python渗透工具编写学习笔记:10、网络爬虫基础/多功能编写
目录
前言
10.1 概念
10.2 调度器/解析器
10.3 存储器/去重器
10.4 日志模块
10.5 反爬模块
10.6 代理模块
前言
在渗透工具中,网络爬虫有着不可忽视的作用,它能够快速而精准的搜寻、提取我们所需要的信息并按照我们所需要的格式排列,那么今天我们就来学习使用python编写实用的爬虫吧!坚持科技向善,勿跨越法律界限,代码仅供教学目的。初出茅庐,如有错误望各位不吝赐教。
10.1 概念
网络爬虫是指自动访问互联网上的网页并提取相关信息的程序。Python是一种常用的编程语言,可以用来编写网络爬虫。Python爬虫的架构通常包括以下几个组件:
-
调度器(Scheduler):负责管理爬取的URL队列,将待爬取的URL添加到队列中,并根据一定的策略从队列中取出URL进行爬取。
-
下载器(Downloader):负责下载URL对应的网页内容,并将下载结果返回给爬虫程序。
-
解析器(Parser):负责解析下载下来的网页内容,提取出需要的数据。
-
存储器(Storage):负责将解析出的数据进行存储,可以是保存到数据库中、写入文件等。
-
去重器(Deduplicator):负责对已下载的URL进行去重,避免重复的爬取。
-
调度器、下载器、解析器、存储器之间一般通过消息队列、数据库等通信机制进行交互。
在实际的爬虫项目中,爬虫的整体流程为:调度器从URL队列中取出一个URL,交给下载器下载该URL对应的网页内容,下载完成后将结果交给解析器进行解析,提取出需要的数据,并交给存储器进行存储。同时,去重器会对已下载的URL进行去重,避免重复爬取。
10.2 调度器/解析器
网络爬虫是指自动访问互联网上的网页并提取相关信息的程序。Python是一种常用的编程语言,也可以用来编写网络爬虫。
我们用Python编写一个简单的爬虫调度器:
在Python中,你可以使用requests库来发送HTTP请求获取网页内容,使用BeautifulSoup库来解析网页内容。
import requests
from bs4 import BeautifulSoup
发送请求获取网页内容:使用requests库发送HTTP请求并获取网页内容。
url = "https://www.example.com" # 要爬取的网页地址
response = requests.get(url)
html = response.text # 获取网页内容
要学习如何编写爬虫的解析器,我们需要先学习正则表达式的编写:
正则表达式是一种用来匹配字符串的工具,可以用来搜索、替换和提取字符串中的特定模式。在Python中,正则表达式的相关函数和模块被封装在re模块中。
下面我们再来学习编写爬虫的解析器,用于筛选出我们需要的信息。我们可以使用re模块来进行字符串的正则表达式匹配。下面是一些常用的re模块函数:
-
re.match(pattern, string, flags=0):
- 函数用于尝试从字符串的起始位置匹配一个模式。
- 如果匹配成功,返回一个匹配对象;如果匹配失败,返回None。
- pattern:要匹配的正则表达式模式。
- string:要匹配的字符串。
- flags:可选参数,用于控制匹配的模式。
-
re.search(pattern, string, flags=0):
- 函数用以在字符串中搜索匹配的第一个位置,返回一个匹配对象。
- pattern:要匹配的正则表达式模式。
- string:要匹配的字符串。
- flags:可选参数,用于控制匹配的模式。
-
re.findall(pattern, string, flags=0):
- 函数用以在字符串中搜索匹配的所有位置,返回一个列表。
- pattern:要匹配的正则表达式模式。
- string:要匹配的字符串。
- flags:可选参数,用于控制匹配的模式。
下面是一个示例,演示如何使用re模块来匹配字符串:
import re# 匹配字符串中的数字
pattern = r'\d+'
string = 'abc123def456ghi'# 使用re.search()匹配第一个数字
match = re.search(pattern, string)
if match:print(f'Matched: {match.group()}') # 输出:Matched: 123# 使用re.findall()匹配所有数字
matches = re.findall(pattern, string)
if matches:print(f'All Matches: {matches}') # 输出:All Matches: ['123', '456']
在上面的示例中,使用正则表达式模式r'\d+'匹配字符串中的数字。首先使用re.search()函数匹配第一个数字,然后使用re.findall()函数匹配所有数字。输出结果显示匹配到的数字。
学会了re模块的主要函数,接下来我们来学习正则表达式筛选条件的编写:
-
字符匹配
- 字符:使用普通字符直接匹配,例如匹配字符串 "hello",可以使用正则表达式 "hello"。
- 句点(.):匹配任意一个字符,除了换行符(\n)。
- 字符集([]):匹配方括号中的任意一个字符。例如,[aeiou] 匹配任意一个元音字母。
- 转义字符(\):用来匹配特殊字符。例如,匹配圆括号字符,可以使用 "("。
- 重复次数:用于指定一个字符的重复次数。例如,a{3} 匹配 "aaa"。
- 元字符(\d、\w、\s):用于匹配特定类型的字符。例如,\d 匹配任意一个数字字符。
-
边界匹配
- 开始位置(^):匹配字符串的开始位置。
- 结束位置($):匹配字符串的结束位置。
-
重复匹配
- 重复(*):匹配前面的元素0次或多次。
- 加号(+):匹配前面的元素1次或多次。
- 问号(?):匹配前面的元素0次或1次。
- 花括号({}):匹配前面的元素指定的次数范围。例如,a{2,4} 匹配 "aa"、"aaa"、"aaaa"。
-
分组和捕获
- 圆括号(()):用于分组的目的。例如,(ab)+ 匹配 "ab"、"abab"、"ababab"。
- 捕获组(\1、\2、\3...):用于引用分组中的内容。例如,(\w+)\s+\1 匹配 "hello hello"。
-
特殊序列
- \d:匹配任意一个数字字符。等价于 [0-9]。
- \D:匹配任意一个非数字字符。等价于 [^0-9]。
- \w:匹配任意一个字母、数字或下划线字符。等价于 [a-zA-Z0-9_]。
- \W:匹配任意一个非字母、数字或下划线字符。等价于 [^a-zA-Z0-9_]。
- \s:匹配任意一个空白字符,包括空格、制表符、换行符等。
- \S:匹配任意一个非空白字符。
以上是正则表达式的一些常用语法,我们再来看看爬虫常用的筛选条件:
soup = BeautifulSoup(html, "html.parser") # 使用html.parser解析器解析网页内容
# 提取需要的信息
title = soup.title.text # 提取网页标题
links = soup.find_all("a") # 提取所有链接10.3 存储器/去重器
完成了调度器与解析器的编写,我们再来看三要素里的最后一个:爬虫的存储器。它用于将爬取完成后的数据储存起来,下面我们利用python的文件写入方法来对数据进行储存,并将提取的信息保存到文件或数据库中。
# 保存到文件
with open("output.txt", "w") as f:f.write(title)for link in links:f.write(link.get("href"))
好了!我们已经写出了网络爬虫最主要的三个部分,接下来是时候为它添加上更加丰富的功能了,为了使我们的爬虫不会爬取相同的网页,我们来编写一个爬虫的去重器。以下是爬虫去重器的示例代码:
import hashlibdef get_md5(url):"""计算URL的MD5值"""if isinstance(url, str):url = url.encode("utf-8")m = hashlib.md5()m.update(url)return m.hexdigest()class Deduplicator:def __init__(self):self.visited_urls = set()def is_visited(self, url):"""判断URL是否已经被访问过"""url_md5 = get_md5(url)if url_md5 in self.visited_urls:return Trueelse:self.visited_urls.add(url_md5)return False
使用方法:
deduplicator = Deduplicator()
url = "http://example.com"if deduplicator.is_visited(url):print("URL已被访问过")
else:print("URL未被访问过")
以上代码中,get_md5函数用于计算URL的MD5值,将其作为唯一的标识。Deduplicator类用于存储已经访问过的URL,通过调用is_visited方法判断URL是否已经被访问过。如果URL已被访问过,则返回True;如果URL未被访问过,则将其MD5值添加到已访问集合中,并返回False。
10.4 日志模块
日志模块,可以使我们的爬虫爬取日志信息,提取不同级别的日志,编写Python爬虫的日志模块可以使用Python内置的logging模块来实现。下面是一个简单示例:
import logging# 创建日志对象
logger = logging.getLogger('crawler')
logger.setLevel(logging.DEBUG)# 创建文件handler,用于将日志写入文件
file_handler = logging.FileHandler('crawler.log')
file_handler.setLevel(logging.DEBUG)# 创建控制台handler,用于在控制台输出日志
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)# 定义日志格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)# 将handler添加到日志对象中
logger.addHandler(file_handler)
logger.addHandler(console_handler)
以上代码创建了一个名为'crawler'的日志对象,并设置了日志级别为DEBUG,即最低级别的日志会输出到文件和控制台。可以根据需求进行调整日志级别。
接下来,可以在爬虫代码中使用日志对象来记录日志信息。例如:
url = 'http://example.com'try:# 爬取数据的代码logger.debug(f'Start crawling url: {url}')# ...# 爬取成功的日志信息logger.info(f'Successfully crawled url: {url}')
except Exception as e:# 爬取失败的日志信息logger.error(f'Failed to crawl url: {url}. Error message: {str(e)}')
以上代码会在开始爬取URL和成功爬取URL时分别记录DEBUG级别和INFO级别的日志信息,如果爬取过程中出现异常,则会记录ERROR级别的日志信息,并将异常信息作为日志消息的一部分。所有日志信息会同时输出到文件和控制台。
这样,就完成了一个简单的Python爬虫日志模块的编写。我们可以根据实际需求对日志模块进行扩展和优化,例如添加日志文件的切割、设置日志文件大小等。
10.5 反爬模块
当遇到反爬机制时,我们可以使用Python编写一些反爬模块来应对。这些模块可以帮助我们绕过一些常见的反爬手段,如User-Agent检测、验证码识别、IP封锁等。
以下是一个示例,演示了如何使用Python的requests库和验证码识别库tesseract来实现一个简单的反爬模块:
import requests
from PIL import Image
import pytesseract# 请求头,可以根据具体的网站进行调整
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 请求网页,可以添加其他参数,如代理IP等
response = requests.get('http://example.com', headers=headers)# 如果返回的响应中有验证码图片,可以使用Pillow库来处理
if 'captcha' in response.text:# 找到验证码图片的URLcaptcha_url = 'http://example.com/captcha.jpg'captcha_response = requests.get(captcha_url, headers=headers)# 保存验证码图片到本地with open('captcha.jpg', 'wb') as f:f.write(captcha_response.content)# 使用tesseract来识别验证码captcha = pytesseract.image_to_string(Image.open('captcha.jpg'))# 构建包含验证码的表单数据data = {'captcha': captcha,# 其他表单数据...}# 提交包含验证码的表单数据response = requests.post('http://example.com/submit', data=data, headers=headers)# 处理响应内容
# ...注:这只是一个简单的示例,实际应用时可能需要根据具体的反爬机制进行具体调整和优化。此外,还可以考虑使用代理IP池、使用多个账号轮流访问等更复杂的反爬策略。
10.6 代理模块
最后,我们再来使用Python编写爬虫的代理模块:
import requests# 使用代理IP访问网页
def request_with_proxy(url, proxies):try:# 使用get方法发送请求response = requests.get(url, proxies=proxies)# 返回响应内容return response.textexcept requests.exceptions.RequestException as e:print('Error:', e)# 获取代理IP
def get_proxy():try:# 代理IP的API地址api_url = 'http://api.ip.data5u.com/dynamic/get.html?order=YOUR_ORDER_NUMBER&ttl=1&json=1'response = requests.get(api_url)# 解析返回的JSON数据data = response.json()# 提取代理IP和端口号proxy_ip = data['data'][0]['ip']proxy_port = data['data'][0]['port']# 构造代理IP字典proxy = {'http': f'http://{proxy_ip}:{proxy_port}','https': f'https://{proxy_ip}:{proxy_port}',}return proxyexcept requests.exceptions.RequestException as e:print('Error:', e)# 测试代理IP是否可用
def test_proxy(proxy):try:# 使用httpbin.org作为测试目标网站url = 'http://httpbin.org/ip'response = requests.get(url, proxies=proxy)# 解析返回的JSON数据data = response.json()# 提取IP地址ip = data['origin']print('Proxy IP:', ip)except requests.exceptions.RequestException as e:print('Error:', e)# 主函数
def main():# 获取代理IPproxy = get_proxy()if proxy:# 测试代理IP是否可用test_proxy(proxy)# 使用代理IP访问网页url = 'https://www.example.com'html = request_with_proxy(url, proxy)print(html)if __name__ == '__main__':main()
确保将YOUR_ORDER_NUMBER替换为在代理IP网站上获得的订单号。在上述代码中,我们使用httpbin.org作为测试网站,可以将url变量替换为任何想要访问的实际网站。
好了,到这里就是今天的全部内容了,如有帮助不胜荣幸。
相关文章:

python渗透工具编写学习笔记:10、网络爬虫基础/多功能编写
目录 前言 10.1 概念 10.2 调度器/解析器 10.3 存储器/去重器 10.4 日志模块 10.5 反爬模块 10.6 代理模块 前言 在渗透工具中,网络爬虫有着不可忽视的作用,它能够快速而精准的搜寻、提取我们所需要的信息并按照我们所需要的格式排列,…...
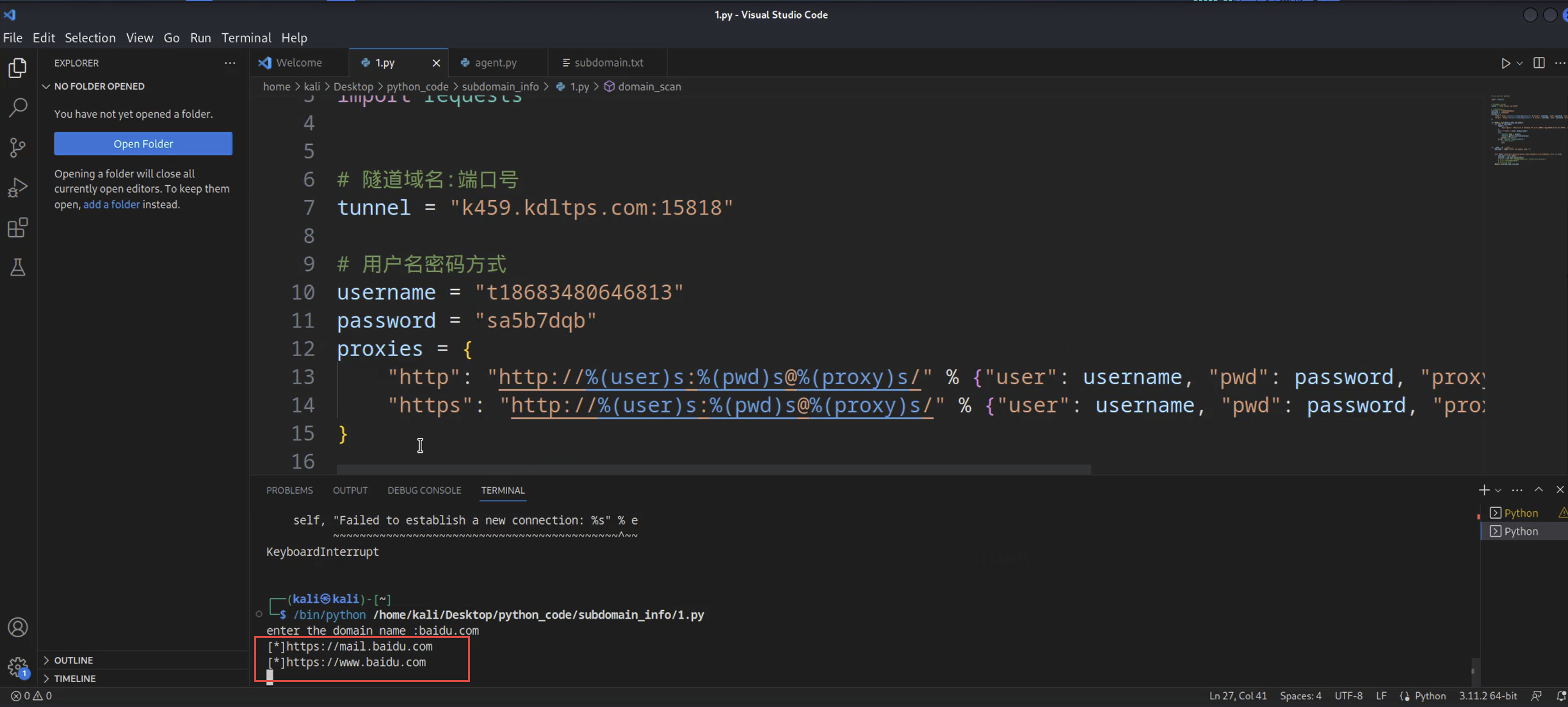
Python武器库开发-武器库篇之子域名扫描器开发(四十一)
Python武器库开发-武器库篇之子域名扫描器开发(四十一) 在我们做红队攻防或者渗透测试的过程中,信息收集往往都是第一步的,有人说:渗透的本质就是信息收集,前期好的信息收集很大程度上决定了渗透的质量和攻击面,本文将…...

通俗易懂的15个Java Lambda表达式案例
文章目录 1. **实现Runnable接口**:2. **事件监听器**(如Swing中的ActionListener):3. **集合遍历**(使用forEach方法):4. **过滤集合**(使用Stream API):5. …...
)
十七:爬虫-JS逆向(上)
1、什么是JS、JS反爬是什么?JS逆向是什么? JS:JS全称JavaScript是互联网上最流行的脚本语言,这门语言可用于HTML 和 web,更可广泛用于服务器、PC、笔记本电脑、平板电脑和智能手机等设备。JavaScript 是一种轻量级的编程语言。JavaScript 是…...

How to implement anti-crawler strategies to protect site data
How to implement anti-crawler strategies to protect site data 信息校验型反爬虫User-Agent反爬虫Cookie反爬虫签名验证反爬虫WebSocket握手验证反爬虫WebSocket消息校验反爬虫WebSocket Ping反爬虫 动态渲染反爬虫文本混淆反爬虫图片伪装反爬虫CSS偏移反爬虫SVG映射反爬虫字…...

王国维的人生三境界,这一生至少当一次傻瓜
一、人生三境界 古今之成大事业、大学问者,必经过三种之境界。“昨夜西风凋碧树,独上高楼,望尽天涯路。”此第一境也。“衣带渐宽终不悔,为伊消得人憔悴。”此第二境也。“众里寻他千百度,蓦然回首,那人却…...
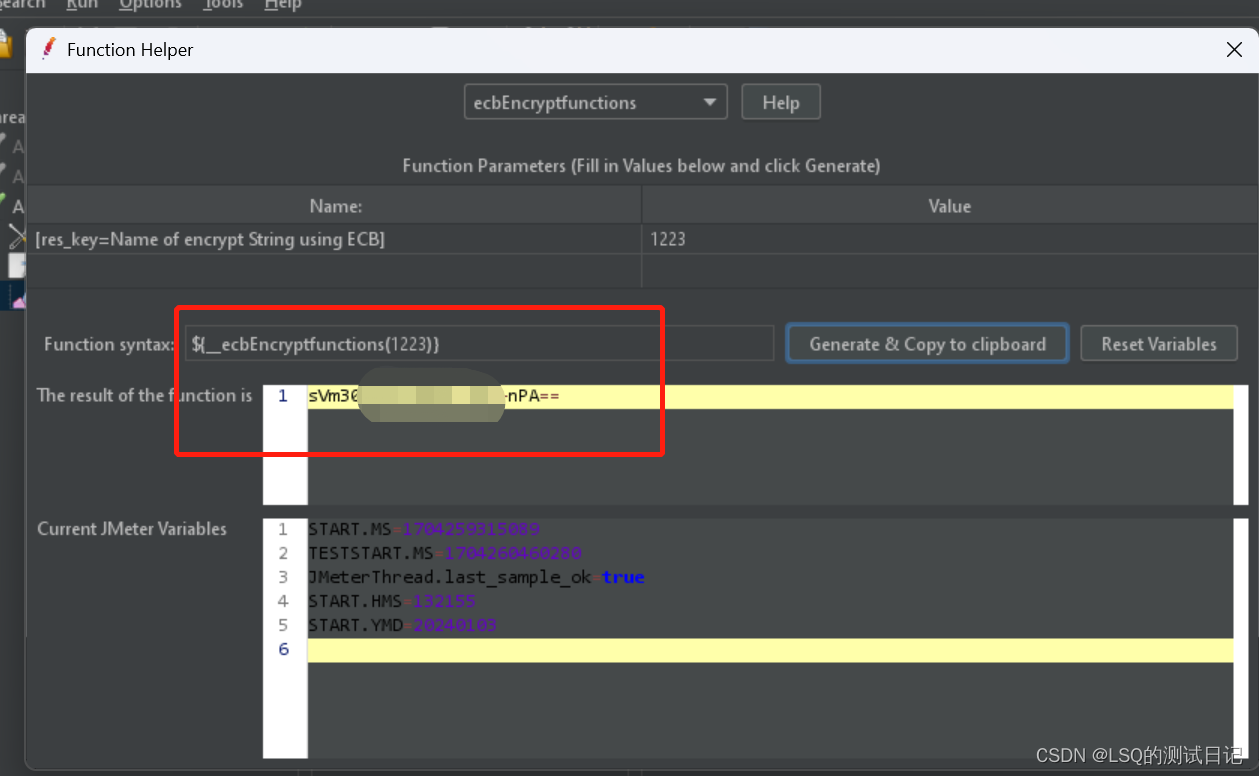
Jmeter二次开发实操问题汇总(JDK问题,jar包问题)
前提 之前写过一篇文章:https://qa-lsq.blog.csdn.net/article/details/119782694 只是简单尝试了一下生成一个随机手机号码。 但是如果在工作中一个实际场景要用的二次开发,可能会遇到一些问题。 比如这样一个场景: Mobile或者前端调用部分…...

网络安全B模块(笔记详解)- 数字取证
数据分析数字取证-attack 1.使用Wireshark查看并分析Windows 7桌面下的attack.pcapng数据包文件,通过分析数据包attack.pcapng找出恶意用户的IP地址,并将恶意用户的IP地址作为Flag(形式:[IP地址])提交; 解析:http.request.method==POST Flag:[172.16.1.102] 2.继续…...
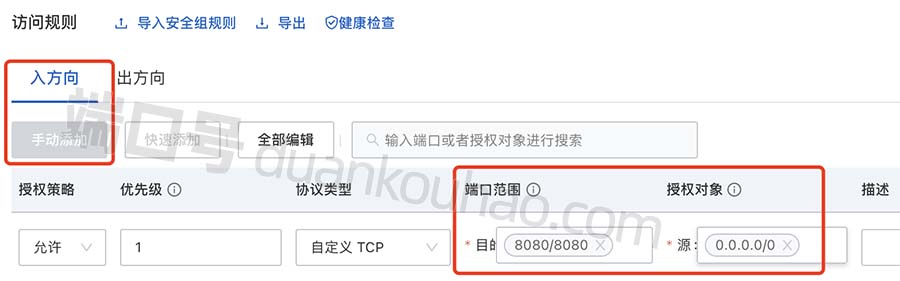
阿里云服务器8080端口安全组开通图文教程
阿里云服务器8080端口开放在安全组中放行,Tomcat默认使用8080端口,8080端口也用于www代理服务,阿腾云atengyun.com以8080端口为例来详细说下阿里云服务器8080端口开启教程教程: 阿里云服务器8080端口开启教程 阿里云服务器8080端…...
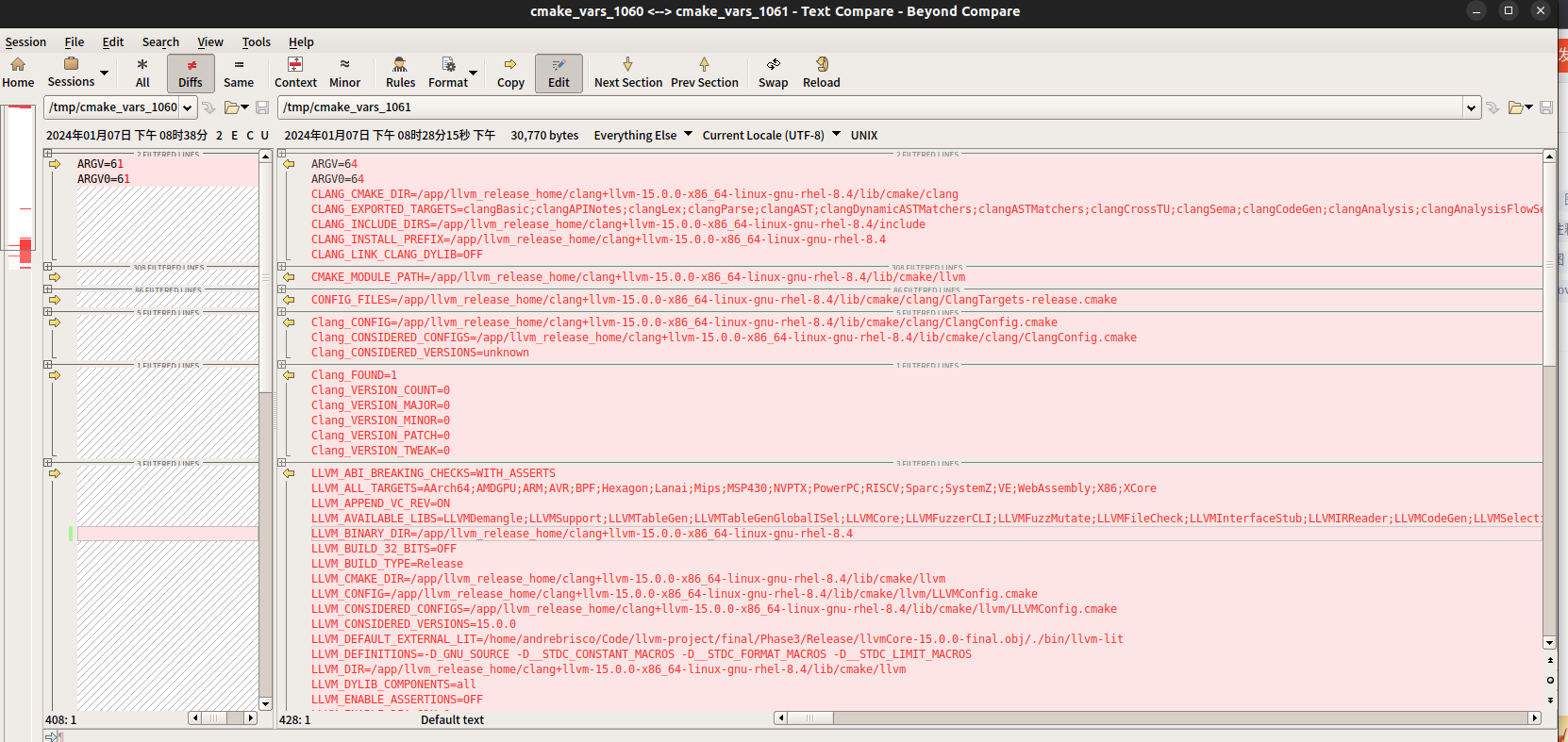
vmlinux, vmlinux.bin, bzImage; cmake的find_package(Clang)新增了哪些变量( 比较两次记录的所有变量差异)
vmlinux, vmlinux.bin, bzImage cd /bal/linux-stable/ file vmlinux #vmlinux: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, BuildID[sha1]=b99bbd9dda1ec2751da246d4a7ae4e6fcf7d789b, not stripped #文件大小 20MB, 19940148Bfile ar…...

webpack配置入门
webpack是需要一定配置才能使用的,否则无任何效果。在开始webpack学习之前必须理解以下5个核心概念。 5大核心配置 1.entry(入口) webpack从那个文件开始打包,支持单文件入口(vue和react脚手架单入口)和多文件入口 2.output(输…...
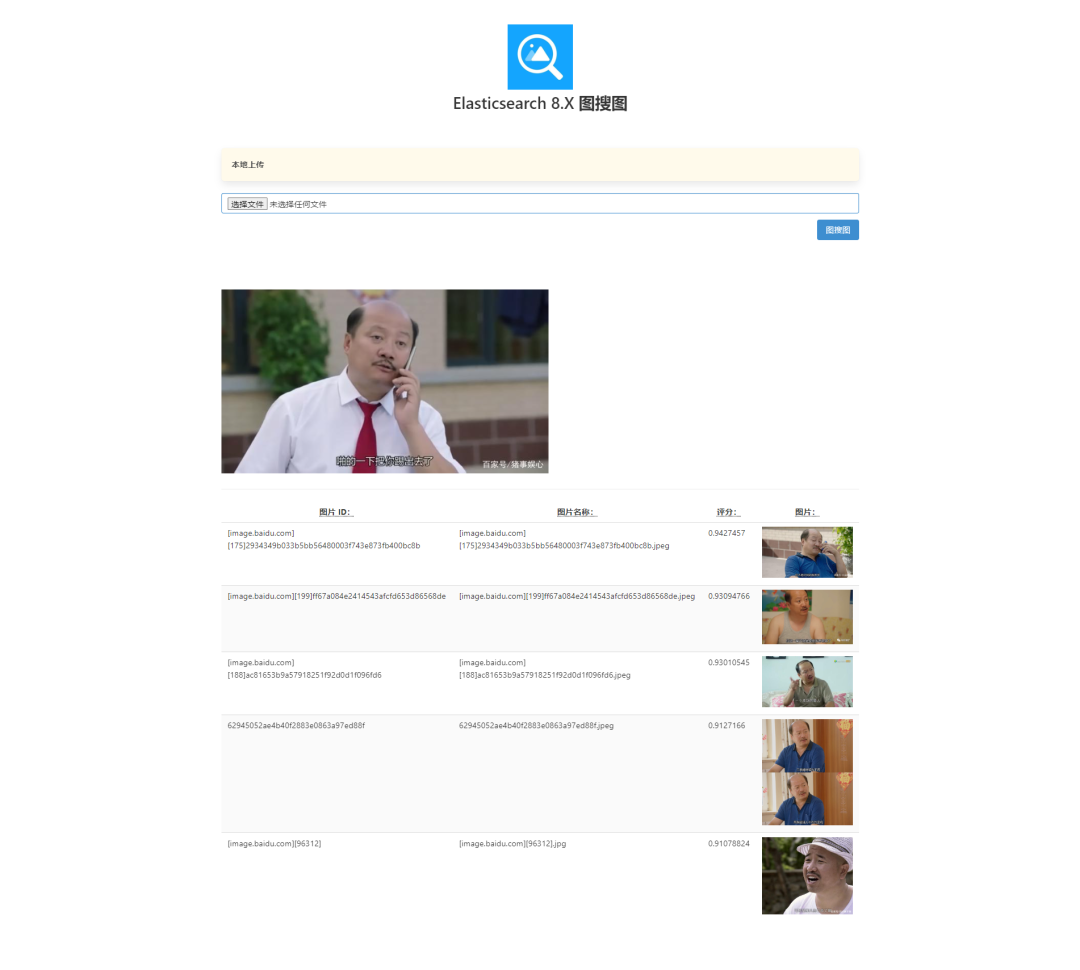
Elasticsearch 8.X进阶搜索之“图搜图”实战
Elasticsearch 8.X “图搜图”实战 1、什么是图搜图? "图搜图"指的是通过图像搜索的一种方法,用户可以通过上传一张图片,搜索引擎会返回类似或者相关的图片结果。这种搜索方式不需要用户输入文字,而是通过比较图片的视…...
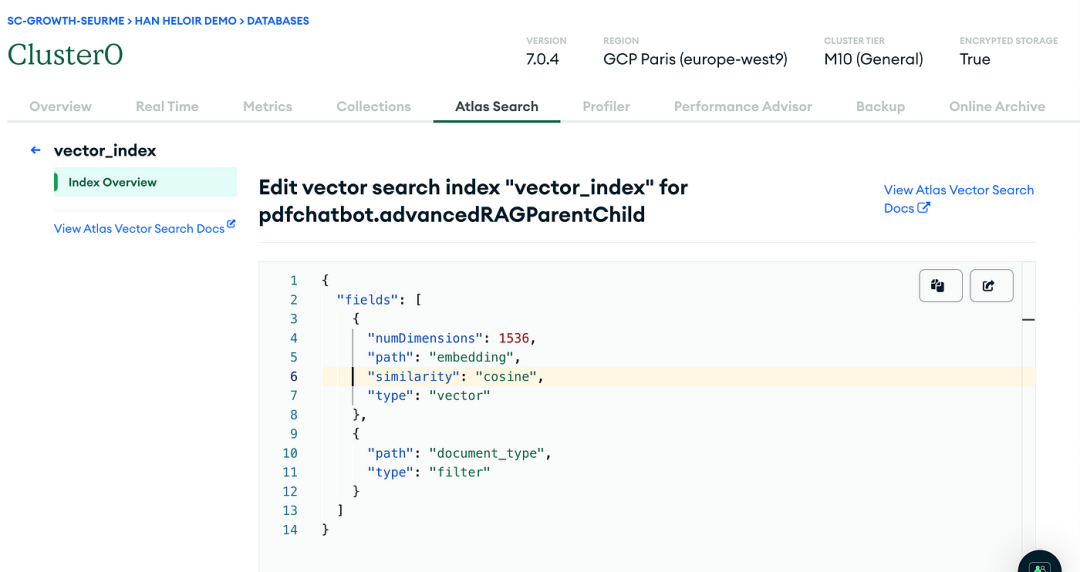
LLM之RAG实战(十三)| 利用MongoDB矢量搜索实现RAG高级检索
想象一下,你是一名侦探,身处庞大的信息世界,试图在堆积如山的数据中找到隐藏的一条重要线索,这就是检索增强生成(RAG)发挥作用的地方,它就像你在人工智能和语言模型世界中的可靠助手。但即使是最…...

UI动效设计师通往高薪之路,AE设计从基础到进阶教学
一、教程描述 UI动效设计,顾名思义即动态效果的设计,用户界面上所有运动的效果,也可以视其为界面设计与动态设计的交集,或者可以简单理解为UI设计中的动画效果,是UI设计中不可或缺的组成部分。现在UI设计的要求越来越…...

APK多渠道加固打包笔记之360加固宝
知识储备 首先需要知道V1,V2,V3签名的区别,可以参考之前的文章:AndroidV1,V2,V3签名原理详解 前言:一般开发者会指定使用自己创建的证书,如果没有指定,则会默认使用系统的证书,该默认的证书存储在C:\Users…...

编程天赋和努力哪个更重要?
编程天赋和努力在编程中都非常重要,但它们的侧重点不同。 编程天赋通常指的是与生俱来的、在逻辑思维、抽象思维、创造力等方面的能力,这些能力可以帮助程序员更快地理解问题、更高效地设计和实现解决方案。天赋的确可以帮助程序员更容易地入门和更快地掌…...
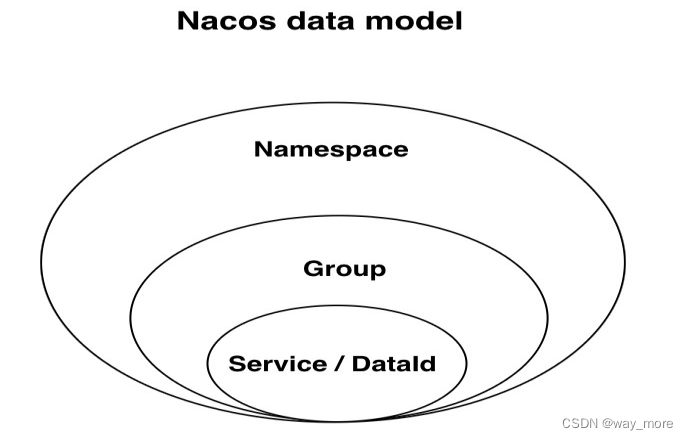
SpringCloud Alibaba之Nacos配置中心配置详解
目录 Nacos配置中心数据模型Nacos配置文件加载Nacos配置 Nacos配置中心数据模型 Nacos 数据模型 Key 由三元组唯一确定,三元组分别是Namespace、Group、DataId,Namespace默认是公共命名空间(public),分组默认是 DEFAUL…...

个人实际开发心得感悟及学习方法
前言 我的学习路线应该和大多数人的学习路线差不多,快速的学习完html和css,很多东西都没有记住的情况下就进入了js的学习,js学的懵懵懂懂就进入了node.js的基础学习和webpack的了解式学习,然后就跨度到了vue和react框架的学习。 节奏很快,学习的基础也极其不扎实。正如同那句…...
光速爱购--靠谱的SpringBoot项目
简介 这是一个靠谱的SpringBoot项目实战,名字叫光速爱购。从零开发项目,视频加文档,十天就能学会开发JavaWeb项目。 教程路线是:搭建环境> 安装软件> 创建项目> 添加依赖和配置> 通过表生成代码> 编写Java代码&g…...
P1019 [NOIP2000 提高组] 单词接龙
网址如下:P1019 [NOIP2000 提高组] 单词接龙 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 很怪,不知道该说什么 我试了题目给的第一个测试点的输入,发现输出和测试点的一样,但是还是WA 不是很懂为什么 有没有大佬帮我看一下…...

Phi-4-mini-reasoning企业落地:保险条款自动推理与理赔逻辑校验系统
Phi-4-mini-reasoning企业落地:保险条款自动推理与理赔逻辑校验系统 1. 项目背景与价值 保险行业长期面临两大核心痛点:复杂的条款解读和繁琐的理赔审核。传统人工处理方式存在效率低、成本高、标准不统一等问题。Phi-4-mini-reasoning模型凭借其强大的…...

微信数据安全终极指南:理解数据保护与合规使用
微信数据安全终极指南:理解数据保护与合规使用 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 在数字时代,微信聊天记录承载着我们的工作沟通、个人回忆和重要信息,数据安全与隐私保护成…...

题解:洛谷 P1850 [NOIP 2016 提高组] 换教室
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南
BiliTools:2026年最全能的哔哩哔哩资源管理工具箱完整指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

ComfyUI-Impact-Pack V8:3大模块化AI图像增强解决方案,彻底解决内存占用与启动速度难题
ComfyUI-Impact-Pack V8:3大模块化AI图像增强解决方案,彻底解决内存占用与启动速度难题 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upsc…...

保姆级教程:用can-utils和Shell脚本自动化你的Ubuntu虚拟CAN测试环境
虚拟CAN环境自动化实战:从Shell脚本到CI/CD集成 在嵌入式开发和汽车电子领域,CAN总线通信测试是日常工作中不可或缺的环节。传统测试方法需要手动输入大量命令,不仅效率低下,还容易出错。本文将展示如何通过Shell脚本和can-utils工…...

重新定义Windows桌面美学:RoundedTB技术深度解析与实战应用
重新定义Windows桌面美学:RoundedTB技术深度解析与实战应用 【免费下载链接】RoundedTB Add margins, rounded corners and segments to your taskbars! 项目地址: https://gitcode.com/gh_mirrors/ro/RoundedTB 你是否曾对Windows任务栏的千篇一律感到厌倦&…...

DxWrapper技术架构深度解析:Windows老游戏兼容性修复的底层实现机制
DxWrapper技术架构深度解析:Windows老游戏兼容性修复的底层实现机制 【免费下载链接】dxwrapper Fixes compatibility issues with older games running on Windows 10/11 by wrapping DirectX dlls. Also allows loading custom libraries with the file extension…...

开源安全自动化平台Tracecat部署与实战:构建SOC告警研判流水线
1. 项目概述:一个为安全运营团队打造的自动化利器如果你在安全运营中心(SOC)、事件响应(IR)团队或者任何需要处理大量告警和流程的岗位上待过,那你一定对“告警疲劳”和“重复性手工操作”这两个词深恶痛绝…...

AlwaysOnTop:3步实现Windows窗口置顶,工作效率提升300%
AlwaysOnTop:3步实现Windows窗口置顶,工作效率提升300% 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多任务处理时频繁切换窗口࿰…...