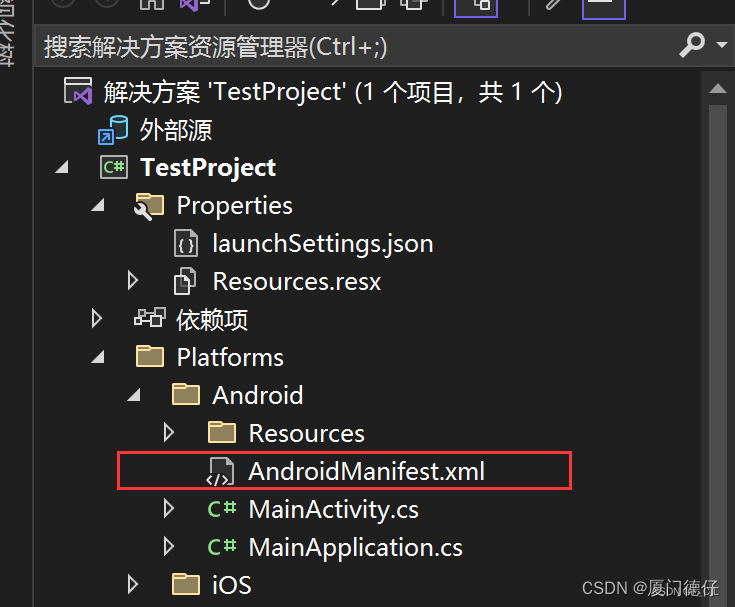
[MAUI]在.NET MAUI中调用拨号界面
在.NET MAUI中调用拨号界面 前置要求: Visual Studio 2022 安装包“.NET Multi-platform App UI 开发” 参考文档: 电话拨号程序 新建一个MAUI项目 在解决方案资源管理器窗口中找到Platforms/Android/AndroidManifest.xml在AndroidManifest.xml中添加下文中…块如下:<?xml…...

Kali/Debian Linux 安装Docker Engine
0x01 卸载旧版本 在安装Docker Engine之前,需要卸载已经安装的可能有冲突的软件包。一些维护者在他们的仓库提供的Docker包可能是非Docker官方发行版,须先卸载这些软件包,然后才能安装Docker官方正式发行的Docker Engine版本。 要卸载的软件…...
:峰回路转,柳暗花明 | 京东云技术团队)
Spring 应用合并之路(二):峰回路转,柳暗花明 | 京东云技术团队
书接上文,前面在 [Spring 应用合并之路(一):摸石头过河]介绍了几种不成功的经验,下面继续折腾… 四、仓库合并,独立容器 在经历了上面的尝试,在同事为啥不搞两个独立的容器提醒下,…...

SQL Error 1366, SQLState HY000
SQL错误 1366 和 SQLState HY000 通常指的是 MySQL 与字符编码或数据截断有关的问题。当尝试将数据插入具有与正在插入的数据不兼容的字符集或排序规则的列时,或者正在插入的数据对于列来说过长时,就会出现此错误。 解决方式: 检查列长度&am…...
(VP-7,寒假加训))
Codeforces Round 893 (Div. 2)(VP-7,寒假加训)
VP时间 A. 关键在于按c的按钮 c&1 Alice可以多按一次c按钮 也就是a多一个(a) 之后比较a,b大小即可 !(c&1) Alice Bob操作c按钮次数一样 1.ac B.贪心 一开始会吃饼干 如果有卖饼的就吃 如果隔离一段时间到d没吃就吃(当时…...
MySQL第四战:视图以及常见面试题(上)
目录 目录: 一.视图 1.介绍什么是视图 2.视图的语法 语法讲解 实例操作 二.MySQL面试题 1.SQL脚本 2.面试题实战 三.思维导图 目录: 随着数字化时代的飞速发展,数据库技术,特别是MySQL,已经成为IT领域中不可…...
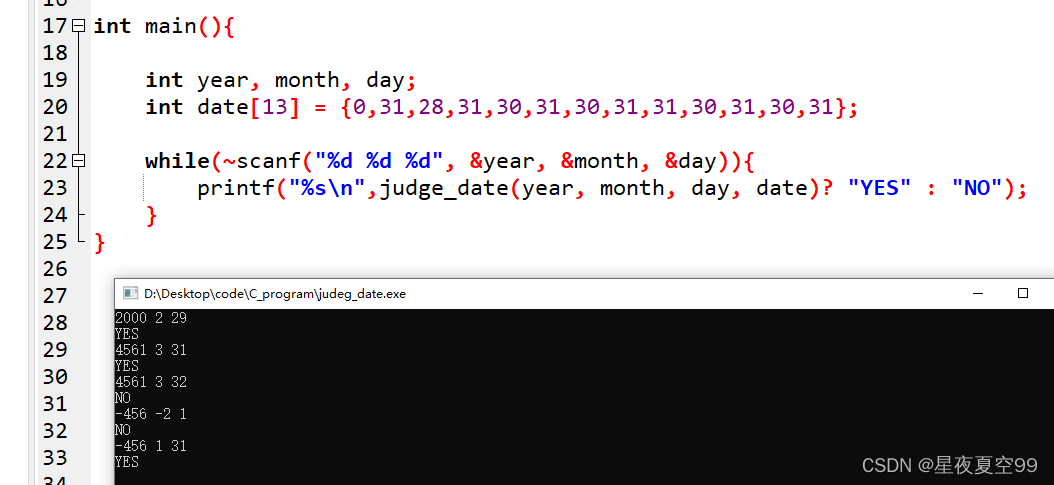
C语言程序设计——程序流程控制方法(一)
C语言关系运算符 ---等于ab!不等于a!b<、>小于和大于a>b 、a<b<、>小于等于、大于等于a>b 、a<b!非!(0)、!(NULL) 在C99之后,C语言开始支持布尔类型,头文件是stdbool.h。在文中我所演示的所有代码均是C99版。 在C语言上上述关…...

torch.backends.cudnn.benchmark
torch.backends.cudnn.benchmark 的设置对于使用 PyTorch 进行深度学习训练的性能优化至关重要。具体而言,它与 NVIDIA 的 CuDNN(CUDA Deep Neural Network library)库有关,该库是在 GPU 上加速深度神经网络计算的核心组件。 启用…...
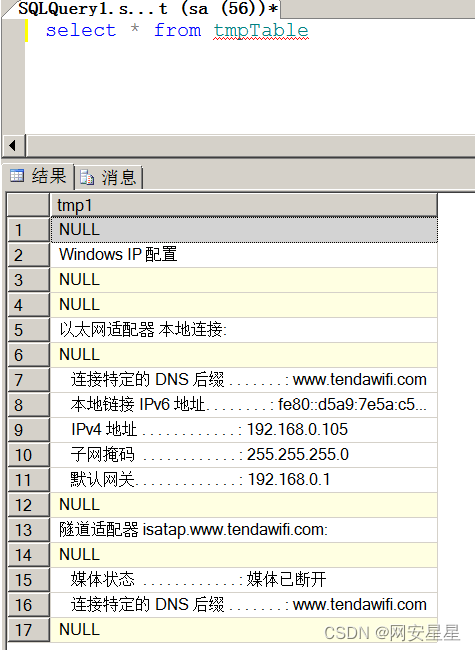
SQL Server从0到1——写shell
xp_cmdshell 查看能否使用xpcmd_shell; select count(*) from master.dbo.sysobjects where xtype x and name xp_cmdshell 直接使用xpcmd_shell执行命令: EXEC master.dbo.xp_cmdshell whoami 发现居然无法使用 查看是否存在xp_cmdshell: EXEC…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...
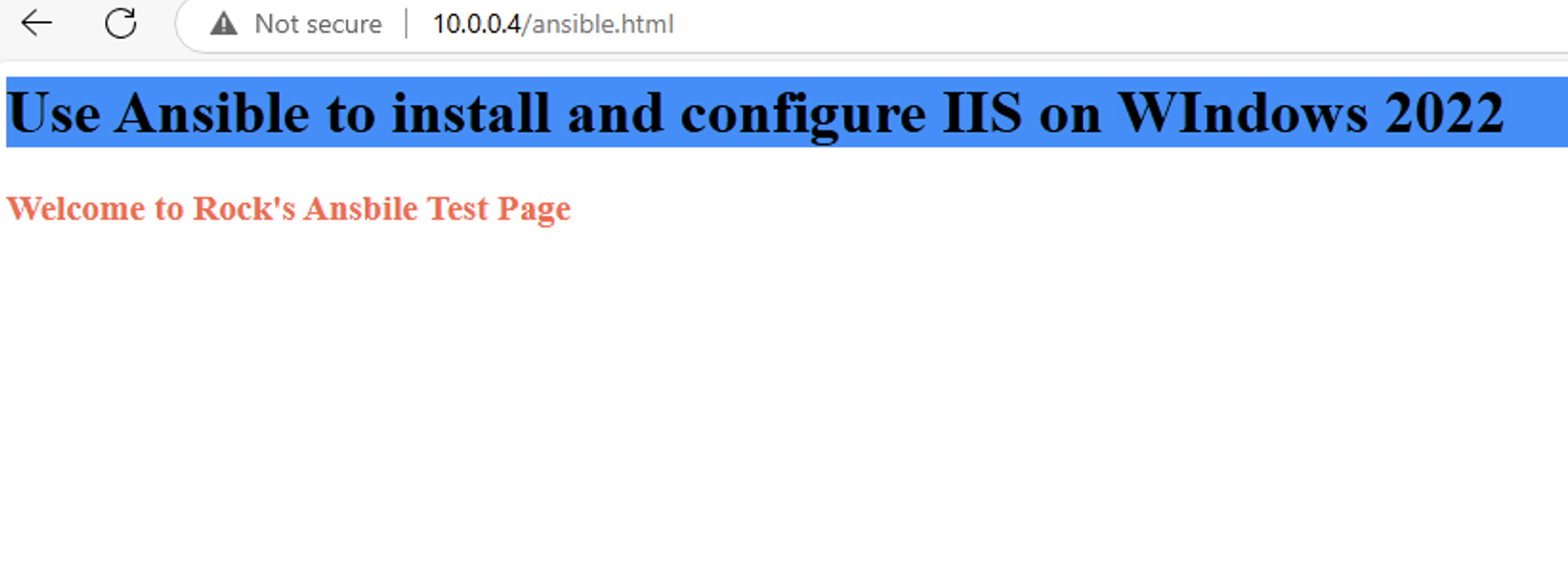
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...
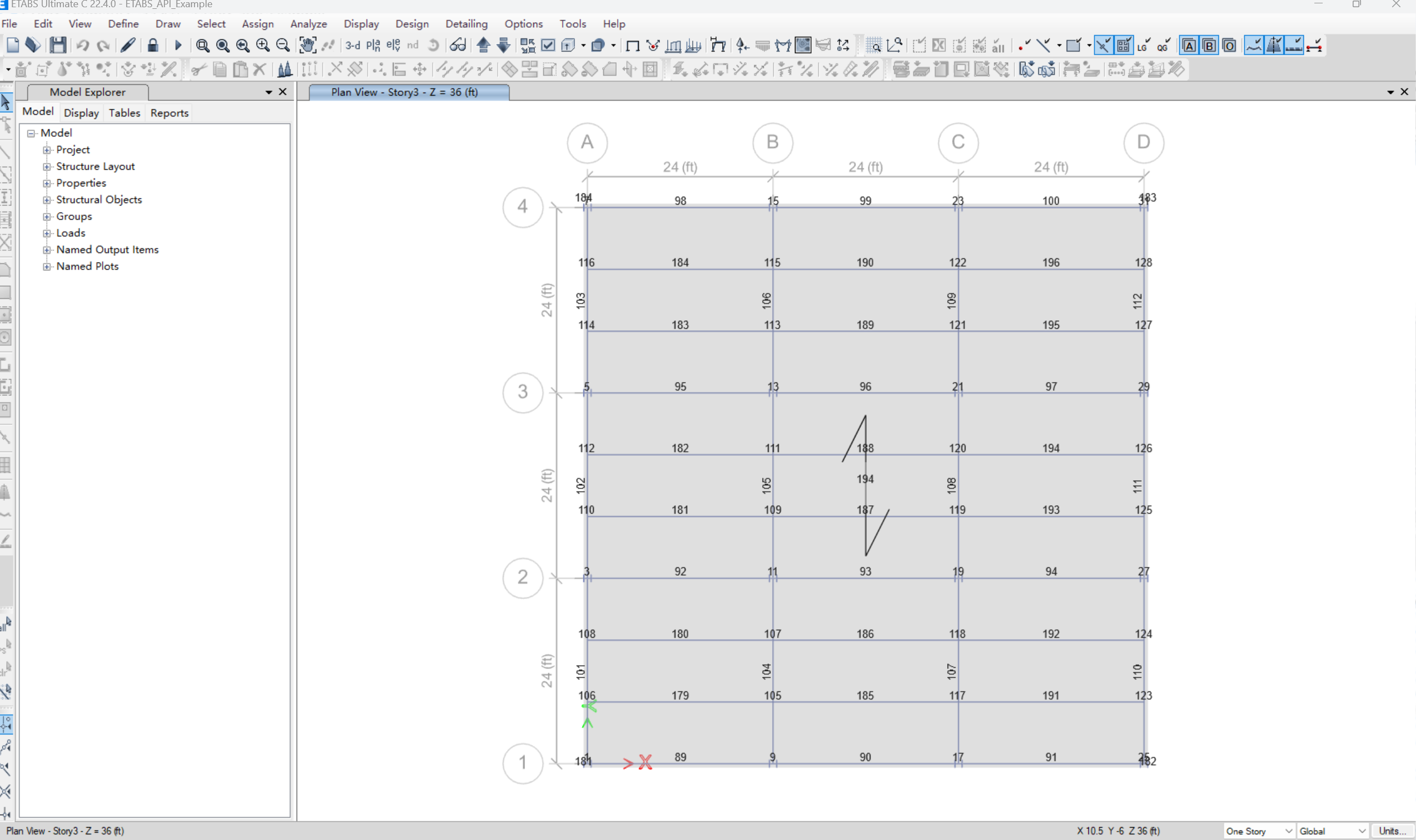
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...