爬虫工具(tkinter+scrapy+pyinstaller)
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个and关系的关键字 ,则用|隔开处理:爬取访问6个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段(不是图片或者图例)输出:输出到csv文件ui:窗口小程序,能实时地跟踪爬虫进度运行要求:不依赖于python环境,独立运行的exe文件
分析实现的主要程序
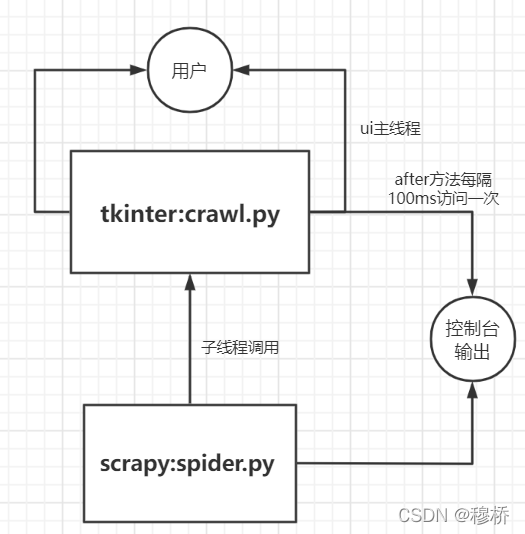
最后pyinstaller 打包crawl.py即可
实现
uI中的线程控制
import tkinter as tk
import time
import sys
import queue
import threading
def fmtTime(timestamp):localtime=time.localtime(timestamp)datetime=time.strftime("%Y-%m-%d %H:%M:%S",localtime)return datetimeclass re_Text():def __init__(self,queue):self.q=queuedef write(self,content):self.q.put(content)class GUI(object):def __init__(self,root):self.root=rootself.q=queue.Queue()self.initGUI(root)def show_msg(self):if not self.q.empty():self.text.insert("insert",self.q.get())self.text.see(tk.END)self.root.after(100,self.show_msg)def initGUI(self,root):root.title("点击数据")root.geometry('400x200+700+500')bn=tk.Button(root,text="click",width=10,command=self.show)#pack 控制排版bn.pack(side="top")scrollBar = tk.Scrollbar(root)scrollBar.pack(side="right", fill="y")self.text = tk.Text(root, height=10, width=45, yscrollcommand=scrollBar.set)self.text.pack(side="top", fill=tk.BOTH, padx=10, pady=10)#动态绑定scrollBar.config(command=self.text.yview)#不要想着中断机制或者调用子函数机制把它视为另一个线程# (write通信作用)sys.stdout=re_Text(self.q)root.after(100,self.show_msg)root.mainloop()def _show(self):i = 0for i in range(4):# 顺序执行 ui的刷新线程没有抢占cpu阻塞在这 等过了3秒后才刷新到texttime.sleep(1)# 重定向 调用writeprint(fmtTime(time.time()))def show(self):# 创建子线程 窗口程序可以不断地监听T=threading.Thread(target=self._show)T.start()if __name__=="__main__":root=tk.Tk()GUI(root)scrapy.py
技术细节可以参考之前的文章这里就直接写spider了
import scrapy
from scrapy import Selector
from scrapy import Request, signals
import pandas as pd
import re
from x93.items import csvItem
import os
import sysclass ExampleSpider(scrapy.Spider):name = 'spider'def __init__(self, **kwargs):super(ExampleSpider, self).__init__(**kwargs)self.data = list()self.keyws=kwargs.get('keywords')#print(self.keyws)print('----------')self.sites=['sh93.gov.cn','93.gov.cn','shszx.gov.cn','tzb.ecnu.edu.cn''ecnu.edu.cn/info/1094','ecnu.edu.cn/info/1095']def start_requests(self):#keyw=self.keywsfor keyw in self.keyws:keyw=keyw.strip()keyw=keyw.split('|')keyw="+".join(keyw)for site in self.sites:self.logger.info("site"+site)#url=f'https://cn.bing.com/search?q=site%3a{site}+allintext%3a{keyw}&first=1'url = f'https://cn.bing.com/search?q=site%3a{site}+{keyw}&first=1'yield Request(url, callback=self.parse, cb_kwargs={'first':1,'site':site,'keyw':keyw,'totallist':0})def parse(self, response,**kwargs):#百度网页 列表内容res=Selector(text=response.text)for a in res.xpath('//h2/a[@target="_blank"]'):title = a.xpath('./text()').get()href = a.xpath('./@href') .get()out = re.search("index",href)htm= re.search("htm",href)# 排除含index列表页 json 数据页if out!=None or htm==None:continuekwargs['href']=hrefyield Request(href,callback=self.get_detail,cb_kwargs=kwargs)#翻页# if kwargs['first']==1:# nub=res.xpath(r'//span[@class="sb_count"]/text()').get()# nub="".join(re.findall(re.compile('[\d]+'),nub))# kwargs['totallist']=int(nub)# #self.logger.info("kwargs['totallist']" + kwargs['totallist'])# if kwargs['first']+10<kwargs['totallist']:# self.logger.info(f"kwargs['totallist']{kwargs['totallist']}")# kwargs['first'] =kwargs['first'] + 10# url=f'https://cn.bing.com/search?q=site%3a{kwargs["site"]}+allintext%3a{kwargs["keyw"]}&first={kwargs["first"]} '# self.logger.info(f"url{url}")# yield Request(url, callback=self.parse, cb_kwargs=kwargs)def get_detail(self,response,**kwargs):res = Selector(response)title=''date =''content=''source=''if kwargs['site']=='sh93.gov.cn':try:title = res.xpath('//h3[contains(@class,"article-title")]/text()').get()date = res.xpath('//div[contains(@class,"article-title-news")]/span/text()').get()date = "".join(re.findall(re.compile(r"[\d-]+"), date))try:source=res.xpath('//span[@class="ml20"]/text()').get()except TypeError:source="九三上海市委新闻"try:content=res.xpath('//div[contains(@class,"article-content")]/p[not (@style="text-align: center;")]/''text()').get().strip()except :content=res.xpath('//span[contains(@style,"font-family")]/text()').get().strip()except:try:title = res.xpath('//td[@class="pix16blackl32"]/text()').get()date = res.xpath('//td[@class="pixh4_line24"]/text()').get()date = re.findall(re.compile(r"[\d-]+"), date)date = "-".join(date)source = "九三学社上海市委员会"content = res.xpath("//p/text()").get()except:self.logger.error(f"无法解析{kwargs['href']}")if kwargs['site']=='93.gov.cn':title=res.xpath('//div[contains(@class,"pageTitle")]/h2/text()').get()date=res.xpath('//div[contains(@class,"pageTitle")]//ul/li[1]/text()').get()date = "".join(re.findall(re.compile(r"[\d-]+"), date))source=res.xpath('//div[contains(@class,"pageTitle")]//ul/li[2]/text()').get()[3:]try:content = res.xpath('//div[@class="text"]/p[not (@style="text-align: center;")]/text()').get().strip()except AttributeError:#print("url:"+kwargs['href'])content= res.xpath('//div[@class="text"]//span[contains(@style,"font-family")]/text()').get().strip()#content= res.xpathif kwargs['site']=='shszx.gov.cn':title=res.xpath('//h2[@id="ivs_title"]/text()').get()date= res.xpath('//div[@class="fc con22 lh28 grey12"]/text()').get()date="".join(re.findall(re.compile(r"[\d-]+"), date))source="上海政协"cnt=1while content == '':cnt=cnt+1content=res.xpath(f'//div[@id="ivs_content"]/p[not (@align="center") and 'f'not (@style="text-align: center;")][{cnt}]/text()').get().strip()if kwargs['site']=='tzb.ecnu.edu.cn':title=res.xpath('//h1[@class="arti_title"]/text()').get()#text() 会取第一个date=res.xpath('//span[@class="arti_update"]/text()').get()date="".join(re.findall(re.compile(r"[\d-]+"), date))source=res.xpath('//span[@class="arti_department"]/text()').get()[4:]content=res.xapth('//div[@class="wp_articlecontent"]//p[contains(@style,"font-size")]/text()').get().strip()if 'ecnu.edu.cn' in kwargs['site']:title=res.xpath('//h2[@class="m3nTitle"]/text()').get()date=res.xpath('//span[@class="m3ntm"]/text()').get()date=re.findall(re.compile(r"[\d-]+"), date)date="-".join(date)if "1094" in kwargs['site']:source="华东师范大学新闻热点"else:source = "华东师范大学媒体关注"content=res.xpath('//p/span[contains(@style,"font-family")]//text()|''//p[contains(@style,"text-align:justify")]/text()').get().strip()item=csvItem()item['keyword']=kwargs['keyw']item['title']=titleitem['date']=dateitem['source']=sourceitem['content']=contentitem['url']=kwargs['href']print(title, date, content)yield itemui脚本中运行scrapyscrapy 脚本运行有三种方式,实现细节可以参考官方文档cmdline.execute方式只能运行一个爬虫,而其他两种方式可以同时运行多个(异步+异步)。
scrapy爬虫比较耗时,需要放在子线程工作,因此选用crawlRunner(crawlProcess要求运行在主线程就不行),但是不清楚为什么刚开始正常运行后来又是报错提示,signal run in main thread.可以尝试的解决方法,参考博客
# !/user/bin/env Python3
# -*- coding:utf-8 -*-from scrapy import *
import scrapy
from scrapy import Selector
from scrapy import Request, signals
import pandas as pd
import re
import time
import tkinter as tk
from tkinter import filedialog, dialog
import os
import threading
import logging
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from scrapy.cmdline import execute
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from scrapy.utils.log import configure_logging
from x93.spiders.spider import ExampleSpider
from scrapy.utils.project import get_project_settingslogger = logging.getLogger(__name__)
file_path = ''
file_text = ''
class re_Text():def __init__(self,text):self.text=textdef write(self,content):self.text.insert("insert",content )self.text.see(tk.END)
class GUI():def __init__(self):self.root=tk.Tk()self.root.title("ecnu数据爬取工具")self.root.geometry("400x400+200+200")def initGUI(self):# self.root.title('窗口标题') # 标题# self.root.geometry('500x500') # 窗口尺寸self.scrollBar = tk.Scrollbar(self.root)self.scrollBar.pack(side="right", fill="y")self.text = tk.Text(self.root, height=10, width=45, yscrollcommand=self.scrollBar.set)self.text.pack(side="top", fill=tk.BOTH, padx=10, pady=10)#self.scrollBar.config(command=self.text.yview) # 动态绑定 滚动条随着鼠标移动bt1 = tk.Button(self.root, text='打开文件', width=15, height=2, command=self.open_file)bt1.pack()bt2 = tk.Button(self.root, text='爬取数据', width=15, height=2, command=self._app)bt2.pack()#bt3 = tk.Button(self.root, text='保存文件', width=15, height=2, command=save_file)#bt3.pack()def open_file(self):'''打开文件:return:'''global file_pathglobal file_textfile_path = filedialog.askopenfilename(title=u'选择文件', initialdir=(os.path.expanduser('H:/')))print('打开文件:', file_path)if file_path is not None:with open(file=file_path, mode='r+', encoding='utf-8') as file:file_text = file.readlines()print(file_text)def thread_it(func, *args):'''将函数打包进线程'''# 创建t = threading.Thread(target=func, args=args)# 守护 !!!t.setDaemon(True)# 启动t.start()# 阻塞--卡死界面!#t.join()def _app(self):t=threading.Thread(target=self.app,args=())t.start()def app(self):global file_textlogger.info(f"type(file_text){type(file_text)}")runner = CrawlerRunner(get_project_settings())d = runner.crawl(ExampleSpider,keywords=file_text)d.addBoth(lambda _: reactor.stop())reactor.run()self.text.insert('insert', "爬取成功")# process = CrawlerProcess(get_project_settings())# process.crawl(ExampleSpider,keywords=file_text)# process.start()# cmd=f'scrapy crawl spider -a kw={file_text}'.split()# execute(cmd)# cmd = 'python Run.py'# print(os.system(cmd))g=GUI()
g.initGUI()
sys.stdout=re_Text(g.text)
g.root.mainloop() # 显示pyinstaller 打包因为看到很多博客都说用pyinstaller打包scrapy 需要引入较多依赖,修改配置文件等多余的操作,一直没敢下手尝试直接用pyinstaller打包主程序,转向成功案例较多的单线程运行爬虫方式,后来还是败给的scrapy框架,返回失败的retry机制以及代理更换的便捷,毕竟批量输入无可避免的有无法访问目标计算机问题。
打包后的程序(调试问题后就上传占个位)
文章转载自:mingruqi
原文链接:https://www.cnblogs.com/Im-Victor/p/17081823.html
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
爬虫工具(tkinter+scrapy+pyinstaller)
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个and关系的关键字 ,则用|隔开处理:爬取访问6个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段࿰…...

MySQL常用sql语句记录
1,创建用户及赋权 -- 创建用户 CREATE USER usernamelocalhost IDENTIFIED BY password;-- 赋予所有权限 GRANT ALL PRIVILEGES ON database_name.* TO usernamelocalhost;-- 赋予特定表的某些权限 GRANT SELECT, INSERT ON table_name TO usernamelocalhost;-- 更…...

2024.1.4力扣每日一题——被列覆盖的最多行数
2024.1.4 题目来源我的题解方法一 回溯位运算优化 题目来源 力扣每日一题;题序:2397 我的题解 方法一 回溯位运算优化 这道题一看就会想到使用回溯法,但是采用回溯法后如何判断有多少行被覆盖,直接计算矩阵时间复杂度较高&…...
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)
本实践教程将教你如何使用 Elasticsearch 构建完整的搜索解决方案。 在本教程中你将学习: 如何对数据集执行全文关键字搜索(可选使用过滤器)如何使用机器学习模型生成、存储和搜索密集向量嵌入如何使用 ELSER 模型生成和搜索稀疏向量如何使用…...

第五讲_css元素显示模式
css元素显示模式 1. 元素的显示模式1.1 块元素1.2 行内元素1.3 行内块元素 2. 元素根据显示模式分类3. 修改元素的显示模式 1. 元素的显示模式 1.1 块元素 块元素的特性: 在页面中独占一行,从上到下排列。默认宽度,撑满父元素。默认高度&a…...

Shell脚本入门实战:探索自动化任务与实用场景
引言 Shell脚本作为一种强大的自动化工具,在现代操作系统中具有广泛的应用。无论是简单的文件操作,还是复杂的系统管理,Shell脚本都能提供高效、快速的解决方案。在本文中,我们将探索Shell脚本的基础知识,并通过实战场…...

【AI视野·今日Sound 声学论文速览 第四十二期】Fri, 5 Jan 2024
AI视野今日CS.Sound 声学论文速览 Fri, 5 Jan 2024 Totally 10 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers PosCUDA: Position based Convolution for Unlearnable Audio Datasets Authors Vignesh Gokul, Shlomo Dubnov深度学习模型需要大量干净的…...

Java中如何使用SQLite数据库
目录 SQLite简介SQLite优势安装 SQLite基本使用Java使用SQLite Springboot使用SQLite1.添加依赖2.配置数据库3.创建实体类 4.创建Repository接口5.创建控制器6.运行应用程序 SQLite简介 SQLite 是一个开源的嵌入式关系数据库,实现了自给自足的、无服务器的、配置无…...

kettle的基本介绍和使用
1、 kettle概述 1.1 什么是kettle Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 1.2 Kettle核心知识点 1.2.1 Kettle工程存储方式 以XML形式存储以资源库方式存储…...

数据结构第2章 栈和队列
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 0、思维导图栈和队列1、栈1)特点2࿰…...

Axure鲜花商城网站原型图,网上花店订花O2O本地生活电商平台
作品概况 页面数量:共 30 页 兼容软件:仅支持Axure RP 9/10,非程序软件无源代码 应用领域:鲜花网、花店网站、本地生活电商 作品特色 本作品为「鲜花购物商城」网站模板,高保真高交互,属于O2O本地生活电…...
【docker】centos 使用 Nexus Repository 搭建私有仓库
Nexus Repository 是一种流行的软件仓库管理工具,它可以帮助您搭建私有仓库,以便在内部网络或私有云环境中存储、管理和分发各种软件包和组件。 它常被用于搭建Maven的镜像仓库。本文演示如何用Nexus Repository搭建docker 私有仓库。 使用Nexus Repos…...
RabbitMQ(八)消息的序列化
目录 一、为什么需要消息序列化?二、常用的消息序列化方式1)Java原生序列化(默认)2)JSON格式3)Protobuf 格式4)Avro 格式5)MessagePack 格式 三、总结 RabbitMQ 是一个强大的消息中间…...

23款奔驰GLC260L升级原厂540全景影像 安装效果分享
嗨 今天给大家介绍一台奔驰GLC260L升级原厂360全景影像 新款GLC升级原厂360全景影像 也只需要安装前面 左右三个摄像头 后面的那个还是正常用的,不过不一样的是 升级完成之后会有多了个功能 那就是新款透明底盘,星骏汇小许Xjh15863 左右两边只需要更换后…...

【CSS】文字描边的三种实现方式
目录 1. 可行的几种方式1.1. text-shadow 描边代码优缺点 1.2. text-stroke 描边实现优缺点 1.3. svg 描边实现优缺点 总结 1. 可行的几种方式 text-shadow–webkit-text-strokesvg 1.1. text-shadow 描边 MDN text-shadow 代码 <div class"text stroke">…...

【事务】事务传播级别
Spring事务定义了7种传播机制: PROPAGATION_REQUIRED:默认的Spring事物传播级别,若当前存在事务,则加入该事务,若不存在事务,则新建一个事务。 PAOPAGATION_REQUIRE_NEW:若当前没有事务&#x…...
Android WiFi 连接
Android WiFi 连接 1、设置中WiFi显示2、WiFi 连接流程2.1 获取PrimaryClientModeManager2.2 ClientModeImpl状态机ConnectableState2.3 ISupplicantStaNetworkCallback 回调监听 3、 简要时序图4、原生低层驱动5、关键日志 1、设置中WiFi显示 Android WiFi基础概览 packages/a…...

PLC与上位机PN通讯时,如何防止连接失败?
连接西门子PLC时失败,或者连接不上PLC,你可能需要做以下几点设置才可以。 一般来说每个PLC都有自己的IP地址,如果你的地址与PLC的地址冲突也就是地址重复是连接不上PLC的,如果地址没有冲突,但是不是在一个网段上也会导…...

LDD学习笔记 -- Linux错误码
LDD学习笔记 -- Linux错误码 EACCES(Permission Denied) 13EEXIST(File Exits) 17EINVAL(Invalid Argument) 22ENOENT(No Such File or Directory)ENOMEM(Out of Memory)EIO(Input/Output Error) 5ENOSPC(No space Left on Device)ENOTTY(Not a Typewrite)EPIPE(Broken Pipe)EI…...
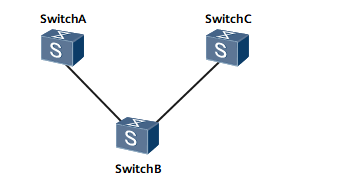
华为交换机入门(六):VLAN的配置
VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。VLAN内的主机间可以直接通信,而VLAN间不能直接互通,从而将广播报文限制在一个VLAN内。 VLAN 主要用来解决如何…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...