KNN 回归
K 近邻回归(K-Nearest Neighbors Regression)是一种基于实例的回归算法,用于预测连续数值型的输出变量。它的基本思想是通过找到与给定测试样本最近的 K 个训练样本,并使用它们的输出值来预测测试样本的输出。它与 K 最近邻分类类似,但是用于解决回归问题而不是分类问题。
K 近邻回归算法的基本步骤:
- 数据准备:首先,我们需要准备训练集和测试集的特征数据和对应的目标变量。特征数据可以包括数值型、分类型或二元型的特征。目标变量是我们要预测的连续数值。
- 选择 K 值和距离度量方法:K 值是指选择的最近邻居的数量,通常通过交叉验证等方法来选择最优的 K 值。距离度量方法用于计算样本之间的距离,常见的方法有欧氏距离、曼哈顿距离等。
- 计算距离:对于给定的测试样本,我们计算它与训练集中所有样本的距离。距离的计算方法取决于选择的距离度量方法。
- 选择最近的 K 个邻居:根据距离的计算结果,选择与测试样本最近的 K 个训练样本作为邻居。可以使用排序算法(如快速排序)来加快寻找最近邻居的过程。
- 预测输出:对于回归问题,根据这 K 个邻居的输出值,可以采用平均值或加权平均值作为预测输出。通常,距离较近的邻居会被赋予更高的权重。
- 模型评估:使用回归评估指标(如均方误差、平均绝对误差等)来评估模型的性能。可以使用交叉验证等方法来获取更准确的模型评估结果。
需要注意的是,K 值的选择对算法的性能有重要影响。较小的 K 值会导致模型过拟合,而较大的 K 值可能会导致模型欠拟合。因此,通常需要通过交叉验证等方法来选择最优的 K 值。
K 近邻回归算法的基本思想就是,在给定一个新的数据点,它的输出值由其 K 个最近邻数据点的输出值的平均值(或加权平均值)来预测。
简单地说,KNN 回归使用多个近邻(即 k > 1)时,预测结果为这些邻居的对应目标值的平均值。
KNN 回归也可以用 score 方法进行模型评估,返回的是 R 2 R^2 R2 分数。 R 2 R^2 R2(R-squared)分数也叫做决定系数,是用来评估模型拟合优度的指标,它表示因变量的方差能够被自变量解释的比例。 R 2 R^2 R2 的取值范围在 0 到 1 之间,越接近 1 表示模型对数据的拟合越好,即模型能够解释更多的因变量的方差。当 R 2 R^2 R2 接近 0 时,说明模型无法解释因变量的方差,拟合效果较差。简单地说, R 2 = 1 R^2 = 1 R2=1 对应完美预测, R 2 = 0 R^2 = 0 R2=0 对应常数模型,即总是预测训练集响应(y_train)的平均值。
R 2 = 1 − ( S S R / S S T ) = 1 − ∑ i = 1 n ( y i − y i ′ ) 2 ∑ i = 1 n ( y i − y m e a n ) 2 R^2 = 1 - (SSR / SST) = 1 - \frac{\displaystyle\sum_{i=1}^{n}(y_i - y'_i)^2}{\displaystyle\sum_{i=1}^{n}(y_i - y_{mean})^2} R2=1−(SSR/SST)=1−i=1∑n(yi−ymean)2i=1∑n(yi−yi′)2
其中, y y y 为实际观测值, y ′ y' y′ 为预测值, y m e a n y_{mean} ymean 为实际观测值的均值。
SSR 与 SST:
- SSR(Sum of Squares Residual)为残差平方和,表示模型预测值与实际观测值之间的差异。
- SST(Total Sum of Squares)为总平方和,表示实际观测值的方差。
一般来说,KNN 分类器有 2 个重要参数:邻居个数以及数据点之间距离的度量方法。在实践中,使用较小的邻居个数(比如 3 个或 5 个)往往可以得到较好的结果,但在不同问题中应根据具体情况调节这个参数。数据点之间的距离度量方法默认使用欧式距离,它在许多情况下的效果都很好。
如果训练集很大(特征数很多或样本数很大),KNN 模型的预测速度可能会比较慢。
使用 KNN 算法时,对数据进行预处理是很重要的。
这一算法对于有很多特征(几百或更多)的数据集往往效果不好,对于大多数特征的大多数取值都为 0 的数据集(所谓的稀疏数据集)来说,这一算法的效果尤其不好。
在 sklearn 中调用 KNN 回归模型:
from sklearn.neighbors import KNeighborsRegressorreg = KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train, y_train)
y_pred = reg.predict(X_new)
相关文章:

KNN 回归
K 近邻回归(K-Nearest Neighbors Regression)是一种基于实例的回归算法,用于预测连续数值型的输出变量。它的基本思想是通过找到与给定测试样本最近的 K 个训练样本,并使用它们的输出值来预测测试样本的输出。它与 K 最近邻分类类…...
Kali Linux——获取root权限
目录 一、设置root密码 【操作命令】 【操作实例】 二、临时获取root权限 【操作命令】 【操作实例】 三、提升用户到root 1、获取root权限 2、进入/etc/passwd 3、查看root账号ID 4、找到需要修改的用户 5、输入i,进入编辑模式 6、把用户的ID改成跟r…...

听GPT 讲Rust源代码--compiler(28)
File: rust/compiler/rustc_codegen_llvm/src/llvm/mod.rs 文件rust/compiler/rustc_codegen_llvm/src/llvm/mod.rs是Rust编译器的LLVM代码生成模块的一个文件。该文件定义了一些用于与LLVM交互的结构体、枚举和常量。 此文件的主要作用是: 定义编译器和LLVM之间的接…...

Debezium日常分享系列之:Debezium2.5版本之connector for JDBC
Debezium日常分享系列之:Debezium2.5版本之connector for JDBC 一、概述二、JDBC 连接器的工作原理三、使用复杂的 Debezium 变更事件四、至少一次交付五、多项任务六、数据和列类型映射七、主键处理八、删除模式九、幂等写入十、Schema evolution十一、引用和区分大…...
爬虫网易易盾滑块案例:某乎
声明: 该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关 一、滑块初步分析 js运行 atob(‘aHR0cHM6Ly93d3cuemhpaHUuY29tL3NpZ25pbg’) 拿到网址,浏览器打开网站࿰…...
机器学习笔记 - 偏最小二乘回归 (PLSR)
一、偏最小二乘回归:简介 PLS 方法构成了一个非常大的方法族。虽然回归方法可能是最流行的 PLS 技术,但它绝不是唯一的一种。即使在 PLSR 中,也有多种不同的算法可以获得解决方案。PLS 回归主要由斯堪的纳维亚化学计量学家 Svante Wold 和 Harald Martens 在 20 世纪 80 年代…...
【HTML5】第1章 HTML5入门
学习目标 了解网页基本概念,能够说出网页的构成以及网页相关名词的含义 熟悉Web标准,能够归纳Web标准的构成。 了解浏览器,能够说出各主流浏览器的特点。 了解HTML5技术,能够知道HTML5发展历程、优势以及浏览器对HTML5的支持情…...

dyld: Library not loaded: /usr/lib/swift/libswiftCoreGraphics.dylib
更新Xcode14后低版本iPhone调试报错 dyld: Library not loaded: /usr/lib/swift/libswiftCoreGraphics.dylib Referenced from: /var/containers/Bundle/Application/…/….app/… Reason: image not found 这是缺少libswiftCoreGraphics库 直接导入libswiftCoreGraphics库即…...

React Hooks中useState的介绍,并封装为useSetState函数的使用
useState 允许我们定义状态变量,并确保当这些状态变量的值发生变化时,页面会重新渲染。 useState 返回值 const [state, setState] useState(initialState);useState 返回一个长度为 2 的数组。通常,我们这样定义状态变量: co…...
)
5 个最适合SEI 网络空投交易等操作的钱包(Bitget Wallet,Coin98等)
大家好!Sei 网络比 SOL 快 5 倍,手续费低,还能防止前台交易。好了,我不会占用大家太多时间,让我们直奔主题吧。 Sei 官方:推特(twitter.com/SeiNetwork) 如上图所示,目前…...
.net8 AOT编绎-跨平台调用C#类库的新方法-函数导出
VB.NET AOT无法编绎DLL,微软的无能,正是你的机会 .net8 AOT编绎-跨平台调用C#类库的新方法-函数导出 1,C#命令行创建工程:dotnet new classlib -o CSharpDllExport 2,编写一个静态方法,并且为它打上UnmanagedCallersO…...

第三十八周周报:文献阅读 +BILSTM+GRU+Seq2seq
目录 摘要 Abstract 文献阅读:耦合时间和非时间序列模型模拟城市洪涝区洪水深度 现有问题 提出方法 创新点 XGBoost和LSTM耦合模型 XGBoost算法 编辑 LSTM(长短期记忆网络) 耦合模型 研究实验 数据集 评估指标 研究目的 洪…...

天津最新web前端培训班 如何提升web技能?
随着互联网的迅猛发展,web前端成为了一个热门的职业方向。越来越多的人希望能够通过学习web前端技术来提升自己的就业竞争力。为了满足市场的需求,许多培训机构纷纷推出了web前端培训课程。 什么是WEB前端 web前端就是web给用户展示的东西,…...

Linux下QT生成的(.o)、(.a)、(.so)、(.so.1)、(.so.1.0)、(.so.1.0.0)之间的区别
记录一下遇到的问题:Linux系统下Qt编译第三方动态库会生成多个.so文件,不了解的小伙伴可能很疑惑: (1)Linux 下 QT 生成的(.o)、(.a)和(.so)三个文…...

线性代数 --- 为什么LU分解中L矩阵的行列式一定等于正负1?
以下是关于下三角矩阵L的行列式一定等于-1的一些说明 笔者的一些话(写在最前面): 这是一篇小文,是我写的关于求解矩阵行列式的一篇文章中的一部分。之所以把这一段专门提溜出来,是因为这一段相对于原文是可以完全独立的,也是因为我…...
Redisson 源码解析 - 分布式锁实现过程
一、Redisson 分布式锁源码解析 Redisson是架设在Redis基础上的一个Java驻内存数据网格。在基于NIO的Netty框架上,充分的利用了Redis键值数据库提供的一系列优势,在Java实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常…...
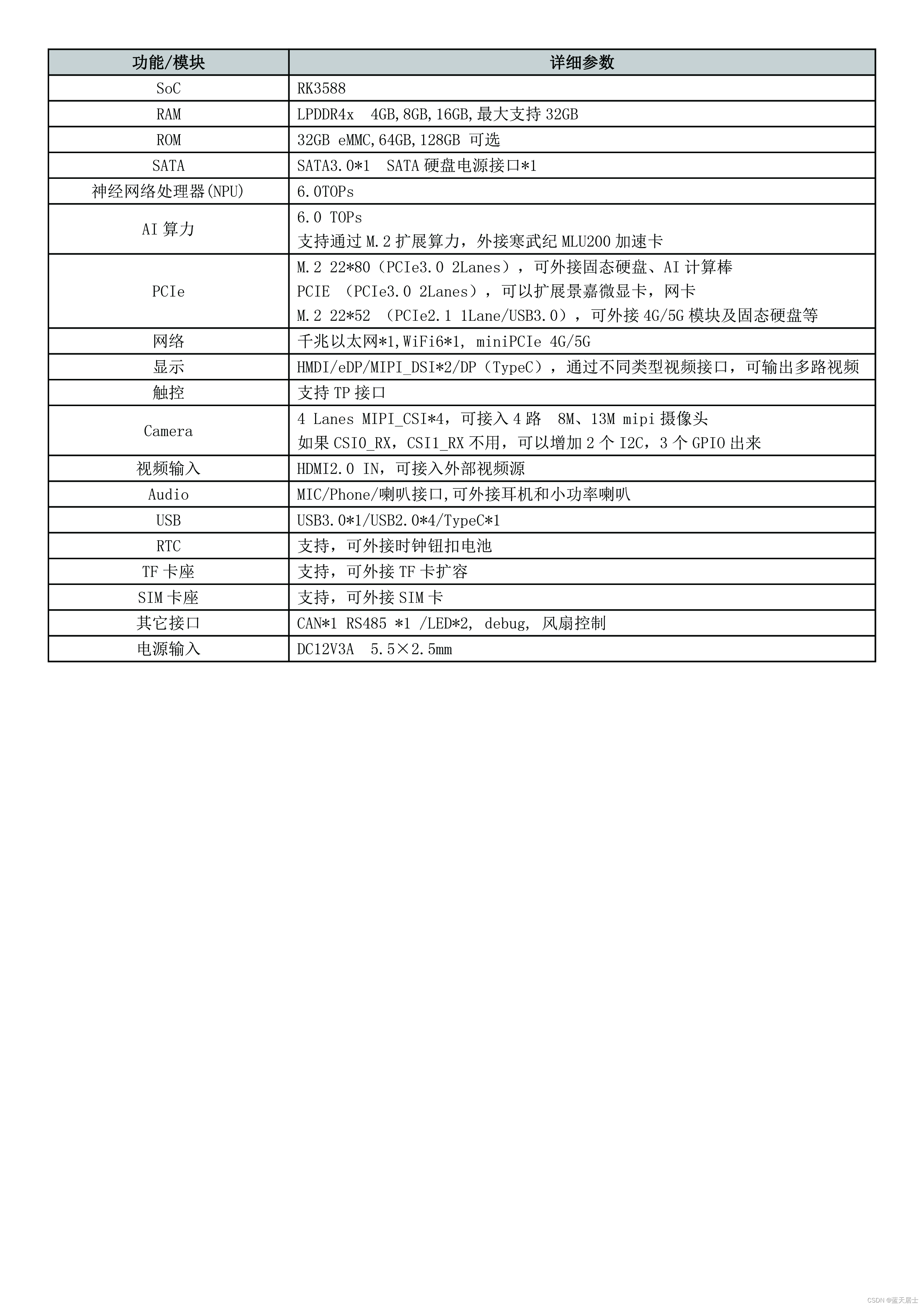
玩转贝启科技BQ3588C开源鸿蒙系统开发板 —— 开发板详情与规格
本文主要参考: BQ3588C_开发板详情-开源鸿蒙技术交流-Bearkey-开源社区 BQ3588C_开发板规格-开源鸿蒙技术交流-Bearkey-开源社区 厦门贝启科技有限公司-Bearkey-官网 1. 开发板详情 RK3588 核心板是一款由贝启科技自主研发的基于瑞芯微 RK3588 AI 芯片的智能核心…...
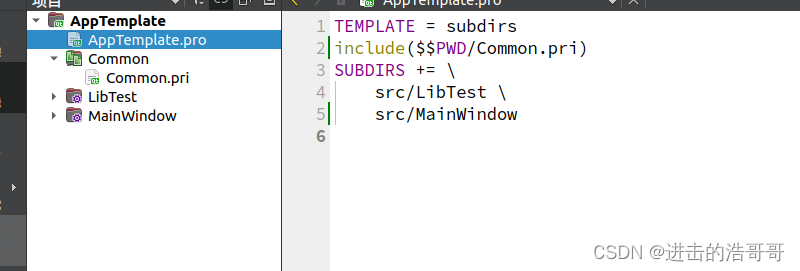
Qt pro文件
1. 项目通常结构 2.pri文件 pri文件可定义通用的宏,例如创建一个COMMON.pri文件内容为 COMMON_PATH D:\MyData 然后其它pri或者pro文件如APPTemplate.pro文件中通过添加include(Common.pri) ,QtCreator就会自动在项目结构树里面创建对应的节点 3.变量…...
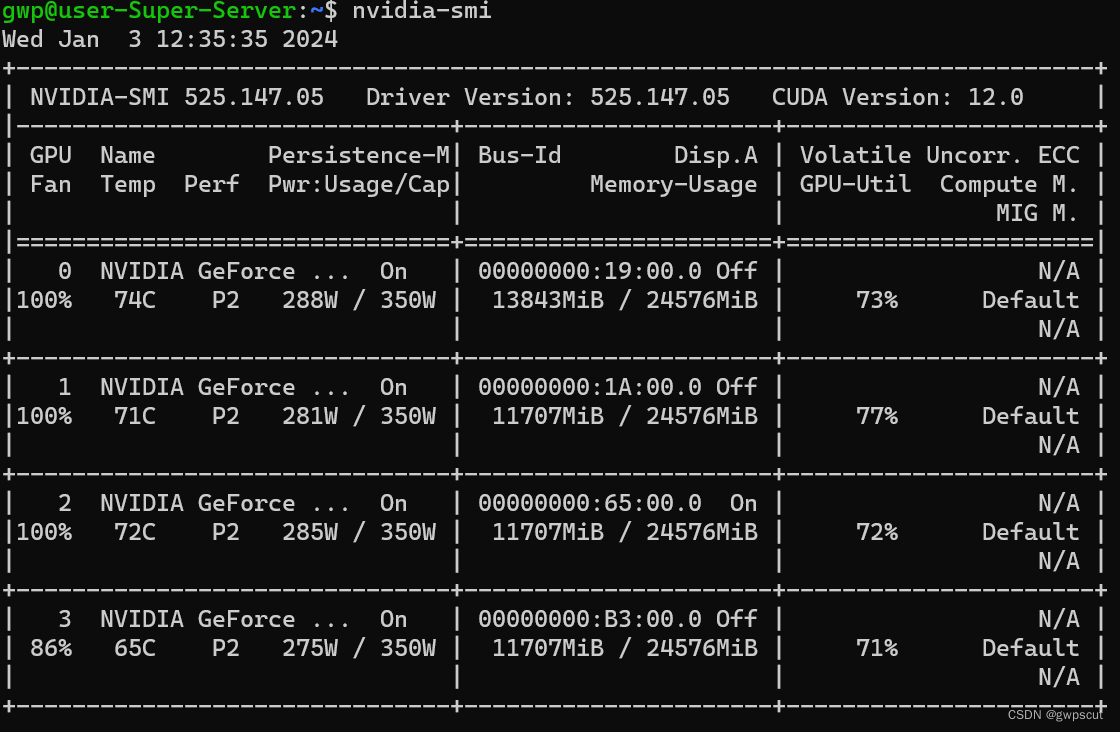
实验笔记之——服务器链接
最近需要做NeRF相关的开发,需要用到GPU,本博文记录本人配置服务器远程链接的过程,本博文仅供本人学习记录用~ 连上服务器 首先先确保环境是HKU的网络环境(HKU AnyConnect也可)。伙伴已经帮忙创建好用户(第一次登录会提示重新设置密码)。用cmd ssh链接ssh -p 60001 <u…...
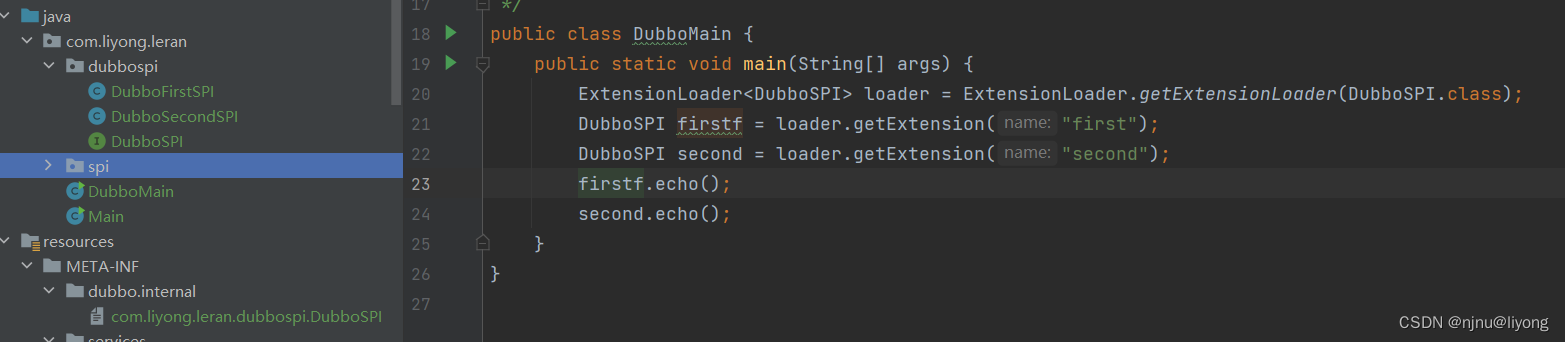
微服务-java spi 与 dubbo spi
Java SPI 通过一个案例来看SPI public interface DemoSPI {void echo(); } public class FirstImpl implements DemoSPI{Overridepublic void echo() {System.out.println("first echo");} } public class SecondImpl implements DemoSPI{Overridepublic void ech…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...
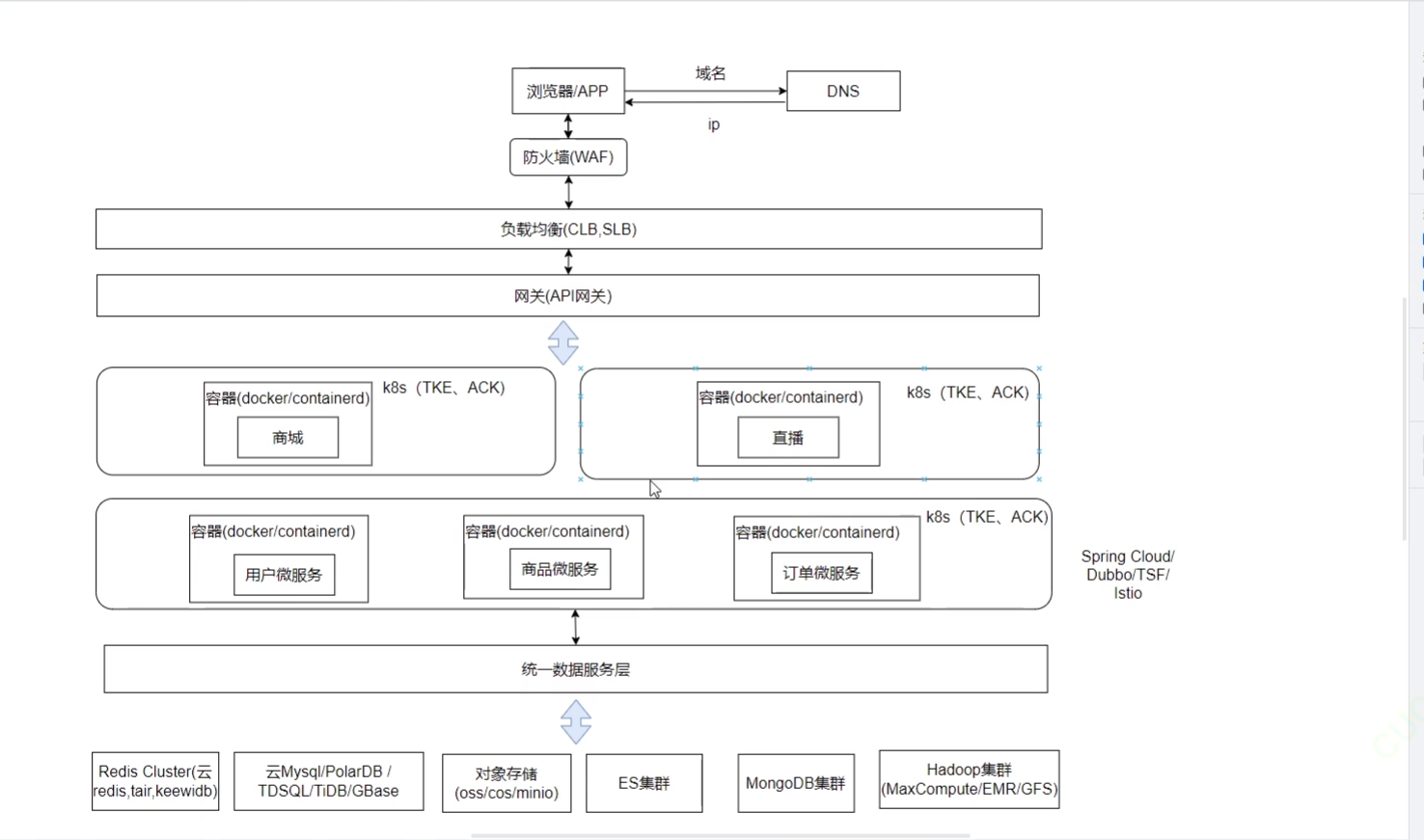
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...