【论文阅读】Variational Graph Auto-Encoder
0、基本信息
- 会议:2016-NIPS
- 作者:Thomas N. Kipf,Max Welling
- 文章链接:Variational Graph Auto-Encoder
- 代码链接:Variational Graph Auto-Encoder
1、介绍
本文提出一个变分图自编码器,一个基于变分自编码(VAE)的,用于在图结构数据上无监督学习的框架。其基本思路是:用已知的图(graph)经过编码(图卷积)学到节点向量表示的分布,在分布中采样得到节点的向量表示,然后进行解码(链接预测)重新构建图。
2、创新点
- 将变分自编码器(VAE)迁移到图领域
3、准备工作
3.1、自编码器(AE)
自编码器由两个部分组成,分别是编码器和解码器,其中编码器通过神经网络,得到原始数据的低维向量表示;解码器也通过神经网络,将低维向量表示还原为原始数据。
下图是自编码器的一个例子:
![[AE.png]]
自编码器的训练目标是最小化重建误差,即使输入和输出保持尽量一致。
3.2、变分自编码器
如果将解码器看做一个生成模型,我们只要有低维向量表示,就可以用这个生成模型得到近似真实的样本。但是,这样的生成模型存在一个问题:低维向量表示必须是由真实样本通过编码器得到的,否则随机产生的低维向量表示通过生成模型几乎不可能得到近似真实的样本。
那么,如果能将低维向量表示约束在一个分布(比如正态分布)中,那么从该分布中随机采样,产生的低维向量表示通过生成模型不是就能产生近似真实的样本了吗?
变分自编码器就是这样的一种自编码器:变分自编码器通过编码器学到的不是样本的低维向量表示,而是低维向量表示的分布。假设这个分布服从正态分布,然后在低维向量表示的分布中采样得到低维向量表示,接下来经过解码器还原出原始样本。
变分自编码器将真实样本 X X X输入变分图自编码器,通过编码器学到每个样本对应的低维向量表示的均值 μ \mu μ和方差 σ 2 \sigma^2 σ2,然后再 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2)中采样出变量的表征,再通过解码器(生成器)生成样本 X ^ \hat{X} X^。均值描述了概率分布的期望值,而标准差描述了概率分布的广度。
3.3、图自编码器(GAE)
图自编码器,即Graph Auto-Encoders,简写GAE。图自编码器也由两部分组成,编码器和解码器。
(1)编码器
GAE的编码器是一个简单的两层GCN模型:
Z = G C N ( A , X ) \mathrm{Z} = \mathrm{GCN}\mathrm(A,\mathrm{X}) Z=GCN(A,X)
更具体一些,两层的GCN在论文中定义如下:
G C N ( A , X ) = A ~ R e L U ( A ^ X W 0 ) W 1 \mathrm{GCN(A,X)}=\tilde{A}\mathrm{ReLU(\hat{A}\mathrm{X}\mathrm{W^0})W^1} GCN(A,X)=A~ReLU(A^XW0)W1
其中, A ~ = D − 1 2 A D − 1 2 \tilde{A}=D^{-\frac{1}{2}}AD^{-\frac{1}{2}} A~=D−21AD−21,即对称归一化邻接矩阵, W 1 W^1 W1和 W 0 W^0 W0是GCN需要学习的参数。
通过编码器,我们可以得到结点的嵌入向量 Z Z Z.
(2)解码器
编码器得到节点表示的向量后,通过解码器通过向量的内积来重构邻接矩阵:
A ^ = σ ( Z Z T ) \hat{A} = \sigma{(ZZ^T)} A^=σ(ZZT)
在GAE中,我们需要优化编码器中的 W 0 W^0 W0和 W 1 W^1 W1进而使得经解码器重构出的邻接矩阵 A ^ \hat{A} A^ 与原始的邻接矩阵A尽量相似。因为邻居矩阵决定了图的结构,经节点向量表示重构出的邻接矩阵与原始邻接矩阵越相似,说明节点的向量表示越符合图的结构。因此,GAE中的损失函数可以定义如下:
L = − 1 N ∑ ( y l o g ( y ^ ) + ( 1 − y ) l o g ( 1 − y ^ ) ) \mathcal{L}=-\frac{1}{N}\sum (ylog(\hat{y})+(1-y)log(1-\hat{y})) L=−N1∑(ylog(y^)+(1−y)log(1−y^))
这里 y y y表示原始邻接矩阵A中的元素,其值为0或1; y ^ \hat{y} y^ 为重构的邻接矩阵 A ^ \hat{A} A^中的元素。从上述损失函数可以看出,损失函数的本质就是两个交叉熵损失函数之和。
当然,我们可以对原始论文中的GAE进行扩展,例如编码器可以使用其他的GNN模型。
2.4、KL散度(又叫相对熵):
如果我们对于同一个随机变量 x有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。其公式定义如下:
K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) q ( x i ) ) KL(p||q)=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)}) KL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))
从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。
4、变分图自编码器(VGAE)
变分图自编码器也有两部分组成,分别是推理模型(编码器)和生成模型(解码器)。
4.1、推理模型
在GAE中,可训练的参数只有 W 0 W^0 W0 和 W 1 W^1 W1 ,训练结束后只要输入邻接矩阵 A A A和节点特征矩阵 X X X,就能得到节点的向量表征 Z Z Z。
与GAE不同,在变分图自编码器VGAE中,节点表征 Z Z Z不是由一个确定的GCN得到,而是从一个多维高斯分布中采样得到。
多维高斯分布的均值和方差由两个GCN确定:
μ = G C N μ ( X , A ) \mu=\mathrm{GCN}_\mu(\mathrm{X,A}) μ=GCNμ(X,A)
以及
l o g σ = G C N σ ( X , A ) log \;\sigma = \mathrm{GCN}_\sigma(\mathrm{X,A}) logσ=GCNσ(X,A)
论文中,这两个不同的GCN都是两层,并且第一层的参数 W 0 W^0 W0是共享的。
有了均值和方差后,我们就能唯一地确定一个多维高斯分布,然后从中进行采样以得到节点的向量表示 Z Z Z,也就是说,向量表征的后验概率分布为:
q ( Z ∣ X , A ) = ∏ i = 1 N q ( z i ∣ X , A ) , q(\mathbf{Z}|\mathbf{X},\mathbf{A})=\prod_{i=1}^Nq(\mathbf{z}_i|\mathbf{X},\mathbf{A}), q(Z∣X,A)=i=1∏Nq(zi∣X,A),
其中,
q ( z i ∣ X , A ) = N ( z i ∣ μ i , diag ( σ i 2 ) ) q(\mathbf{z}_i|\mathbf{X},\mathbf{A})=\mathcal{N}(\mathbf{z}_i|\boldsymbol{\mu}_i,\operatorname{diag}(\boldsymbol{\sigma}_i^2)) q(zi∣X,A)=N(zi∣μi,diag(σi2))
其中 和 μ i \mu_i μi和 σ i 2 \sigma^2_i σi2分别表示节点向量的均值和方差。也就是说,通过两个GCN我们得到了所有节点向量的均值和方差,然后再从中采样形成节点向量。具体来讲,编码器得到多维高斯分布的均值向量和协方差矩阵后,我们就可以通过采样来得到节点的向量表示,但是,采样操作无法提供梯度信息,这对神经网络来讲是没有意义的,因此作者做了重采样:
z = μ + ϵ σ \mathrm{z=\mu+\epsilon\sigma} z=μ+ϵσ
这里 ϵ \epsilon ϵ服从 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1),也就是标准高斯分布,因为 ϵ \epsilon ϵ服从标准高斯分布,所以 μ + ϵ σ \mu+\epsilon \sigma μ+ϵσ服从 N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma^2) N(μ,σ2).
反复从训练集中抽取样本,并对每个样本重新拟合感兴趣的模型,以获得有关拟合模型的其他信息。
4.2、生成模型
生成模型,通过计算图中任意两个节点间存在边的概率来重构图,
p ( A ∣ Z ) = ∏ i = 1 N ∏ j = 1 N p ( A i j ∣ z i , z j ) , with p ( A i j = 1 ∣ z i , z j ) = σ ( z i ⊤ z j ) , p\left(\mathbf{A}|\mathbf{Z}\right)=\prod_{i=1}^N\prod_{j=1}^Np\left(A_{ij}|\mathbf{z}_i,\mathbf{z}_j\right),\quad\text{with}\quad p\left(A_{ij}=1|\mathbf{z}_i,\mathbf{z}_j\right)=\sigma(\mathbf{z}_i^\top\mathbf{z}_j), p(A∣Z)=i=1∏Nj=1∏Np(Aij∣zi,zj),withp(Aij=1∣zi,zj)=σ(zi⊤zj),
也就是说,解码器通过计算任意两个节点向量表示的相似性来重建图结构。
4.3、学习
损失函数定义如下:
L = E q ( Z ∣ X , A ) [ log p ( A ∣ Z ) ] − K L [ q ( Z ∣ X , A ) ∣ ∣ p ( Z ) ] \mathcal{L}=\mathbb{E}_{q(\mathbf{Z}\mid\mathbf{X},\mathbf{A})}\big[\log p\left(\mathbf{A}\mid\mathbf{Z}\right)\big]-\mathrm{KL}\big[q(\mathbf{Z}\mid\mathbf{X},\mathbf{A})||p(\mathbf{Z})\big] L=Eq(Z∣X,A)[logp(A∣Z)]−KL[q(Z∣X,A)∣∣p(Z)]
- 第一部分与GAE中类似,为交叉熵函数,也就是经分布 q q q得到的向量重构出的图与原图的差异,这种差异越小越好;
- 第二部分表示利用GCN得到的分布 q ( ⋅ ) q(·) q(⋅)与标准高斯分布 p ( Z ) p(Z) p(Z)间的KL散度,也就是要求分布 q q q尽量与标准高斯分布相似。
其中, p ( Z ) p(Z) p(Z)为为标准高斯分布 p ( Z ) = ∏ i p ( z i ) = ∏ i N ( z i ∣ 0 , I ) . \begin{aligned}p(\mathbf{Z})=\prod_ip(\mathbf{z_i})=\prod_i\mathcal{N}(\mathbf{z}_i|0,\mathbf{I}).\end{aligned} p(Z)=i∏p(zi)=i∏N(zi∣0,I).
损失函数展开形式下:
∑ i = 1 n { − p ( x ) l o g ( p ( x ) ) − ( 1 − p ( x ) ) l o g ( 1 − p ( x ) ) + 1 / 2 ( μ ( i ) 2 + σ ( i ) 2 − l o g σ ( i ) 2 − 1 ) } \sum_{i=1}^n\{-p(x)log(p(x))-(1-p(x))log(1-p(x)) +1/2(\mu_{(i)}^{2}+\sigma_{(i)}^{2}-log\sigma_{(i)}^{2}-1)\} i=1∑n{−p(x)log(p(x))−(1−p(x))log(1−p(x))+1/2(μ(i)2+σ(i)2−logσ(i)2−1)}
5、模型实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import numpy as np
import args
class VGAE(nn.Module):def __init__(self,adj) -> None:super(VGAE,self).__init__()self.adj = adjself.share_gcn = GraphConvLayer(args.infeat,args.hidfeat1)self.gcn_mean = GraphConvLayer(args.hidfeat1,args.hidfeat2,activation = lambda x: x)self.gcn_logstd = GraphConvLayer(args.hidfeat1,args.hidfeat2,activation = lambda x:x)def encode(self,x,adj):hidden = self.share_gcn(x,adj)self.mean = self.gcn_mean(hidden,adj)self.logstd = self.gcn_logstd(hidden,adj)gaussian_noise = torch.randn(x.shape[0],args.hidfeat2)sampled_z = gaussian_noise * torch.exp(self.logstd) + self.meanreturn sampled_z@staticmethoddef decode(z):'''静态方法'''A_pred = F.sigmoid(torch.matmul(z,z.T))return A_preddef forward(self,x):Z = self.encode(x,self.adj)A_pred = self.decode(Z)return A_pred
class GraphConvLayer(nn.Module): def __init__(self, infeat,outfeat,activation = F.relu) -> None:super(GraphConvLayer,self).__init__()self.activation = activationself.layer = nn.Linear(infeat,outfeat,bias=False)self.init_param()passdef init_param(self):self.layer.reset_parameters()def forward(self,x,adj):AX = torch.mm(adj,x)AXW = self.layer(AX)return self.activation(AXW)
参考链接
- 参考链接1
- 参考链接2
- 参考链接3
相关文章:

【论文阅读】Variational Graph Auto-Encoder
0、基本信息 会议:2016-NIPS作者:Thomas N. Kipf,Max Welling文章链接:Variational Graph Auto-Encoder代码链接:Variational Graph Auto-Encoder 1、介绍 本文提出一个变分图自编码器,一个基于变分自编…...
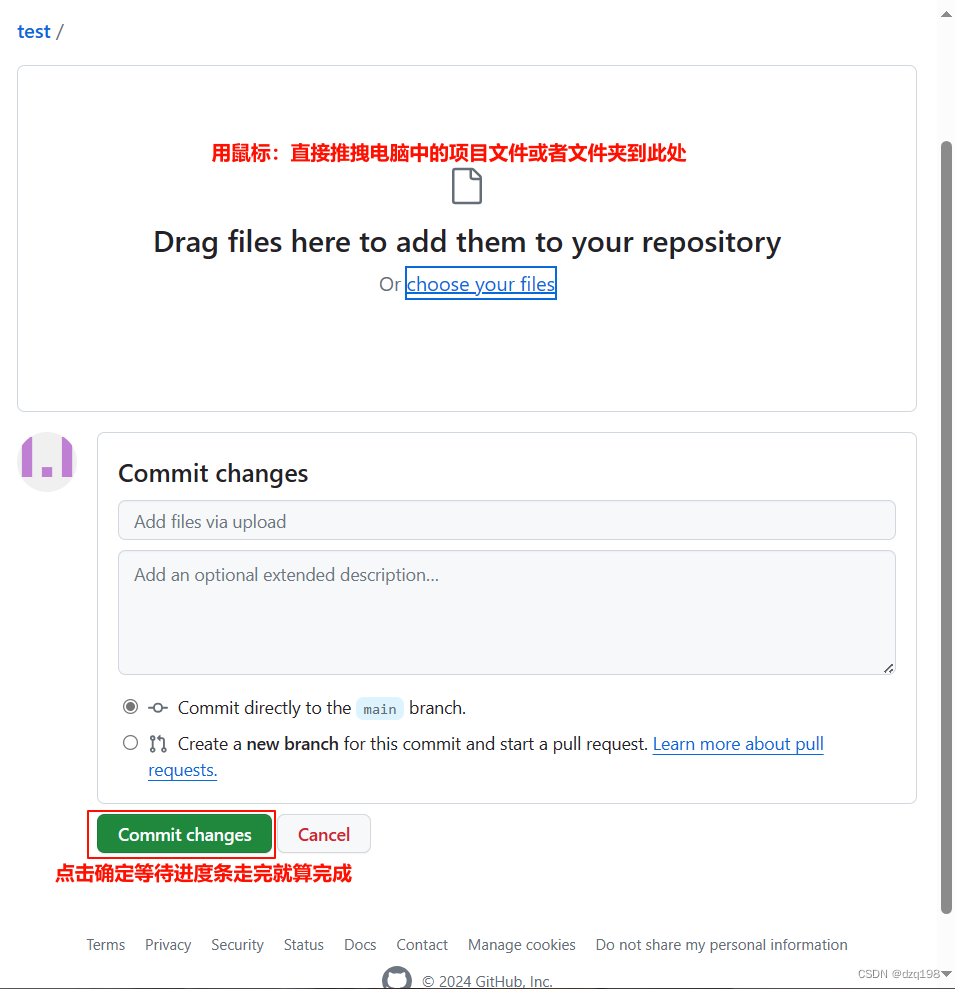
如何把电脑中的项目快速传进Github中?
一、打开GitHub网站:https:github.com 登录自己的个人账号 1.新建一个项目 2.用鼠标直接拖拽电脑中的项目文件夹与文件到新创建的项目中点击保存即可。...
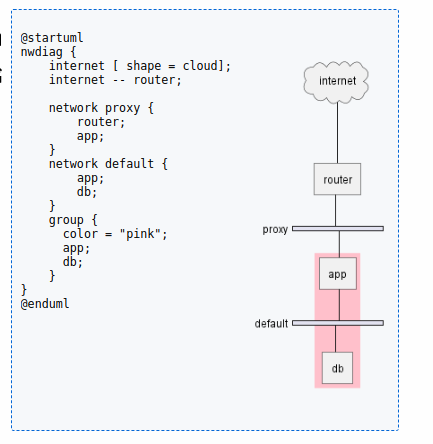
Plantuml之nwdiag网络图语法介绍(二十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

MyBatis接口的方法上使用,定义对应的 SQL 操作
目录标题 一、Mapper:二、Select、Insert、Update、Delete:三、Results、Result:四、Param:五、# 和 $: MyBatis 是一款基于 Java 的持久层框架,它通过简化数据库操作来帮助开发者构建更好的数据库访问应用…...

(20)Linux初始文件描述符
前言:本章我们介绍 O_WRONLY, O_TRUNC, O_APPEND 和 O_RDONLY。之后我们开始讲解文件描述符。 一、系统传递标记位 1、O_WRONLY C 语言在 w 模式打开文件时,文件内容是会被清空的,但是 O_WRONLY 好像并非如此? 代码演示&…...
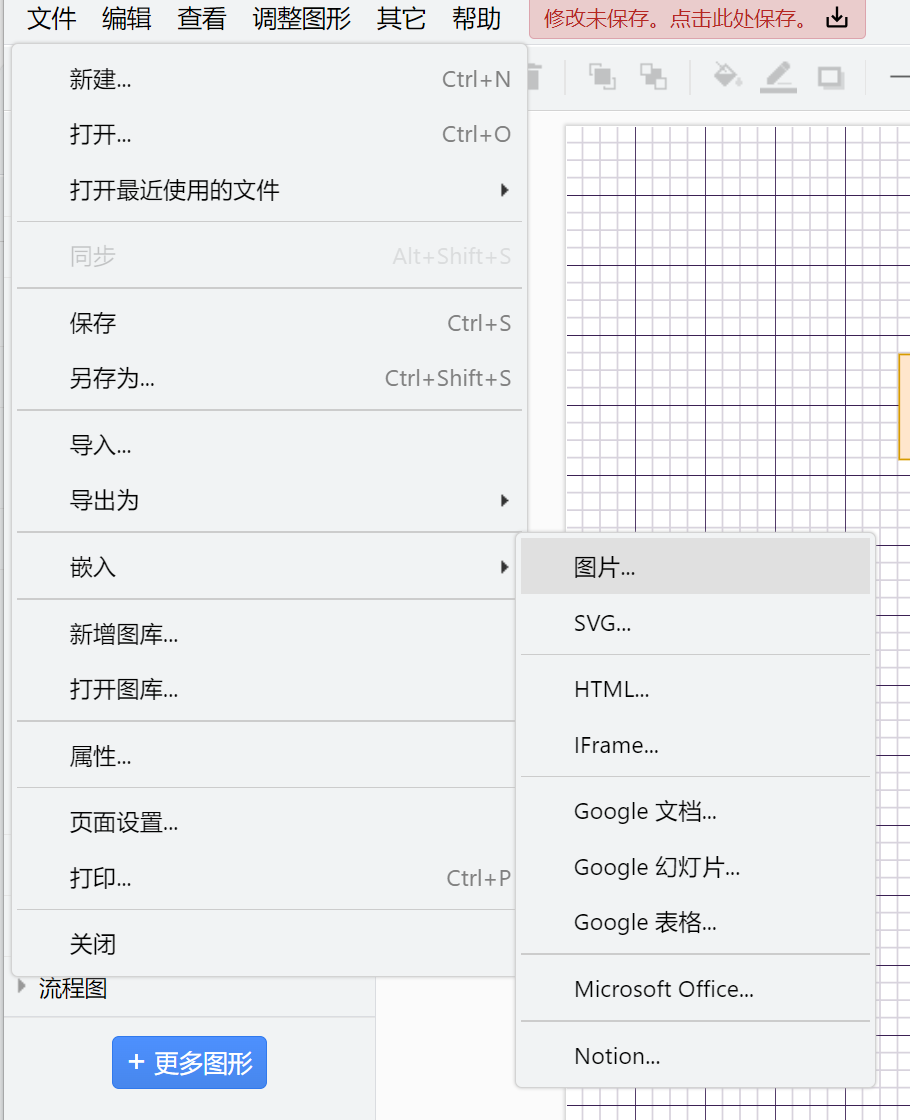
draw.io基础操作和代码高效画图进阶
文章目录 一、基础操作1、链接2、等比例变形3、复制4、插入表格 二、在线打开三、插入—功能聚集地1、插入图片2、插入画笔3、插入布局4、导出 四、图码转换——高效画图1、通用图码转换2、流程图生成:使用mermaid语言生成图: 五、图码转换高效画图的典型…...
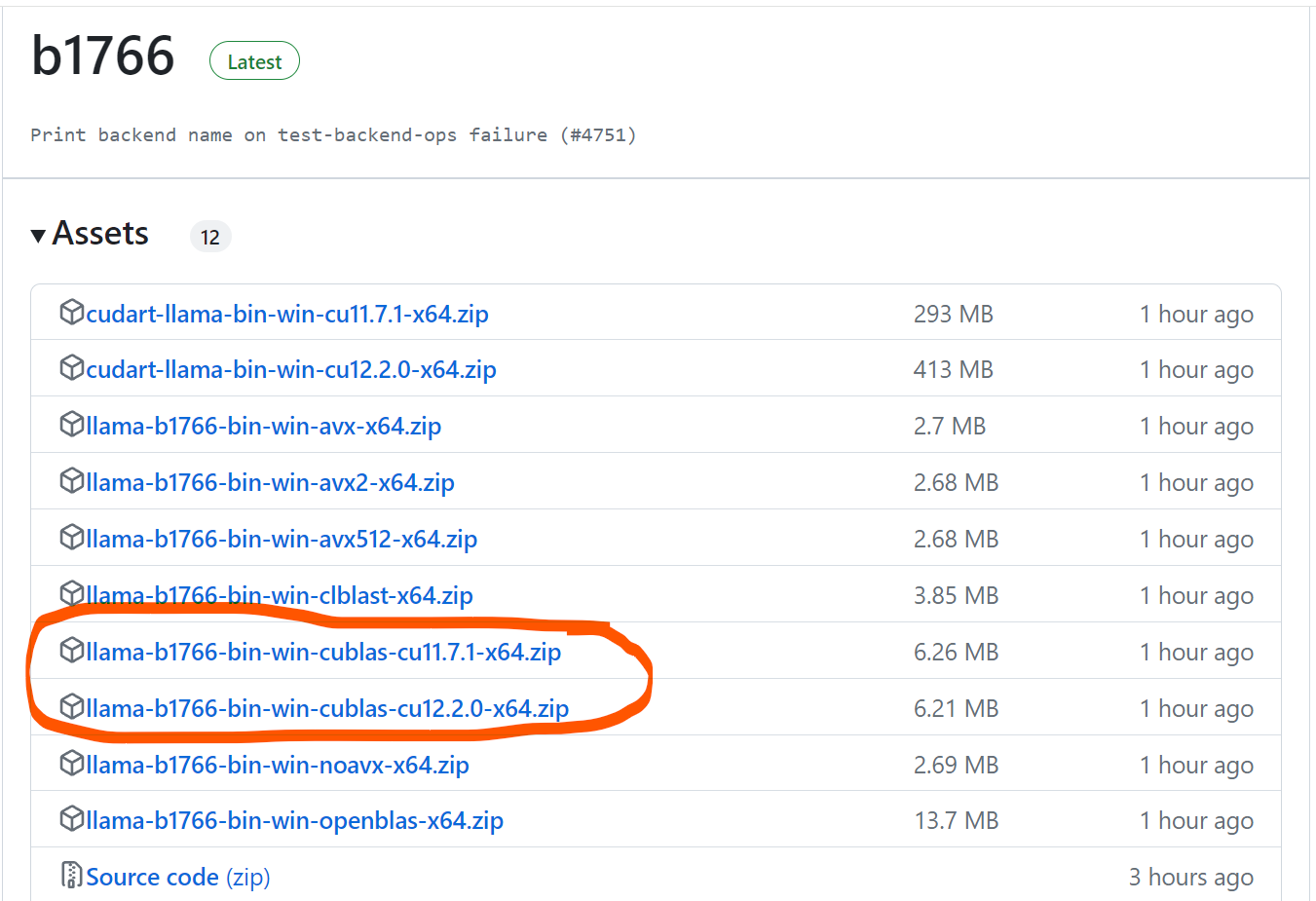
2024-01-04 用llama.cpp部署本地llama2-7b大模型
点击 <C 语言编程核心突破> 快速C语言入门 用llama.cpp部署本地llama2-7b大模型 前言一、下载llama.cpp以及llama2-7B模型文件二、具体调用总结 前言 要解决问题: 使用一个准工业级大模型, 进行部署, 测试, 了解基本使用方法. 想到的思路: llama.cpp, 不必依赖显卡硬件…...

HTTP打怪升级之路
新手村 上个世纪80年代末,有一天,Tim Berners-Lee正在工作,他需要与另一台计算机上的同事共享一个文件。他尝试使用电子邮件,但发现电子邮件不能发送二进制文件。Tim Berners-Lee意识到,他需要一种新的协议来共享二进制…...
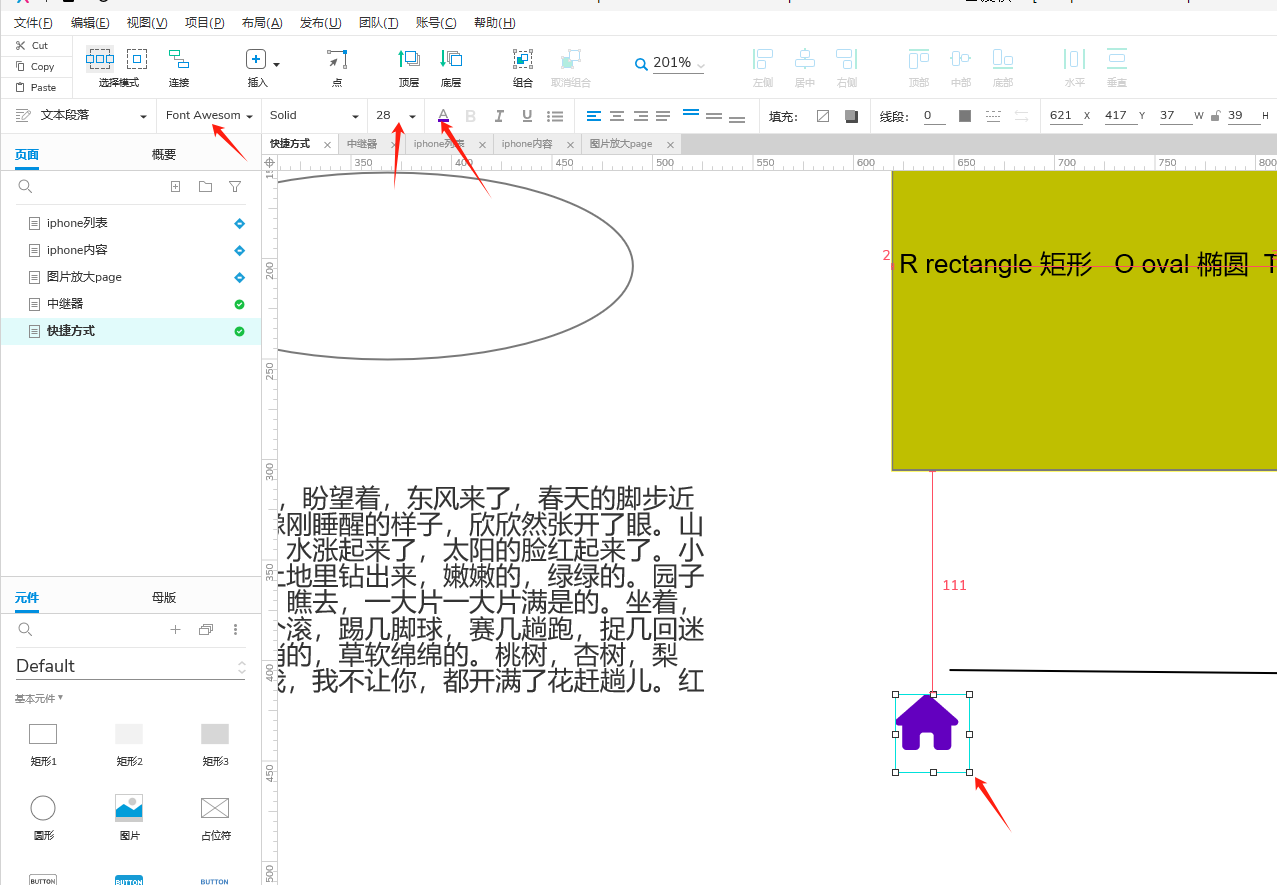
axure RP9.0安装字体图标库fontawesome
字体图库地址: Font AwesomeThe internets icon library toolkit. Used by millions of designers, devs, & content creators. Open-source. Always free. Always awesome.https://fontawesome.com/v6/download进入后下载想要的版本如我是6.3 下载后得到压缩包,解压之后…...

PiflowX组件-ReadFromUpsertKafka
ReadFromUpsertKafka组件 组件说明 upsert方式从Kafka topic中读取数据。 计算引擎 flink 有界性 Unbounded 组件分组 kafka 端口 Inport:默认端口 outport:默认端口 组件属性 名称展示名称默认值允许值是否必填描述例子kafka_hostKAFKA_HO…...
序列号2000-3000)
keil 5 ARM CC编译错误和警告解释大全(3)序列号2000-3000
2001年:已声明虚拟参数,但从未使用过 2002年:虚拟参数重新定义为do变量 2003:无法优化:常量/表达式传递给可能修改的变量 2004:重新维度的数组作为参数传递 2005:重维度数组等价 2006&…...
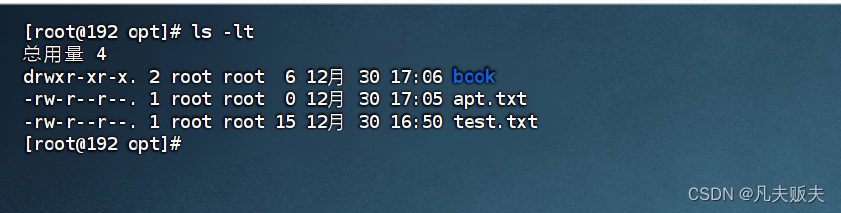
CentOS 7 实战指南:文件或目录的权限操作命令详解
前言 这篇文章详细介绍了文件和目录的常用权限操作命令,并提供了全面的技术解析。通过本文,你将学习如何使用 chmod 和 chown 命令来管理文件和目录的权限,控制用户和用户组的访问权限。无论你是初学者还是有经验的系统管理员,这…...
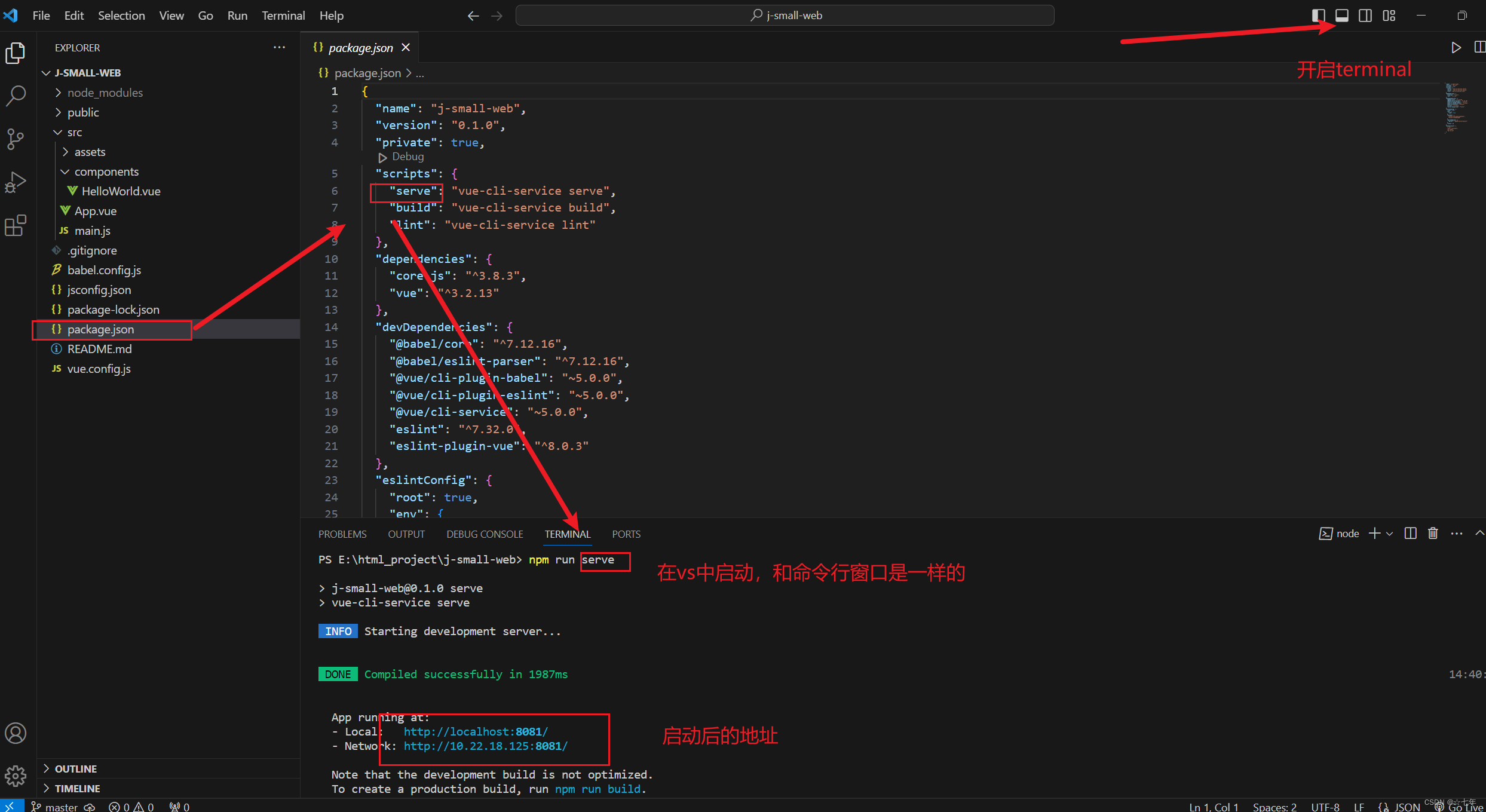
我的第一个前端项目,vue项目从零开始创建和运行
入门前端,从基础做起,从零开始新建项目 背景:VUE脚手架项目是一个“单页面”应用,即整个项目中只有1个网页! 在VUE脚手架项目中,主要是设计各个“视图组件”,它们都是整个网页中某个部分&…...

【OJ】C++,Java,Python,Go,Rust
for循环语法 // cpp// java// python for i in range(集合): for i, val in enumerate(集合): for v1,v2,v3,... in zip(集合1,集合2,集合3,...):Pair // cpp pair<int, string> first second // java Pair<Integer, String> first() new Pair<>(firstVal…...

Flink 任务指标监控
目录 状态监控指标 JobManager 指标 TaskManager 指标 Job 指标 资源监控指标 数据流监控指标 任务监控指标 网络监控指标 容错监控指标 数据源监控指标 数据存储监控指标 当使用 Apache Flink 进行流处理任务时,可以根据不同的监控需求,监控…...

Go语言程序设计-第7章--接口
Go语言程序设计-第7章–接口 接口类型是对其他类型行为的概括与抽象。 Go 语言的接口的独特之处在于它是隐式实现。对于一个具体的类型,无须声明它实现了哪些接口,只要提供接口所必须实现的方法即可。 7.1 接口即约定 7.2 接口类型 package iotype …...

性能优化-OpenMP基础教程(二)
本文主要介绍OpenMP并行编程技术,编程模型、指令和函数的介绍、以及OpenMP实战的几个例子。希望给OpenMP并行编程者提供指导。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:高性能(HPC&am…...

让电脑变得更聪明——用python实现五子棋游戏
作为经典的棋类游戏,五子棋深受大众喜爱,但如果仅实现人与人的博弈,那程序很简单,如果要实现人机对战,教会计算机如何战胜人类,那就不是十分容易的事了。本文我们先从简单入手,完成五子棋游戏的…...

C#-接口
接口 (interface) 定义了一个可由类和结构实现的协定。接口可以包含方法、属性、事件和索引器。接口不提供它所定义的成员的实现 — 它仅指定实现该接口的类或结构必须提供的成员。 接口可支持多重继承。在下面的示例中,接口 IComboBox 同时从 ITextBox 和 IListBox 继承。 i…...
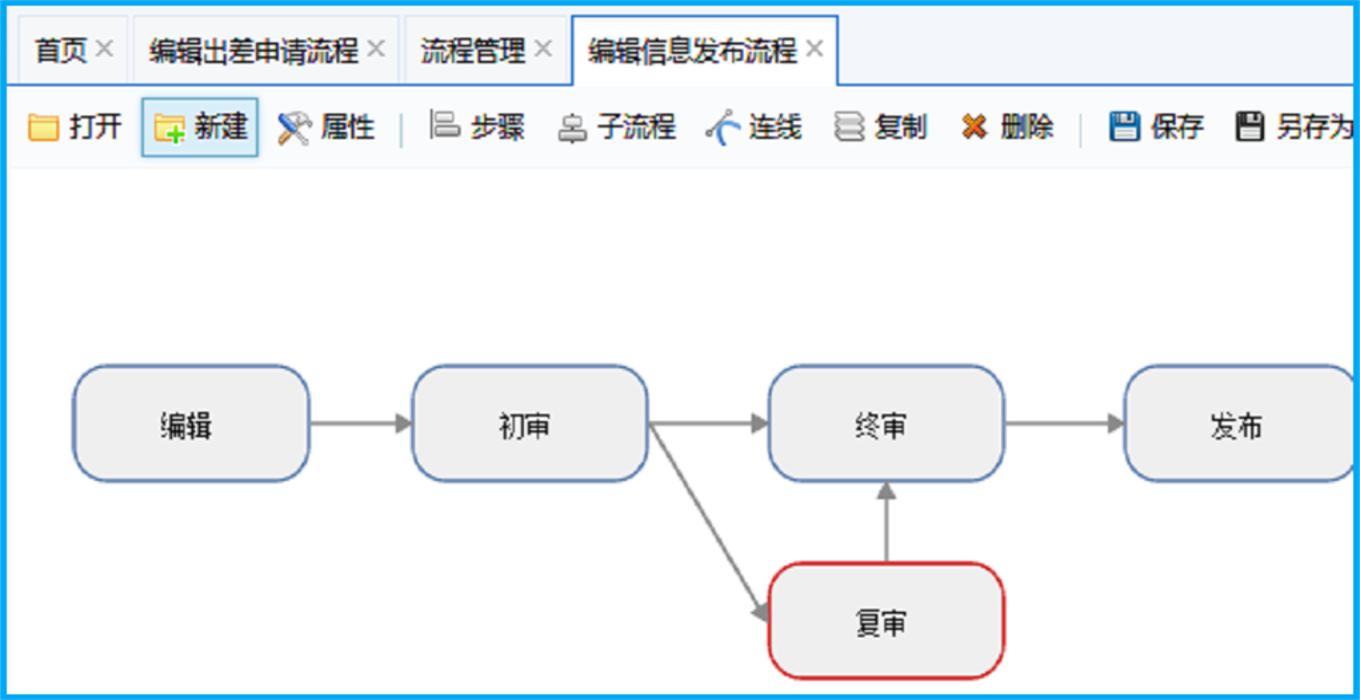
ASP.NET可视化流程设计器源码
源码介绍: ASP.NET可视化流程设计器源码已应用于众多大型企事业单位。拥有全浏览器兼容的可视化流程设计器、表单设计器、基于角色的权限管理等系统开发必须功能,大大为您节省开发时间,是您开发OA.CRM、HR等企事业各种应用管理系统和工作流系统的最佳基…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...

用Playwright自动化测试工具,5分钟搞定网站短信验证码接口的批量测试
用Playwright实现短信验证码接口的自动化测试实战指南短信验证码作为现代Web应用的核心安全组件,其稳定性和防护能力直接影响用户体验和系统安全。根据2023年DevOps状态报告,超过60%的线上身份验证故障源于短信服务接口的异常。本文将带你用Playwright这…...